Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
Digital platforms amplify misinformation via deceptive multimodal content. While automated defense is critical, mainstream approaches predominately employ consistency-based fusion to align cross-modal features. However, we argue this premise is fundamentally flawed: the essence of fake news lies in inconsistency, subtle clashes between visual and textual evidence. By prioritizing alignment and treating discrepancies as noise, existing models inadvertently dilute the conflicting signals that serve as the primary evidence of fabrication. Consequently, effective detection demands a paradigm shift: * Equal contribution. † Corresponding author: Quanchen Zou. The work was done at 360 AI Security Lab. moving from seeking consensus to explicitly modeling and amplifying inconsistency.
Fake news detection methods generally fall into three categories. Unimodal methods analyze single data streams, yet this isolation creates information islands that overlook critical cross-modal inconsistencies. Multimodal fusion approaches, ranging from early concatenation (BMR [1]) to co-attention (SEER [2]), typically adopt consistency-seeking paradigms. These methods inadvertently smooth out vital conflict signals by treating discrepancies as noise and conflating objective facts with subjective sentiment. Recently, Large Language Models (LLMs) have been leveraged for their reasoning capabilities in approaches like INSIDE [3] and LIFE [4]. Nevertheless, the inherent focus of these models on semantic alignment hinders their ability to effectively capture and amplify the fine-grained inconsistent evidence essential for robust detection.
Despite innovations, existing methods suffer from fundamental limitations: (1) Semantic Entanglement, where objective content and subjective emotion are treated as a mixed signal, blurring the distinction between what is depicted and how it is described, making it difficult to distinguish factual mismatches from emotional dissonance. We resolve this by explicitly disentangling inputs via multi-task supervision. (2) Inconsistency Attenuation, where existing approaches prioritize alignment, inadvertently treating meaningful contradictions as noise and filtering them out, effectively smoothing out the critical discrepancy signals. In contrast, our framework pioneers an inconsistency-seeking paradigm, deploying a tension field network to explicitly amplify feature repulsions and extract maximally informative conflicts as primary evidence.
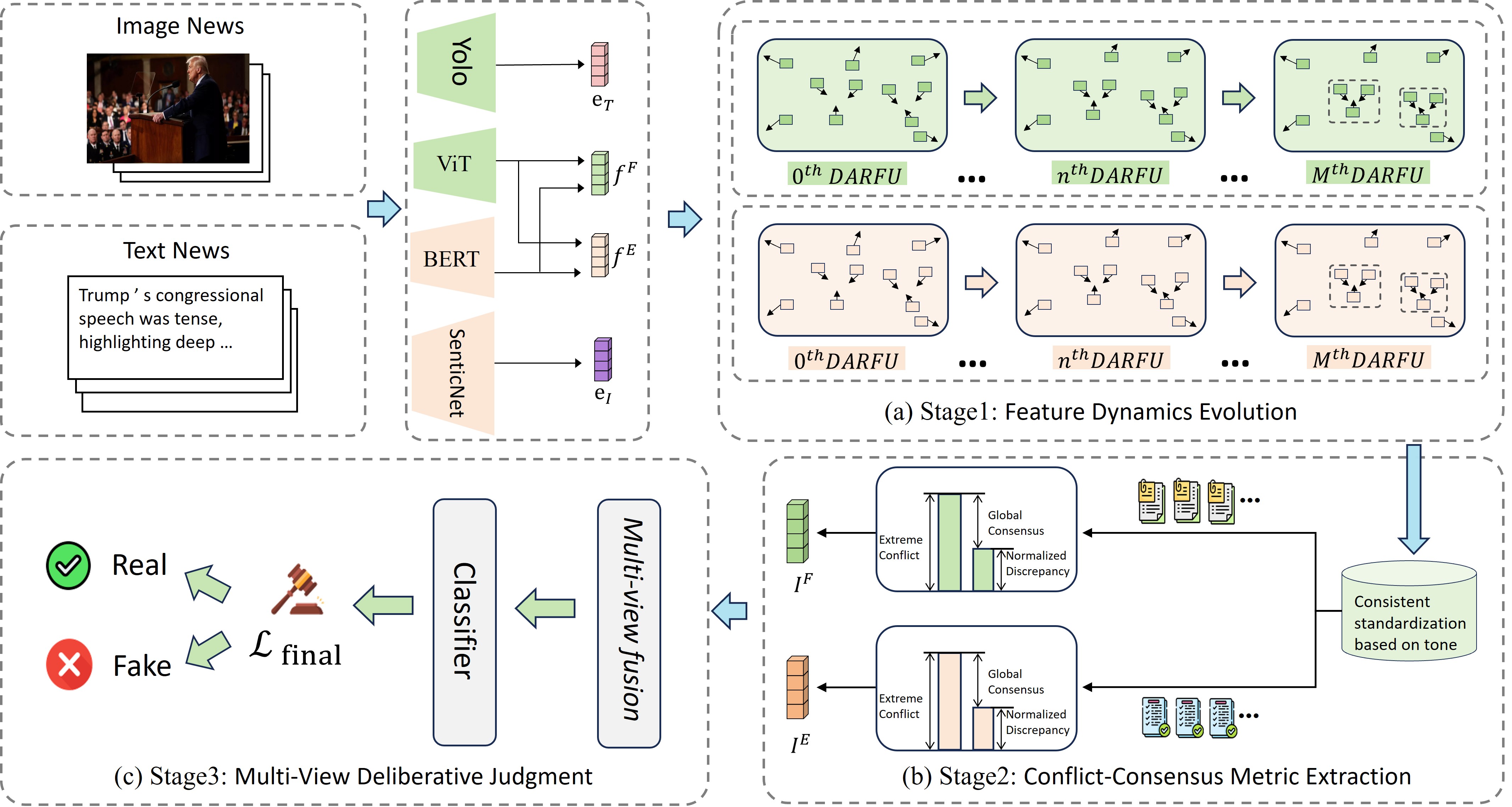
