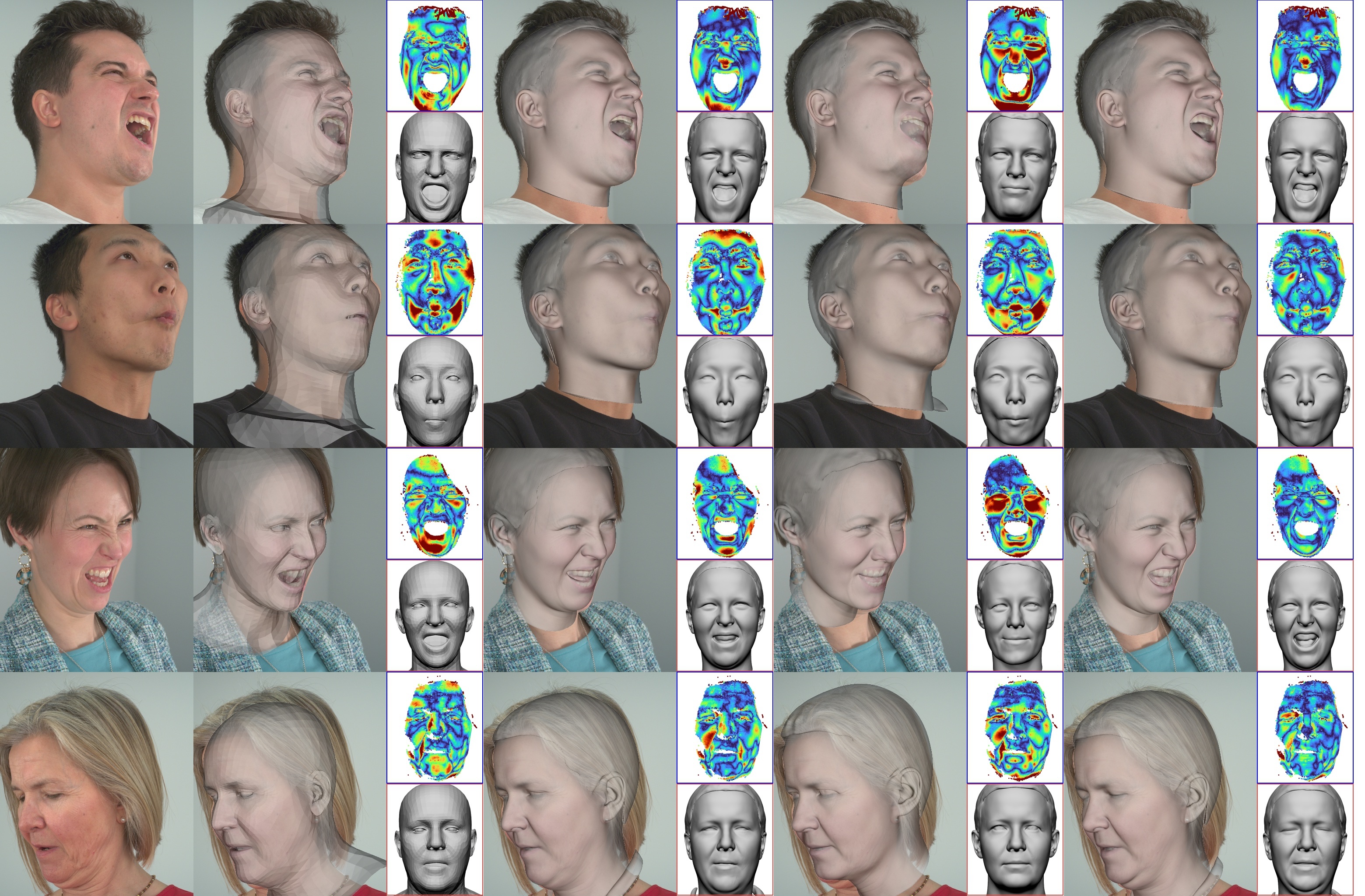
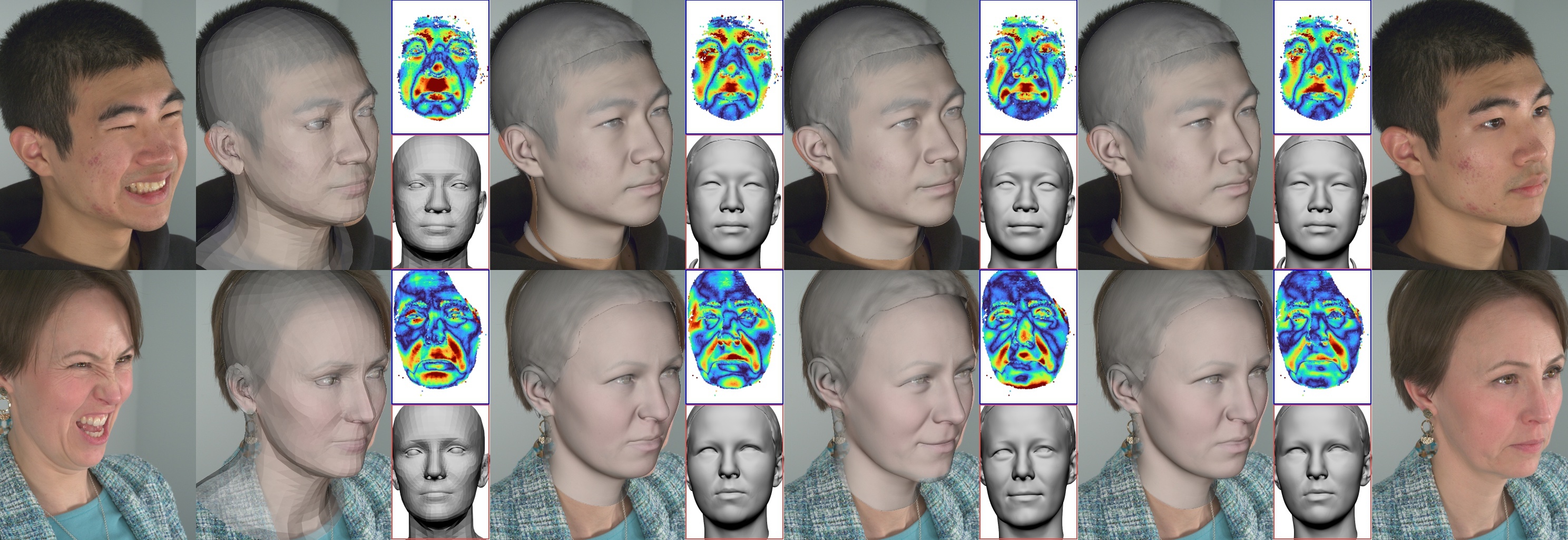
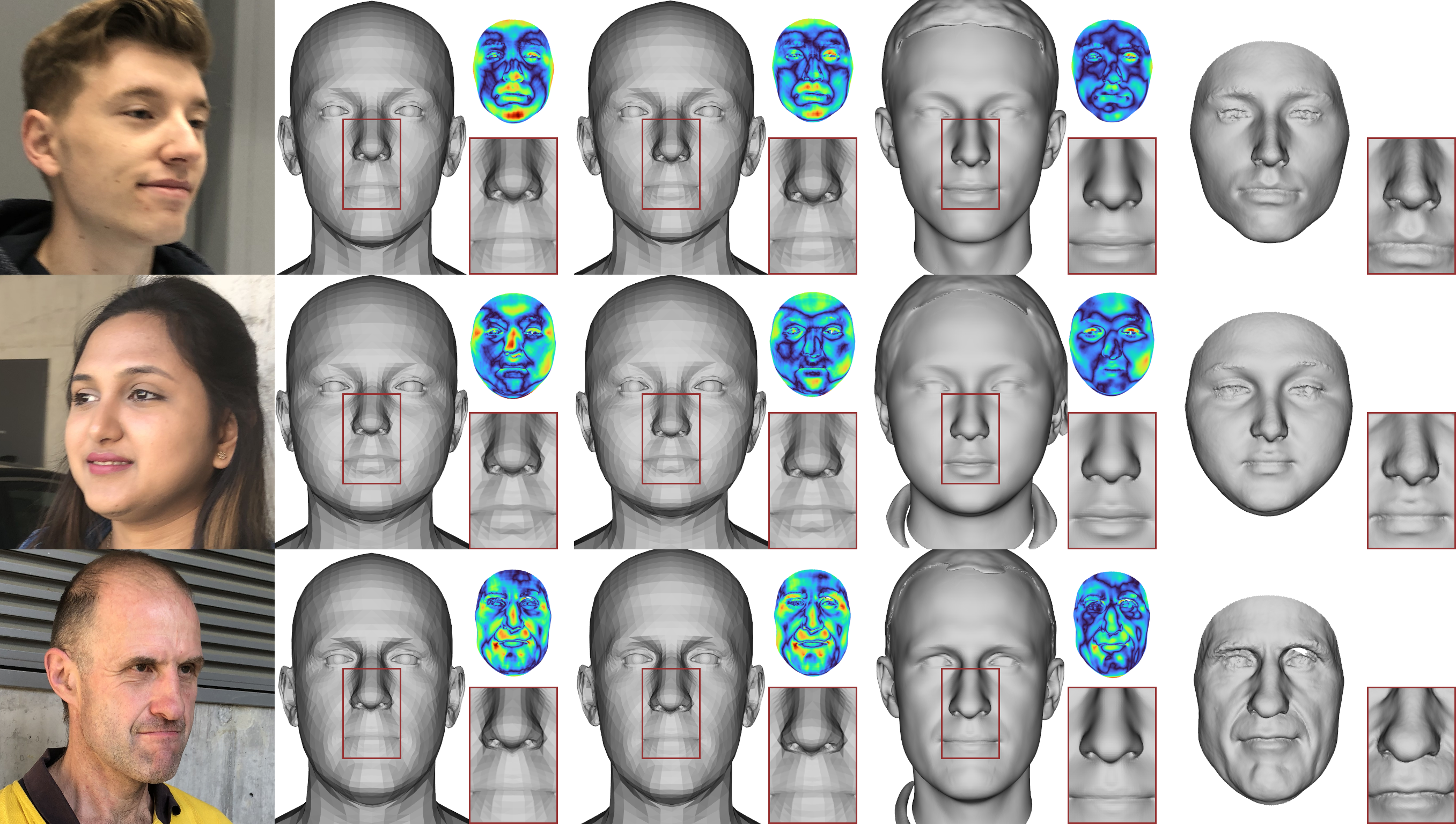
Neural Parametric Head Models (NPHMs) are a recent advancement over mesh-based 3d morphable models (3DMMs) to facilitate high-fidelity geometric detail. However, fitting NPHMs to visual inputs is notoriously challenging due to the expressive nature of their underlying latent space. To this end, we propose Pix2NPHM, a vision transformer (ViT) network that directly regresses NPHM parameters, given a single image as input. Compared to existing approaches, the neural parametric space allows our method to reconstruct more recognizable facial geometry and accurate facial expressions. For broad generalization, we exploit domain-specific ViTs as backbones, which are pretrained on geometric prediction tasks. We train Pix2NPHM on a mixture of 3D data, including a total of over 100K NPHM registrations that enable direct supervision in SDF space, and large-scale 2D video datasets, for which normal estimates serve as pseudo ground truth geometry. Pix2NPHM not only allows for 3D reconstructions at interactive frame rates, it is also possible to improve geometric fidelity by a subsequent inference-time optimization against estimated surface normals and canonical point maps. As a result, we achieve unprecedented face reconstruction quality that can run at scale on in-the-wild data.
