Title: From Prompt to Product: A Human-Centered Benchmark of Agentic App Generation Systems
ArXiv ID: 2512.18080
Date: 2025-12-19
Authors: Marcos Ortiz, Justin Hill, Collin Overbay, Ingrida Semenec, Frederic Sauve-Hoover, Jim Schwoebel, Joel Shor
📝 Abstract
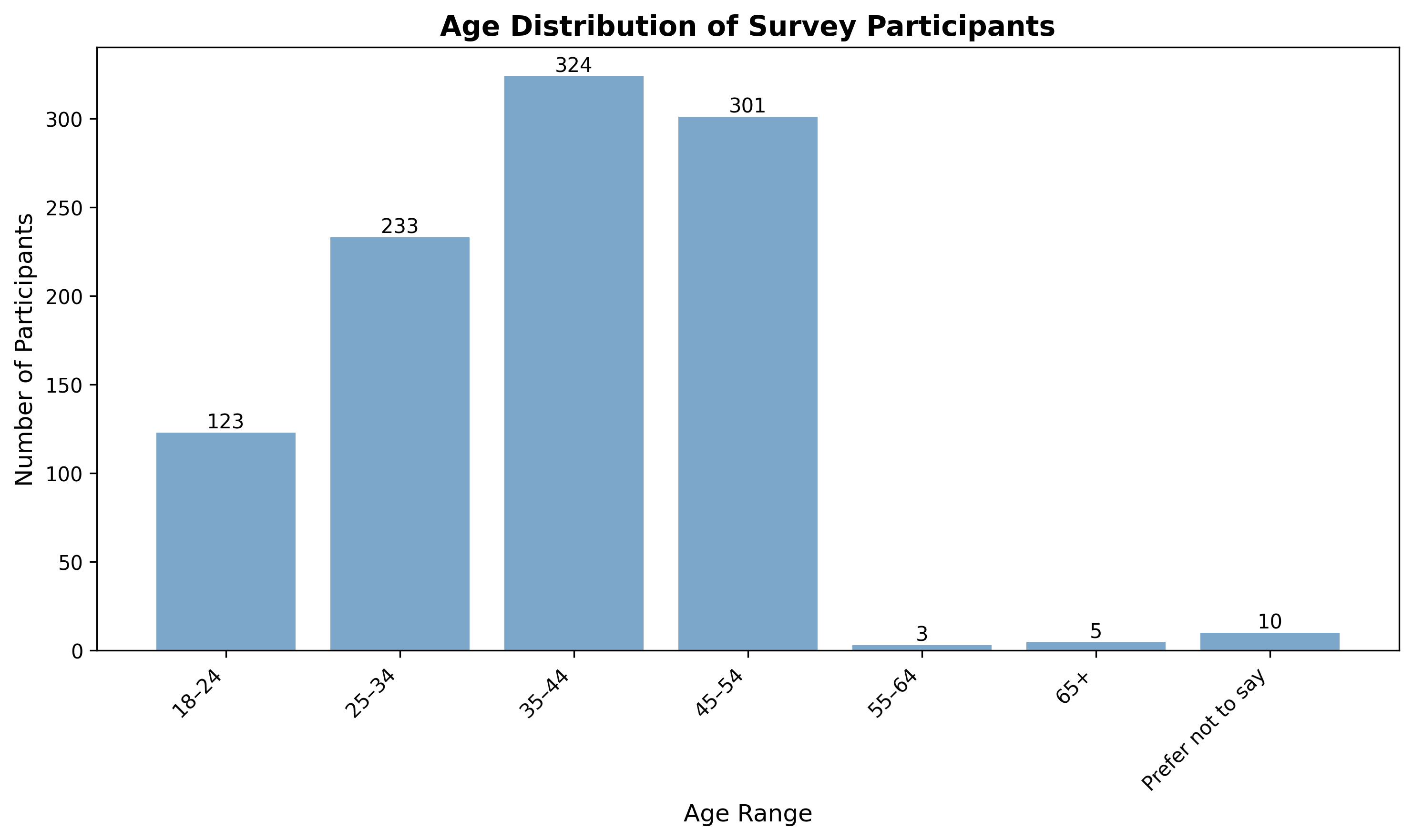
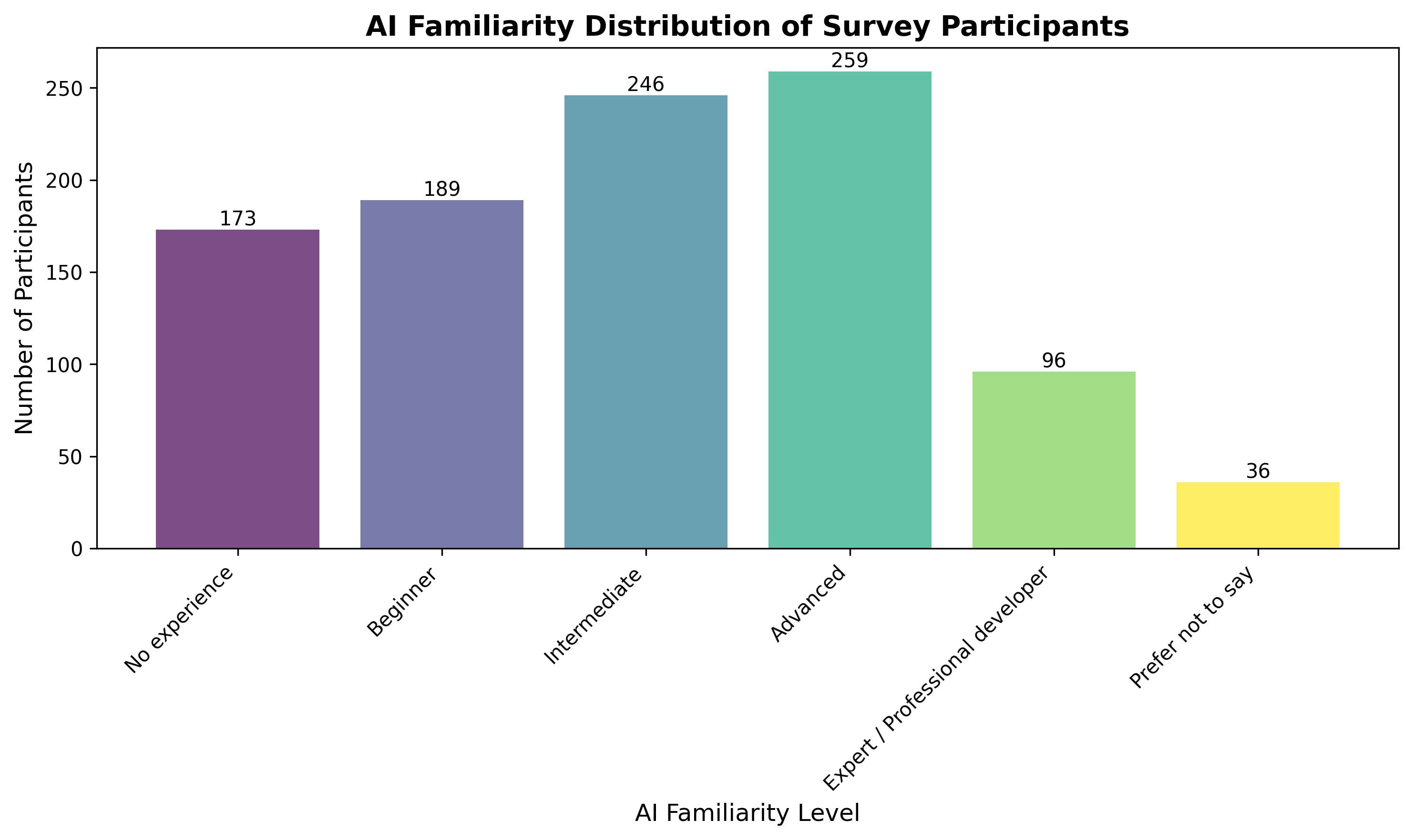
