Traditional software fairness research typically emphasizes ethical and social imperatives, neglecting that fairness fundamentally represents a core software quality issue arising directly from performance disparities across sensitive user groups. Recognizing fairness explicitly as a software quality dimension yields practical benefits beyond ethical considerations, notably improved predictive performance for unprivileged groups, enhanced out-of-distribution generalization, and increased geographic transferability in real-world deployments. Nevertheless, existing bias mitigation methods face a critical dilemma: while pre-processing methods offer broad applicability across model types, they generally fall short in effectiveness compared to post-processing techniques. To overcome this challenge, we propose Correlation Tuning (CoT), a novel pre-processing approach designed to mitigate bias by adjusting data correlations. Specifically, CoT introduces the Phi-coefficient, an intuitive correlation measure, to systematically quantify correlation between sensitive attributes and labels, and employs multi-objective optimization to address the proxy biases. Extensive evaluations demonstrate that CoT increases the true positive rate of unprivileged groups by an average of 17.5% and reduces three key bias metrics, including statistical parity difference (SPD), average odds difference (AOD), and equal opportunity difference (EOD), by more than 50% on average. CoT outperforms state-of-the-art methods by three and ten percentage points in single attribute and multiple attributes scenarios, respectively. We will publicly release our experimental results and source code to facilitate future research.
Empowered by artificial intelligence (AI) techniques such as machine learning (ML) and deep learning (DL), software systems have become increasingly intelligent and widely deployed in critical decision-making scenarios, including justice [4,27,42], healthcare [2, 36,71], and finance [1,3,20]. However, these software systems may produce biased predictions against groups or individuals with specific sensitive attributes, causing significant concern about software fairness [20,28] and potentially violating anti-discrimination laws [77]. In the Software Engineering (SE) community, software fairness is generally considered an ethical issue, and developing responsible, fair software is recognized as an essential ethical responsibility for software engineers [27,30]. In fact, fairness metrics such as Equal Opportunity Difference quantify the performance disparity across groups [14,20]. Meanwhile, performance and consistency are critical software quality attributes explicitly outlined by established quality frameworks, such as McCall's Quality Model [55], Boehm's Quality Model [15], and the FURPS Quality Model [6,38]. Thus, software fairness represents not only a social and ethical concern but also a fundamental software quality issue arising from software performance disparities.
Although substantial progress has been made in the SE community to improve software fairness, one conceptual gap and one significant challenge hinder further advancement [27,56]. The conceptual gap arises because software fairness is predominantly viewed as purely an ethical issue, with research typically motivated by social requirements, policies, and laws [30,77]. This viewpoint overlooks a significant practical benefit: fairness improvement methods can enhance model performance for discriminated groups (unprivileged groups), improve out-of-distribution generalization, and enhance geographical transferability [7,64]. For example, the bias mitigation method FairMask enhances racial fairness in the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) software system, used by US courts to predict recidivism likelihood [4], by improving predictive performance for Black individuals. Such improvements facilitate the deployment of existing software to predominantly Black regions without needing new systems trained on additional datasets. Recognizing software fairness as inherently tied to software performance helps provide strong motivation for fairness research.
The primary challenge is the trade-off between the applicability and effectiveness of existing bias mitigation methods. Preprocessing methods, which mitigate bias by adjusting training data, are model-agnostic and applicable across ML, and DL. However, recent empirical studies [26,30] indicate that post-processing methods such as MAAT [27], FairMask [61], and MirrorFair [71] achieve better fairness effectiveness than leading pre-processing methods, such as Fair-SMOTE [20] and LTDD [52], in ML and DL. However, their applicability can be limited by model types due to differences in prediction mechanisms.
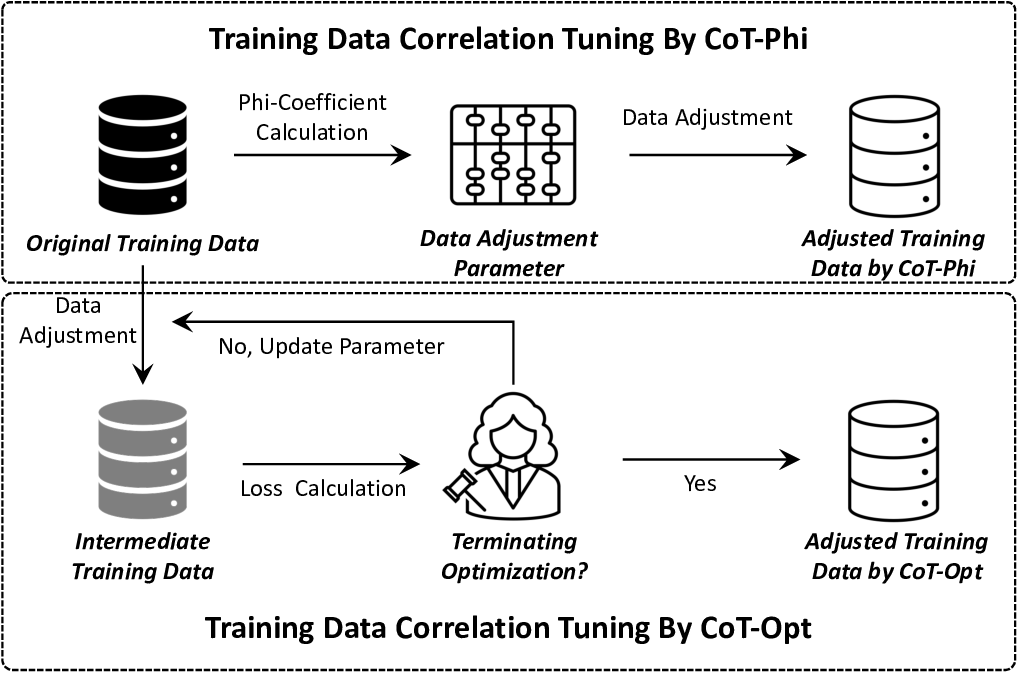
To address this dilemma and enable pre-processing methods to achieve state-of-the-art effectiveness in bias mitigation while balancing performance-fairness trade-offs, we propose Correlation Tuning (CoT). CoT adjusts sensitive attribute distributions to tune data correlations explicitly for fairness improvement. Specifically, we utilize the Phi-coefficient [34,60,65,68] to measure correlations between sensitive attributes and labels, guiding dataset adjustments to directly mitigate biases associated with sensitive attributes. Additionally, we employ a multi-objective optimization algorithm to address proxy biases caused by non-sensitive attributes [71,76].
