Transformer-based models have been widely adopted for sentiment analysis tasks due to their exceptional ability to capture contextual information. However, these methods often exhibit suboptimal accuracy in certain scenarios. By analyzing their attention distributions, we observe that existing models tend to allocate attention primarily to common words, overlooking less popular yet highly task-relevant terms, which significantly impairs overall performance. To address this issue, we propose an Adversarial Feedback for Attention(AFA) training mechanism that enables the model to automatically redistribute attention weights to appropriate focal points without requiring manual annotations. This mechanism incorporates a dynamic masking strategy that attempts to mask various words to deceive a discriminator, while the discriminator strives to detect significant differences induced by these masks. Additionally, leveraging the sensitivity of Transformer models to token-level perturbations, we employ a policy gradient approach to optimize attention distributions, which facilitates efficient and rapid convergence. Experiments on three public datasets demonstrate that our method achieves state-of-the-art results. Furthermore, applying this training mechanism to enhance attention in large language models yields a further performance improvement of 12.6%
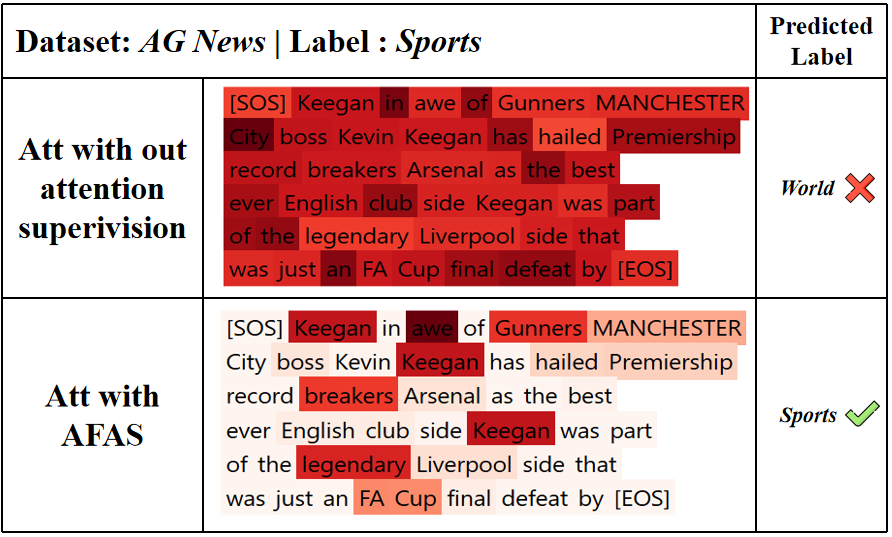
Sentiment analysis is a fundamental natural language processing task that aims to automatically detect, interpret, and categorize opinions or emotions expressed in text [6]. Existing sentiment analysis algorithms, especially recent Transformer-based models, aim to capture contextual semantics and long-range dependencies to classify sentiment at the sentence or document level [2]. Despite their success, these models often struggle to assign accurate token-level attention, misidentifying sentiment-relevant words or overemphasizing irrelevant tokens. For example, in the sentence "The movie was surprisingly engaging despite its slow start," a model might mistakenly focus on neutral words like "surprisingly" or "despite" rather than the sentiment-bearing words "engaging" or "slow, " leading to incorrect sentiment interpretation. Such inaccurate attention distributions can impair the model's ability to capture nuanced opinions, ultimately affecting classification performance.
To address the inaccuracy of token-level attention, a growing body of research has focused on attention supervision, which guides or regularizes the attention mechanism using external signals [9,16,20,21,23]. The intuition is that by aligning attention distributions with human-annotated rationales or heuristic rules [4,5], models can learn to focus on linguistically or semantically salient tokens. While these approaches have shown promise, they face two fundamental challenges. First, constructing large-scale datasets with explicit token-level annotations is prohibitively costly and often limited to specific domains, which restricts the applicability of supervised attention across diverse tasks [20]. Second, the importance of a token is highly context-dependent; static labeling strategies-whether based on lexical cues, frequency heuristics, or pre-defined annotations-lack flexibility and fail to provide accurate guidance for varying textual contexts [8]. These limitations motivate the need for dynamic, context-aware attention supervision mechanisms. However, introducing this kind of mechanism inevitably raises a combinatorial problem: even a short sequence with ten tokens yields factorial-scale permutations of possible importance rankings.
