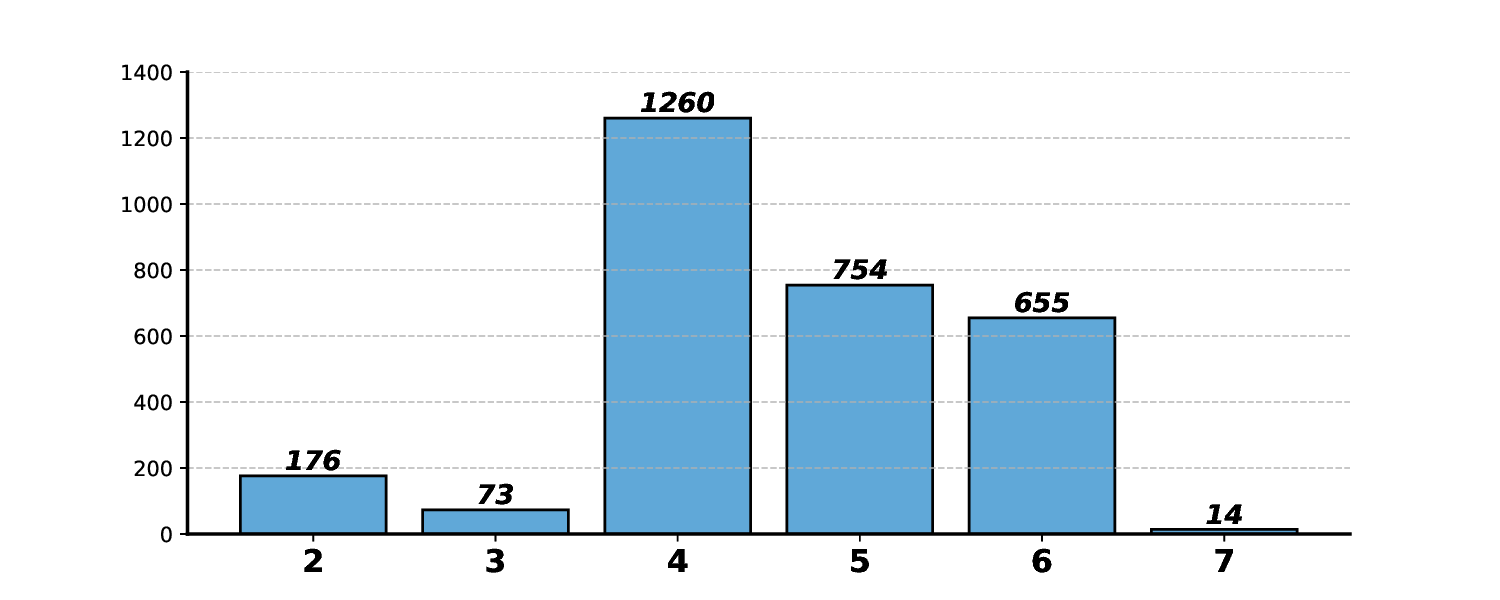
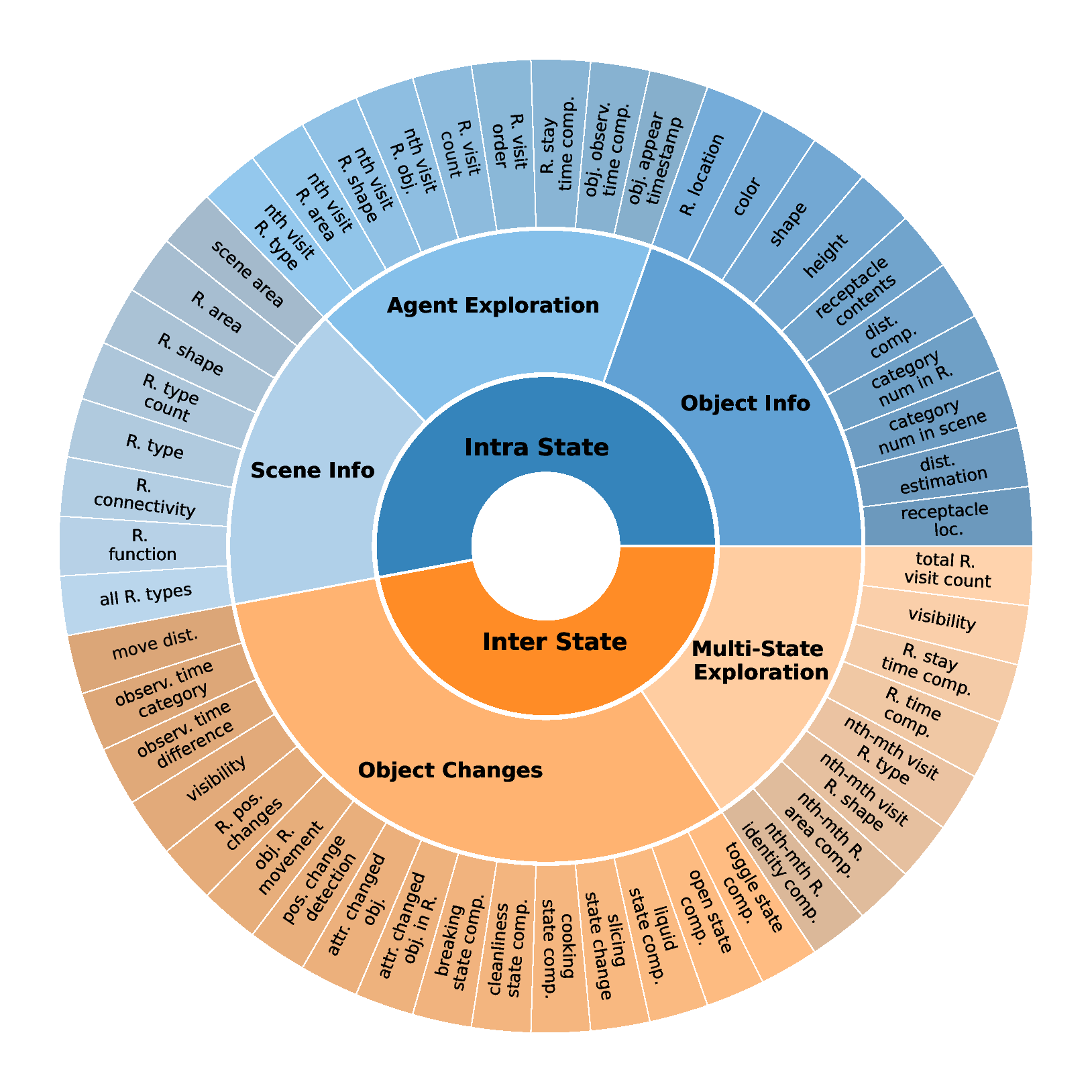
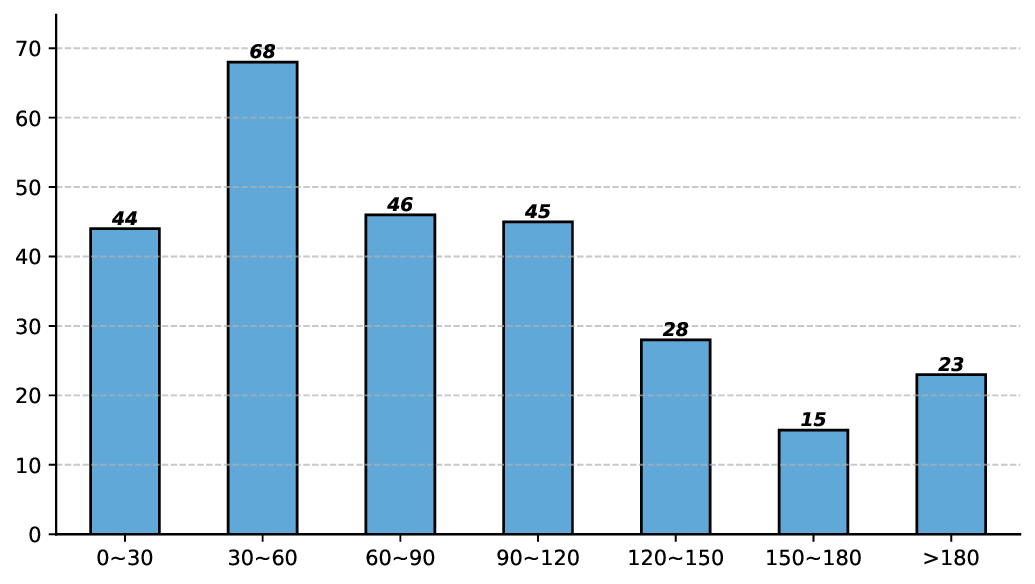Modern Large Multimodal Models (LMMs) have demonstrated extraordinary ability in static image and single-state spatial-temporal understanding. However, their capacity to comprehend the dynamic changes of objects within a shared spatial context between two distinct video observations, remains largely unexplored. This ability to reason about transformations within a consistent environment is particularly crucial for advancements in the field of spatial intelligence. In this paper, we introduce $M^3-Verse$, a Multi-Modal, Multi-State, Multi-Dimensional benchmark, to formally evaluate this capability. It is built upon paired videos that provide multi-perspective observations of an indoor scene before and after a state change. The benchmark contains a total of 270 scenes and 2,932 questions, which are categorized into over 50 subtasks that probe 4 core capabilities. We evaluate 16 state-of-the-art LMMs and observe their limitations in tracking state transitions. To address these challenges, we further propose a simple yet effective baseline that achieves significant performance improvements in multi-state perception. $M^3-Verse$ thus provides a challenging new testbed to catalyze the development of