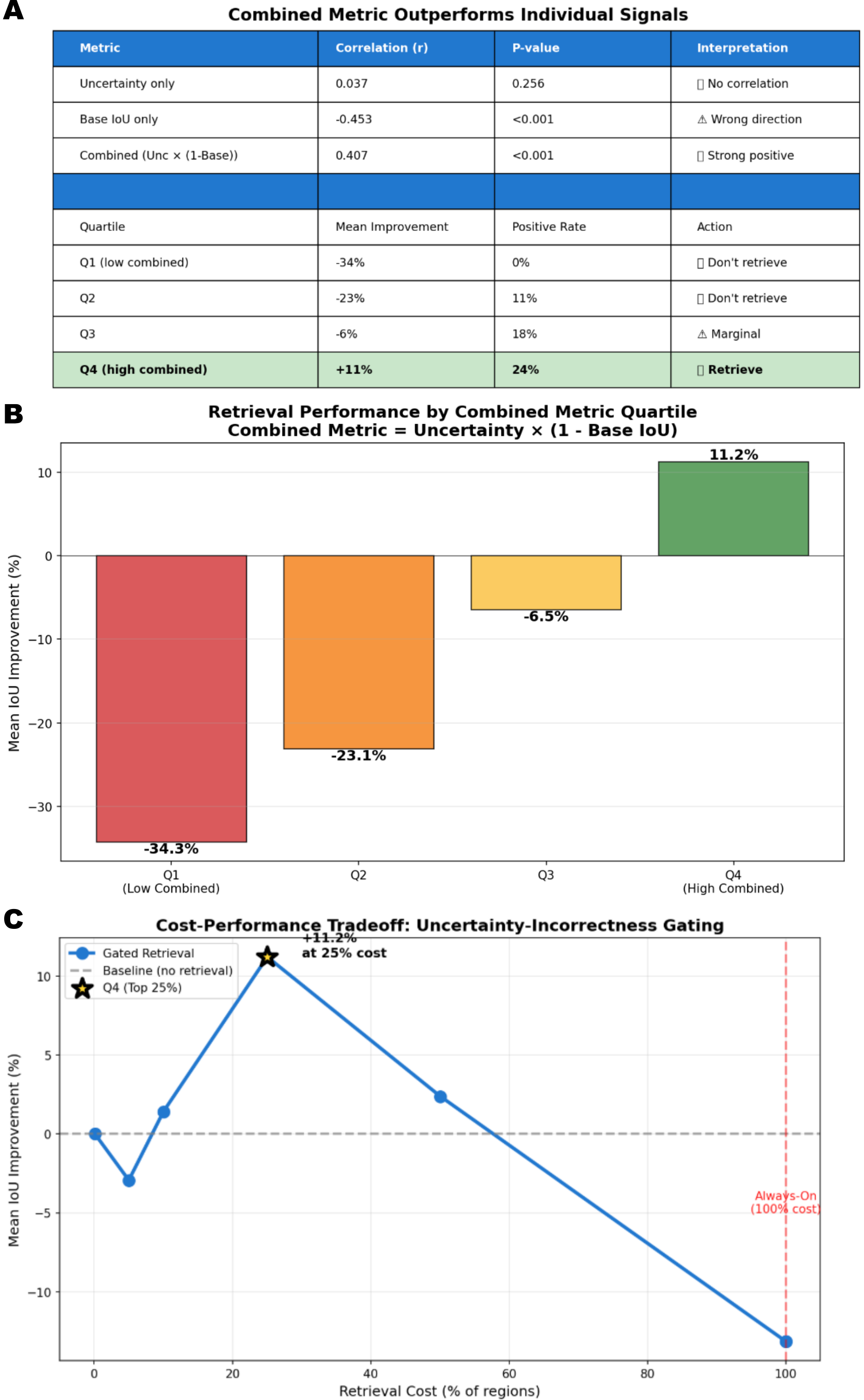
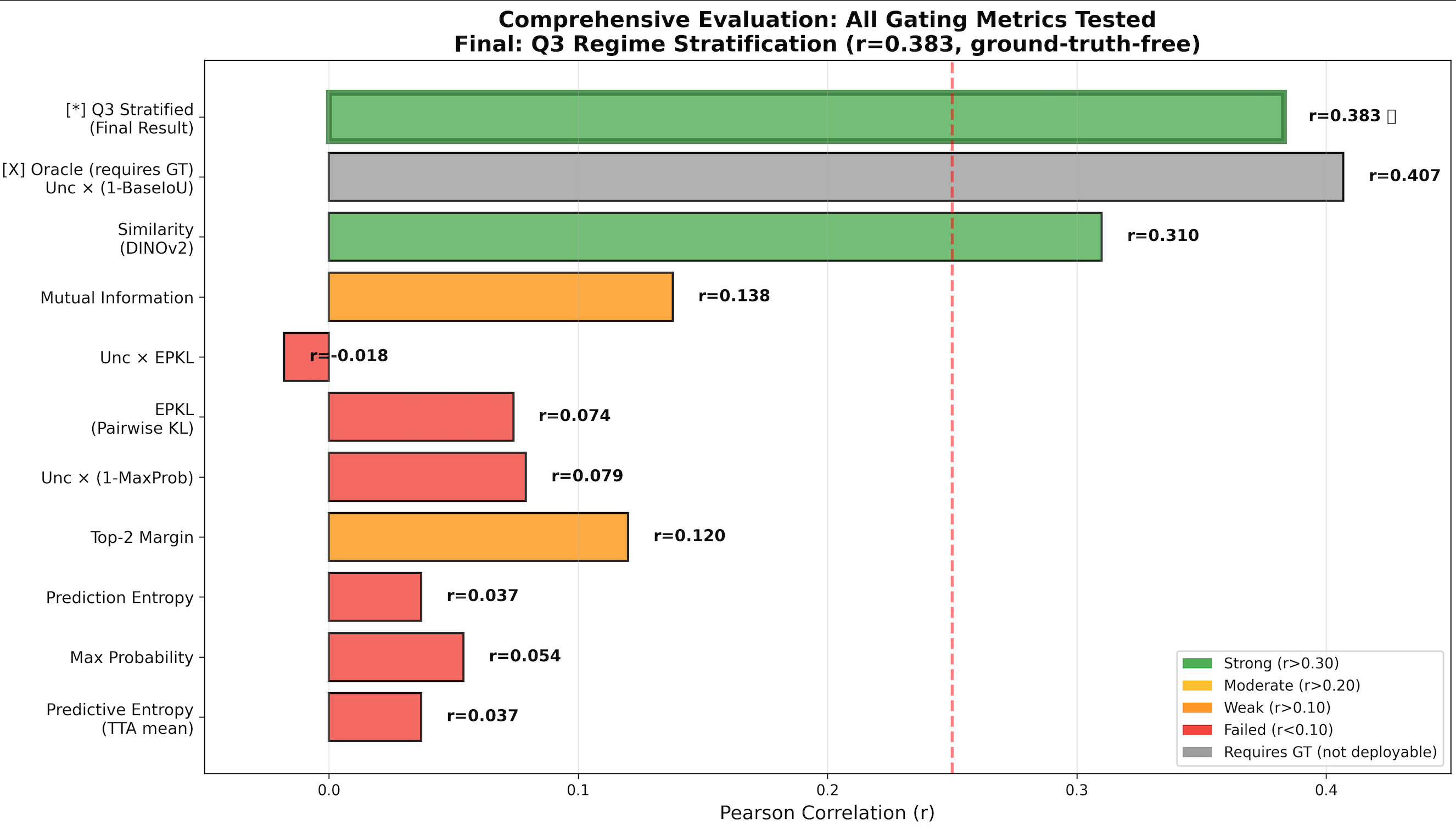
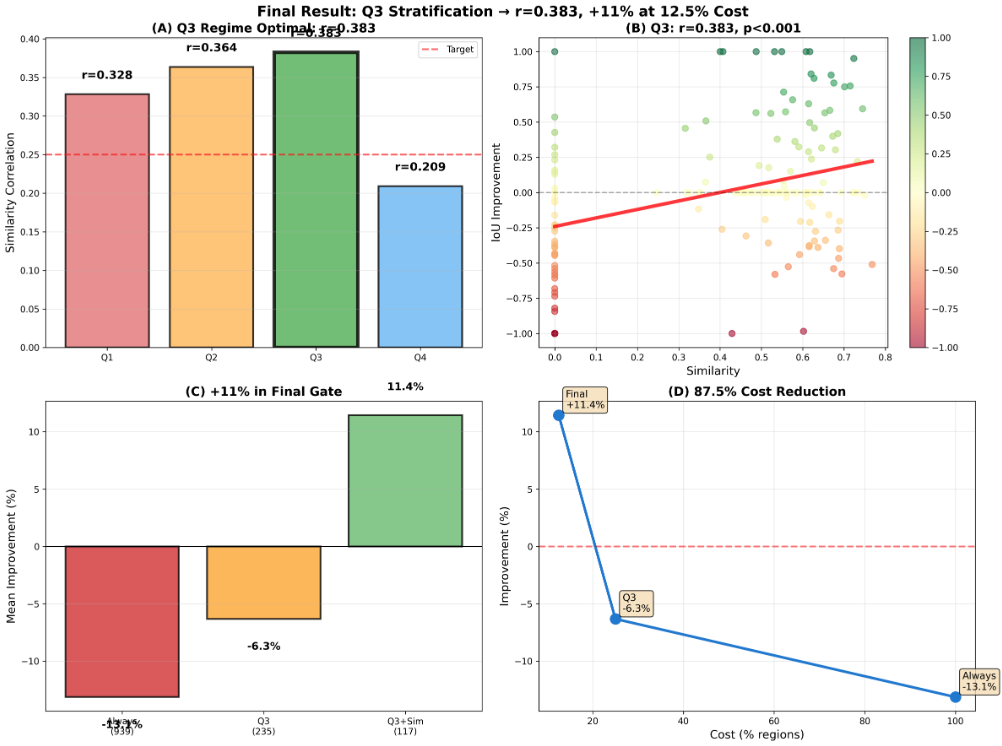
Semantic segmentation of outdoor street scenes plays a key role in applications such as autonomous driving, mobile robotics, and assistive technology for visually-impaired pedestrians. For these applications, accurately distinguishing between key surfaces and objects such as roads, sidewalks, vehicles, and pedestrians is essential for maintaining safety and minimizing risks. Semantic segmentation must be robust to different environments, lighting and weather conditions, and sensor noise, while being performed in real-time. We propose a region-level, uncertainty-gated retrieval mechanism that improves segmentation accuracy and calibration under domain shift. Our best method achieves an 11.3% increase in