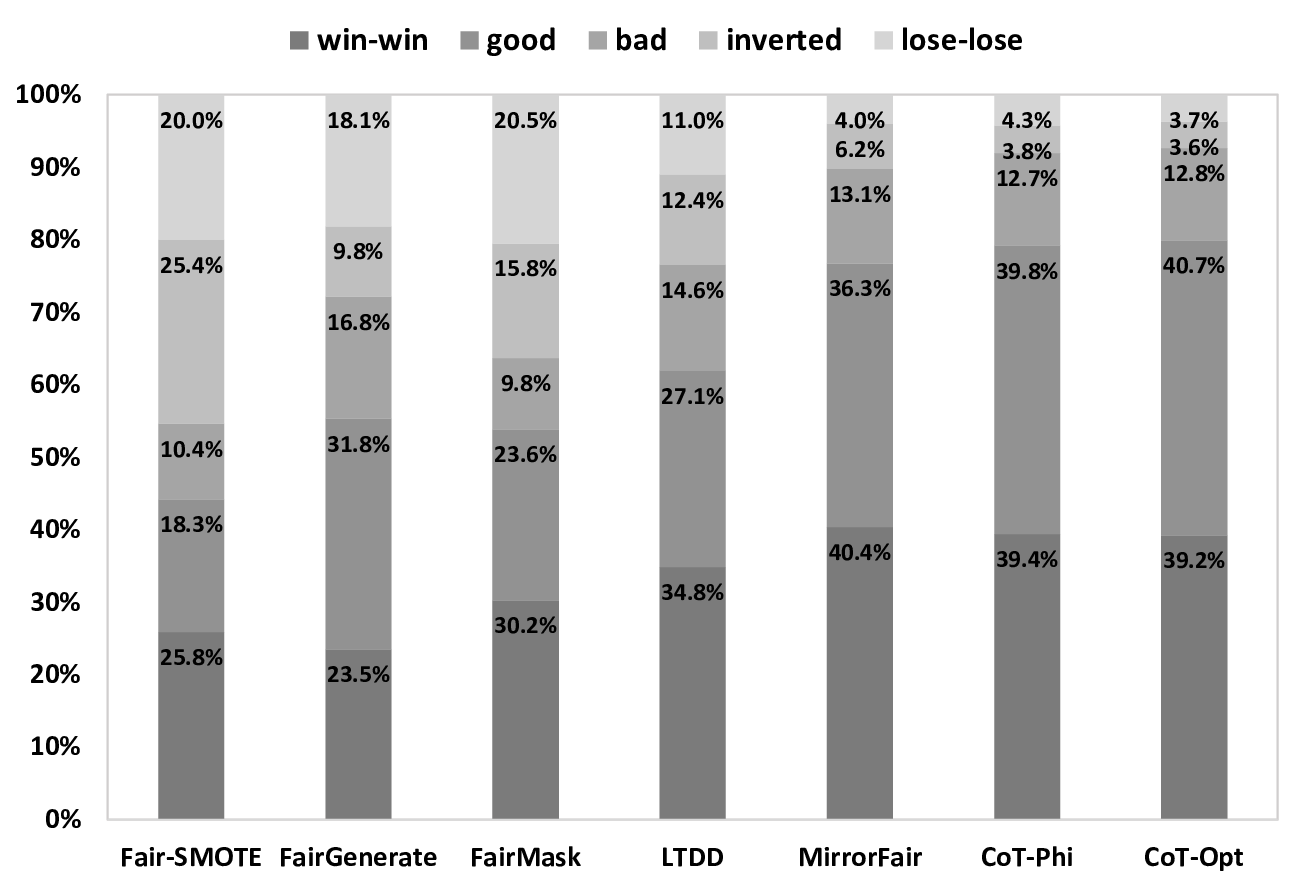
We extensively evaluate CoT across ten widely adopted fairness benchmark tasks involving six ML and DL models. The evaluation compares CoT against five state-of-the-art methods across multiple dimensions, including single and multiple sensitive attribute biases, as well as performance-fairness trade-offs and group-level performance. Our results show that CoT improves the true positive rate on unprivileged groups (e.g., “female”) by an average of 17.5% across all evaluated tasks without significantly compromising overall performance. For single attributes, CoT reduces SPD, AOD, and EOD biases by 46.9%, 58.1%, and 51.0%, respectively, surpassing existing state-of-the-art methods by more than three percentage points. CoT also outperforms the fairness-performance trade-off baseline in 79.9% of cases, exceeding state-of-the-art by three percentage points. In addressing multiple sensitive attributes, CoT reduces intersectional biases ISPD, IAOD, and IEOD by 50.3%, 42.1%, and 29.5%, respectively, surpassing existing methods by more than 10 percentage points on average.
Overall, this work makes the following contributions:
• We analyze software fairness, emphasizing that it is both an ethical concern and a funda
This content is AI-processed based on open access ArXiv data.