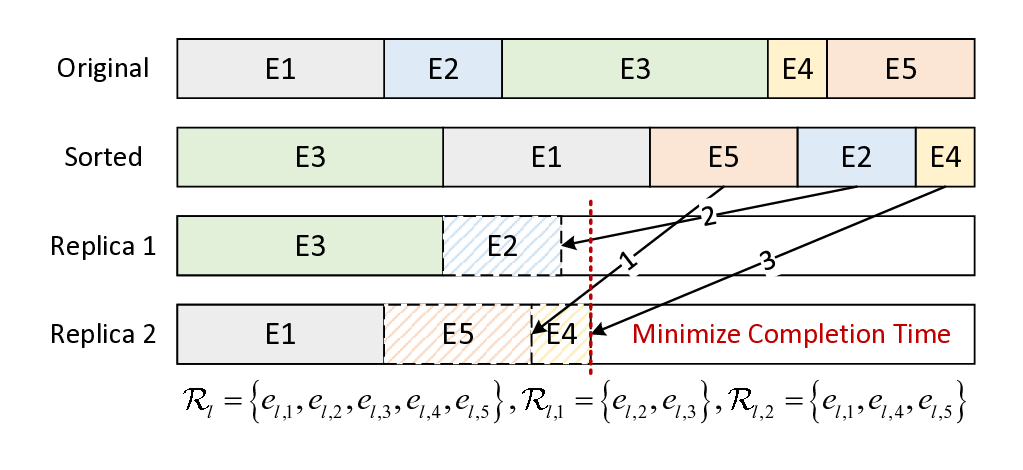
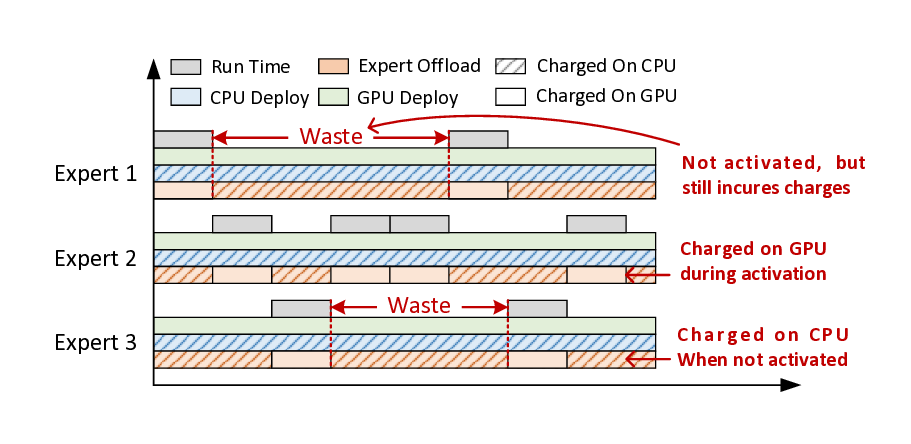
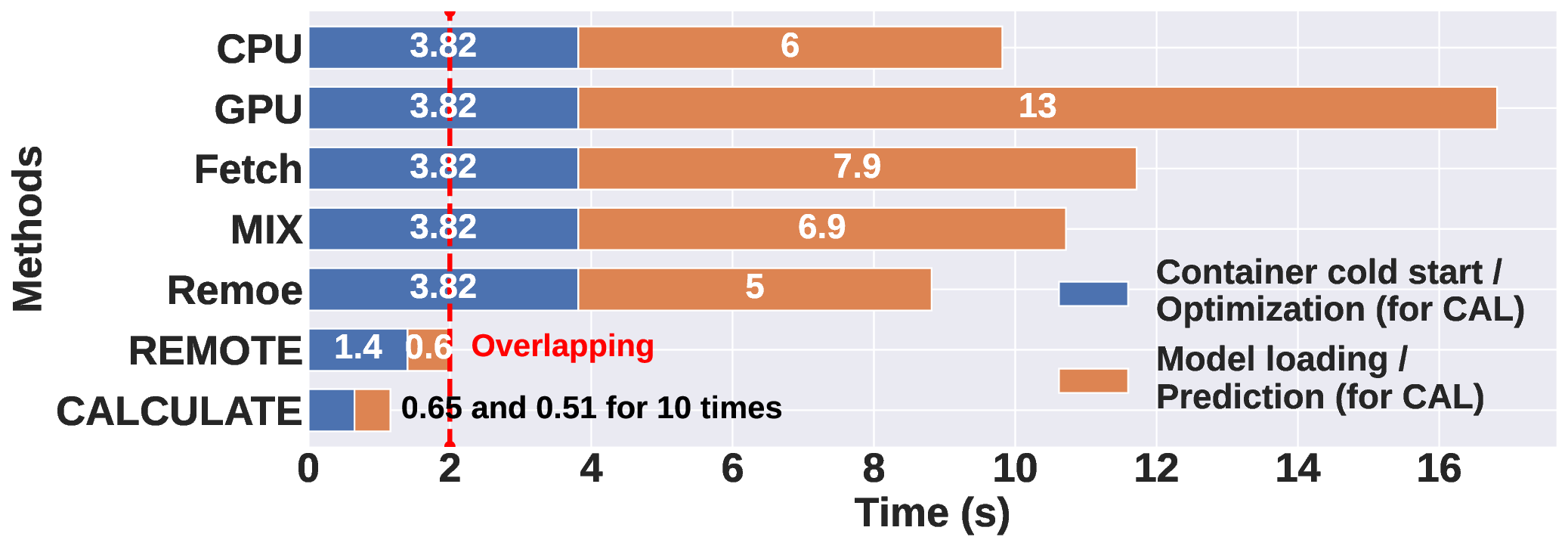
