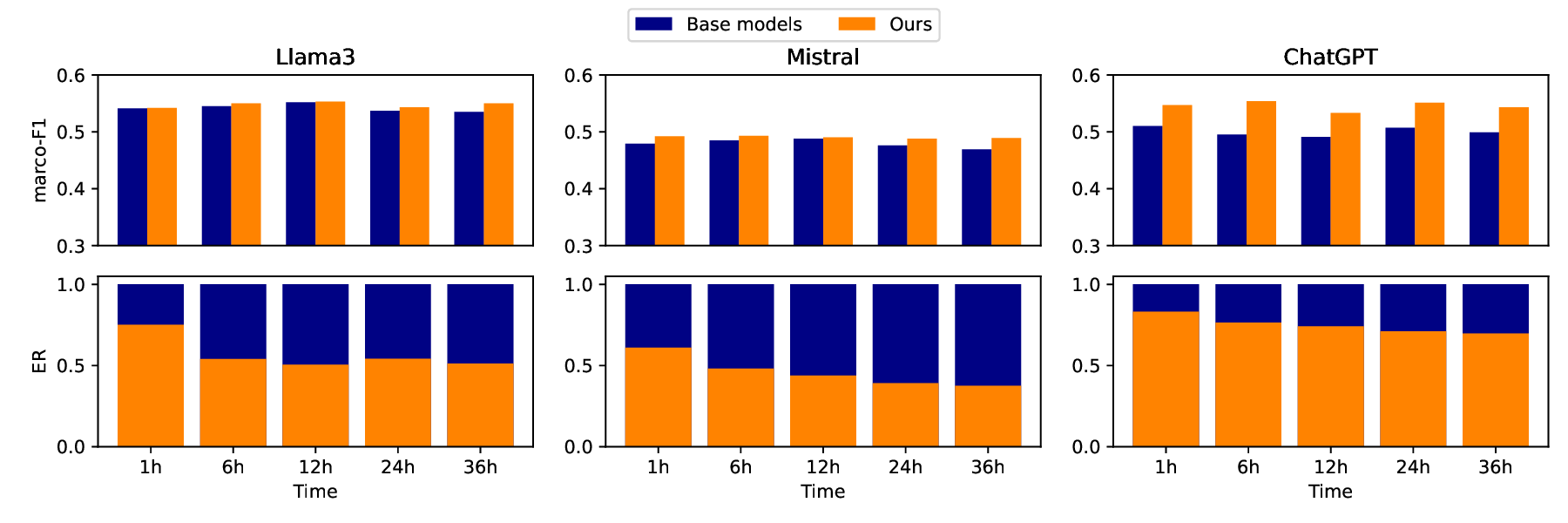
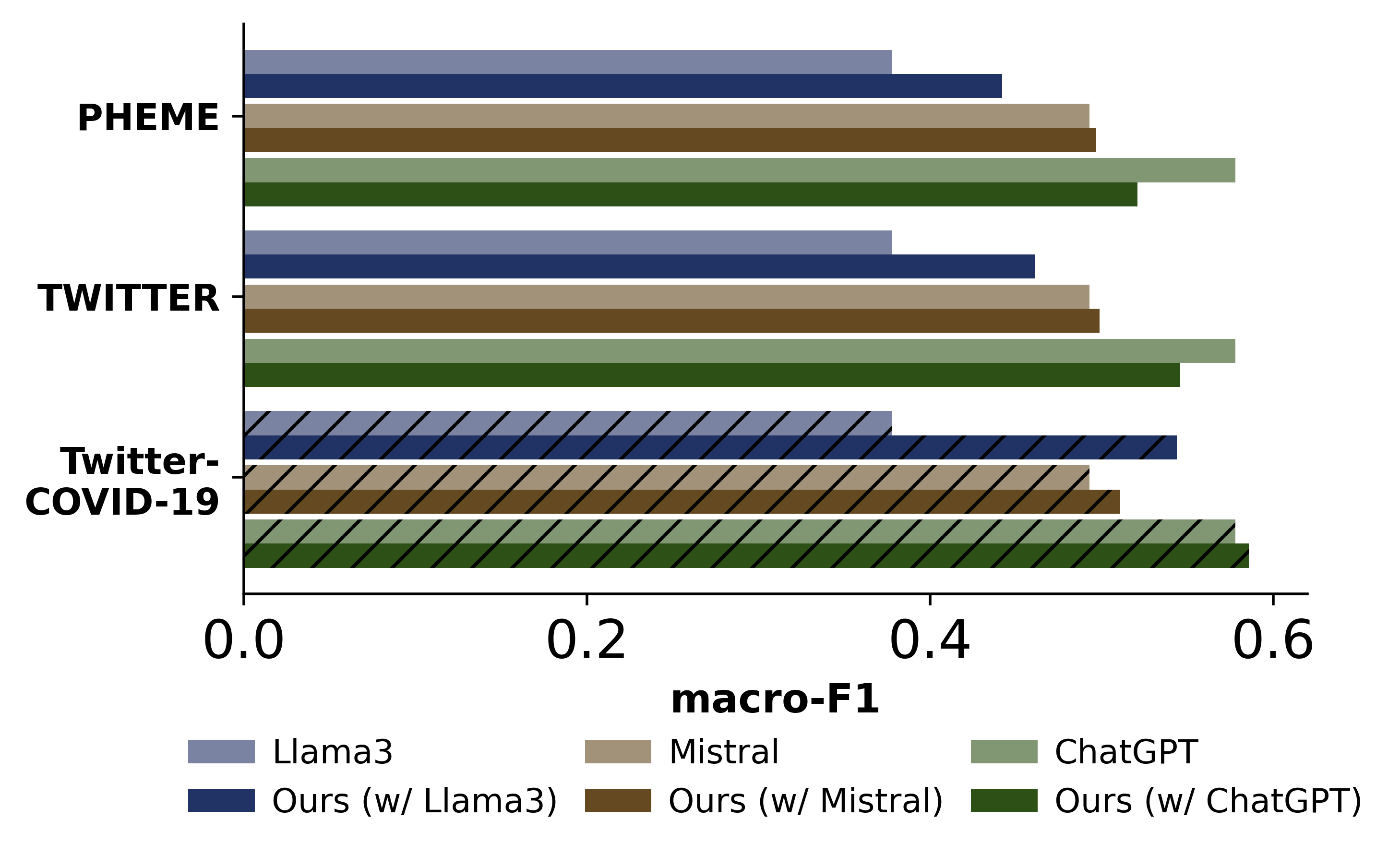
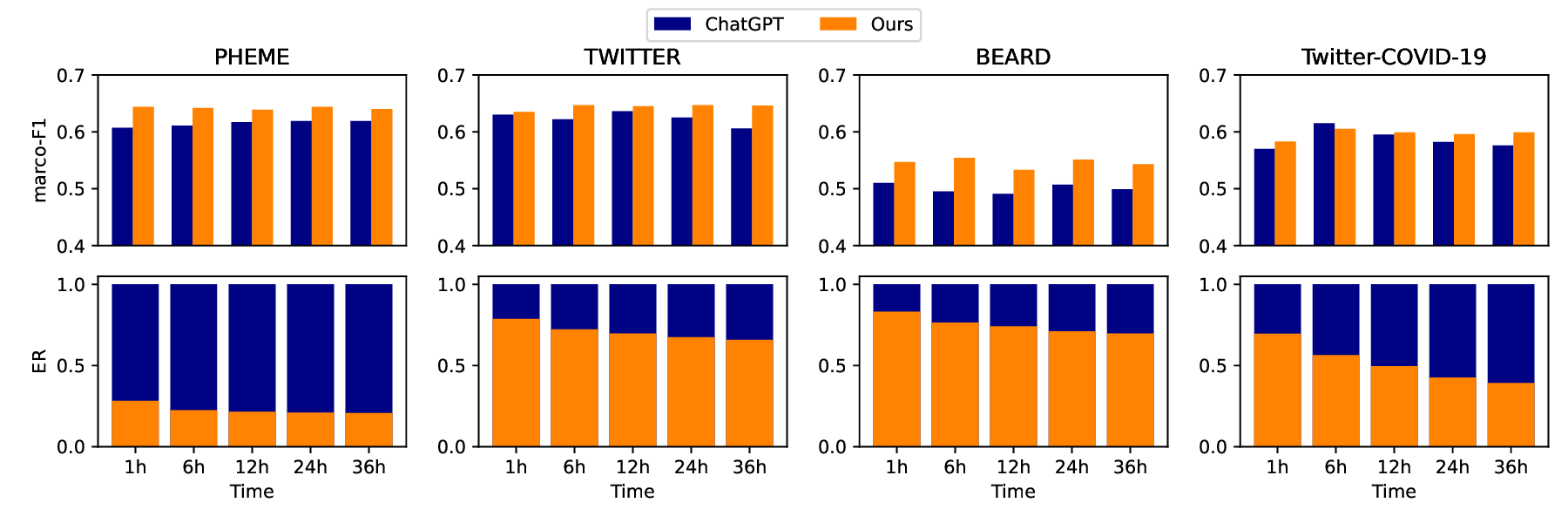
Early Rumor Detection (EARD) aims to identify the earliest point at which a claim can be accurately classified based on a sequence of social media posts. This is especially challenging in data-scarce settings. While Large Language Models (LLMs) perform well in few-shot NLP tasks, they are not well-suited for time-series data and are computationally expensive for both training and inference. In this work, we propose a novel EARD framework that combines an autonomous agent and an LLM-based detection model, where the agent acts as a reliable decision-maker for \textit{early time point determination}, while the LLM serves as a powerful \textit{rumor detector}. This approach offers the first solution for few-shot EARD, necessitating only the training of a lightweight agent and allowing the LLM to remain training-free. Extensive experiments on four real-world datasets show our approach boosts performance across LLMs and surpasses existing EARD methods in accuracy and earliness.
The spread of false rumors can have serious societal consequences, leading to widespread concerns. For example, in July 2024, a brutal knife attack occurred in Southport, UK. Within less than two hours, rumors began circulating on social media, falsely accusing the attacker of being a Muslim immigrant, sparking one of the most violent riots in UK history 2 . Despite government efforts to control the situation, the damage caused by such misinformation had already caused significant harm, highlighting the critical need for EArly Rumor Detection (EARD) approaches to ensure timely identification of rumorous claims.
EARD aims to automatically determine an early time point in a sequence of social posts related to an unverified claim, at which the prediction regarding whether that claim is a rumor shall be accurate [51]. Specifically, the model continuously monitors a stream of posts, and at each time step it must assess whether the current moment is suitable for making an accurate prediction (i.e., classifying the claim as a rumor or non-rumor) based on the observed social posts. If it determines that such a decision can be made, the model outputs its prediction and terminates further observation; otherwise, it continues monitoring the stream.
