Fine-Tuned In-Context Learners for Efficient Adaptation
Reading time: 5 minute
...
📝 Original Info
Title: Fine-Tuned In-Context Learners for Efficient Adaptation
ArXiv ID: 2512.19879
Date: 2025-12-22
Authors: ** - Jörg Bornschein (*) – Google DeepMind - Clare Lyle – Google DeepMind - Yazhe Li (†) – Microsoft AI - Amal Rannen‑Triki – Google DeepMind - Xu Owen He (†) – MakerMaker AI - Razvan Pascanu – Google DeepMind *Corresponding author: bornschein@google.com † Work performed while at Google DeepMind — **
📝 Abstract
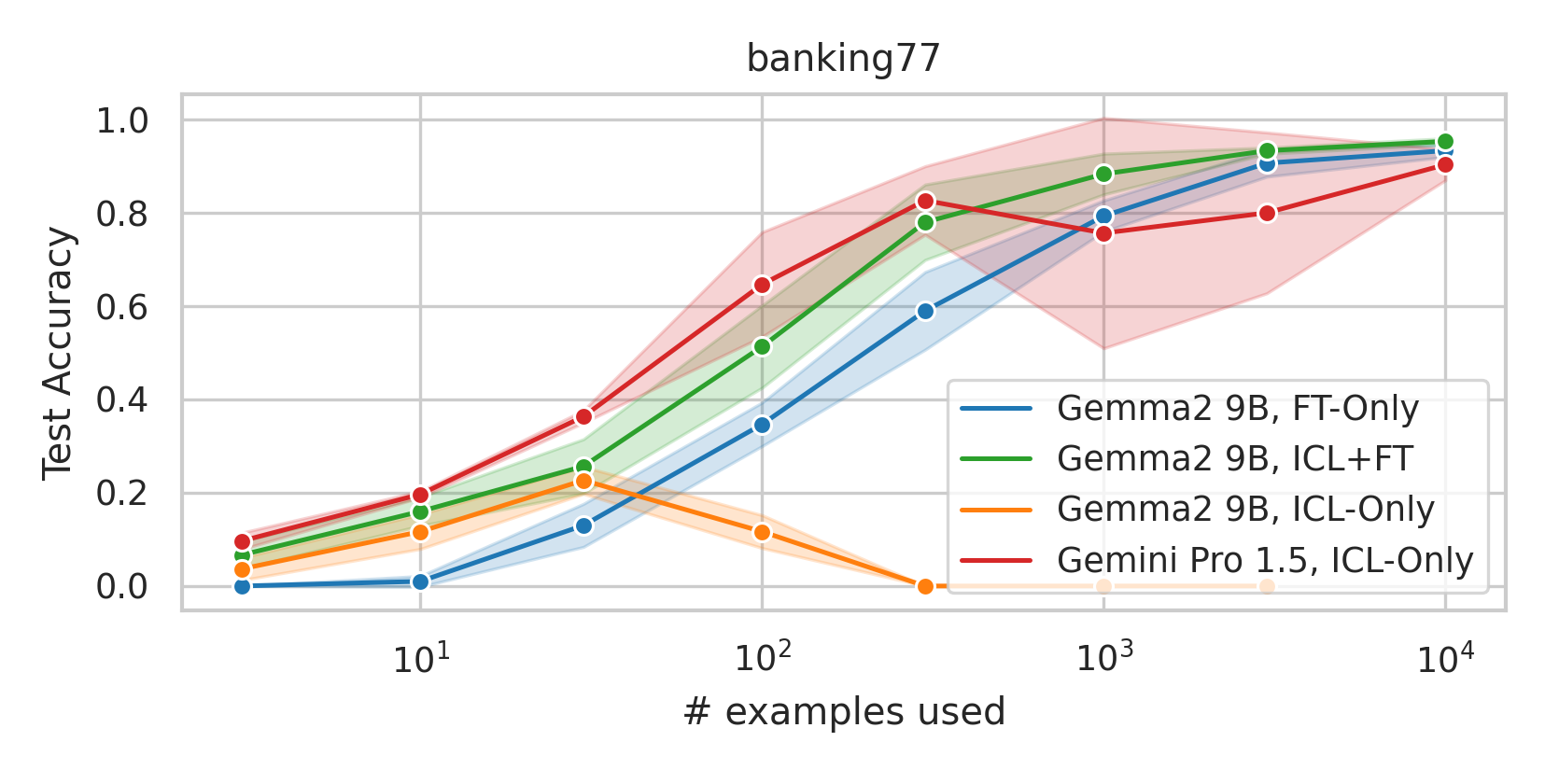
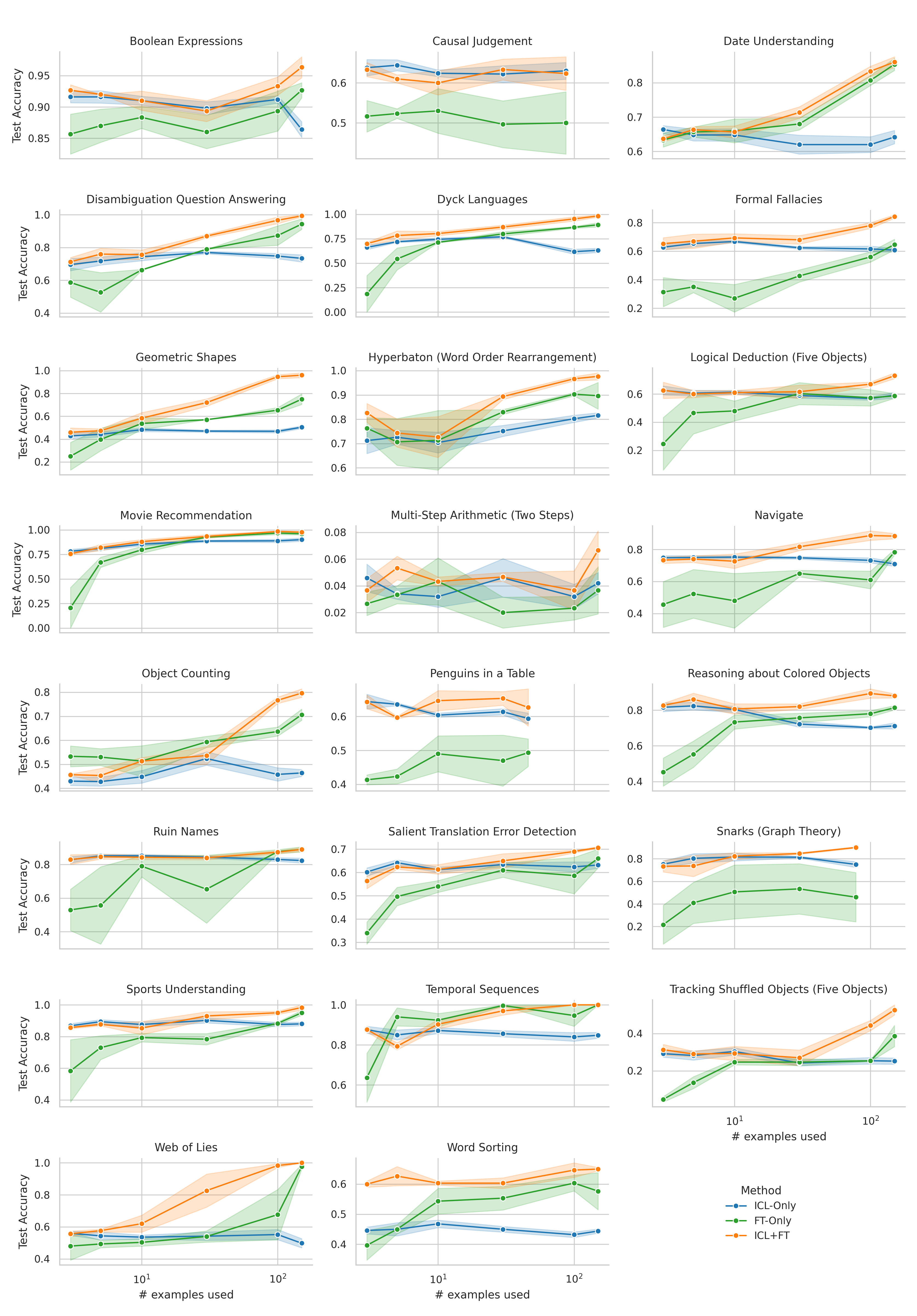
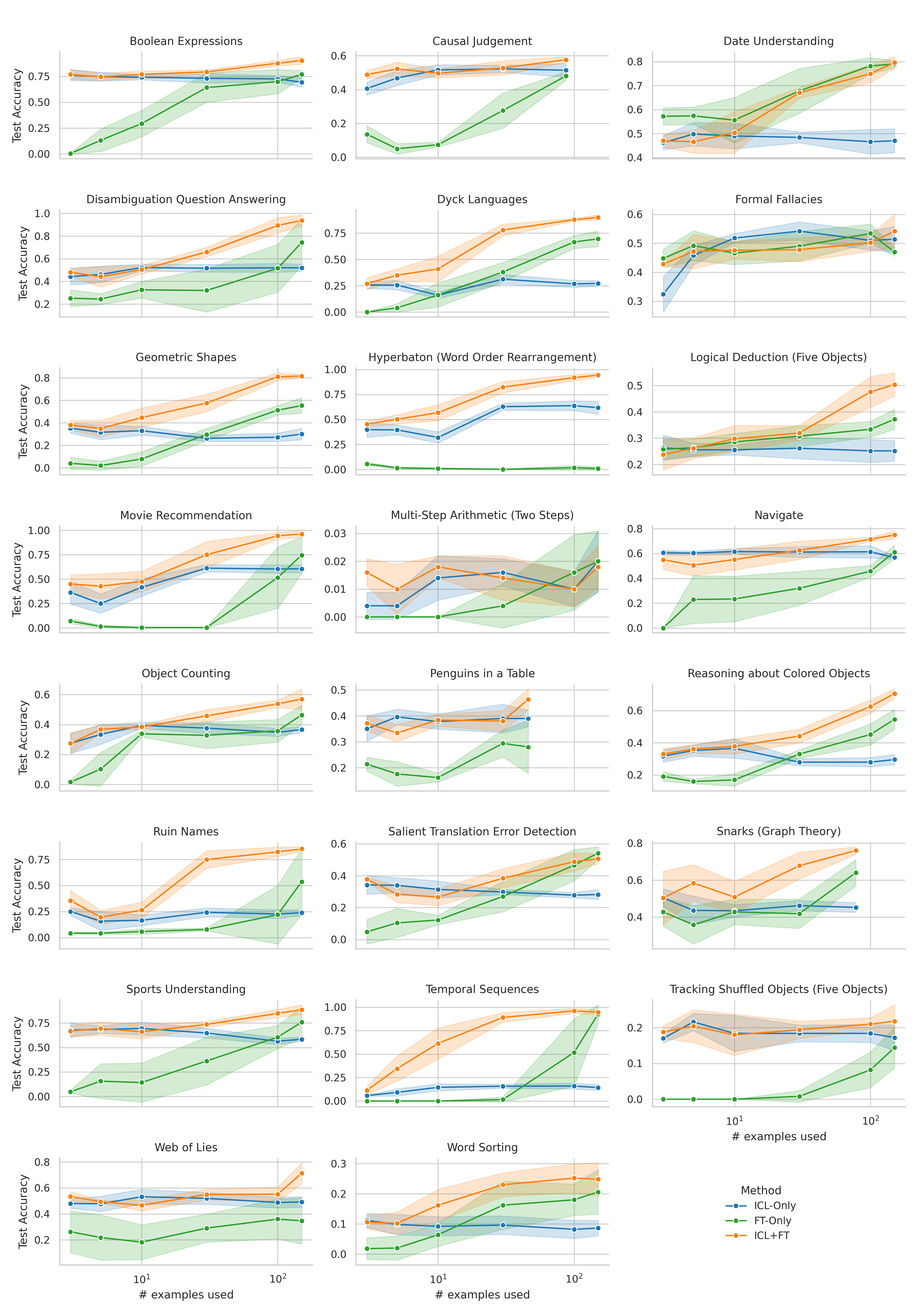
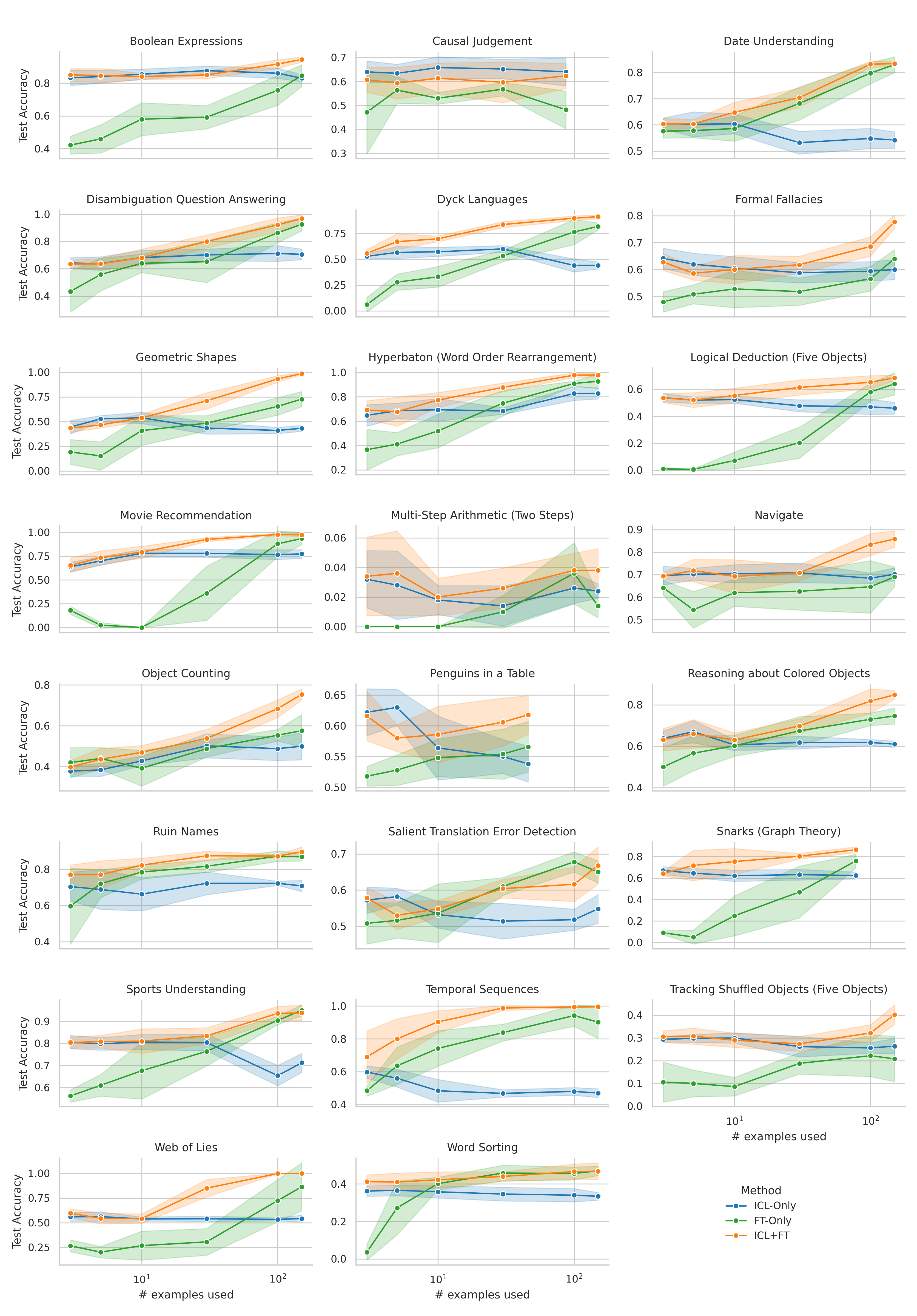
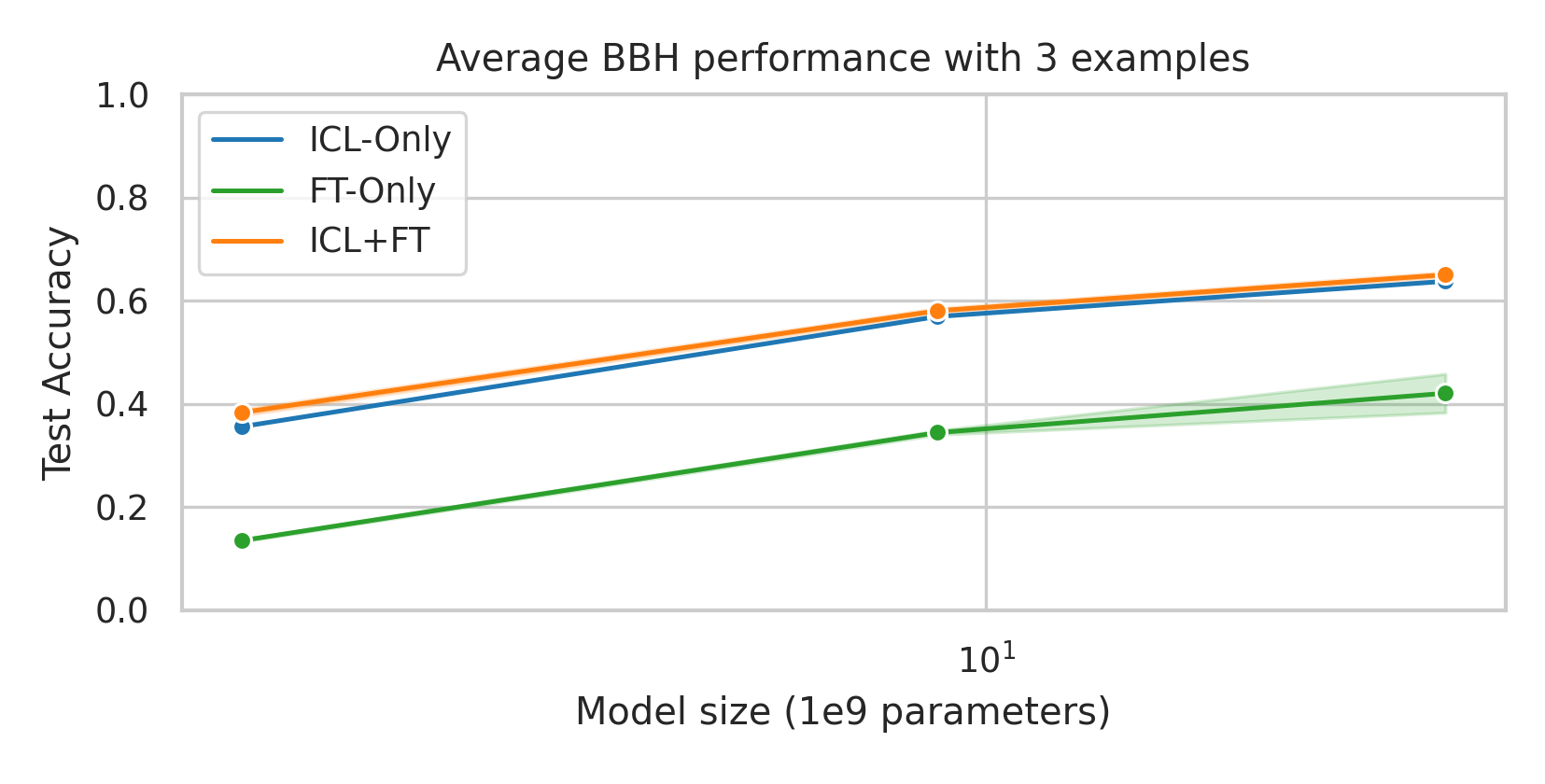
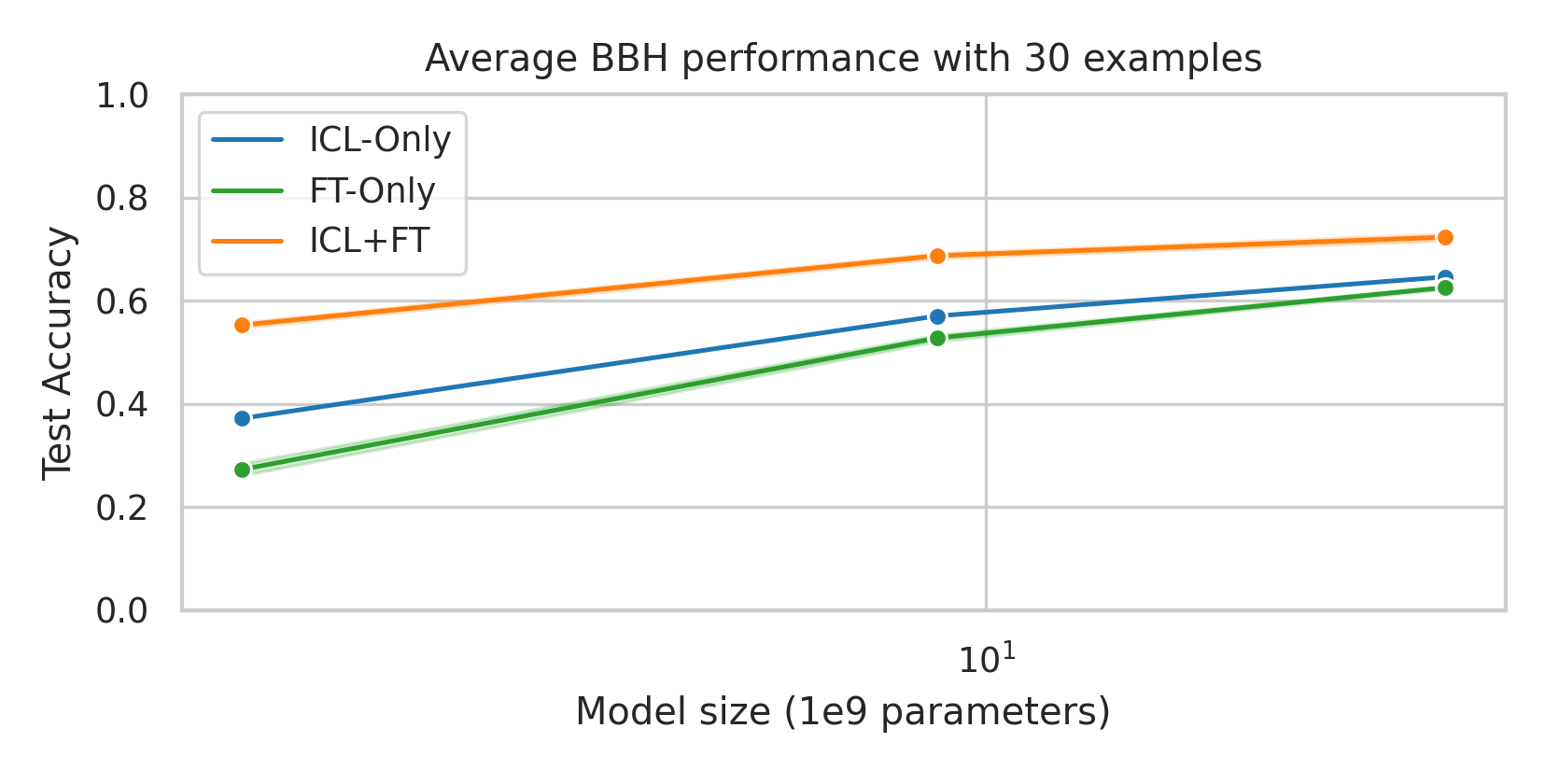
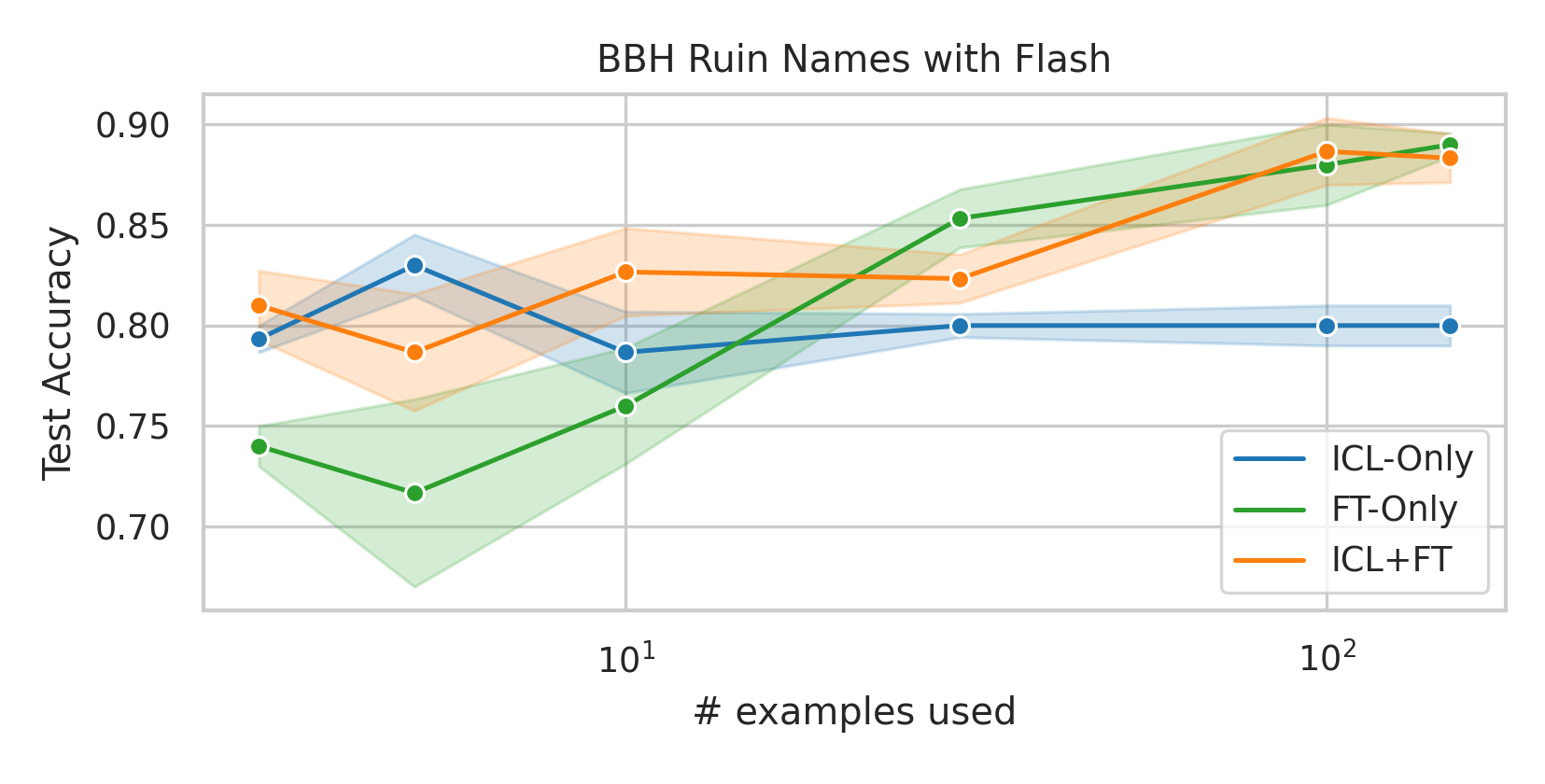
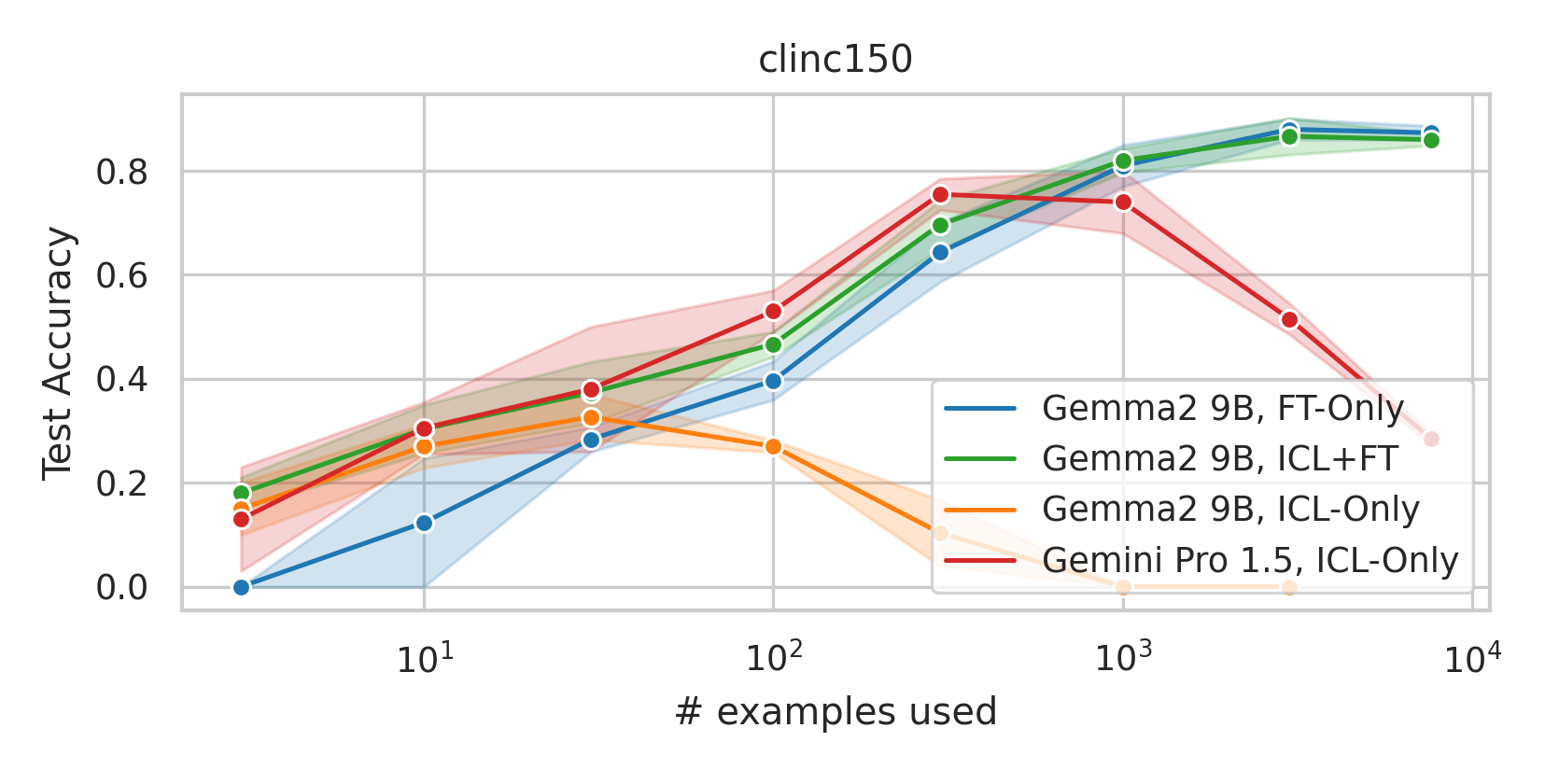
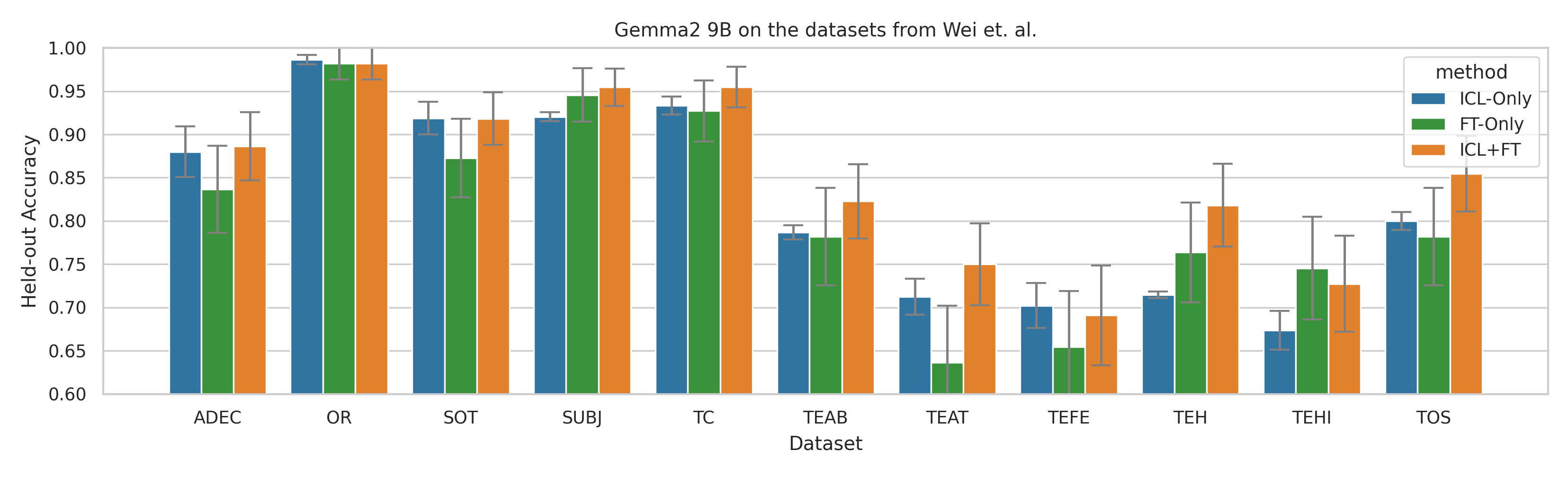
When adapting large language models (LLMs) to a specific downstream task, two primary approaches are commonly employed: (1) prompt engineering, often with in-context few-shot learning, leveraging the model's inherent generalization abilities, and (2) fine-tuning on task-specific data, directly optimizing the model's parameters. While prompt-based methods excel in few-shot scenarios, their effectiveness often plateaus as more data becomes available. Conversely, fine-tuning scales well with data but may underperform when training examples are scarce. We investigate a unified approach that bridges these two paradigms by incorporating in-context learning directly into the fine-tuning process. Specifically, we fine-tune the model on task-specific data augmented with in-context examples, mimicking the structure of k-shot prompts. This approach, while requiring per-task fine-tuning, combines the sample efficiency of in-context learning with the performance gains of fine-tuning, leading to a method that consistently matches and often significantly exceeds both these baselines. To perform hyperparameter selection in the low-data regime, we propose to use prequential evaluation, which eliminates the need for expensive cross-validation and leverages all available data for training while simultaneously providing a robust validation signal. We conduct an extensive empirical study to determine which adaptation paradigm - fine-tuning, in-context learning, or our proposed unified approach offers the best predictive performance on a concrete data downstream-tasks.
