Text-to-image diffusion models have drawn significant attention for their ability to generate diverse and high-fidelity images. However, when generating from multi-concept prompts, one concept token often dominates the generation, suppressing the others-a phenomenon we term the Dominant-vs-Dominated (DvD) imbalance. To systematically analyze this imbalance, we introduce DominanceBench and examine its causes from both data and architectural perspectives. Through various experiments, we show that the limited instance diversity in training data exacerbates the inter-concept interference. Analysis of cross-attention dynamics further reveals that dominant tokens rapidly saturate attention, progressively suppressing others across diffusion timesteps. In addition, head ablation studies show that the DvD behavior arises from distributed attention mechanisms across multiple heads. Our findings provide key insights into generative collapse, advancing toward more reliable and controllable text-to-image generation.
Text-to-image diffusion models [9,13,21,24,25,27,39] have achieved remarkable success in generating highquality images from textual descriptions. However, ensuring the model's representational fidelity to textual concepts [38] remains a fundamental challenge. Recent research has extensively explored this limitation from complementary perspectives. One line of work investigates memorization [3,5,11,12,15,26,26,28,32,33,37], where models reproduce near-identical images across different random seeds mainly due to excessive duplication of specific image-prompt pairs in training data. Another line focuses on image editing [2,8,10,22], aiming to enhance semantic compositional capability by addressing failures in generating images from complex prompts containing