next-generation models with a more holistic understanding of our dynamic visual world. You can get the construction pipeline from https://github.com/Wal-K-aWay/M3-Verse_pipeline and full benchmark data from https://www.modelscope.cn/datasets/WalKaWay/M3-Verse.
Biological intelligent agents, such as animals and humans, all possess a vital ability preserved through natural selection: to compare and perceive changes in the environment and learn from them [4]. Wild animals identify the presence of predators or prey by comparing changes in their habitat, such as new tracks, disturbed vegetation, or broken branches, allowing them to make rational decisions that increase their probability of survival. Similarly, humans acquire skills through the same comparative process. For example, an archer improves by comparing the results of consecutive shots, analyzing differences in distance and direction, and refining their technique based on these comparisons to reduce errors. This process highlights that a key feature of biological intelligent learning is the act of minimizing the 'delta' between ever-changing environment states.
This provides a key insight for research in intelligent agents: we can not provide intelligent agents with an infinite supply of high-quality training data, and the performance ceiling of models based on human-annotated data will always be limited by its quality. A truly advanced cognitive agent should mirror biological intelligence, constantly improving its abilities by perceiving and comparing changes in its environment. This ability constitutes the foundation for such higher-order cognition. Without this fundamental capacity for change detection, no meaningful learning can occur.
While recent state-of-the-art large multimodal models (LMMs) [2,25,30,41,42] have demonstrated remarkable advancements, their focus has predominantly been on interpreting static images or continuous video streams. Existing benchmarks [5,13,17,27,37] focus on static content or single-state videos, failing to test a model’s ability to reason about transformations between distinct temporal points. This deficiency represents a significant impediment to the future development of artificial intelligence and truly intelligent agents.
To address this critical gap, we introduce M 3 -Verse, a novel benchmark designed to evaluate the understanding of discrete state changes. It is constructed from paired egocentric videos that capture indoor scenes before and after a change is made. This two-state structure transcends simple recognition, requiring models to perform a fine-grained semantic comparison and infer the transformations that connect the two scenes.
