Large-scale networked multi-agent systems increasingly underpin critical infrastructure, yet their collective behavior can drift toward undesirable emergent norms that elude conventional governance mechanisms. We introduce an adaptive accountability framework that (i) continuously traces responsibility flows through a lifecycle-aware audit ledger, (ii) detects harmful emergent norms online via decentralized sequential hypothesis tests, and (iii) deploys local policy and reward-shaping interventions that realign agents with system-level objectives in near real time. We prove a bounded-compromise theorem showing that whenever the expected intervention cost exceeds an adversary's payoff, the long-run proportion of compromised interactions is bounded by a constant strictly less than one. Extensive high-performance simulations with up to 100 heterogeneous agents, partial observability, and stochastic communication graphs show that our framework prevents collusion and resource hoarding in at least 90% of configurations, boosts average collective reward by 12-18%, and lowers the Gini inequality index by up to 33% relative to a PPO baseline. These results demonstrate that a theoretically principled accountability layer can induce ethically aligned, self-regulating behavior in complex MAS without sacrificing performance or scalability.
Multi-agent systems (MAS) increasingly underpin critical applications in transportation, smart-grid energy management, finance, and healthcare [60,67]. By distributing decision making across many partly autonomous agents, these systems offer scalability, resilience to single-point failures, and rapid adaptation to non-stationary environments. Those benefits, however, come with interaction complexity: once deployed, the collective behavior can drift toward undesirable emergent norms that were never explicitly designed or anticipated [61,54]. Identifying and correcting such norms is essential for ensuring fairness, security, and compliance with societal values.
In large-scale networked MAS, responsibility is diffused across agents and time steps. Classical AI-accountability frameworks-often built for single models or clearly identifiable human decision makers-rely on static compliance checks or post-hoc audits [38,28]. These approaches break down when no single node sees the full global state and harms can emerge from subtle feedback loops. Recent policy instruments, such as the EU Artificial Intelligence Act [16] and the U.S. NIST AI Risk-Management Framework [42], call for “collective accountability” in AI infrastructures but leave open the technical challenge of tracing and mitigating harmful norms online and in a decentralized fashion.
Three established research threads touch on this challenge yet remain individually insufficient. Normative MAS studies formal norms and sanctions [3,25] but typically assumes a central monitor with perfect state access. Multi-agent reinforcement learning (MARL) has produced sophisticated training algorithms [9,18], but only recently has begun to explore equity, collusion, or convergence to harmful equilibria. Runtime assurance for cyber-physical systems proposes supervisory safety guards [51], yet seldom scales beyond a handful of agents or supports changing objectives. Consequently, the field still lacks a comprehensive method to detect, trace, and correct undesirable emergent norms under partial observability and heterogeneous incentives. This paper tackles four questions: (i) How can responsibility for distributed actions be continuously attributed when no participant sees the entire trajectory? (ii) Can harmful emergent norms be detected online without halting operations or requiring global state? (iii) Which local policy or reward interventions can steer a large MAS back toward socially preferred outcomes while respecting resource and latency constraints? (iv) Do those interventions remain robust as the number of agents, communication topology, or payoff structure changes?
We answer by proposing an Adaptive Accountability Framework that combines a lifecycle-aware audit ledger, decentralized sequential hypothesis tests for online norm detection, and targeted reward-shaping or policy-patch interventions. Our principal theoretical result-the bounded-compromise theorem-proves that when the expected cost of interventions exceeds an adversary’s payoff, the steady-state fraction of compromised or collusive interactions converges to a value strictly below one. The theorem formalizes the intuition that inexpensive, well-targeted corrections can prevent persistent harmful norms even in strategic environments.