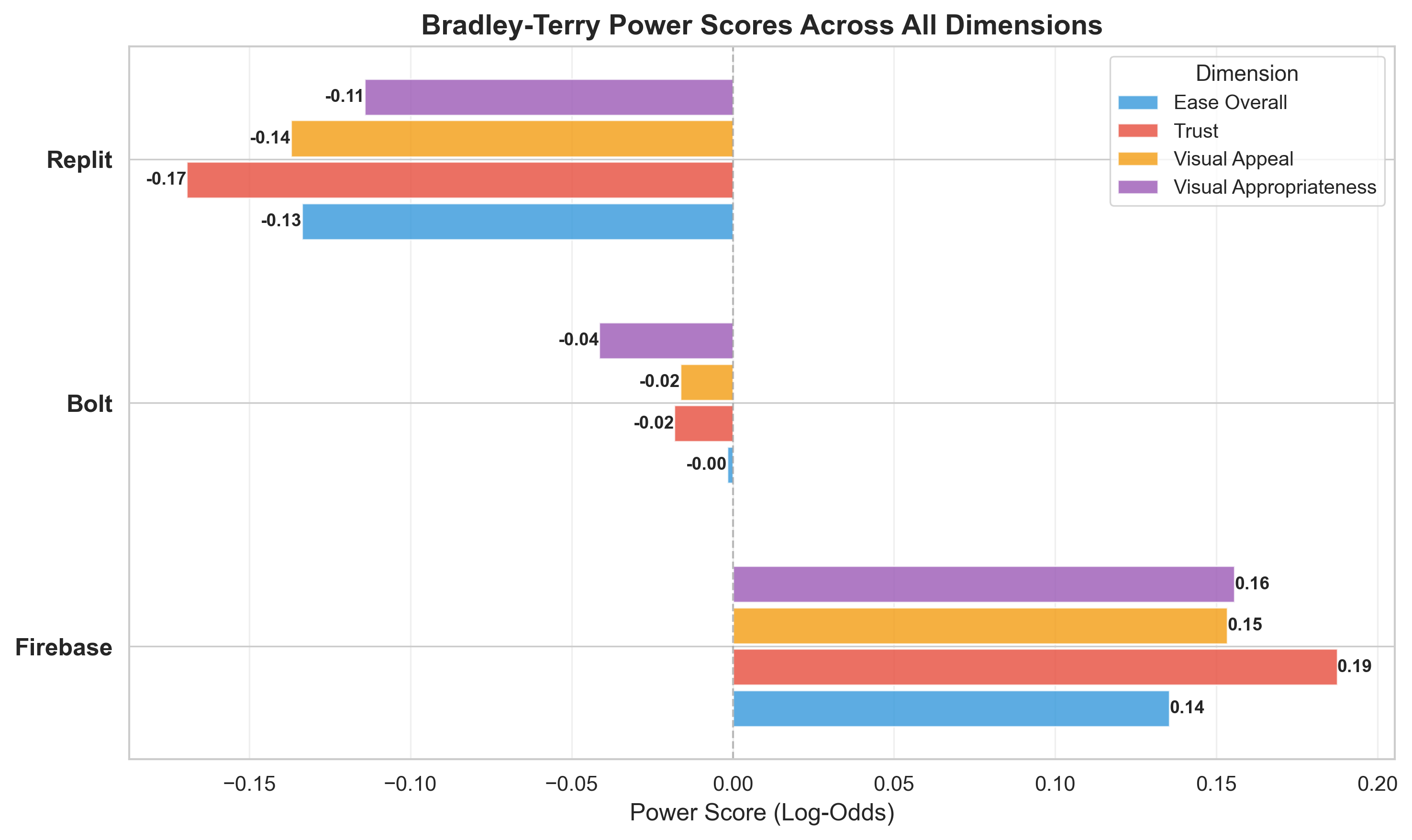
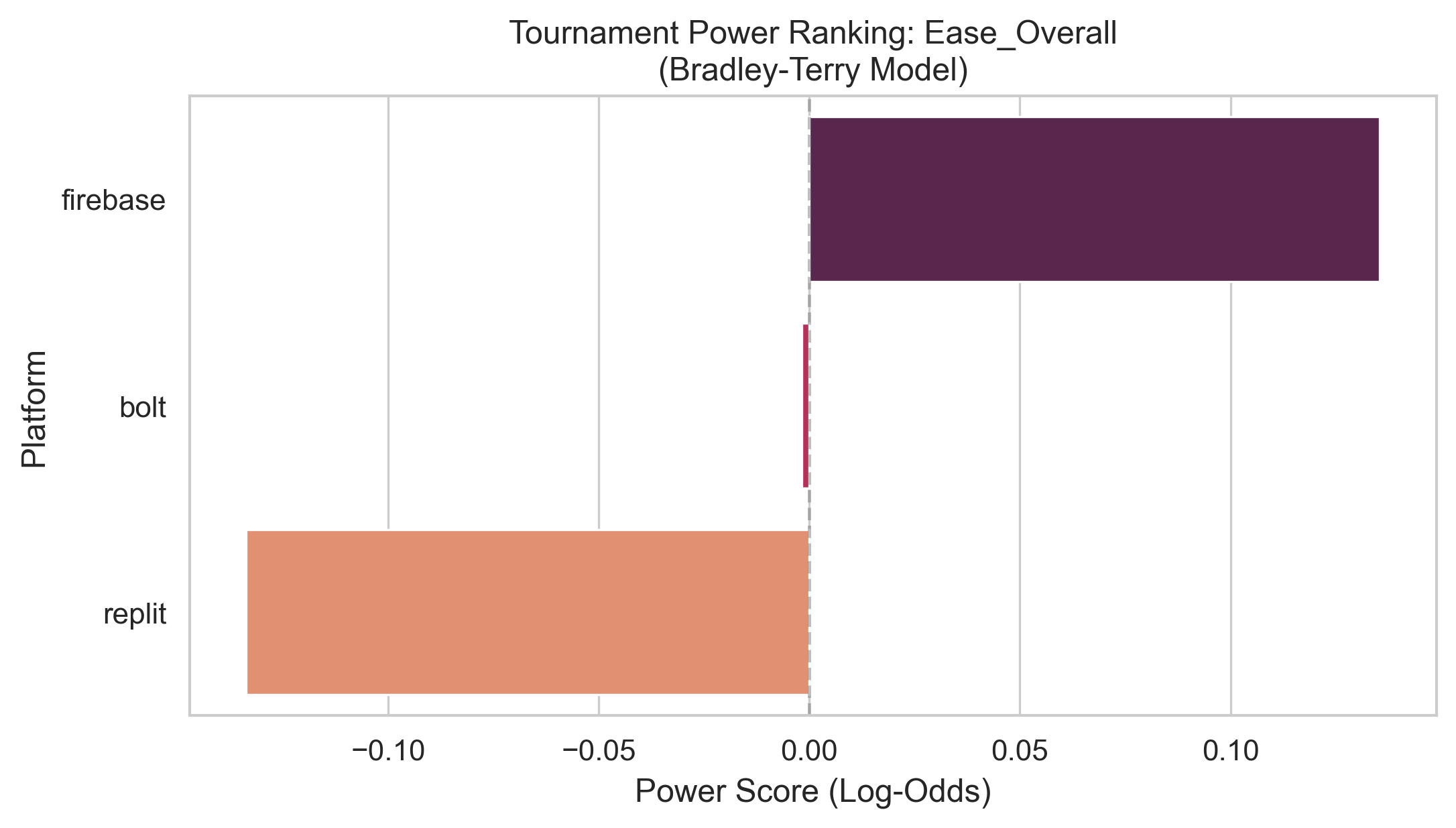
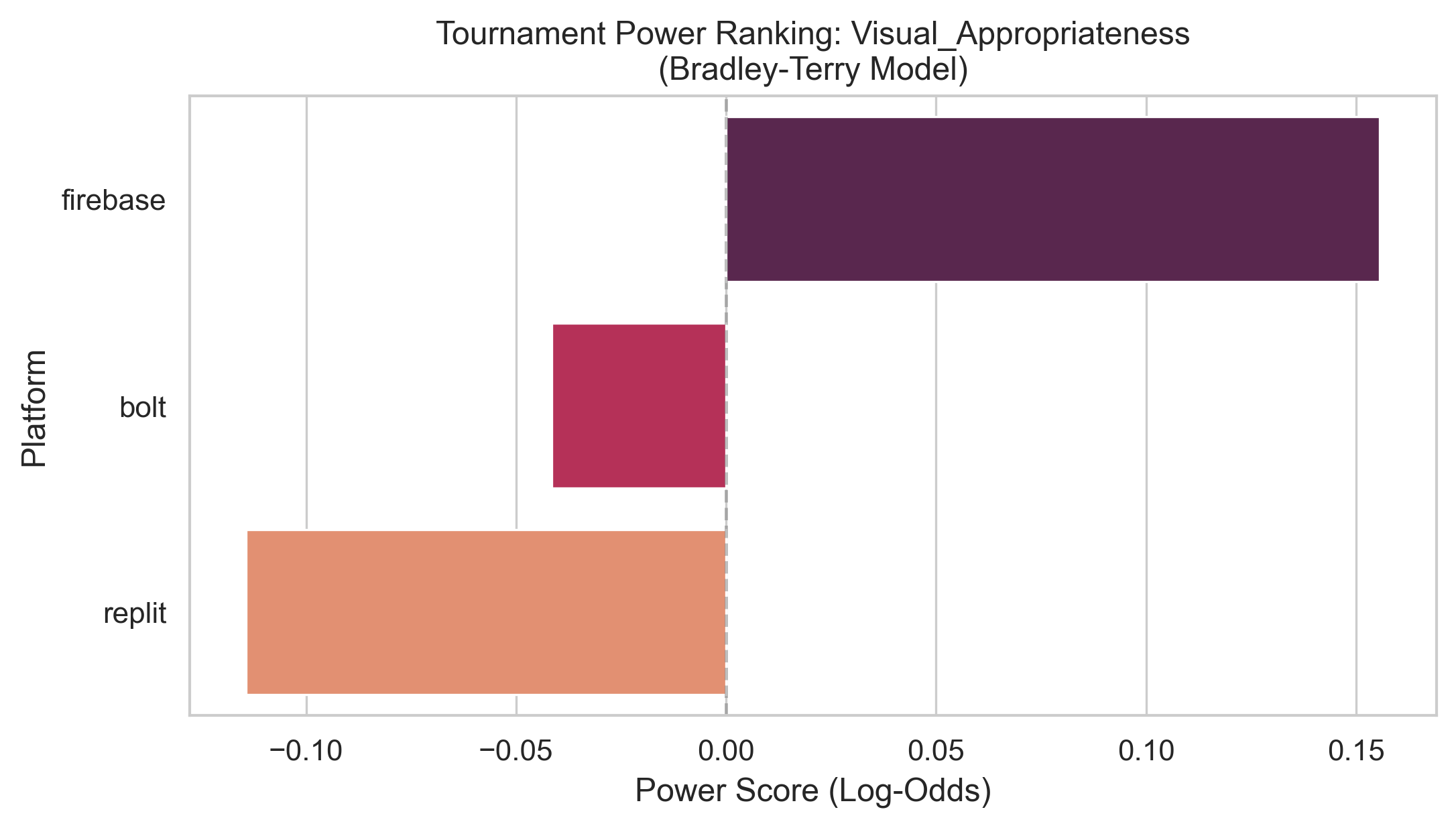
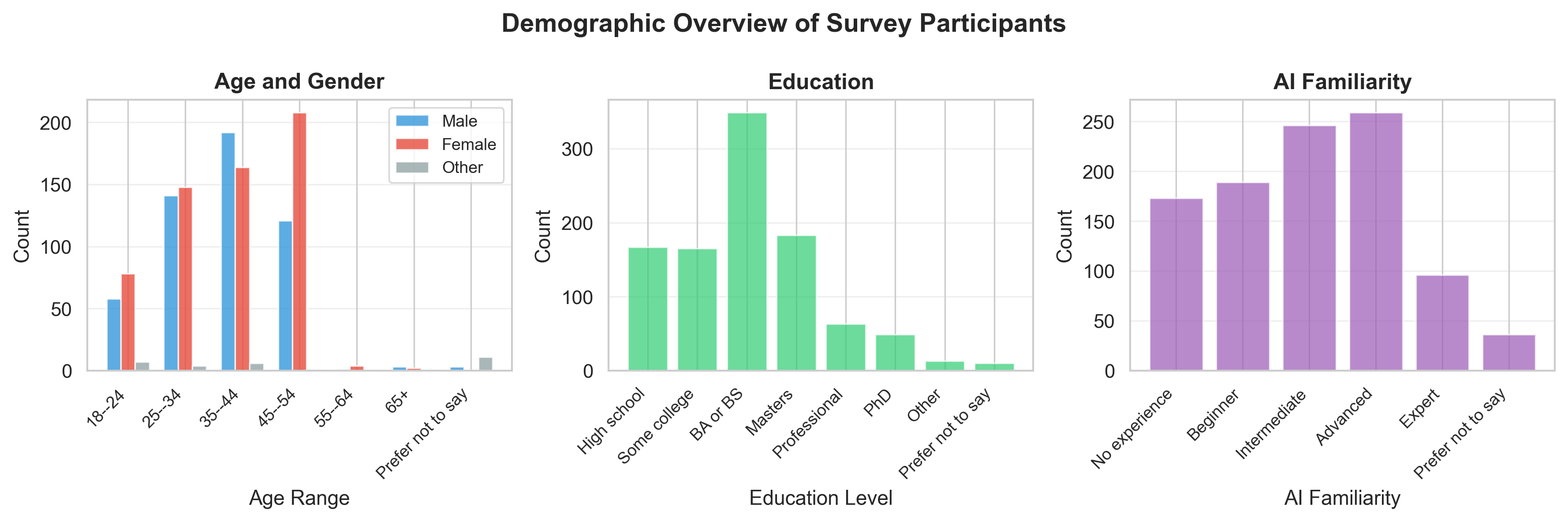
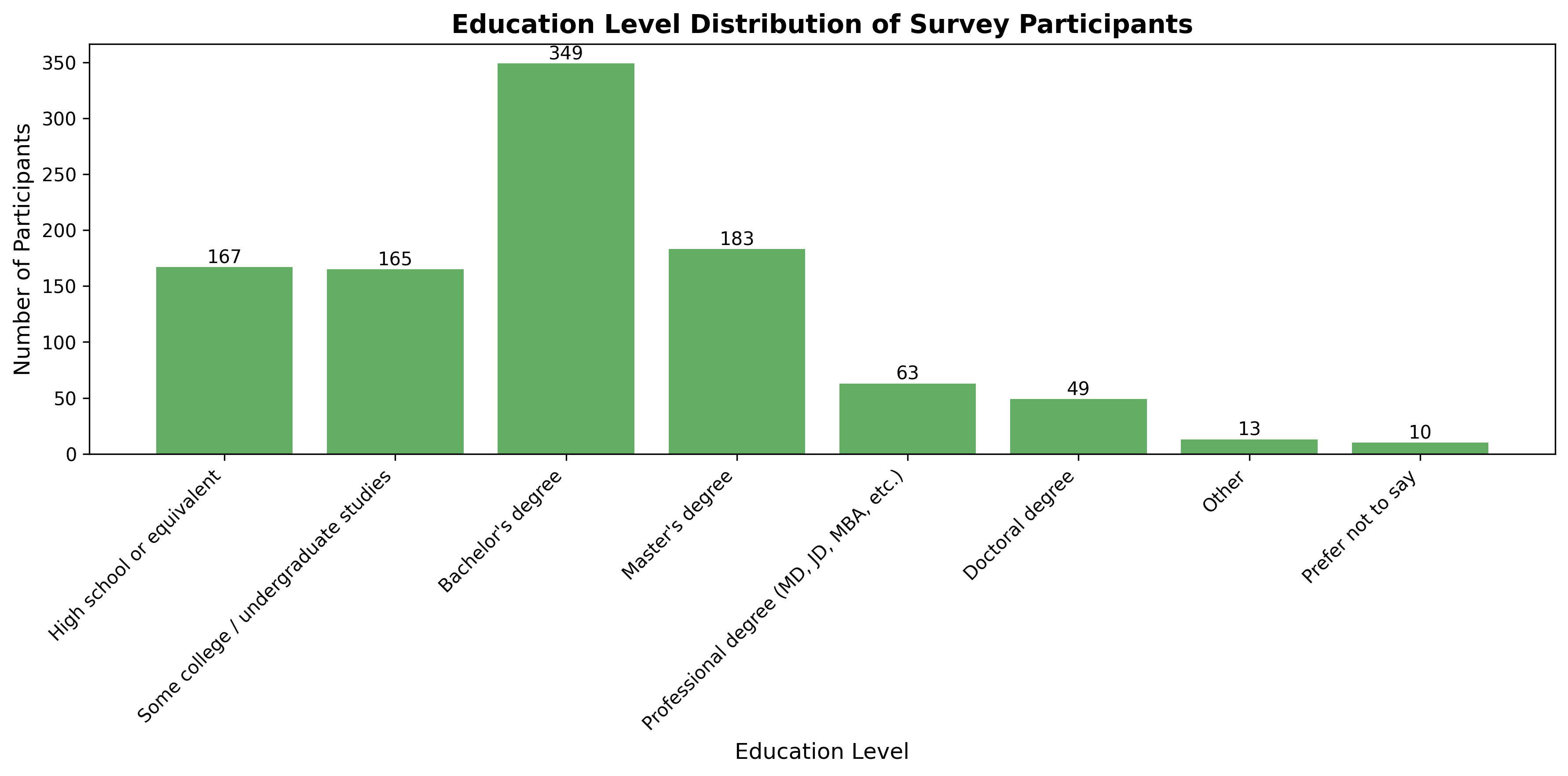
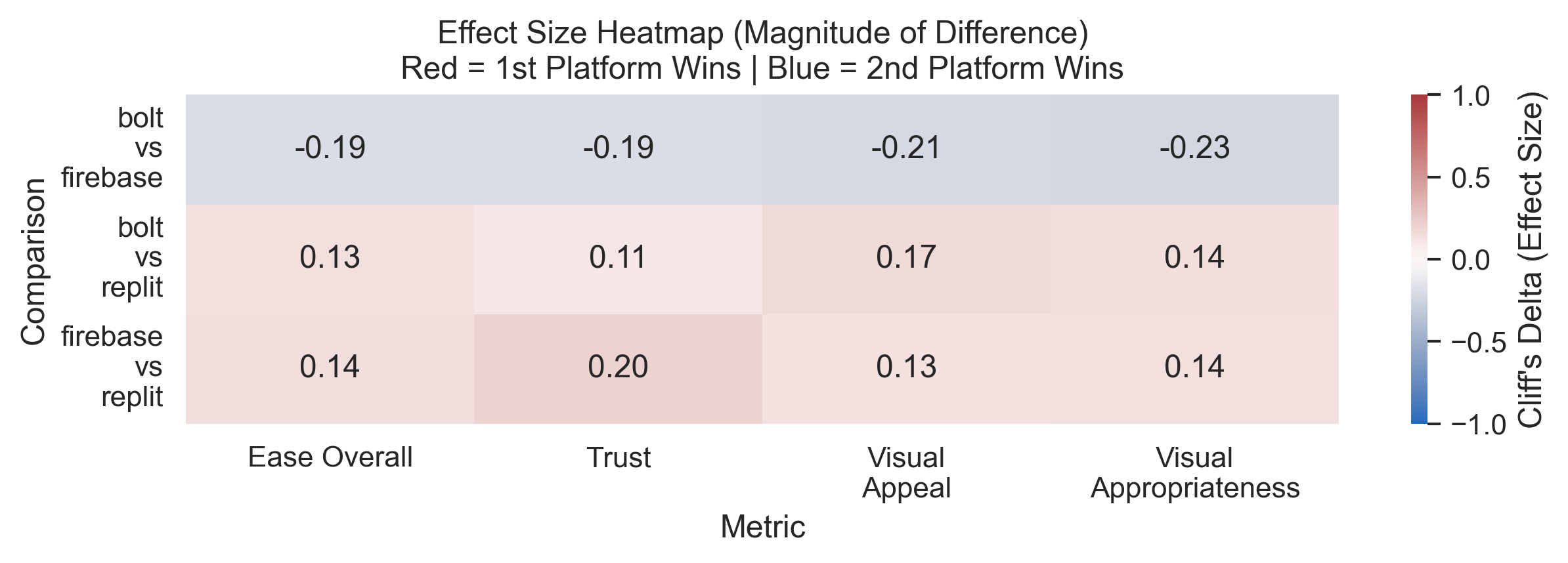
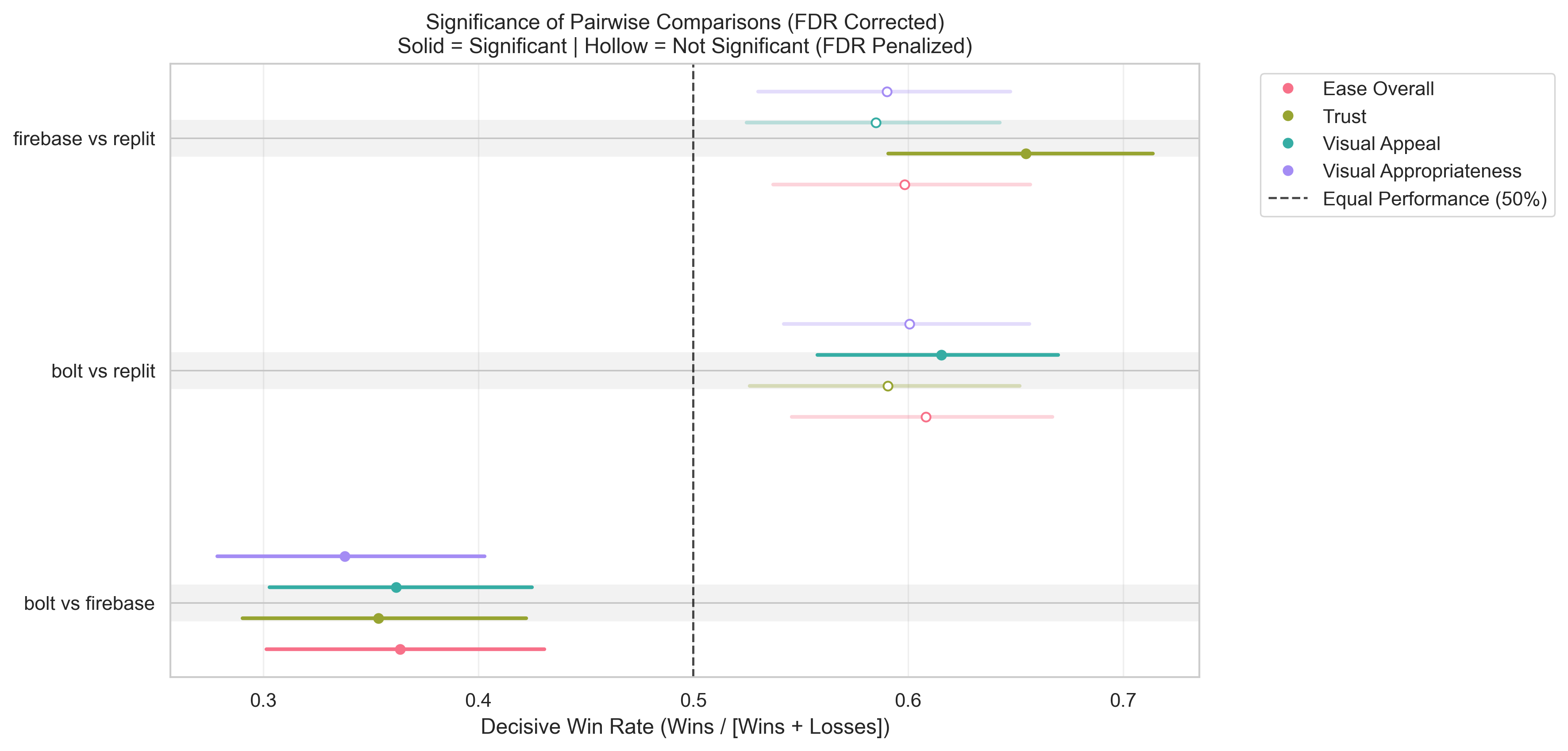
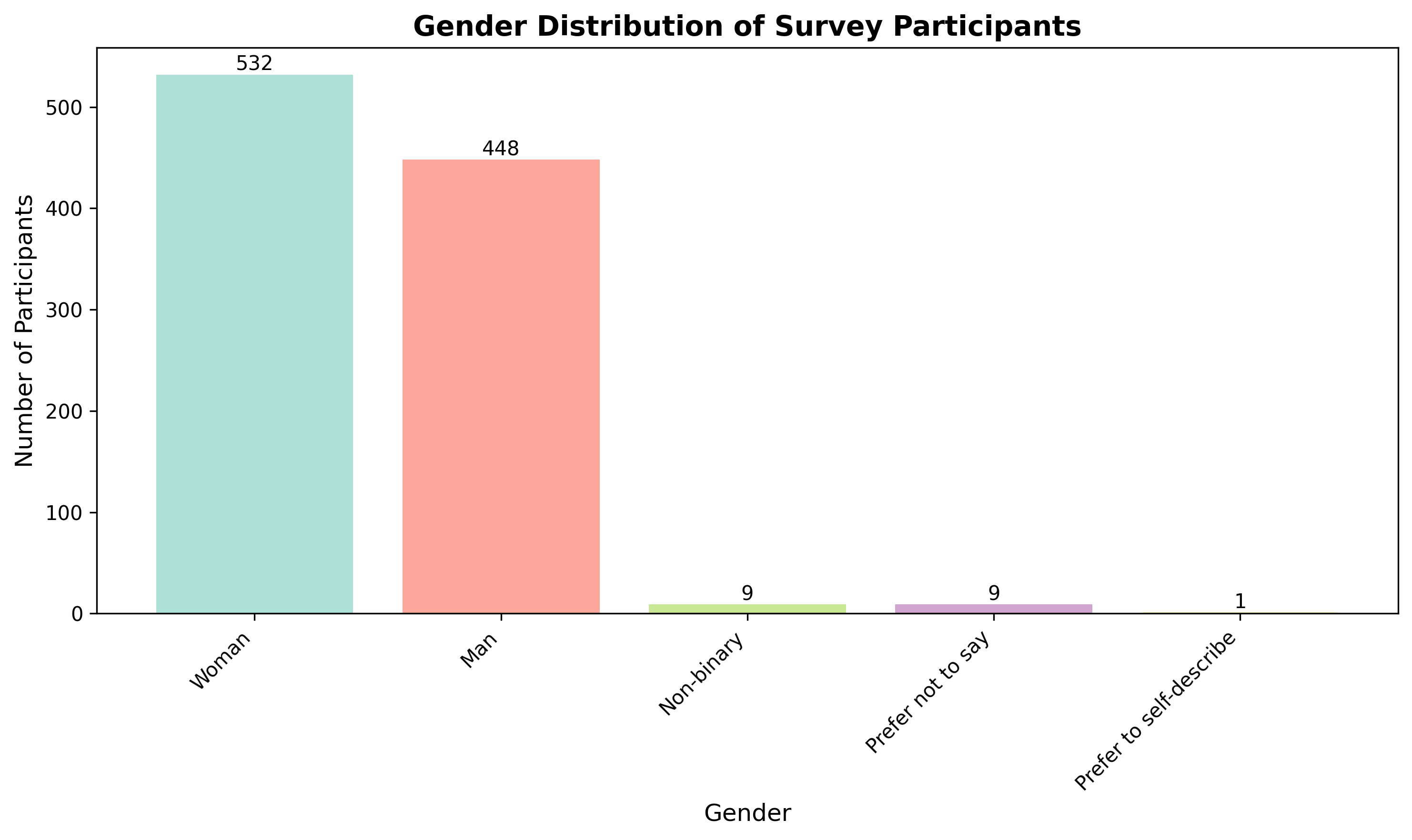
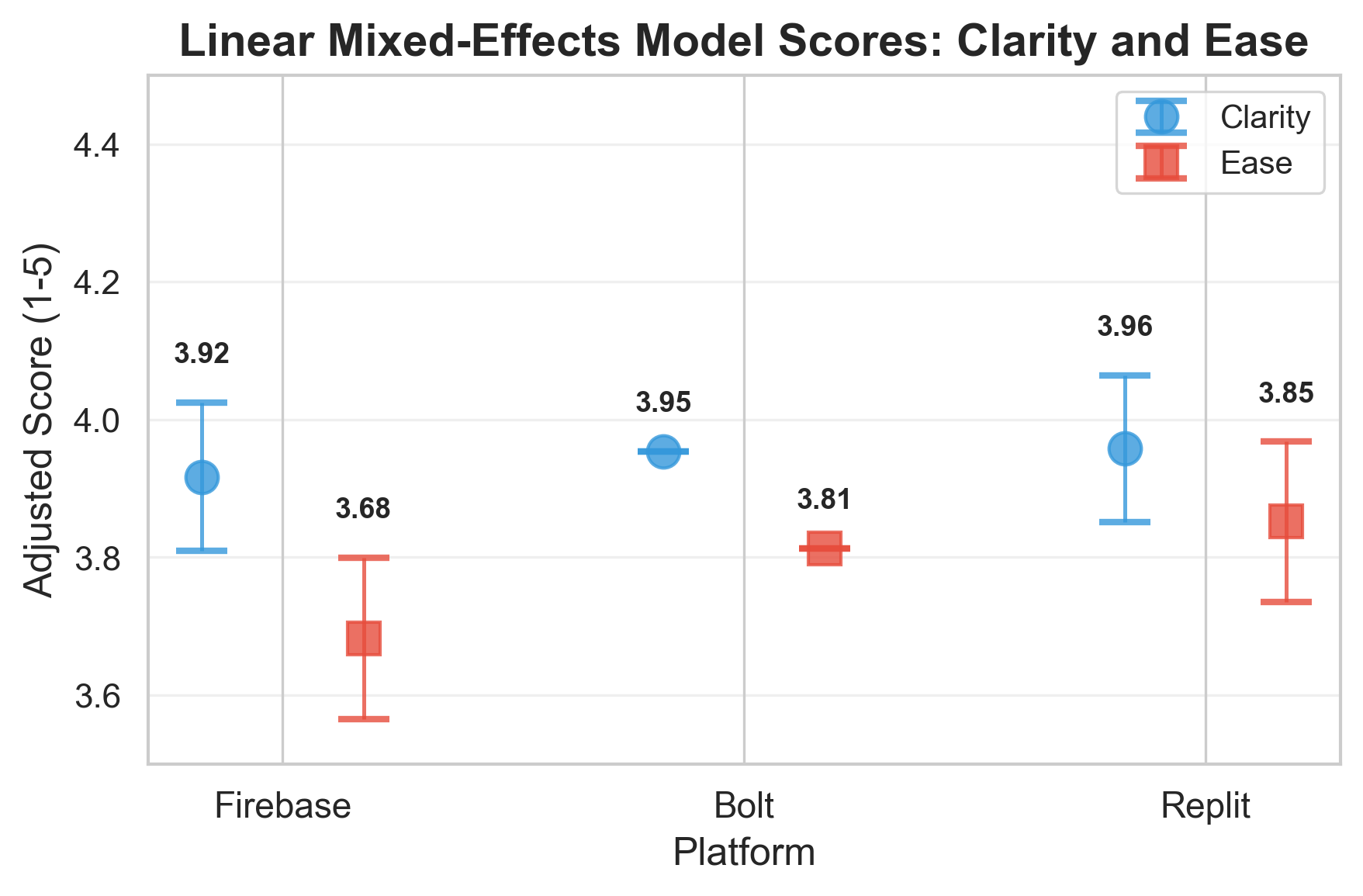
