Title: ShareChat: A Dataset of Chatbot Conversations in the Wild
ArXiv ID: 2512.17843
Date: 2025-12-19
Authors: Yueru Yan, Tuc Nguyen, Bo Su, Melissa Lieffers, Thai Le
📝 Abstract
While academic research typically treats Large Language Models (LLM) as generic text generators, they are distinct commercial products with unique interfaces and capabilities that fundamentally shape user behavior. Current datasets obscure this reality by collecting text-only data through uniform interfaces that fail to capture authentic chatbot usage. To address this limitation, we present ShareChat, a large-scale corpus of 142,808 conversations (660,293 turns) sourced directly from publicly shared URLs on ChatGPT, Perplexity, Grok, Gemini, and Claude. ShareChat distinguishes itself by preserving native platform affordances, such as citations and thinking traces, across a diverse collection covering 101 languages and the period from April 2023 to October 2025. Furthermore, ShareChat offers substantially longer context windows and greater interaction depth than prior datasets. To illustrate the dataset's breadth, we present three case studies: a completeness analysis of intent satisfaction, a citation study of model grounding, and a temporal analysis of engagement rhythms. This work provides the community with a vital and timely resource for understanding authentic user-LLM chatbot interactions in the wild. The dataset is publicly available via Hugging Face.
💡 Deep Analysis
📄 Full Content
SHARECHAT: A Dataset of Chatbot Conversations in the Wild
Yueru Yan
Tuc Nguyen
Bo Su
Melissa Lieffers
Thai Le
Indiana University
Bloomington, USA
{yueryan,tucnguye,subo,mealieff,tle}@iu.edu
Abstract
While academic research typically treats Large
Language Models (LLM) as generic text gener-
ators, they are distinct commercial products
with unique interfaces and capabilities that
fundamentally shape user behavior. Current
datasets obscure this reality by collecting text-
only data through uniform interfaces that fail to
capture authentic chatbot usage. To address this
limitation, we present SHARECHAT, a large-
scale corpus of 142,808 conversations (660,293
turns) sourced directly from publicly shared
URLs on ChatGPT, Perplexity, Grok, Gemini,
and Claude. SHARECHAT distinguishes itself
by preserving native platform affordances, such
as citations and thinking traces, across a diverse
collection covering 101 languages and the pe-
riod from April 2023 to October 2025. Further-
more, SHARECHAT offers substantially longer
context windows and greater interaction depth
than prior datasets. To illustrate the dataset’s
breadth, we present three case studies: a com-
pleteness analysis of intent satisfaction, a cita-
tion study of model grounding, and a temporal
analysis of engagement rhythms. This work
provides the community with a vital and timely
resource for understanding authentic user-LLM
chatbot interactions in the wild. The dataset is
publicly available via Hugging Face 1 2.
1
Introduction
Conversational Large Language Model (LLM)-
based chatbot services have evolved rapidly in the
past three years. The first widely adopted general-
purpose LLM chatbot, ChatGPT, was launched in
November 2022 and has reached more than 700
million weekly active users by mid-2025 (OpenAI
Research, 2025). Following this success, many
companies quickly released their own chatbot ser-
1https://github.com/raye22/ShareChat
2https://huggingface.co/datasets/tucnguyen/Sh
areChat
vices, which also attracted substantial public at-
tention. For example, Anthropic introduced the
Claude families in 2023 (Anthropic, 2023, 2024,
2025), Google deployed the Gemini family of mod-
els (Anil et al., 2023), xAI launched Grok as a
chatbot integrated with the social media platform X
(xAI, 2023), and Perplexity emerged as an answer
engine that combines conversational interaction
with web search (Perplexity AI, 2024).
Although all of these services are built on text-
based LLMs, they differ in interface design, sup-
ported features, and safety policies, which in turn
shape how users interact with them. For exam-
ple, Grok can surface live posts from X when
providing answers, Claude models are optimized
and evaluated for coding, math, and analysis tasks
(Anthropic, 2023, 2024), and Perplexity consis-
tently presents responses with explicit source ci-
tations (Perplexity AI, 2024). Commercial sys-
tems typically undergo continuous reinforcement
learning and fine tuning on conversation logs and
human feedback (Ouyang et al., 2022; Bai et al.,
2022; Chen et al., 2024), which tends to reinforce
platform-specific strengths and norms over time.
