Practical utilization of large-scale machine learning requires a powerful compute setup, a necessity which poses a significant barrier to engagement with such artificial intelligence in more restricted system environments. While cloud computing offers a solution to weaker local environments, certain situations like training involving private or sensitive data, physical environments not available through the cloud, or higher anticipated usage costs, necessitate computing locally. We explore the potential to improve weaker local compute systems at zero additional cost by taking advantage of ubiquitous yet underutilized resources: mobile phones. Specifically, recent iOS phones are equipped with surprisingly powerful processors, but they also face limitations like memory constraints, thermal throttling, and OS sandboxing. We present a proof-of-concept system demonstrating a novel approach to harness an iOS device via distributed pipeline parallelism, achieving significant benefits in a lesser compute environment by accelerating modest model training, batch inference, and agentic LRM tool-usage. We discuss practical use-cases, limitations, and directions for future work. The findings of this paper highlight the potential for the improving commonplace mobile devices to provide greater contributions to machine learning.
Running practical large-scale model training and inference requires devices with powerful compute. Such devices are at times prohibitively expensive, leaving smaller research labs, universities, and individuals limited to weaker compute setups. Cloud computing alternatives are not always readily available, e.g. in situations where outsourcing compute to third parties risks data privacy or is physically infeasible, like due to required local hardware interactions. However, thousands of consumer mobile devices are shipped each year with increasingly powerful processors, now capable of