Long-horizon manipulation has been a long-standing challenge in the robotics community. We propose ReinforceGen, a system that combines task decomposition, data generation, imitation learning, and motion planning to form an initial solution, and improves each component through reinforcement-learning-based fine-tuning. ReinforceGen first segments the task into multiple localized skills, which are connected through motion planning. The skills and motion planning targets are trained with imitation learning on a dataset generated from 10 human demonstrations, and then fine-tuned through online adaptation and reinforcement learning. When benchmarked on the Robosuite dataset, ReinforceGen reaches 80% success rate on all tasks with visuomotor controls in the highest reset range setting. Additional ablation studies show that our fine-tuning approaches contributes to an 89% average performance increase. More results and videos available in https://reinforcegen.github.io/
Imitation Learning (IL) from demonstrations is an effective approach for agents to complete tasks without environmental guidance. In long-horizon tasks, collecting demonstrations can be expensive, and the trained agent is more likely to deviate from the demonstrations to out-of-distribution states. Reinforcement Learning (RL) leverages random exploration, incorporating environmental feedback through rewards. However, long horizons exacerbate the exploration challenge, especially when the reward signals are also sparse. In the context of robot learning, collecting demonstrations for IL is often time-consuming and expensive, as it typically requires a teleoperation platform and coordinating with human operators. Furthermore, the solution quality and data coverage of the demonstrations are critical, as they directly impact the agent's performance when used in methods such as Behavior Cloning (BC) (Mandlekar et al., 2021).