💡 Deep Analysis
📄 Full Content
FINE-TUNED IN-CONTEXT LEARNERS
FOR EFFICIENT ADAPTATION
J¨org Bornschein∗
Google DeepMind
Clare Lyle
Google DeepMind
Yazhe Li†
Microsoft AI
Amal Rannen-Triki
Google DeepMind
Xu Owen He†
MakerMaker AI
Razvan Pascanu
Google DeepMind
ABSTRACT
When adapting large language models (LLMs) to a specific downstream task, two
primary approaches are commonly employed: (1) prompt engineering, often with
in-context few-shot learning, leveraging the model’s inherent generalization abil-
ities, and (2) fine-tuning on task-specific data, directly optimizing the model’s
parameters. While prompt-based methods excel in few-shot scenarios, their effec-
tiveness often plateaus as more data becomes available. Conversely, fine-tuning
scales well with data but may underperform when training examples are scarce.
We investigate a unified approach that bridges these two paradigms by incorpo-
rating in-context learning directly into the fine-tuning process. Specifically, we
fine-tune the model on task-specific data augmented with in-context examples,
mimicking the structure of k-shot prompts. This approach, while requiring per-
task fine-tuning, combines the sample efficiency of in-context learning with the
performance gains of fine-tuning, leading to a method that consistently matches
and often significantly exceeds both these baselines. To perform hyperparame-
ter selection in the low-data regime, we propose to use prequential evaluation,
which eliminates the need for expensive cross-validation and leverages all avail-
able data for training while simultaneously providing a robust validation signal.
We conduct an extensive empirical study to determine which adaptation paradigm
- fine-tuning, in-context learning, or our proposed unified approach offers the best
predictive performance on a concrete data downstream-tasks.
1
INTRODUCTION
The rapid progress in Large Language Models (LLMs) has unleashed a flood of new techniques for
adapting these powerful models to specific downstream tasks. A wide spectrum of approaches have
