SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
Reading time: 5 minute
...
📝 Original Info
Title: SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
ArXiv ID: 2512.18470
Date: 2025-12-20
Authors: Minh V. T. Thai, Tue Le, Dung Nguyen Manh, Huy Phan Nhat, Nghi D. Q. Bui
📝 Abstract
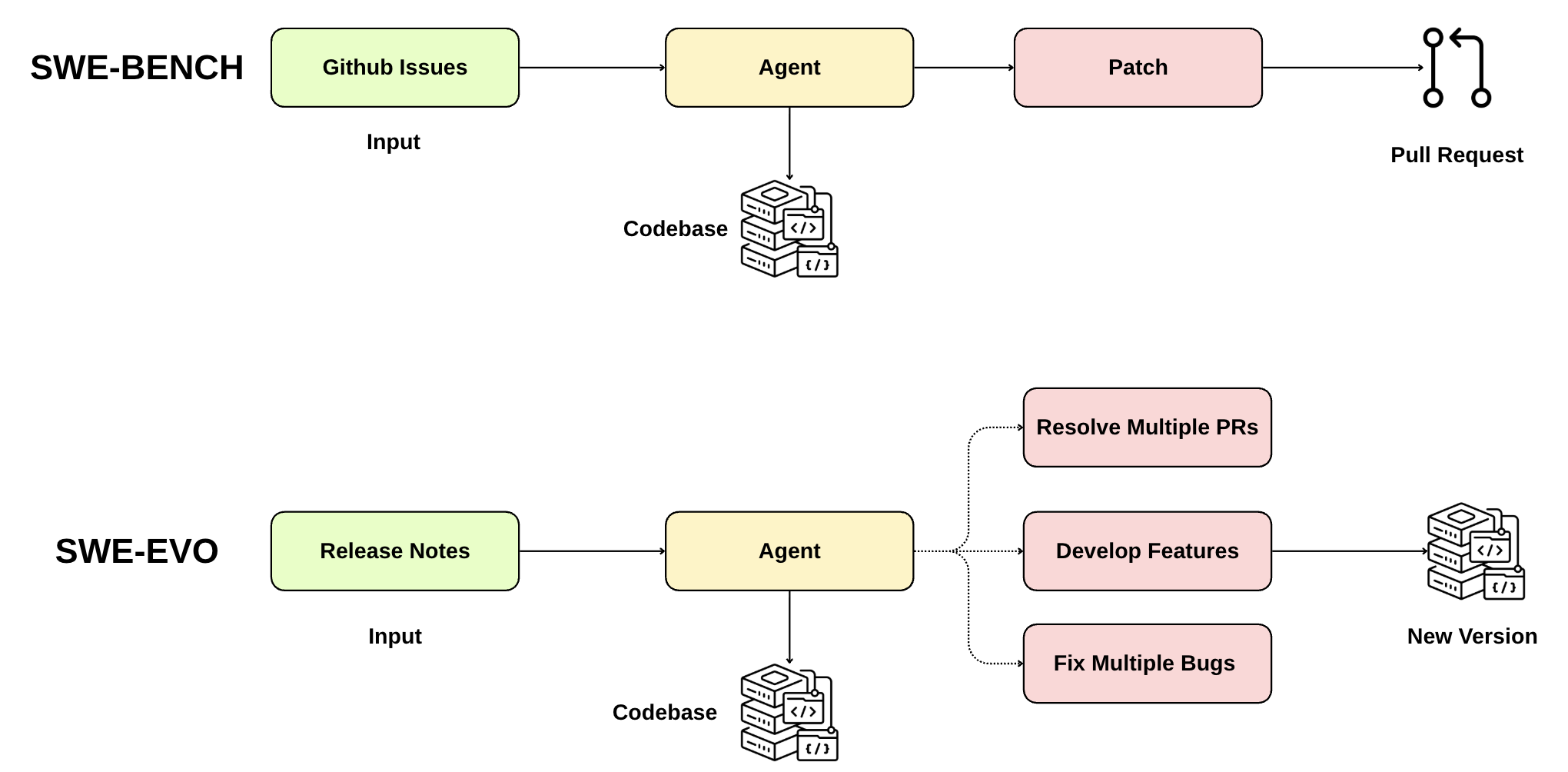
Existing benchmarks for AI coding agents focus on isolated, single-issue tasks such as fixing a bug or implementing a small feature. However, real-world software engineering is fundamentally a long-horizon endeavor: developers must interpret high-level requirements, plan coordinated changes across many files, and evolve codebases over multiple iterations while preserving existing functionality. We introduce SWE-EVO, a benchmark that evaluates agents on this long-horizon software evolution challenge. Constructed from release notes and version histories of seven mature open-source Python projects, SWE-EVO comprises 48 evolution tasks that require agents to implement multi-step modifications spanning an average of 21 files, validated against comprehensive test suites averaging 874 tests per instance. Experiments with state-of-the-art models reveal a striking capability gap: even GPT-5 with OpenHands achieves only a 21 percent resolution rate on SWE-EVO, compared to 65 percent on the single-issue SWE-Bench Verified. This demonstrates that current agents struggle with sustained, multi-file reasoning. We also propose Fix Rate, a fine-grained metric that captures partial progress toward solving these complex, long-horizon tasks.
