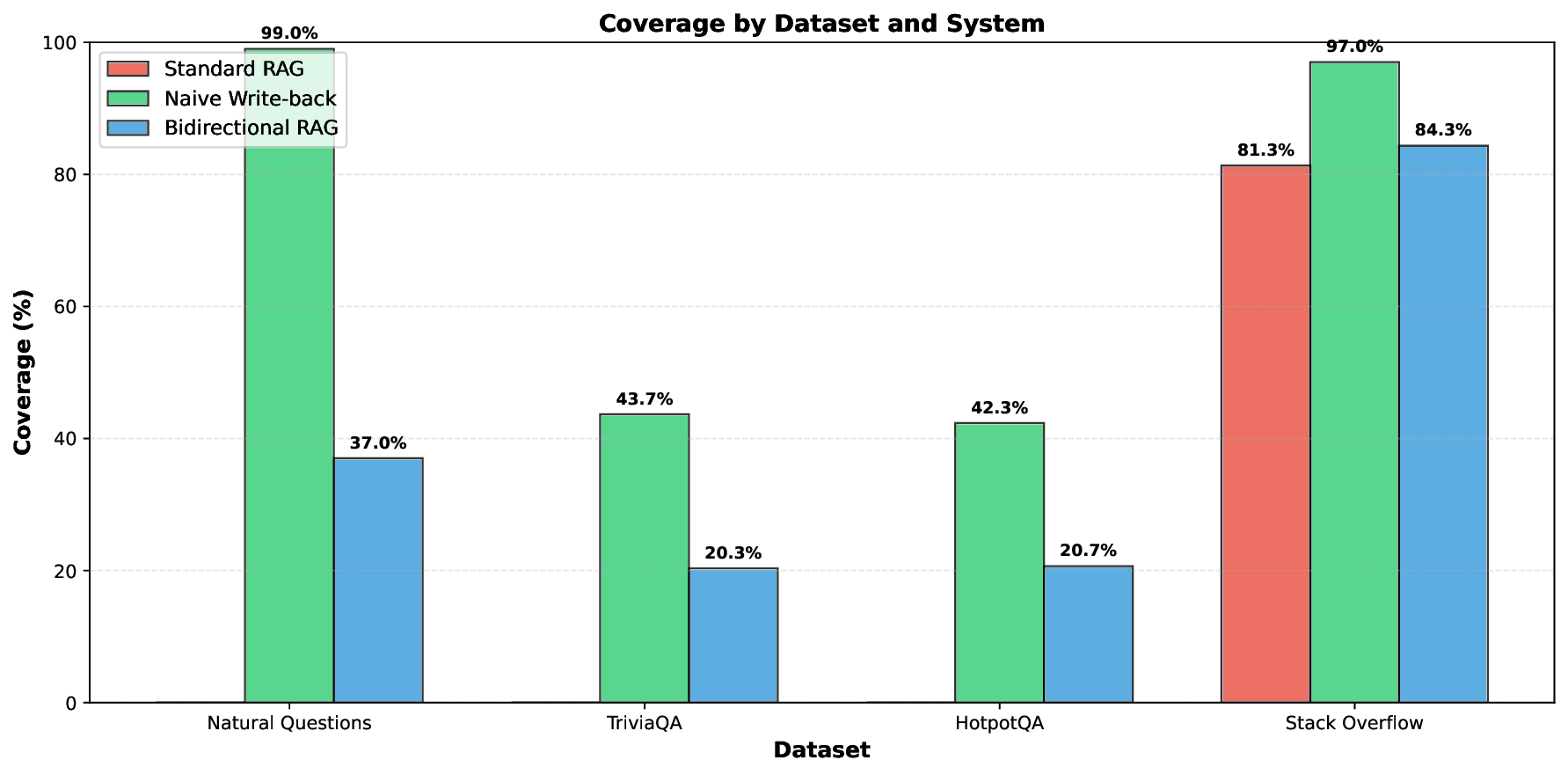
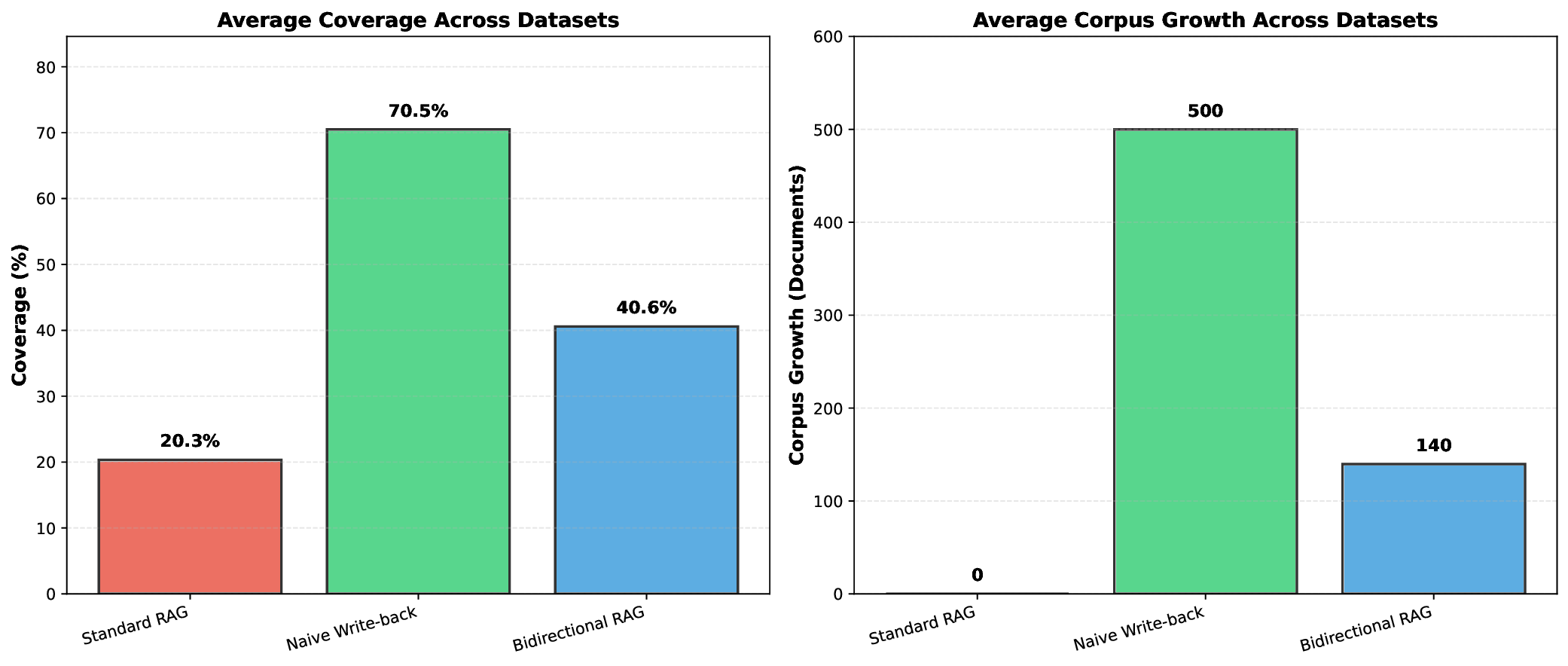
Retrieval-Augmented Generation RAG systems enhance large language models by grounding responses in external knowledge bases, but conventional RAG architectures operate with static corpora that cannot evolve from user interactions. We introduce Bidirectional RAG, a novel RAG architecture that enables safe corpus expansion through validated write back of high quality generated responses. Our system employs a multi stage acceptance layer combining grounding verification (NLI based entailment, attribution checking, and novelty detection to prevent hallucination pollution while enabling knowledge accumulation. Across four datasets Natural Questions, TriviaQA, HotpotQA, Stack Overflow with three random seeds 12 experiments per system, Bidirectional RAG achieves 40.58% average coverage nearly doubling Standard RAG 20.33% while adding 72% fewer documents than naive write back 140 vs 500. Our work demonstrates that self improving RAG is feasible and safe when governed by rigorous validation, offering a practical path toward RAG systems that learn from deployment.