To address these limitations, we propose the Dynamic Conflict-Consensus Framework (DCCF). Inspired by physical field theory where tension [5] reflects the intensity of differences, our framework adopts a novel approach that actively searches for inconsistencies. It first separates inputs into factual content and emotional tone using multi-task supervision, guided by YOLO [6] and SenticNet [7], to distinguish objective entities from subjective feelings. A fact sentiment tension field network, modeling dynamic forces between features, then iteratively refines these features to highlight their differences. This process amplifies the contrast to extract the most significant conflicts as primary evidence, while simultaneously summarizing the overall style to serve as a global reference. By evaluating specific local conflicts against this global context, DCCF achieves robust, interpretable predictions. Our main contributions are:
- We propose DCCF, a novel inconsistency-seeking paradigm for multimodal fake news detection (MFND). Unlike consistency-seeking methods that blur critical signals, our framework models feature dynamics to amplify and extract inconsistency as primary evidence. 2) We introduce an end-to-end fact-sentiment tension field network that quantifies tension metrics to expose latent inconsistencies. By standardizing extreme conflicts against global consensus, it transforms abstract feature dynamics into interpretable reasoning, pinpointing the exact evidence of fabrication. 3) We validate DCCF’s effectiveness through extensive experiments on widely used MFND benchmarks. Our scheme shows significant performance gains over stateof-the-art baselines, demonstrating superior reliability and robustness.
Early unimodal methods [8] were insufficient, leading to multimodal detection. Text-visual fusion often interprets images superficially. This, with isolated text features, creates information islands and weak reasoning, failing cross-modal inconsistency detection. Our multi-stage framework addresses this [9]. We extract diverse factual/sentimental features for dynamic evolution, then extract high level metrics of conflict, consensus, and inconsistency. This focus on evolved relationships, not raw features [10], enables robust multi-view judgment by reasoning about inconsistencies.
Multi-domain learning models news data spanning diverse domains [11]. Approaches use hard sharing for domainspecific/cross-domain knowledge or soft sharing, like gating networks or doma
This content is AI-processed based on open access ArXiv data.