been proposed, from established methods like full fine-tuning or parameter-efficient fine-tuning to
a diverse array of prompting techniques, including in-context learning, retrieval-augmented genera-
tion, and beyond (Schulhoff et al., 2024). Irrespective of the chosen adaptation strategy, the avail-
ability of ground-truth or ”golden” data remains essential, not only for evaluating the efficacy of the
chosen method, but also for tuning relevant hyper-parameters. Within this landscape, fine-tuning
and in-context few-shot learning (Brown et al., 2020) can be seen as two cornerstone techniques
for adapting LLMs. In the former, the model’s parameters are directly optimized on task-specific
data, enabling it to learn nuanced patterns and potentially achieve superior performance with suf-
ficient training data. In contrast, in-context learning leverages the model’s pre-trained knowledge
and generalization capabilities by providing a few illustrative examples within the prompt, offering
a sample-efficient approach particularly suitable when data is limited. However, in-context learn-
ing’s effectiveness is intrinsically tied to the generalization abilities of the model and is generally
expected to not scale as effectively with larger datasets and number of examples in-context (Wang
et al., 2023; Li et al., 2024).
∗Corresponding Author: bornschein@google.com
†Work done while at Google DeepMind
1
arXiv:2512.19879v1 [cs.LG] 22 Dec 2025
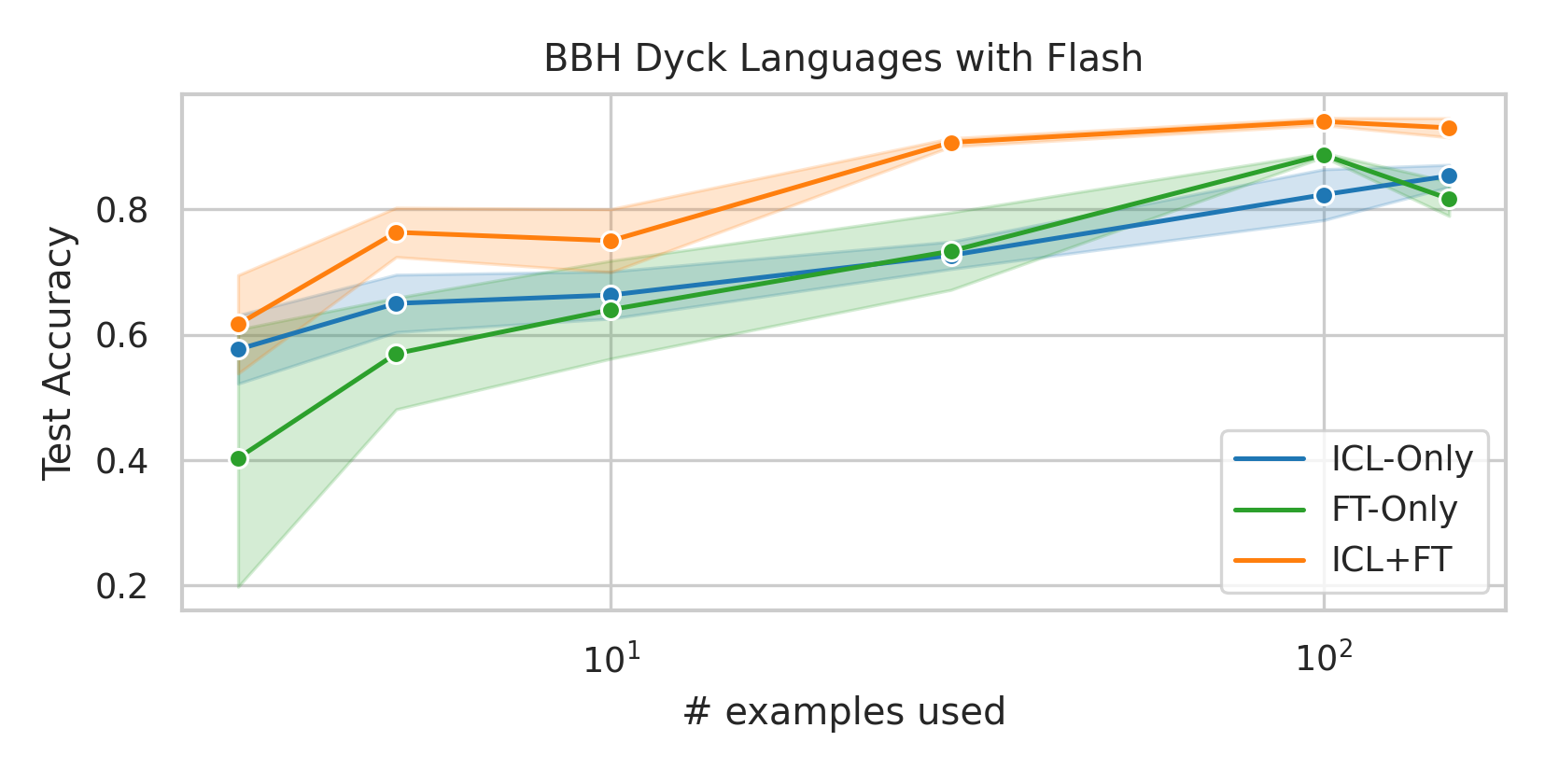
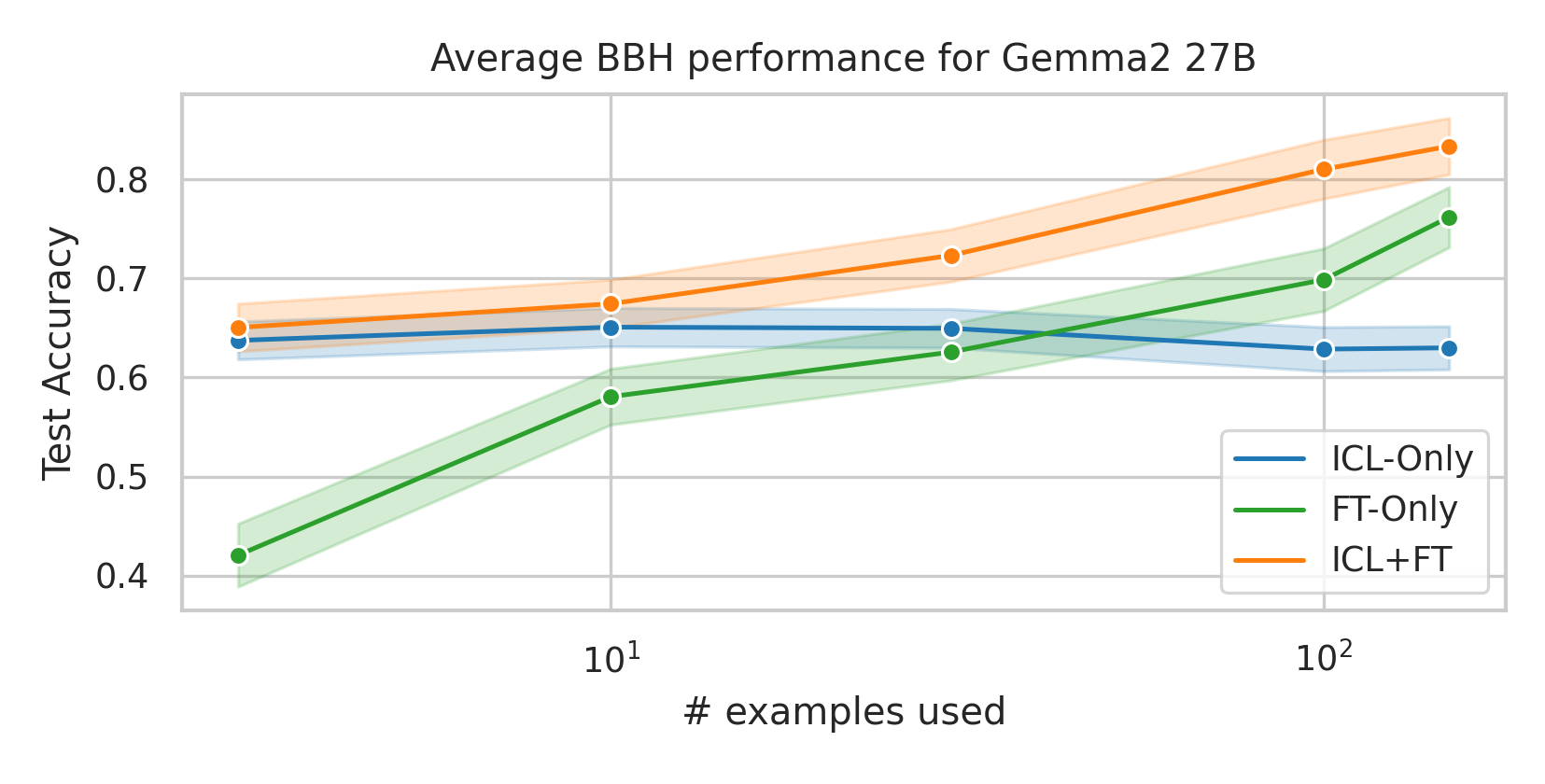
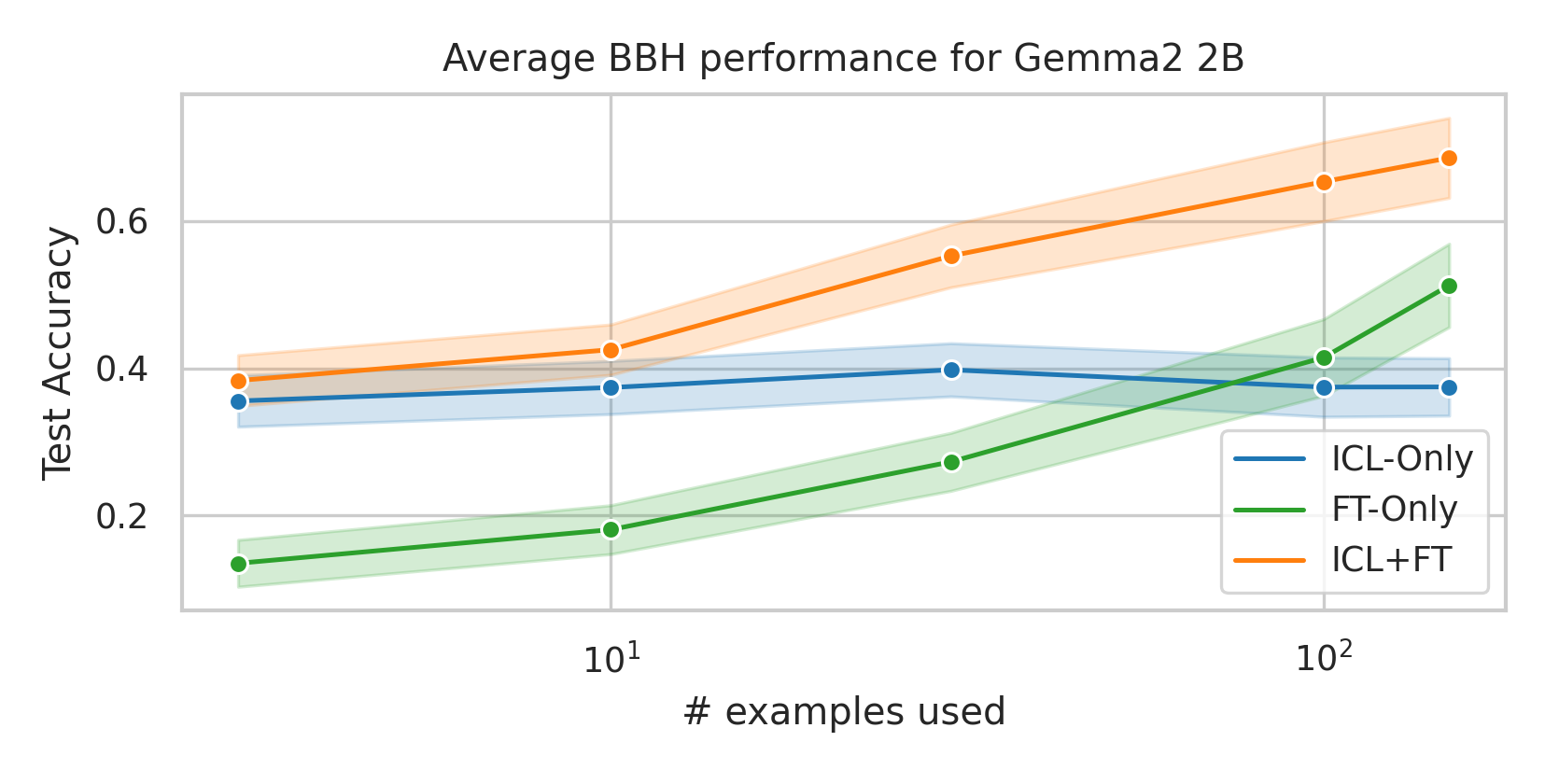
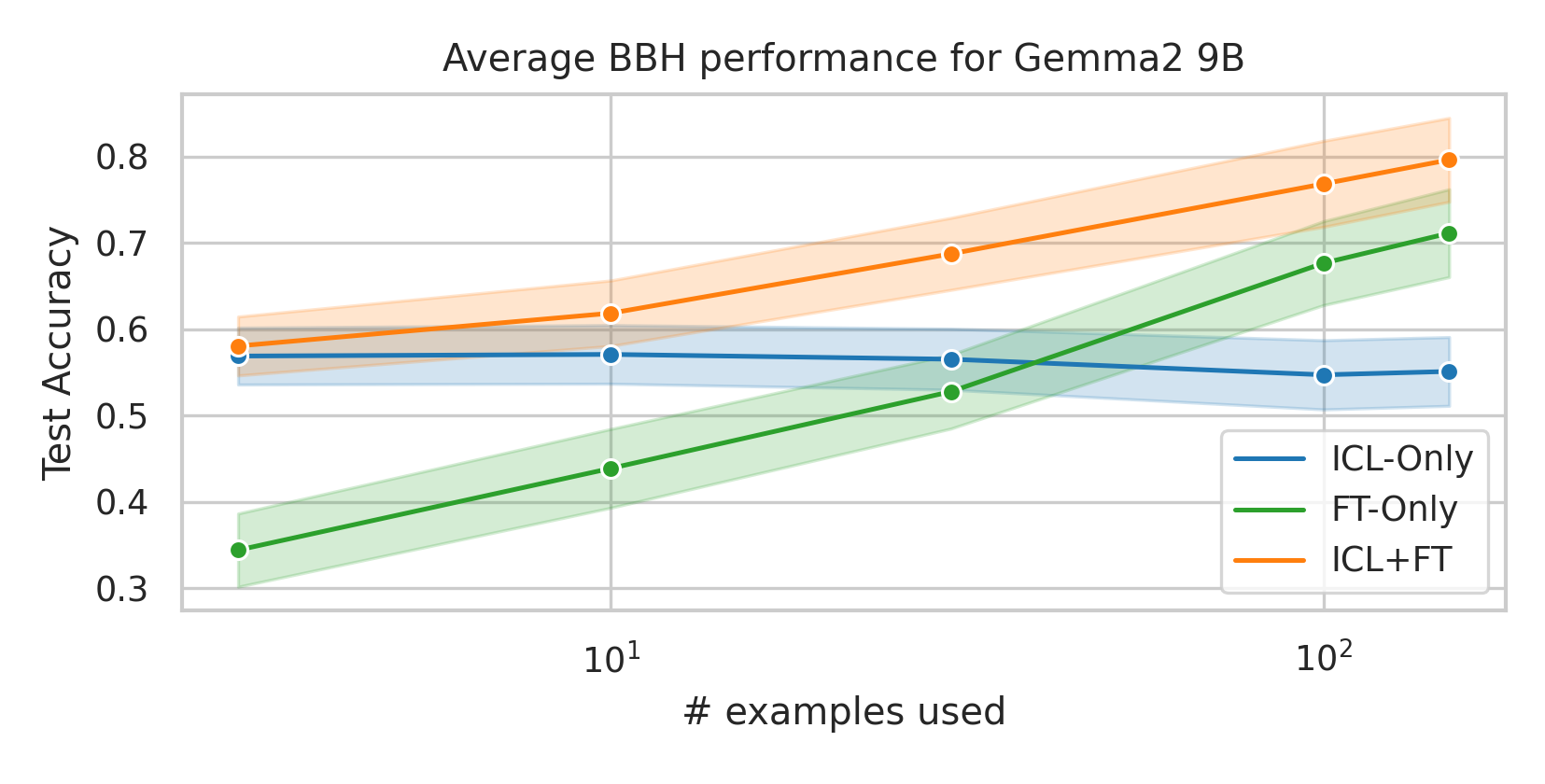
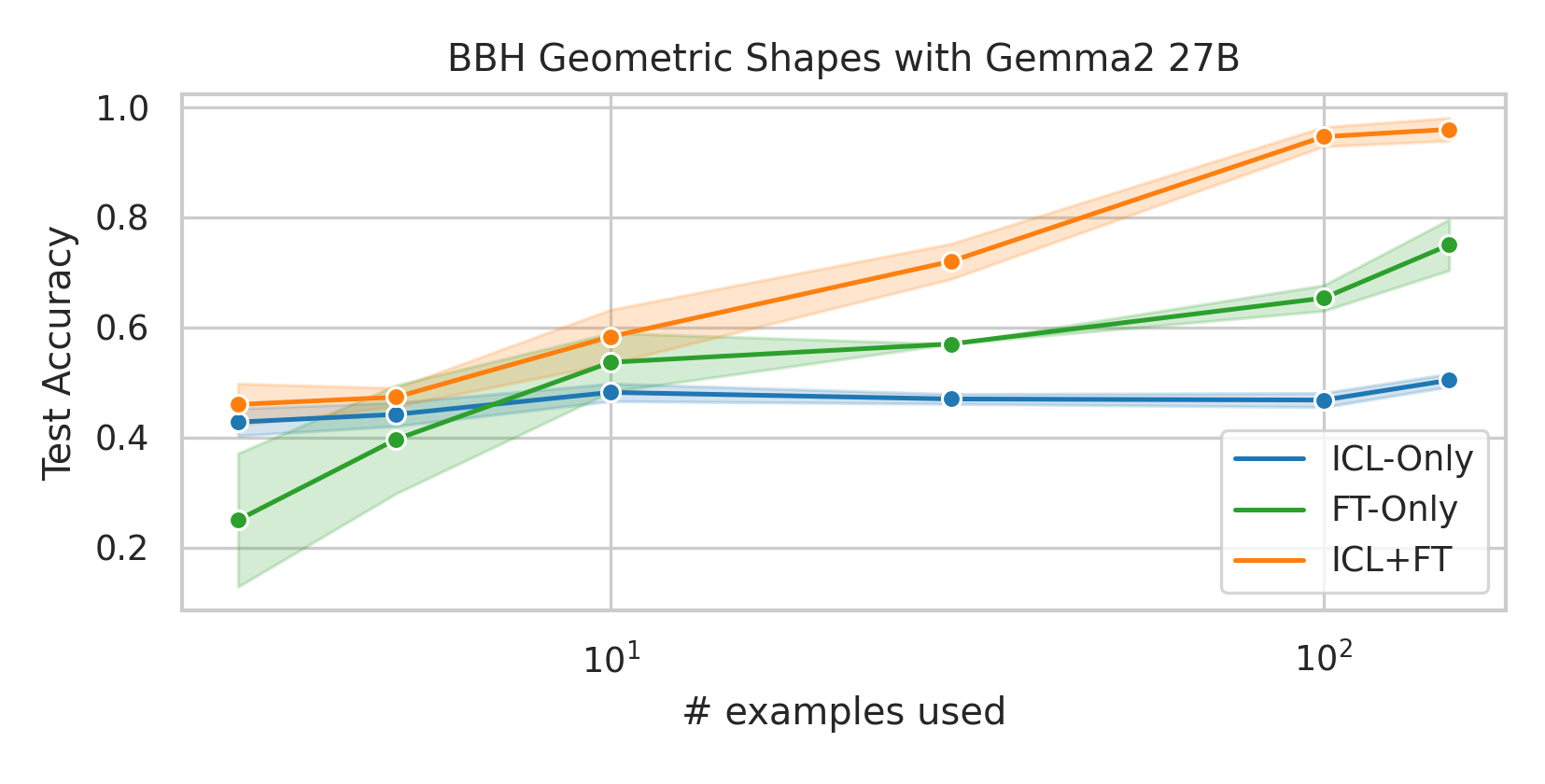
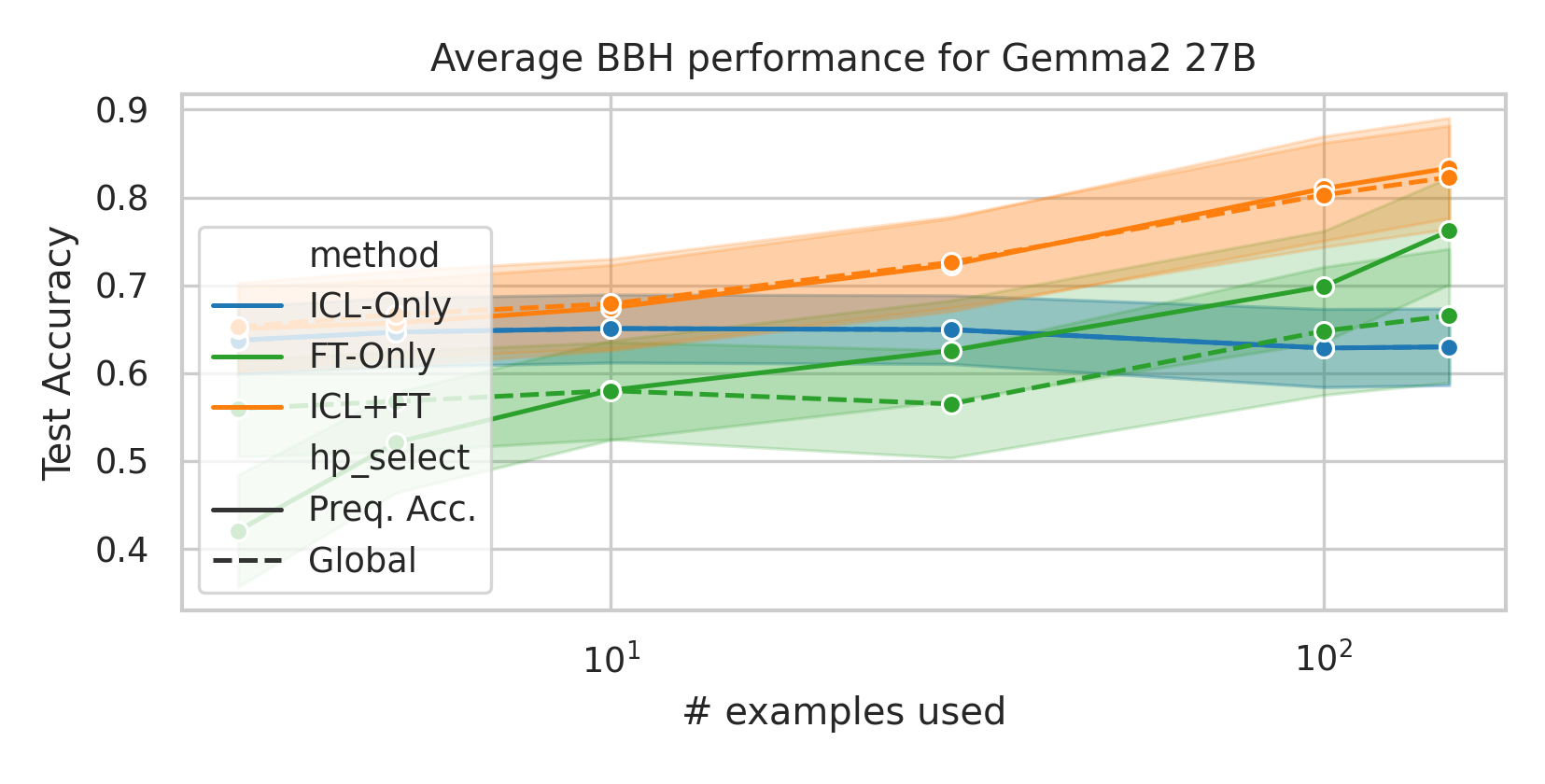
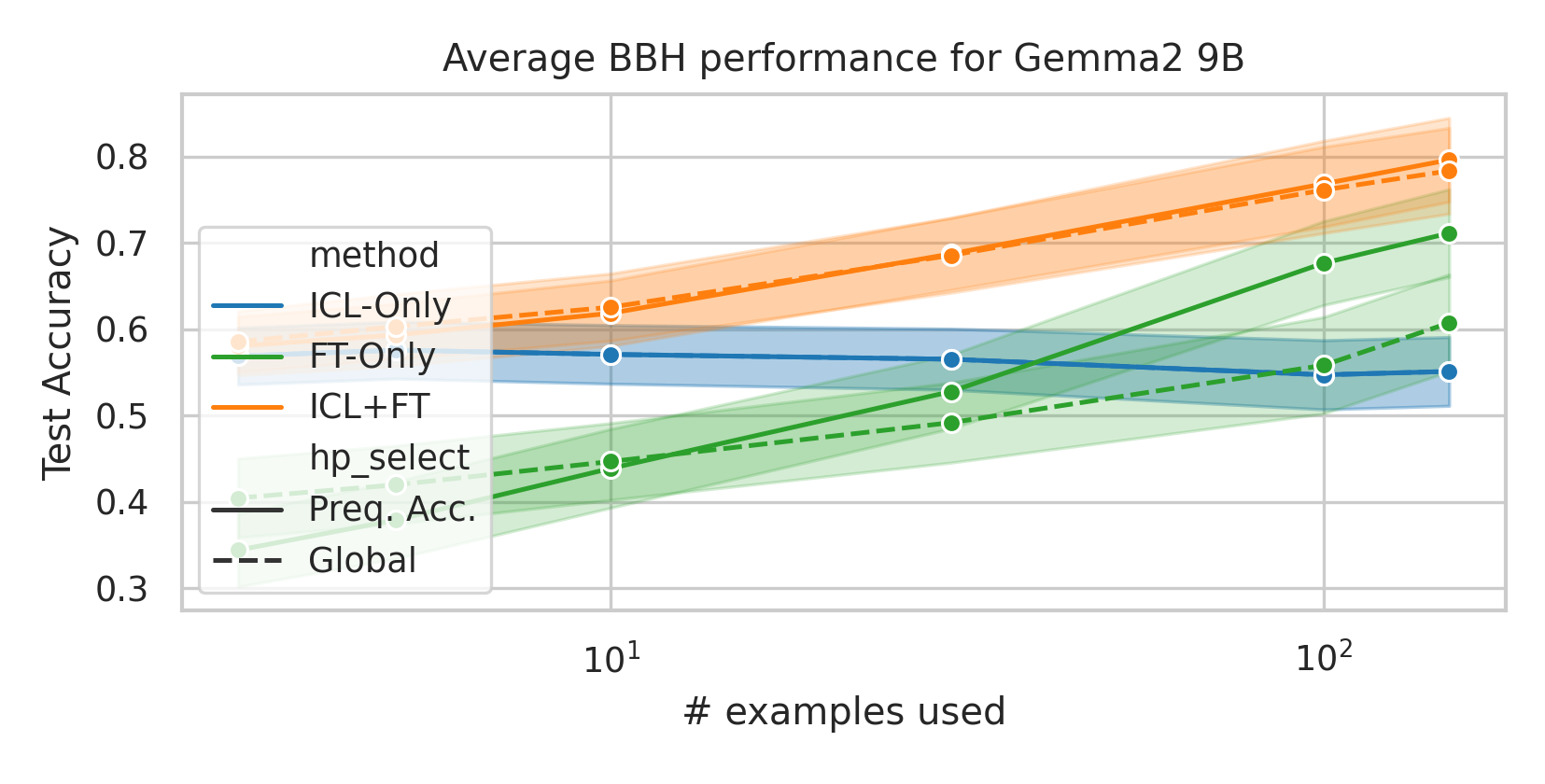
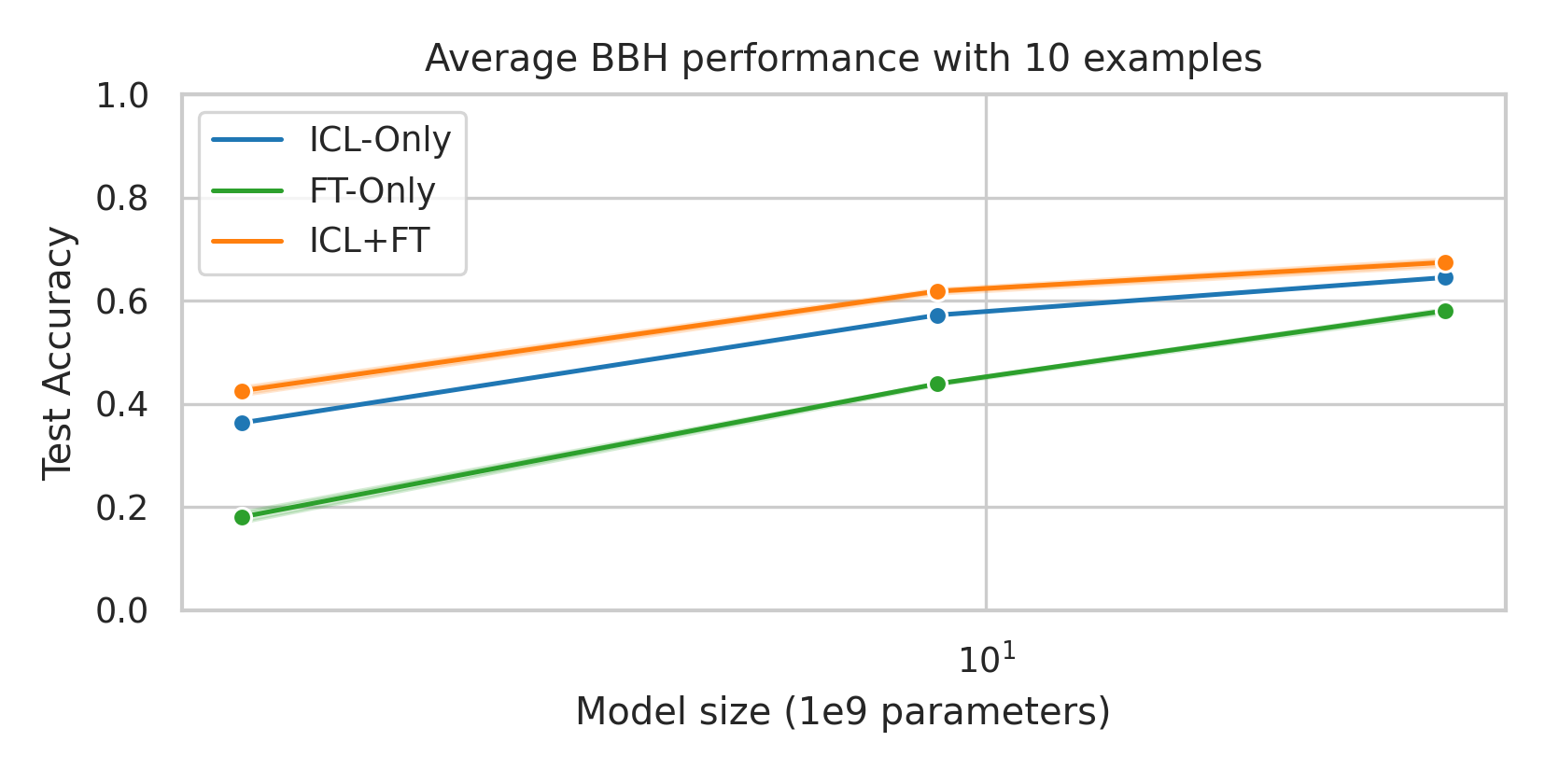
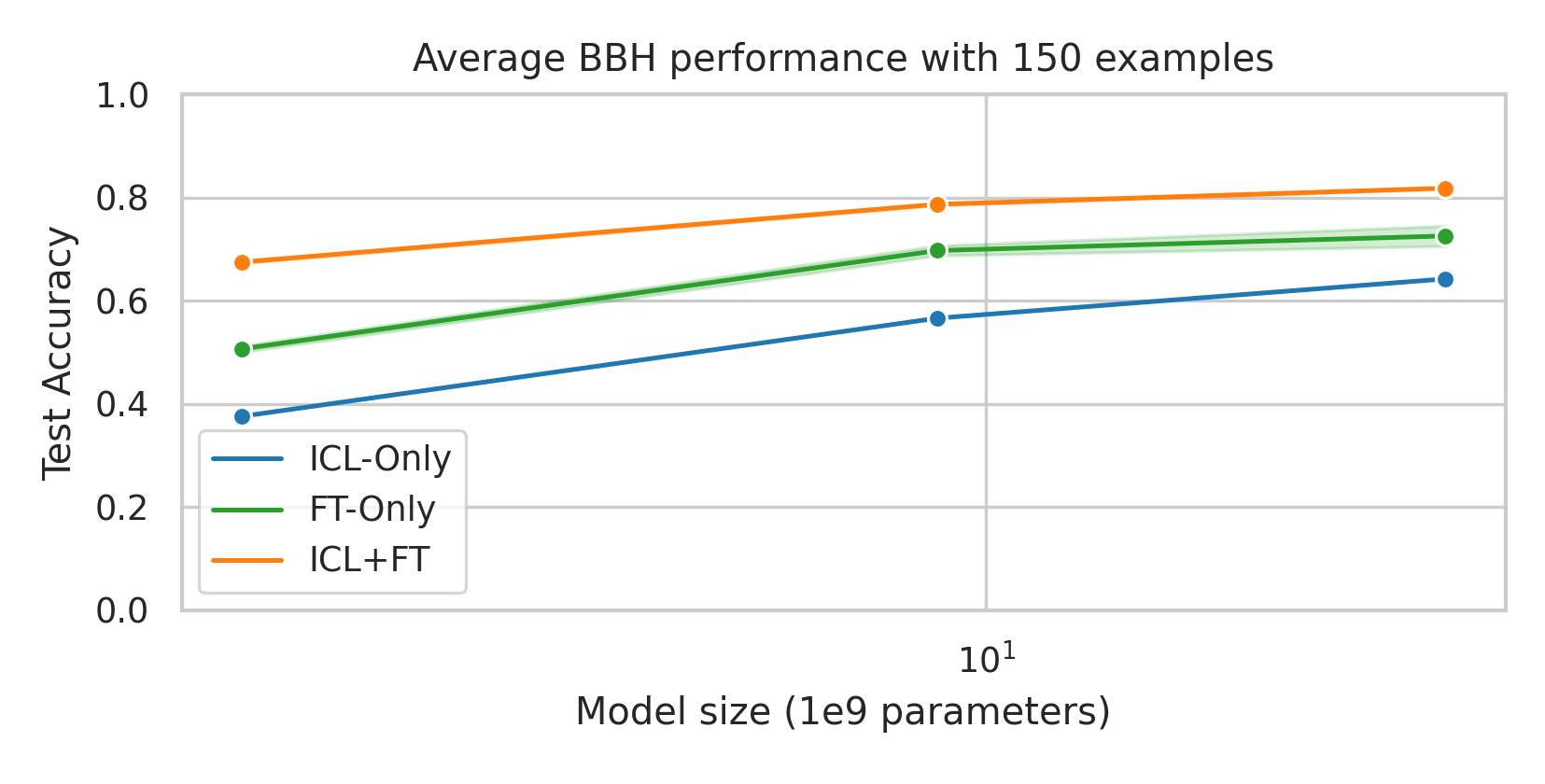
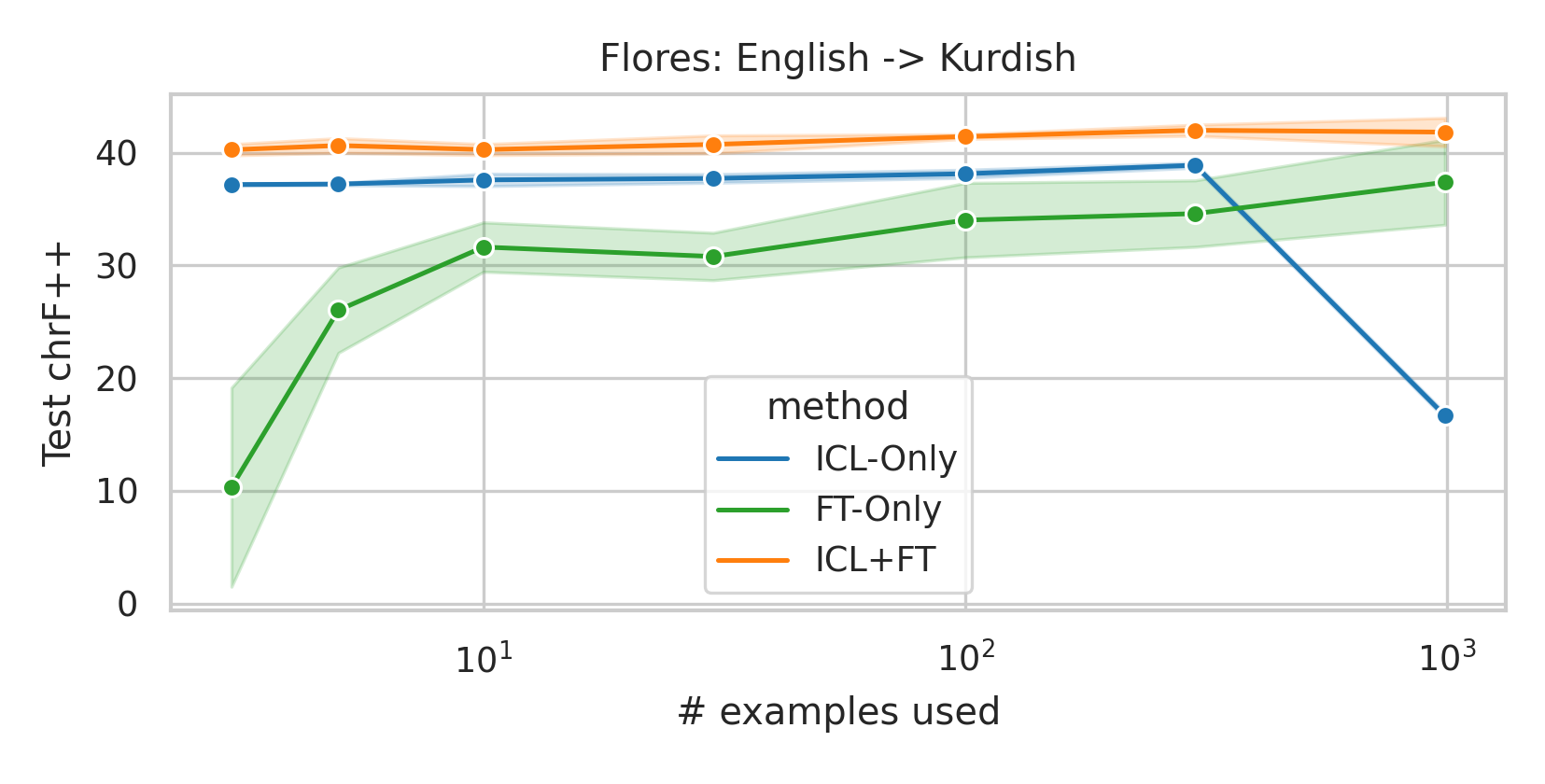
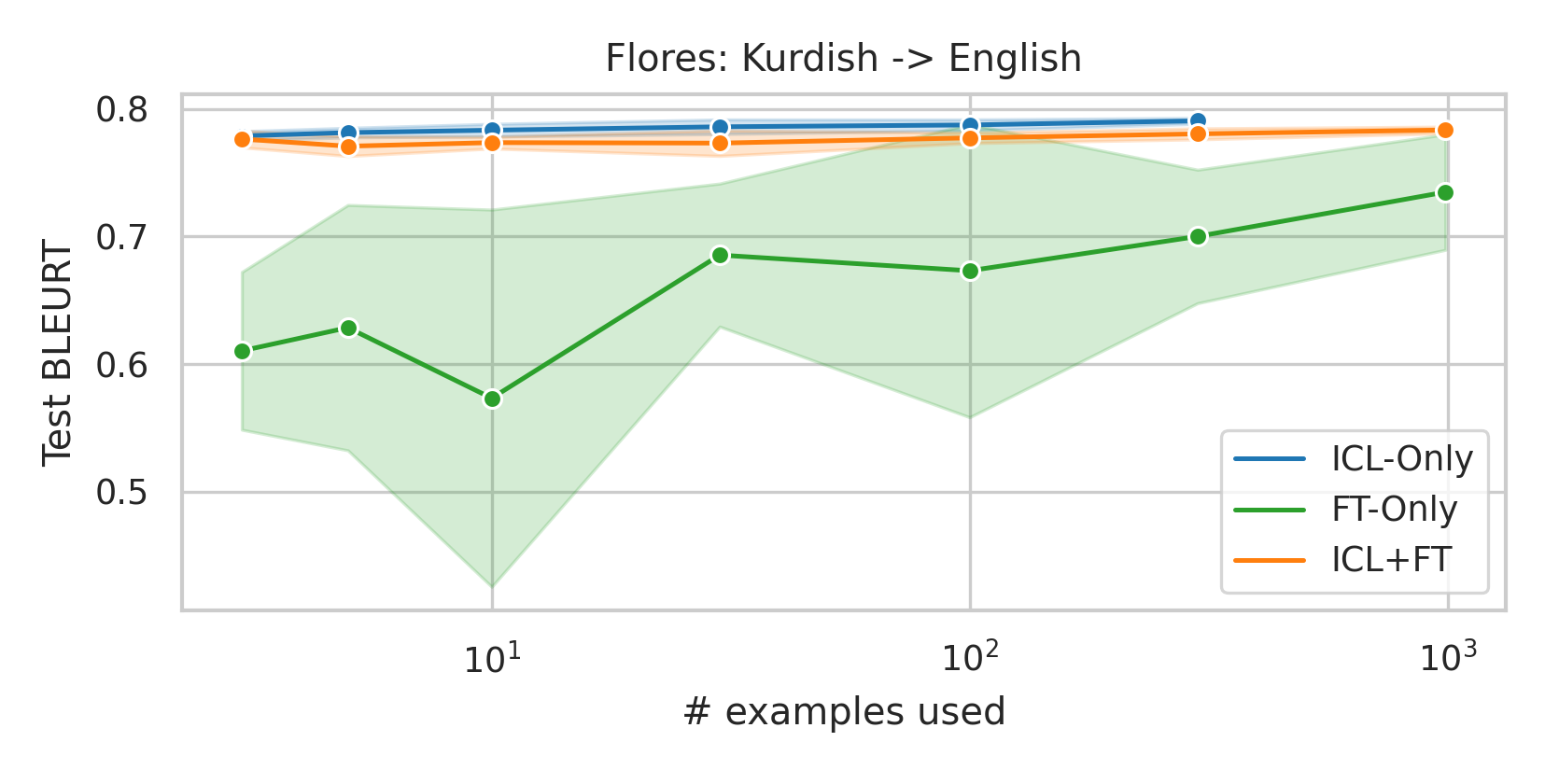
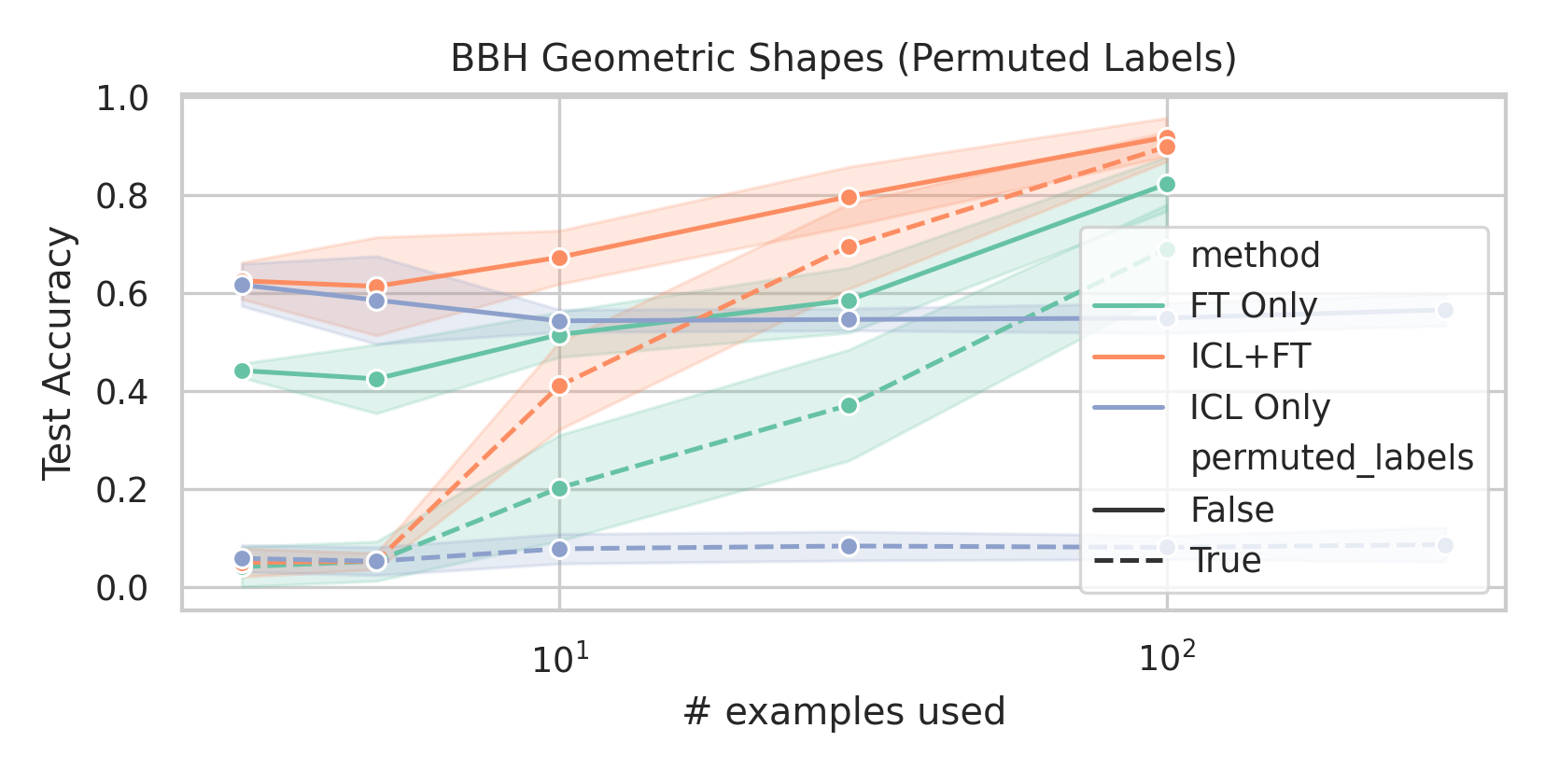
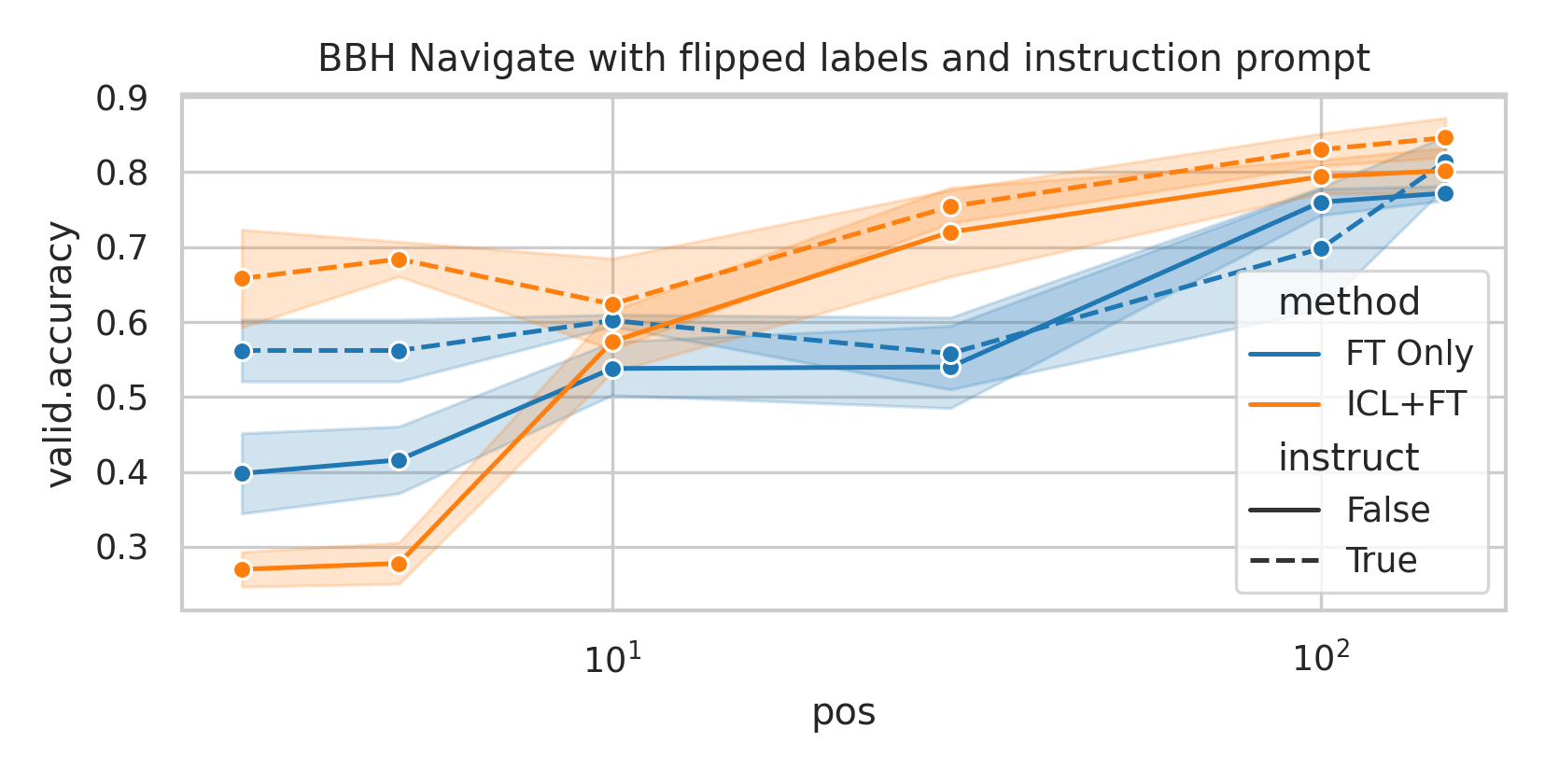