running substantial local machine learning tasks independently [28]; we believe they have the potential to contribute more significantly at another level. For the sake of this paper, we focus specifically on iOS mobile phones, as newer Apple iPhones feature consistent high-performing processors and optimized frameworks to interact with them. These devices, while equipped with relatively powerful chips, are limited by memory constraints, thermal throttling, and OS sandboxing, restricting their ability to run training or inference for larger models by themselves [22].
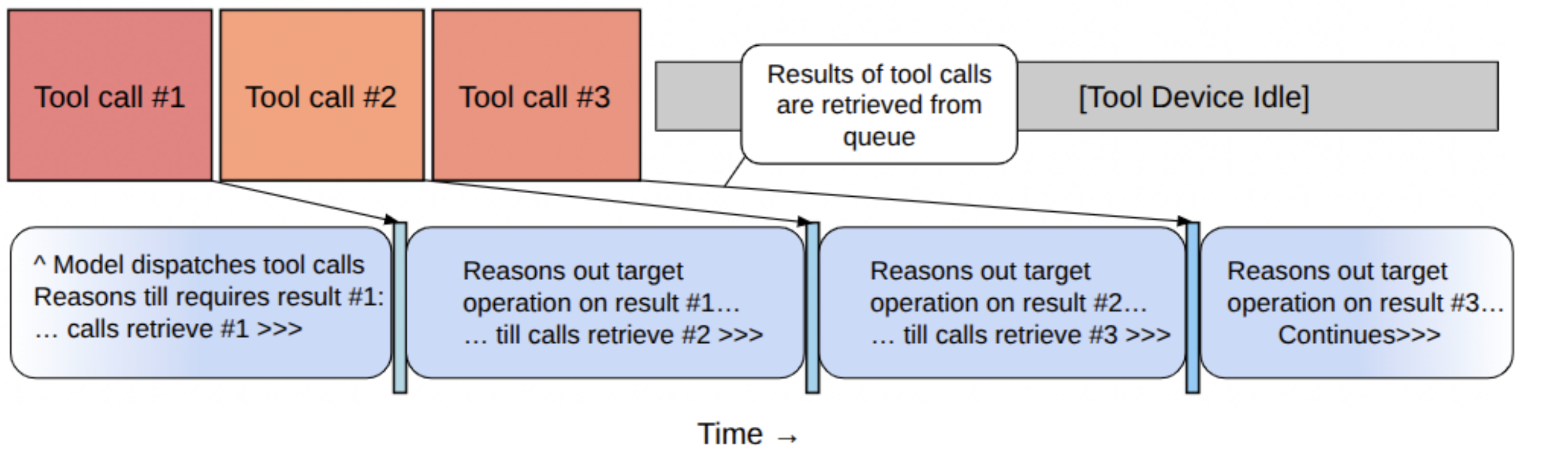
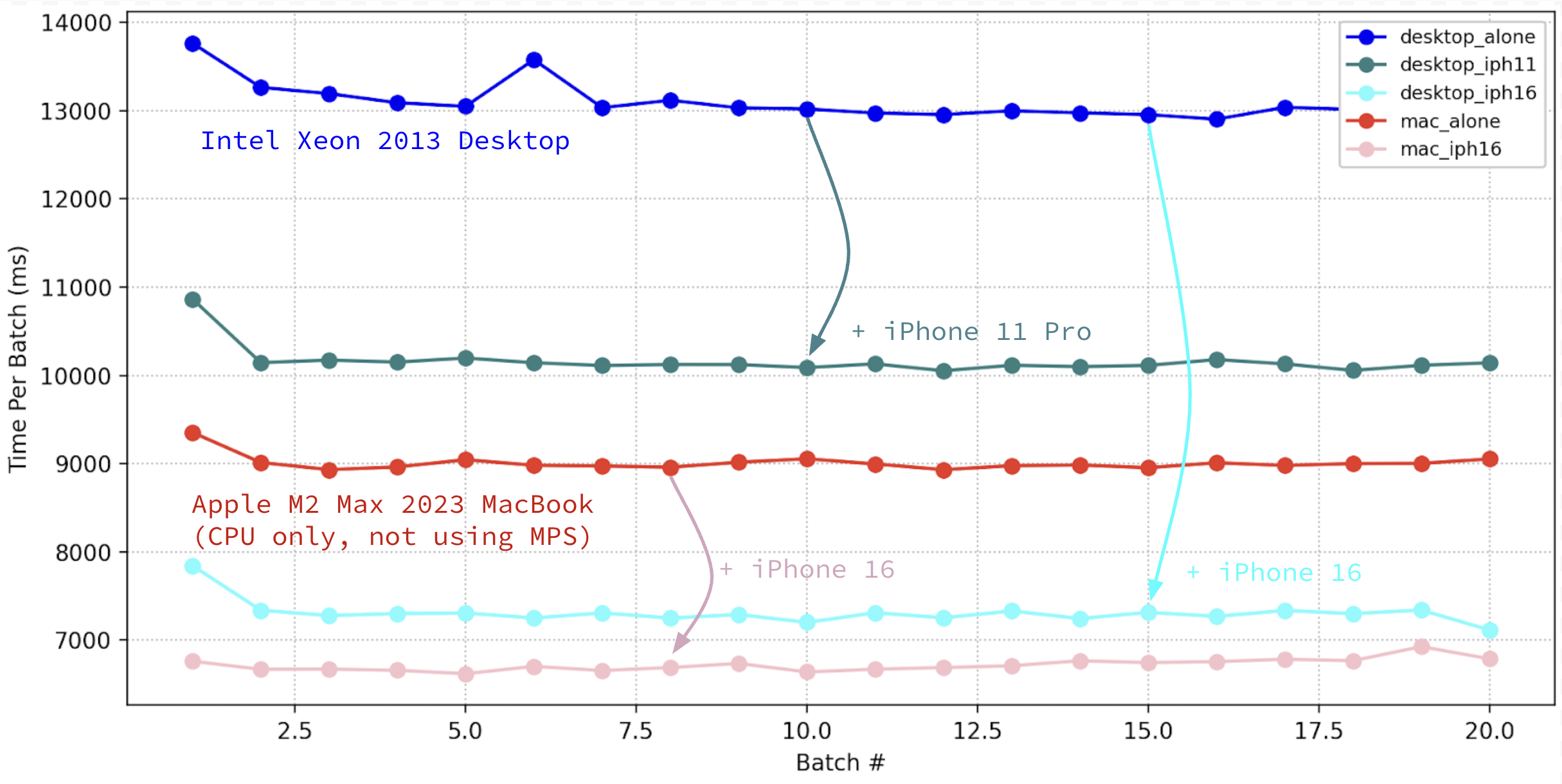
In this paper we propose leveraging a pipeline parallel distributed system, letting iOS devices only store small partitions of model weights to still meaningfully contribute their compute, circumventing mobile memory limitations. This worked well for training and inference with the modestly sized ResNet-34 [15] with an old 2013 Intel Xeon desktop as integrating an iPhone 16 reaped a 44% decrease in training time, detailed in the Results (section 4). However, we found our iOS worker impractical when attempting training on more significant models like LLMs. This prompted us to pursue relatively lighter computation tasks, leading us to attempt parallelizing tool usage computation with agentic LRMs reasoning. Further, iOS devices provide a unique suite of physical sensors and on-device features, such as LiDAR 3d-sensing, audio processing, and GPS positioning, which could serve as potential cost-effective paths of exploration towards embodying agentic AI. We experimented with a scenario using Qwen3-8B [29] on a 2023 Macbook Pro and a mocked vector database search operation and show a theoretical elimination of idle-time waiting for tool results via tool parallelism. Finally, we discuss limitations and directions for future work in Discussion (section 5).
