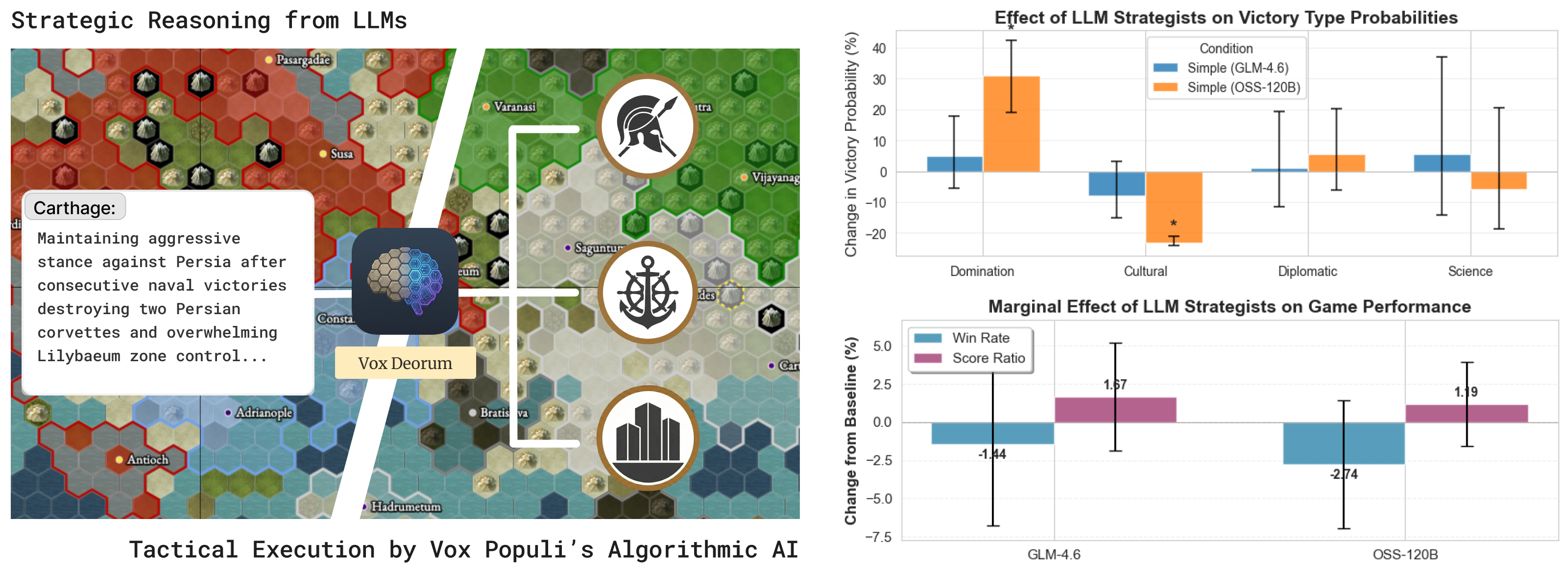
Large Language Models' capacity to reason in natural language makes them uniquely promising for 4X and grand strategy games, enabling more natural human-AI gameplay interactions such as collaboration and negotiation. However, these games present unique challenges due to their complexity and long-horizon nature, while latency and cost factors may hinder LLMs' real-world deployment. Working on a classic 4X strategy game, Sid Meier's Civilization V with the Vox Populi mod, we introduce Vox Deorum, a hybrid LLM+X architecture. Our layered technical design empowers LLMs to handle macro-strategic reasoning, delegating tactical execution to subsystems (e.g., algorithmic AI or reinforcement learning AI in the future). We validate our approach through 2,327 complete games, comparing two open-source LLMs with a simple prompt against Vox Populi's enhanced AI. Results show that LLMs achieve competitive end-to-end gameplay while exhibiting play styles that diverge substantially from algorithmic AI and from each other. Our work establishes a viable architecture for integrating LLMs in commercial 4X games, opening new opportunities for game design and agentic AI research.
