Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction
Reading time: 5 minute
...
📝 Original Info
Title: Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction
ArXiv ID: 2512.18880
Date: 2025-12-21
Authors: Ming Li, Han Chen, Yunze Xiao, Jian Chen, Hong Jiao, Tianyi Zhou
📝 Abstract
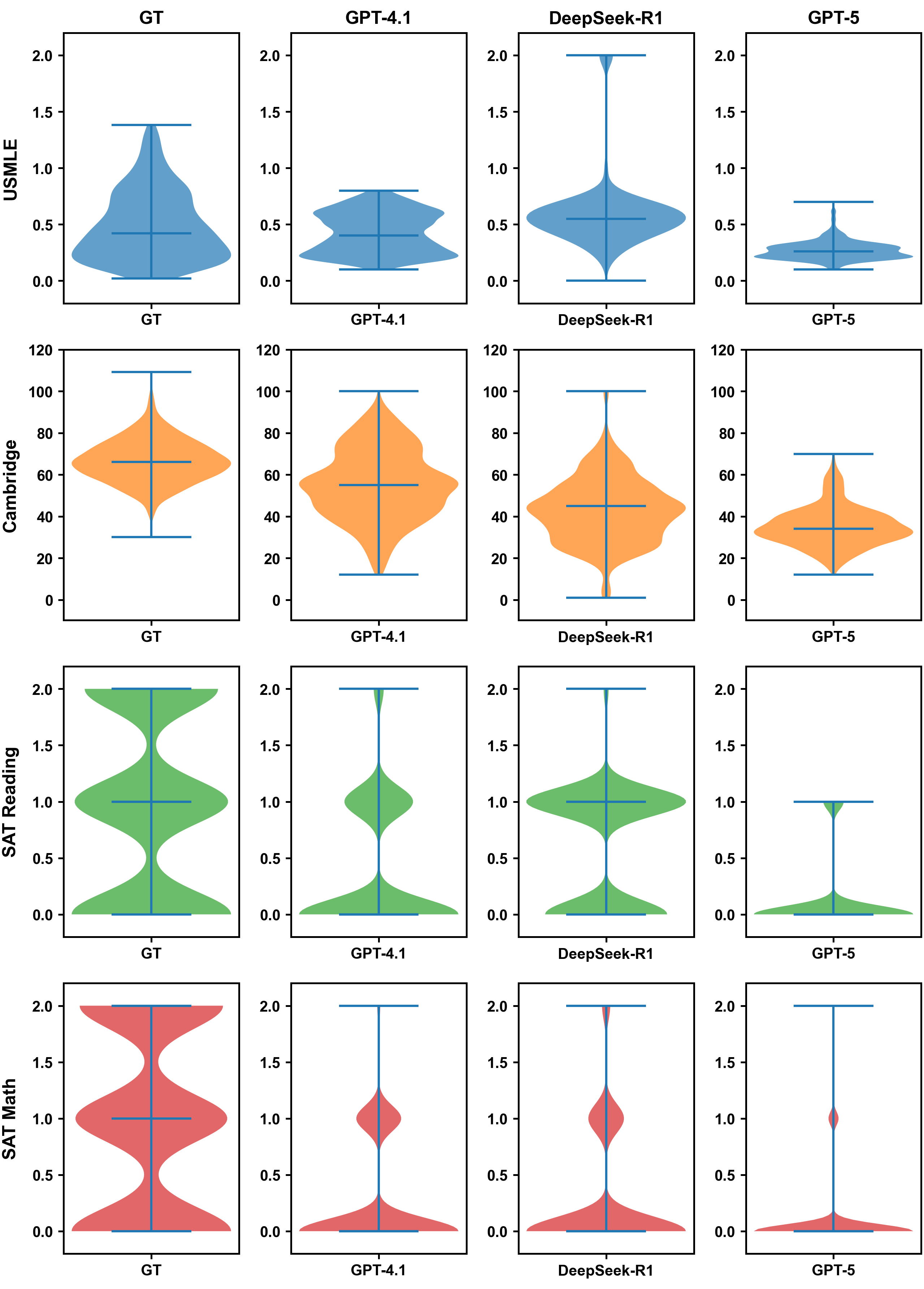
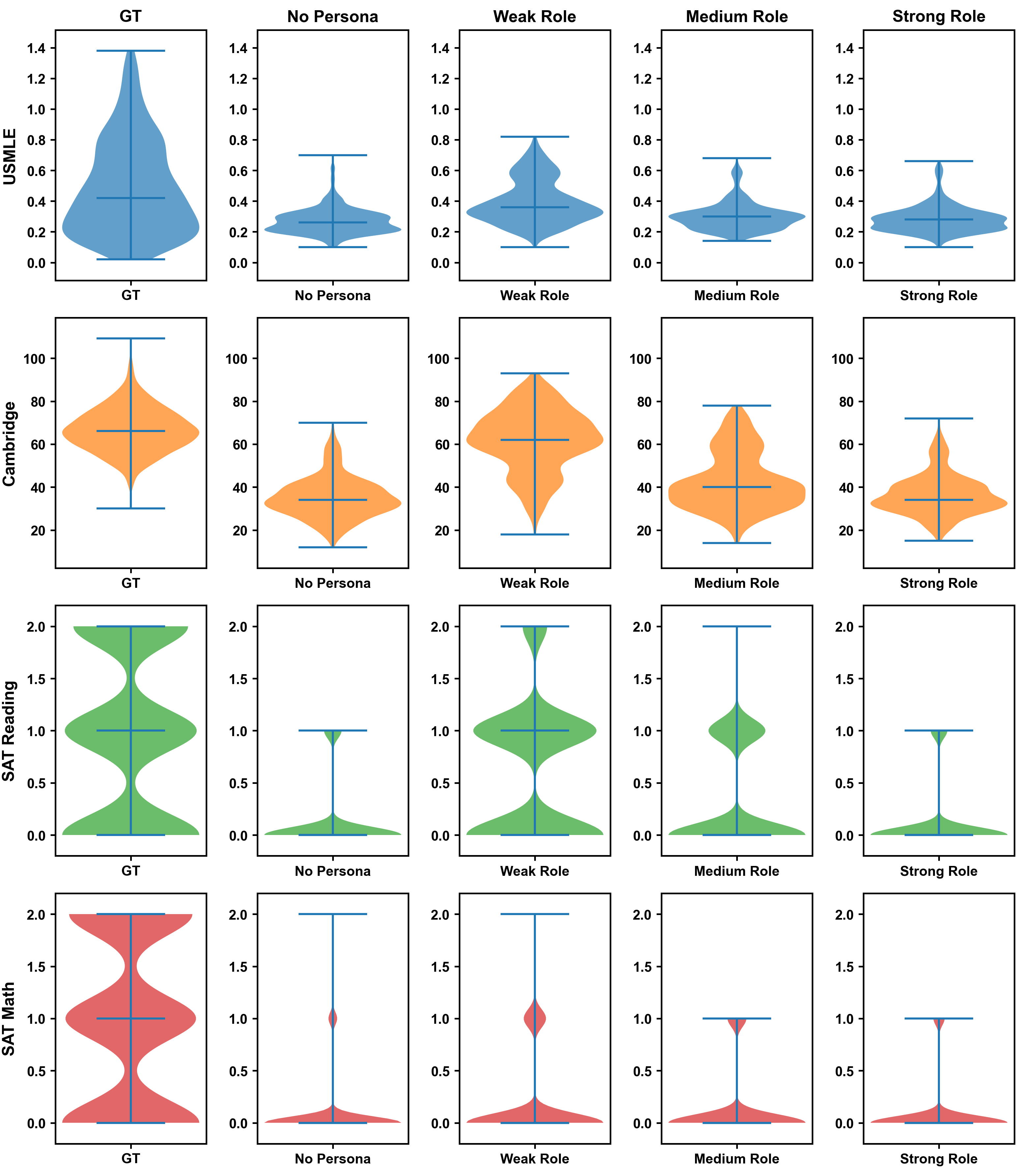
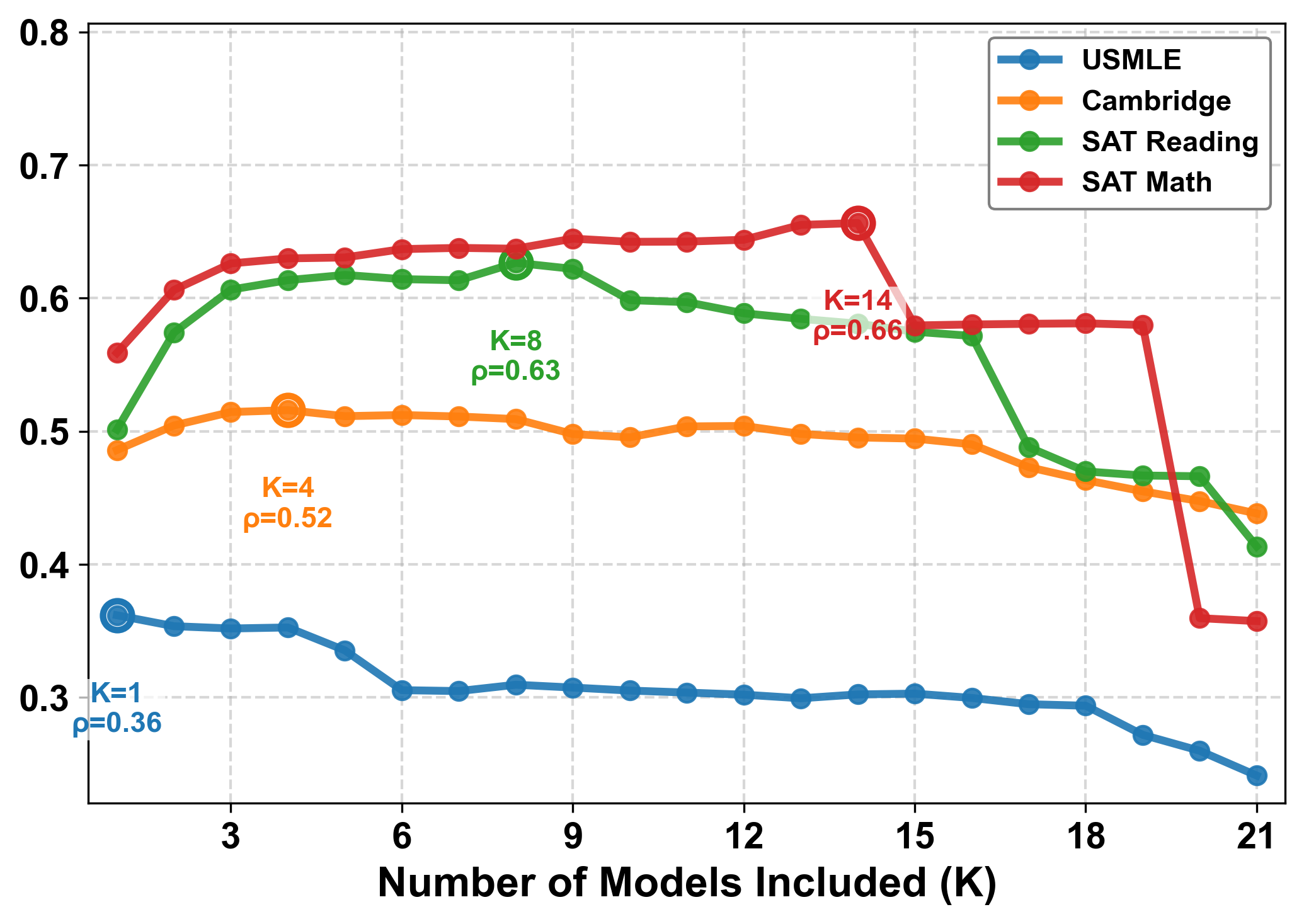
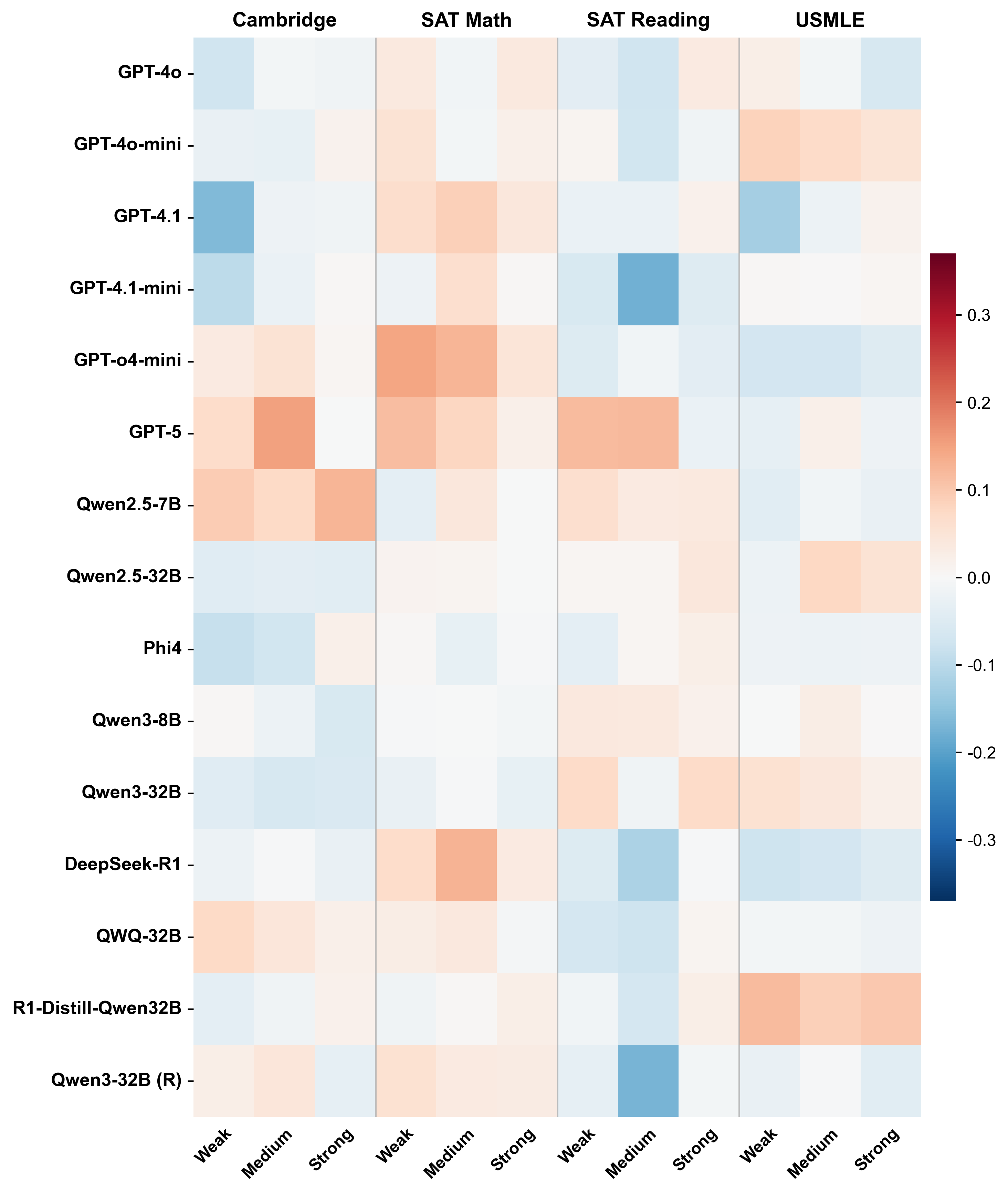
Accurate estimation of item (question or task) difficulty is critical for educational assessment but suffers from the cold start problem. While Large Language Models demonstrate superhuman problem-solving capabilities, it remains an open question whether they can perceive the cognitive struggles of human learners. In this work, we present a large-scale empirical analysis of Human-AI Difficulty Alignment for over 20 models across diverse domains such as medical knowledge