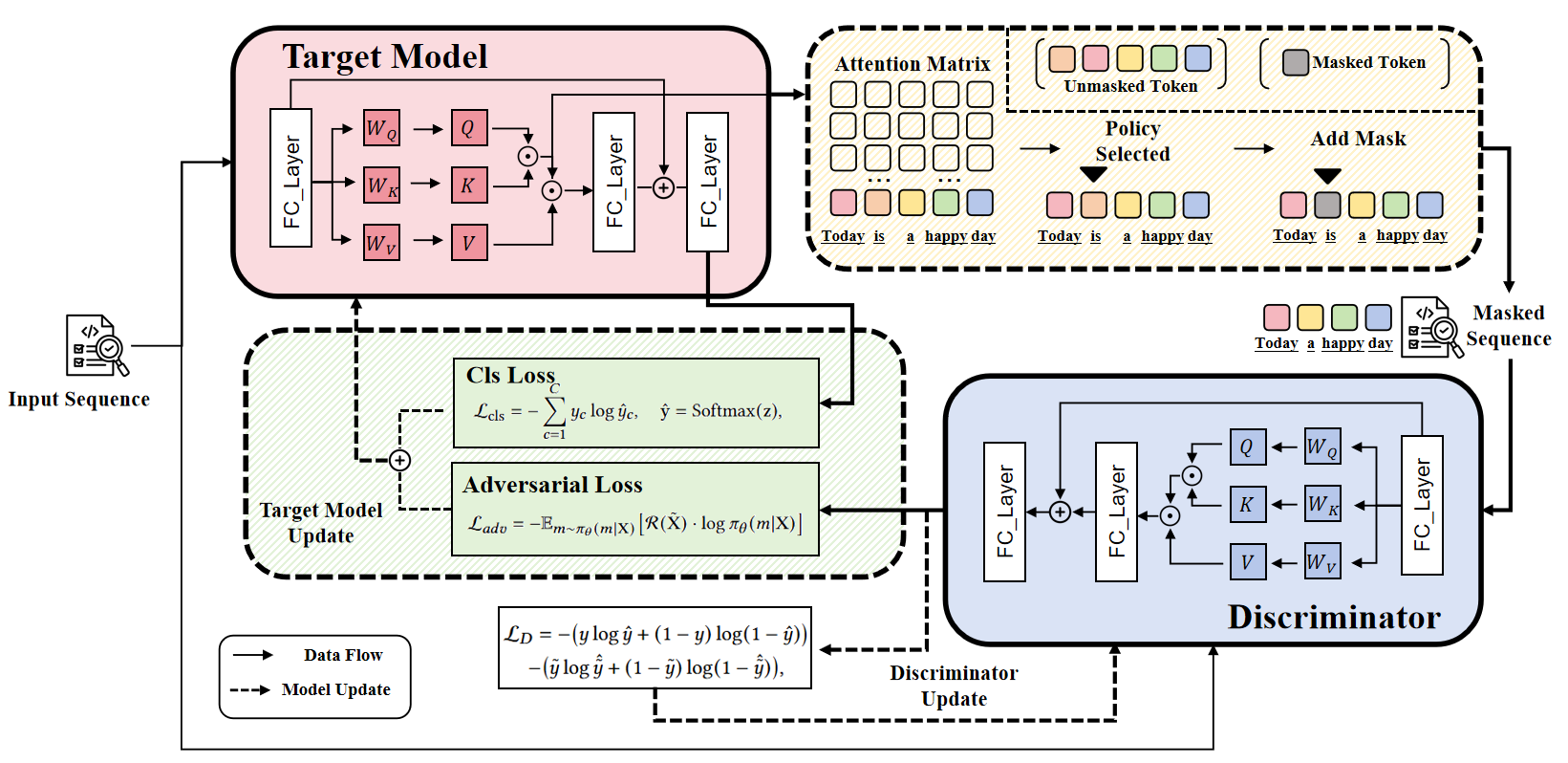
Motivated by these challenges, we propose a novel training mechanism, termed the Adversarial Feedback for Attention (AFA), which introduces a dynamic and self-adaptive supervision mechanism without relying on static annotations. Specifically, AFA comprises two core components: a target model and a discriminator. The target model first generates token-level attention distributions over the input sequence, which are then used to selectively mask or delete certain tokens. The modified sequences are fed into the discriminator, whose task is to detect whether key information has been masked. This adversarial setup incentivizes the target model to adjust its attention so that masking certain tokens-e.g., positive words in a sentiment sentence-prevents the discriminator from distinguishing whether the sequence is an unmodified neutral input or a positive input with key sentiment tokens masked. Through iterative training, this adversarial interaction produces attention distributions that are both dynamic and context-aware, allowing the model to capture nuanced sentiment signals even in complex sentences. By formulating the attention allocation as a probabilistic action space and leveraging adversarial feedback as rewards, our method circumvents the combinatorial explosion of exhaustive token ranking. Unlike conventional attention supervision methods, AFA does not require expensive manual annotations and adapts naturally to varying textual contexts. By integrating this feedback-driven attention refinement directly into the Transformer architecture, our method enhances model performance, demonstrating its potential for robust sentiment analysis in diverse datasets.