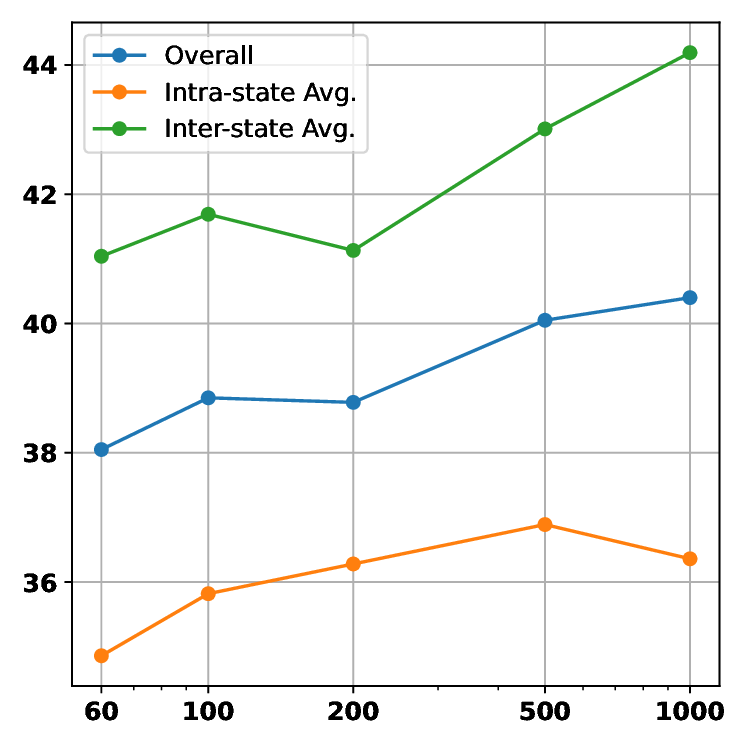
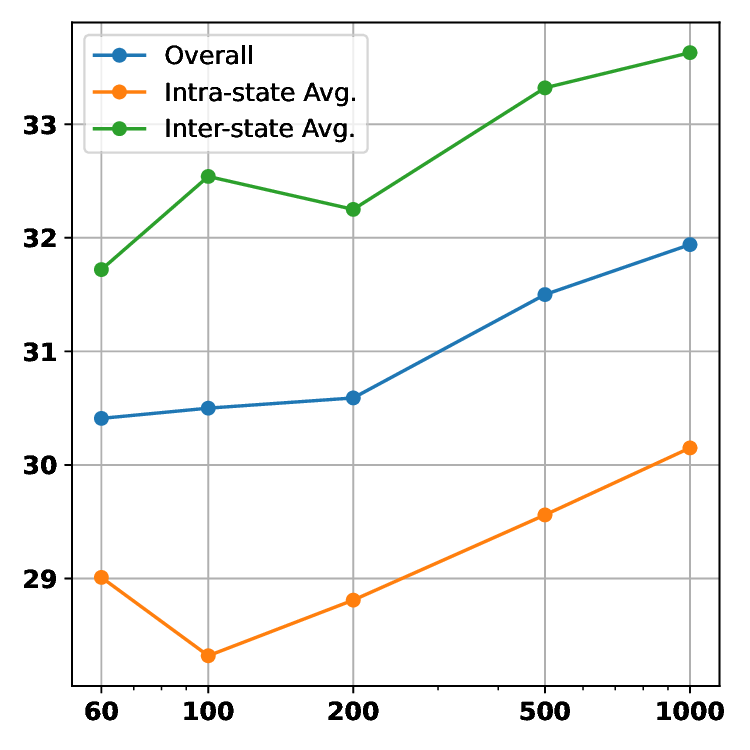
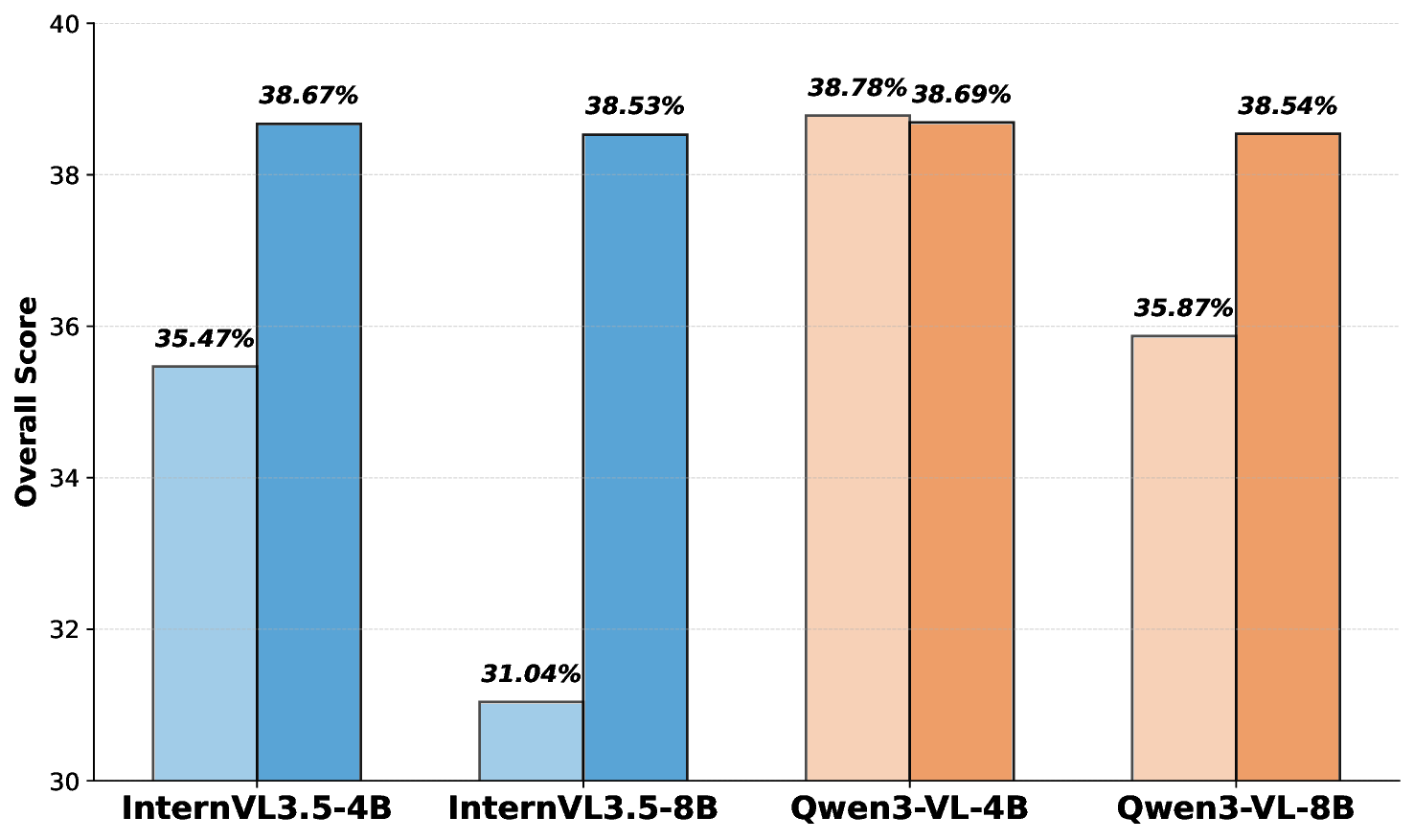
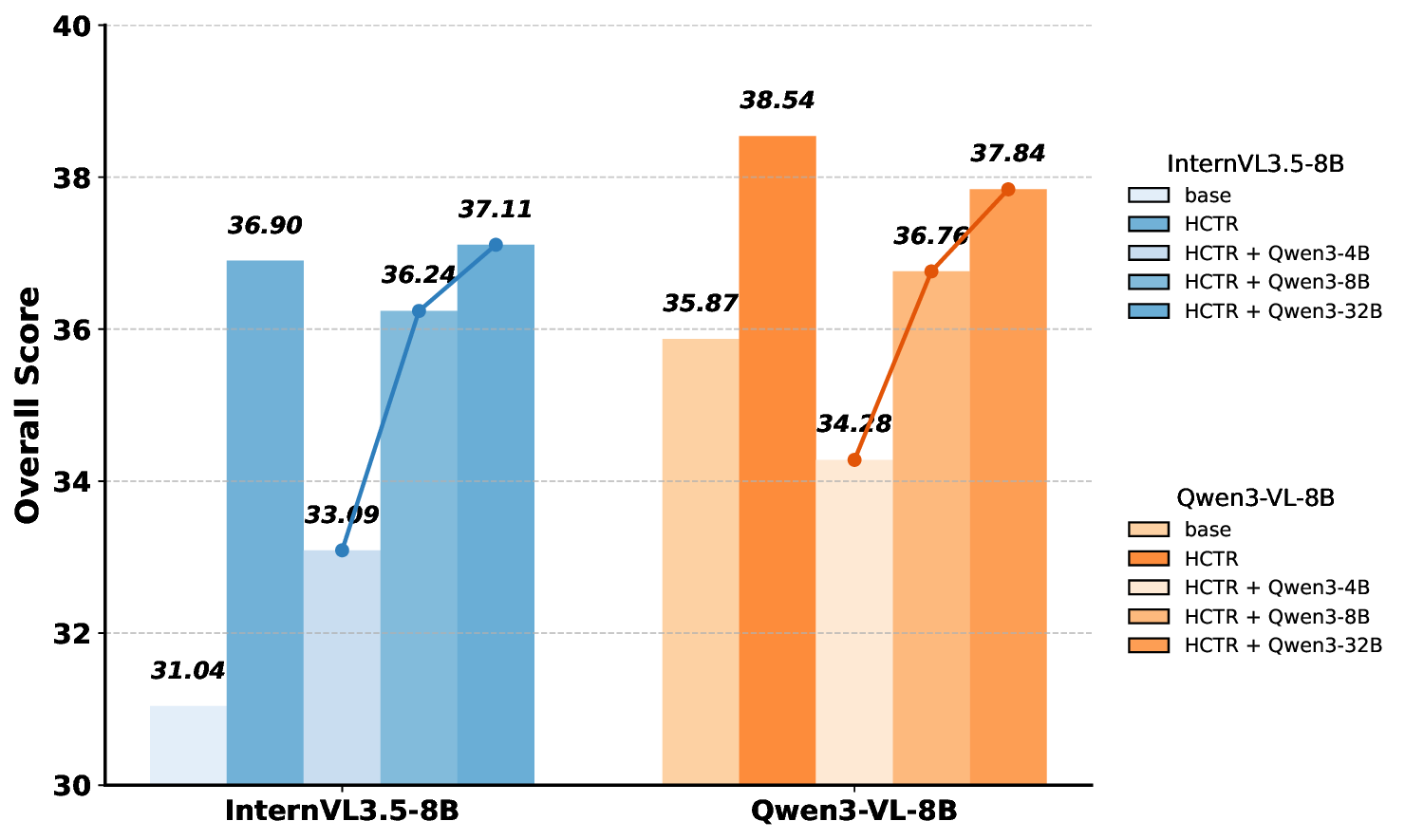
We offer the following principal contributions: • A Novel Benchmark: We introduce M 3 -Verse, the first large-scale benchmark dedicated to evaluating multi-state visual understanding. • A Challenging Evaluation Paradigm: Our two-state, paired-video design goes beyond conventional QA, enabling the rigorous evaluation of comparative reasoning about state transitions. • In-depth Model Analysis: Our evaluation of 16 leading LMMs and 6 text-only LLMs reveals their limitations in tracking state transitions, highlighting critical weaknesses not exposed by