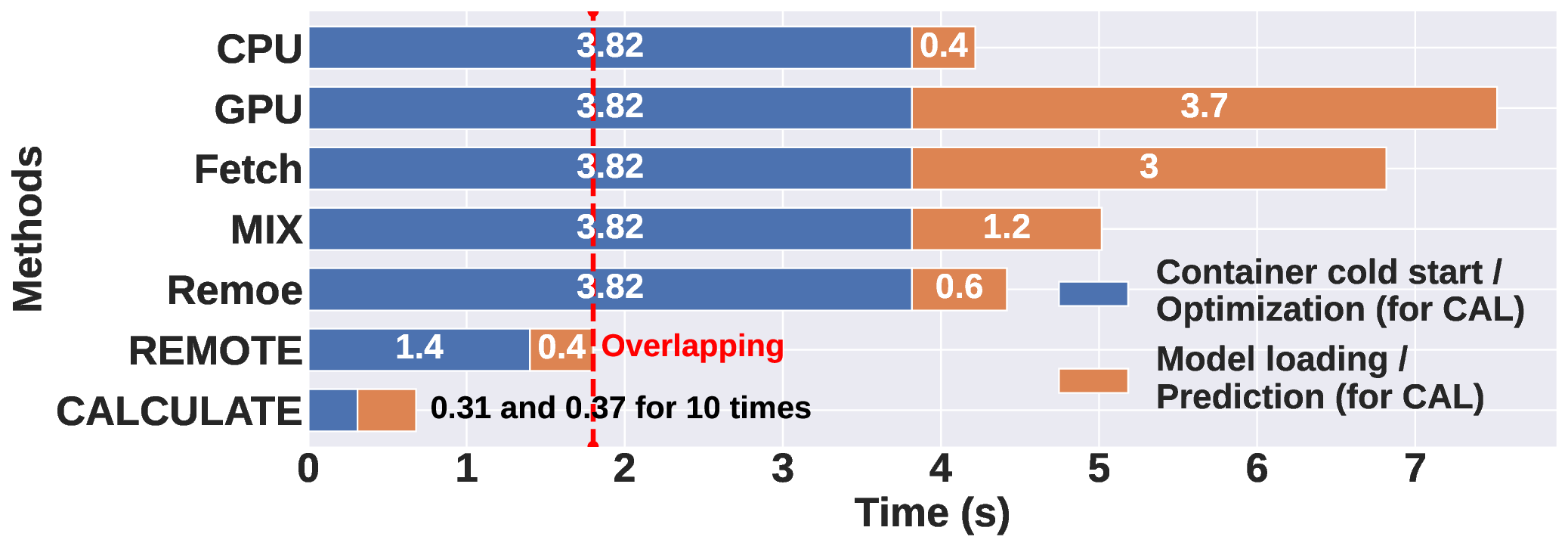
Remoe: Towards Efficient and Low-Cost MoE Inference in Serverless Computing
Reading time: 5 minute
...
