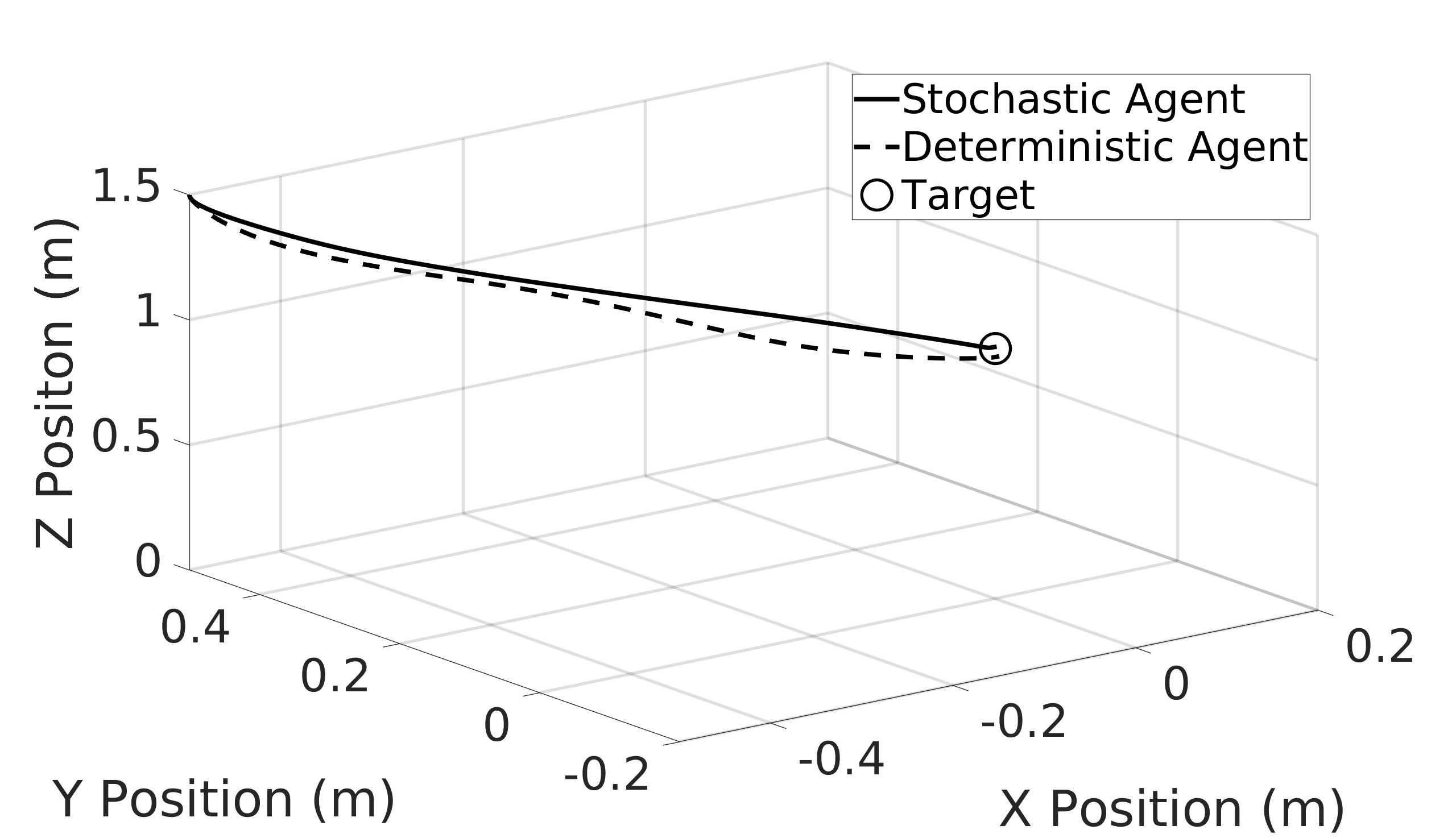
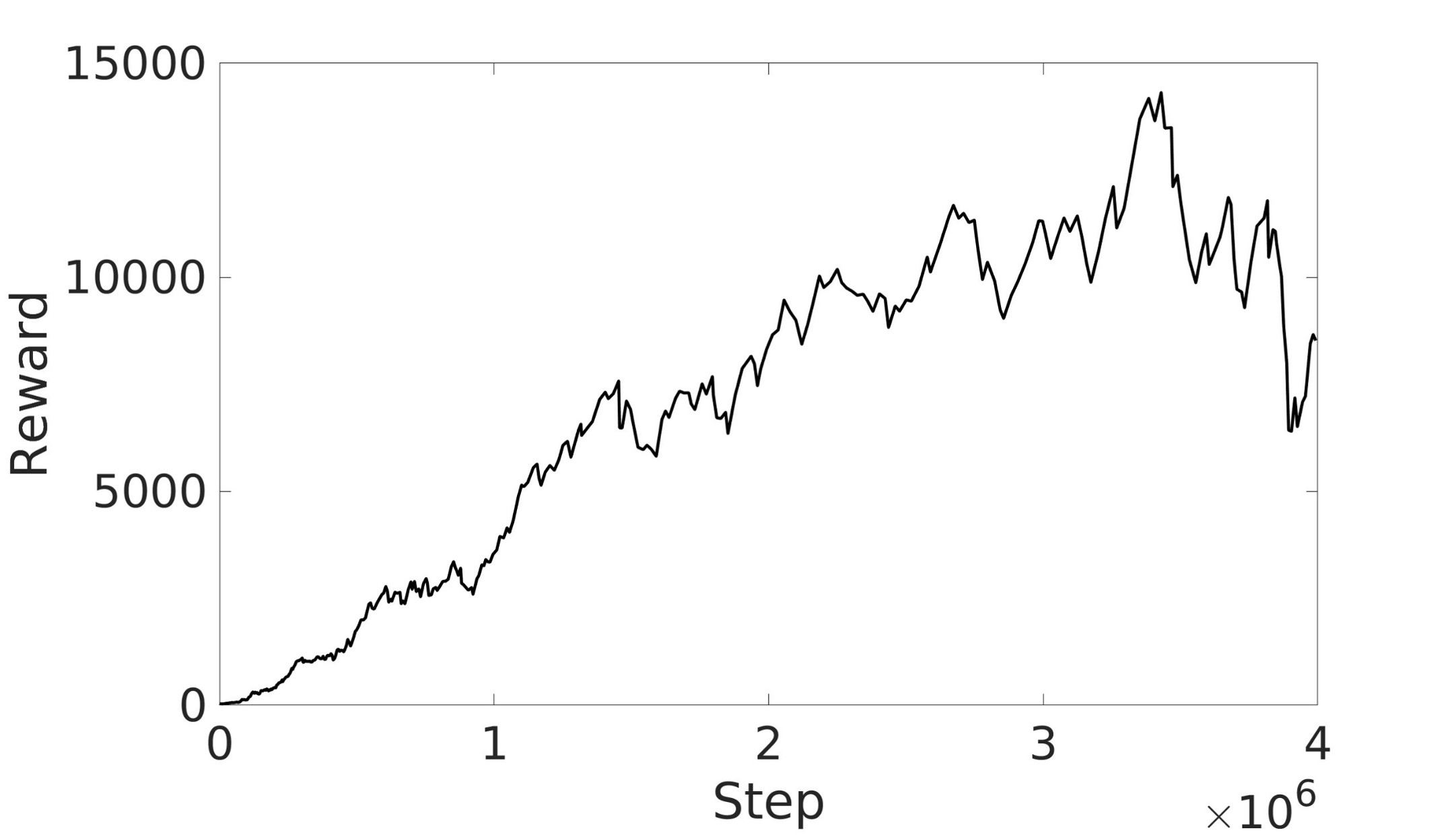
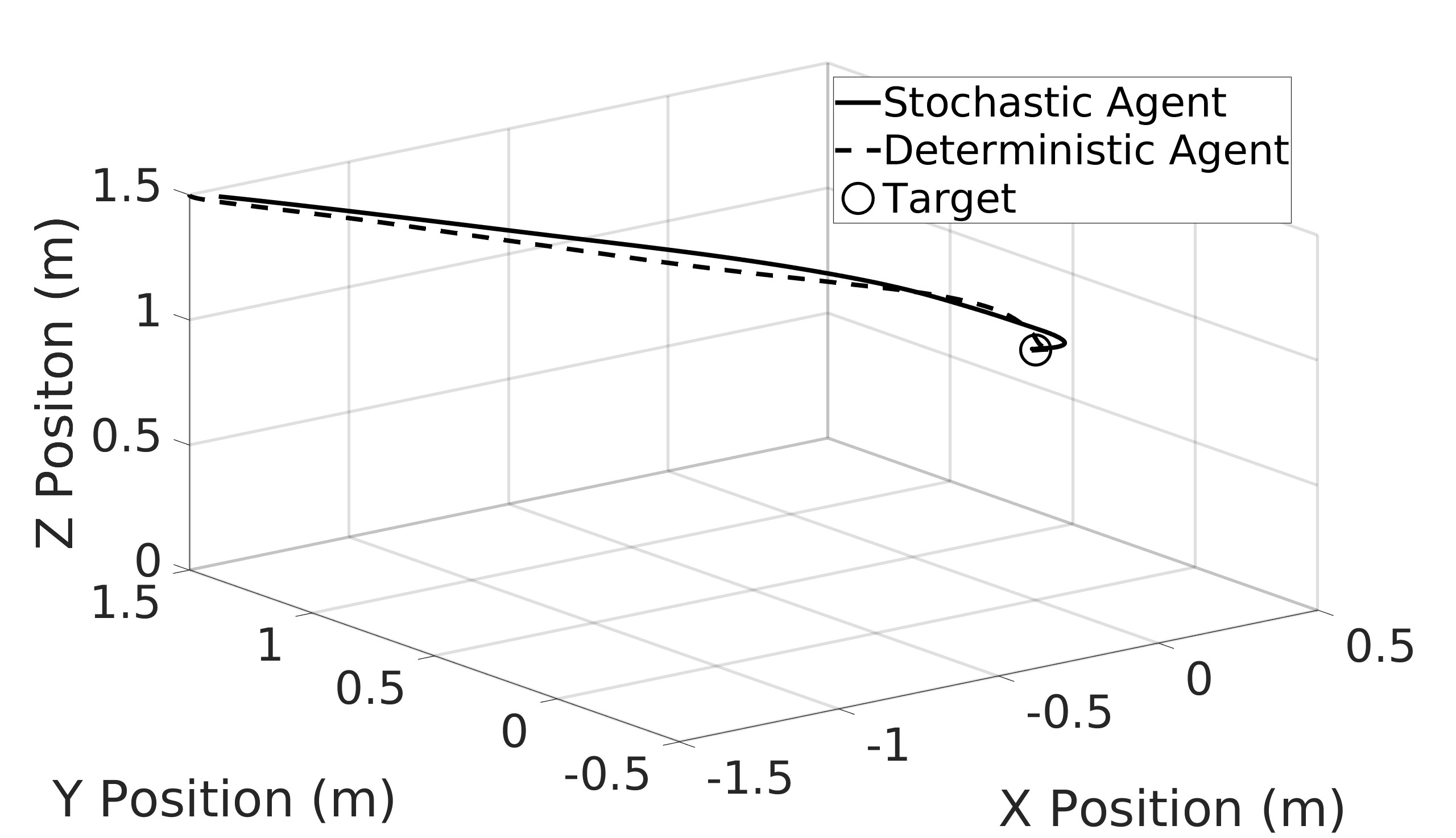
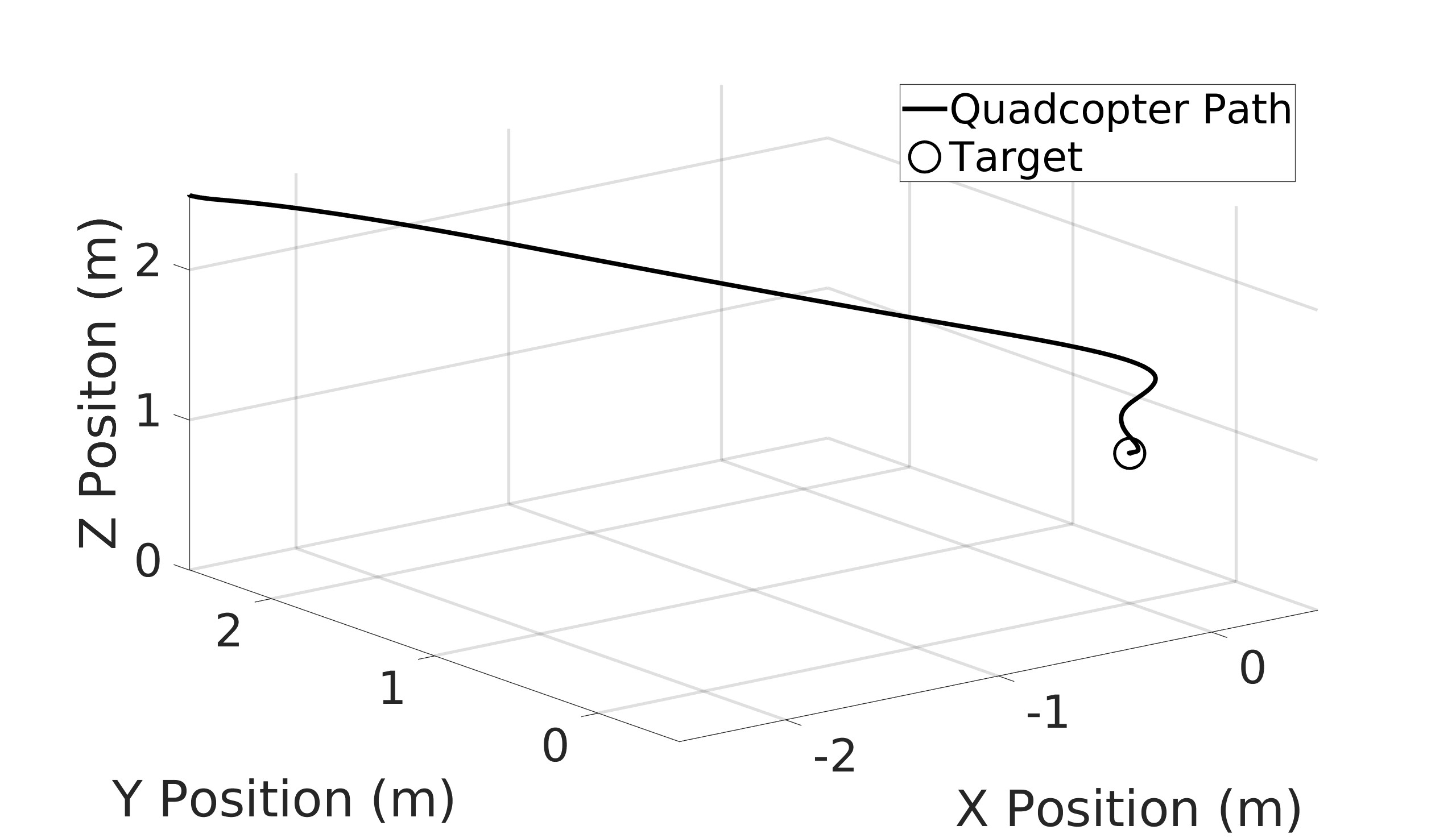
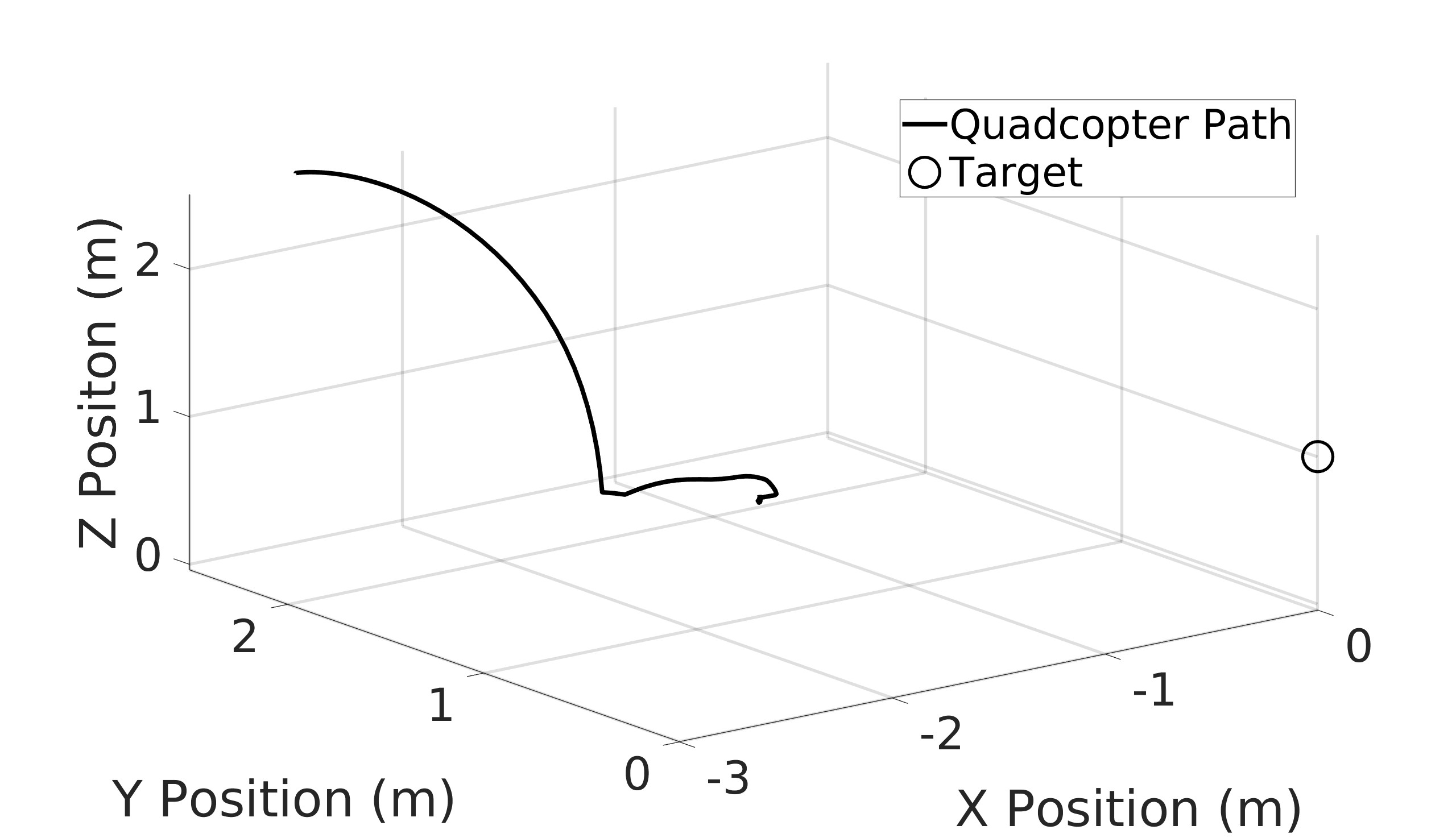
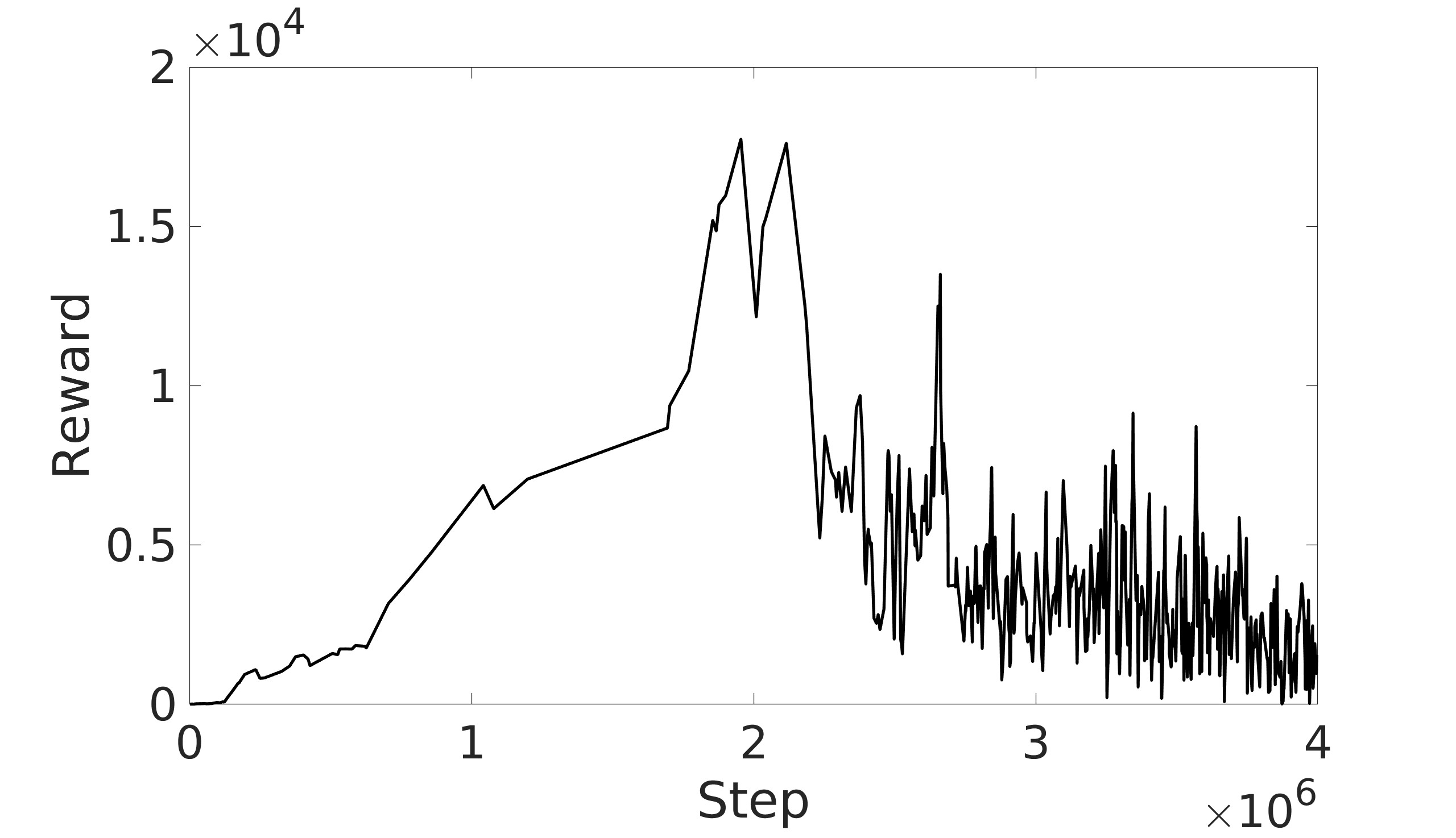
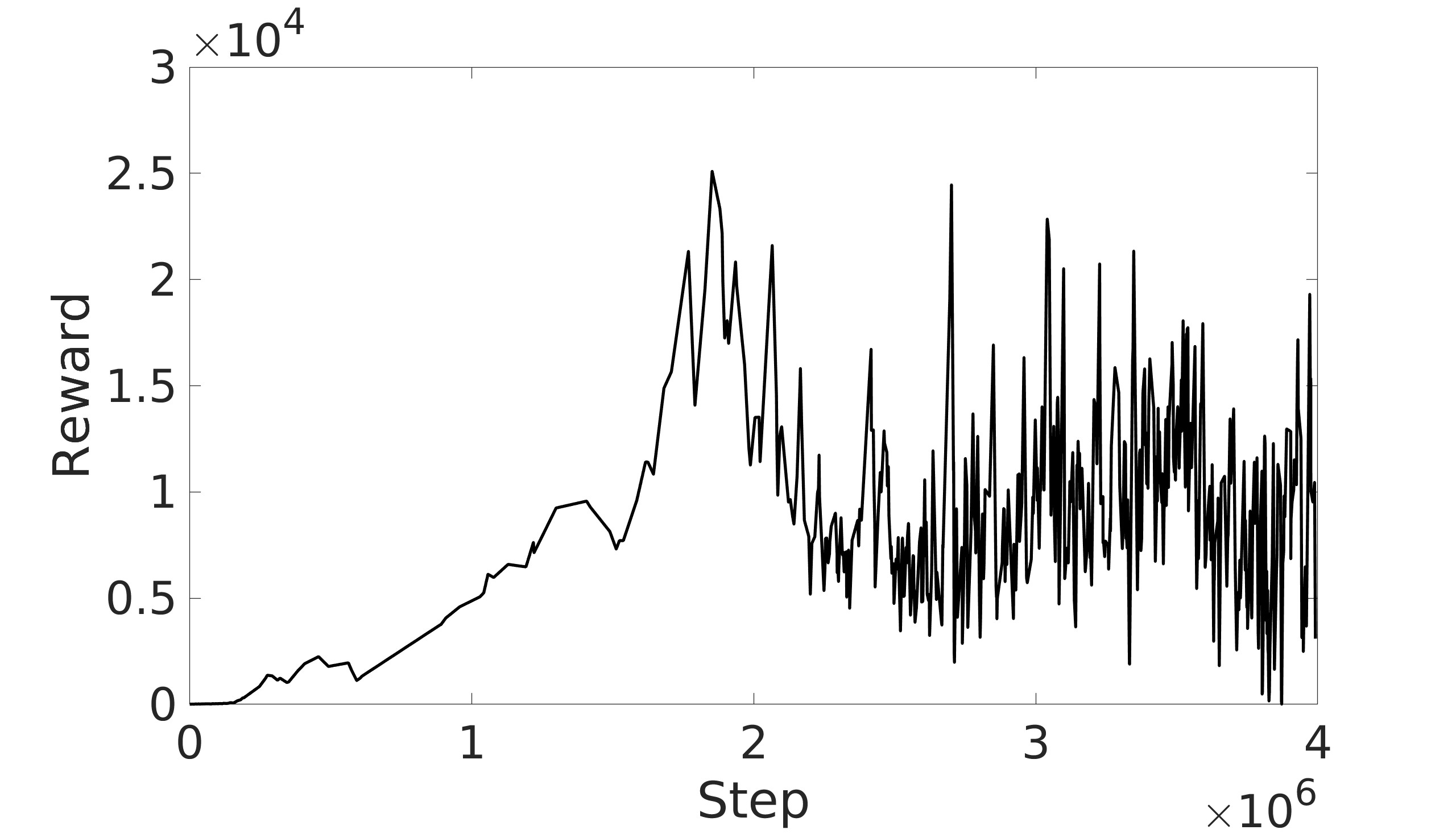
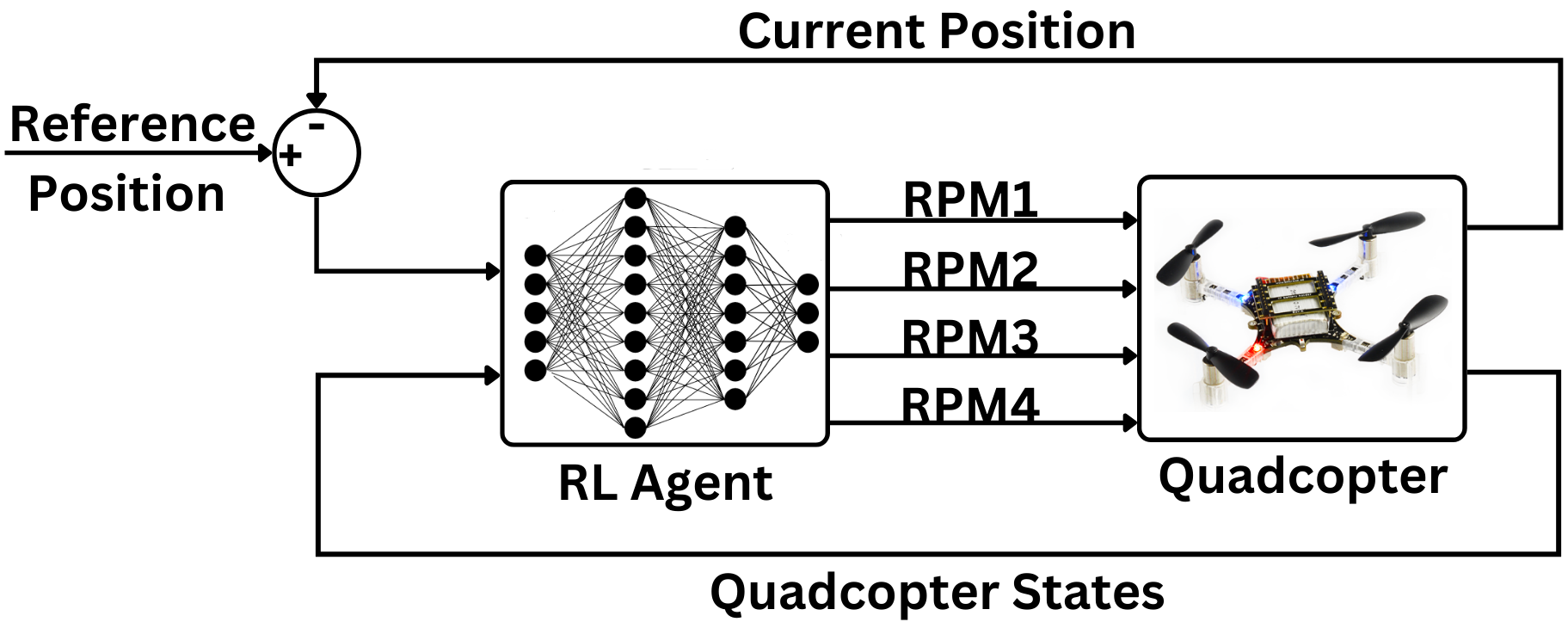
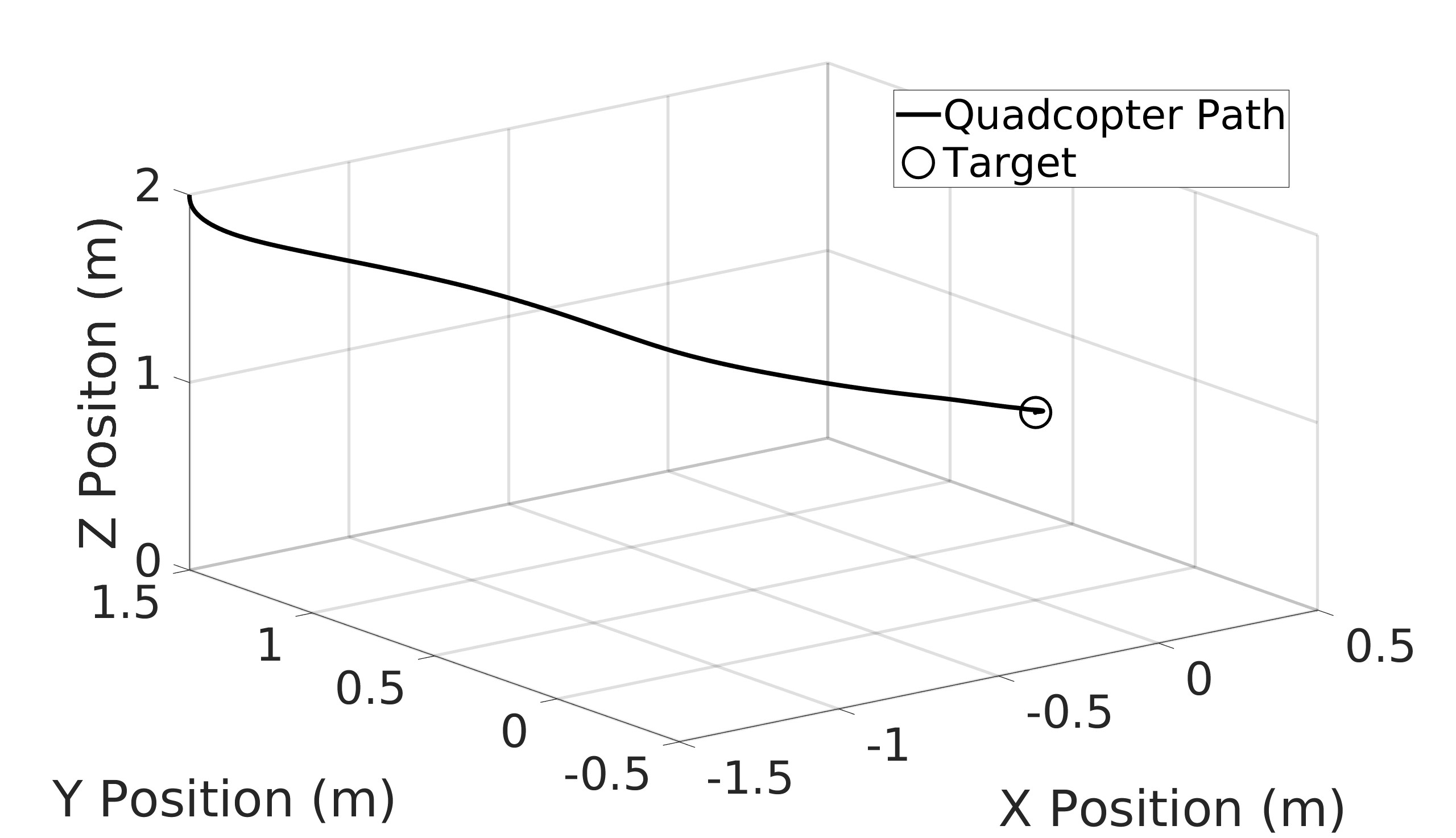
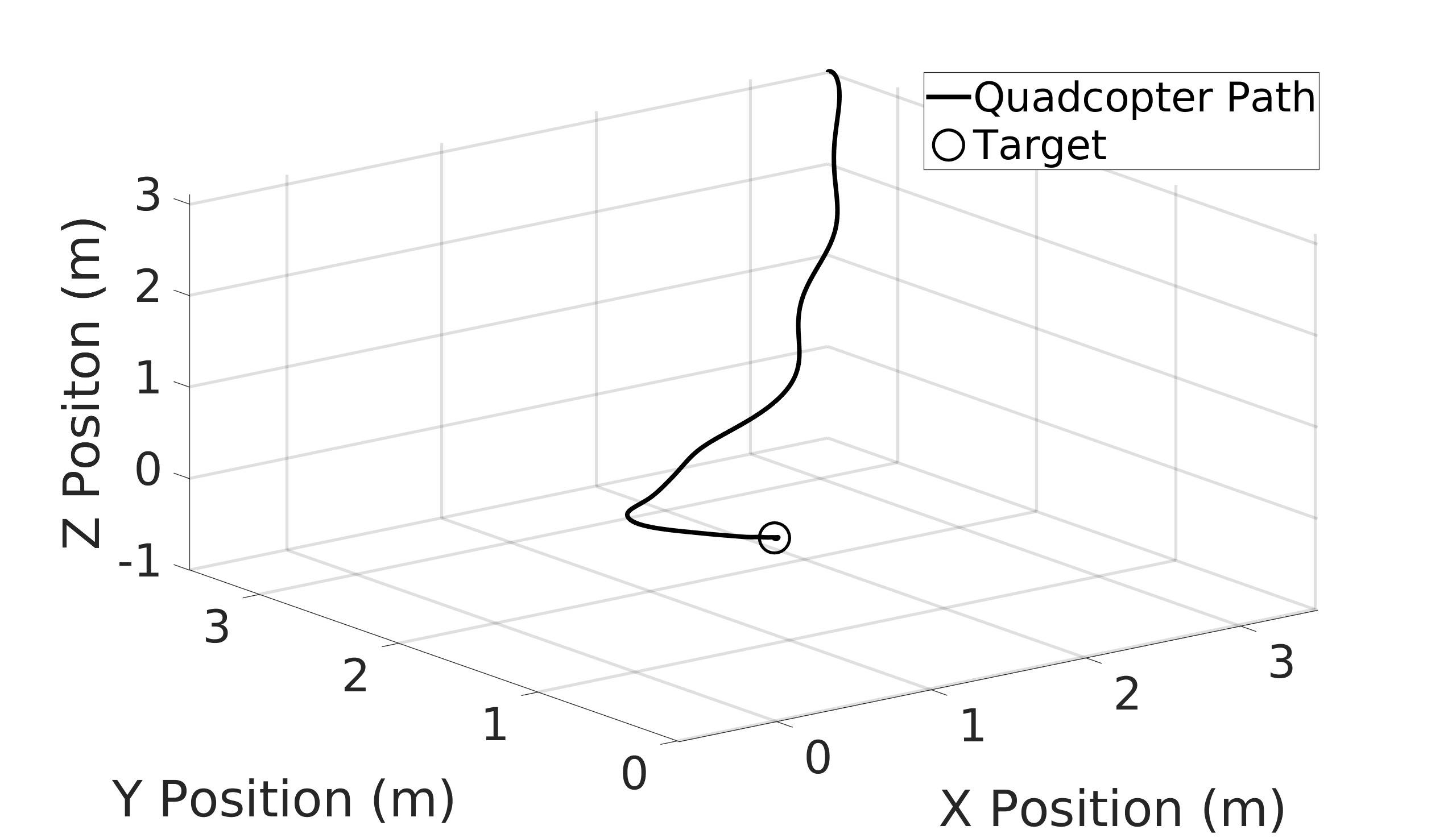
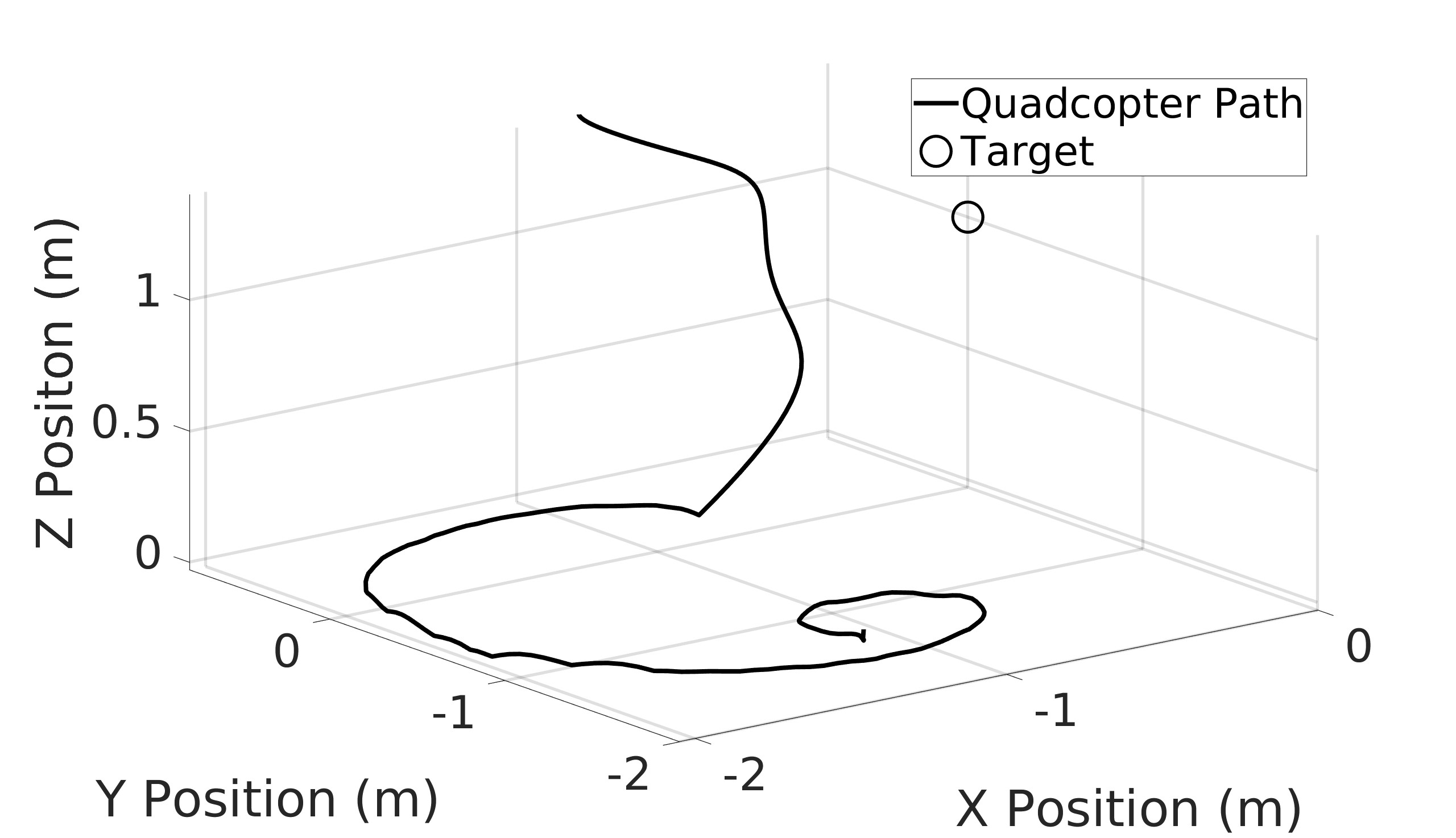
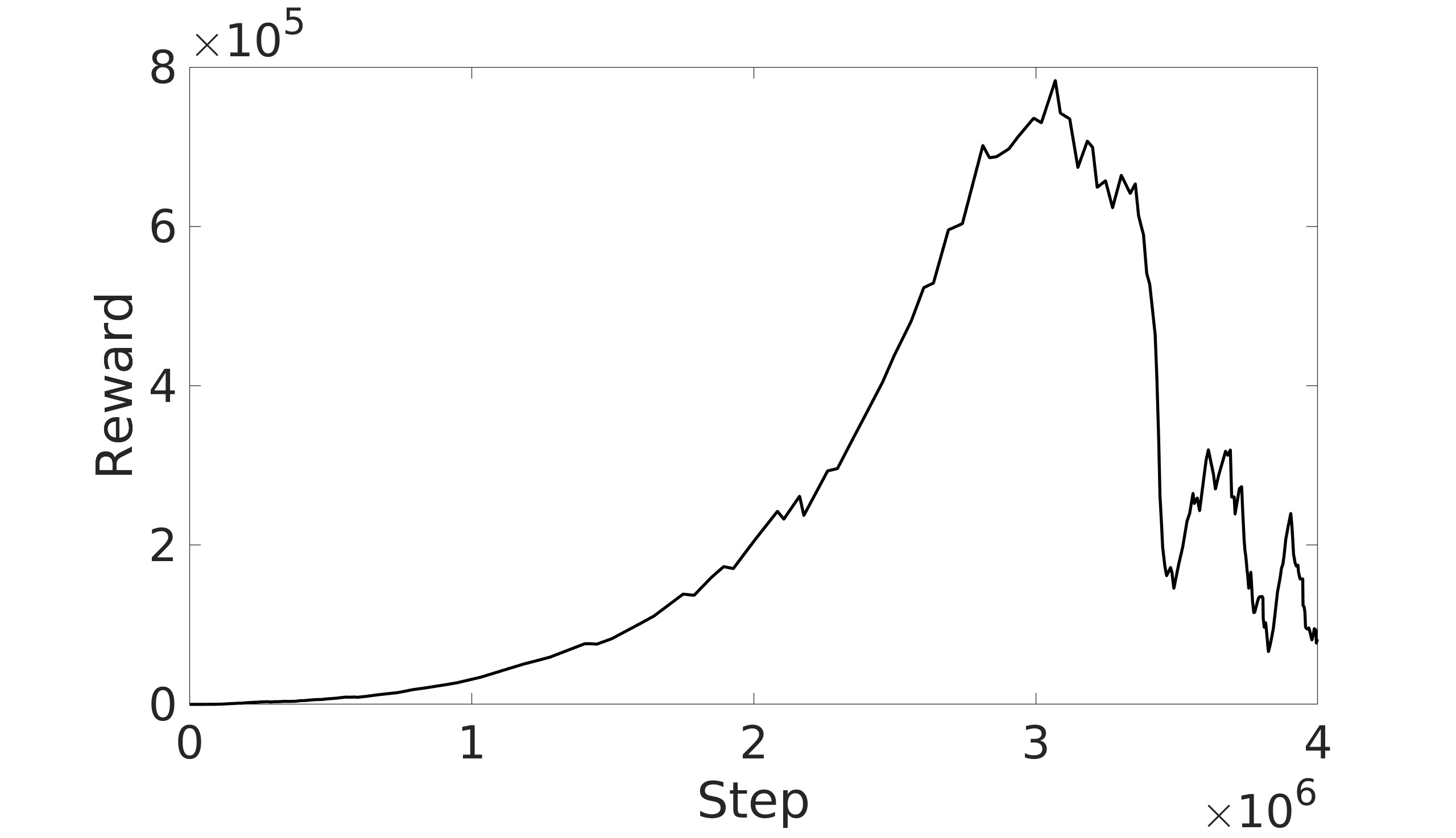
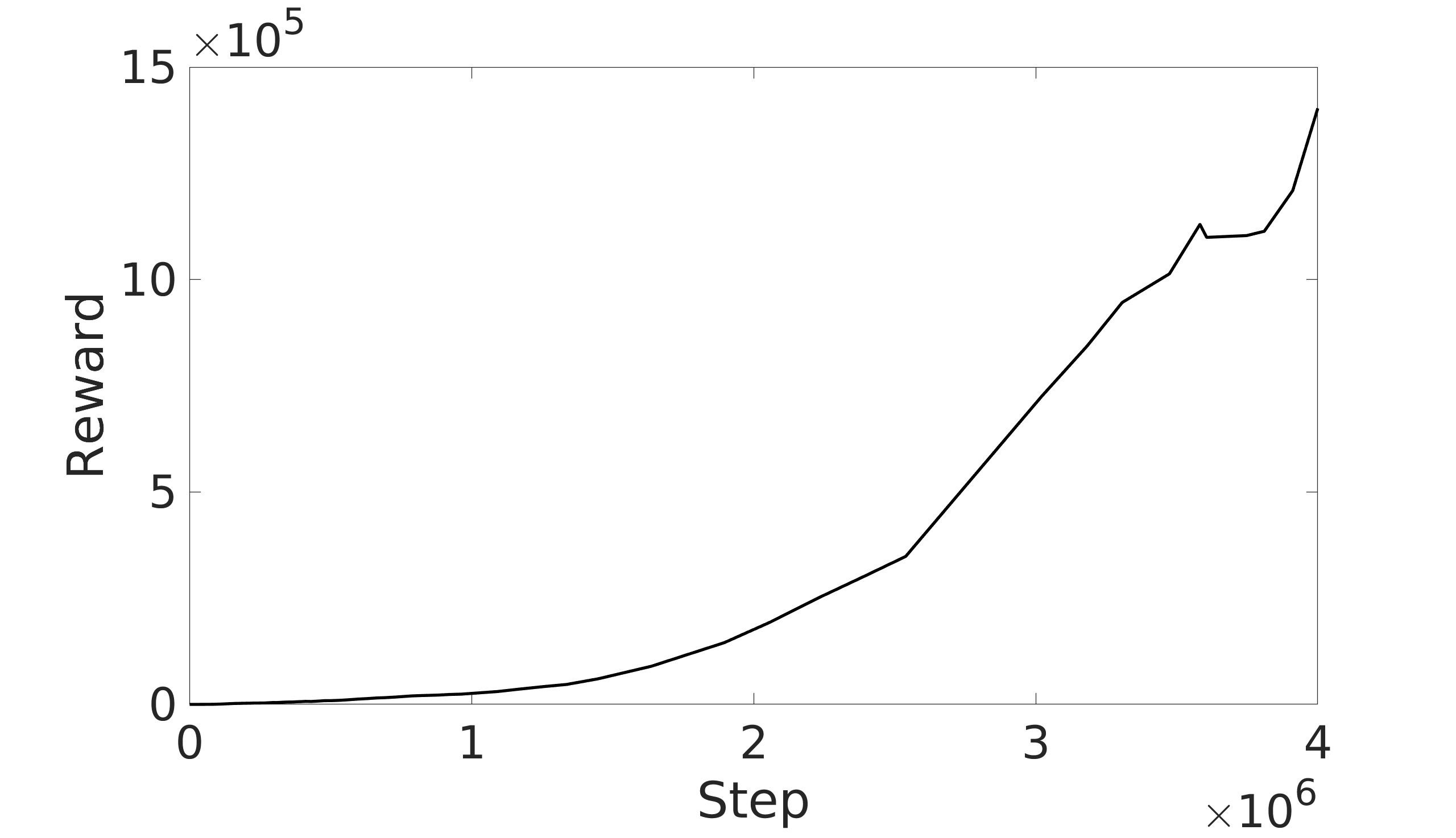
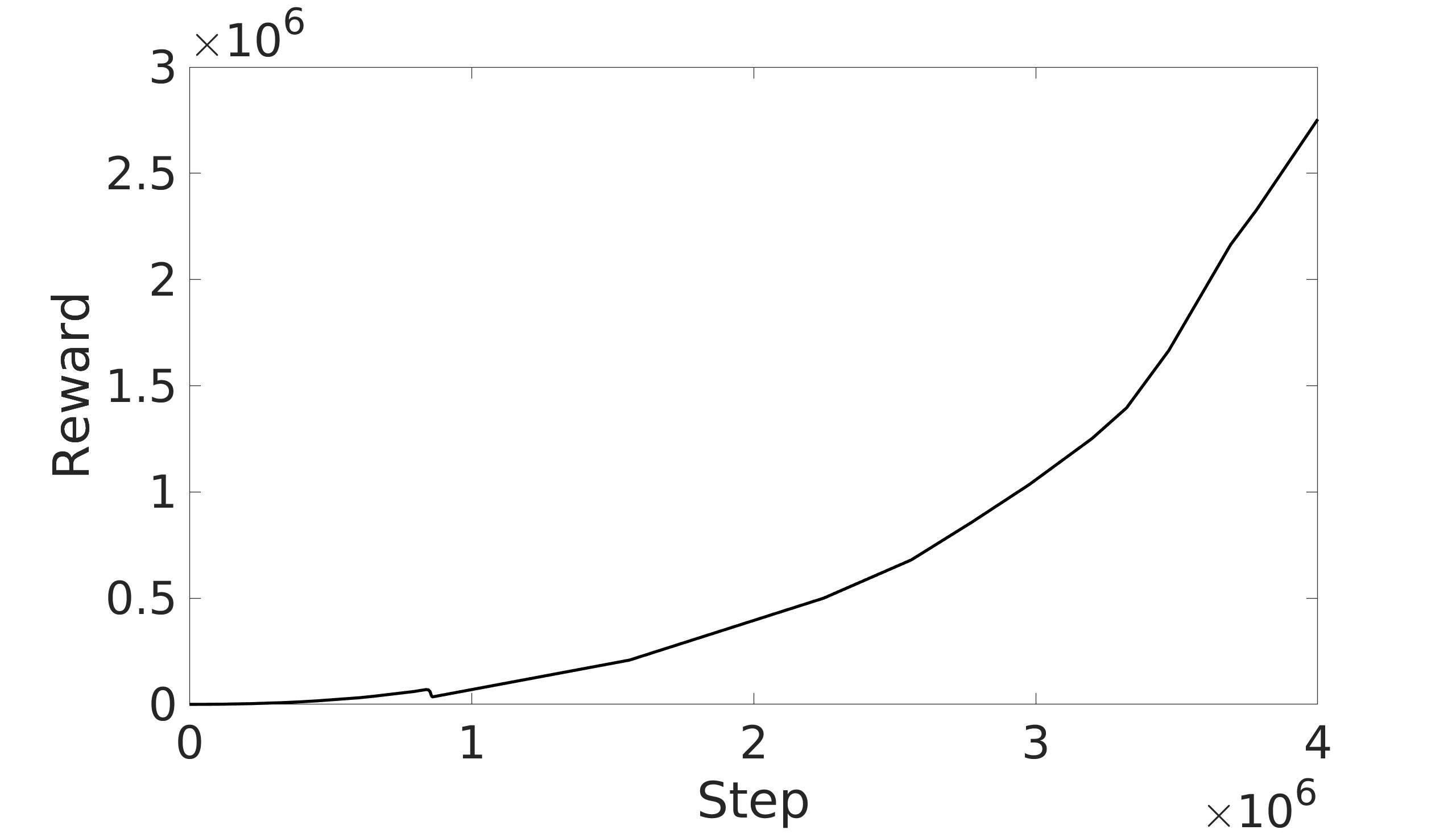
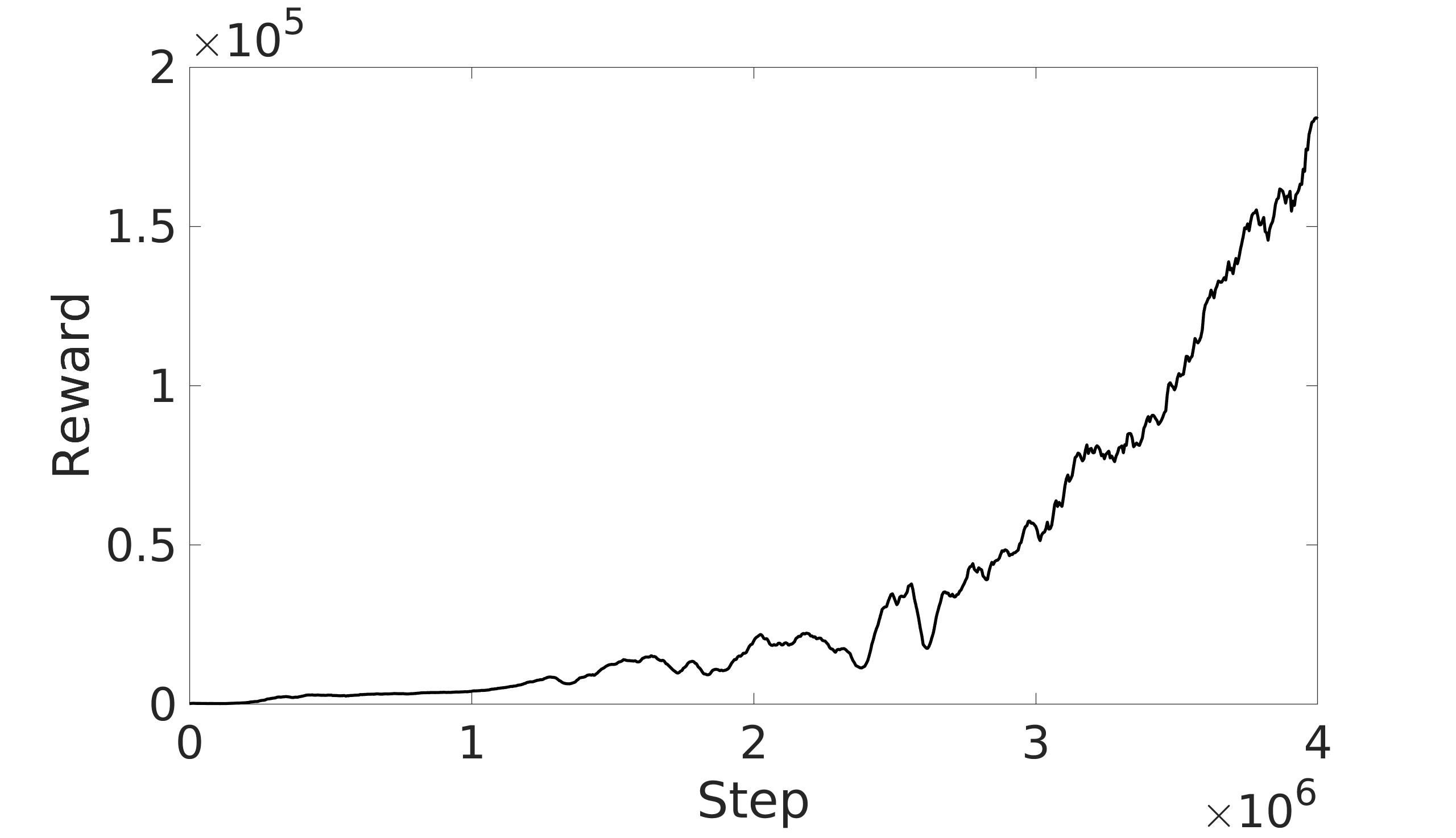
This paper explores the impact of dynamic entropy tuning in Reinforcement Learning (RL) algorithms that train a stochastic policy. Its performance is compared against algorithms that train a deterministic one. Stochastic policies optimize a