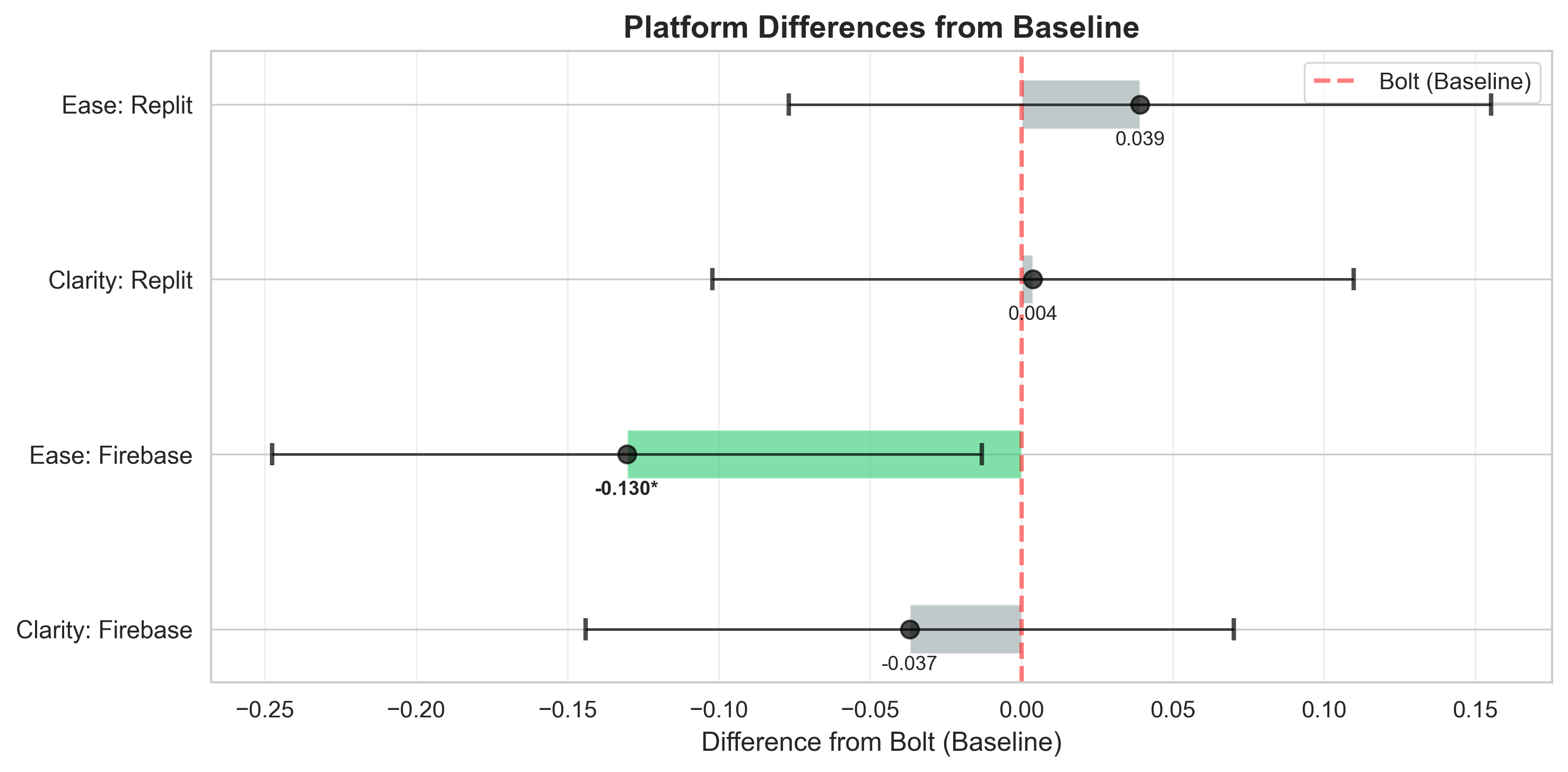
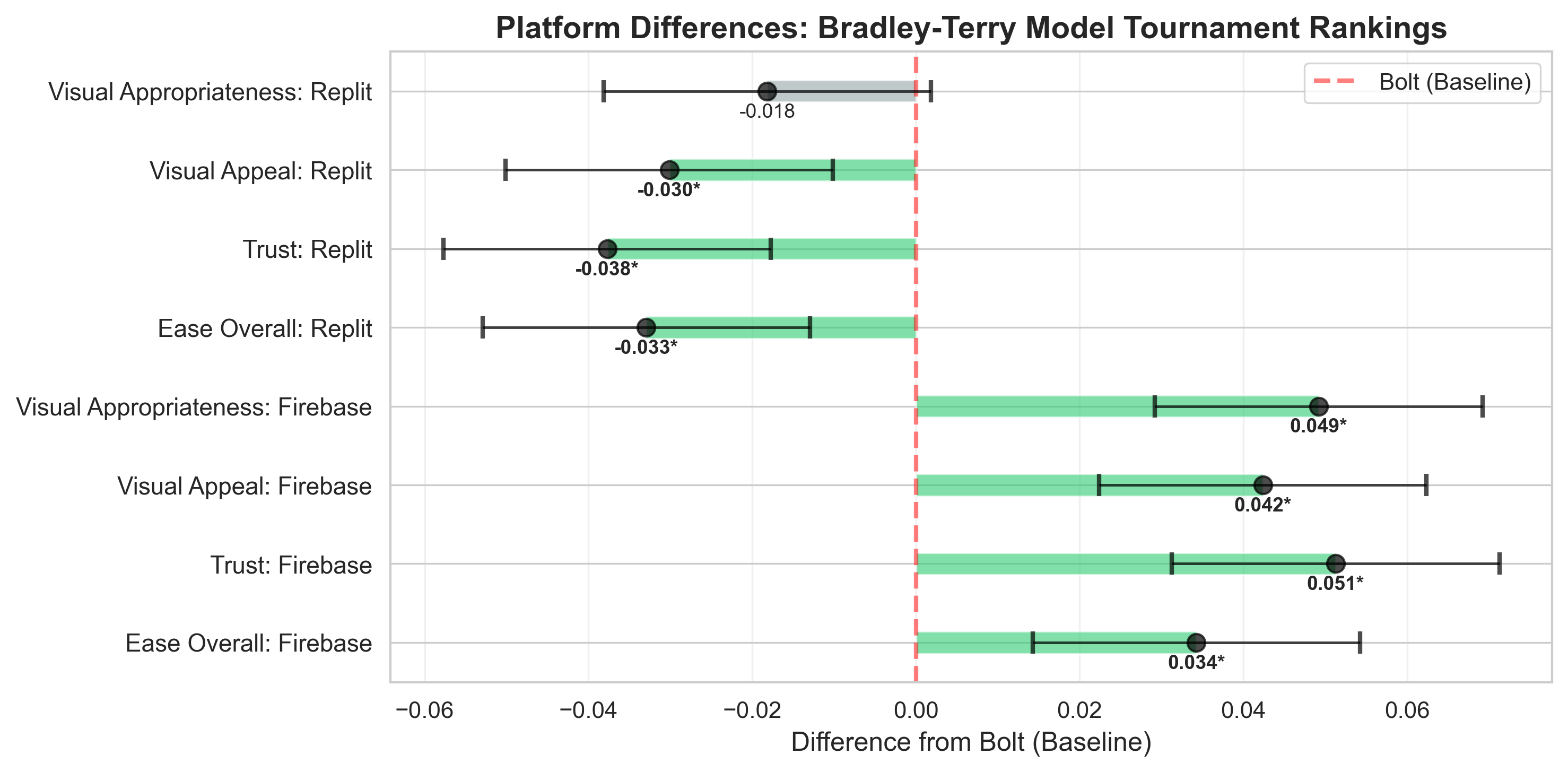
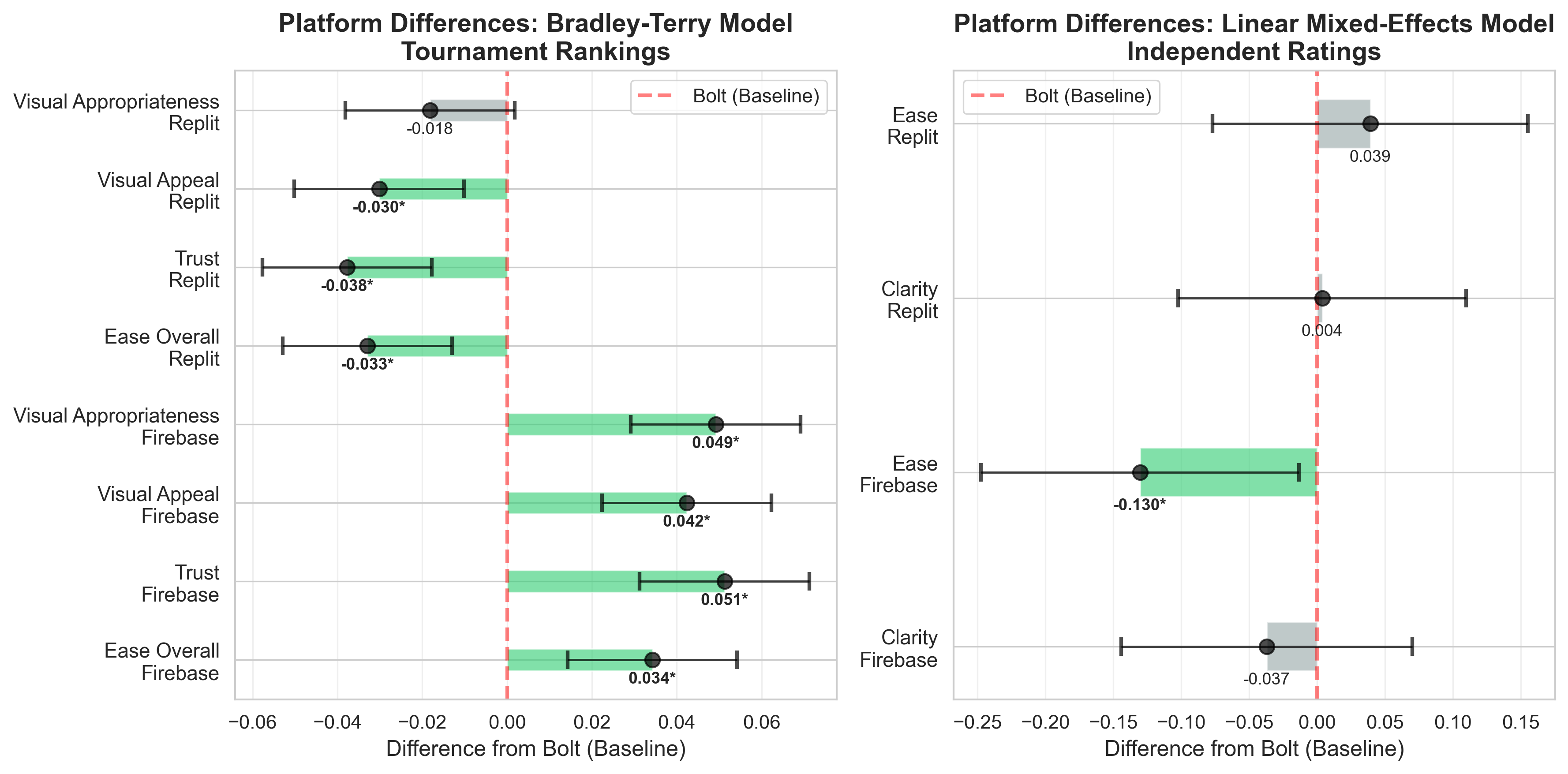
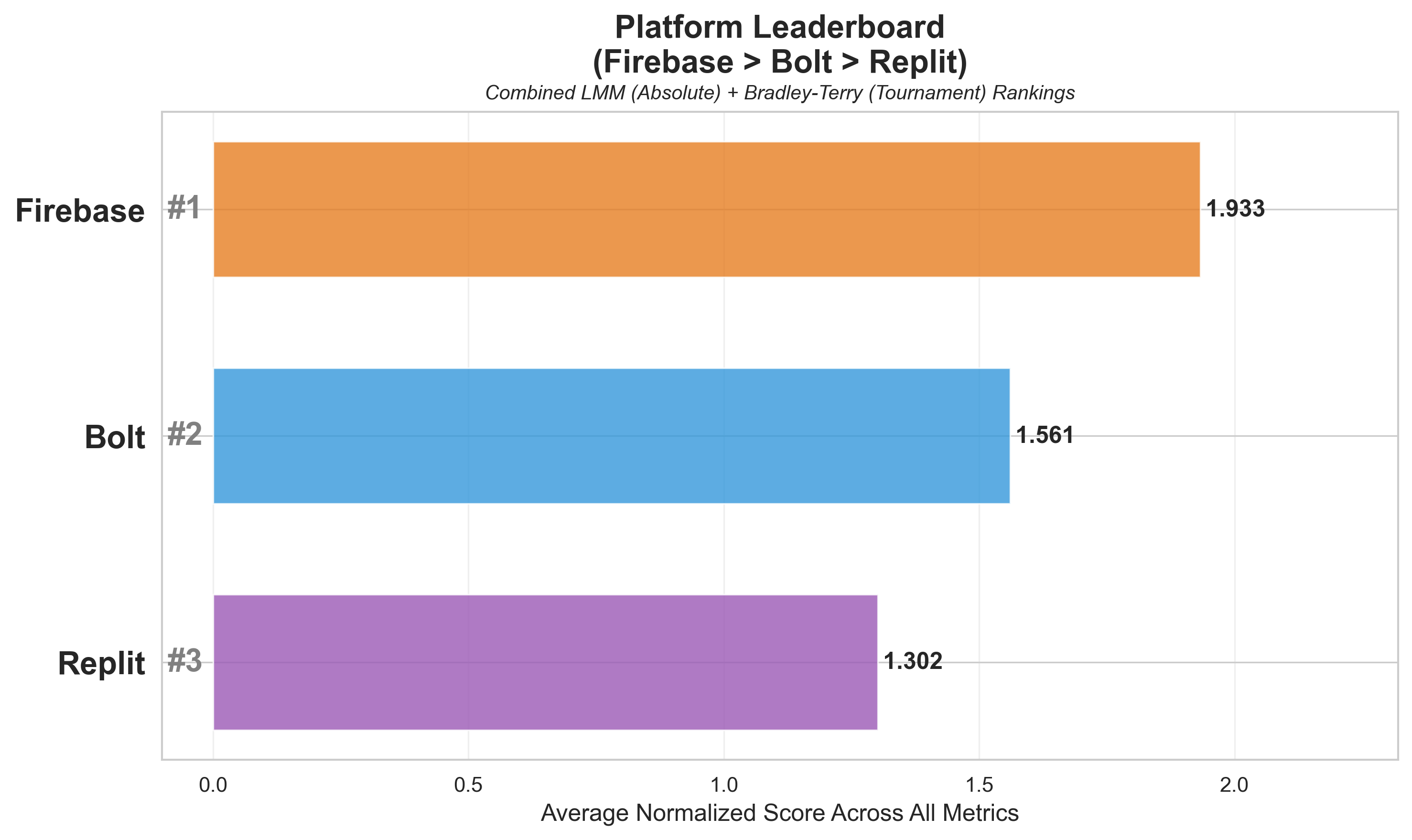
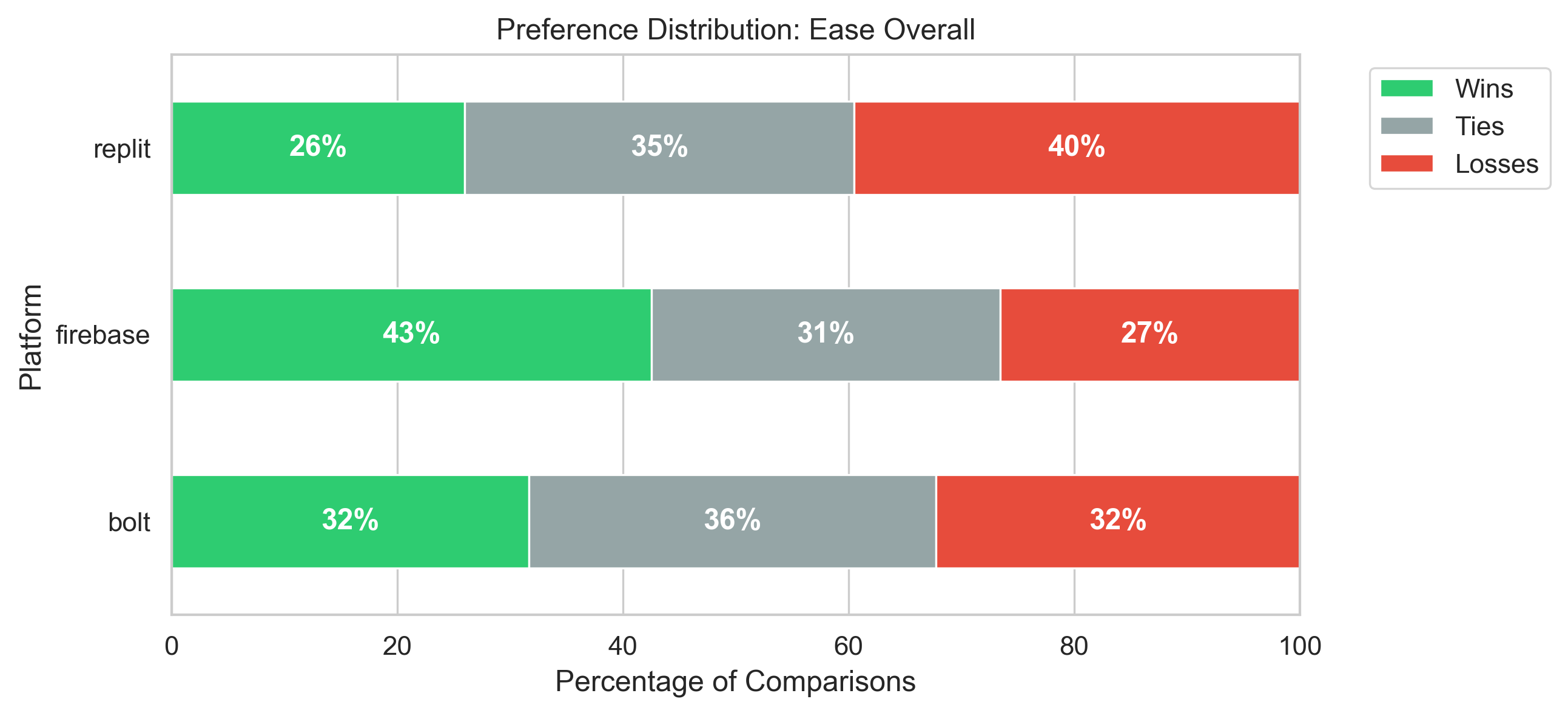
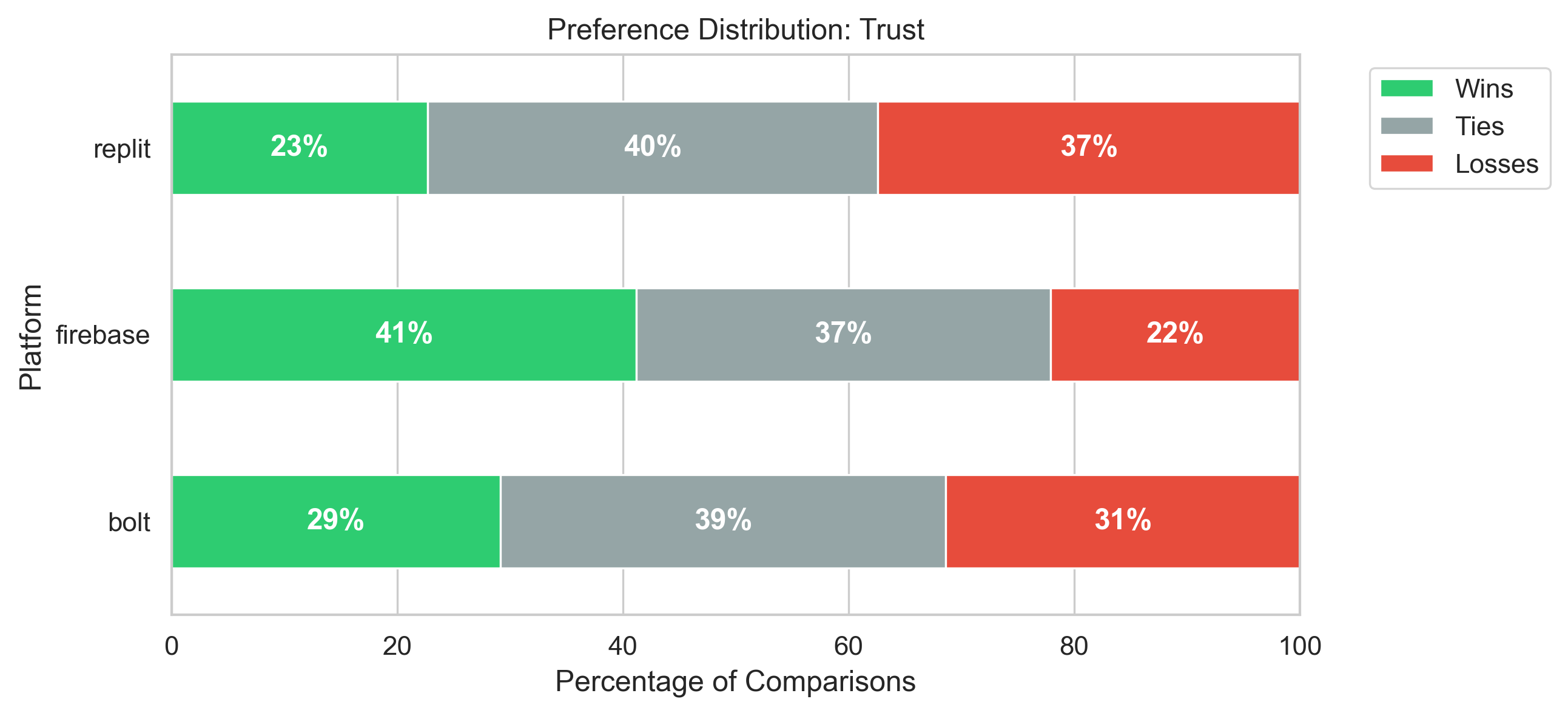
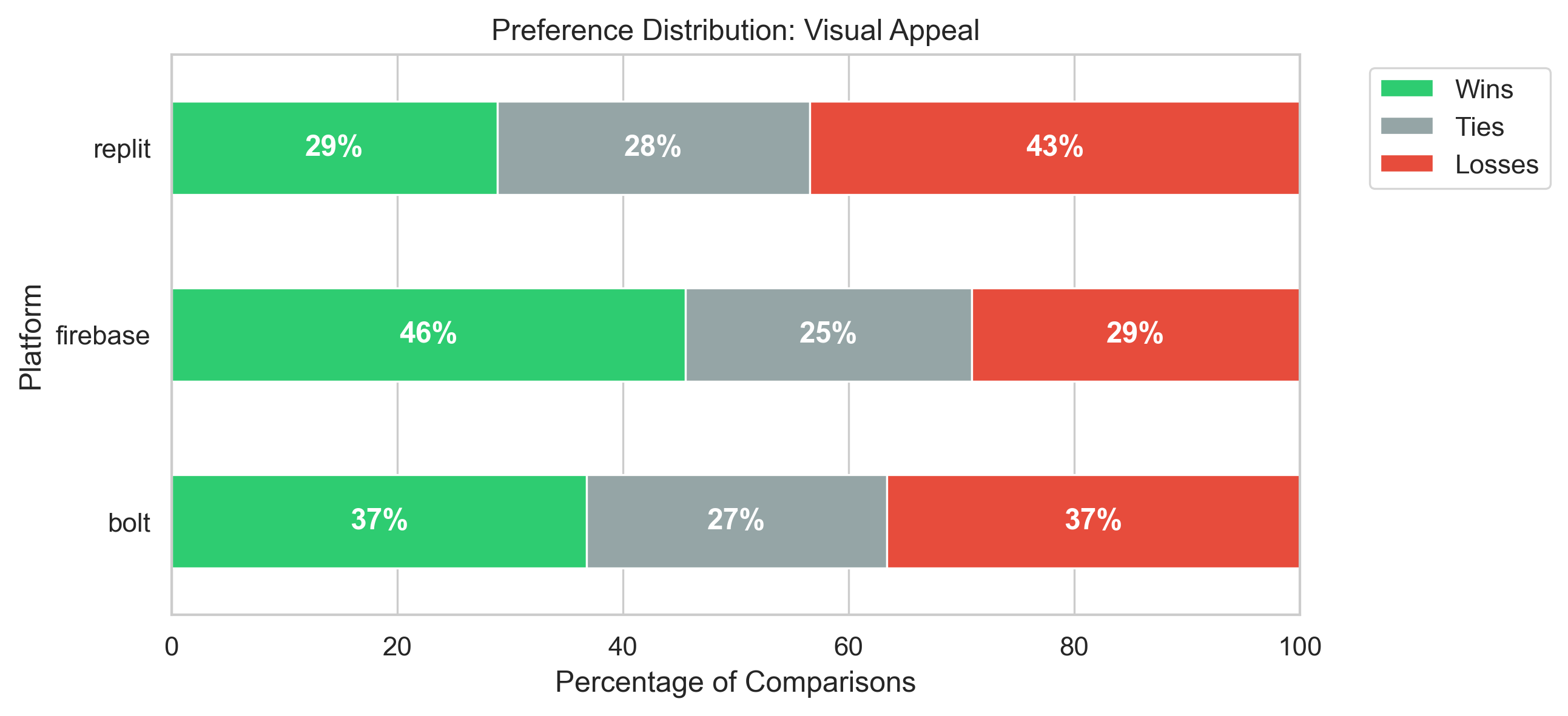
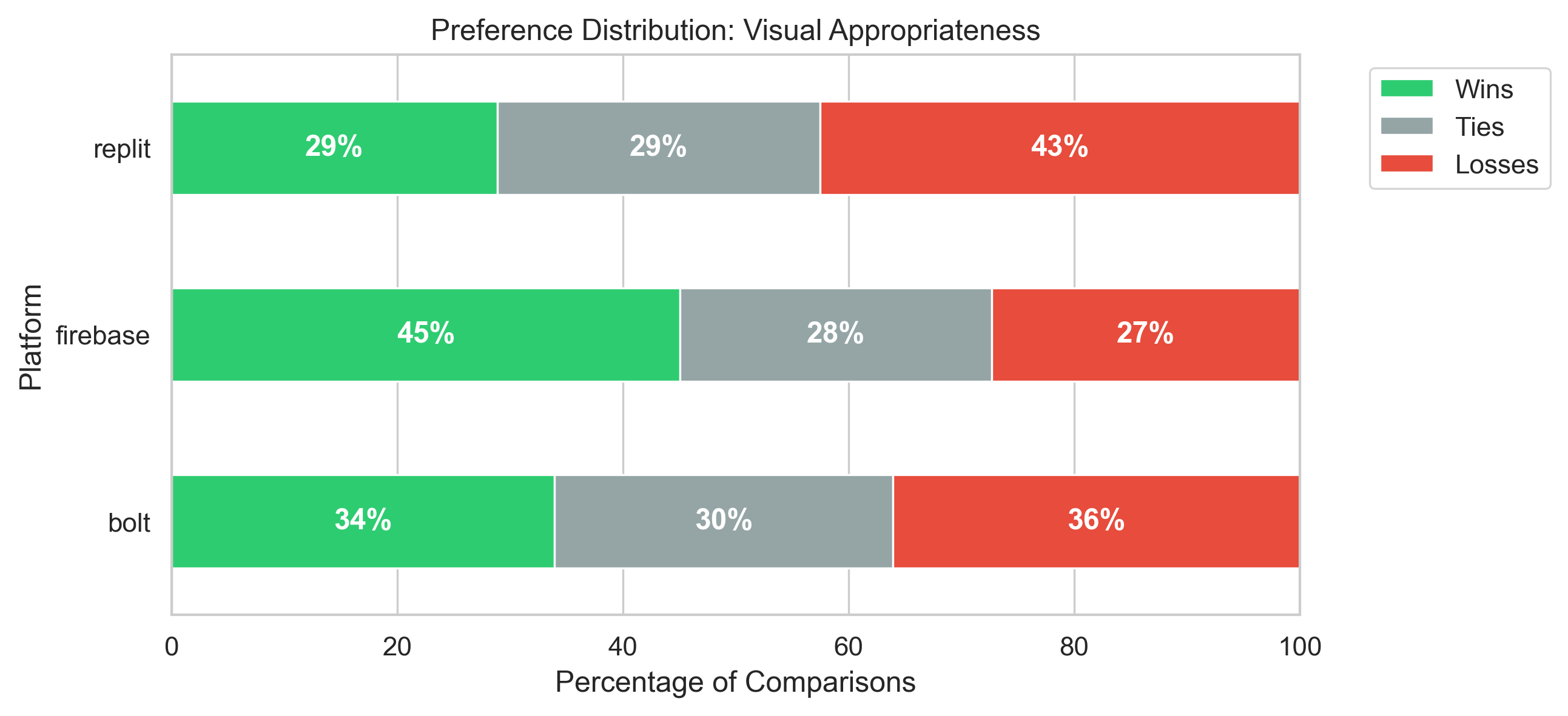