📝 Original Info
Title: Remoe: Towards Efficient and Low-Cost MoE Inference in Serverless Computing
ArXiv ID: 2512.18674
Date: 2025-12-21
Authors: ** - Wentao Liu (동남대학교, 중국) - Yuhao Hu (동남대학교, 중국) - Ruiting Zhou (동남대학교, 중국) – 교신 저자 - Baochun Li (토론토 대학교, 캐나다) - Ne Wang (홍콩 폴리테크닉 대학교, 홍콩) **
📝 Abstract
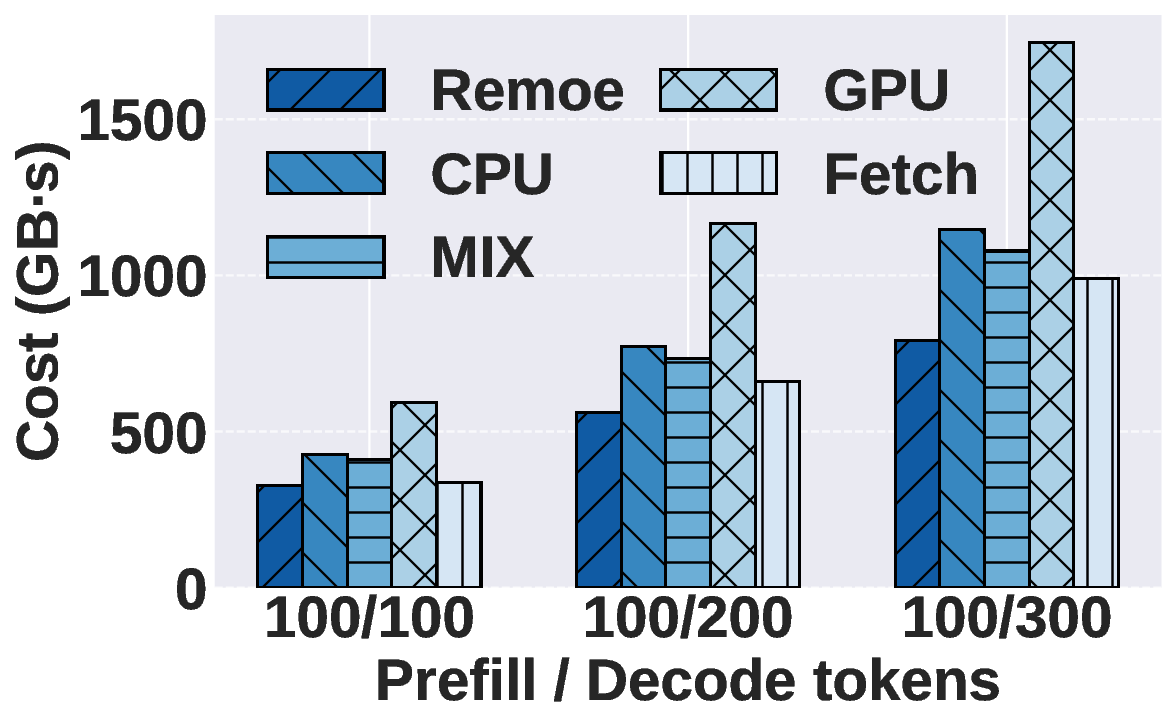
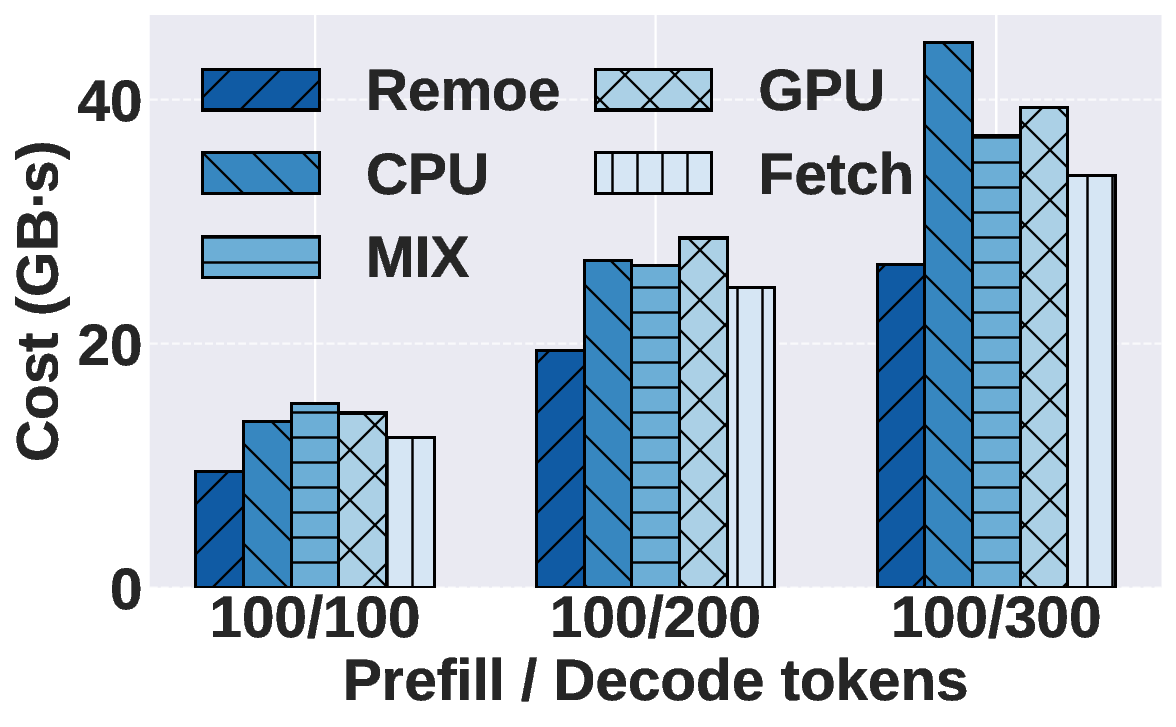
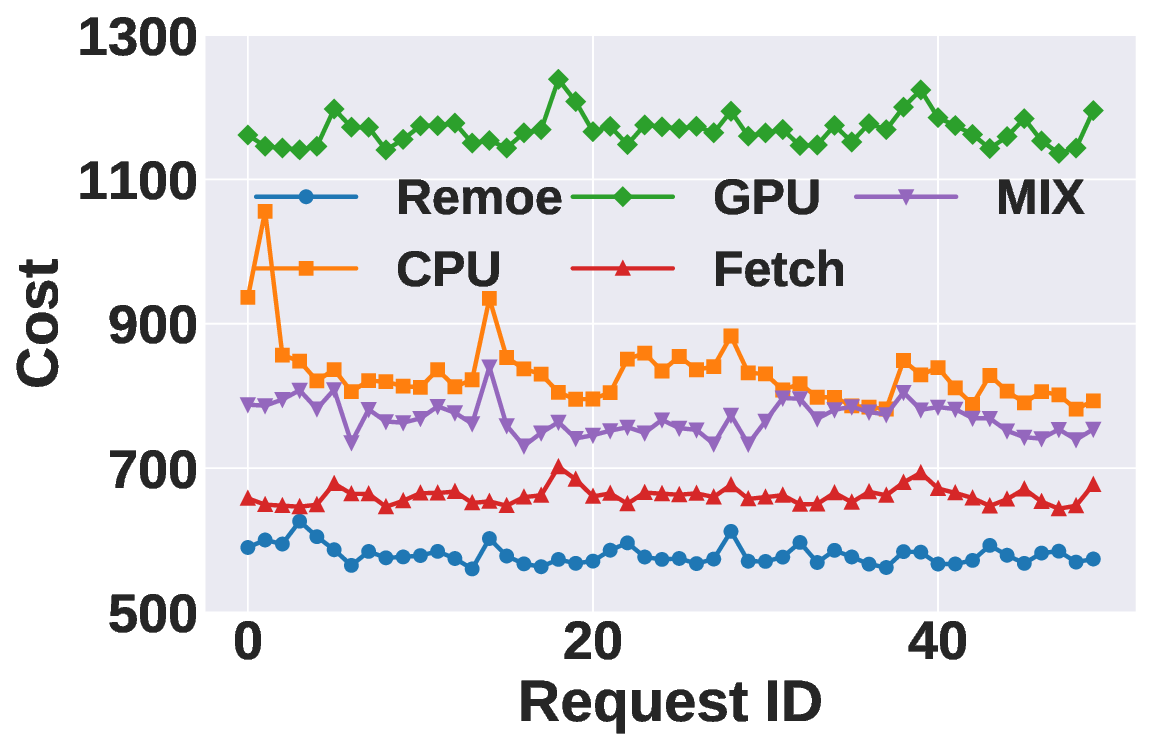
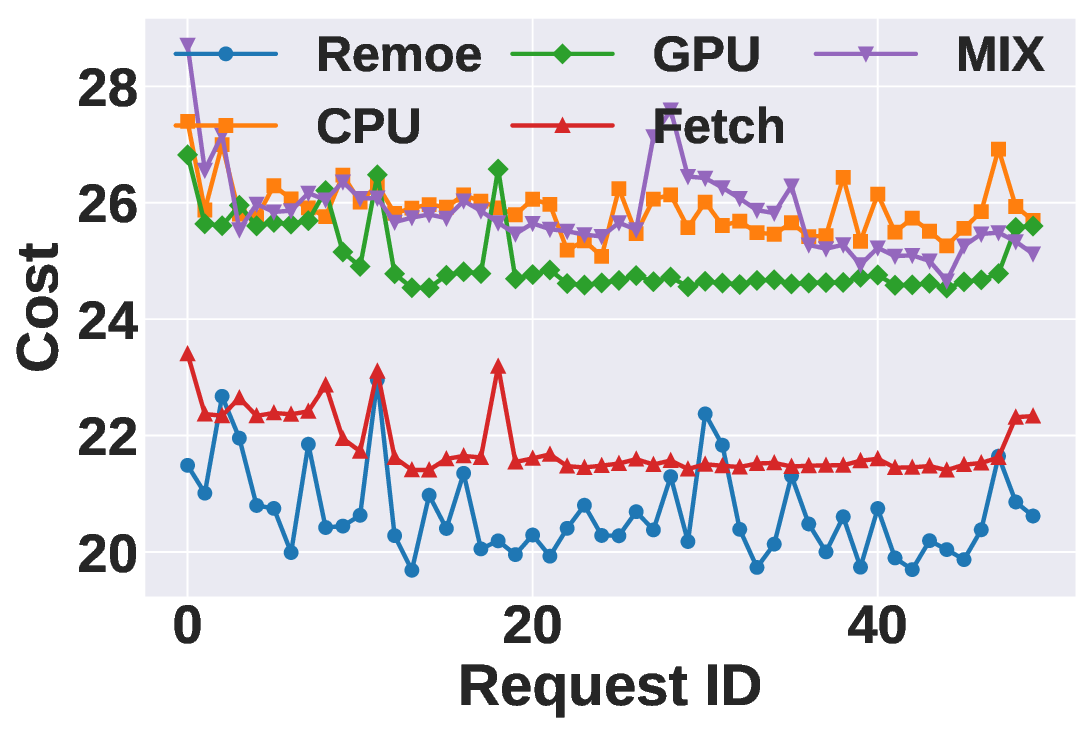
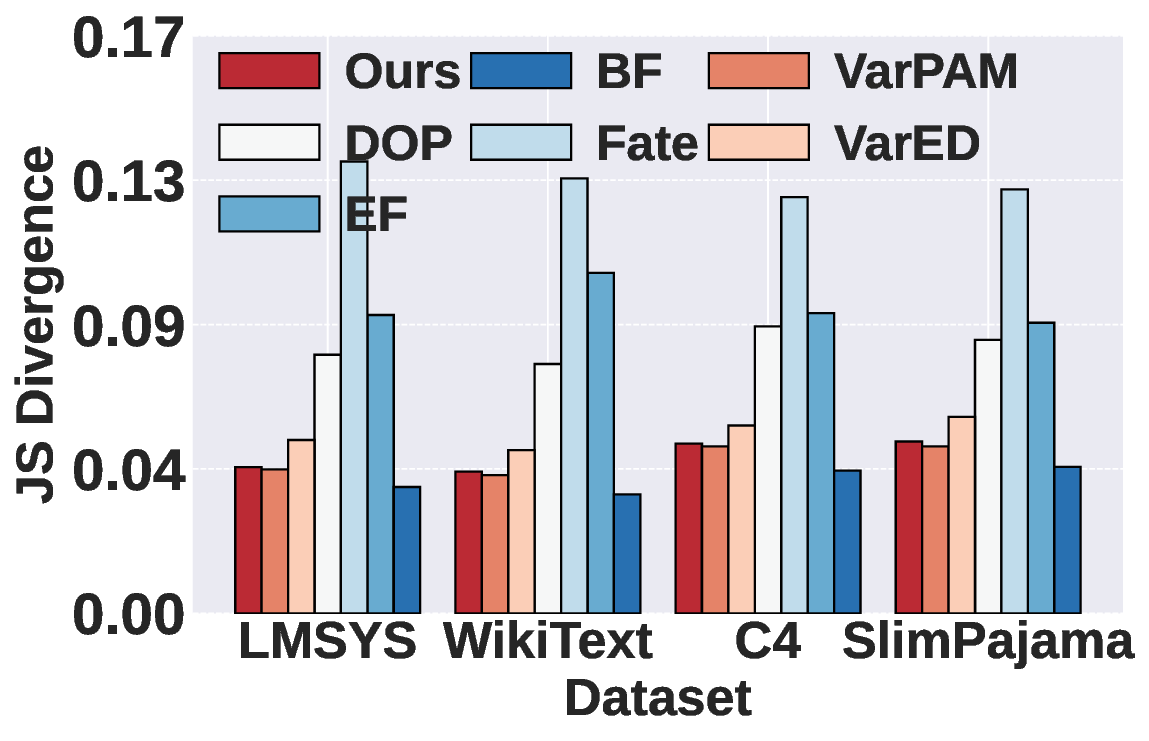
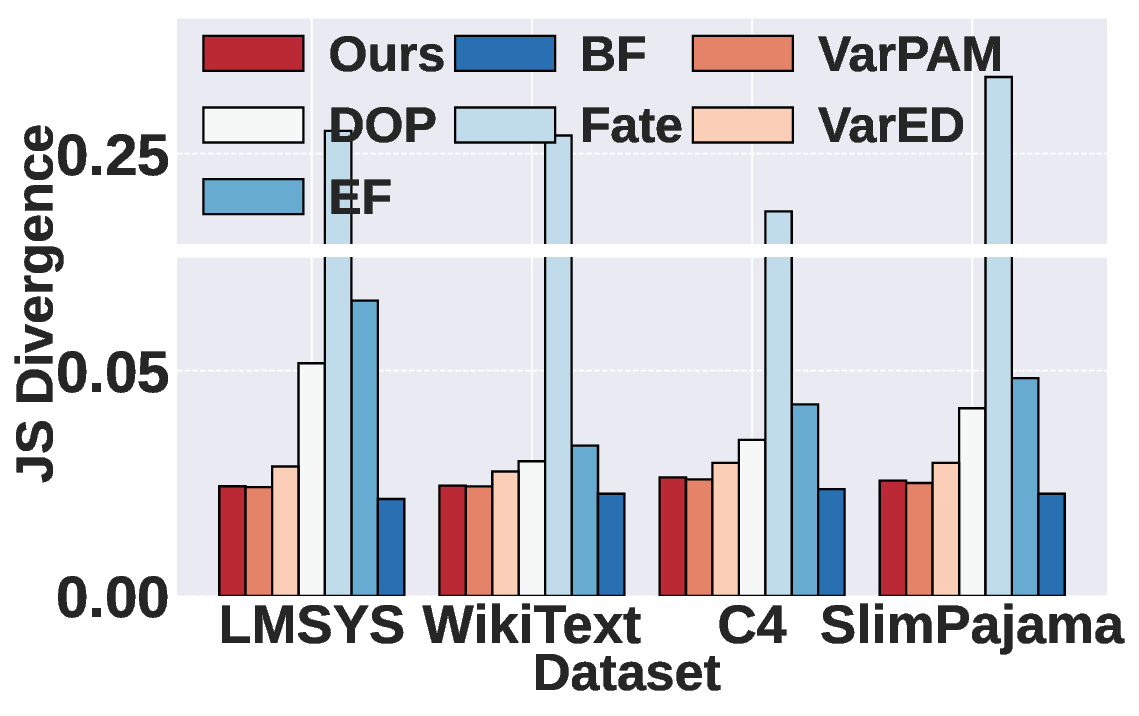
Mixture-of-Experts (MoE) has become a dominant architecture in large language models (LLMs) due to its ability to scale model capacity via sparse expert activation. Meanwhile, serverless computing, with its elasticity and pay-per-use billing, is well-suited for deploying MoEs with bursty workloads. However, the large number of experts in MoE models incurs high inference costs due to memory-intensive parameter caching. These costs are difficult to mitigate via simple model partitioning due to input-dependent expert activation. To address these issues, we propose Remoe, a heterogeneous MoE inference system tailored for serverless computing. Remoe assigns non-expert modules to GPUs and expert modules to CPUs, and further offloads infrequently activated experts to separate