probability distribution over actions to maximize rewards, while deterministic policies select a single deterministic action per state. The effect of training a stochastic policy with both static entropy and dynamic entropy and then executing deterministic actions to control the quadcopter is explored. It is then compared against training a deterministic policy and executing deterministic actions. For the purpose of this research, the Soft Actor-Critic (SAC) algorithm was chosen for the stochastic algorithm while the Twin Delayed Deep Deterministic Policy Gradient (TD3) was chosen for the deterministic algorithm. The training and simulation results show the positive effect the dynamic entropy tuning has on controlling the quadcopter by preventing catastrophic forgetting and improving exploration efficiency.
Recent advancements in RL showed huge potential in controlling quadcopters. This was proven by allowing a quadcopter to obtain champion-level drone racing performance [1]. The quadcopter was able to navigate the race course and pass through all the gates in the correct sequence faster than the human-controlled quadcopter and win against 3 different drone racing champions achieving the fastest recorded race time. This shows the potential of using the RL control framework in controlling quadcopters.
Deterministic RL algorithms were explored in the literature to better study the control of quadcopters. The TD3 algorithm is a powerful deterministic algorithm with its dual-clipped Q-learning and delayed policy update techniques. Two different RL agents were developed to handle two different quadcopter control tasks using TD3 [2]. The main goal of the first agent, known as the stabilization