Large language models (LLMs) demonstrate remarkable capabilities but suffer from well-known limitations: knowledge cutoffs freeze understanding at training time, domain-specific information remains incomplete, and hallucinations produce plausible but factually incorrect statements [1]. Retrieval-Augmented Generation (RAG) addresses these issues by augmenting model inputs with relevant passages from external corpora, enabling grounded responses without model retraining [2].
Despite widespread adoption, conventional RAG architectures exhibit a fundamental asymmetry: they operate as readonly systems. The retrieval corpus is populated once through document ingestion, after which the model solely consumes from this fixed knowledge base. This design overlooks a critical opportunity-over extended deployment, language models generate numerous high-quality responses (clarifications, summaries, syntheses) that often surpass the informativeness of original corpus chunks. These valuable knowledge artifacts are discarded after generation rather than preserved for future retrieval.
We introduce Bidirectional RAG, a novel RAG architecture that enables controlled write-back of validated model outputs to the retrieval corpus. The central challenge is safety: naively storing all outputs would rapidly pollute the corpus with hallucinations, creating a self-reinforcing degradation cycle. We address this through a multi-stage acceptance layer that validates responses against strict criteria for factual grounding, source attribution, and novelty before corpus insertion.
Our contributions are: 1) Novel architecture for safe corpus expansion through validated write-back 2) Multi-stage validation combining grounding (NLI), attribution, and novelty checks 3) Experience store for meta-learning from both accepted and rejected responses 4) Comprehensive evaluation across 4 datasets showing 2× coverage improvement with 72% less corpus growth than naive write-back
A. Retrieval-Augmented Generation RAG was formalized by Lewis et al. [1], who demonstrated that augmenting sequence-to-sequence models with retrieved passages improves performance on knowledge-intensive tasks. Self-RAG [2] introduced reflection tokens for adaptive retrieval but maintains a static corpus. FLARE [3] uses iterative retrieval triggered by uncertainty, while CRAG [4] implements corrective retrieval when initial results are insufficient. Our work extends RAG with bidirectional information flow while remaining compatible with these advances.
Recent work addresses hallucination through various mechanisms: entailment-based verification [5], retrieval-augmented revision [6], and attribution checking [7]. We incorporate these techniques into a unified acceptance layer specifically designed for corpus write-back safety.
Our approach shares motivation with continual learning systems that update knowledge over time [8]. However, while arXiv:2512.22199v1 [cs.AI] 20 Dec 2025 continual learning typically updates model parameters, we update the retrieval corpus-enabling knowledge expansion without retraining while avoiding catastrophic forgetting through careful validation.
Let D t denote the corpus at time t, R a retrieval function, G a generative model, and Q = {q 1 , q 2 , . . .} a query stream.
Objective: Maximize retrieval coverage C t over time while maintaining safety constraints:
subject to
where H(D t ) is hallucination rate and α(D t ) is the composition ratio (fraction of model-generated content).
Bidirectional RAG extends standard RAG with a backward path:
Forward path (standard RAG):
Backward path (novel):
where A is the acceptance layer and W is the write-back operator.
The acceptance layer implements three sequential checks: 1) Grounding Verification: We use Natural Language Inference (NLI) to verify response entailment. For each sentence s in response y, we compute the maximum entailment probability against all retrieved documents:
We use a cross-encoder model (DeBERTa-v3-base [9]) and require grounding(y, X) ≥ 0.65 for acceptance.
Attribution Checking: We verify that generated citations reference actual retrieved documents:
Novelty Detection: We prevent near-duplicate insertion using semantic similarity:
We require novelty(y, D t ) ≥ 0.10.
Beyond accepted responses, we store critique logs capturing why responses were rejected. These are retrieved at query time to guide future generation away from past failure modes, providing meta-cognitive learning without corpus pollution.
We evaluate on four diverse datasets:
• Natural Questions (NQ) [10]
We compare against two fundamental baselines:
• Standard RAG: Traditional retrieve-and-generate with static corpus • Naive Write-back: Writes all responses to corpus without validation • Bidirectional RAG (Ours): Multi-stage validation with experience store Note: We focus on architectural comparisons rather than concurrent RAG methods (Self-RAG, FLARE, CRAG) as our contribution (validated write-
This content is AI-processed based on open access ArXiv data.