serverless functions to reduce memory overhead and enable parallel execution. We incorporate three key techniques: (1) a Similar Prompts Searching (SPS) algorithm to predict expert activation patterns based on semantic similarity of inputs; (2) a Main Model Pre-allocation (MMP) algorithm to ensure service-level objectives (SLOs) via worst-case memory estimation; and (3) a joint memory and replica optimization framework leveraging Lagrangian duality and the Longest Processing Time (LPT) algorithm. We implement Remoe on Kubernetes and evaluate it across multiple LLM benchmarks. Experimental results show that Remoe reduces inference cost by up to 57% and cold start latency by 47% compared to state-of-the-art baselines.
💡 Deep Analysis
📄 Full Content
Remoe: Towards Efficient and Low-Cost MoE
Inference in Serverless Computing
Wentao Liu˚, Yuhao Hu˚, Ruiting Zhou˚, Baochun Li:, Ne Wang;
˚School of Computer Science and Engineering, Southeast University, China
:Department of Electrical and Computer Engineering, University of Toronto, Canada
;Department of Computing, The Hong Kong Polytechnic University, Hong Kong
Email: ˚(liuwentao, yuhaohu, ruitingzhou)@seu.edu.cn, :bli@ece.toronto.edu, ;newang@polyu.edu.hk
Abstract—Mixture-of-Experts (MoE) has become a dominant
architecture in large language models (LLMs) due to its ability