agent, was to maintain the quadcopter hovering at a certain pre-set point, while the second agent, known as the path-following agent, was to navigate the quadcopter along a predetermined path. Both agents mapped environment states into motor commands. Simulation results showcased the efficiency of both agents. To further enhance the quadcopter capabilities, an obstacle avoidance agent (OA) was created in addition to the path following agent (PF) [3]. The target of the PF agent was to map the states into motor RPMs to follow a certain path. The OA agent modified the tracking error information before it was sent to the PF agent to ensure that the path was free from any obstacles. Simulation results proved that this control framework was successful in following paths while avoiding obstacles along the way. Another control framework in the form of highlevel and low-level waypoint navigation of the quadcopter was proposed [4]. The low-level controller maps the environment states into motor commands while the high-level controller produces the linear velocities of the quadcopter. Both agents’ simulation results showed the successful navigation and trajectory tracking of the quadcopter.
The SAC algorithm on the other hand combines two powerful reinforcement learning techniques, the Actor-Critic technique and maximum entropy deep RL. Combining these two techniques makes the SAC a state-of-the-art algorithm. The SAC differs from the TD3 by adding an entropy term to the target and the policy. This technique helps maximize the exploration while taking into consideration maximizing the rewards as well. It also computes the next-state action from the current policy and does not utilize target