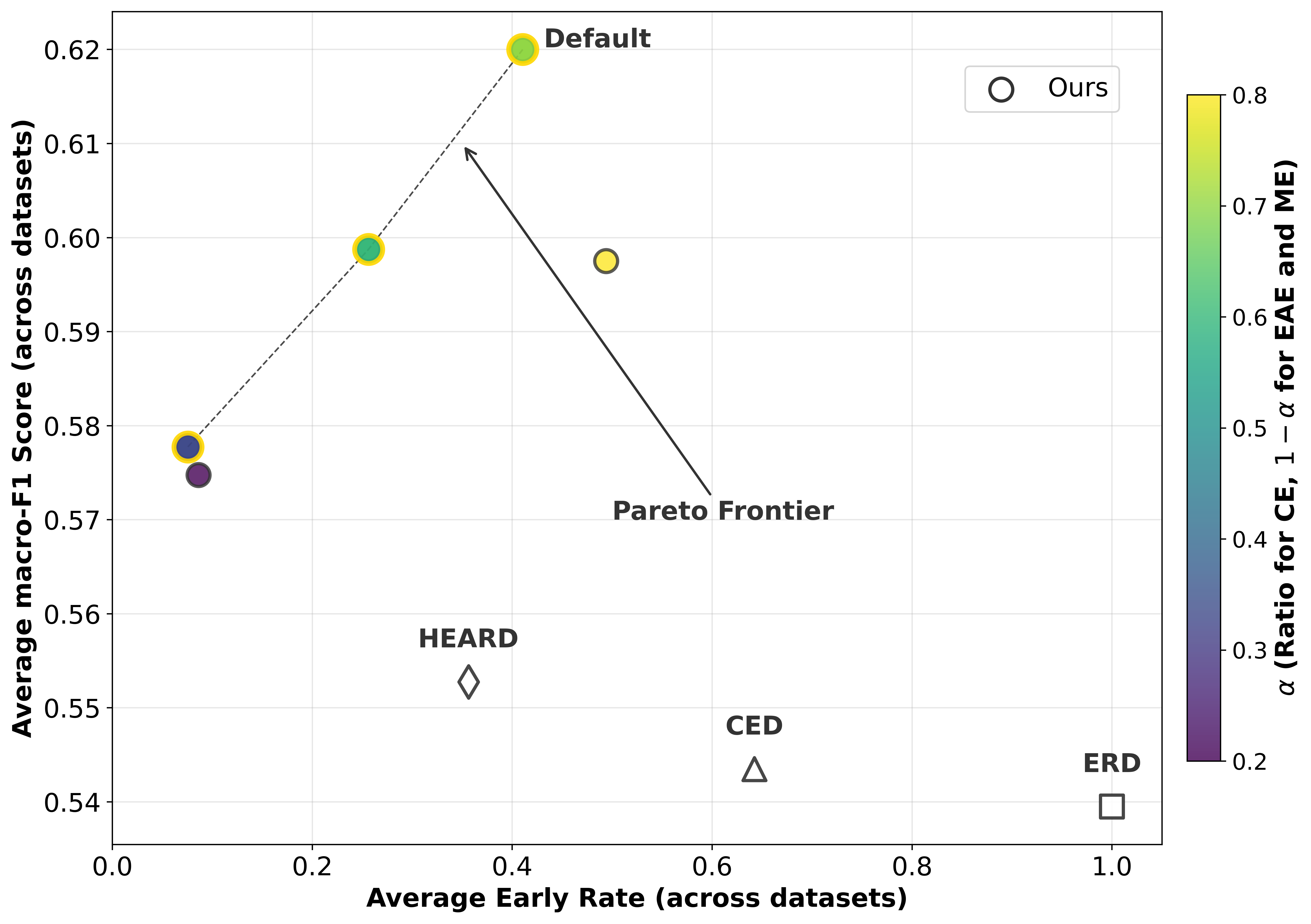
The EARD task is challenging yet has received limited attention. Existing EARD methods typically rely on recurrent neural networks (RNNs) for the rumor detection module, and the early time point prediction module often employs deep reinforcement learning [56], fixed probability thresholds [43], or the neural Hawkes Process [51]. These methods tightly couple the two modules for joint training in a recurrent manner, necessitating extensive annotated data for effective model training while lacking the flexibility to easily replace either module with a more powerful alternative.
New events on social media constantly emerge, while there could be rarely or even no annotated claims for them and each claim tends to have limited number of relevant posts available in the early stage of propagation. Meanwhile, the evolving nature of social conversations about rumorous events requires advanced text understanding capabilities for a detector. Annotating training data under such dynamics is very costly [37]. Moreover, waiting for lots of posts to accumulate before making decision (e.g., for a intervention) can inadvertently allow rumors to spread even further. This dilemma highlights the critical need for effective EARD methods in datalimited scenarios, a challenge that existing approaches struggle to address.