existing benchmarks. • A simple but effective method: we propose a simple but effective method, namely Hierarchical Captioning and Text-based Reasoning (HCTR), which outperforms the base models on our benchmark. By open-sourcing the M 3 -Verse, we provide the community with a vital tool to advance the next generation of AI systems capable of understanding and reasoning about our dynamic world.
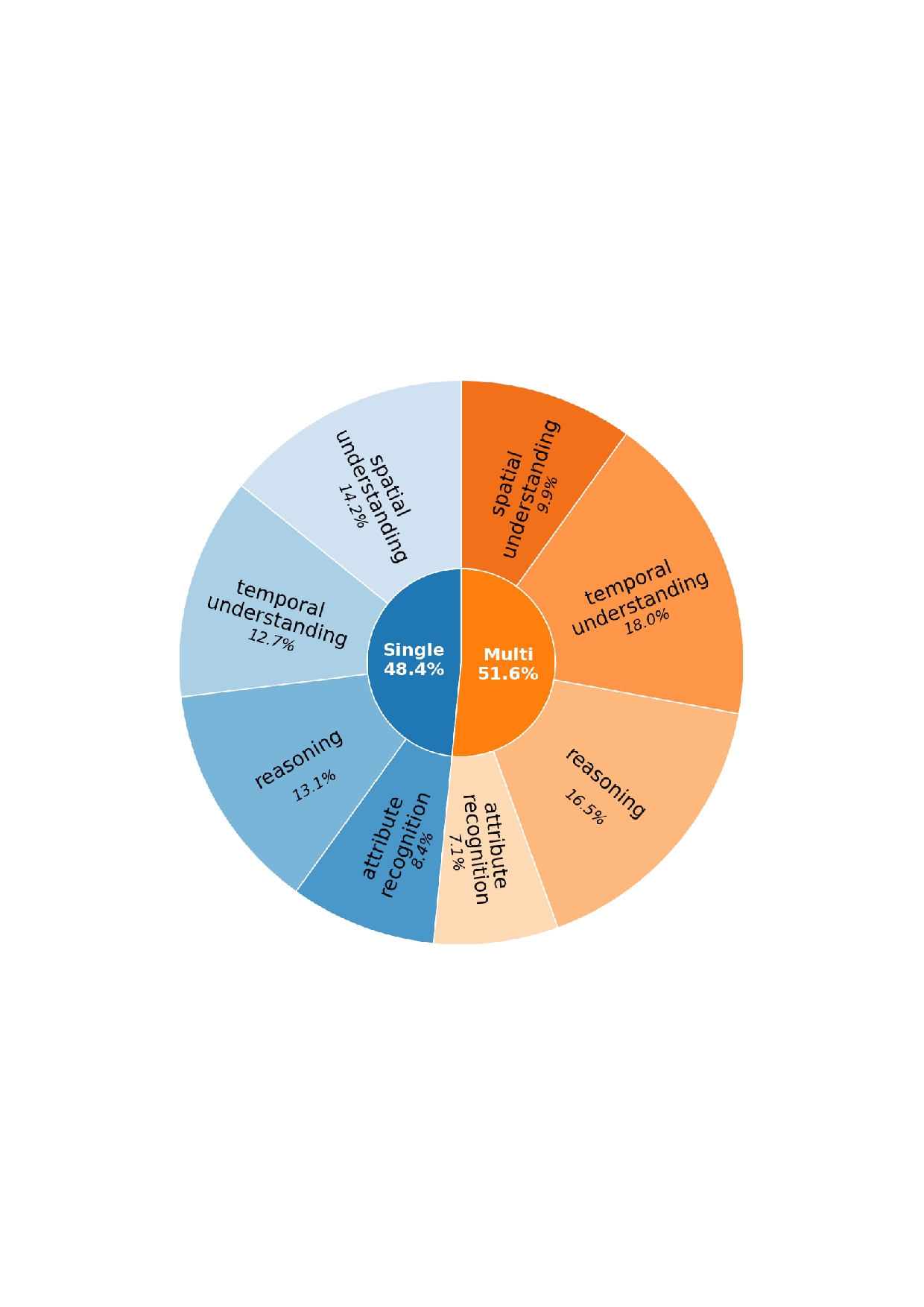
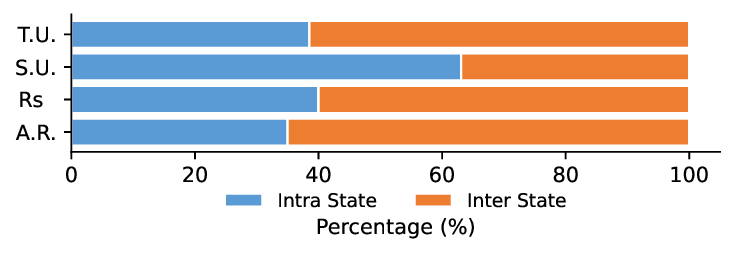
The development of Large Multimodal Models (LMMs) has markedly advanced AI’s ability to perceive the world. Early works [1,15,26] mapped visual features to text embeddings, leading to models [3,21] that bridged visual encoders with LLMs for impressive visual question answering. This architecture was then extended from static images to short video understanding [14,16,19,23,43]. To 3 -Verse. Intra-State: can be answered using information from a single state, Inter-State: requires information from both ‘before’ and ‘after’ states to be answered. These categories are further structured to evaluate four key capabilities: Spatial Understanding, Temporal Understanding, Attribute Recognition and Reasoning. push the boundaries of the model’s capabilities, recent research has focused on long-term video understanding, tack-ling the challenge of long contexts with methods like token merging strategies [28,32] and innovative architec-tures [25,31,34,41]. Beyond extending context length, a new frontier aims to enhance the reasoning capabilities of LMMs via post-training techniques like reinforcement learning (RL) [9,10,36]. While these models have made significant progress in video processing, their ability to understand fine-grained changes in discrete multi-state videos remains unexplored. We introduce a benchmark, concentrating on this overlooked dimension, multi-state video understanding, and utilize it to evaluate how well current SOTA models can identify the state transitions of key objects or scenes at different points in time.
To evaluate the visual understanding capabilities of LMMs, a large num
This content is AI-processed based on open access ArXiv data.