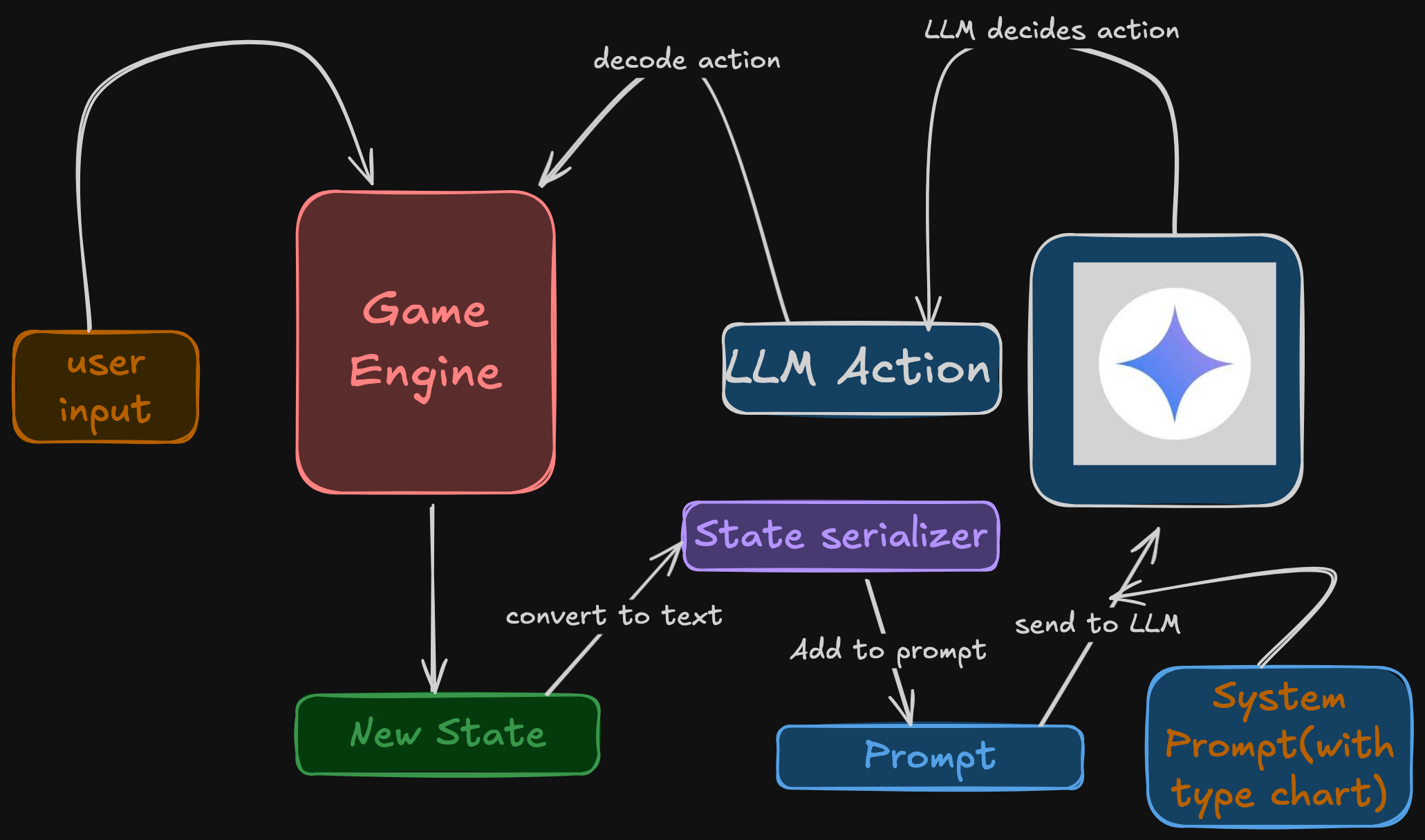
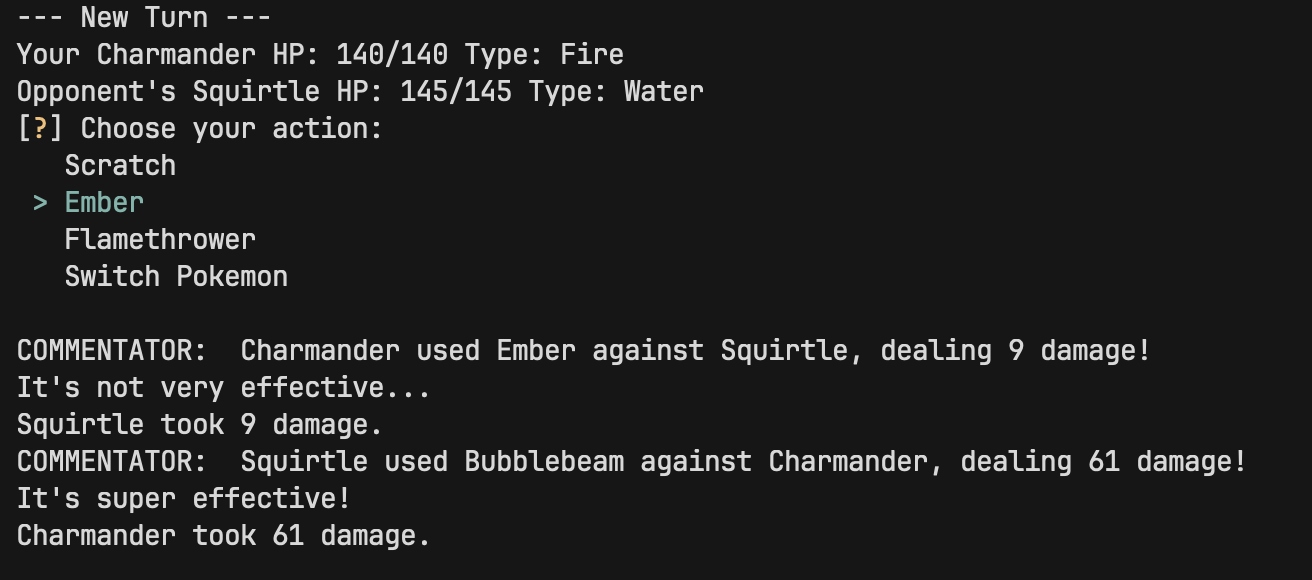
Strategic decision-making in Pokémon battles presents a unique testbed for evaluating large language models. Pokémon battles demand reasoning about type matchups, statistical trade-offs, and risk assessment, skills that mirror human strategic thinking. This work examines whether Large Language Models (LLMs) can serve as competent battle agents, capable of both making tactically sound decisions and generating novel, balanced game content. We developed a turn-based Pokémon battle system where LLMs select moves based on battle state rather than pre-programmed logic. The framework captures essential Pokémon mechanics: type effectiveness multipliers, stat-based damage calculations, and multi-Pokémon team management. Through systematic evaluation across multiple model architectures we measured win rates, decision latency, type-alignment accuracy, and token efficiency. These results suggest LLMs can function as dynamic game opponents without domain-specific training, offering a practical alternative to reinforcement learning for turn-based strategic games. The dual capability of tactical reasoning and content creation, positions LLMs as both players and designers, with implications for procedural generation and adaptive difficulty systems in interactive entertainment.
💡 Deep Analysis
📄 Full Content
Large Language Models as Pokémon Battle Agents: Strategic Play and
Content Generation
Daksh Jain1, Aarya Jain1, Ashutosh Desai1, Avyakt Verma1
Ishan Bhanuka1, Pratik Narang1, Dhruv Kumar1
1Birla Institute of Technology and Science, Pilani, India
Correspondence: f20230675@pilani.bits-pilani.ac.in
Abstract
Strategic decision-making in Pokémon bat-
tles presents a unique testbed for evaluating
large language models. Pokémon battles de-
mand reasoning about type matchups, statisti-
cal trade-offs, and risk assessment, skills that
mirror human strategic thinking. This work
examines whether Large Language Models
(LLMs) can serve as competent battle agents,
capable of both making tactically sound de-
cisions and generating novel, balanced game
content. We developed a turn-based Pokémon
battle system where LLMs select moves based
on battle state rather than pre-programmed
logic. The framework captures essential Poké-
mon mechanics: type effectiveness multipli-
ers, stat-based damage calculations, and multi-
Pokémon team management.
