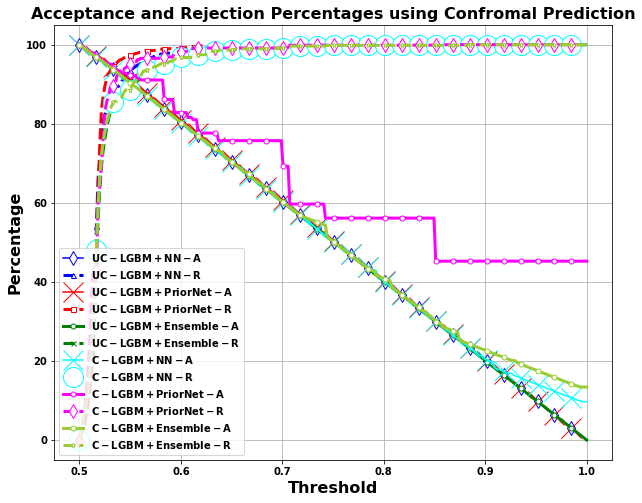
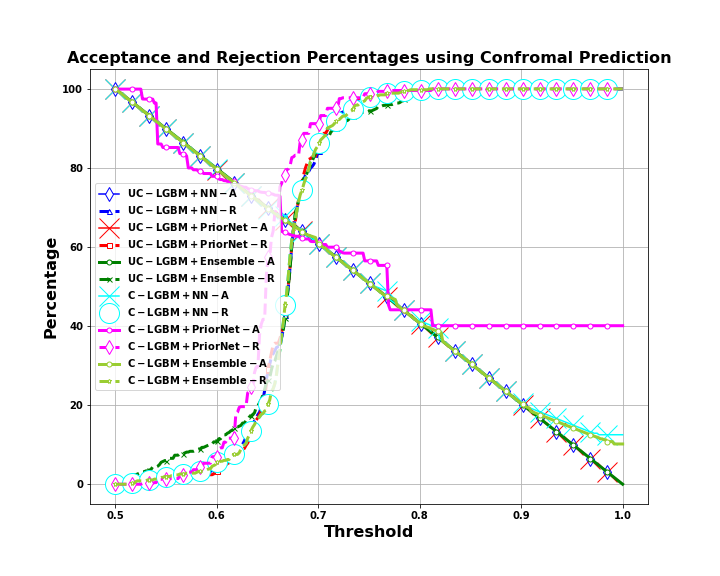
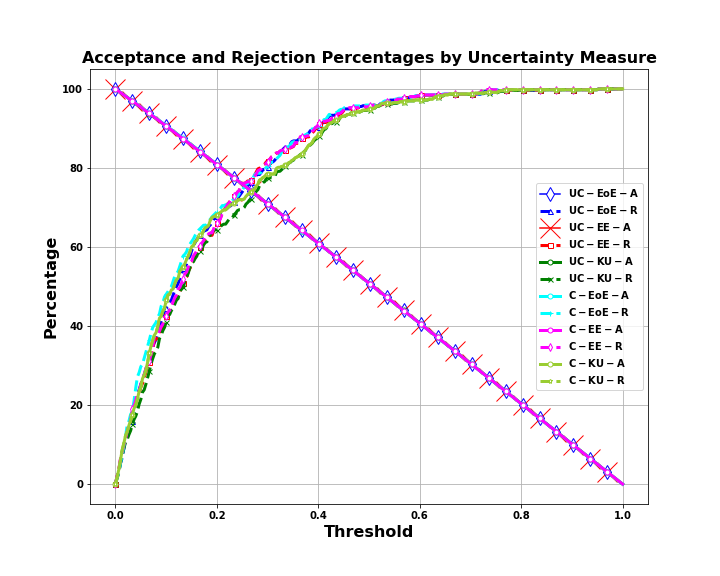
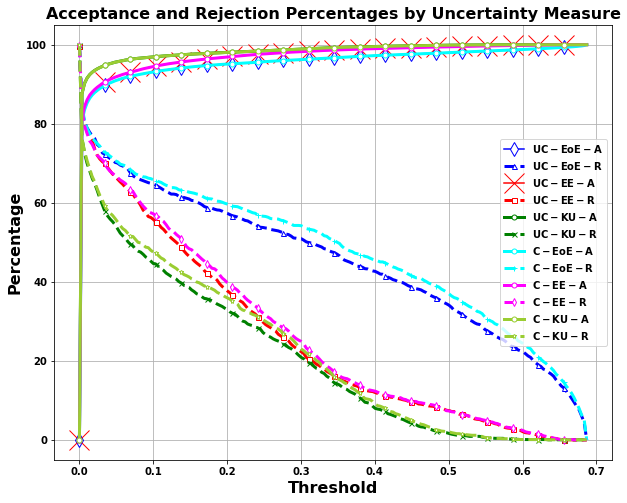
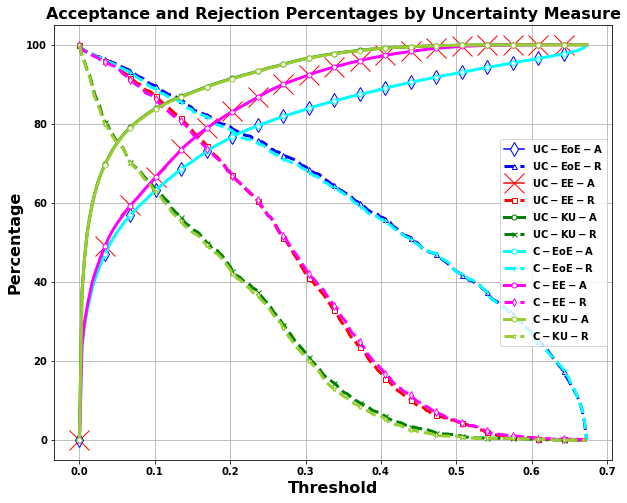
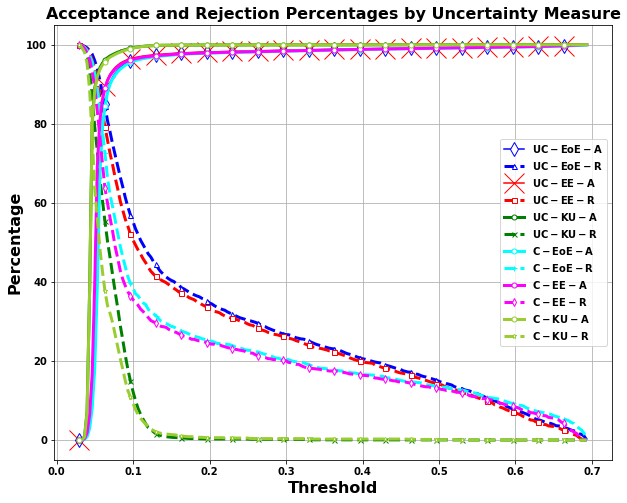
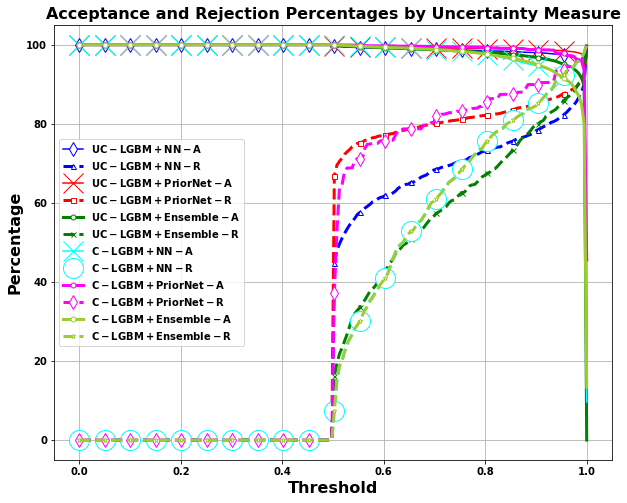
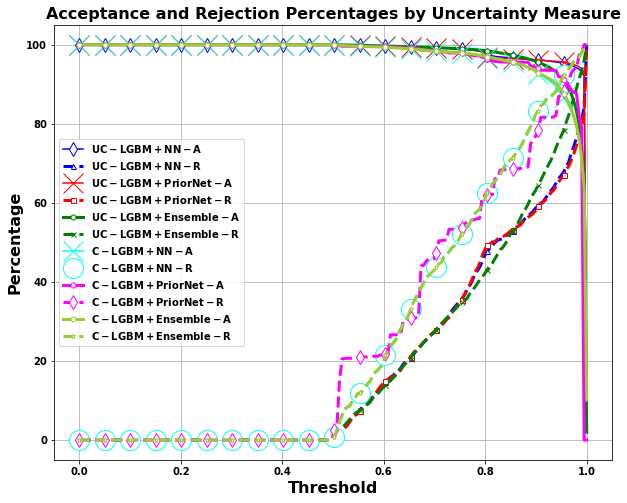
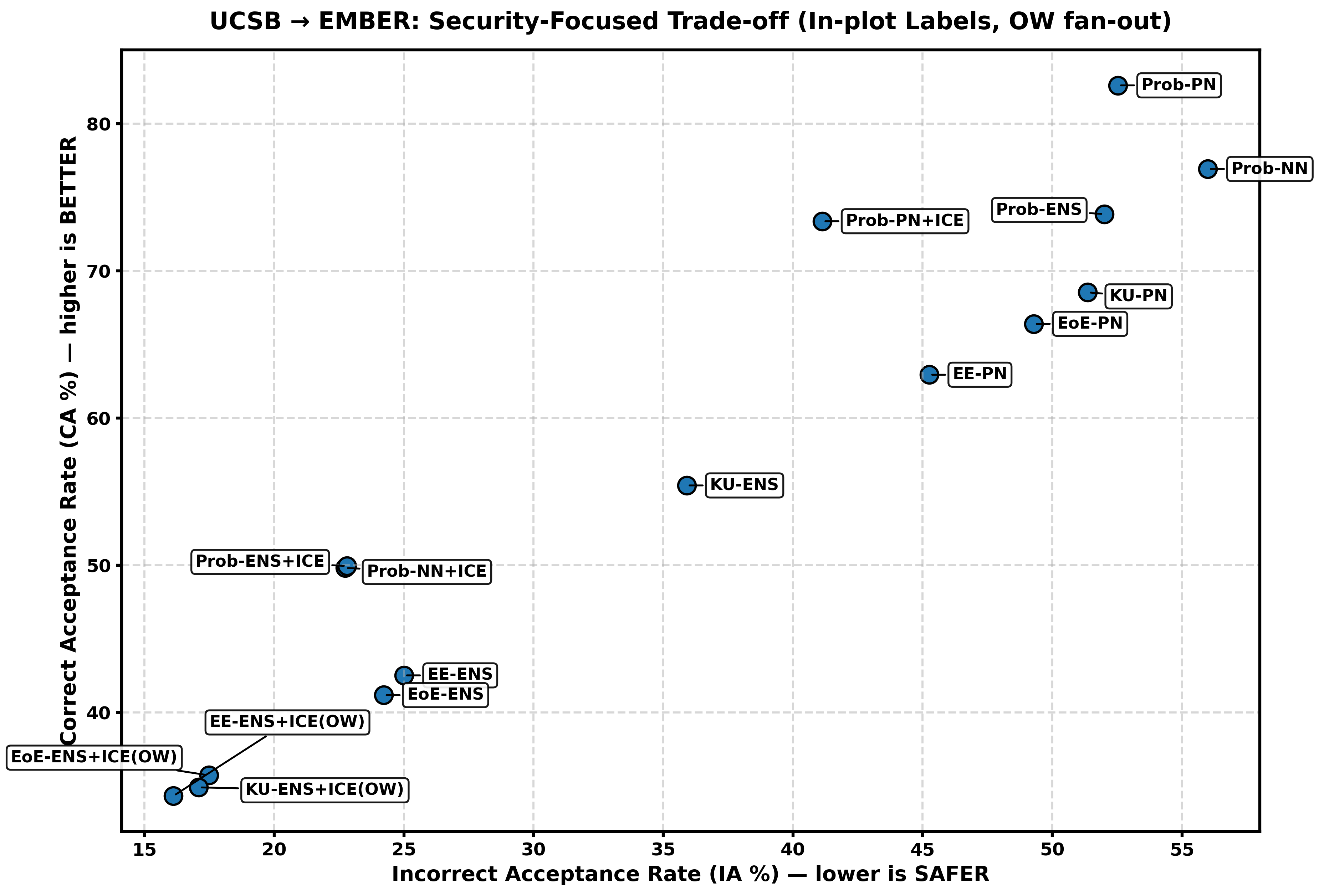
Title: Enhancing Decision-Making in Windows PE Malware Classification During Dataset Shifts with Uncertainty Estimation
ArXiv ID: 2512.18495
Date: 2025-12-20
Authors: Rahul Yumlembam, Biju Issac, Seibu Mary Jacob
📝 Abstract
Artificial intelligence techniques have achieved strong performance in classifying Windows Portable Executable (PE) malware, but their reliability often degrades under dataset shifts, leading to misclassifications with severe security consequences. To address this, we enhance an existing LightGBM (LGBM) malware detector by integrating Neural Networks (NN), PriorNet, and Neural Network Ensembles, evaluated across three benchmark datasets: EMBER, BODMAS, and UCSB. The UCSB dataset, composed mainly of packed malware, introduces a substantial distributional shift relative to EMBER and BODMAS, making it a challenging testbed for robustness. We study uncertainty-aware decision strategies, including probability thresholding, PriorNet, ensemble-derived estimates, and Inductive Conformal Evaluation (ICE). Our main contribution is the use of ensemble-based uncertainty estimates as Non-Conformity Measures within ICE, combined with a novel threshold optimisation method. On the UCSB dataset, where the shift is most severe, the state-of-the-art probability-based ICE (SOTA) yields an incorrect acceptance rate (IA%) of 22.8%. In contrast, our method reduces this to 16% a relative reduction of about 30% while maintaining competitive correct acceptance rates (CA%). These results demonstrate that integrating ensemble-based uncertainty with conformal prediction provides a more reliable safeguard against misclassifications under extreme dataset shifts, particularly in the presence of packed malware, thereby offering practical benefits for real-world security operations.
