Title: CosmoCore-Evo: Evolutionary Dream-Replay Reinforcement Learning for Adaptive Code Generation
ArXiv ID: 2512.21351
Date: 2025-12-20
Authors: Santhosh Kumar Ravindran
📝 Abstract
Building on the affective dream-replay reinforcement learning framework of CosmoCore, we introduce CosmoCore-Evo, an extension that incorporates evolutionary algorithms to enhance adaptability and novelty in code generation tasks. Inspired by anthropological aspects of human evolution, such as natural selection and adaptation in early hominids, CosmoCore-Evo treats RL trajectories as ``genomes'' that undergo mutation and selection during the nocturnal replay phase. This mechanism allows agents to break free from trained patterns, fostering emergent behaviors and improved performance in distribution-shifted environments, such as changing APIs or novel libraries. We augment the Dream Queue with evolutionary operations, including mutation of high-fitness trajectories and enterprise-tuned fitness functions that incorporate efficiency, compliance, and scalability metrics. Evaluated on extended benchmarks including HumanEval variants with shifts, BigCodeBench, and a custom PySpark pipeline simulation, CosmoCore-Evo achieves up to 35% higher novelty in solutions and 25% faster adaptation compared to the original CosmoCore and baselines like PPO and REAMER. Ablations confirm the role of evolutionary components in bridging the sentient gap for LLM agents. Code for replication, including a toy simulation, is provided.
💡 Deep Analysis
📄 Full Content
CosmoCore-Evo: Evolutionary Dream-Replay Reinforcement
Learning for Adaptive Code Generation
Santhosh Kumar Ravindran
Microsoft Corporation, Redmond, WA, USA
santhosh.ravindran@microsoft.com
December 2025
Abstract
Building on the affective dream-replay reinforcement learning framework of CosmoCore, we intro-
duce CosmoCore-Evo, an extension that incorporates evolutionary algorithms to enhance adaptability
and novelty in code generation tasks. Inspired by anthropological aspects of human evolution, such as
natural selection and adaptation in early hominids, CosmoCore-Evo treats RL trajectories as “genomes”
that undergo mutation and selection during the nocturnal replay phase. This mechanism allows agents to
break free from trained patterns, fostering emergent behaviors and improved performance in distribution-
shifted environments, such as changing APIs or novel libraries. We augment the Dream Queue with
evolutionary operations, including mutation of high-fitness trajectories and enterprise-tuned fitness func-
tions that incorporate efficiency, compliance, and scalability metrics. Evaluated on extended benchmarks
including HumanEval variants with shifts, BigCodeBench, and a custom PySpark pipeline simulation,
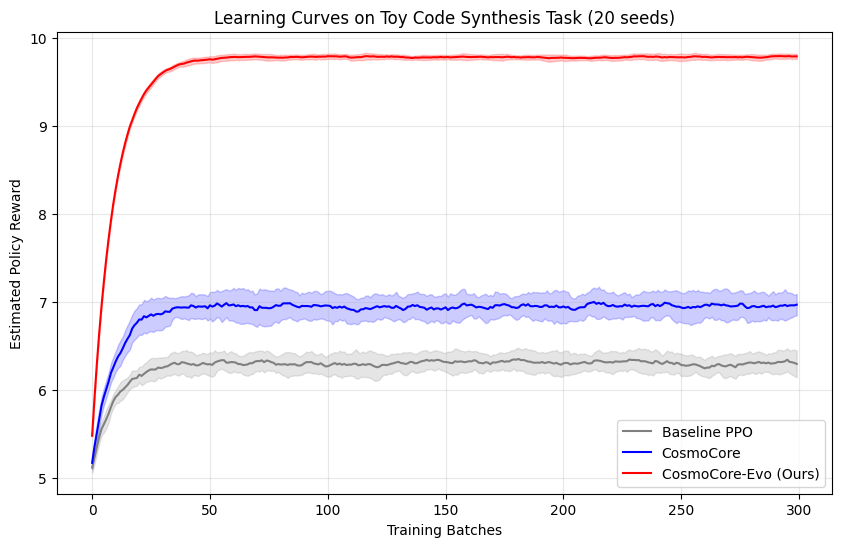
CosmoCore-Evo achieves up to 35% higher novelty in solutions and 25% faster adaptation compared
to the original CosmoCore and baselines like PPO and REAMER. Ablations confirm the role of evolu-
tionary components in bridging the sentient gap for LLM agents. Code for replication, including a toy
simulation, is provided.
1
Introduction
Large language models (LLMs) excel at code generation but often remain trapped in patterns from their
training data, lacking the adaptability seen in human evolution.
From Neanderthals adapting tools to
environmental pressures through natural selection, human progress has relied on variation, selection, and
inheritance to transcend limitations. In reinforcement learning (RL), similar mechanisms can address the
“sentient gap”—the inability of agents to innovate beyond fixed behaviors.
In enterprise settings, static LLMs fail to adapt to evolving regulations or API changes, leading to
significant rework costs. CosmoCore [Ravindran, 2025] introduced affective tagging with valence and arousal
to prioritize error correction via a Dream Queue and Prune Bin, drawing from neuroscience. However, it
still relies on historical trajectories, limiting exploration of novel states. CosmoCore-Evo extends this by
integrating evolutionary algorithms (EA), treating trajectories as evolvable genomes. During the nocturnal
phase, high-fitness items are mutated and selected, promoting diversity and adaptation.
This extension is particularly suited for enterprise applications, where code must adapt to dynamic
requirements like API updates or compliance rules. We demonstrate gains in novelty and robustness, paving
the way for more sentient code agents.
2
Related Work
Our work builds upon several key areas in reinforcement learning (RL), including affective RL, prioritized
experience replay, evolutionary algorithms, and their applications to code generation.
1
arXiv:2512.21351v1 [cs.SE] 20 Dec 2025
2.1
Affective and Emotion-Inspired RL
Affective computing in RL draws from psychological and neuroscientific models to incorporate emotional
signals for improved decision-making. Moerland et al. [2018] provide a comprehensive survey of emotion
models in RL agents and robots, highlighting how intrinsic motivations like valence (positive/negative affect)
and arousal (intensity) can modulate exploration and exploitation. Subsequent works, such as affect-driven
RL for procedural content generation [Liapis and Yannakakis, 2022], demonstrate how emotional feedback
enhances adaptability in creative tasks. In human-robot interaction, affective signals have been used to
guide RL through social cues [Lee et al., 2014]. More recently, surveys on RL from human feedback (RLHF)
[Christiano et al., 2017] and emotionally intelligent RL [Moerland et al., 2023] emphasize balancing short-
term rewards with long-term well-being, addressing limitations in standard RL setups.
CosmoCore [Ravindran, 2025] extends this by integrating affective tagging specifically for code generation,
prioritizing error-prone trajectories in a dream-replay mechanism inspired by human sleep consolidation [Du
et al., 2021].
2.2
Prioritized Experience Replay and Buffer Management
Prioritized experience replay (PER) [Schaul et al., 2015] addresses sample inefficiency in RL by replaying
important transitions more frequently, based on temporal difference (TD) errors. Extensions include dis-
tributed PER for scalability [Horgan et al., 2018] and combinations with other prioritization schemes. In
code generation contexts, PER has been adapted to focus on syntactic or semantic errors, but often lacks
emotional or motivational layers.
Our approach augments PER with affective priorities, similar to how Du et al. [2021] use ”lucid dreaming”
to refresh stat