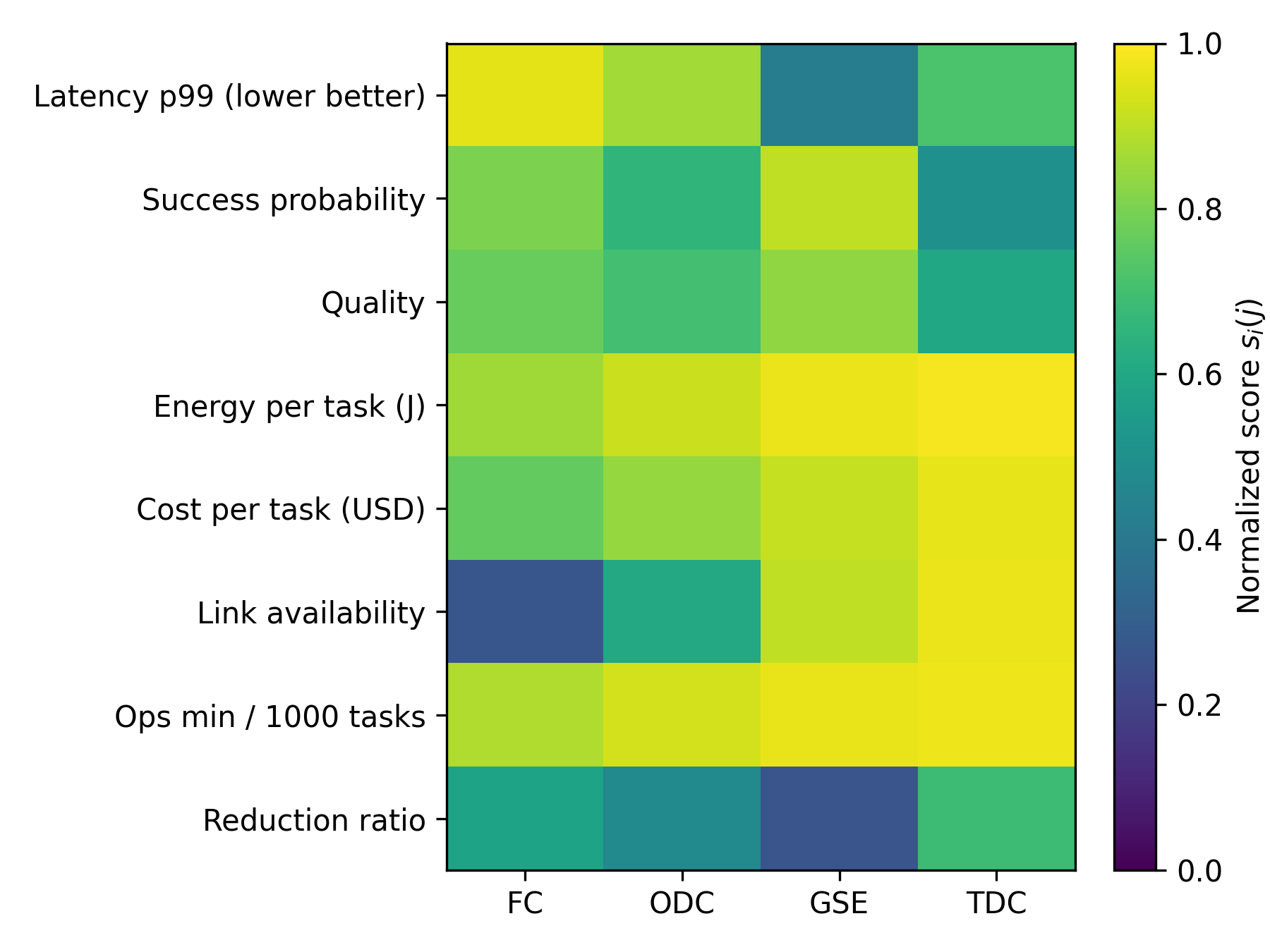
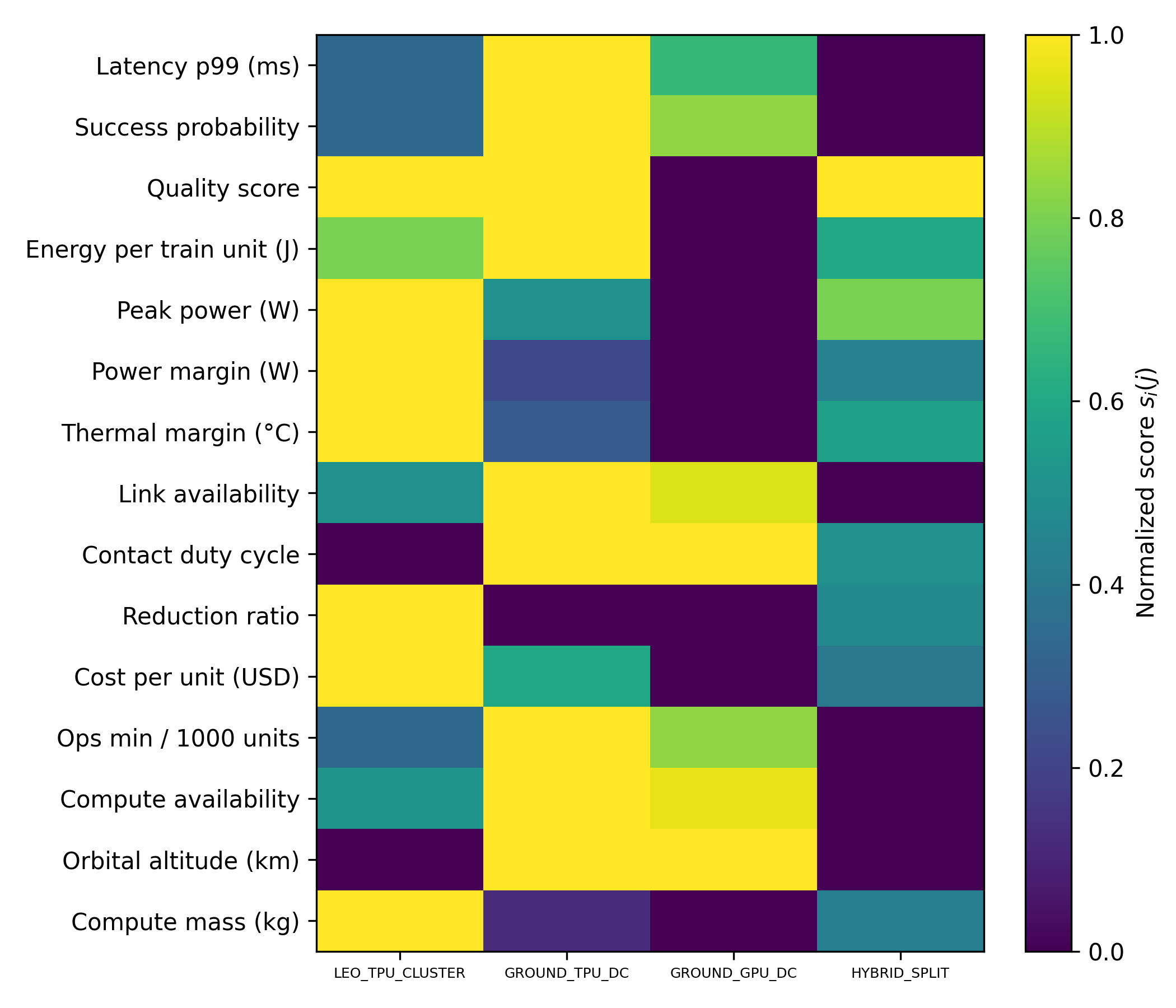
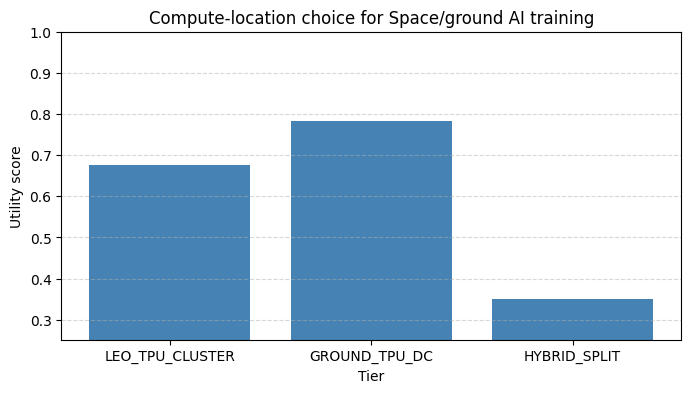
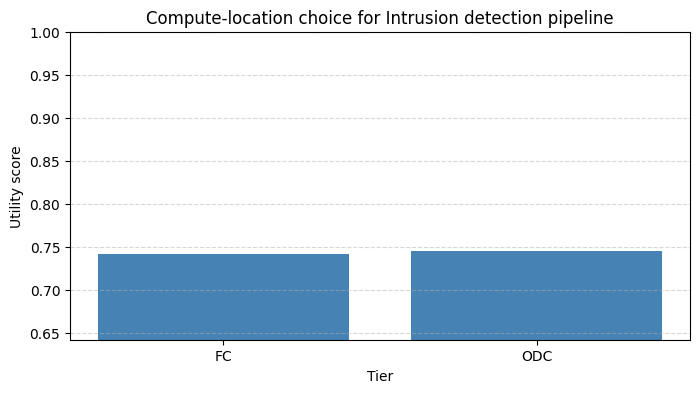
Spacecraft increasingly rely on heterogeneous computing resources spanning onboard flight computers, orbital data centers, ground station edge nodes, and terrestrial cloud infrastructure. Selecting where a workload should execute is a nontrivial multi objective problem driven by latency, reliability, power, communication constraints, cost, and regulatory feasibility. This paper introduces a quantitative optimization framework that formalizes compute location selection through empirically measurable metrics, normalized scoring, feasibility constraints, and a unified utility function designed to operate under incomplete information. We evaluate the model on two representative workloads demonstrating how the framework compares compute tiers and identifies preferred deployment locations. The approach provides a structured, extensible method for mission designers to reason about compute placement in emerging space architectures.