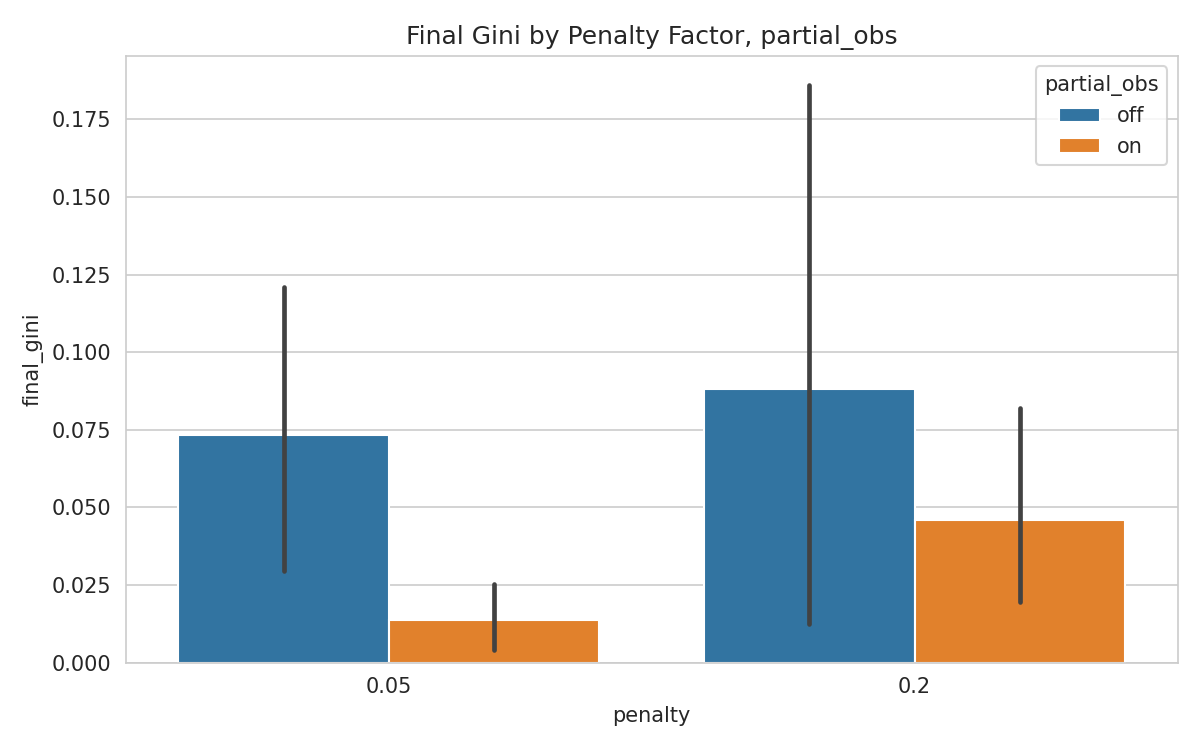
To evaluate the framework at realistic scale, we run extensive simulations on a high-performance cluster equipped with NVIDIA A40 GPUs. Up to 100 heterogeneous agents interact over stochastic communication graphs under partial observability. Across 360 Monte-Carlo configurations that vary random seeds, payoff functions, and intervention protocols, the framework averts collusion and resource hoarding in at least 90% of runs, lifts average collective reward by 12-18%, and reduces the Gini inequality index by up to 33% relative to a PPO baseline. All code and simulation scripts will be released to support replication.
The paper has the following main contributions:
An accountability architecture that logs interaction events, tags causal chains, and maps evolving responsibility flows without centralized state.
Online norm-detection algorithms based on decentralized sequential hypothesis testing.
Adaptive mitigation protocols that apply graded local incentives or policy patches to realign global behavior.
A high-fidelity implementation integrated with modern MLOps pipelines and illustrated through resourceallocation and collaborative-task case studies.
Comprehensive large-scale evaluation demonstrating robustness and scalability across diverse operating conditions.
The rest of the paper is organized as follows. Section 2 surveys related work on MAS coordination, normative design, and AI governance. Section 3 formalizes the problem setting. Section 4 details the proposed architecture, detection tests, and intervention algorithms. Section 6 describes the software stack and deployment considerations. Section 7 reports empirical results, and Section 8 discu
This content is AI-processed based on open access ArXiv data.