4X and grand strategy games are among the most complex environments for human players. Named after their core mechanics (eXploration, eXpansion, eXploitation, and eXtermination), these games challenge players to manage political entities ranging from clans to civilizations across hundreds of turns. Under conditions of imperfect information and multilateral competition, players have to make strategic decisions across multiple aspects each turn: economic development, military strategy, diplomatic relations, and technological advancement. With such depth and emergent complexity, popular game titles such as Sid Meier's Civilization, Europa Universalis, and Stellaris have captivated millions of players.
Yet, AI opponents in those games struggle to match human expectations, often relying on major handicaps (i.e., bonuses only available to AI players) to stay competitive (e.g., [6]). Effective 4X gameplay requires two distinct competencies: high-level strategic reasoning and tactical execution. Algorithmic AI may excel at tactical execution, as evidenced by the Vox Populi project’s improvement on Civilization V’s AI [10]. However, 4X games present a uniquely difficult challenge at the strategic level, with multiagent interactions, multiple victory paths, imperfect information, and general-sum game dynamics. As such, algorithmic AI systems struggle to achieve the flexibility and unpredictability that human opponents naturally provide, creating long-standing challenges for game designers and developers.
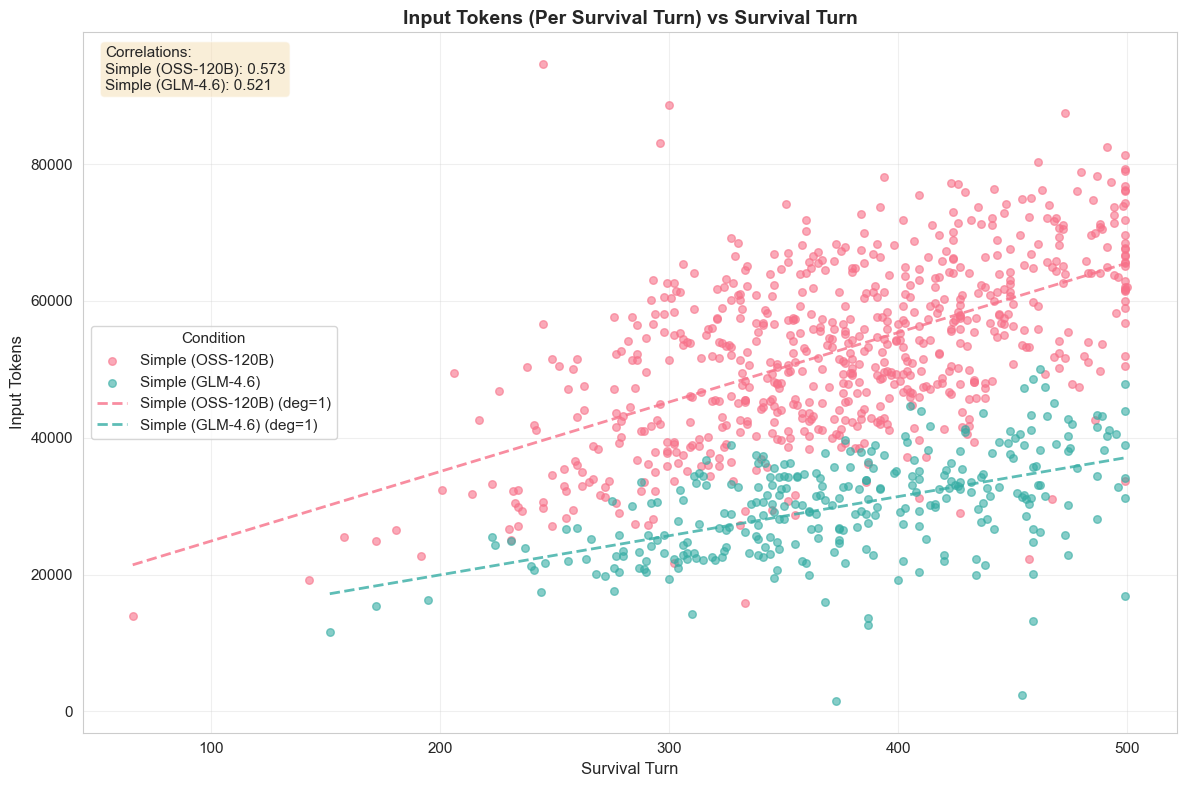
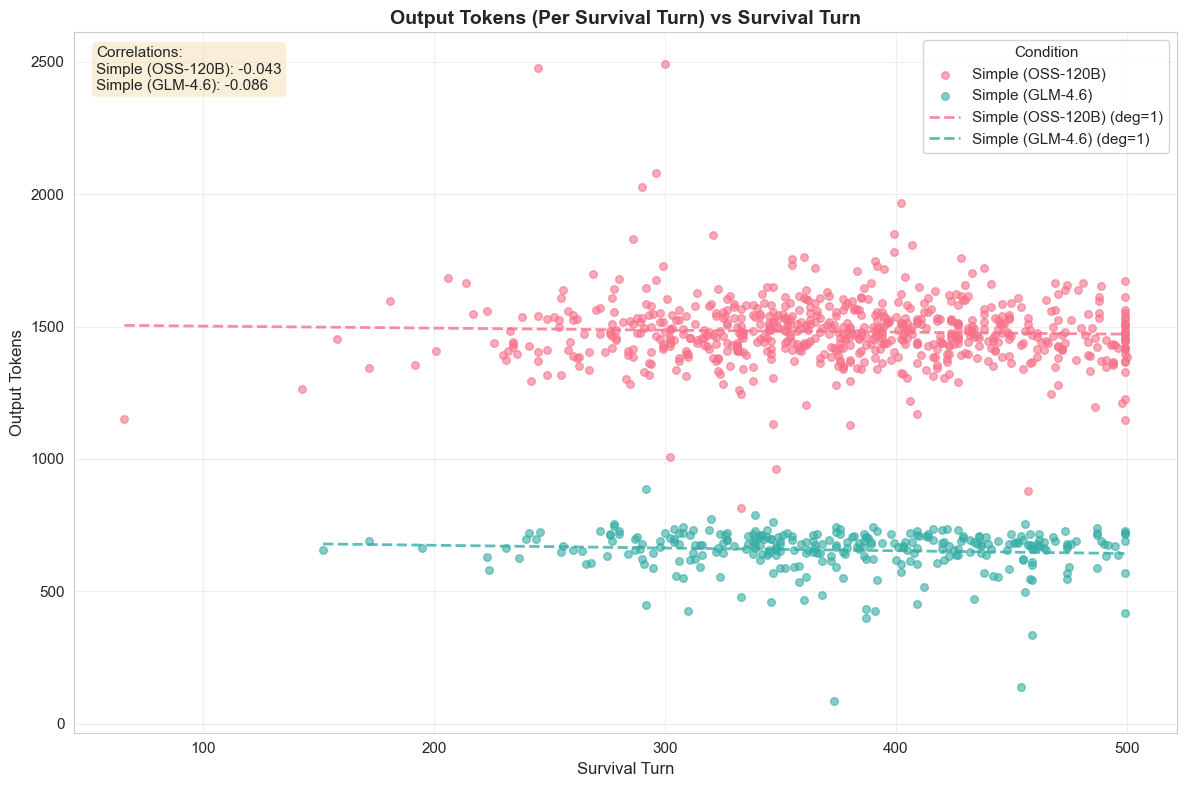
Advanced AI approaches, such as large language models (LLMs) and reinforcement learning (RL), offer promising avenues for addressing these limitations; however, each approach faces distinct challenges when applied in isolation. RL agents have achieved superhuman performance in games like Go [26] and StarCraft II [34]. However, a previous study finds RL models underperforming in 4X games, inclining towards short-term rewards while failing to plan for long-term gains [22]. On the other hand, LLMs bring complementary strengths: they can reason and take instructions in natural languages, articulate multi-step plans, adapt to novel situations, and often provide out-of-the-box usability [12,29]. However, while LLMs can perform reasonably well in mini-game tasks [22,35] and outperform RL agents [22], both approaches fail to survive full games. The volume of tactical decisions required each turn (managing dozens of cities and units) also creates prohibitive costs and latency for real-world deployment.