💡 Deep Analysis
📄 Full Content
When to compute in space
Rajiv Thummala ∗and Gregory Falco †
Cornell University, Ithaca, NY, 14850
Spacecraft increasingly rely on heterogeneous computing resources spanning onboard flight
computers, orbital data centers, ground station edge nodes, and terrestrial cloud infrastructure.
Selecting where a workload should execute is a nontrivial multi objective problem driven by
latency, reliability, power, communication constraints, cost, and regulatory feasibility. This
paper introduces a quantitative optimization framework that formalizes compute-location
selection through empirically measurable metrics, normalized scoring, feasibility constraints,
and a unified utility function designed to operate under incomplete information. We evaluate the
model on two representative workloads demonstrating how the framework compares compute
tiers and identifies preferred deployment locations. The approach provides a structured,
extensible method for mission designers to reason about compute placement in emerging space
architectures.
I. Introduction
Modern satellites generate unprecedented volumes of data. Historically, this data followed the simple flow of being
captured through the payload, stored in onboard memory, and downlinked to ground stations for processing. This
paradigm is shifting, however, as new computational paradigms and space infrastructure is enabling diverse options
for where computation occurs. In the decades to come, mission architects can choose to perform computation for a
spacecraft on the onboard flight computer, an orbital data center, ground station edge nodes, and terrestrial data centers.
However, the decision of where to execute a computational workload in the context of space systems remains a complex
multi-objective optimization problem. Each compute tier presents distinct trade-offs across latency, reliability, power
consumption, communication overhead, and cost. Furthermore, regulatory considerations such as ITAR restrictions,
data sovereignty requirements, and mission security policies may impose hard constraints that supersede performance
considerations.
Existing approaches to compute placement in distributed systems typically assume homogeneous network conditions
and focus on cloud-edge trade-offs in terrestrial settings. These frameworks do not adequately capture the unique
constraints of space systems such as intermittent line-of-sight communication windows, orbit-dependent propagation
delays, power budgets dominated by solar panel geometry and eclipse periods, radiation effects on computational
reliability, and the need to balance operational complexity against mission autonomy.
This paper [1] introduces a formal optimization framework designed specifically for this heterogeneous space
compute landscape, providing mission architects with a principled method to navigate these trade-offs and select the
appropriate compute tier for each workload.
II. Prior Art
Several studies describe the ongoing shift in how computing is conceived and implemented in the space domain. [2]
outlines four principal phases in the development of space computing architectures. The first, distributed embedded
systems, characterizes spacecraft composed of independent embedded units. The second, integrated electronic systems,
consolidates multiple functions onto a single platform. The third, external intelligent systems, augments the integrated
architecture with high performance computing modules capable of executing complex algorithms, including artificial
intelligence. The fourth, integrated intelligent systems, unifies the external and integrated architectures into a single
construct with reduced power consumption, smaller volume, and improved performance. Although the work provides
a clear articulation of the advantages and limitations of each paradigm, it does not supply a formal decision-making
construct that would allow mission engineers to determine which architecture is most appropriate for a given application.
[3] similarly compares multiple space computing paradigms and examines their operational constraints, incorporating
examples from real systems such as the James Webb Space Telescope. The authors argue that an orbital data center
∗PhD Student, Sibley School of Mech. and Aerospace Engineering, 124 Hoy Rd, and AIAA Member
†Assistant Professor, Department of Mech. and Aerospace Engineering, 124 Hoy Rd, and AIAA Member
1
arXiv:2512.17054v1 [cs.CE] 18 Dec 2025
located at the Earth–Moon L1 point could support activities such as calibration, cosmic ray scrubbing, and first-order
science processing by receiving raw instrument data directly from JWST. This paper, however, also stops short of
offering a rigorous decision function to guide engineers in selecting an optimal computing architecture.
Although academic literature on orbital data centers remains sparse, the concept of employing sun-synchronous
orbits to provide large-scale AI computation and inference has gained widespread media attention. [4