However, current research often fails to cap-
ture the complexity of real-world LLM deploy-
ment. While commercial platforms have evolved
into complex ecosystems with unique features,
the scientific community relies on datasets that
homogenize these interactions. As seen in both
synthetic (Xu et al., 2024; Li et al., 2025; Ding
et al., 2023) and real-world datasets including Wild-
Chat (Zhao et al., 2024), LMSYS-Chat-1M (Zheng
et al., 2024), OpenAssistant (Köpf et al., 2023),
Alpaca (Taori et al., 2023), ShareGPT3, and
Dolly (Conover et al., 2023), current corpora strip
away interface context, treating diverse products as
identical, generic text boxes. For instance, Wild-
Chat (Zhao et al., 2024) compiles about one mil-
3https://sharegpt.com/
arXiv:2512.17843v3 [cs.CL] 27 Jan 2026
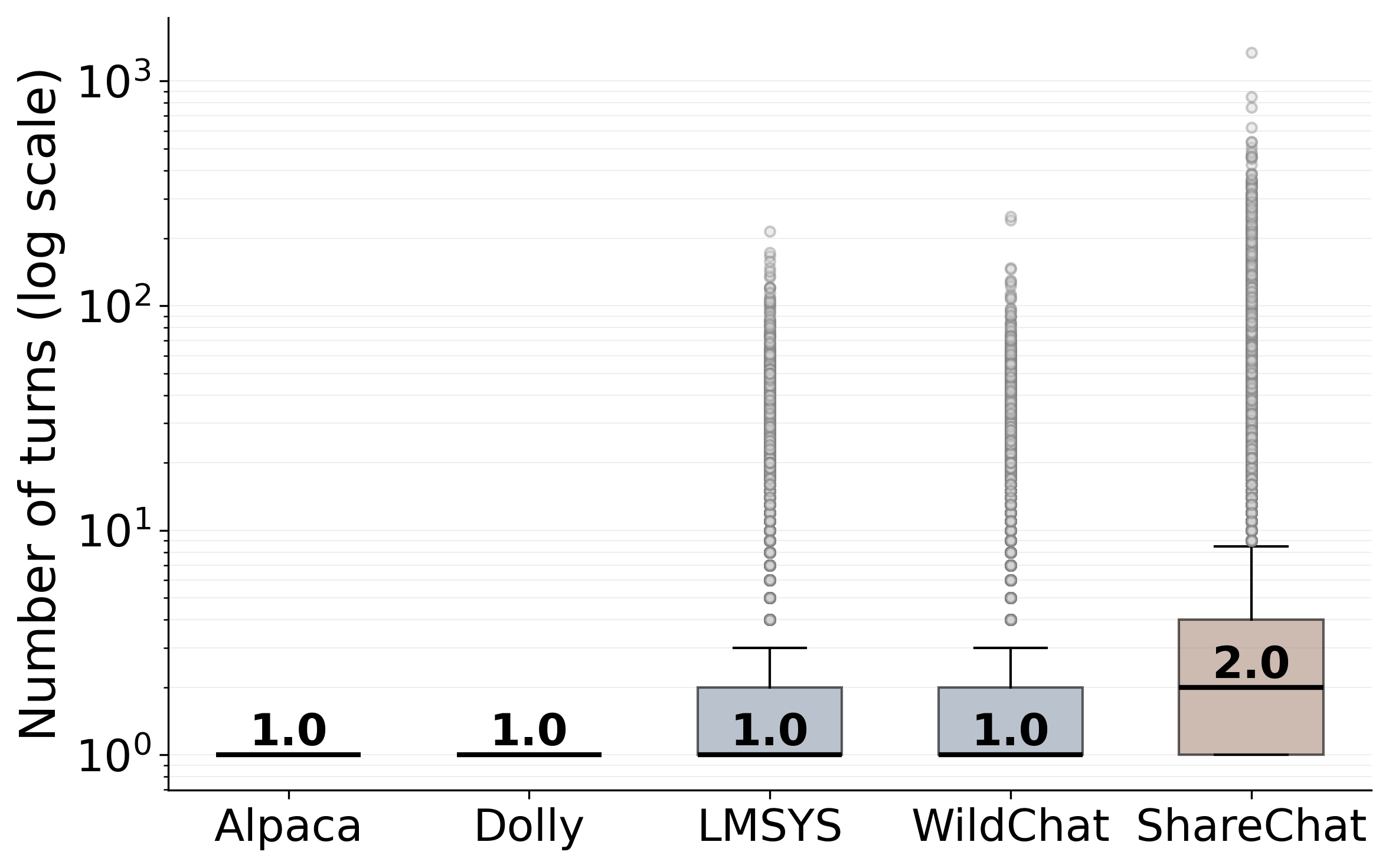
Dataset
#Convs
#Users
#Turns
Avg. Turns
#User Tok
#Chatbot Tok
#Langs
Existing Public Datasets
Alpaca
52,002
–
52,002
1.00
19.67±15.19