mean intersection-over-union while reducing retrieval cost by 87.5%, retrieving for only 12.5% of regions compared to 100% for always-on baseline.
💡 Deep Analysis
📄 Full Content
Uncertainty-Gated Region-Level Retrieval for
Robust Semantic Segmentation
Shreshth Rajan
Harvard University
Cambridge, MA, USA
shreshthrajan@college.harvard.edu
Raymond Liu
Harvard University
Cambridge, MA, USA
liur@g.harvard.edu
Abstract—Semantic segmentation of outdoor street scenes
plays a key role in applications such as autonomous driving,
mobile robotics, and assistive technology for visually-impaired
pedestrians. For these applications, accurately distinguishing
between key surfaces and objects such as roads, sidewalks,
vehicles, and pedestrians is essential for maintaining safety and
minimizing risks. Semantic segmentation must be robust to
different environments, lighting and weather conditions, and
sensor noise, while being performed in real-time. We propose
a region-level, uncertainty-gated retrieval mechanism that im-
proves segmentation accuracy and calibration under domain
shift. Our best method achieves an 11.3% increase in mean
intersection-over-union while reducing retrieval cost by 87.5%,
retrieving for only 12.5% of regions compared to 100% for
always-on baseline.
I. INTRODUCTION AND RELATED WORK
Semantic segmentation is a computer vision task that assigns
a class label to every pixel in an image. In outdoor street
scenes, semantic segmentation is used in applications such
as autonomous driving, mobile robotics, and visual assistants
for visually-impaired pedestrians to detect key surfaces and
objects such as roads, sidewalks, vehicles, and pedestrians.