One promising solution to combat demonstration insufficiency is to augment the dataset through synthetic data generation. In robotic manipulation tasks, a thread of work (Mandlekar et al., 2023b;Garrett et al., 2024;Jiang et al., 2025) focuses on object-centric data generation through demonstration adaptation. Other approaches (McDonald & Hadfield-Menell, 2022;Dalal et al., 2023) use use Task and Motion Planning (TAMP) (Garrett et al., 2021) to generate demonstrations. An alternative strategy is to hierarchically divide the task into consecutive stages with easier-to-solve subgoals (Mandlekar et al., 2023a;Garrett et al., 2024;Zhou et al., 2024). In most manipulation tasks, only a small fraction of robot execution requires high-precision movements, for example, only the contact-rich segments. Thus, these approaches concentrate the demo collection effort at the precision-intensive skill segments and connect segments using planning, ultimately improving demo sample efficiency.
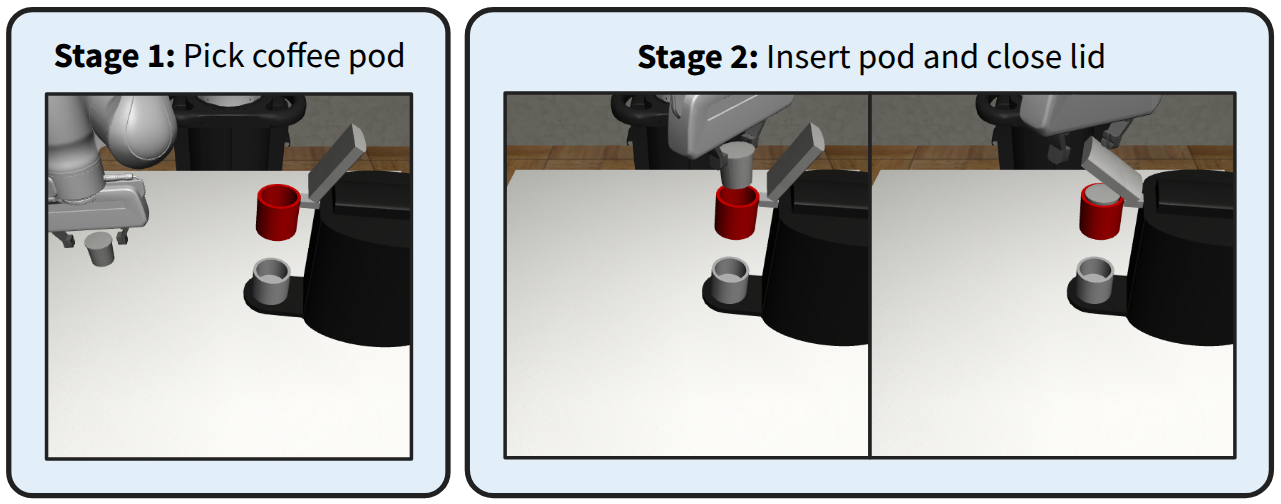
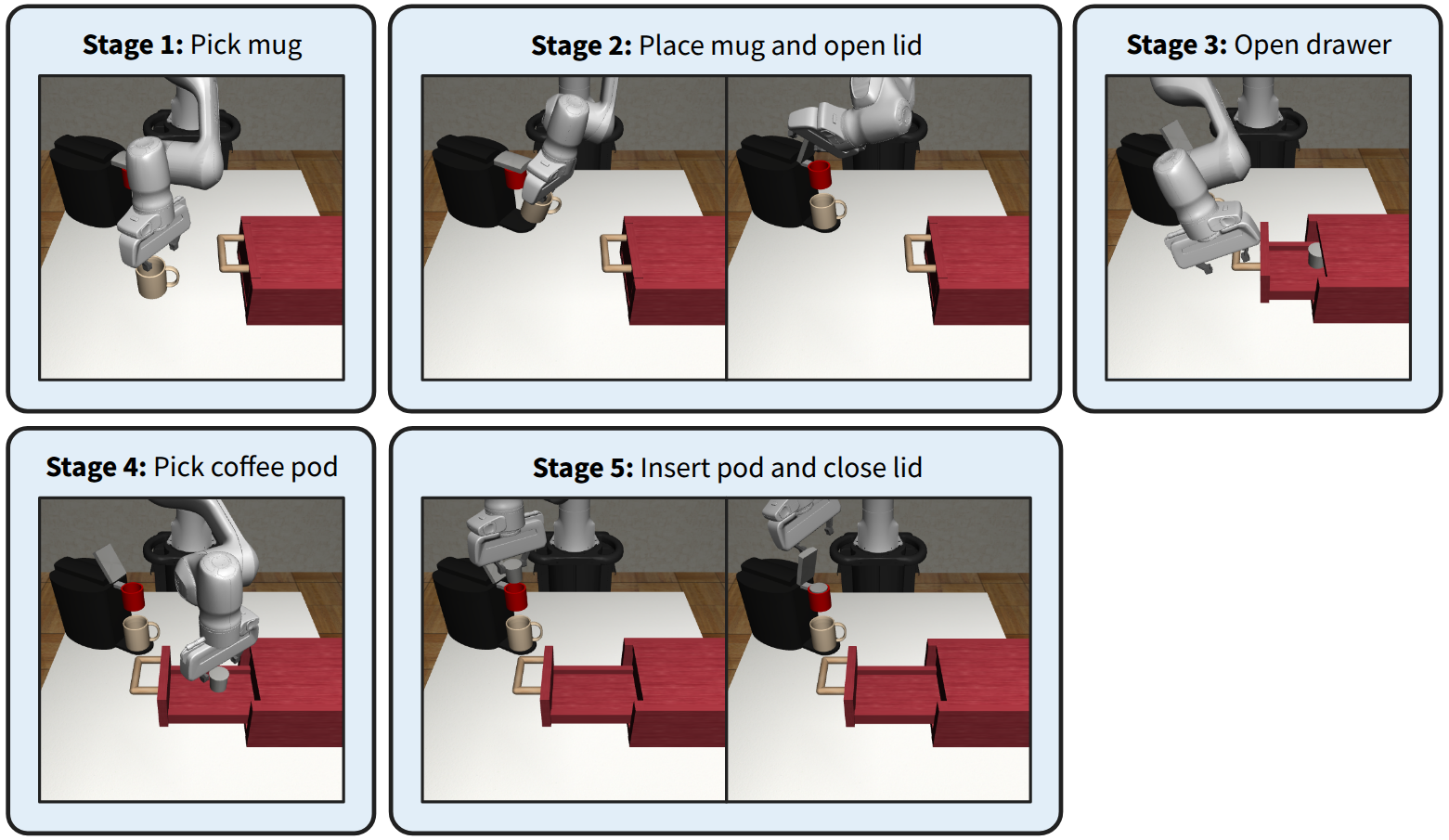
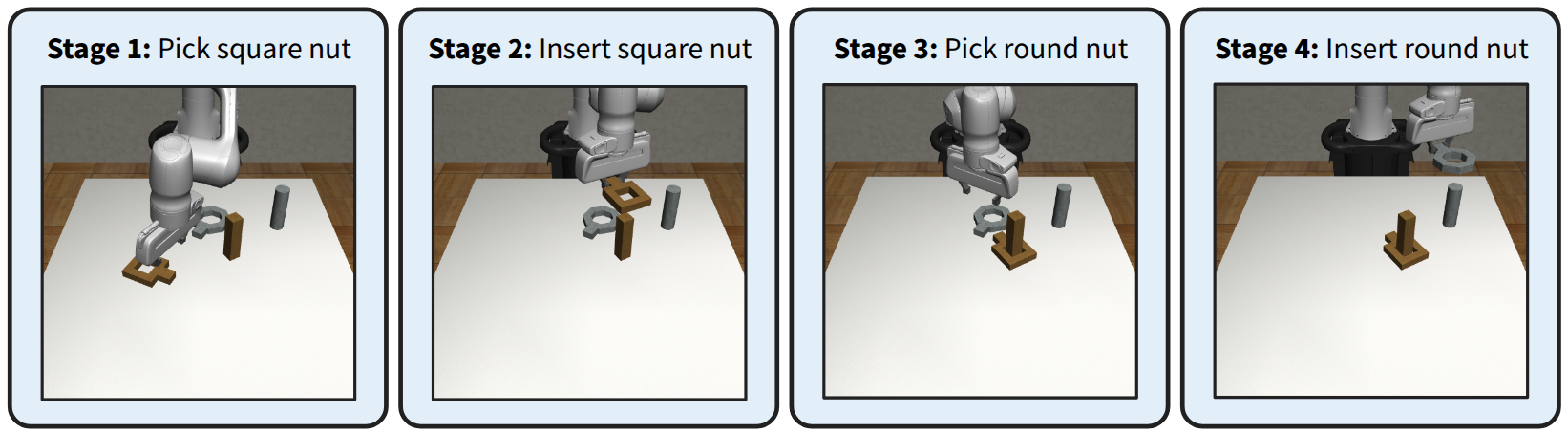
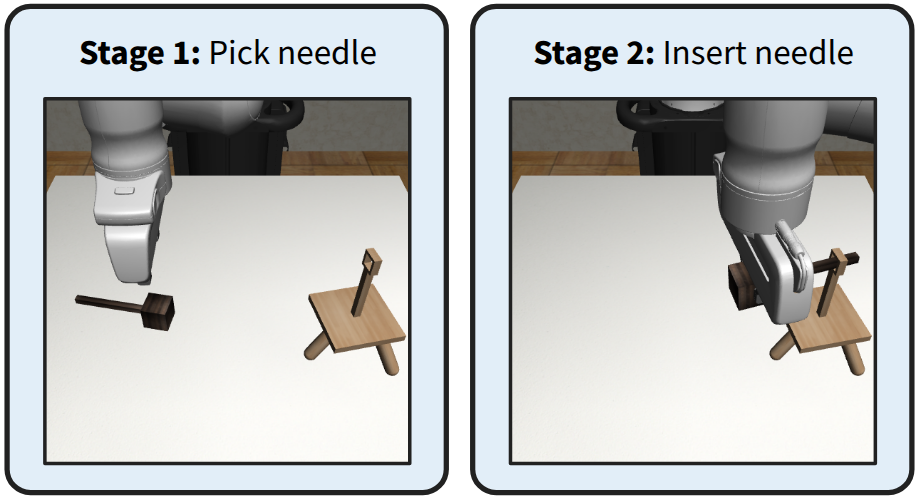
Still, these demonstration generation methods are open-loop and rely solely on offline data. As a result, IL agents trained with the generated data are still bottlenecked by the quality of the source demonstrations. To combat this, we propose ReinforceGen, a framework that improves hierarchical data generation by incorporating online exploration and environmental feedback using RL. Reinforce-Gen trains a hybrid BC agent with object-centric data generation as its base policy. It then combines distillation, causal inference, and RL to improve the base agent with online data, as well as real-time adaptation from environment feedback during deployment. We demonstrate that ReinforceGen Figure 1: ReinforceGen first creates an offline dataset by synthetic data generation from a small set of source human demonstrations. The dataset is then used to train a hybrid imitation learning agent that alternates between moving to a predicted waypoint using a motion planner and directly controlling the robot using a learned policy. Finally, ReinforceGen uses reinforcement learning to fine-tune the agent with online environment interactions.