💡 Deep Analysis
📄 Full Content
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021
1
Enhancing Decision-Making in Windows PE
Malware Classification During Dataset Shifts with
Uncertainty Estimation
Rahul Yumlembam, Biju Issac, and Seibu Mary Jacob
Abstract—Artificial
intelligence
techniques
have
achieved
strong performance in classifying Windows Portable Executable
(PE) malware, but their reliability often degrades under dataset
shifts, leading to misclassifications with severe security conse-
quences. To address this, we enhance an existing LightGBM
(LGBM) malware detector by integrating Neural Networks (NN),
PriorNet, and Neural Network Ensembles, evaluated across
three benchmark datasets: EMBER, BODMAS, and UCSB. The
UCSB dataset, composed mainly of packed malware, intro-
duces a substantial distributional shift relative to EMBER and
BODMAS, making it a challenging testbed for robustness. We
study uncertainty-aware decision strategies, including probability
thresholding, PriorNet, ensemble-derived estimates, and Induc-
tive Conformal Evaluation (ICE). Our main contribution is the
use of ensemble-based uncertainty estimates as Non-Conformity
Measures within ICE, combined with a novel threshold optimi-
sation method. On the UCSB dataset, where the shift is most
severe, the state-of-the-art probability-based ICE (SOTA) yields
an incorrect acceptance rate (IA%) of 22.8%. In contrast, our
method reduces this to 16% a relative reduction of about 30%
while maintaining competitive correct acceptance rates (CA%).
These results demonstrate that integrating ensemble-based un-
certainty with conformal prediction provides a more reliable
safeguard against misclassifications under extreme dataset shifts,
particularly in the presence of packed malware, thereby offering
practical benefits for real-world security operations.
Index Terms—Conformal Prediction, Windows PE Malware,
Machine Learning, Deep Learning, Uncertainty estimation
I. INTRODUCTION
Artificial Intelligence (AI) and machine learning are pivotal
in enhancing the detection, prevention, and response mech-
anisms against Windows Portable Executable (PE) malware
in cybersecurity. The Portable Executable (PE) format serves
as the standard file format for executable programs within
Microsoft’s 32-bit and 64-bit Windows operating systems
[1]. PE files encompass various formats, including .exe files,
dynamic link libraries (.dlls), BAT/Batch files (.bat), control
panel applications (.cpl), kernel modules (.srv), device drivers
(.sys), and numerous others, with .exe files being the most
prevalent among them. Recent studies illustrate that machine
learning and deep learning models, characterized by various
representations of PE files, have achieved high accuracy in
Rahul
Yumlembam,
and
Biju
Issac
are
with
the
Department
of
Computer and Information Sciences, Northumbria University, Newcastle,
UK (email: r.yumlembam@northumbria.ac.uk, bijuissac@northumbria.ac.uk).
Corresponding author: Biju Issac
Seibu Mary Jacob is with the School of Computing, Engineering
& Digital Technologies, Teesside University, Middlesbrough, UK (email:
s.jacob@tees.ac.uk).
malware detection. However, high accuracy only sometimes
translates to reliability, especially in new or ambiguous cases.
Typically, classifiers predict the class of an instance based on
the highest probability, neglecting the confidence or uncer-
tainty of this prediction. For instance, if a model predicts a
PE file as benign with a 60% probability and as malware with
a 40% probability, it classifies the file as benign despite the
narrow margin, indicating low confidence in the prediction.
Such borderline predictions pose risks in critical applications
like cybersecurity, prompting the need for strategies to assess
each prediction’s certainty. For example, a benign PE file
such as a Windows update utility may be misclassified as
benign with low confidence, while actually embedding a trojan
downloader. This misclassification allows it to bypass security
layers and trigger further payload downloads, leading to severe
security breaches in enterprise networks. There are two broad
categories which induce uncertainty in the classifier’s pre-
diction: (1) Data uncertainty (Aleatoric Uncertainty), caused
by measurement errors or inherent system randomness, and
(2) Model uncertainty (Epistemic Uncertainty), resulting from
inadequate knowledge or model limitations [25]. Address-
ing model uncertainty is feasible through improvements in
architecture, learning processes, or training data, while data
uncertainty is irreducible [2].
Consider a scenario where a security operations centre de-
ploys a machine learning model trained on historical malware
samples. An attacker develops a slightly modified ransomware
variant that incorporates new obfuscation techniques not seen
during training. The model may classify the sample as benign
with 55% probability and as malware with 45% probability,
reflecting low confidence. In such borderline cases, relying
solely on the h