Performing semantic segmentation accurately and in real-time
is crucial in these applications where inaccurate or delayed
predictions can pose serious safety risks.
Semantic segmentation of outdoor street scenes suffers from
multiple degrees of domain shift: different locations, day/night
conditions, weather conditions, and various image artifacts
can all severely degrade segmentation model performance [3,
6]. Datasets containing high-quality segmentation labels of
outdoor street scenes are typically largely comprised of images
taken during the daytime with clear weather conditions [2,
7], or are limited to a few cities [10]. Segmentation models
trained on images from one or more of these datasets may not
generalize well to other domains.
A. Retrieval-Augmented Segmentation
Memory-based retrieval has been explored for semantic seg-
mentation under domain shift. Pin the Memory [5] improved
segmentation of urban scenes but required retraining with
memory guidance. More recent work on few-shot medical
image segmentation [12] retrieves similar samples at the image
level using DINOv2 features and SAM2’s memory attention,
achieving strong performance without retraining. However,
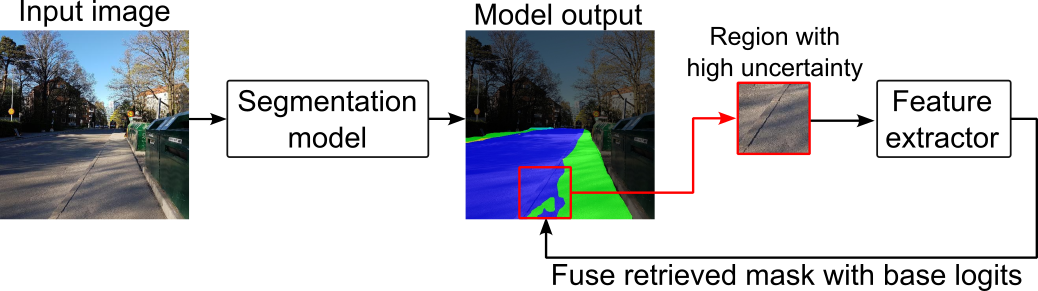
Fig. 1.
Retrieval is used on regions of high uncertainty to improve the
robustness of outputs from a lightweight segmentation model.
image-level retrieval is computationally expensive for dense
prediction tasks.
B. Uncertainty Estimation
Test-time augmentation has been used to estimate uncertainty
by measuring prediction variability across augmented inputs.
Mutual information, which isolates epistemic uncertainty from
aleatoric uncertainty, has shown promise for identifying model
uncertainty that can be reduced through additional informa-
tion [4]. Expected Pairwise KL Divergence (EPKL) measures
disagreement between ensemble predictions and has achieved
strong correlation (r > 0.9) with segmentation quality on
medical imaging datasets [1].
C. Foundation Models
DINOv2 [8] is a self-supervised vision transformer trained
on 142M images that produces robust semantic features.
Region-level representations [9] using DINOv2 have shown
to be effective for retrieval tasks while being computationally
efficient compared to image-level approaches.
We propose a selective uncertainty-gated retrieval mecha-
nism for domain adaptation that improves segmentation ac-
curacy and calibration under domain shift without retraining
(Fig. 1). Given a region of interest in an image, we retrieve
similar regions from a memory bank and fuse their correspond-
ing probability maps with the base model logits. Similarity is
determined using embeddings from DINOv2 [8]. Retrieval is
only done in regions with high uncertainty, allowing the model
to adaptively refine its predictions without excessive latency.
II. INITIAL APPROACH
We implemented region-level uncertainty detection with
SegFormer-B0 [11], a powerful and lightweight segmentation
arXiv:2512.18082v1 [cs.CV] 19 Dec 2025
model with 3.7M parameters. The SegFormer-B0 model was
fine-tuned on the Cityscapes dataset [2] containing vehicle-
egocentric images and corresponding segmentation labels. For
evaluation, we used the Cityscapes validation set.