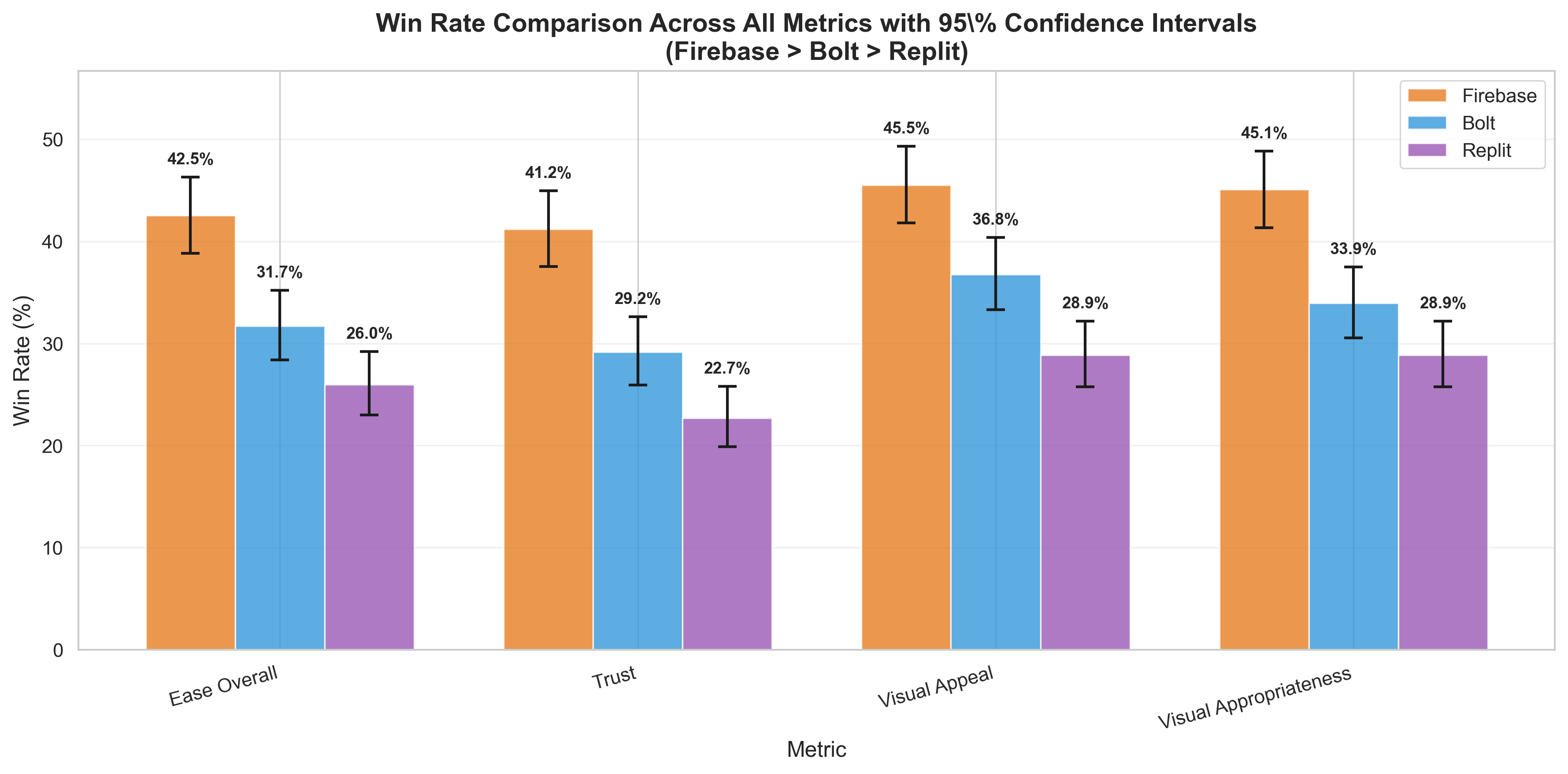
Agentic AI systems capable of generating full-stack web applications from natural language prompts ("prompt- to-app") represent a significant shift in software development. However, evaluating these systems remains challenging, as visual polish, functional correctness, and user trust are often misaligned. As a result, it is unclear how existing prompt-to-app tools compare under realistic, human-centered evaluation criteria. In this paper, we introduce a human-centered benchmark for evaluating prompt-to-app systems and conduct a large-scale comparative study of three widely used platforms: Replit, Bolt, and Firebase Studio. Using a diverse set of 96 prompts spanning common web application tasks, we generate 288 unique application artifacts. We evaluate these systems through a large-scale human-rater study involving 205 participants and 1,071 quality-filtered pairwise comparisons, assessing task-based ease of use, visual appeal, perceived completeness, and user trust. Our results show that these systems are not interchangeable: Firebase Studio consistently outperforms competing platforms across all human-evaluated dimensions, achieving the highest win rates for ease of use, trust, visual appeal, and visual appropriateness. Bolt performs competitively on visual appeal but trails Firebase on usability and trust, while Replit underperforms relative to both across most metrics. These findings highlight a persistent gap between visual polish and functional reliability in prompt-to-app systems and demonstrate the necessity of interactive, task-based evaluation. We release our benchmark framework, prompt set, and generated artifacts to support reproducible evaluation and future research in agentic application generation.