multiple diverse concepts. In this work, we examine a complementary aspect that arises from the interplay of these two dimensions-training data characteristics and multi-concept compositional capability. We observe that when generating images from prompts containing multiple concepts, one concept can visually overwhelm the generation while the other is completely suppressed and fails to appear. For example, as shown in Fig. 1, when generating images from the prompt "Neuschwanstein Castle coaster" across different random seeds, the Castle's distinctive architecture dominates nearly all outputs, while the coaster concept is entirely absent. In this paper, we refer to this as the Dominant-vs-Dominated (DvD) phenomenon.
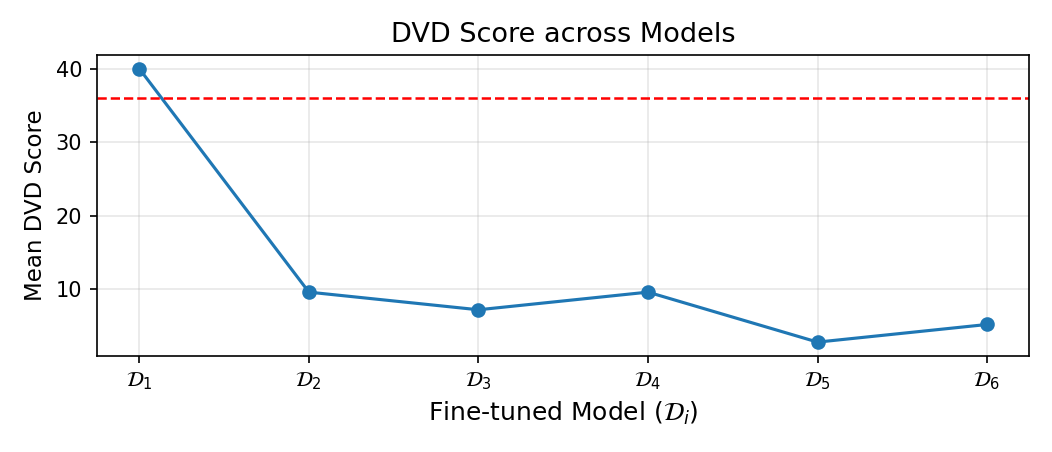
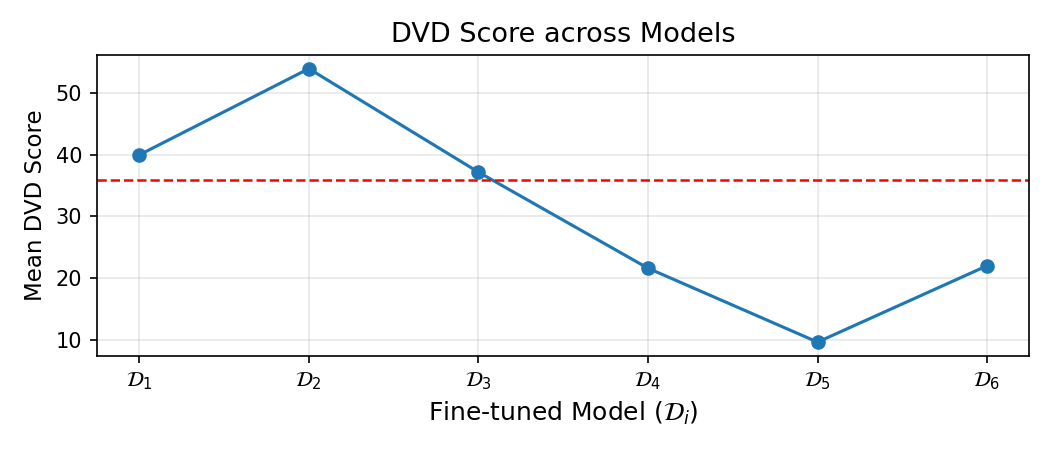
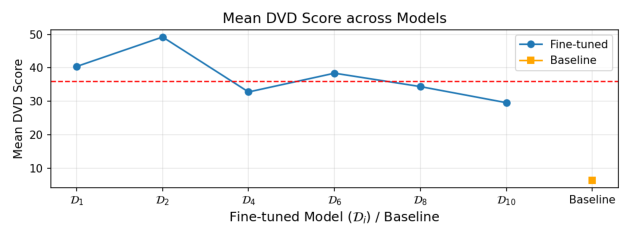
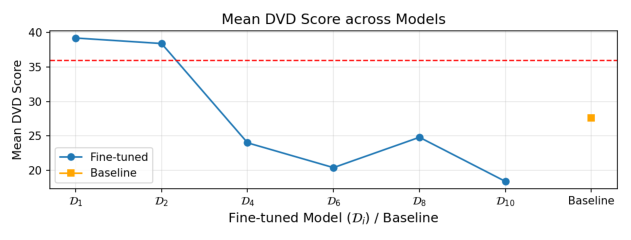
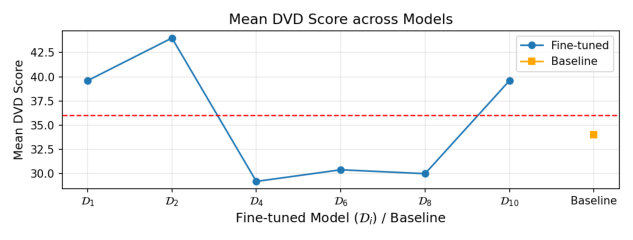
DvD extends the existing understanding by operating at the concept level through visual dominance: unlike memorization, which concerns prompt-specific reproduction, and concept editing, which addresses semantic compositional failures, DvD reveals how an individual concept’s visual characteristics systematically suppress others during multiconcept generation. We hypothesize that this dominance emerges from visual diversity disparity in training data: concepts with limited variation (e.g., landmarks, artists) develop rigid visual priors, while high-diversity concepts (e.g., everyday objects) develop flexible representations. Through a controlled experiments using DreamBooth [29] to manipulate visual diversity, we show that the dominance increases monotonically as the training diversity decreases, validating visual diversity disparity as the root cause.