to scale model capacity via sparse expert activation. Meanwhile,
serverless computing, with its elasticity and pay-per-use billing, is
well-suited for deploying MoEs with bursty workloads. However,
the large number of experts in MoE models incurs high inference
costs due to memory-intensive parameter caching. These costs are
difficult to mitigate via simple model partitioning due to input-
dependent expert activation. To address these issues, we propose
Remoe, a heterogeneous MoE inference system tailored for
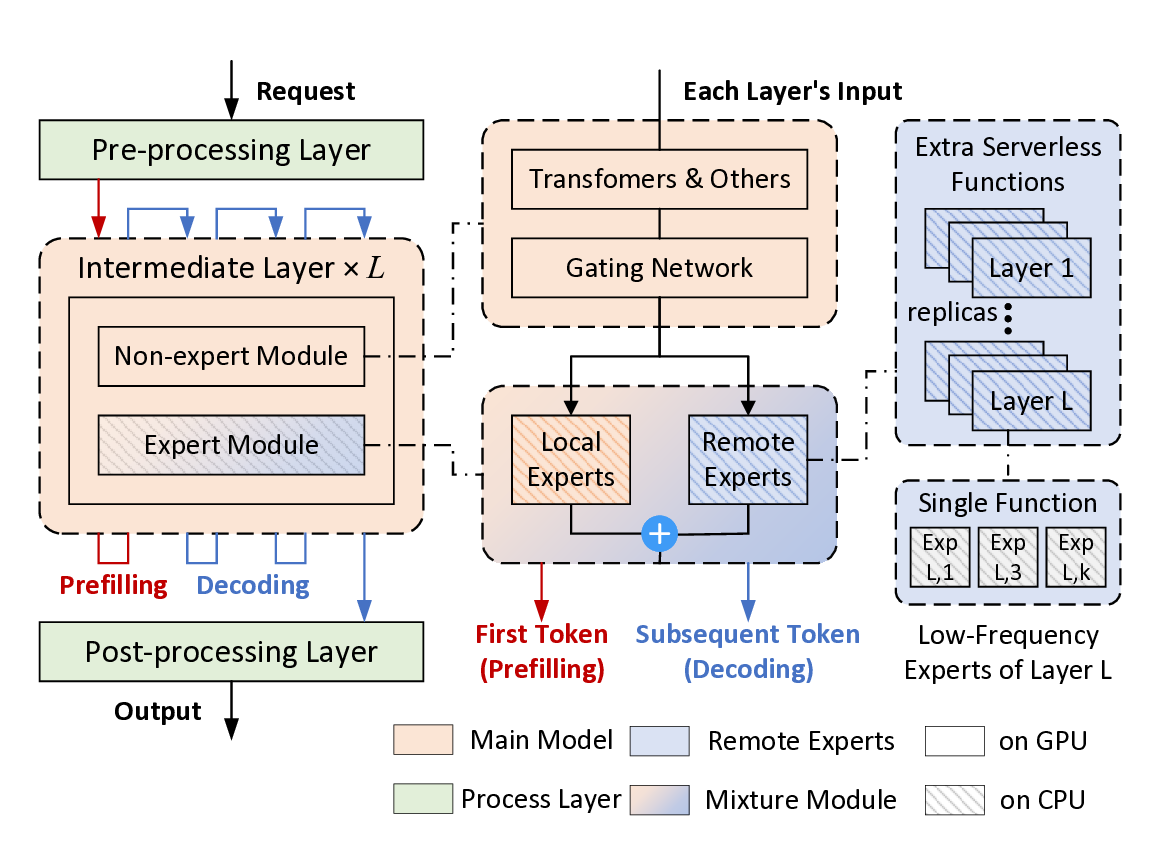
serverless computing. Remoe assigns non-expert modules to GPUs
and expert modules to CPUs, and further offloads infrequently
activated experts to separate serverless functions to reduce
memory overhead and enable parallel execution. We incorporate
three key techniques: (1) a Similar Prompts Searching (SPS)
algorithm to predict expert activation patterns based on semantic
similarity of inputs; (2) a Main Model Pre-allocation (MMP)
algorithm to ensure service-level objectives (SLOs) via worst-
case memory estimation; and (3) a joint memory and replica
optimization framework leveraging Lagrangian duality and the
Longest Processing Time (LPT) algorithm. We implement Remoe
on Kubernetes and evaluate it across multiple LLM benchmarks.
