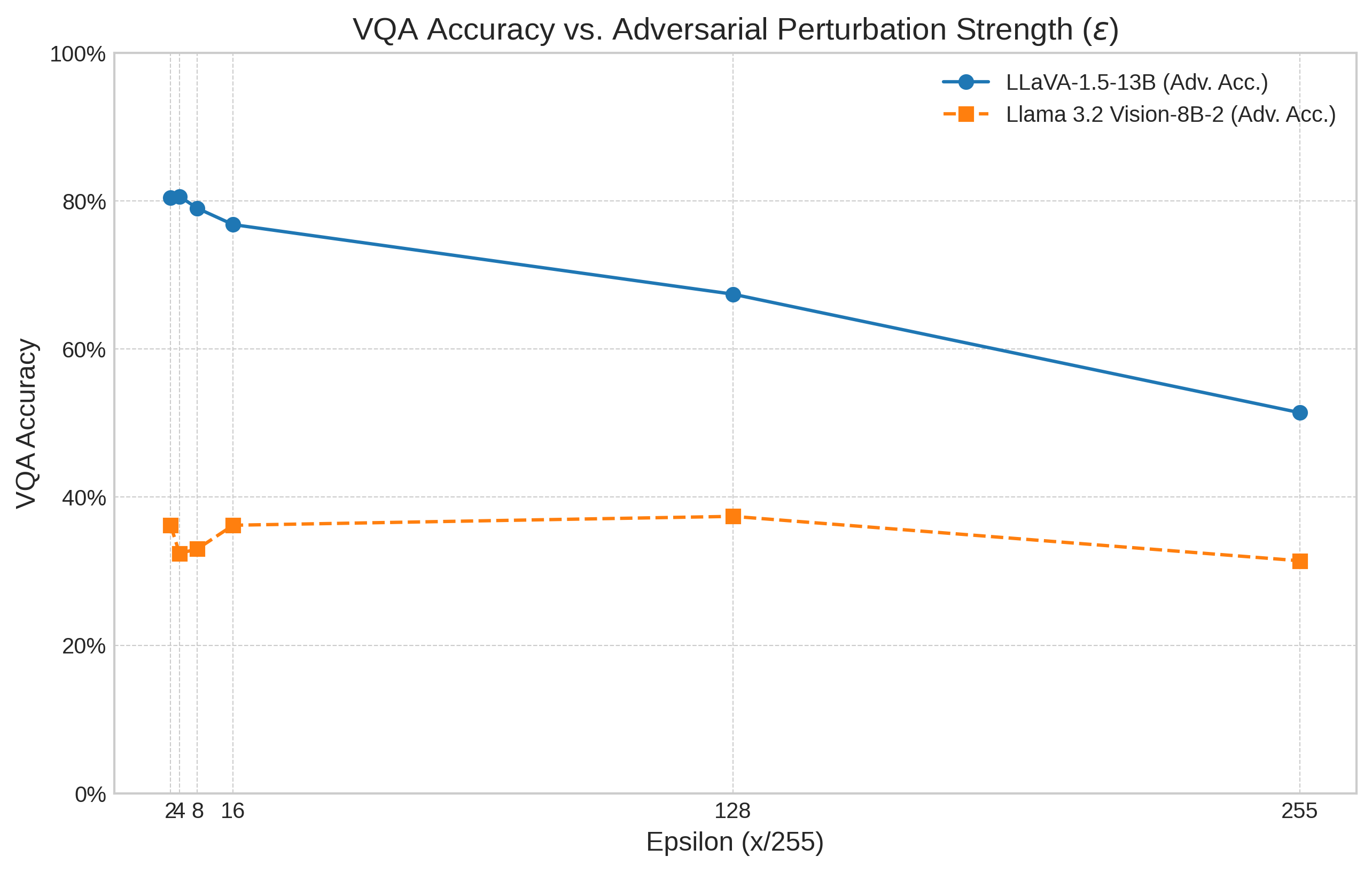
With the increase in deep learning, it becomes increasingly difficult to understand the model in which AI systems can identify objects. Thus, an adversary could aim to modify an image by adding unseen elements, which will confuse the AI in its recognition of an entity. This paper thus investigates the adversarial robustness of LLaVA-1.5-13B and Meta's Llama 3.2 Vision-8B-2. These are tested for untargeted PGD (Projected Gradient Descent) against the visual input modality, and empirically evaluated on the Visual Question Answering (VQA) v2 dataset subset. The results of these adversarial attacks are then quantified using the standard VQA accuracy metric. This evaluation is then compared with the accuracy degradation (accuracy drop) of LLaVA and Llama 3.2 Vision. A key finding is that Llama 3.2 Vision, despite a lower baseline accuracy in this setup, exhibited a smaller drop in performance under attack compared to LLaVA, particularly at higher perturbation levels. Overall, the findings confirm that the vision modality represents a viable attack vector for degrading the performance of contemporary open-weight VLMs, including Meta's Llama 3.2 Vision. Furthermore, they highlight that adversarial robustness does not necessarily correlate directly with standard benchmark performance and may be influenced by underlying architectural and training factors.