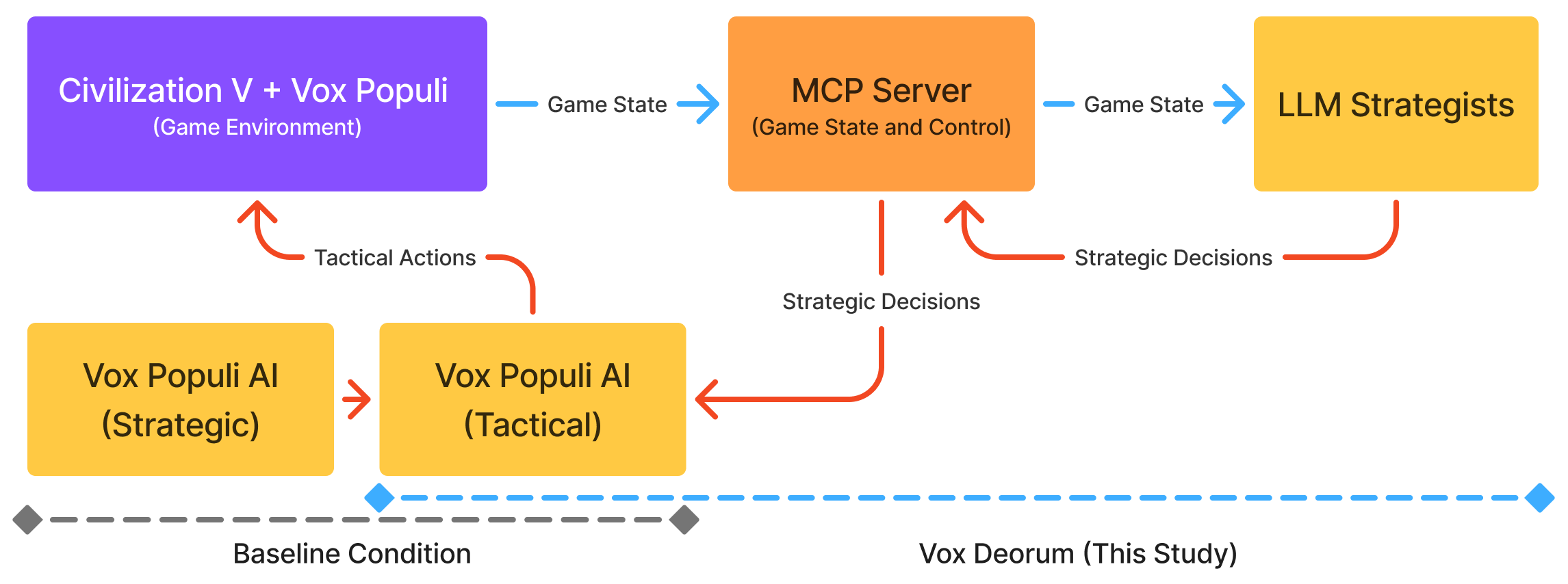
To combine the strengths of LLMs and other AI systems, this paper introduces Vox Deorum, a hybrid LLM+X architecture that delegates tactical execution to specialized subsystems (“X”) while reserving strategic decision-making for LLMs. We validate our architecture through an empirical study on Sid Meier’s Civilization V with the Vox Populi community mod, which has substantially enhanced the game’s built-in AI [10]. We evaluated two open-source models’ out-of-the-box gameplay capability with a simple prompt design, establishing a baseline for further research. Specifically, we asked the following research questions:
• RQ1: Can hybrid LLM+X architectures handle end-to-end long-horizon gameplays in commercial 4X games? • RQ2: How do open-source LLMs perform vs. Vox Populi’s algorithmic AI? • RQ3: How do LLMs play differently compared to each other or Vox Populi’s algorithmic AI?
