Planning as Descent: Goal-Conditioned Latent Trajectory Synthesis in Learned Energy Landscapes
Reading time: 5 minute
...
📝 Original Info
Title: Planning as Descent: Goal-Conditioned Latent Trajectory Synthesis in Learned Energy Landscapes
ArXiv ID: 2512.17846
Date: 2025-12-19
Authors: ** - Carlos V´elez García (cvelez@inescop.es) – Robotics & Automation, INESCOP, Elda, Alicante, Spain - Miguel Cazorla (miguel.cazorla@ua.es) – University Institute for Computing Research, University of Alicante, Alicante, Spain - Jorge Pomares (jpomares@ua.es) – University Institute for Computing Research, University of Alicante, Alicante, Spain **
📝 Abstract
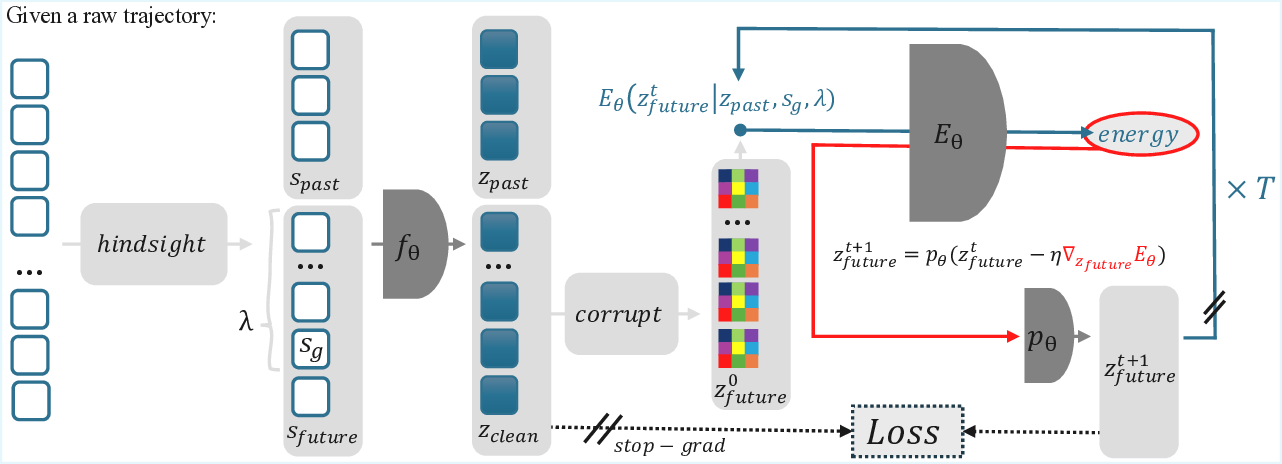
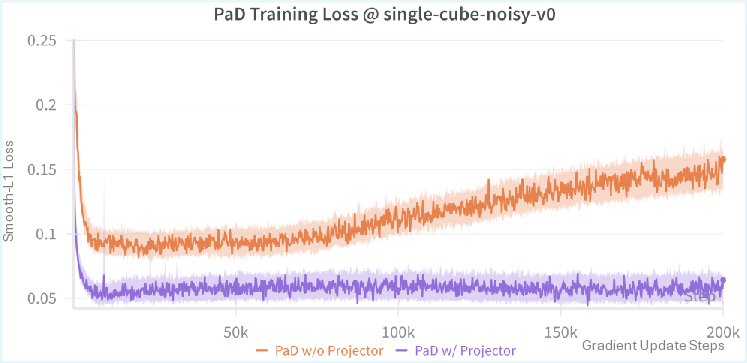
We present Planning as Descent (PaD), a framework for offline goal-conditioned reinforcement learning that grounds trajectory synthesis in verification. Instead of learning a policy or explicit planner, PaD learns a goal-conditioned energy function over entire latent trajectories, assigning low energy to feasible, goal-consistent futures. Planning is realized as gradient-based refinement in this energy landscape, using identical computation during training and inference to reduce train-test mismatch common in decoupled modeling pipelines.