Recent advances in artificial intelligence have led to the development of foundation models -large-scale models pre-trained on vast, diverse datasets, exhibiting remarkable capabilities across a range of downstream tasks (Bommasani et al. 2021). Prominent examples include Large Language Models (LLMs), which process text, and more recently, Vision-Language Models (VLMs), which integrate visual understanding alongside language capabilities. The proliferation of these models, particularly powerful open-source variants like Meta's Llama series (Touvron et al. 2023a,b;Grattafiori et al. 2024), has democratised access but simultaneously introduced significant security considerations (Kapoor et al. 2024). While the security of foundation models is an active research area, much focus has centred on the textual vulnerabilities of LLMs, such as prompt injection or jailbreaking. The integration of vision in VLMs, however, creates an expanded attack surface, introducing vulnerabilities specific to the visual modality that remain comparatively underexplored.
Specifically, VLMs are susceptible to adversarial image attacks -carefully crafted, often imperceptible, perturbations applied to input images that can deceive the model and cause erroneous or unintended textual outputs. Understanding this vulnerability is critical, as these multimodal models are increasingly integrated into diverse applications, from content generation to assistive technologies. This paper addresses the pressing need to assess the adversarial robustness of the vision component within state-of-the-art open-weight VLMs. It specifically investigates models related to the influential Llama family, namely LLaVA and Llama 3.2 Vision, and offers one of the first systematic comparisons of visual adversarial robustness in popular open models. This shows that robustness does not always align with standard accuracy metrics.
This paper aims to investigate the security implications arising from the visual modality in these open-source foundation models. The primary focus is on evaluating the adversarial robustness of two prominent VLMs related to Meta’s Llama family: LLaVA and Llama 3.2 Vision, using adversarial image attacks. Additionally, the research seeks to analyse how differences in model architecture and training methodologies might influence their robustness against such visual perturbations. The objectives are as follows:
• Present the state-of-the-art in the technical evolution of language and com- puter vision models; integration of multimodality with pre-trained models; and adversarial machine learning attacks & defences.