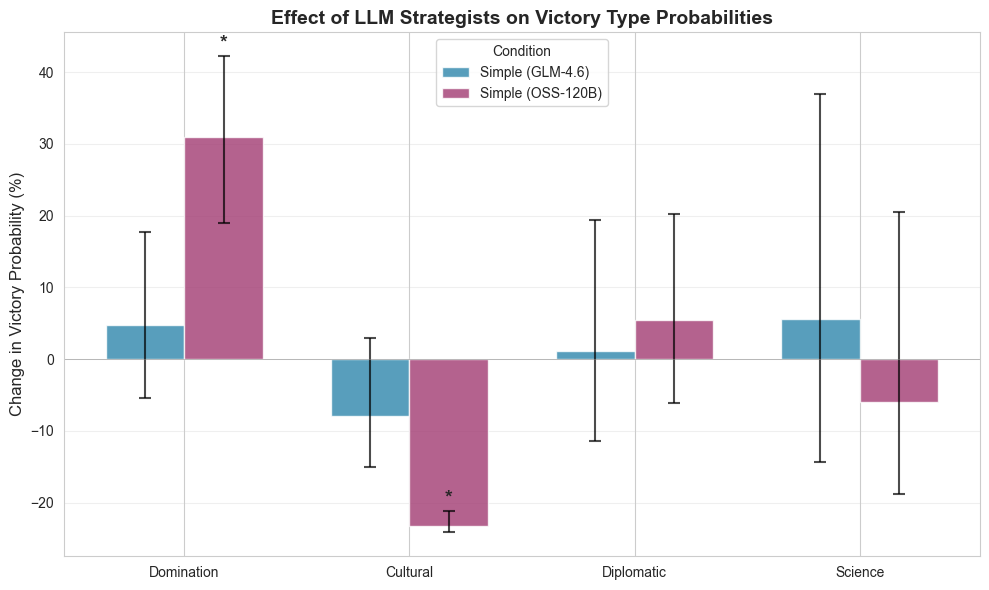
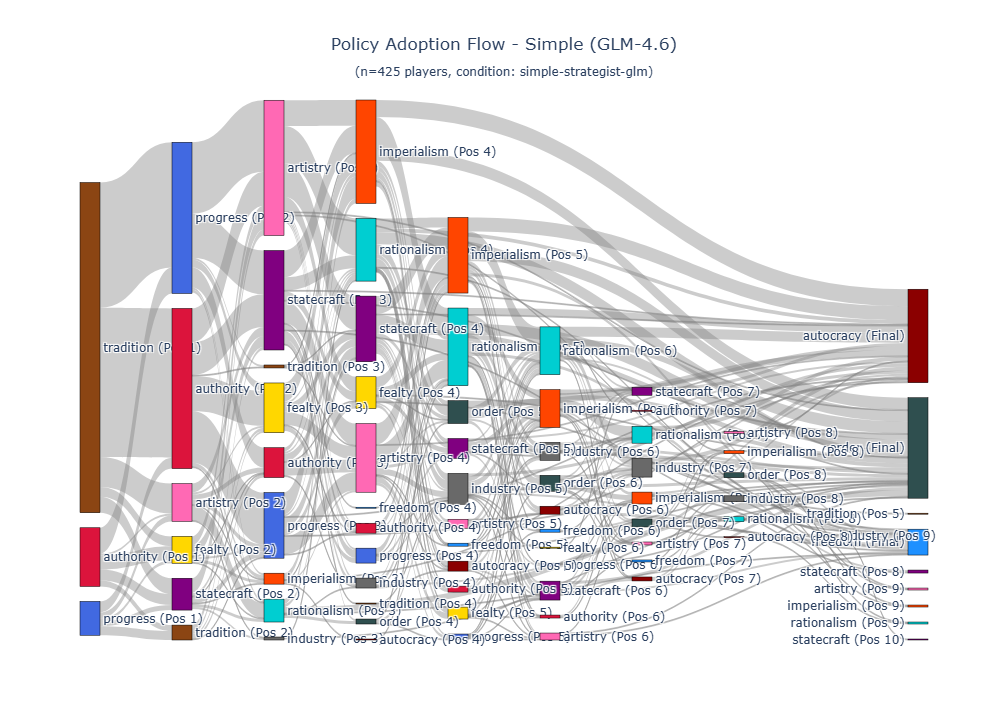
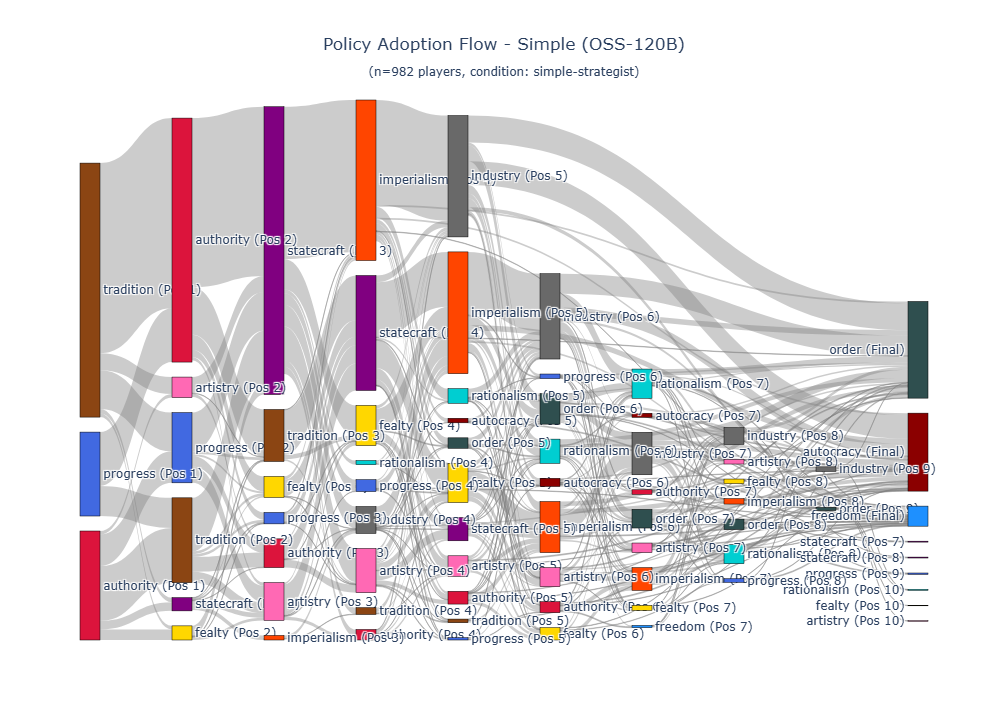
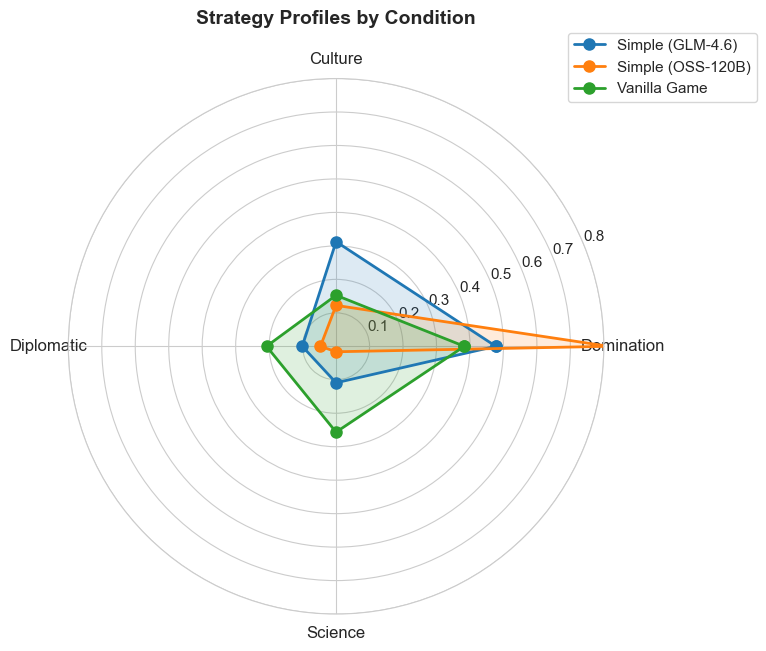
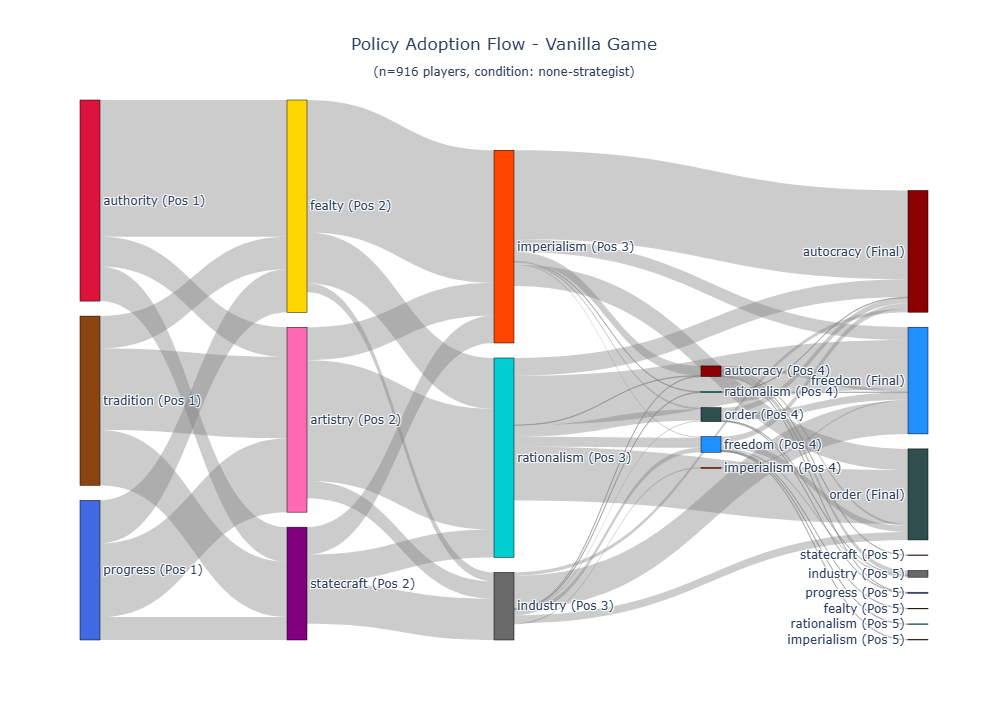
Our findings demonstrate the viability and potential of the proposed LLM+X architecture. Both of the open-source LLMs that were considered (GPT-OSS-120B from OpenAI and GLM-4.6 from z.ai) successfully completed hundreds of full games, with survival rates approaching 100%. Across 2,327 full games, LLMs achieved statistically tied win rates and score ratios against Vox Populi’s algorithmic AI (VPAI) baseline. Both LLMs exhibited distinct play styles compared with VPAI, with different victory type preferences, strategic pivoting behaviors, and policy adoption trajectories. With excellent latency and reasonable cost, this architecture opens a wide range of opportunities for game design, (machine learning) research, and commercial adoption. Our study makes the following contributions:
• We introduce Vox Deorum, a hybrid LLM+X architecture for 4X games, delegating tactical execution to complementary modules for better latency, cost-effectiveness, and gameplay performance.
• We present an open-source implementation of the Vox Deorum architecture for Civilization V with Vox Populi, providing a research platform for game AI and agentic AI researchers. • We conduct the largest empirical study to date of LLM agents in 4X games, comparing end-to-end gameplay across 2,327 complete games between LLMs and the baseline VPAI.
Recent research on advanced game AI often focuses on reinforcement learning (RL)-based or large language models (LLM)-based agents, two prominent approaches that offer complementary strengths in tactical execution and high-level strategic reaso
This content is AI-processed based on open access ArXiv data.