policy smoothing. This is due to the SAC algorithm training a stochastic policy and the stochastic noise is enough to smooth the Q-values. The SAC algorithm was explored in the literature by proposing a SAC low-level control of a quadcopter that maps environment states to motor commands [5]. The simulation results show the efficiency of the controller in a simple go-to task and in tracking moving objects at high and low speeds with maximum efficiency. The agent was then tested with various extreme initial positions to test its robustness and the SAC algorithm’s ability in state space exploration. However, the proposed algorithm utilized static entropy only. Another SAC agent for a quadcopter was developed to control the quadcopter despite having a single rotor failure [6]. Simulation results showed the SAC’s effectiveness in hovering, landing, and tracking various trajectories with only three active rotors. The controller was also successfully tested against wind dis-turbances to validate its robustness. Also in this research, the effect of dynamic entropy tuning was not explored.
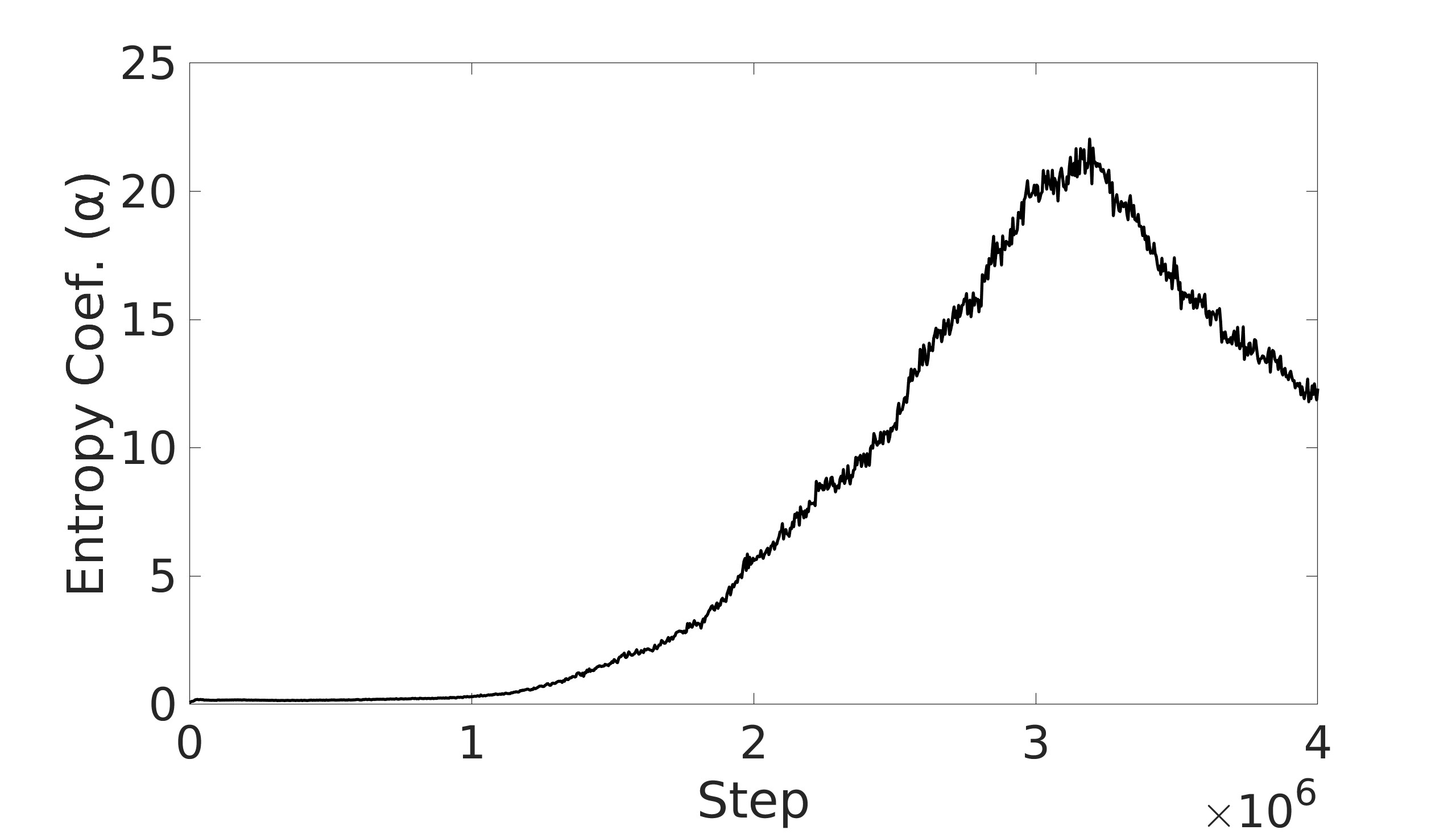
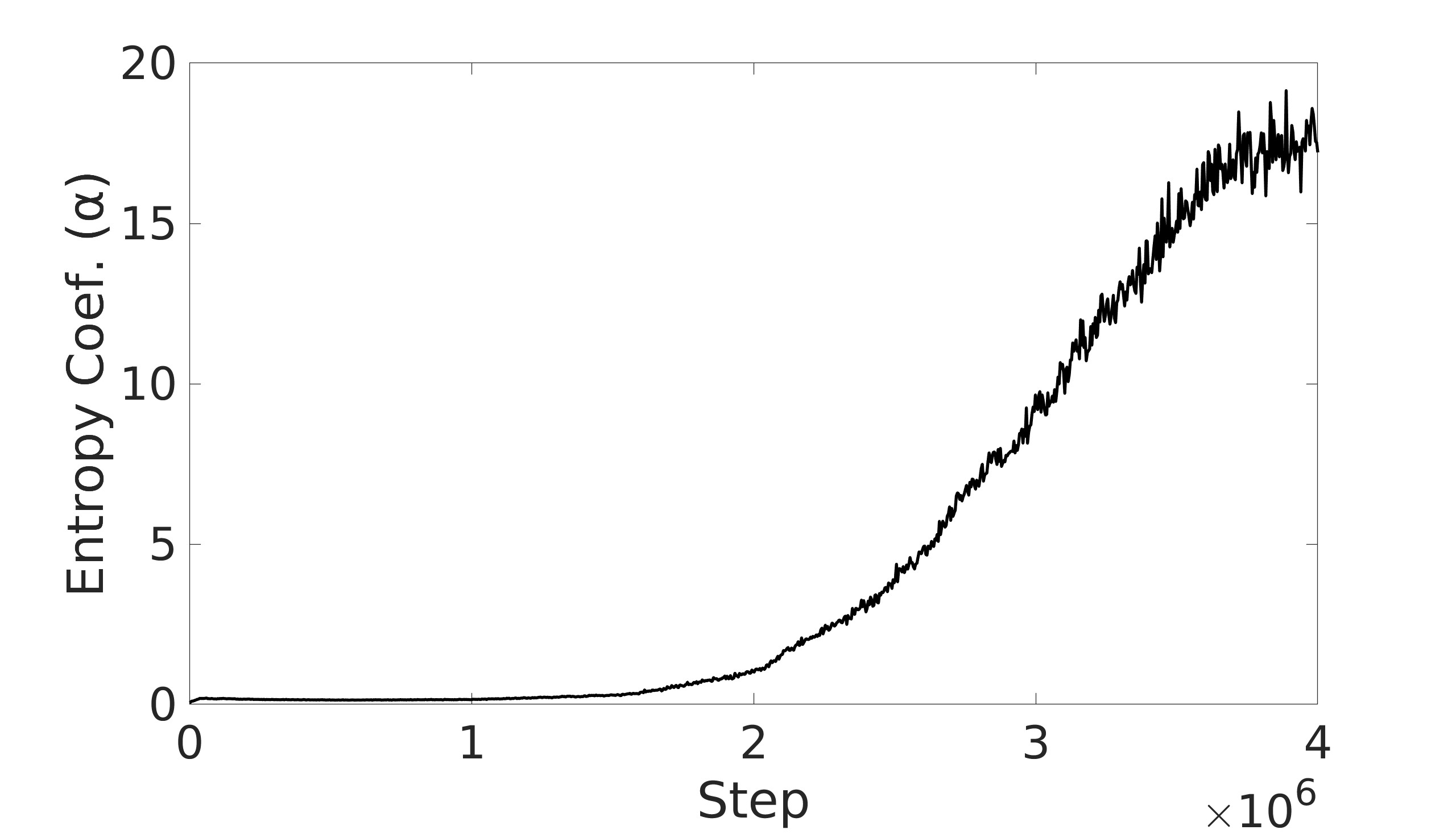
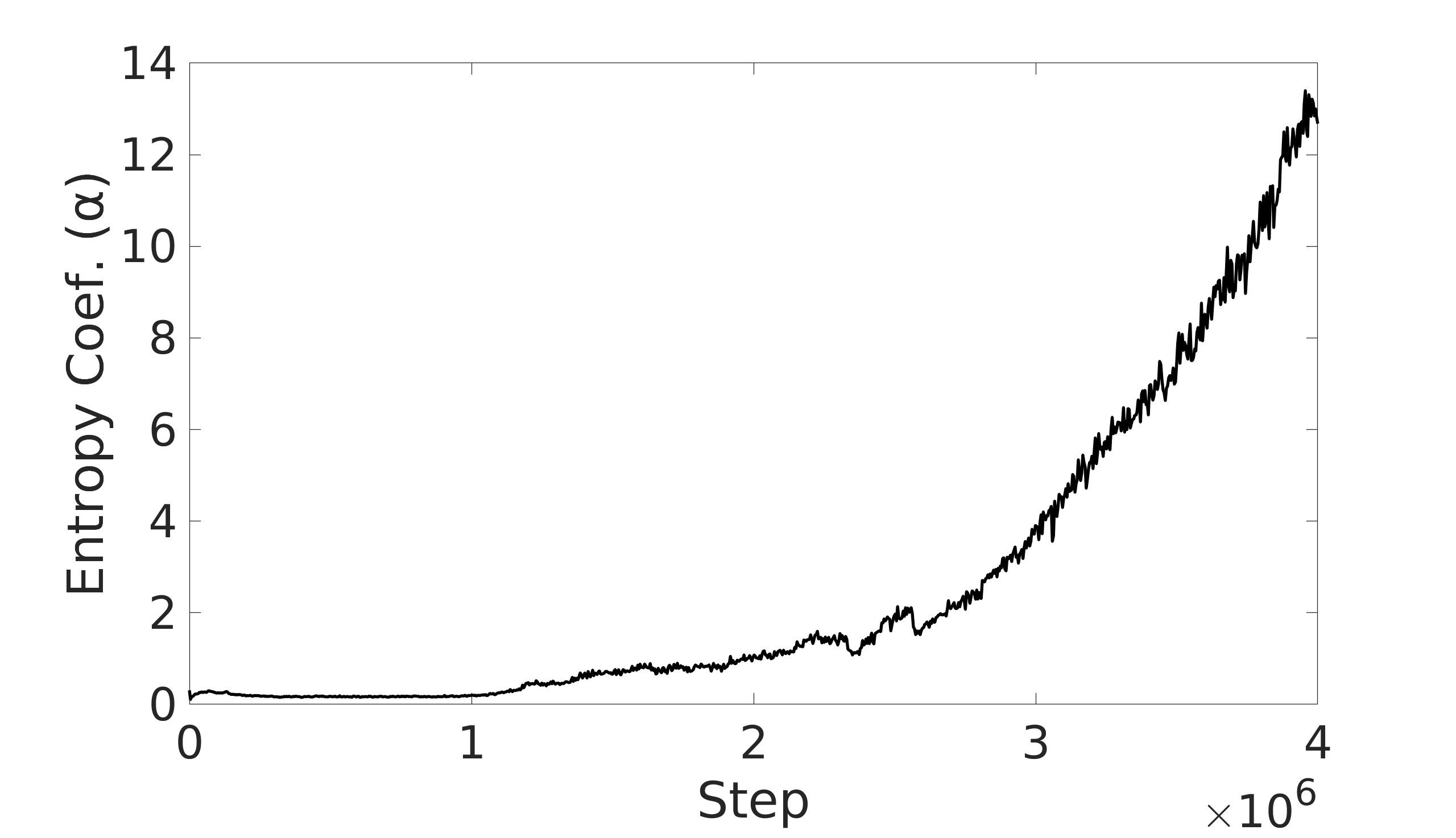
A key factor in the SAC algorithm’s performance is the entropy value. Entropy, in the context of reinforcement learning, refers to the randomness or unpredictability of the agent’s action selection. Higher entropy encourages the agent to explore a wider range of actions, while lower entropy leads to more deterministic and exploitative behavior. Choosing the optimal entropy in entropy-based algorithms is a non-trivial task where the entropy is required to be tuned for each application [7]. Dynamically adjusting the entropy allows the policy to balance exploration and exploitation effectively throughout the training process. The entropy is tuned by adjusting the entropy coefficient to match a target entropy value to minimize the difference between the current policy’s entropy and the target entropy. This automatic tuning mechanism allows the agent to explore more when necessary and exploit more in explored regions, leading to more efficient and effective learning.
This paper aims to explore the impact of dynamic entropy tuning on low-level control of quadcopters. While deterministic algorithms are used more than stochastic algorithms for quadcopter control, this research compares stochastic and deterministic policy training. Both policies are tested within a deterministic
This content is AI-processed based on open access ArXiv data.