produces high-performance hybrid data generators and show that ReinforceGen-generated data can also be used to train end-to-end visuomotor imitation policies.
The contributions of this paper are the following.
We propose ReinforceGen, an automated demonstration generation system that integrates planning, behavior cloning, and reinforcement learning to train policies that robustly solve long-horizon and contact-rich tasks using only a handful of human demonstrations.
Through using localized reinforcement learning, ReinforceGen is able to explore and thus go beyond existing automated demonstration systems, which are fundamentally bounded by the performance of the demonstrator, and learn more successful and efficient behaviors.
At deployment time, ReinforceGen executes a hybrid control strategy that alternates between motion planning and fine-tuned skill policy segments, where the use of planning also at deployment reduces the generalization burden of learning, resulting in higher success rates.
We evaluate ReinforceGen on multi-stage contact-rich manipulation tasks. ReinforceGen reaches an 80% success rate, almost doubling the success rate of the prior state-of-the-art (Garrett et al., 2024).
Finally, we train proficient end-to-end imitation agents with ReinforceGen.
Imitation and reinforcement learning for robotics. Imitation Learning (IL) from human demonstrations has been a pillar in robot learning, benchmarking significant results in both simulations and real-world applications (Florence et al., 2022;Chi et al., 2023;Shafiullah et al., 2022;Zhao et al., 2023;Kim et al., 2024). Reinforcement Learning (RL) is another promising approach to solve robotic problems with even real-world successes (Tang et al., 2025;Wu et al., 2022;Yu et al., 2023). However, without engineered rewards, RL often struggles with exploration and can even outright fail (Zhou et al., 2024). Similar to our approach, Nair et
This content is AI-processed based on open access ArXiv data.