64.51±64.85
1
Open Assistant
46,283
13,500
108,341
2.34
33.41±69.89
211.76±246.71
11
Dolly
15,011
–
15,011
1.00
110.25±261.14
91.14±149.15
1
ShareGPT
94,145
–
330,239
3.51
94.46±626.39
348.45±269.93
41
LMSYS-Chat-1M
1,000,000 210,479 2,020,000
2.02
69.83±143.49
215.71±1858.09
65
WILDCHAT
1,039,785 204,736 2,641,054
2.54
295.58±1609.18
441.34±410.91
68
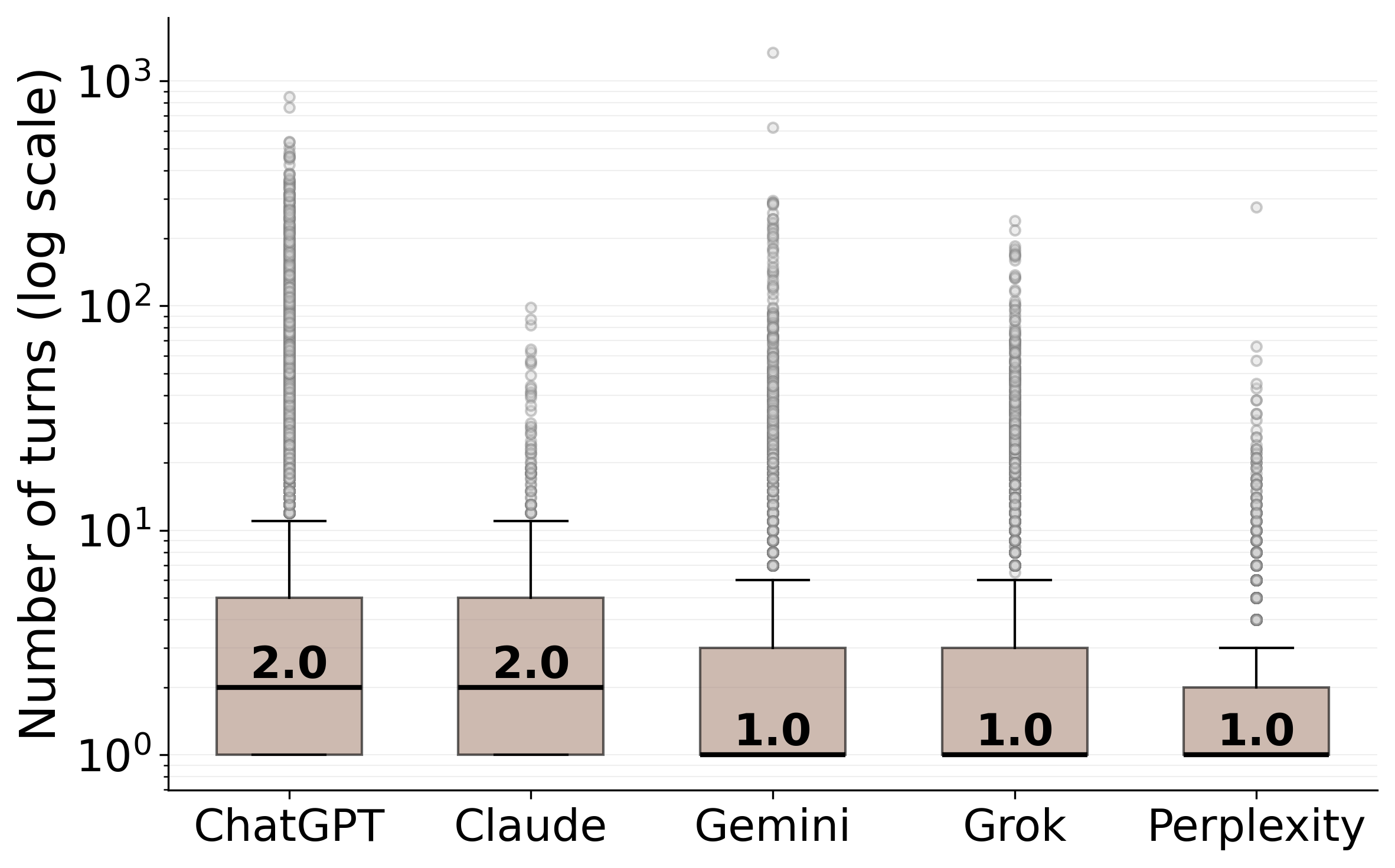
Our Multi-Platform Dataset
Multi-Platform (Total)
142,808
–
660,293
4.62
135.04±1820.88 1, 115.30±1764.81
101
Per-Platform Breakdown
ChatGPT
102,740
–
542,148
5.28
142.35±1191.57 1, 230.25±2448.38
101
Perplexity
17,305
4,763
24,378
1.41
33.07±261.74
573.33±932.90
45
Grok
14,415
–
53,094
3.69
179.04±6999.90 1, 141.74±1506.97
60
Gemini
7,402
–
36,422
4.92
184.62±1571.62
803.23±1609.27
47
Claude
946
–
4,251
4.49
138.67±2213.46
576.16±1649.61
19
Table 1: Comprehensive dataset comparison showing existing corpora, multi-platform aggregate, and per-platform
breakdown. Our