and mathematical reasoning. Our findings reveal a systematic misalignment where scaling up model size is not reliably helpful; instead of aligning with humans, models converge toward a shared machine consensus. We observe that high performance often impedes accurate difficulty estimation, as models struggle to simulate the capability limitations of students even when being explicitly prompted to adopt specific proficiency levels. Furthermore, we identify a critical lack of introspection, as models fail to predict their own limitations. These results suggest that general problem-solving capability does not imply an understanding of human cognitive struggles, highlighting the challenge of using current models for automated difficulty prediction.
💡 Deep Analysis
📄 Full Content
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment
with Proficiency Simulation for Item Difficulty Prediction
Ming Li*1, Han Chen*, Yunze Xiao2, Jian Chen3, Hong Jiao1, Tianyi Zhou
1University of Maryland
2Carnegie Mellon University
3University at Buffalo
minglii@umd.edu, tianyi.david.zhou@gmail.com
Project: https://github.com/MingLiiii/Difficulty_Alignment
Abstract
Accurate estimation of item (question or task)
difficulty is critical for educational assessment
but suffers from the cold start problem. While
Large Language Models demonstrate superhu-
man problem-solving capabilities, it remains
an open question whether they can perceive the
cognitive struggles of human learners. In this
work, we present a large-scale empirical anal-
ysis of Human-AI Difficulty Alignment for
over 20 models across diverse domains such as
medical knowledge and mathematical reason-
ing. Our findings reveal a systematic misalign-
ment where scaling up model size is not reliably
helpful; instead of aligning with humans,
models converge toward a shared machine
consensus. We observe that high performance
often impedes accurate difficulty estimation, as
models struggle to simulate the capability lim-
itations of students even when being explicitly
prompted to adopt specific proficiency levels.
Furthermore, we identify a critical lack of in-
trospection, as models fail to predict their own
limitations. These results suggest that general
problem-solving capability does not imply an
understanding of human cognitive struggles,
highlighting the challenge of using current
models for automated difficulty prediction.
1
Introduction
Accurate estimation of item difficulty is the
cornerstone of educational assessment (Hambleton
et al., 1991; Hsu et al., 2018; AlKhuzaey et al.,
2021; Peters et al., 2025). It underpins critical
applications such as curriculum design, automated
test generation, and automated item generation
with controlled difficulty levels (DeMars, 2010;
Lord, 2012).
