Reranking is a critical stage in contemporary information retrieval (IR) systems, improving the relevance of the user-presented final results by honing initial candidate sets. This paper is a thorough guide to examine the changing reranker landscape and offer a clear view of the advancements made in reranking methods. We present a comprehensive survey of reranking models employed in IR, particularly within modern Retrieval Augmented Generation (RAG) pipelines, where retrieved documents notably influence output quality.
We embark on a chronological journey through the historical trajectory of reranking techniques, starting with foundational approaches, before exploring the wide range of sophisticated neural network architectures such as cross-encoders, sequence-generation models like T5, and Graph Neural Networks (GNNs) utilized for structural information. Recognizing the computational cost of advancing neural rerankers, we analyze techniques for enhancing efficiency, notably knowledge distillation for creating competitive, lighter alternatives. Furthermore, we map the emerging territory of integrating Large Language Models (LLMs) in reranking, examining novel prompting strategies and fine-tuning tactics. This survey seeks to elucidate the fundamental ideas, relative effectiveness, computational features, and real-world trade-offs of various reranking strategies. The survey provides a structured synthesis of the diverse reranking paradigms, highlighting their underlying principles and comparative strengths and weaknesses.
💡 Deep Analysis
📄 Full Content
This version of the article has been accepted for publication in Springer CCIS, volume 2775, after peer review (when ap-
plicable) but is not the Version of Record and does not reflect post-acceptance improvements, or any corrections. The
Version of Record is available online at springnature. Use of this Accepted Version is subject to the publisher’s Ac-
cepted Manuscript terms of use https://www.springernature.com/gp/open-research/policies/accepted-manuscriptterms.
The Evolution of Reranking Models in
Information Retrieval: From Heuristic Methods
to Large Language Models
Tejul Pandit1[0009-0006-4376-1063], Sakshi Mahendru1∗, Meet Raval2∗, and
Dhvani Upadhyay3
1 Palo Alto Networks, USA
2 University of Southern California, USA
3 Dhirubhai Ambani University, India
tejulpandit96@gmail.com
Abstract. Reranking is a critical stage in contemporary information re-
trieval (IR) systems, improving the relevance of the user-presented final
results by honing initial candidate sets. This paper is a thorough guide
to examine the changing reranker landscape and offer a clear view of the
advancements made in reranking methods. We present a comprehensive
survey of reranking models employed in IR, particularly within mod-
ern Retrieval Augmented Generation (RAG) pipelines, where retrieved
documents notably influence output quality.
We embark on a chronological journey through the historical trajectory
of reranking techniques, starting with foundational approaches, before
exploring the wide range of sophisticated neural network architectures
such as cross-encoders, sequence-generation models like T5, and Graph
Neural Networks (GNNs) utilized for structural information. Recognizing
the computational cost of advancing neural rerankers, we analyze tech-
niques for enhancing efficiency, notably knowledge distillation for creat-
ing competitive, lighter alternatives. Furthermore, we map the emerging
territory of integrating Large Language Models (LLMs) in reranking, ex-
amining novel prompting strategies and fine-tuning tactics. This survey
seeks to elucidate the fundamental ideas, relative effectiveness, compu-
tational features, and real-world trade-offs of various reranking strate-
gies. The survey provides a structured synthesis of the diverse rerank-
ing paradigms, highlighting their underlying principles and comparative
strengths and weaknesses.
Keywords: Rerankers, Information Retrieval (IR), Retrieval Augmented
Generation (RAG), Learning-to-rank, Neural rerankers, cross-encoders,
T5, Graph Neural Networks (GNN), knowledge distillation, Large Lan-
guage Models (LLM)
* Equal contribution
arXiv:2512.16236v1 [cs.IR] 18 Dec 2025
This version of the article has been accepted for publication in Springer CCIS, volume 2775, after peer review (when ap-
plicable) but is not the Version of Record and does not reflect post-acceptance improvements, or any corrections. The
Version of Record is available online at springnature. Use of this Accepted Version is subject to the publisher’s Ac-
cepted Manuscript terms of use https://www.springernature.com/gp/open-research/policies/accepted-manuscriptterms.