• Implement LLaVA and Llama 3.2 Vision and test robustness against adversarial examples using Projected Gradient Descent.
• Quantify, compare and evaluate the results considering the models’ architecture and training.
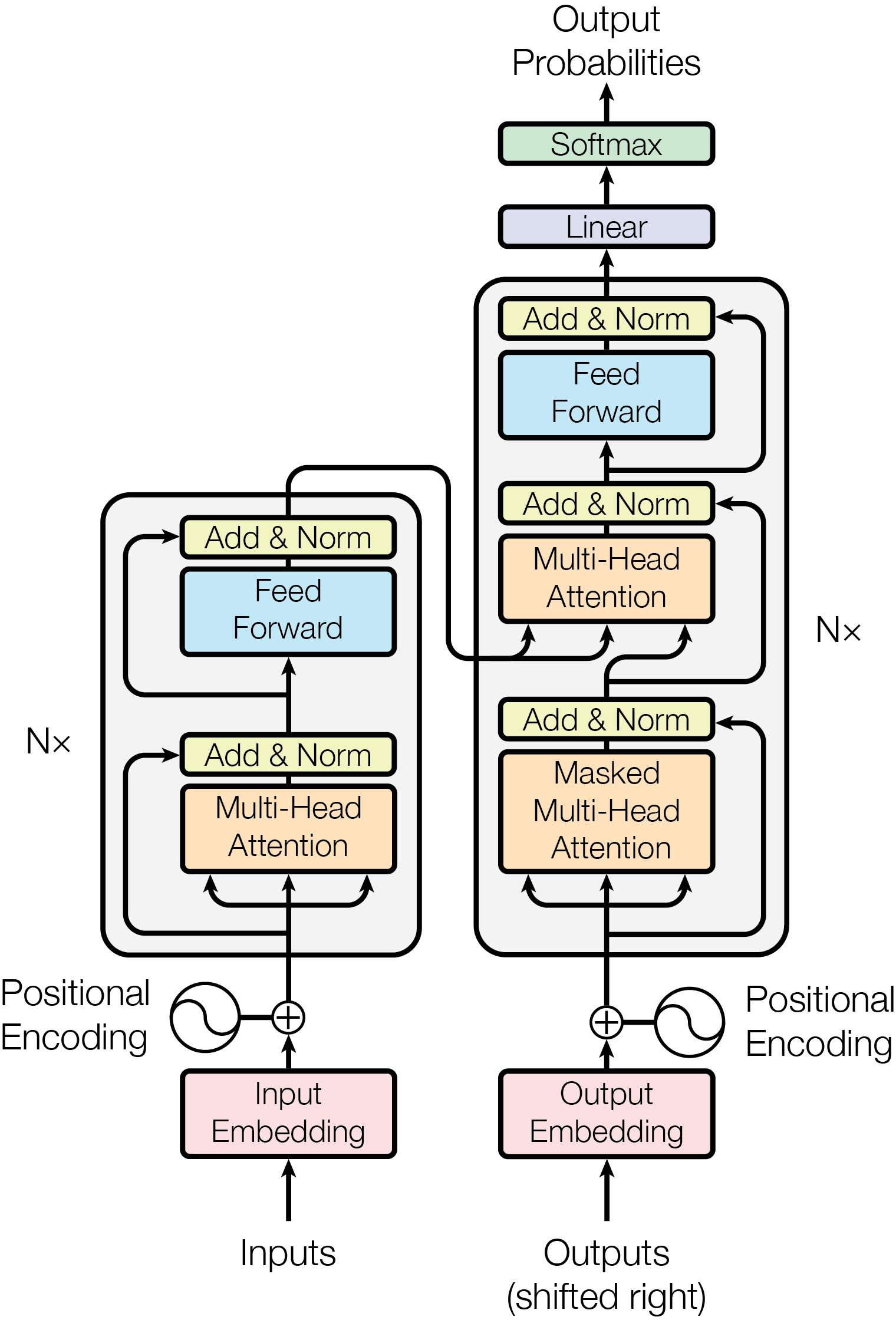
Recent advancements in artificial intelligence, such as the Transformer (Vaswani et al. 2017), have given rise to large language models but also underpin the development of vision-language models. This section lays the groundwork for this evolution, providing the background necessary for language and vision model development, as well as adversarial robustness, to understand the research questions, related work, and methodology of this study.
Over the past decade, the field of natural language processing (NLP) has been marked by a shift away from traditional statistical methods towards deep learning models. Prior approaches such as n-gram models (Chen and Goodman 1996), Hidden Markov Models (HMMs) (Rabiner 1989), and phrase-based machine translation (Koehn et al. 2003) have now been replaced as state of the art (SOTA) by neural network approaches.
Although early neural network research, including backpropagation, dates back to the 1980s (Rumelhart et al. 1986), these models did not achieve widespread use in NLP due to data and hardware limitations. Indeed, it was not until 2012 that large-scale deep learning gained mainstream attention in AI research. This breakthrough occurred when AlexNet -a convolutional neural network (CNN) -achieved remarkable results on the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC-2012). This annual challenge, considered a benchmark for SOTA computer vision, involved the classification of over a million images across 1,000 object categories. AlexNet achieved a top-5 error rate of only 15.3%, significantly outperforming the second-best method, which had an error rate of 26.2% (Krizhevsky et al. 2012). Although this result occurred in the field of computer vision, it demonstrated the effectiveness of large-scale, GPU-accelerated deep learning and reignited interest in applying neural networks to NLP tasks.
Following the breakthrough, Recurrent Neural Networks (RNNs) or, specifically, a type known as Long Short-Term Memory (LSTM) (Hochreiter and Schmidhuber 1997), originally developed in 1997 to address the vanishing gradient issue, emerged as a promising candidate for appl
This content is AI-processed based on open access ArXiv data.