Traditionally, obtaining accurate
difficulty parameters (e.g., within Item Response
Theory (IRT) models (Baker, 2001; Lalor et al.,
2024)) relies on extensive field testing, a process
that requires administering questions to large
*Equal Contribution.
cohorts of real test-takers to observe response
patterns. This reliance creates a significant cold
start problem: newly generated questions lack the
historical response data necessary to statistically es-
timate their parameters, effectively rendering them
unusable in adaptive systems until they undergo
expensive and time-consuming pre-testing cycles.
Prior approaches to Item Difficulty Prediction
(IDP) generally treated the task as a supervised
learning problem, relying on linguistic features or
deep learning models trained on known item param-
eters estimated based on item response data (Hsu
et al., 2018; Benedetto, 2023; Li et al., 2025b).
While effective within specific domains, these
methods depend heavily on the availability of his-
torical performance data for training, limiting their
utility in cold-start scenarios (i.e., no historical
tested data is available for training). The emer-
gence of LLMs (OpenAI, 2024b; Hurst et al., 2024;
Touvron et al., 2023; Qwen-Team, 2024, 2025a)
offers a potential paradigm shift. With their vast
pre-training and exceptional problem-solving capa-
bilities, LLMs seemingly possess the knowledge
required to analyze complex content. However, it
remains an open question whether these general-
purpose models can align with human percep-
tion of difficulty without task-specific fine-tuning.