Mobile compute power has progressed rapidly over the past years, reaching or surpassing capabilities of lower-end computer hardware. Table 1 compares some iOS integrated chips with other mobile, edge device, and lower-end computer processers. [21,25,20,19,2,5,6,3,4,1]. Bolded devices were used during experimentation.
Note: iOS physical RAM specifications are not indicative of how much RAM a given application can consistently use, due to sandbox restrictions. For example, an iPhone 11 Pro with 4 GB of physical RAM can force quit an application if it uses more than roughly 2 GB of RAM.
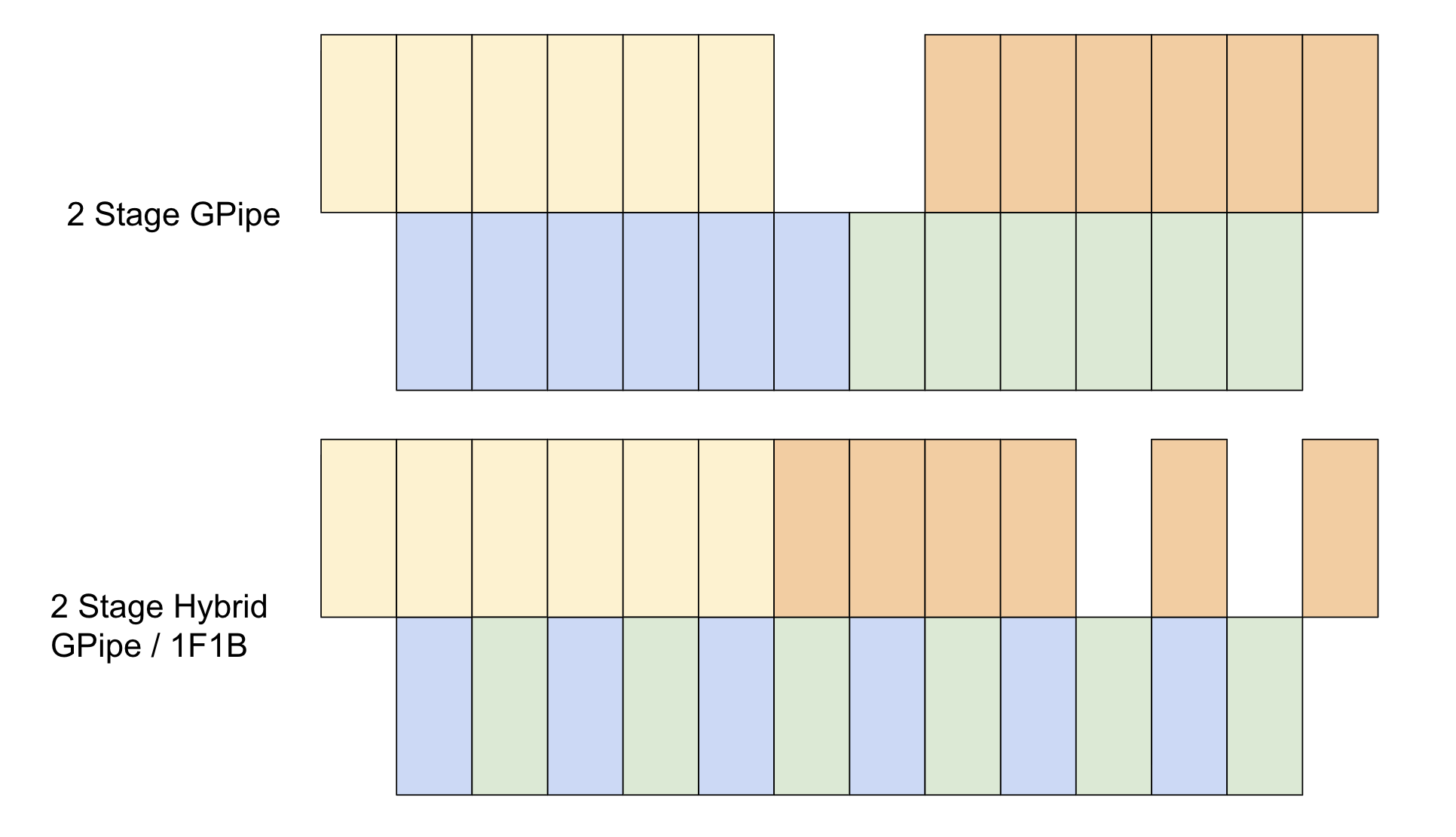
As advanced models have continued to grow in size, it has become practically impossible for singular devices to efficiently train or run models due to memory and compute limitations. Thus, parallelism techniques have been explored like pipeline parallelism [14,17] and model parallelism [24] which split models across multiple devices to take advantage of combined memory and compute overlapping.
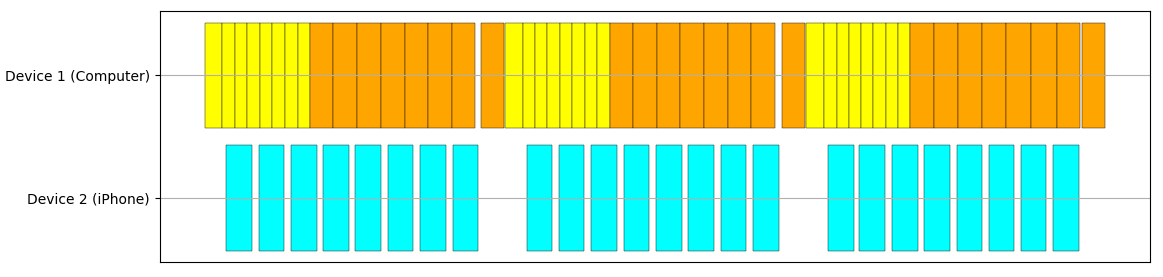
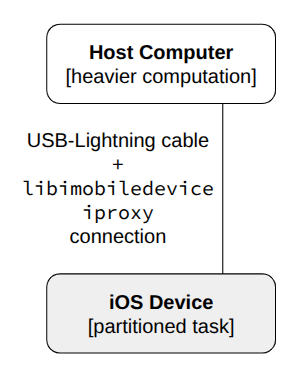
Edge computing also garnered significant interest as distributed training gained more traction and widespread use. Specifically concerning mobile devices, federated learning has been explored as mobile devices can serve as compute resources for collecting and adaptively processing information to cumulatively train models [26,16]. This paper explores a novel intersection between parallelism and mobile edge computing. We are at a point where mobile phones are powerful enough such that techniques typically applied to more powerful devices to enhance compute can be applied with such edge devices like mobile phones. We can apply such techniques to more directly enhance larger-scale model training and inference systems through these devices. To demonstrate our concept, we developed a proof-of-concept application framework, diagrammed in Figure 1. A host computer running its share of compute in PyTorch directs computation offload through a Python interface while wired to an iOS device running our Swift mobile application. We note that our techniques may not be the most optimal, but are sufficient for demonstrating tangible results.
For data communication between the iOS worker and host computer, we use Swift’s Network framework and libimobiledevice ′ s iproxy [11] to communicate bytes through a TCP socket port between wired devices. We establish a simple communication protocol for sending tensors from device to device by sending datatype, shape information, then raw values sequentially, illustrated in Figure 2.
Our mobile application utilizes Metal Per
This content is AI-processed based on open access ArXiv data.