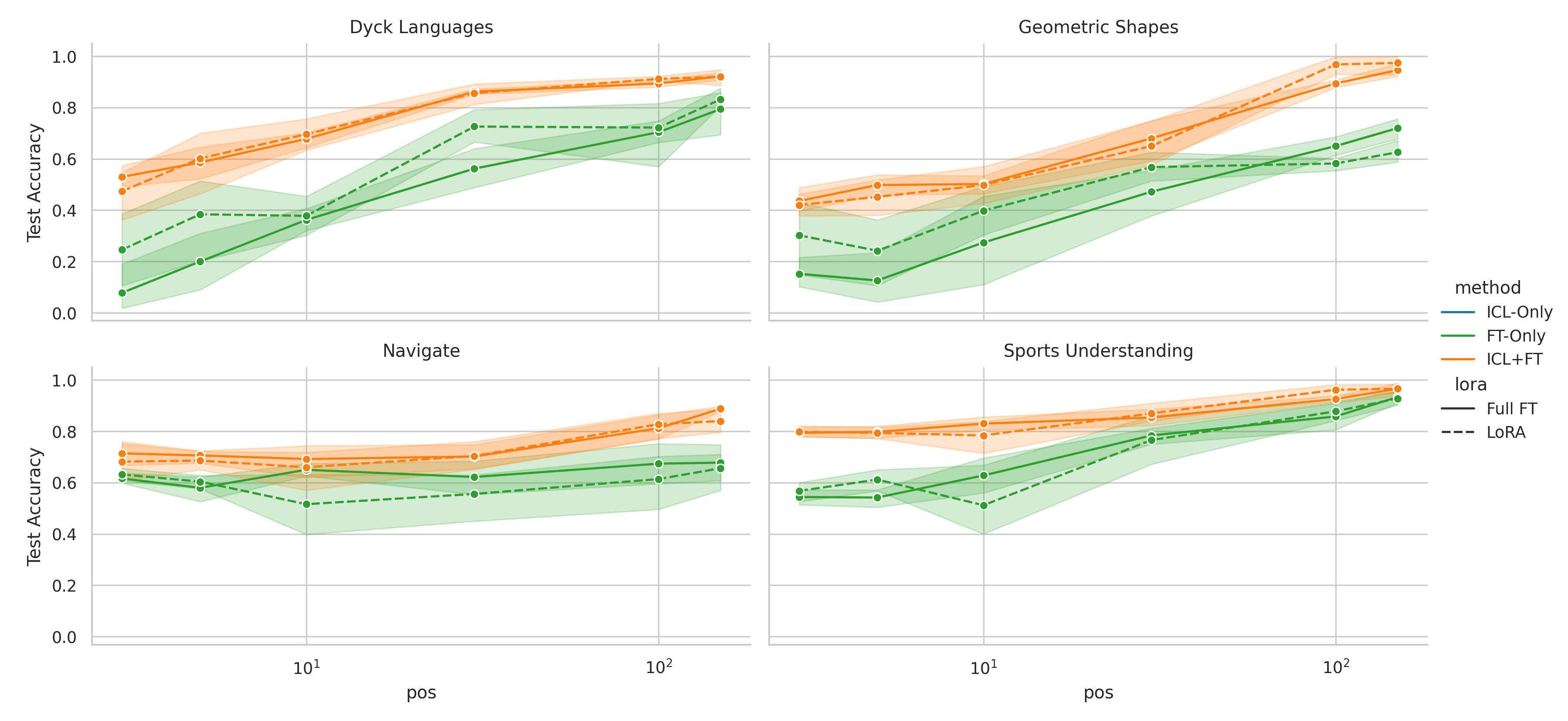
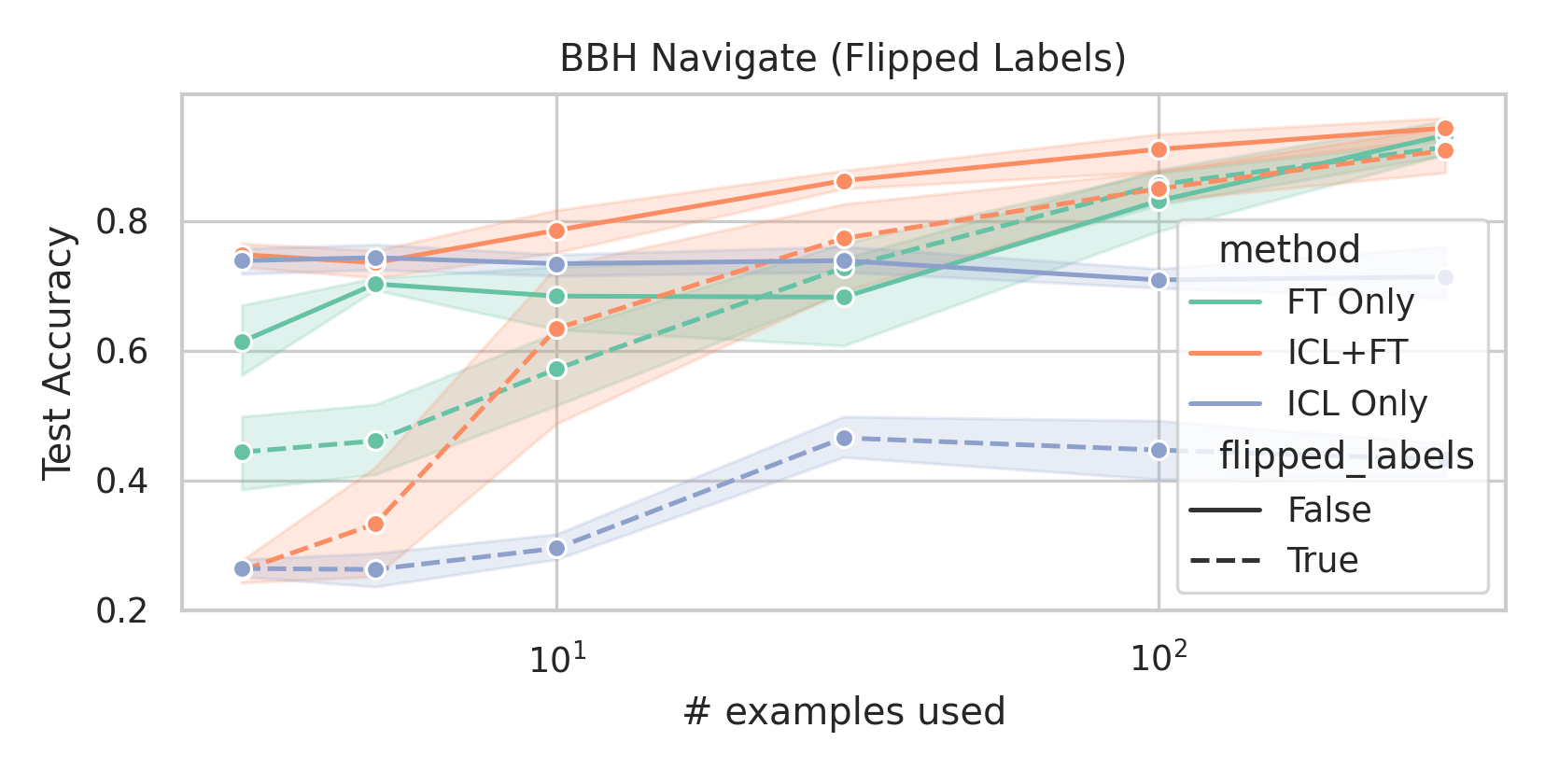
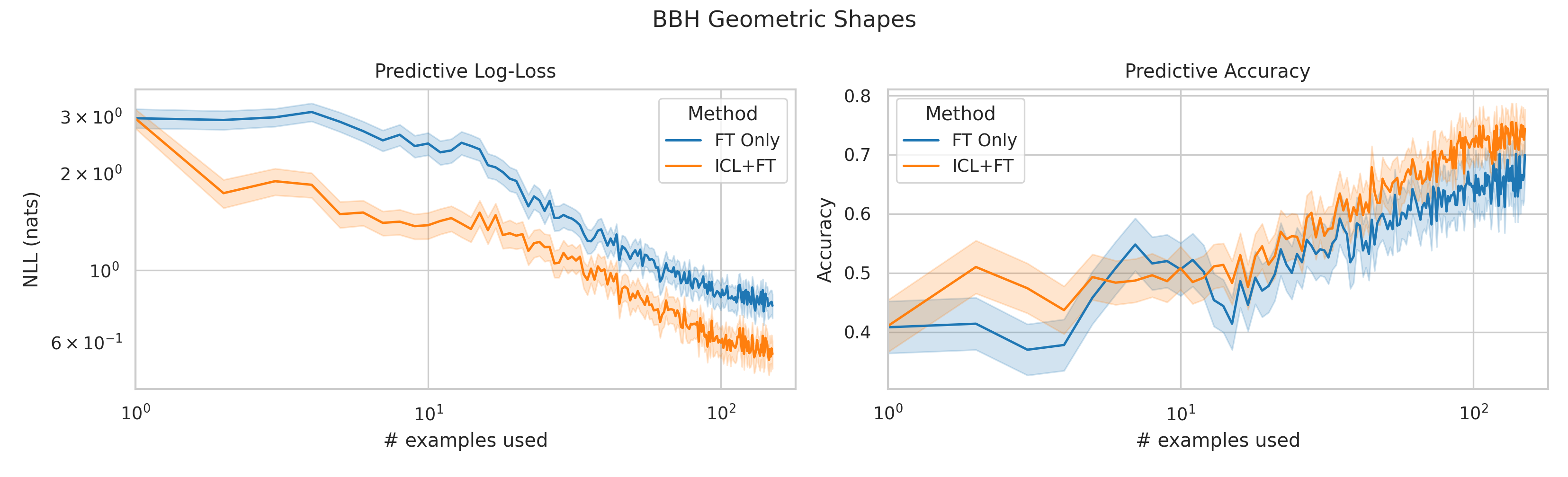
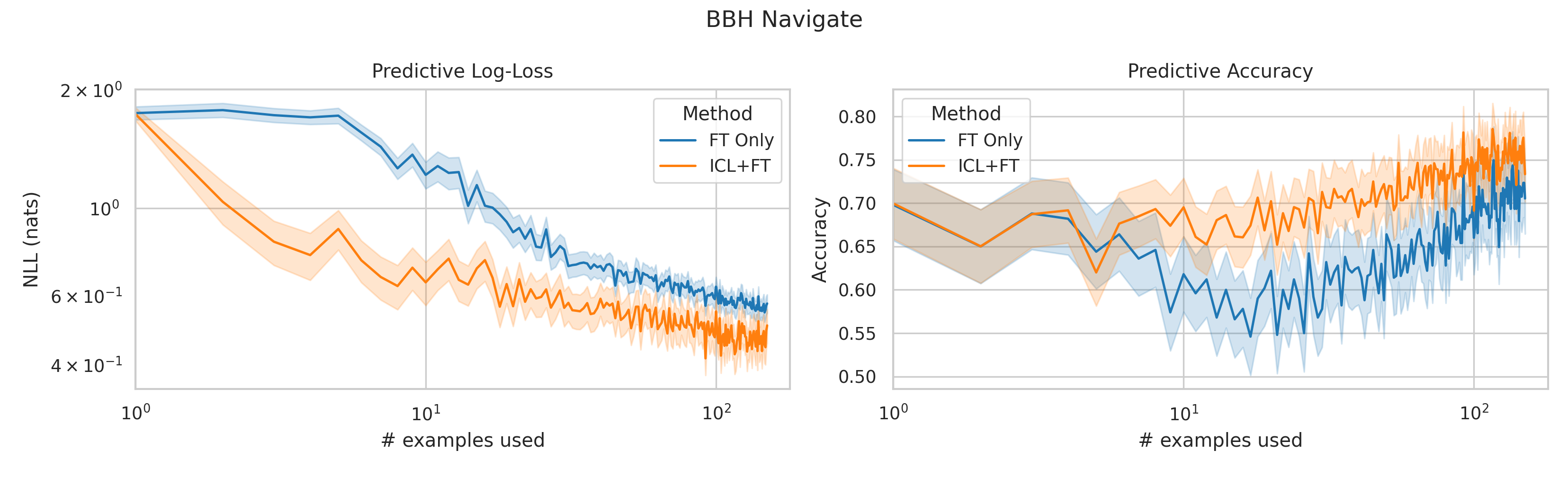
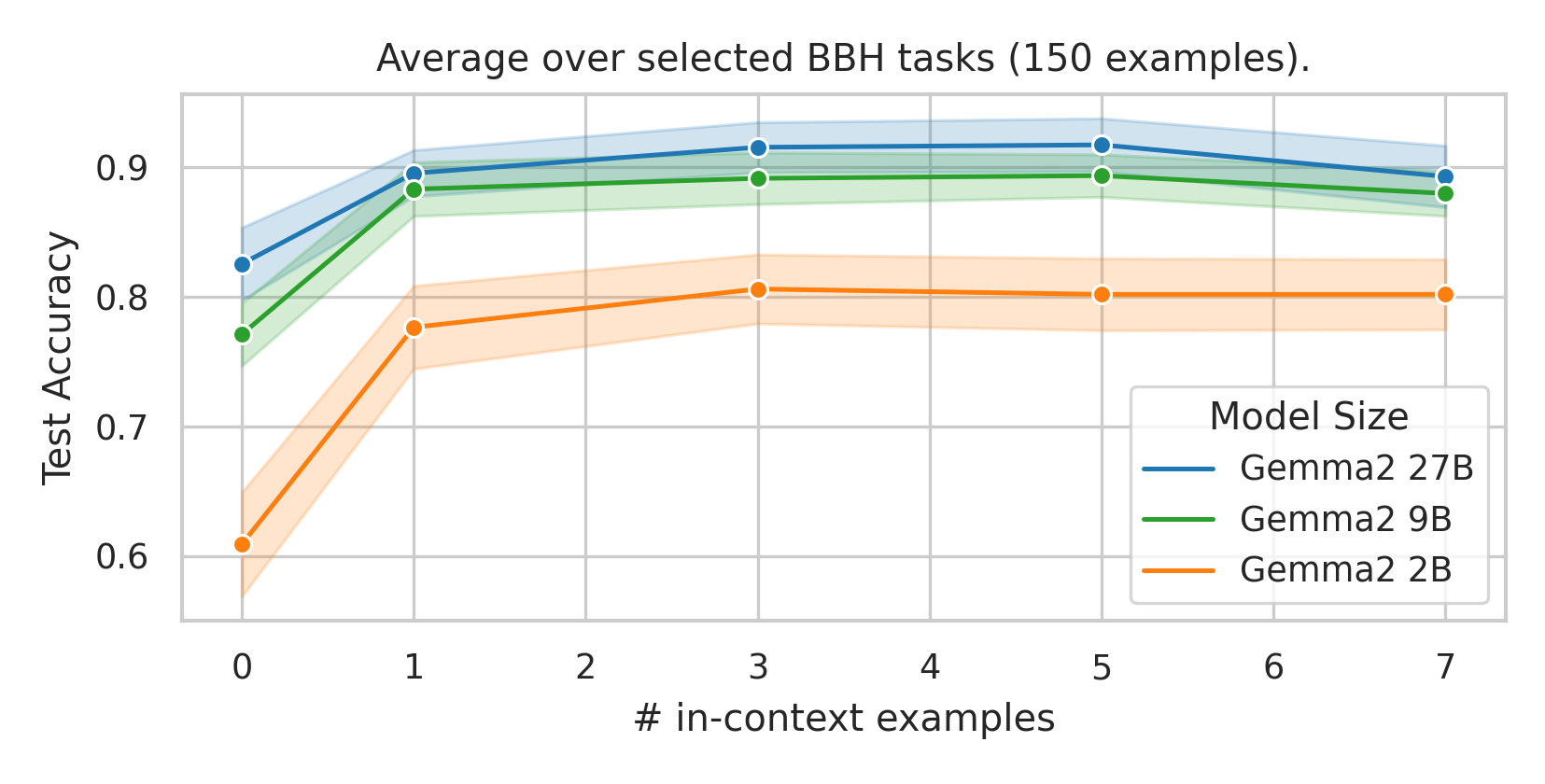
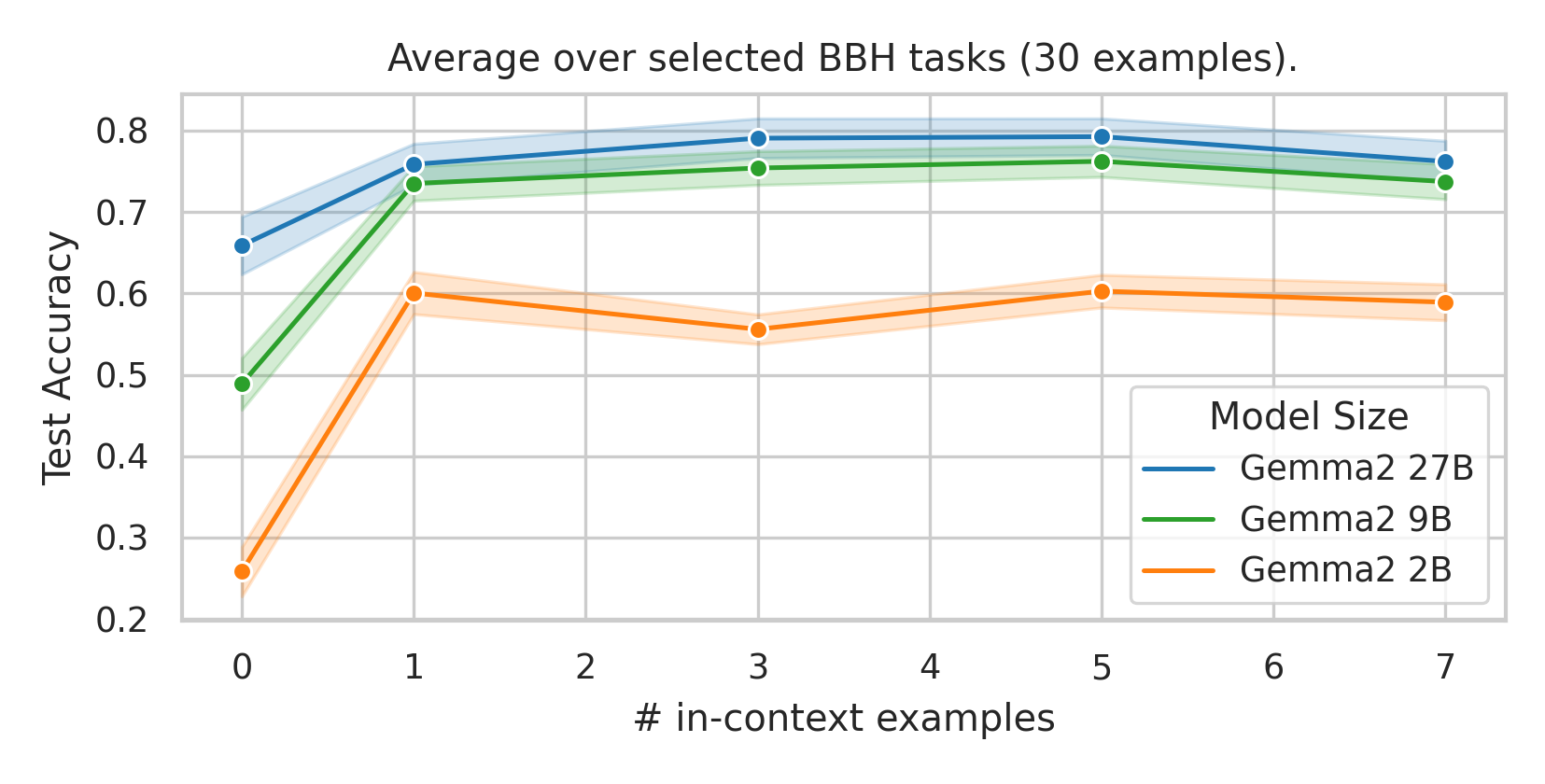
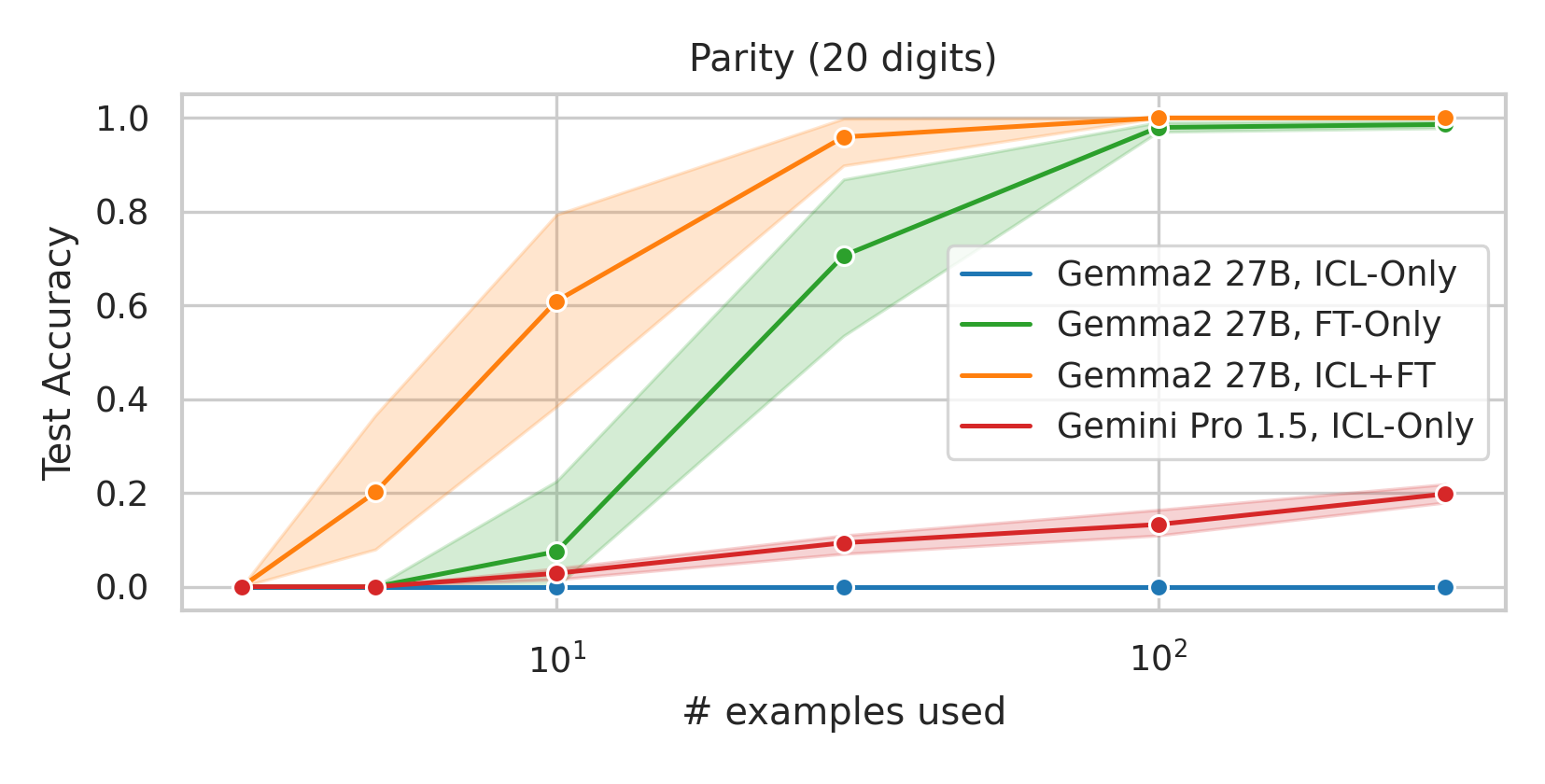
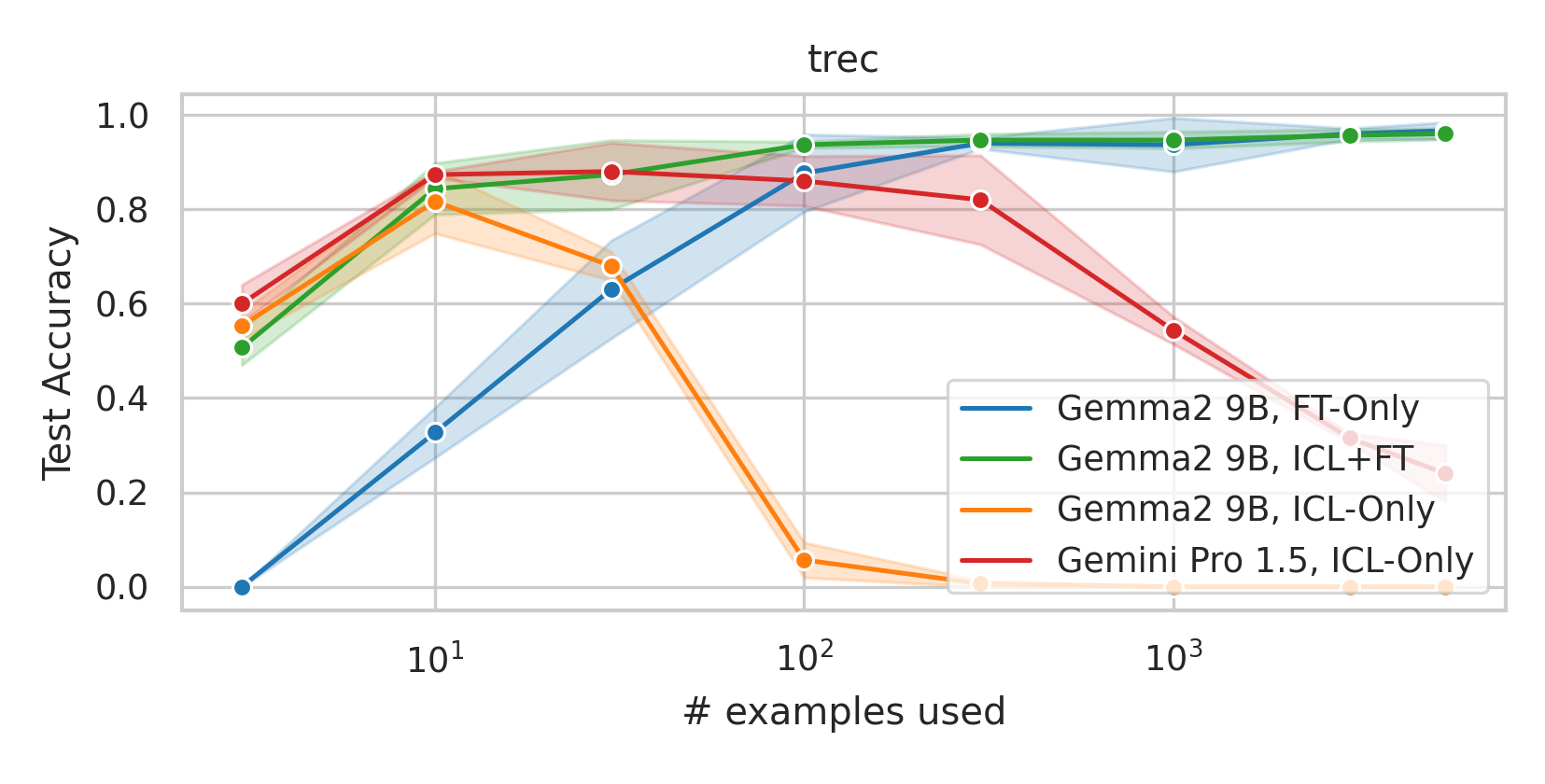
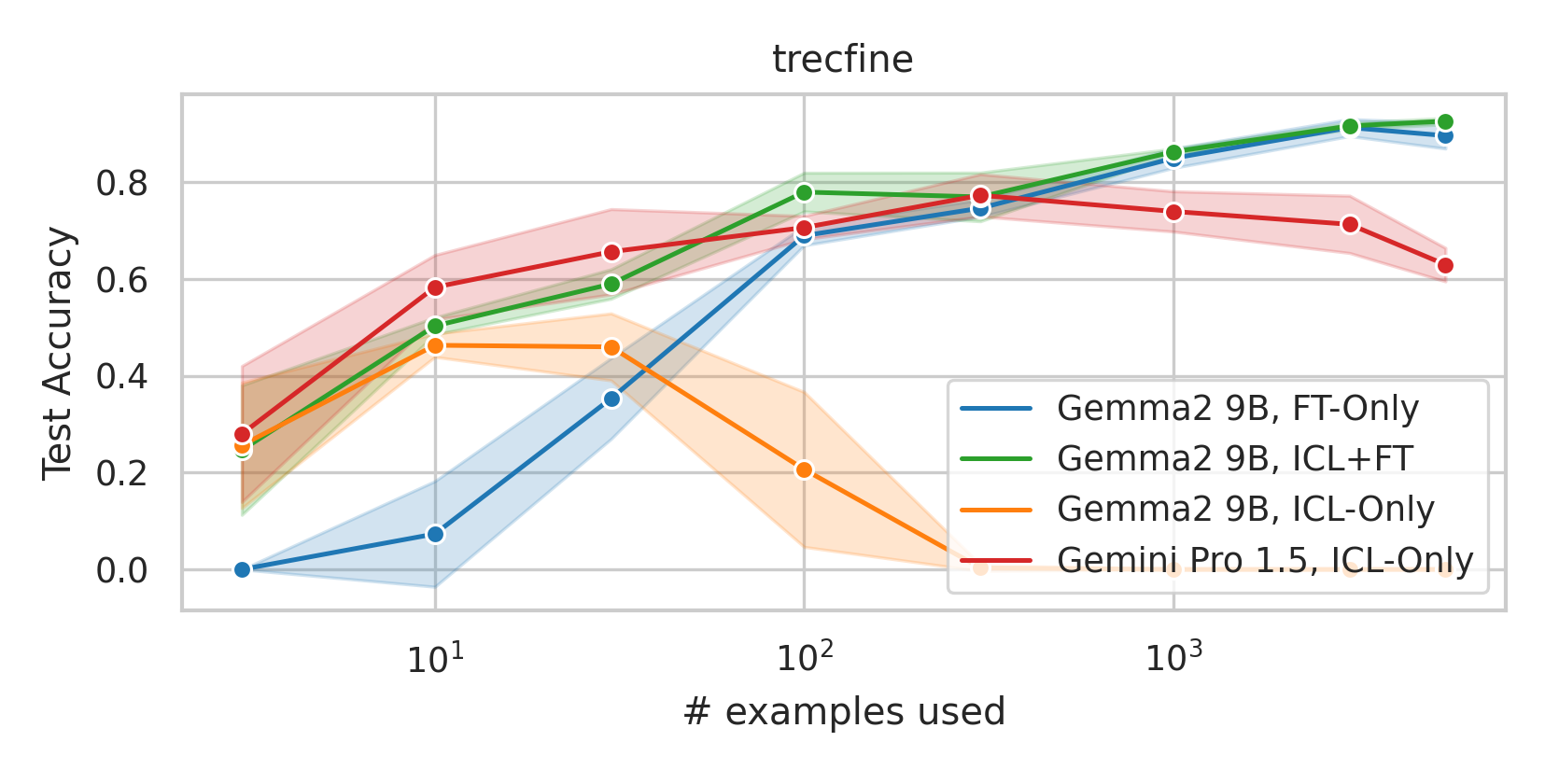
We here investigate a unified approach that bridges these two paradigms. Instead of fine-tuning on
individual examples, we fine-tune a model on k-shot in-context prompts. During inference, the fine-
tuned model is again supplied with k in-context examples from the training set in addition to the test-
point. We conduct an extensive empirical study comparing the sample efficiency of these approaches
across a range of downstream tasks and model sizes. Prior work has explored training on k-shot ICL
examples, however generally from a meta-learning perspective (Min et al., 2022; Chen et al., 2022).
We focus on a different scenario: Given a concrete downstream task, which paradigm offers the