Recently, Large Language Models (LLMs) have demonstrated promising capabilities in understanding social media text with limited data across various tasks [5,10,19,23,36,49,54]. However, LLMs face significant limitations when applied to the EARD task, as they are not inherently well-suited for handling time series data or representing sequential dependencies of such data [46] while training LLMs for dealing with such data requires intensive resources. Additionally, in the context of EARD, the cost of inference can become prohibitively high because the model must generate predictions at every time step along the sequence of posts, with the context length increasing over time, further compounding computational overhead and latency. This raises an important question: Given the strong language understanding capabilities of LLMs, how can we efficiently and effectively utilize them for few-shot EARD?
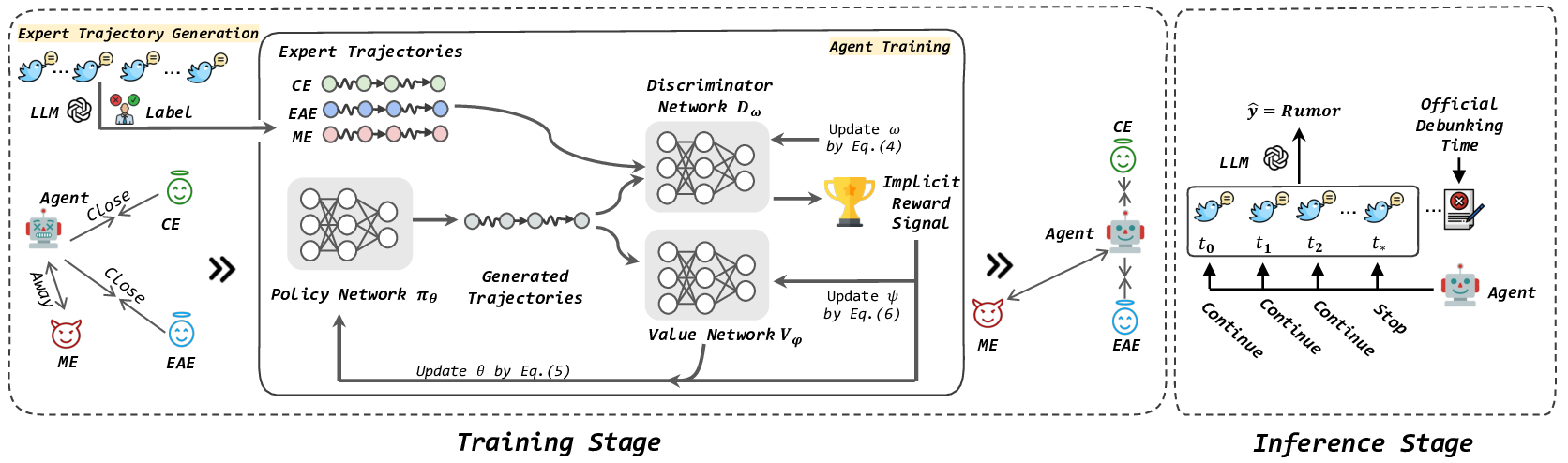
In this work, we present a novel framework for EARD in datalimited scenarios, providing an agile and cost-effective solution. Our framework consists of two components: a lightweight autonomous neural agent and an LLM. At a high level, the neural agent serves as a reliable decision-maker for determining the optimal early time point by continuously monitoring the stream of social media posts, tracking the evolution of such social conversations about a claim. Meanwhile, the LLM functions as a powerful rumor detector, analyzing the observed posts at the early time point determined by the neural agent. This framework not only leverages the LLM’s strong few-shot capabilities in text understanding but also decouples the training of the early time point prediction module from the rumor detection module. As a result, only the lightweight agent requires training, allowing the LLM to remain training-free and reducing its inference frequency to a single prediction, which can remarkably lower the demand for intensive computation.
We first model EARD as a Markov Decision Process (MDP), where the observed posts represent the state, the action involves deciding whether to trigger the LLM for rumor detection. The agent aims to maximize expected returns, reflecting its ability to make early and accurate detection. However, the expected return depends on an effective reward function that can be highly challenging to design in a complex, real-world setting [30]. In EARD, reward for determining the optimal e
This content is AI-processed based on open access ArXiv data.