There is a fundamental distinction between solving
a problem and evaluating its difficulty: a model
that effortlessly surpasses human baselines in per-
formance may fail to recognize the cognitive hur-
dles faced by an average learner (Sweller, 1988,
2011; Noroozi and Karami, 2022; Li et al., 2025c).
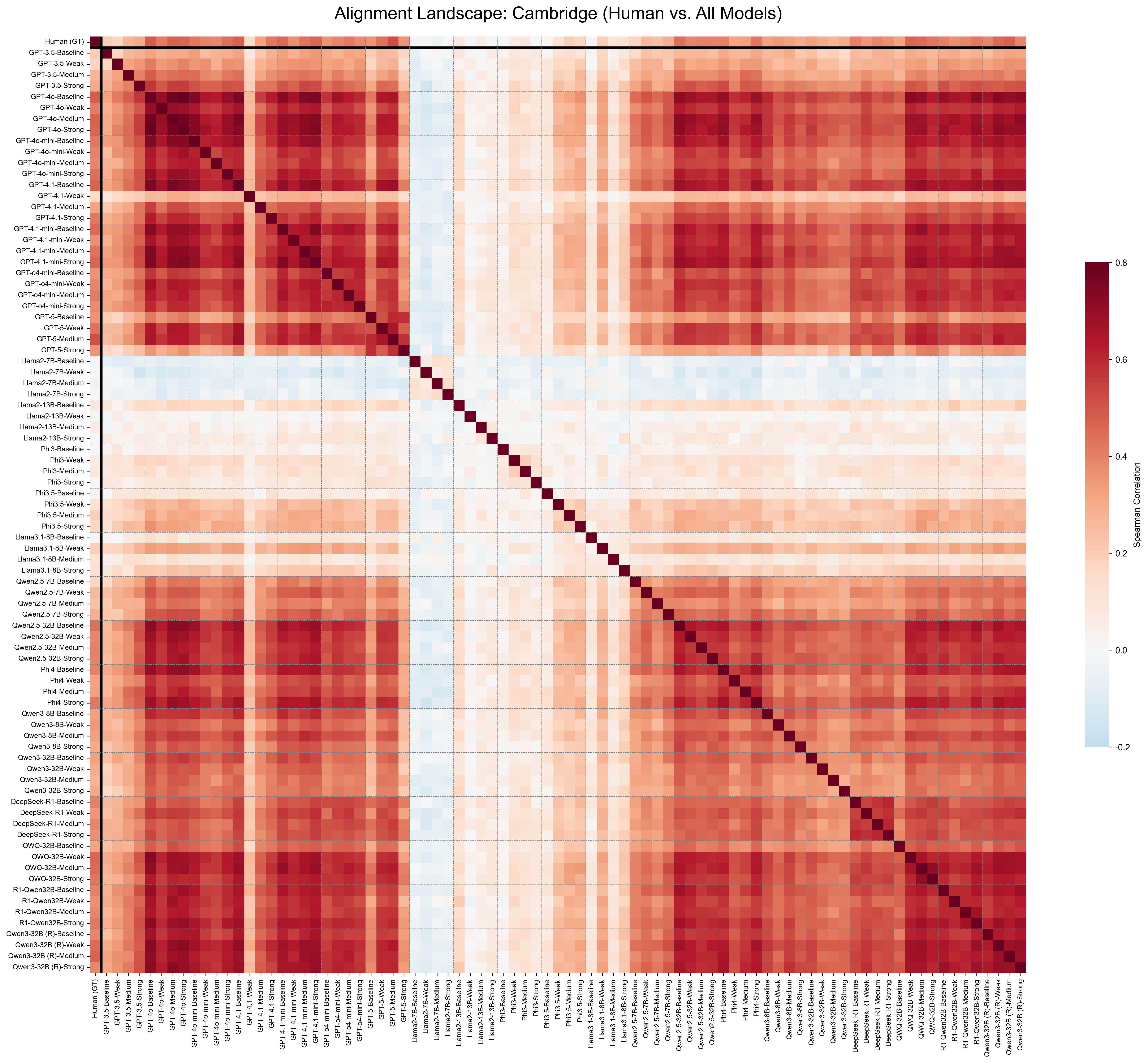
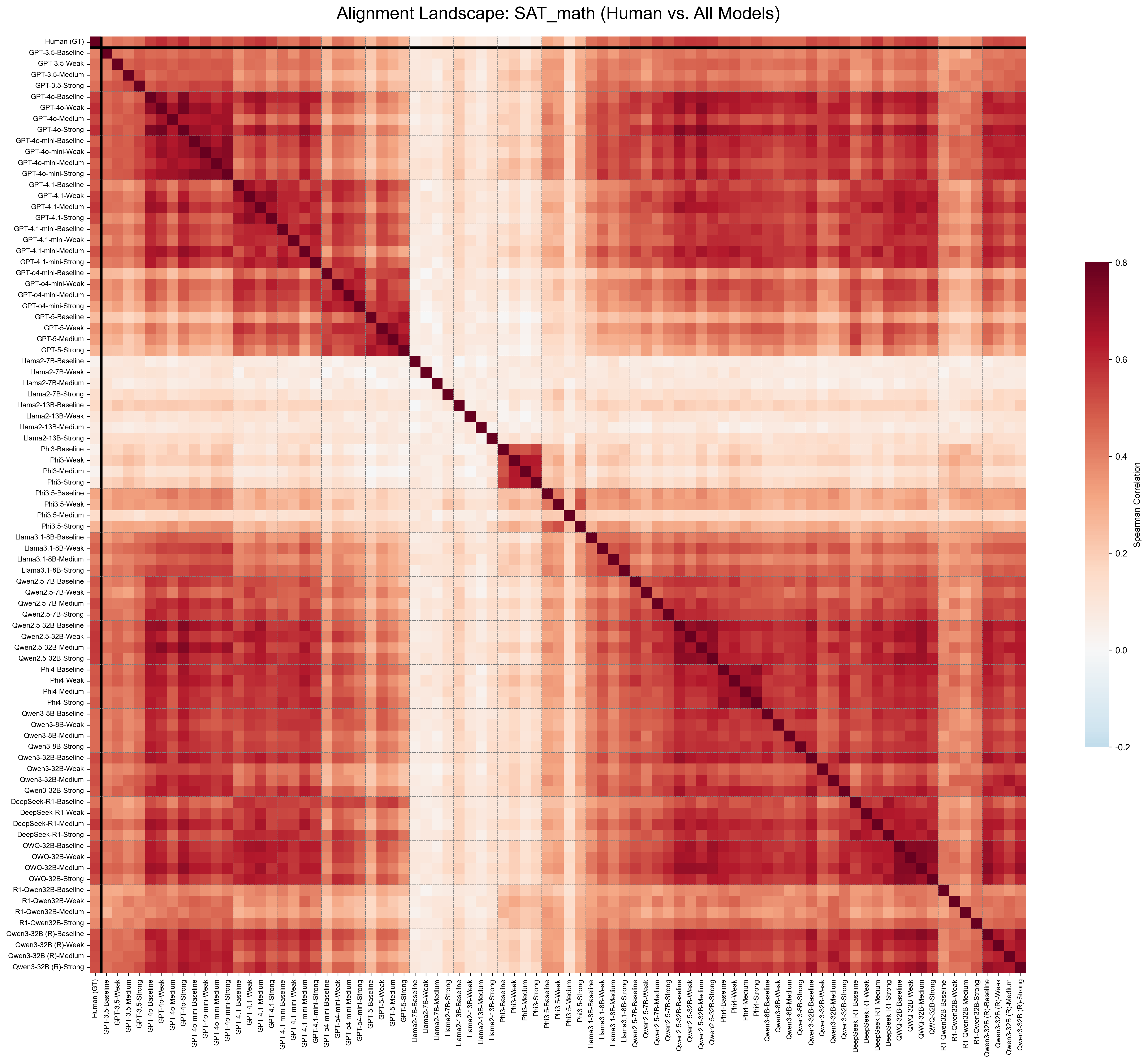
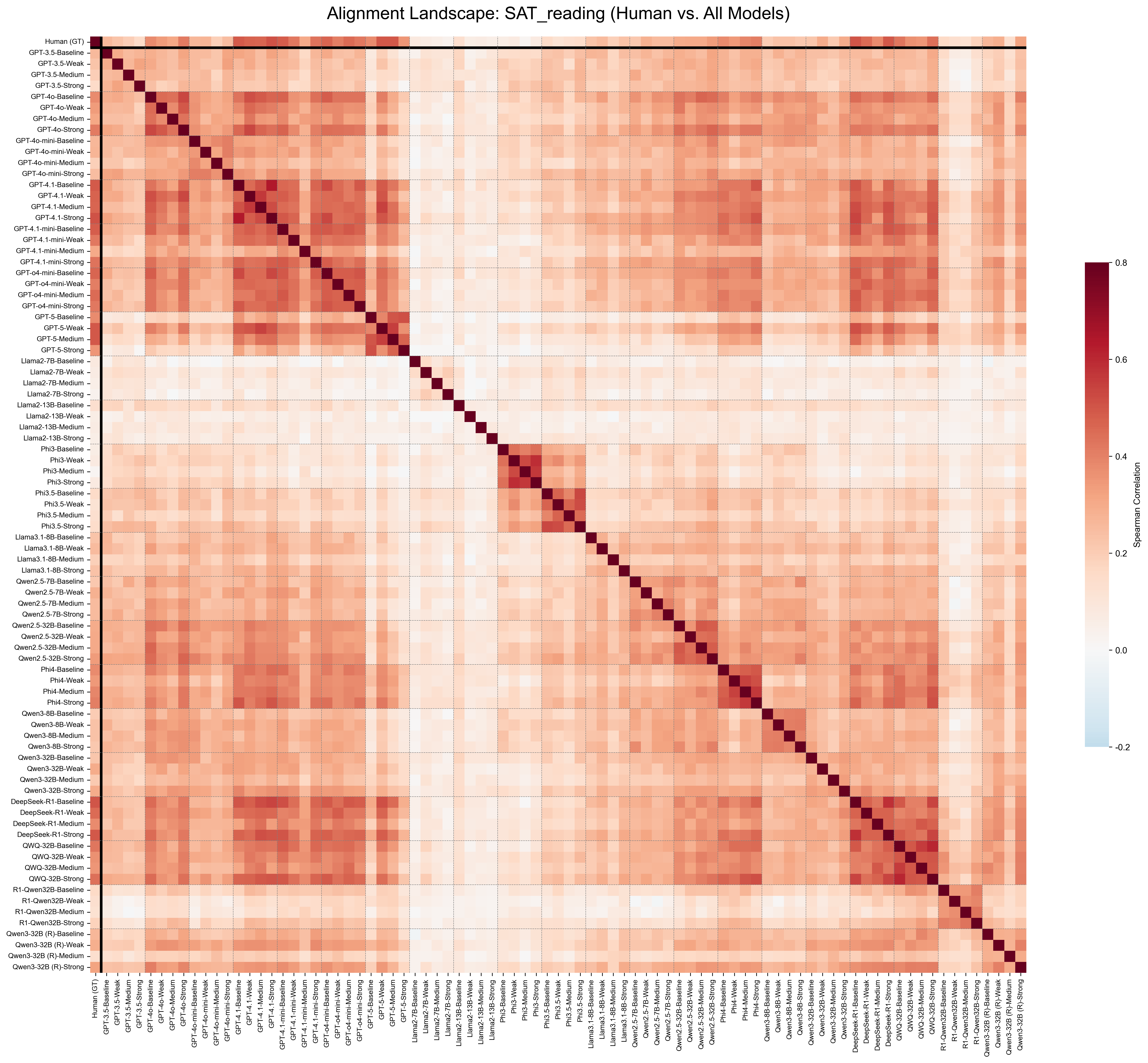
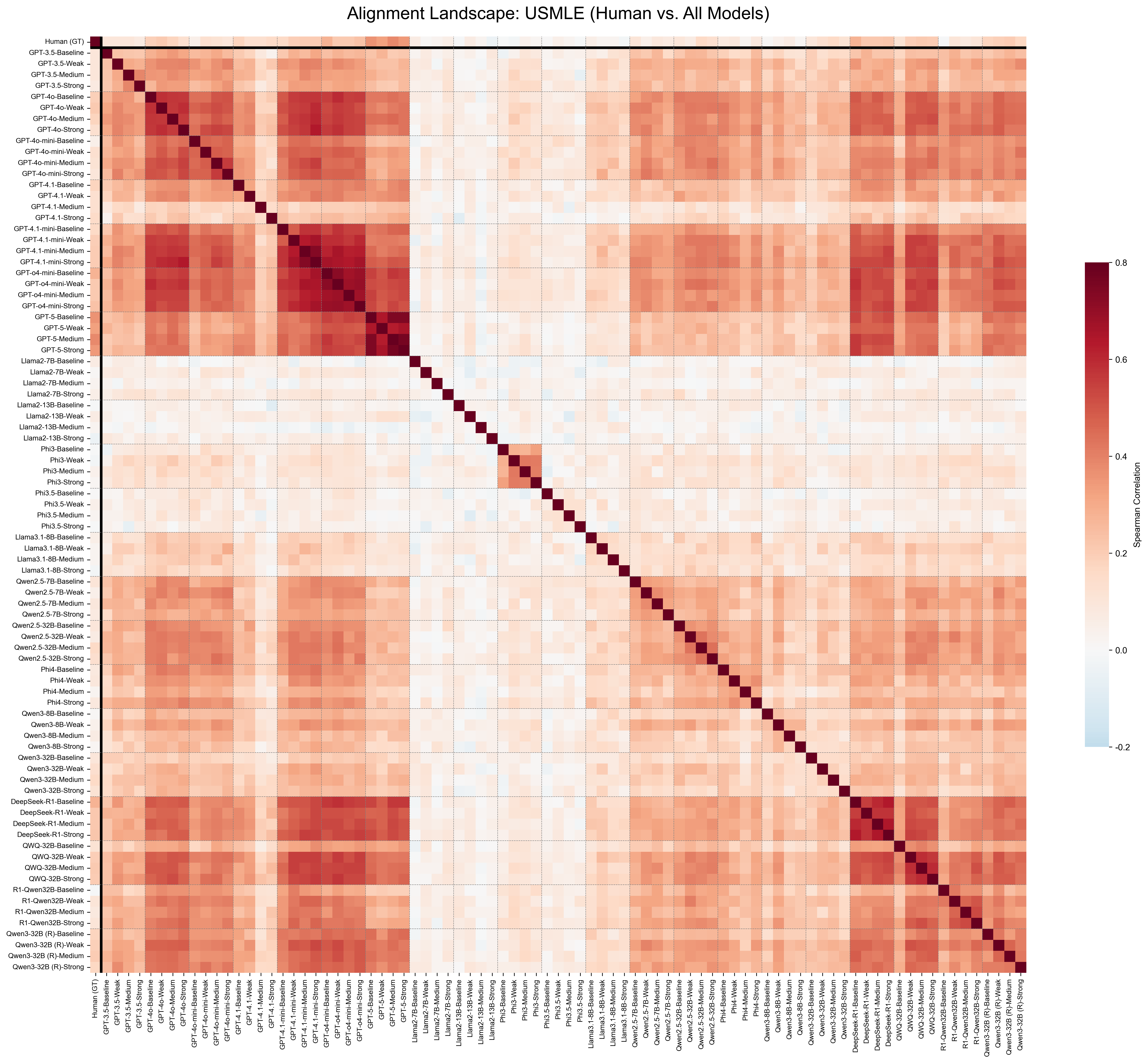
This study investigates this Human-AI Difficulty
Alignment, exploring whether off-the-shelf LLMs
can bridge the gap between their own capabilities
and the student struggles, whose difficulty values
are obtained from real student field testing.
To investigate this, we propose a comprehensive
empirical study that evaluates this Difficulty Align-
ment through two distinct lenses: the model as an
1
arXiv:2512.18880v1 [cs.CL] 21 Dec 2025
external observer (predicting others’ difficulty)
and an internal actor (experiencing difficulty it-
self).
Our study operates at scale, benchmark-
ing over 20 LLMs, spanning both open-weights
and closed-source families, including reasoning-
specialized models, across four diverse educational
domains: language proficiency (Cambridge) (Mul-
looly et al., 2023), reasoning and logic (SAT Read-
ing/Writing, SAT Math), and professional medical
knowledge (USMLE) (Yaneva et al., 2024).
We structure our investigation around three pri-
mary dimensions to disentangle the relationship
between intrinsic capability and extrinsic percep-
tion. First, we go beyond simple