💡 Deep Analysis
📄 Full Content
2026-1-27
SWE-EVO: Benchmarking Coding Agents in
Long-Horizon Software Evolution Scenarios
Minh Vu Thai Pham*1, Tue Le*1, Dung Nguyen Manh2, Huy Nhat Phan1 and Nghi D. Q. Bui†1
1FPT Software AI Center, 2School of Computing and Information Systems - University of Melbourne
Existing benchmarks for AI coding agents focus on isolated, single-issue tasks such as fixing a bug
or adding a small feature. However, real-world software engineering is a long-horizon endeavor:
developers interpret high-level requirements, coordinate changes across many files, and evolve
codebases over multiple iterations while preserving functionality. We introduce SWE-EVO, a
benchmark for this long-horizon software evolution challenge. Constructed from release notes of
seven mature open-source Python projects, SWE-EVO comprises 48 tasks requiring multi-step
modifications spanning an average of 21 files, validated against test suites averaging 874 tests
per instance. Experiments reveal a striking capability gap: GPT-5 with OpenHands achieves only
21% on SWE-EVO versus 65% on SWE-Bench Verified, showing that current agents struggle with
sustained, multi-file reasoning. We also propose Fix Rate, a metric capturing partial progress on
these complex, long-horizon tasks.
§ https://github.com/SWE-EVO/SWE-EVO
1. Introduction
Large language models (LLMs) have achieved remarkable progress in automating software engineering
(SE) tasks, including code generation (Bui et al., 2023; Chen et al., 2021a; Li et al., 2022; Manh et al.,
2023; To et al., 2023; Wang et al., 2023; Wei et al., 2023; Zhuo et al., 2024), bug fixing (Jimenez
et al., 2023; Xia et al., 2024), and test synthesis (Chen et al., 2022; Jain et al., 2024; Wang et al.,
2024b). These advancements have facilitated the emergence of AI-powered coding agents capable of
assisting or automating key aspects of the software development lifecycle (Fan et al., 2023; Gao et al.,
2025; He et al., 2025; Zhang et al., 2023).
Building on these capabilities, multi-agent systems, where specialized agents collaborate on subtasks
such as repository navigation, bug localization, patch generation, and verification, have evolved
rapidly to address long-horizon challenges in SE, outpacing single-agent architectures in scalability
and performance as of 2025. Recent agent-based frameworks (Nguyen et al., 2025b; Phan et al.,
2024; Wang et al., 2024d; Yang et al., 2024a) exemplify this trend, enabling autonomous handling of
complex workflows in real-world repositories. According to (DORA Research Program, 2025), industry
adoption underscores this momentum: over 90% of engineering teams now integrate generative AI
into SE practices, a sharp rise from 61% in 2024, driven by the need for efficient tools in maintaining
vast legacy systems.
To evaluate these agents rigorously, benchmarks have become essential. Early efforts like Hu-
manEval (Chen et al., 2021b) focused on function-level code completion (Chen et al., 2021a),
*Equal contribution
†Project lead
Correspondence to: Minh Vu Thai Pham , Tue Le ,
Dung Nguyen Manh , Huy Nhat Phan ,
Nghi D. Q. Bui .
arXiv:2512.18470v4 [cs.SE] 26 Jan 2026
SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
while SWE-Bench (Jimenez et al., 2023) marked a shift by curating real-world GitHub issues, tasking
agents with generating verifiable patches for isolated problems (Jimenez et al., 2023). SWE-Bench
has gained prominence as a de facto standard for assessing multi-agent capabilities in practical coding
scenarios.
However, as state-of-the-art (SOTA) models and agents advance (Jimenez et al., 2024), achieving
scores up to 75% on variants like SWE-Bench-Verified (e.g., GPT-5 (OpenAI, 2025b)) and around
40% on the full leaderboard (e.g., OpenCSG Starship at 39.67%), the benchmark is showing signs
of saturation, with diminishing marginal gains on isolated tasks. This progress, while impressive,
masks deeper limitations: SWE-Bench primarily addresses discrete issue resolution, failing to capture
the core intricacy of software development, which is the continuous evolution of existing systems
in response to high-level requirements (Kaur and Singh, 2015; Singh et al., 2019). In reality, up to
80% of software engineering efforts involve maintaining and evolving legacy codebases rather than
building new ones from scratch, entailing iterative modifications across interdependent modules,
versions, and specifications (Kaur and Singh, 2015; Singh et al., 2019).
This gap between benchmark tasks and real-world evolution scenarios motivates our central research
question:
Given an existing codebase, can multi-agent LLM systems autonomously evolve the system in response
to dynamic input requirements, demonstrating sustained planning, adaptability, and innovation
across long-horizon tasks?
Figure 1 illustrates this high-level setting: software evolution as a