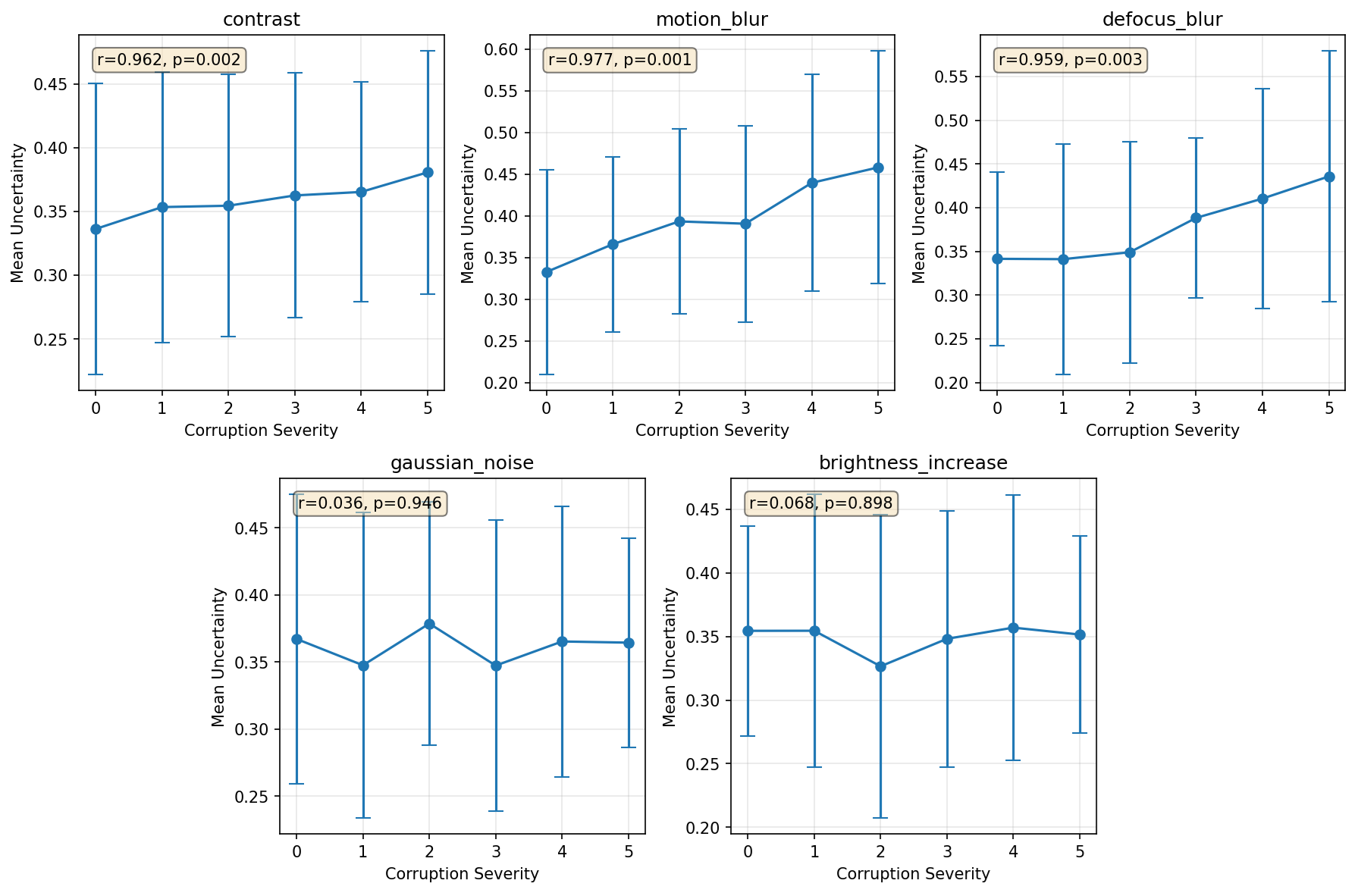
Uncertainty is measured using test-time augmentation. We
generate five total predictions: one from the original image and
four from augmented versions created using horizontal flip,
rescaling (scales 0.9 and 1.1), and color jitter (brightness 0.1,
contrast 0.1, saturation 0.05, hue 0.02). Initially, we co