Text2SQL, the task of generating SQL queries from natural language text, is a critical challenge in data engineering. Recently, Large Language Models (LLMs) have demonstrated superior performance for this task due to their advanced comprehension and generation capabilities. However, privacy and cost considerations prevent companies from using Text2SQL solutions based on external LLMs offered as a service. Rather, small LLMs (SLMs) that are openly available and can hosted in-house are adopted. These SLMs, in turn, lack the generalization capabilities of larger LLMs, which impairs their effectiveness for complex tasks such as Text2SQL. To address these limitations, we propose MATS, a novel Text2SQL framework designed specifically for SLMs. MATS uses a multi-agent mechanism that assigns specialized roles to auxiliary agents, reducing individual workloads and fostering interaction. A training scheme based on reinforcement learning aligns these agents using feedback obtained during execution, thereby maintaining competitive performance despite a limited LLM size. Evaluation results using on benchmark datasets show that MATS, deployed on a single- GPU server, yields accuracy that are on-par with large-scale LLMs when using significantly fewer parameters. Our source code and data are available at https://github.com/thanhdath/mats-sql.
Text2SQL, the task of translating natural language into SQL queries, is a long-standing research challenge [49][50][51]54]. While an increasing complexity of user queries and database schemas contribute to the task's difficulty [39], recent solutions based on Large Language Models (LLMs) achieved notable results for Text2SQL [6,23,33,43]. Text2SQL approaches promise to enable non-experts to query databases using a natural language interface [30,45]. Most existing solutions for this task, however, rely on external LLMs offered as a service [28,41], primarily variants of OpenAI GPT, to generate SQL queries. These approaches combine user queries and schema representations with instructional text to generate SQL queries [22,40]. However, the use of external LLM services comes with drawbacks. Privacy concerns arise when sensitive data, such as database schemas or query logs, are shared with third-party platforms, potentially violating confidentiality or exposing data to security risks. Also, the recurring costs of such services can become a substantial financial burden, especially for small organizations.
To be independent of external LLM services, recent approaches for Text2SQL fine-tune open-source LLMs with instructional data [5,14,38]. Fine-tuning improves the task-specific model performance, but requires significant computational resources and technical expertise. In addition, even with models as large as 15 billion parameters, the accuracy obtained using open-source LLMs is considerably lower than the one achieved with external LLM services [16,19]. Striving for a cost-effective solution, one may adopt small Large Language Models (SLMs) with generally smaller numbers of