Tokenization is a critical preprocessing step for large language models (LLMs), directly impacting training efficiency and downstream performance. General-purpose tokenizers trained predominantly on English and Latin-script languages exhibit suboptimal performance on morphologically rich languages such as Arabic, resulting in inflated token sequences and reduced compression efficiency. In this work, we present AraToken, an Arabic-optimized tokenizer built on SentencePiece Unigram algorithm with a comprehensive normalization pipeline addressing Arabic-specific orthographic variations including Alif variants, diacritics, and Arabic-Indic numerals. We systematically compare BPE, WordPiece, and SentencePiece algorithms across multiple configurations, demonstrating that SentencePiece with normalization achieves 18% lower fertility (1.199 vs 1.35 tokens/word) compared to unnormalized baselines. Furthermore, we introduce the Language Extension Pipeline (LEP), a method for integrating the optimized tokenizer into Qwen3-0.6B through vocabulary extension with mean subtoken initialization and selective transformer layer unfreezing. Our experiments show that LEP reduces evaluation loss from 8.28 to 2.43 within 800 training steps on 100K Arabic samples. We release our tokenizer, training scripts, and model checkpoints to facilitate Arabic NLP research.
Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks [1,16,17]. However, the effectiveness of these models is fundamentally constrained by their tokenization strategy. Tokenizers trained on predominantly English corpora often exhibit poor compression efficiency for non-Latin scripts and morphologically rich languages [12,11].
Arabic presents unique challenges for tokenization due to several linguistic characteristics. First, Arabic is a highly inflected language where words carry extensive morphological information through prefixes, suffixes, and infixes [4]. Second, Arabic orthography exhibits significant variability, particularly in the representation of Alif variants ([Hamzaabove], [Hamza-below], [Madda], [Alif]) and the optional nature of diacritical marks (harakat). Third, Arabic text frequently contains Arabic-Indic numerals and specialized punctuation that require explicit normalization.
These challenges result in general-purpose tokenizers producing excessively fragmented token sequences for Arabic text, leading to: (1) increased computational costs during training and inference, (2) reduced effective context length, and (3) potential degradation in model performance on Arabic tasks.
In this paper, we address these challenges through a two-pronged approach:
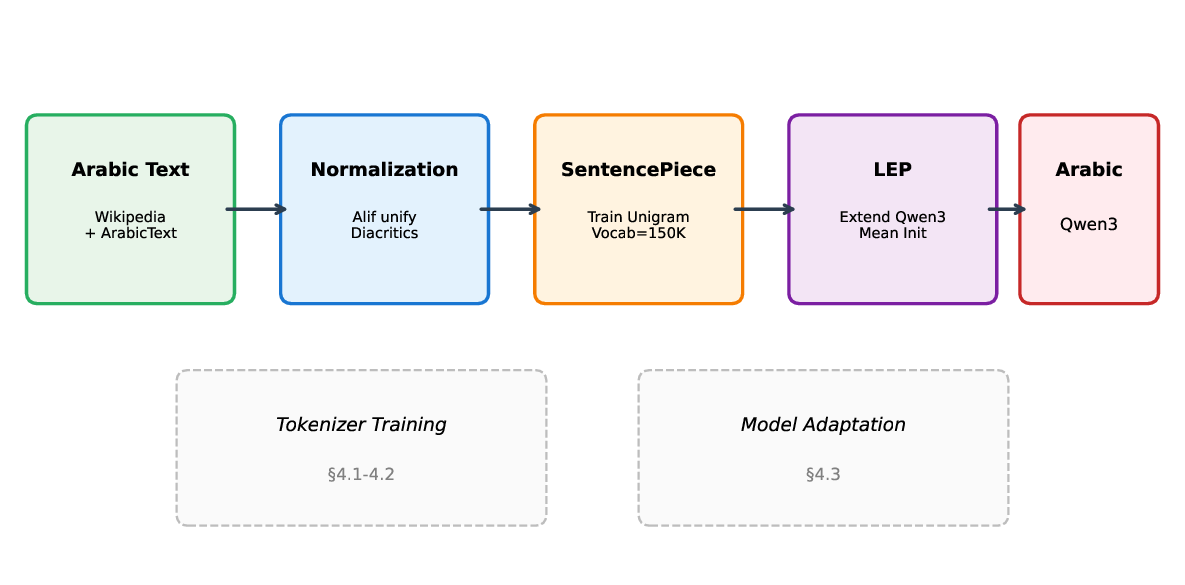
• Arabic-Optimized Tokenizer: We develop AraToken, a SentencePiece Unigram tokenizer trained on Arabic corpora with a comprehensive normalization pipeline that unifies orthographic variations and removes optional diacritics.