2
T. Pandit et al.
1
Introduction
Information retrieval (IR) systems are essential in today’s digital world, with
their ability to power anything from online search and recommender systems to
sophisticated question-answering and knowledge management platforms. A crit-
ical component within these systems is the reranking stage. Reranking carefully
reorders these candidates to show the user the most pertinent results after an
initial, often rapid, retrieval phase that produces an extensive collection of can-
didate documents. This dramatically improves the overall quality and efficacy of
the IR system[1]. Notably, the significant development in Large Language Models
(LLMs) has subsequently driven substantial improvements and interest in Re-
trieval Augmented Generation (RAG) pipelines, where the precision of retrieved
context, refined by reranking, is crucial for generating accurate and relevant
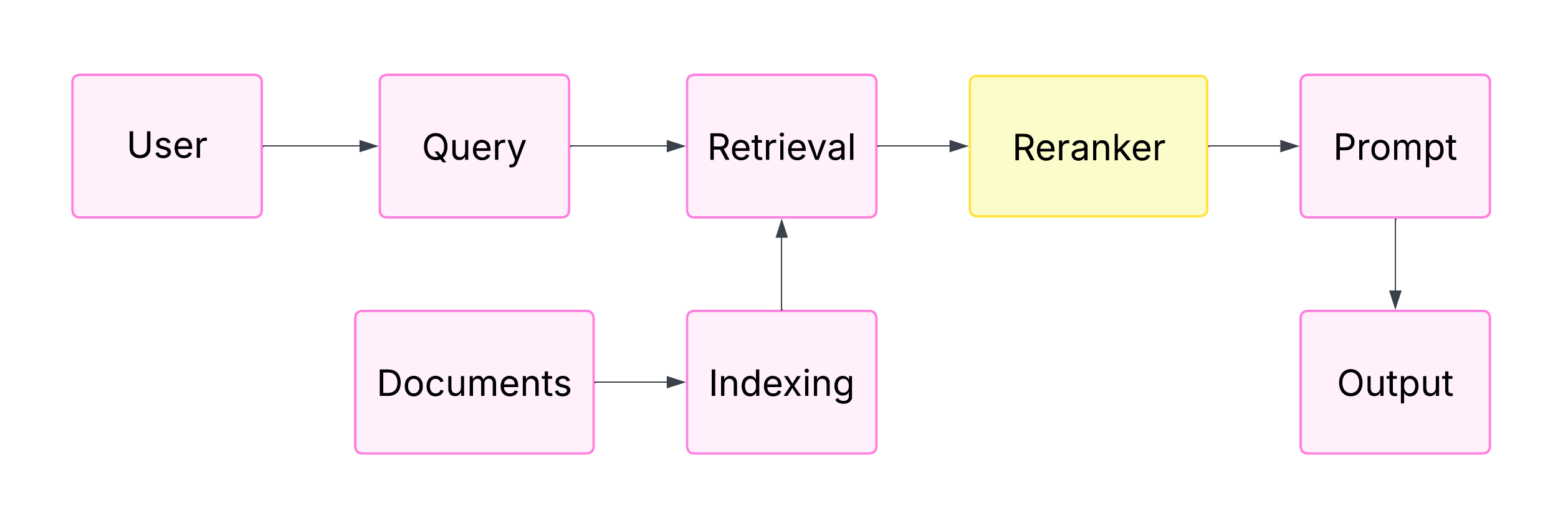
outputs[2]. Based on [3], we represent the typical placement of the reranking
component within a RAG pipeline in Figure 1.
Fig. 1. RAG approach highlighting a post-retrieval step of Reranking documents.
Reranking methods have evolved significantly, from heuristic scoring and
traditional learning-to-rank models to deep learning and, more recently, LLMs,
enabling richer semantic understanding and inter-document relationships.
This survey provides a comprehensive exploration of the evolving field of
reranking models in IR. We trace the development trajectory from classical
learning-to-rank methods in Section 3, followed by Deep learning rerankers in
Section 4. We also cover methods aimed at improving the efficiency of reranking
models, with a particular focus on knowledge distillation techniques in Section
5. Finally, we examine the cutting-edge integration of LLM-based rerankers in
Section 6. This study aims to provide scholars and practitioners with a