parameters (typically 100M-5B) [25]. Such models are optimized to run on a single-node server that features a single GPU. While the use of SLMs enlarges the efficiency and, hence, applicability of a Text2SQL solution, one faces challenges in terms of model effectiveness. SLMs often struggle with tasks that require deep reasoning or understanding of complex contexts, such as required for Text2SQL [25]. Their limited capacity makes it challenging to maintain relationships between tables or fields, especially with large schemas, and they frequently miss nuances in natural language inputs, leading to syntax or semantic errors in SQL generation.
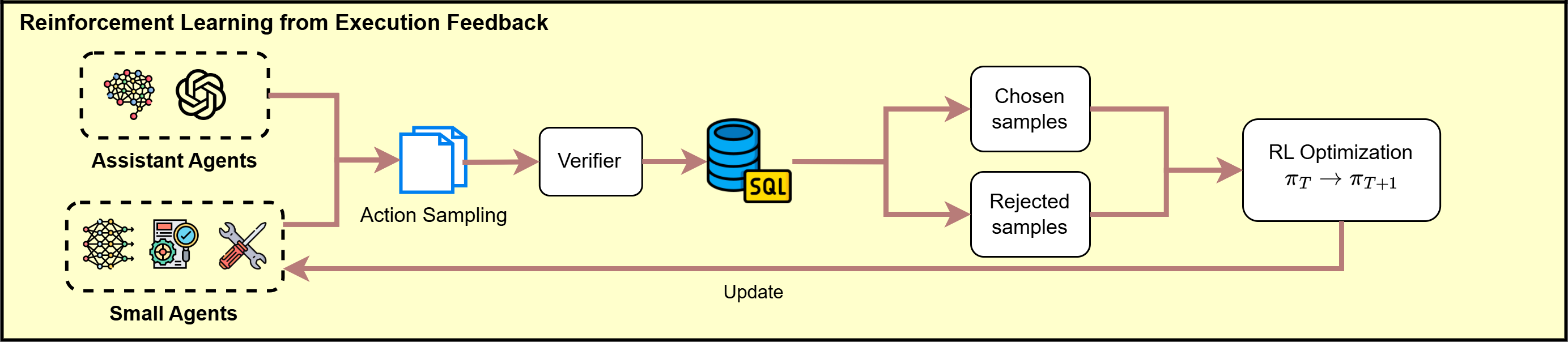
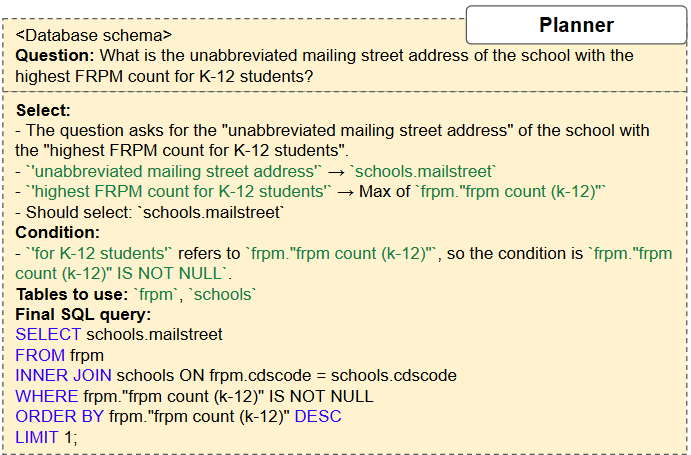
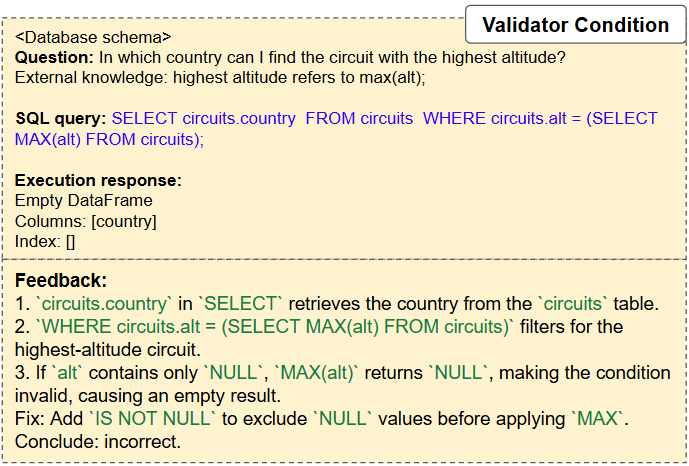
In this paper, we follow the idea of using SLMs for Text2SQL and propose the Multi-Agent Text2SQL (MATS) framework to operationalize it. MATS employs a multi-agent mechanism [11,13,35] to decompose the Text2SQL task into sub-tasks, each handled by a specialized agent: a schema investigator filters irrelevant schema elements and retrieves relevant column values; a query planner generates multiple SQL queries step-by-step; a validator evaluates SQL outputs using database responses; a fix agent refines SQL based on validator feedback; and a selection agent, at the end of the pipeline, selects the best SQL query from the final candidates. To enhance the collaboration between the agents, we design a collaborative training scheme, coined Reinforcement Learning with Execution Feedback (RLEF). Unlike traditional Reinforcement Learning from Human Feedback [29], RLEF generates multiple responses using automated database feedback, avoiding the need for costly human-labeled data.
The divide-and-conquer strategy realized in MATS is beneficial in terms of efficiency and effectiveness. Due to the specialization of agents and their focus on a single sub-task, the generalization capabilities of SLMs, which can be managed efficiently, are sufficient to yield high accuracy. At the same time, the integration of the agents using reinforcement learning enables our framework to effectively handle complex user queries and large-scale datasets. Furthermore, our framework facilitates the adaptation of opensource SLMs, thereby supporting wider applicability on resourceconstrained devices and under restricted budgets. We summarize the contributions of our paper as follows:
• We propose a novel multi-agent framework in which specialized agents rely on SLMs to collaboratively solve Text2SQL tasks. The framework defines sub-tasks for element filtering, query planing, validation of query results, refinement of queries, and query selection. • We introduce Reinforcement Learning with Execution Feedback (RLEF) as a mechanism to enable SLMs agents to collaborate during training, significantly improving their performance in Text2SQL tasks. It relies on recent advancements for preference optimization [12] and instantiates them based on a sampling scheme for appropriate responses.