Experimental results show that Remoe reduces inference cost by
up to 57% and cold start latency by 47% compared to state-of-
the-art baselines.
I. INTRODUCTION
The rise of large language models (LLMs) has ushered
in a new era of deep learning applications, enabling capa-
bilities such as advanced text generation and context-aware
understanding [1], [2]. Among recent LLM architectures, the
Mixture-of-Experts (MoE) model has emerged as a promising
solution to scale model capacity without proportionally in-
creasing inference computation. The foundational MoE archi-
tecture replaces a transformer’s standard feed-forward network
(FFN) with multiple expert FFNs and a gating network for
token-to-expert routing [3]. This approach allows for building
vastly larger and more capable models, as only a fraction
of the model’s total parameters (experts) are used for any
given inference task. Meanwhile, serverless computing has
gained traction as a cost-effective deployment paradigm for
machine learning (ML) inference [4], owing to its elasticity,
fine-grained billing, and simplified resource management [5].
Corresponding author: Ruiting Zhou (email: ruitingzhou@seu.edu.cn).
These features make it particularly attractive for LLM infer-
ence workloads that exhibit bursty traffic [6].
However, the convergence of MoE models and serverless
platforms is far from straightforward. Pricing for serverless
computing is the product of the resources allocated to a
function and its execution duration. While MoE’s sparse
expert activation is efficient, its vast number of experts intro-
duces unique challenges under the serverless pricing model.
The primary challenge stems from the massive memory
requirement of MoE models. Deploying the full model as a
single serverless function typically requires loading all experts
into memory, even if most are unused. This results in signifi-
cant memory waste and high costs during inference, especially
when expensive GPU memory is involved. To address the
high memory occupation of MoE models, expert offloading
has been widely studied [7]–[10], where most experts are
cached on slower CPU memory, and only the predicted
active experts are dynamically transferred to the GPU for
inference. Existing offloading methods such as fMoE [7] and
HOBBIT [10] implement dynamic expert swapping between
the CPU and GPU through experts prefetching techniques.
These approaches, however, still require a large, continuously
provisioned memory pool on the CPU to hold the inactive
experts. This persistent memory allocation fails to eliminate
cost inefficiencies thus making existing solutions suboptimal
for serverless MoE inference.