Through sys-
tematic evaluation across multiple model ar-
chitectures we measured win rates, decision
latency, type-alignment accuracy, and token
efficiency. These results suggest LLMs can
function as dynamic game opponents without
domain-specific training, offering a practical
alternative to reinforcement learning for turn-
based strategic games.
The dual capability
of tactical reasoning and content creation, po-
sitions LLMs as both players and designers,
with implications for procedural generation and
adaptive difficulty systems in interactive enter-
tainment.
1
Introduction
The intersection of artificial intelligence (AI) and
competitive turn-based strategy has long been an
area of innovation within computer science and dig-
ital media. In particular, the Pokémon battle system
serves as a sophisticated environment for testing
decision-making under complex constraints, includ-
ing elemental type-hierarchies, variable statistics,
and probabilistic outcomes. Traditional game AI
in this domain has historically relied on finite state
machines (FSMs) or minimax algorithms, which,
while functional, often struggle with the vast state-
space and the creative "meta-gaming" required for
high-level competitive play. While Reinforcement
Learning (RL) has enabled agents to optimize battle
strategies through experience, these models often
lack transparency and fail to adapt when the under-
lying "move-set" or "meta" changes unexpectedly.
Meanwhile, Large Language Models (LLMs), built
upon transformer architectures, have demonstrated
advanced reasoning and contextual understanding
(Vaswani et al., 2017). These capabilities suggest
that LLMs may bridge the gap in Pokémon AI
by making high-level strategic decisions based on
a holistic understanding of the battle state. De-
spite progress in AI-driven gaming, most existing
Pokémon simulators still rely on predefined heuris-
tic logic or heavy reinforcement training, which
lack the general reasoning to handle novel, user-
generated content. The challenge addressed in this
work is integrating LLMs as both strategic battle
commanders and creative move designers within
the structured, rule-based Pokémon environment.
Specifically, we explore how LLMs can:
1. Execute Optimal Moves: Selecting moves
and switches based on battle context (Health
Points, Statistics, and Type-Matchups).
2. Expand the Move-Space: Generating novel,
balanced, and type-consistent moves that ad-
here to the internal logic of the Pokémon fran-
chise, effectively evolving the game’s mechan-
ics.
By moving beyond static scripts, this research po-
sitions LLMs as adaptive strategists capable of
navigating the nuances of the Pokémon Battle en-
gine. The system architecture combines a deter-
ministic battle simulator with a generative LLM
interface. During gameplay, the LLM receives a
structured JSON-based game state representing the
current battlefield. The model is then required to
1
arXiv:2512.17308v1 [cs.AI] 19 Dec 2025
reason through its move selection, simulating the
"thinking" process of a competitive player. To
evaluate the efficacy of this approach, we con-
ducted LLM-vs-LLM tournaments to assess strate-
gic depth across numerous automated matches,
alongside human-agent benchmarks. We measured
performance through win rates, "turns-to-win" effi-
ciency, and type-exploitation accuracy, which is a
metric quantifying how often the model correctly
identifies elemental advantages. Furthermore, we
analyzed the trade-off between reasoning depth
(Chain-of-Thought) and operational latency. Fi-
nally, we subjected LLM-generated moves to a
dual-validation pipeline: an LLM-based "creativity
score" and a deterministic check for mechanical
balance, ensuring that new content remains com-
petitive without breaking the game’s mathematical
integrity. Our findings reveal substantial perfor-
mance variation across different models. Gemini
2.5 Flash, with chain-of-thought reasoning enabled,
achieved a