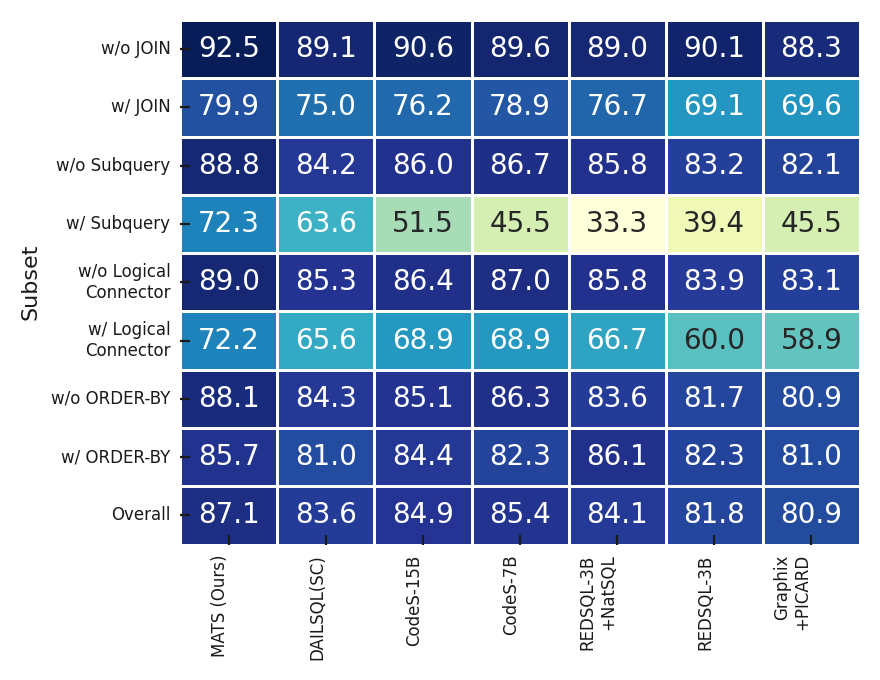
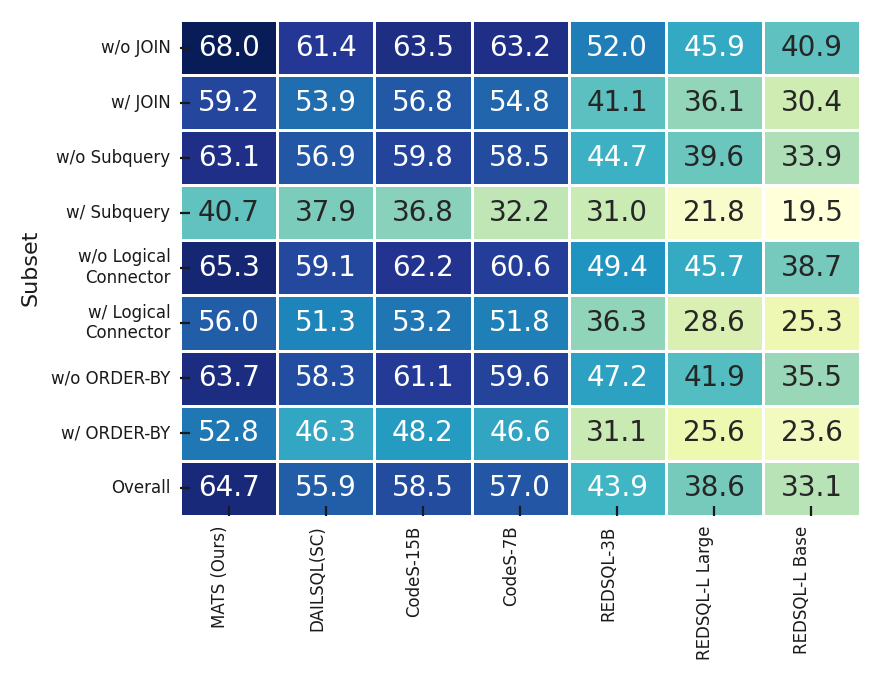
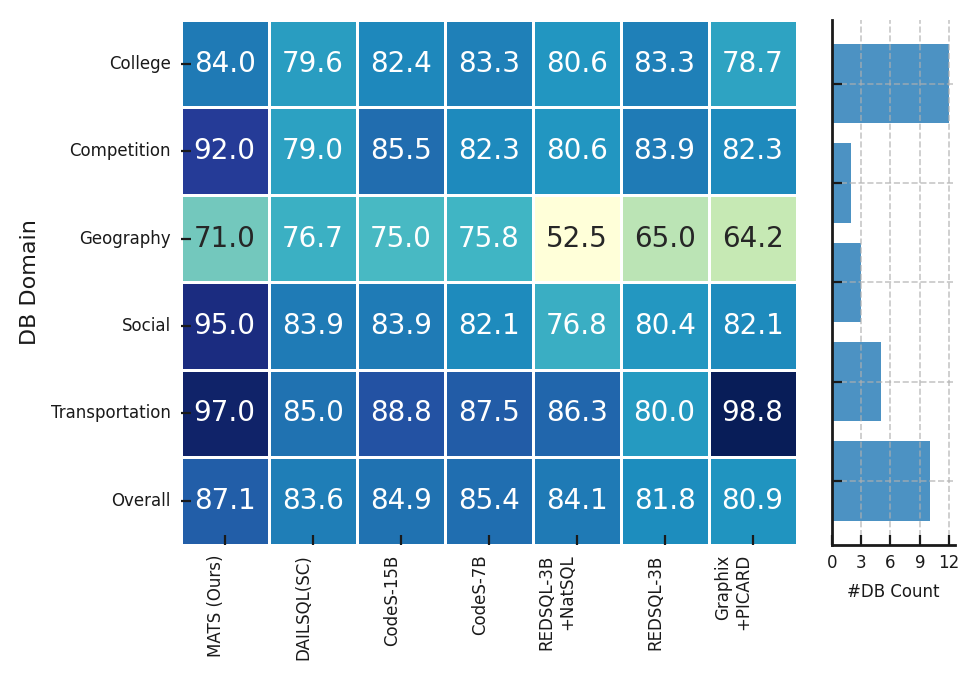
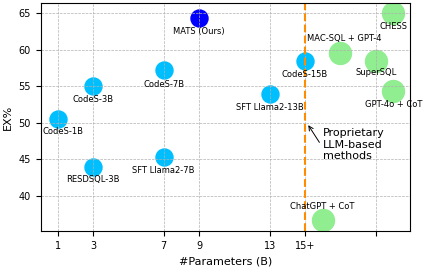
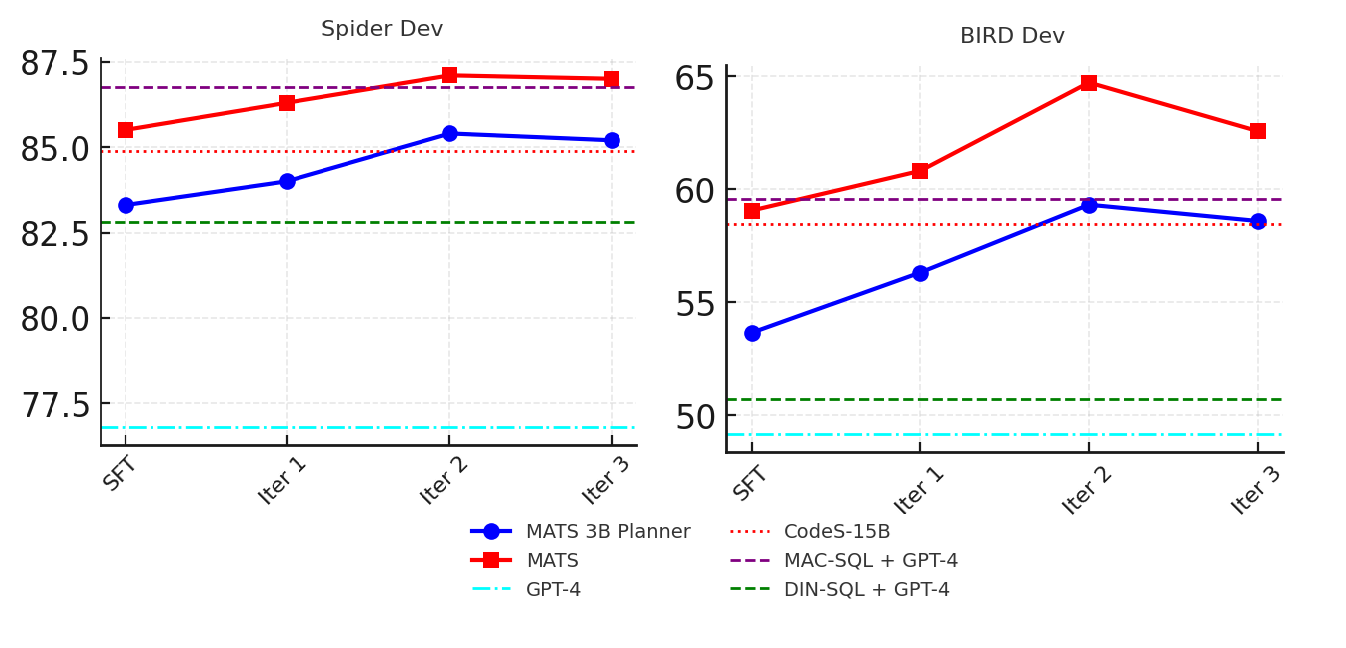
SLMs agents by extending the Spider and BIRD datasets through manual labeling, few-shot prompting, and finetuning, ensuring high-quality examples for robust learning. • We evaluate MATS in comprehensive experiments and observe that it achieves results that are on-par with large-scale LLMs, such as GPT-4o + CoT [20] and CHESS [44], while relying on significantly
This content is AI-processed based on open access ArXiv data.