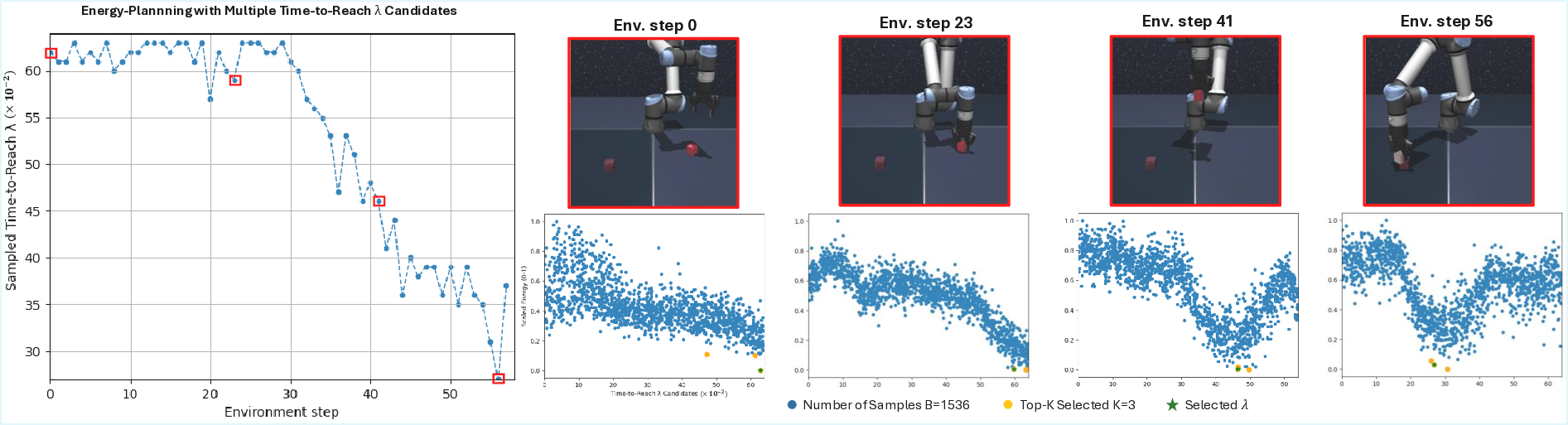
PaD is trained via self-supervised hindsight goal relabeling, shaping the energy landscape around the planning dynamics. At inference, multiple trajectory candidates are refined under different temporal hypotheses, and low-energy plans balancing feasibility and efficiency are selected.
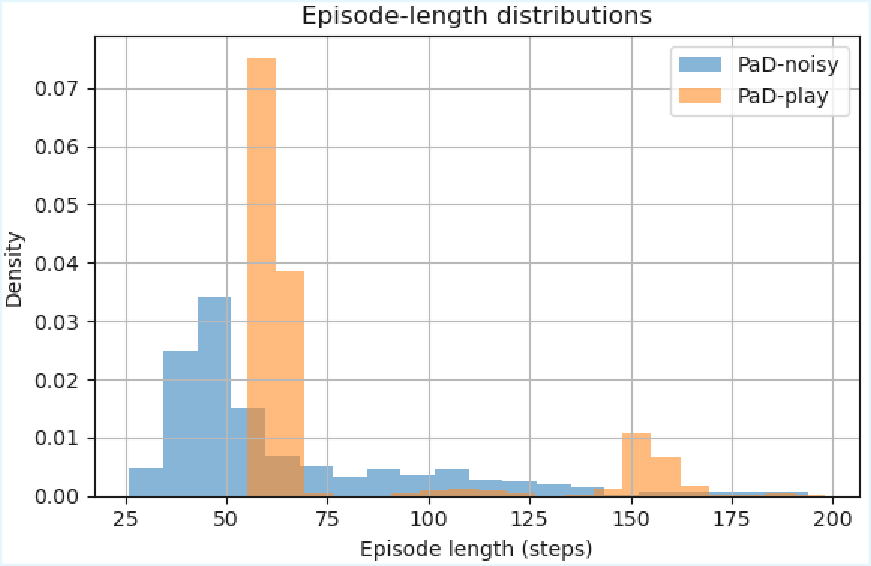
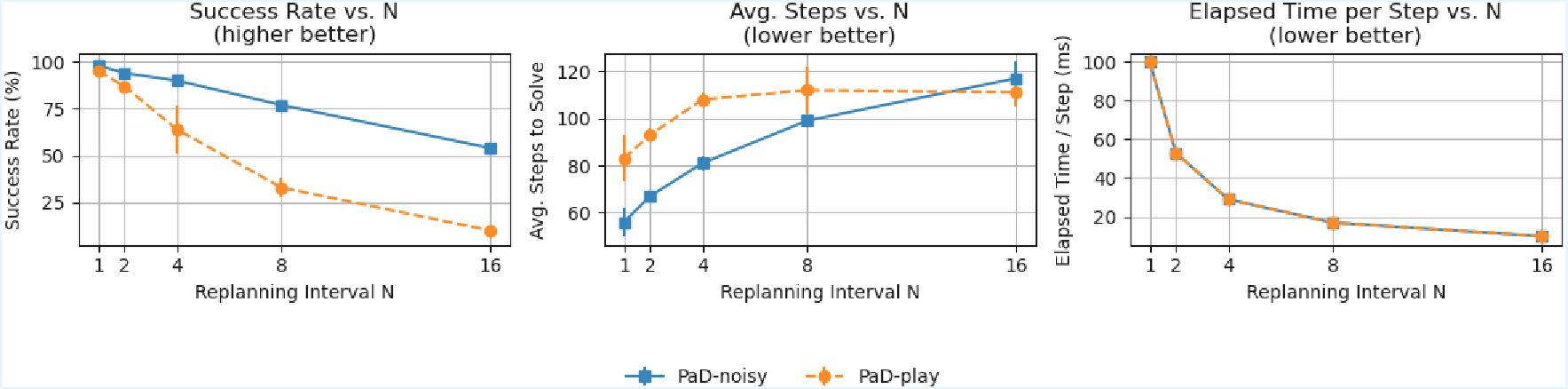
We evaluate PaD on OGBench cube manipulation tasks. When trained on narrow expert demonstrations, PaD achieves state-of-the-art 95\% success, strongly outperforming prior methods that peak at 68\%. Remarkably, training on noisy, suboptimal data further improves success and plan efficiency, highlighting the benefits of verification-driven planning. Our results suggest learning to evaluate and refine trajectories provides a robust alternative to direct policy learning for offline, reward-free planning.