To mitigate the high memory costs, distributing experts
across multiple serverless functions is a natural strategy.
Unfortunately, this approach is complicated by the unbalanced
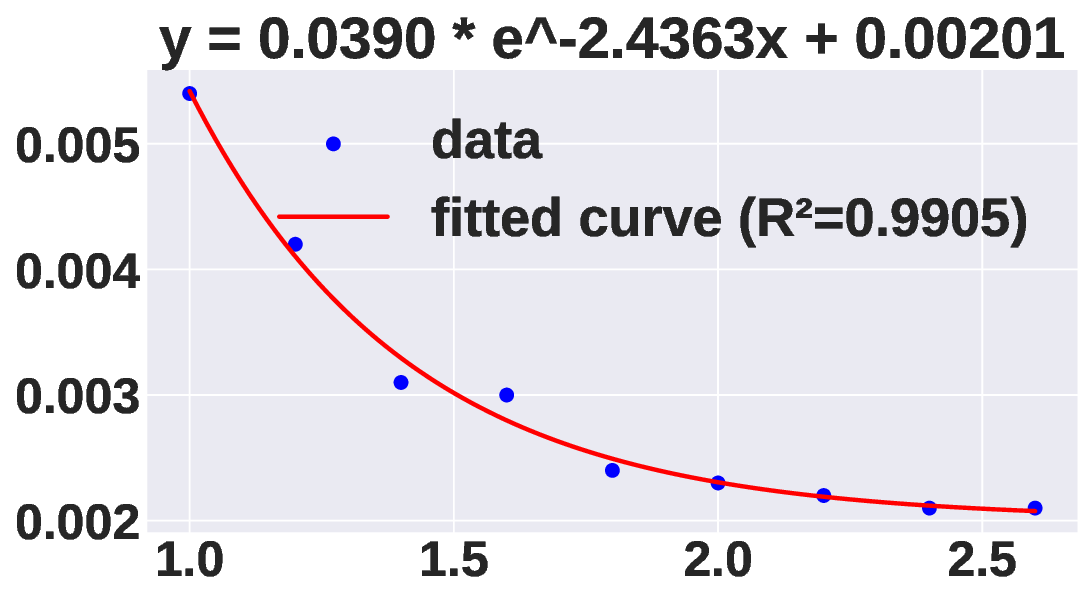
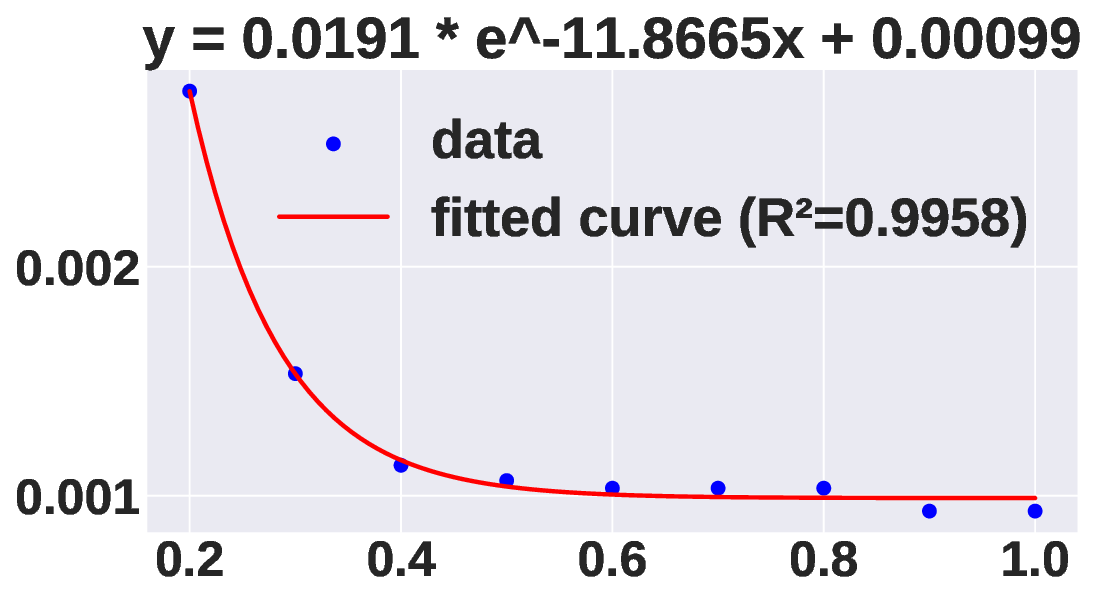
and unpredictable nature of expert activation in MoE. In MoE
inference, the activated experts depend heavily on the input
prompt and vary across requests. Several studies [7], [9],
[11] have shown that for a single prompt, expert activation
frequencies vary significantly, and this specialized pattern is
difficult to pr