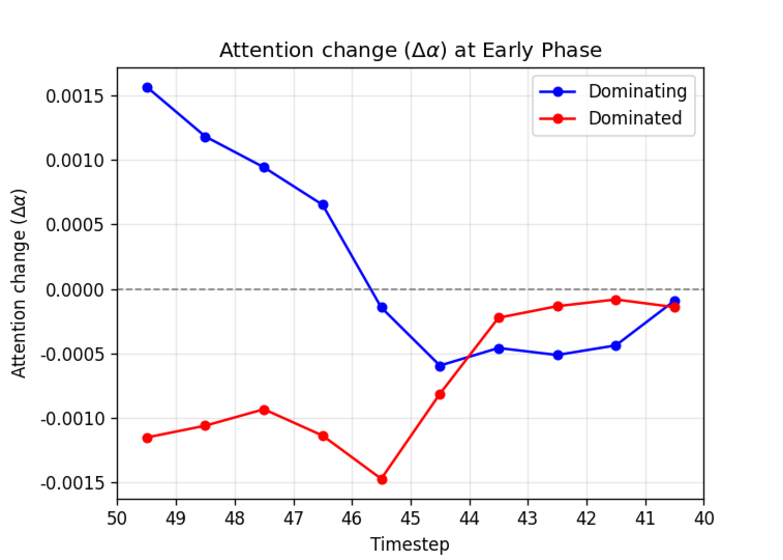
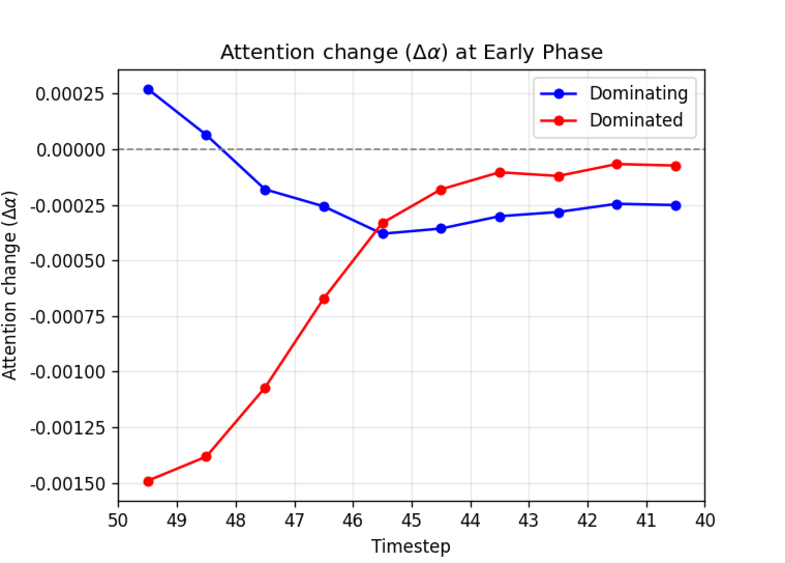
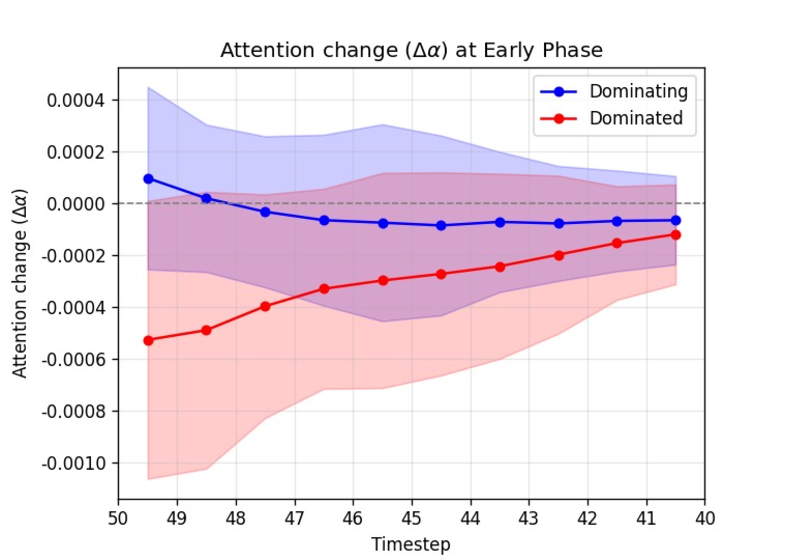
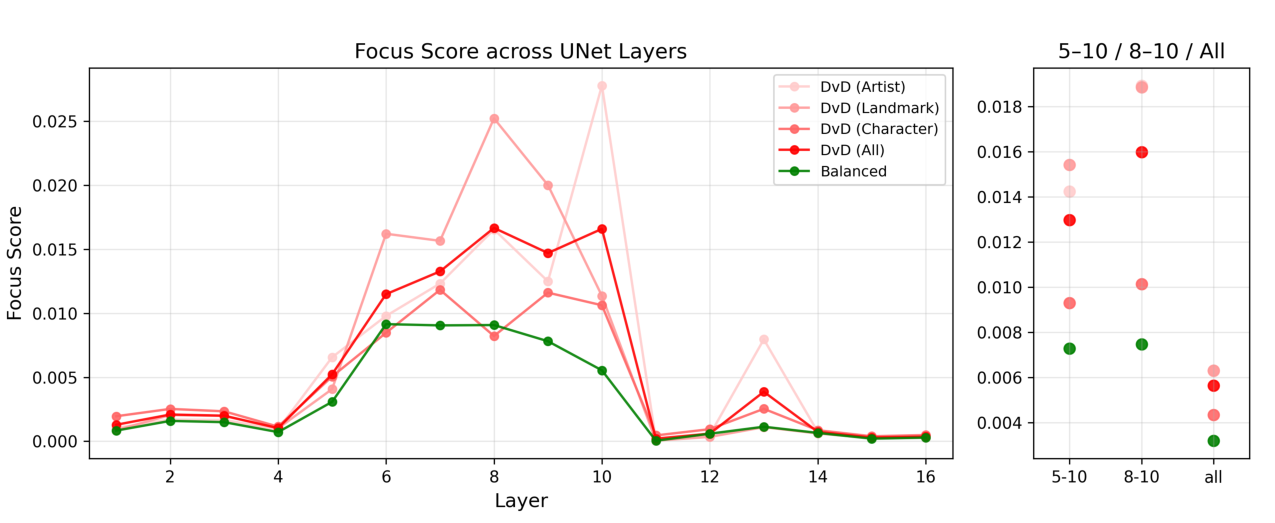
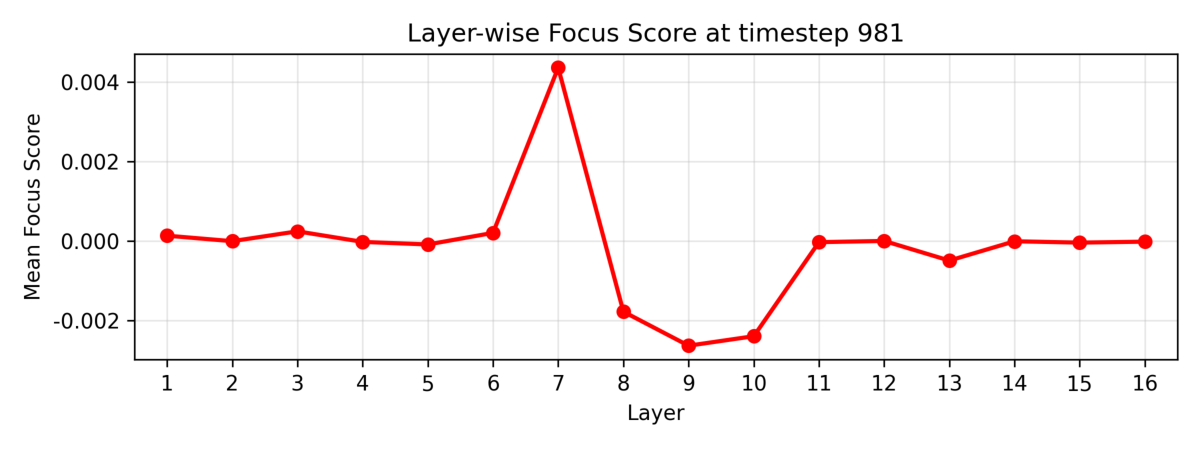
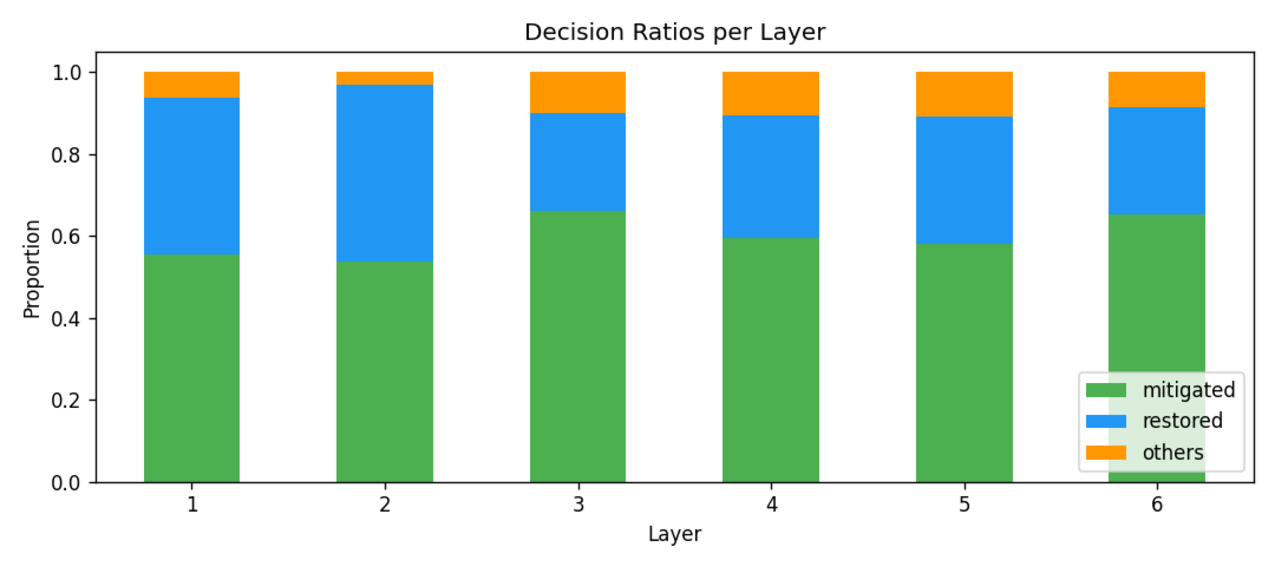
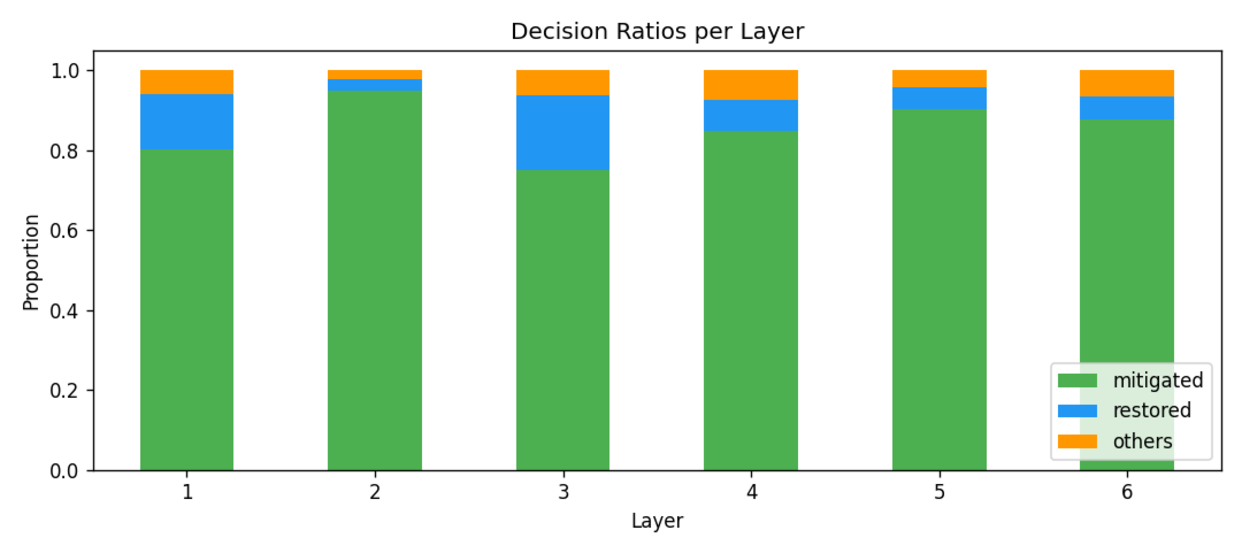
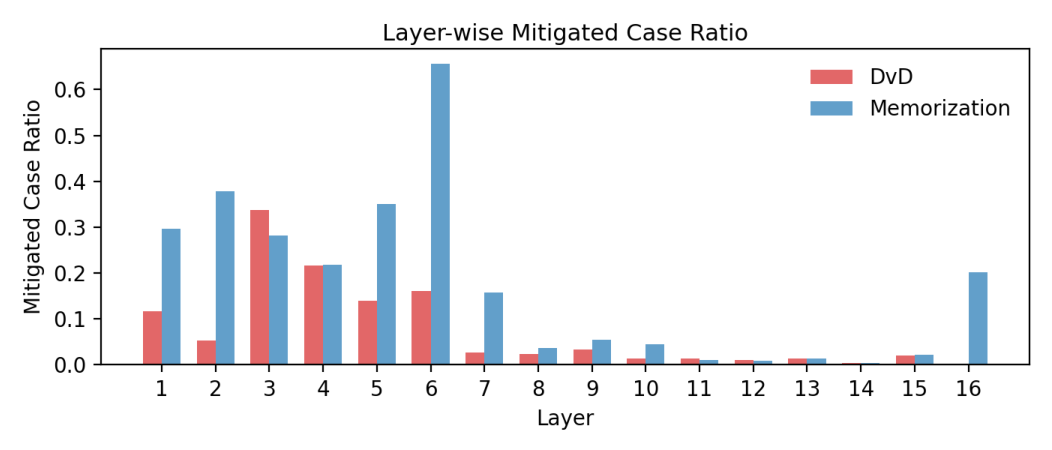
To systematically investigate how DvD manifests, we propose DominanceBench, a curated benchmark of 300 prompts exhibiting strong DvD behavior. Through crossattention analysis, we reveal that (1) DvD prompts exhibit significantly higher attention concentration on dominant tokens in lower-resolution layers at early denoising steps, (2) dominated concepts experience sharp attention decline in the early phase of denoising process, and (3) unlike memorization which localizes to specific heads, DvD emerges from distributed cooperation among multiple attention heads.
Our main contributions are: • We characterize the Dominant-vs-Dominated (i.e., DvD) phenomenon and demonstrate through controlled experiments that visual diversity disparity in training data is its root cause. • We propose DominanceBench, a benchmark dataset for systematic analysis of DvD across concept categories. • We reveal the internal mechanisms of DvD through comprehensive cross-attention analysis, identifying when (early timesteps), where (lower-resolution layers), and how (distributed across heads) dominance manifests during generation.
Memorization in diffusion models refers to the phenomenon where models replicate near-identical training images during generation, raising significant privacy and copyright concerns [3,33]. To understand how memorization is encoded in model architectures, researchers have examined cross-attention mechanisms from multiple perspectives, revealing imbalanced attention focus in token embeddings [5,26], prediction magnitudes [37], and localized neurons [11].
Recent work has further investigated the root causes: [28] provided a geometric framework relating memorization to data manifold dimensionality, and [15] revealed that overestimation during early denoising collapses trajectories toward memorized images. While these works focus on detecting and preventing prompt-specific reproduction of entire training images, our work investigates how visual diversity disparity in training data leads to concept-level dominance in multi-concept generation.
Text-to-image diffusion models continue to face substantial difficulties when prompts contain multiple concepts-such as several objects, attributes, or artistic styles-often yielding attribute leakage, concept mixing, or incomplete sub-jects. These limitations have been widely reported across compositional diffusion and attention-guided control frameworks [4,6,10,16,19,34,36], which show that even strong diffusion backbones tend to violate object-attribute bindings or collapse distinct entities. Recently, multiconcept customization and multi-subject generation ap
This content is AI-processed based on open access ArXiv data.