💡 Deep Analysis
📄 Full Content
Planning as Descent
Planning as Descent: Goal-Conditioned Latent Trajectory
Synthesis in Learned Energy Landscapes
Carlos V´elez Garc´ıa
cvelez@inescop.es
Robotics & Automation
INESCOP
Elda, Alicante, Spain
Miguel Cazorla
miguel.cazorla@ua.es
University Institute for Computing Research
University of Alicante
Alicante, E03690, Spain
Jorge Pomares
jpomares@ua.es
University Institute for Computing Research
University of Alicante
Alicante, E03690, Spain
Editor:
Abstract
We present Planning as Descent (PaD), a framework for offline goal-conditioned rein-
forcement learning that grounds trajectory synthesis in verification. Instead of learning a
policy or explicit planner, PaD learns a goal-conditioned energy function over entire latent
trajectories, assigning low energy to feasible, goal-consistent futures. Planning is realized
as gradient-based refinement in this energy landscape, using identical computation dur-
ing training and inference to reduce train-test mismatch common in decoupled modeling
pipelines.
PaD is trained via self-supervised hindsight goal relabeling, shaping the energy land-
scape around the planning dynamics.
At inference, multiple trajectory candidates are
refined under different temporal hypotheses, and low-energy plans balancing feasibility and
efficiency are selected.
We evaluate PaD on OGBench cube manipulation tasks.
When trained on narrow
expert demonstrations, PaD achieves state-of-the-art 95% success, strongly outperforming
prior methods that peak at 68%. Remarkably, training on noisy, suboptimal data further
improves success and plan efficiency, highlighting the benefits of verification-driven plan-
ning. Our results suggest learning to evaluate and refine trajectories provides a robust
alternative to direct policy learning for offline, reward-free planning.
Keywords:
offline reinforcement learning, goal-conditioned planning, energy-based mod-
els, trajectory optimization, latent-space planning.
1 Introduction
Learning to act primarily from observation alone remains a central challenge in modern arti-
ficial intelligence (LeCun, 2022). This challenge is particularly acute in real-world domains
such as robotics, where interaction is expensive, unsafe, or impractical, and where available
1
arXiv:2512.17846v1 [cs.RO] 19 Dec 2025
Velez-Garcia et al.
data mostly consist of offline, reward-free trajectories collected under unknown and poten-
tially suboptimal policies. In such settings, agents must infer how to achieve user-specified
goals purely from heterogeneous demonstrations, without access to online exploration or
reward signals.
We study this problem in the setting of offline goal-conditioned reinforcement learning
(GCRL), where the objective is to reach arbitrary target states using only a static dataset of
reward-free trajectories. Offline GCRL poses several fundamental difficulties: (i) extracting
meaningful structure from unstructured and suboptimal data; (ii) composing disjoint be-
havioral fragments that may not co-occur within a single trajectory; (iii) propagating sparse
goal information over long horizons; and (iv) reasoning about multi-modal futures under
stochastic dynamics. Recent benchmarks such as OGBench (Park et al., 2024) highlight the
difficulty of these challenges and show that many existing methods struggle to generalize
robustly to unseen goals.
A common strategy for addressing offline decision making is to separate modeling and
planning. Model-based methods learn forward dynamics and then perform trajectory opti-
mization or model predictive control (MPC) at inference time (Zhou et al., 2024; Hansen
et al., 2023; Sobal et al., 2025). While conceptually appealing, this separation often leads
to train–test mismatches: powerful optimizers can exploit small inaccuracies in learned
dynamics models, producing adversarial or physically implausible trajectories that fail at
deployment time (Henaff et al., 2019).
An alternative line of work reframes control as trajectory generation, using sequence
models such as Decision Transformers (Chen et al., 2021), masked trajectory models (Wu
et al., 2023; Janner et al., 2021; Carroll et al., 2022), or diffusion-based policies (Chi et al.,
2023; Janner et al., 2022). These models directly model the distribution of trajectories
and can synthesize diverse, multimodal behaviors from offline datasets.
However, their
sampling-based nature often leads to reproducing undesirable behaviors when trained on
noisy or suboptimal data, and they lack explicit mechanisms for enforcing long-horizon
dynamical feasibility or goal satisfaction.
More broadly, these approaches learn how to
generate trajectories, but do not explicitly learn how to evaluate or verify them(West et al.,
2023).
In this work, we propose Planning as Descent (PaD), a framework that rethinks offline
goal-conditioned control through the lens of generation by verification. Rather than learning
a policy, generator, or explicit planner, PaD learns a goal-conditioned energy la