The contributions can be summarized as follows:
(1) We propose AFA, a Adversarial Feedback for Attention training mechanism to dynamically refine attention distributions without relying on external annotations.
(2) We demonstrate that AFA can be applied to existing largescale pre-trained models, enhancing their performance and producing more interpretable, context-aware attention distributions.
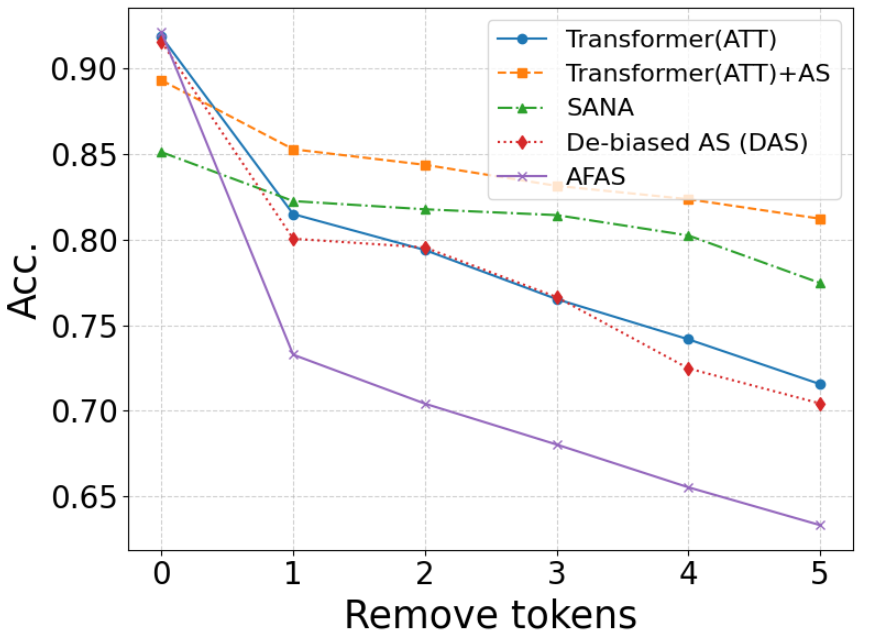
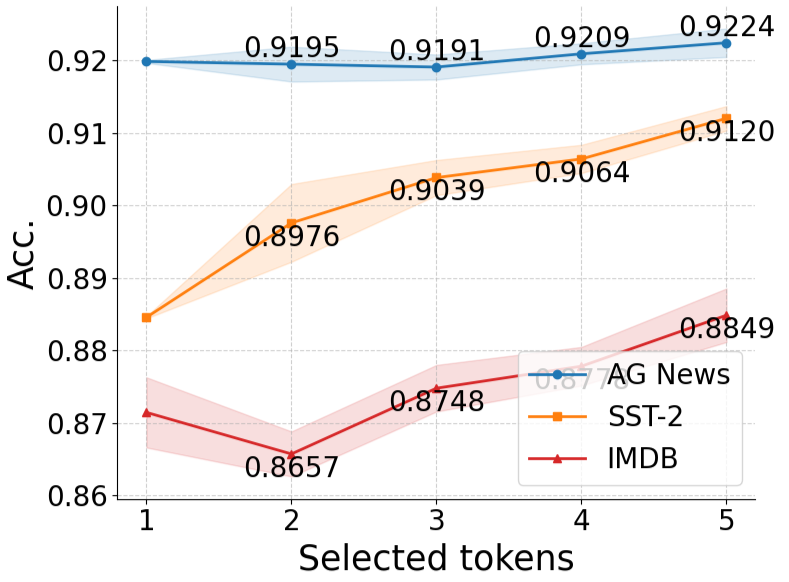
(3)We conduct experiments on three benchmark datasets and compare AFA with three existing attention supervision methods, demonstrating that it not only enhances model performance but also optimizes attention distributions, thereby validating the effectiveness of the proposed approach.
Recent studies have sought to address the problem of suboptimal or misaligned attention distributions through attention supervision. Attention supervision has emerged as a key paradigm in neural network research, aiming to guide attention distributions with external signals to enhance both model interpretability and task performance. Early approaches in this area relied heavily
This content is AI-processed based on open access ArXiv data.