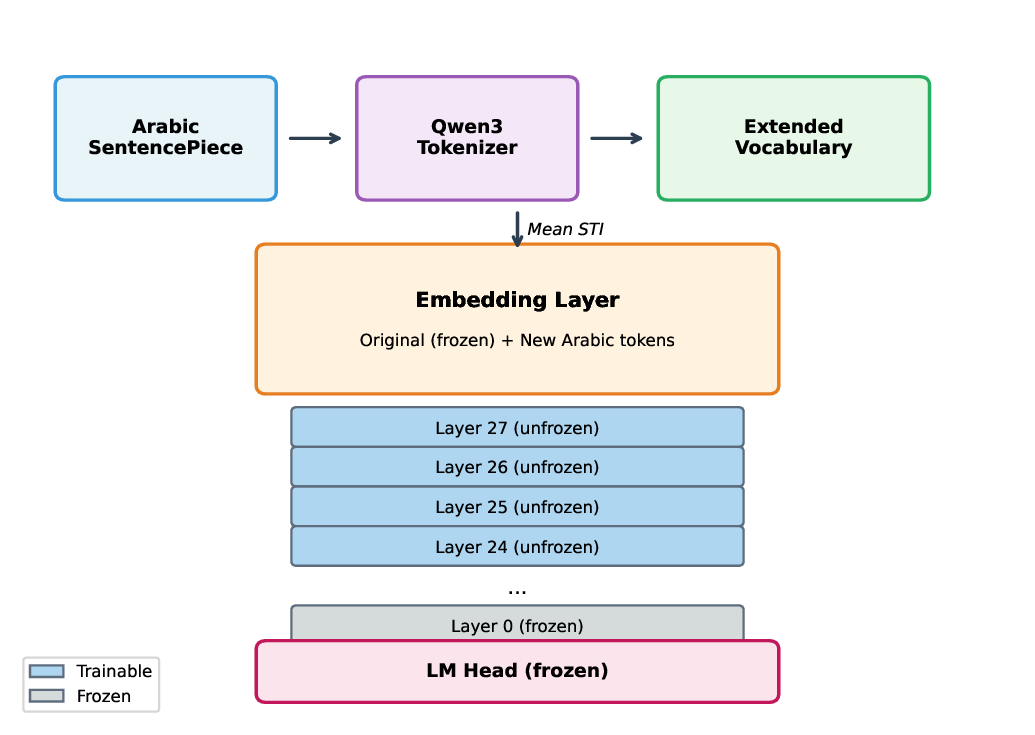
• Language Extension Pipeline (LEP): We propose a method for integrating the optimized tokenizer into existing LLMs (specifically Qwen3) through vocabulary extension, mean subtoken initialization, and selective layer unfreezing.