💡 Deep Analysis
📄 Full Content
Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Simon Giebenhain1
Tobias Kirschstein1
Liam Schoneveld2
Davide Davoli3∗
Zhe Chen2
Matthias Nießner1
1Technical University of Munich
2Woven by Toyota
3Toyota Motor Europe
Figure 1. Pix2NPHM is a feed-forward network that predicts NPHM [12] latent codes from a single image. The latent codes can be further
optimized at test-time to obtain more detailed 3D reconstructions. Here, we show mesh overlays showcasing well-aligned fittings of diverse
head shapes and expressions under strong lighting conditions and occlusions. Website: https://simongiebenhain.github.io/Pix2NPHM/
Abstract
Neural Parametric Head Models (NPHMs) are a re-
cent advancement over mesh-based 3d morphable models
(3DMMs) to facilitate high-fidelity geometric detail. How-
ever, fitting NPHMs to visual inputs is notoriously chal-
lenging due to the expressive nature of their underlying la-
tent space. To this end, we propose Pix2NPHM, a vision
transformer (ViT) network that directly regresses NPHM
parameters, given a single image as input. Compared to
existing approaches, the neural parametric space allows
our method to reconstruct more recognizable facial geome-
try and accurate facial expressions. For broad generaliza-
tion, we exploit domain-specific ViTs as backbones, which
are pretrained on geometric prediction tasks.
We train
Pix2NPHM on a mixture of 3D data, including a total of
over 100K NPHM registrations that enable direct super-
vision in SDF space, and large-scale 2D video datasets,
for which normal estimates serve as pseudo ground truth
geometry. Pix2NPHM not only allows for 3D reconstruc-
tions at interactive frame rates, it is also possible to improve
geometric fidelity by a subsequent inference-time optimiza-
tion against estimated surface normals and canonical point
maps. As a result, we achieve unprecedented face recon-
struction quality that can run at scale on in-the-wild data.
1. Introduction
Reconstructing faces in 3D, tracking facial movements, and
ultimately extracting animation signals for virtual avatars
are fundamental problems in many domains such as the
computer games and movie industry, telecommunication,
and AR/VR. Arguably the most relevant sub-task is 3D face
reconstruction from a single image due to the vast availabil-
ity of image collections as well as straight-forward exten-
sions to sequential tracking.
In order to solve the underconstrained reconstruction
problem, 3d morphable models (3DMMs) [2] have evolved
as industry and research standard due to their concise low-
dimensional parametric representation, which lead to a
plethora of algorithms build on top of 3DMMs. With the
advancement of deep-learning methods, photometric track-
ing [45] approaches, have been augmented with additional
priors, such as facial landmark detection, or direct 3DMM
parameter regression from RGB signal [8, 10, 39, 56, 63].
Recently, additional priors, such as dense landmarks [41,
52] and surface normals [15] have further improved recon-
structions. Due to such methods that enable fitting in even
the most challenging scenarios, 3DMMs have become an
essential component of photo-realistic avatars [14, 33], gen-
eralized avatars [4, 23, 24], and even controllable generative
. ∗Providing contracted services for Toyota
arXiv:2512.17773v1 [cs.CV] 19 Dec 2025
diffusion models for faces [22, 32, 42, 43, 60].
While 3DMMs have achieved great success in these do-
mains, we argue that their concise parametric representation
comes at the cost of geometric expressiveness – i.e., mod-
ern 3DMMs, such as FLAME [25], are unable to model
high-fidelity geometric detail.
Therefore, a more recent
line of work has developed neural parametric head mod-
els (NPHMs) [12, 13, 54, 57] for increased representational
capacity, as shown in Fig. 2. This increased model capac-
ity, however, makes image-based reconstruction challeng-
ing due its expressive parameter space. MonoNPHM [13]
has attempted to reconstruct NPHM parameters from a sin-
gle image. However, their purely photometric fitting ap-
proach remained slow and brittle in real-world applications
To this end, we propose a robust and high-fidelity fitting
frame-work, yielding a first-class tool for face reconstruc-
tion and tracking based on NPHM [12, 13].
Our approach addresses the two main challenges of neu-
ral parametric model fitting: underconstrained optimiza-
tion and reconstruction speed. This is achieved by tailor-
ing a transformer-based feed-forward predictor for NPHM
parameters from a single image. As a highly data-driven
approach, large-scale high-quality training data is essential.
To this end, we curated a large collection of publicly avail-
able 3D face datasets and fitted MonoNPHM against it, re-
sulting in a total of 102K registrations, which will be shared
with the research community. Despite these efforts, we find
that training on large-scale 2D video datasets using a self-
supervised geometric loss based on estima