best predictive performance, particularly when task-specific data is limited?
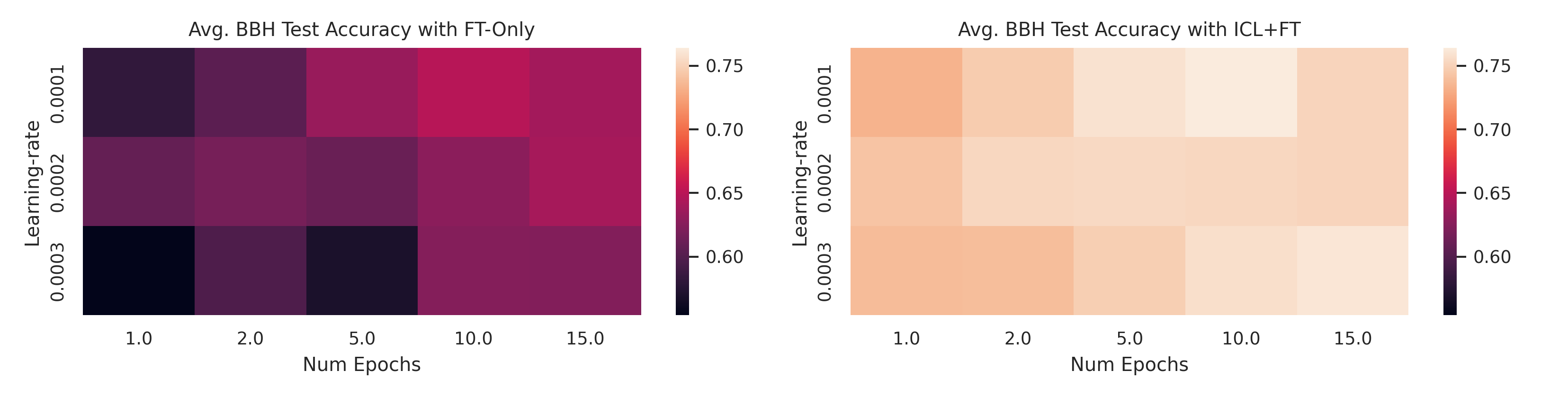
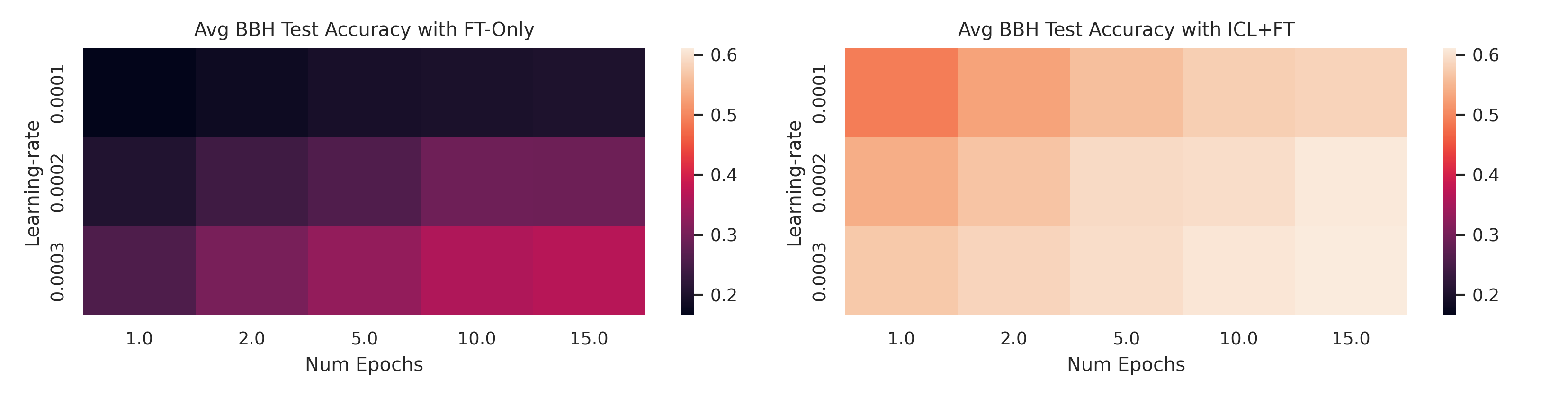
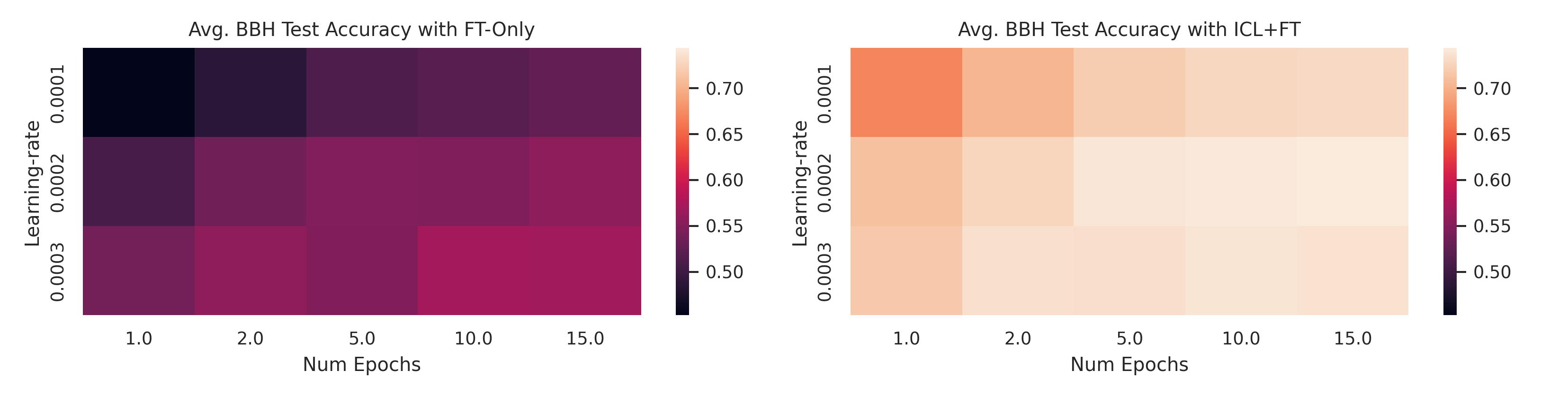
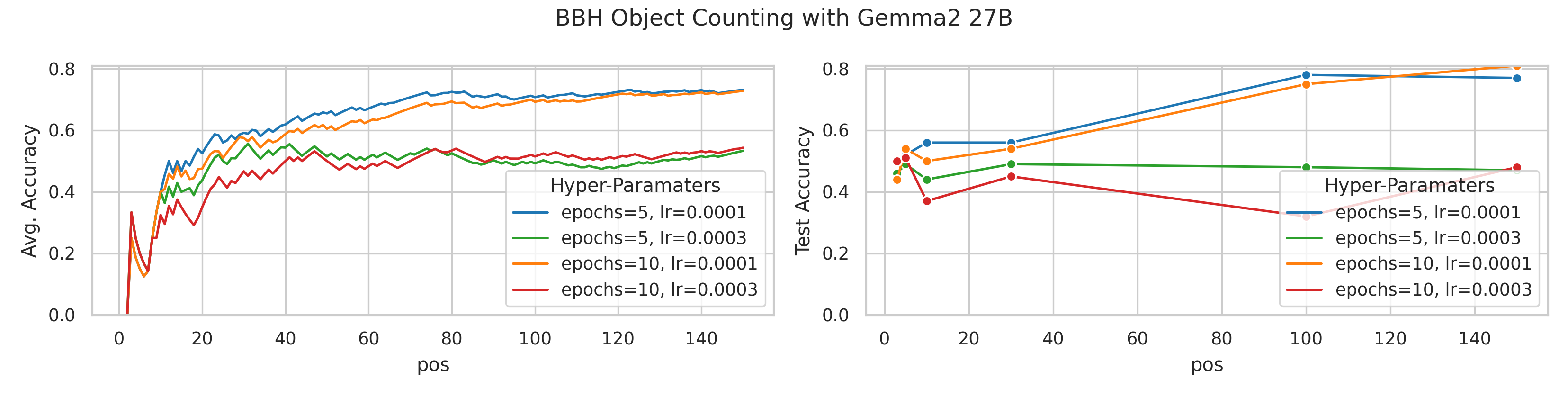
All approaches rely on adequately chosen hyperparameters.
For ICL, these relate to prompt
construction and response parsing , while for FT, they involve factors like learning rate and number
of training epochs. While the literature and established best practices offer reasonable starting
points, optimizing these hyperparameters for a specific task often yields significant performance
gains. However, the challenges of hyperparameter selection in few-shot and small-data regimes
are often overlooked.
Prior work frequently tunes hyperparameters on large held-out sets, a
luxury not available in data-scarce scenarios. To address this, we propose a hyperparameter tuning
protocol that is both data- and computationally efficient, allowing for