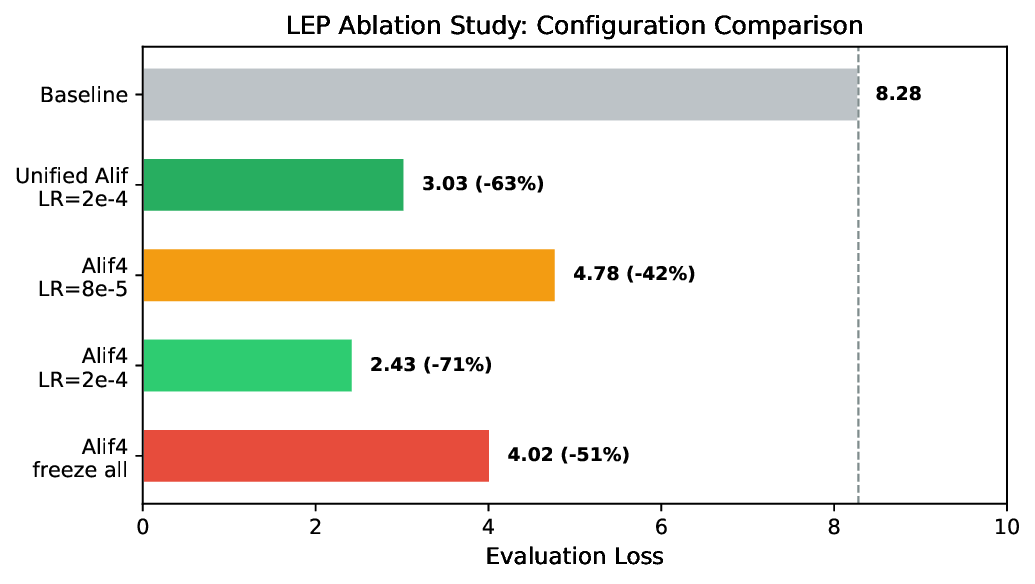
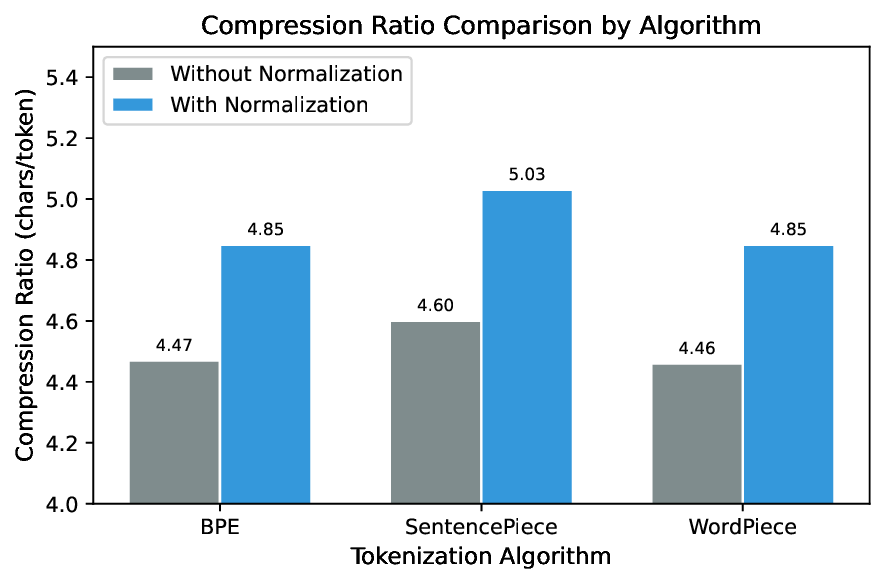
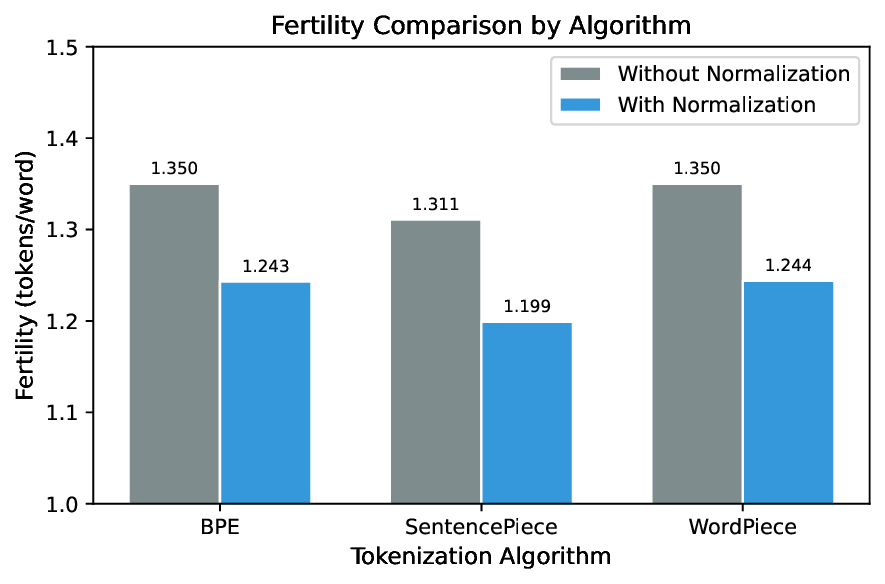
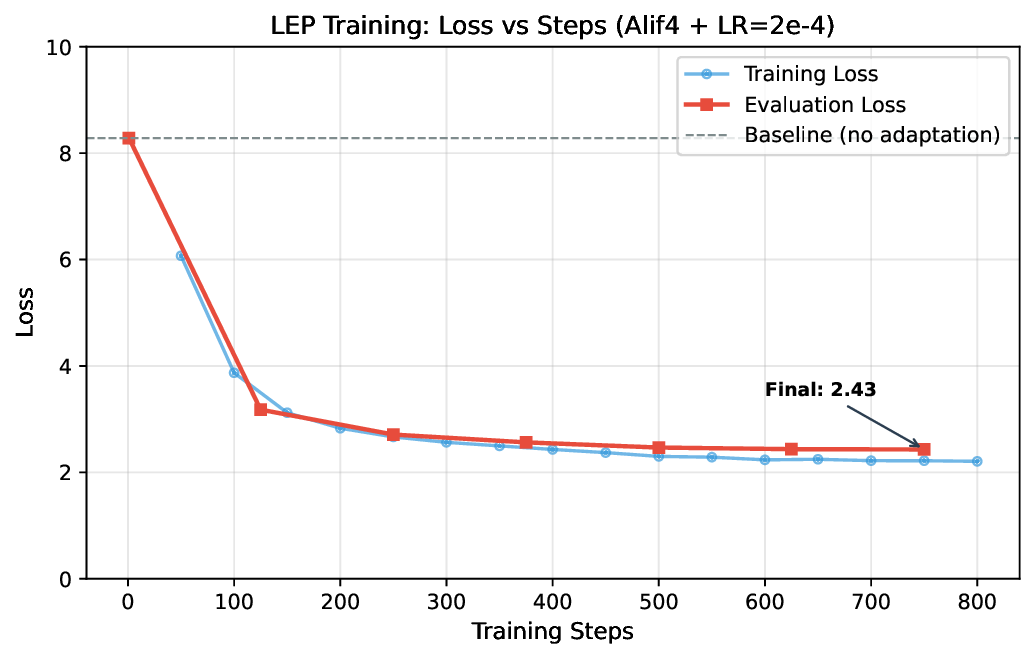
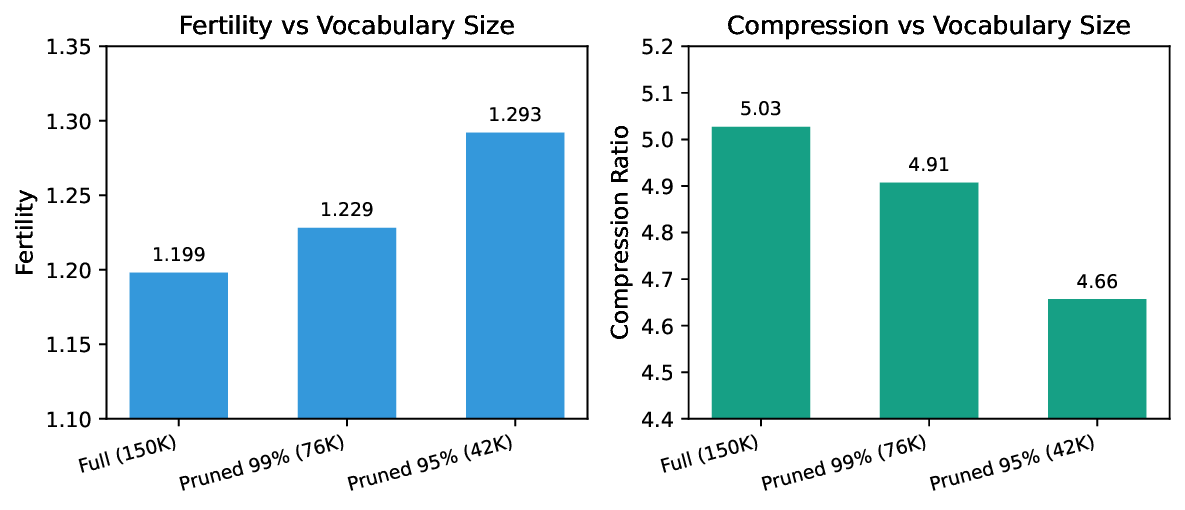
Our experiments demonstrate that the normalized SentencePiece tokenizer achieves a fertility of 1.199 tokens per word, representing an 18% improvement over unnormalized baselines. When integrated into Qwen3-0.6B via LEP, the model achieves an evaluation loss of 2.43 after only 800 training steps, compared to 8.28 without adaptation.
Figure 1 illustrates our overall approach, combining tokenizer training with model adaptation through LEP.
The remainder of this paper is organized as follows: Section 2 reviews related work on tokenization and language adaptation. Section 3 describes our normalization pipeline, tokenizer training, and LEP architecture. Section 4 presents our experimental setup, and Section 5 discusses the results. We conclude in Section 7 with limitations and future directions.
Modern LLMs predominantly employ subword tokenization to balance vocabulary size with coverage. Byte Pair Encoding (BPE) [15] iteratively merges the most frequent character pairs to construct a vocabulary. WordPiece [13] uses a likelihood-based criterion for merge decisions, while the Unigram algorithm [6] learns a probabilistic language model over subword sequences using the EM algorithm.
SentencePiece [7] provides a language-agnostic implementation supporting both BPE and Unigram algorithms, operating directly on raw text without pre-tokenization. This is particularly advantageous for languages like Arabic that do not use whitespace consistently.
Arabic NLP has received significant attention due to the language’s morphological complexity and dialectal variation [2]. CAMeL Tools [10] provides comprehensive utilities for Arabic preprocessing including morphological analysis and normalization. AraBART [5] and AraT5 [9] are pretrained transformer models specifically designed for Arabic, employing custom tokenization strategies.
Normalization is a critical preprocessing step for Arabic text [4]. Common normalization operations include Alif unification (collapsing [Hamza-above], [Hamza-below], [Madda] to [Alif]), Hamza normalization, Ta Marbuta/Ha unification, and diacritic removal. The optimal normalization strategy depends on the downstream task, with some applications benefiting from preserved orthographic distinctions.
Extending pretrained LLMs to new languages has been explored through several approaches. BLOOM+1 [18] investigates language adaptation strategies including continued pretraining and adapter-based methods, finding that adapters outperform continued pretraining for larger models. LLaMA Beyond English [19] studies vocabulary extension for Chinese, demonstrating that effective transfer can be achieved with less than 1% of the original pretraining data. WECHSEL [8] proposes cross-lingual embedding initialization for vocabulary extension, while FOCUS [3] introduces a method for initializing new token embeddings based on semantic similarity. Our work builds on these approaches by combining vocabulary extension with selective layer unfreezing for Arabic adaptation.
We implement a comprehensive Arabic normalization pipeline designed to reduce orthographic variability while preserving semantic content. The pipeline is inte
This content is AI-processed based on open access ArXiv data.