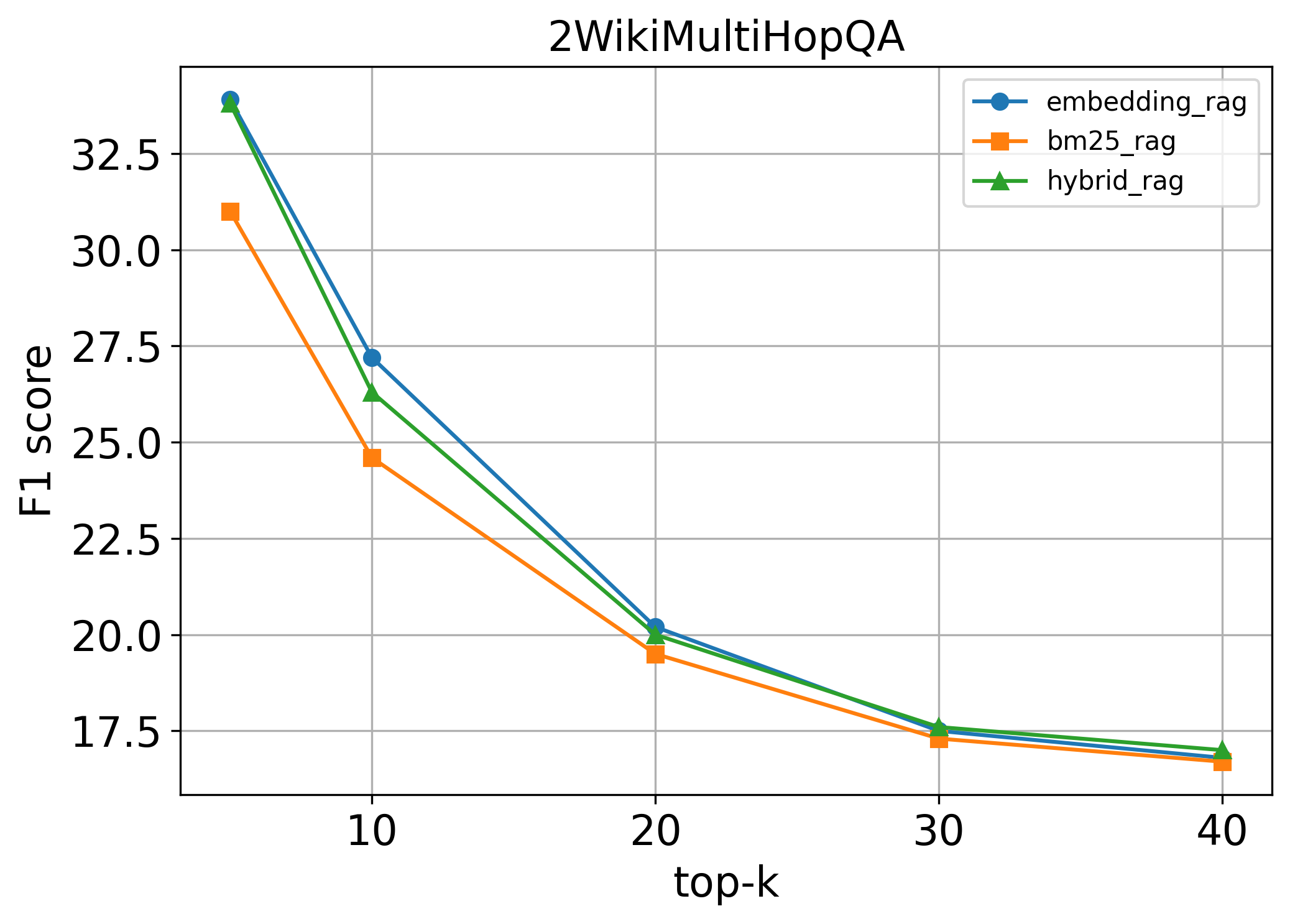
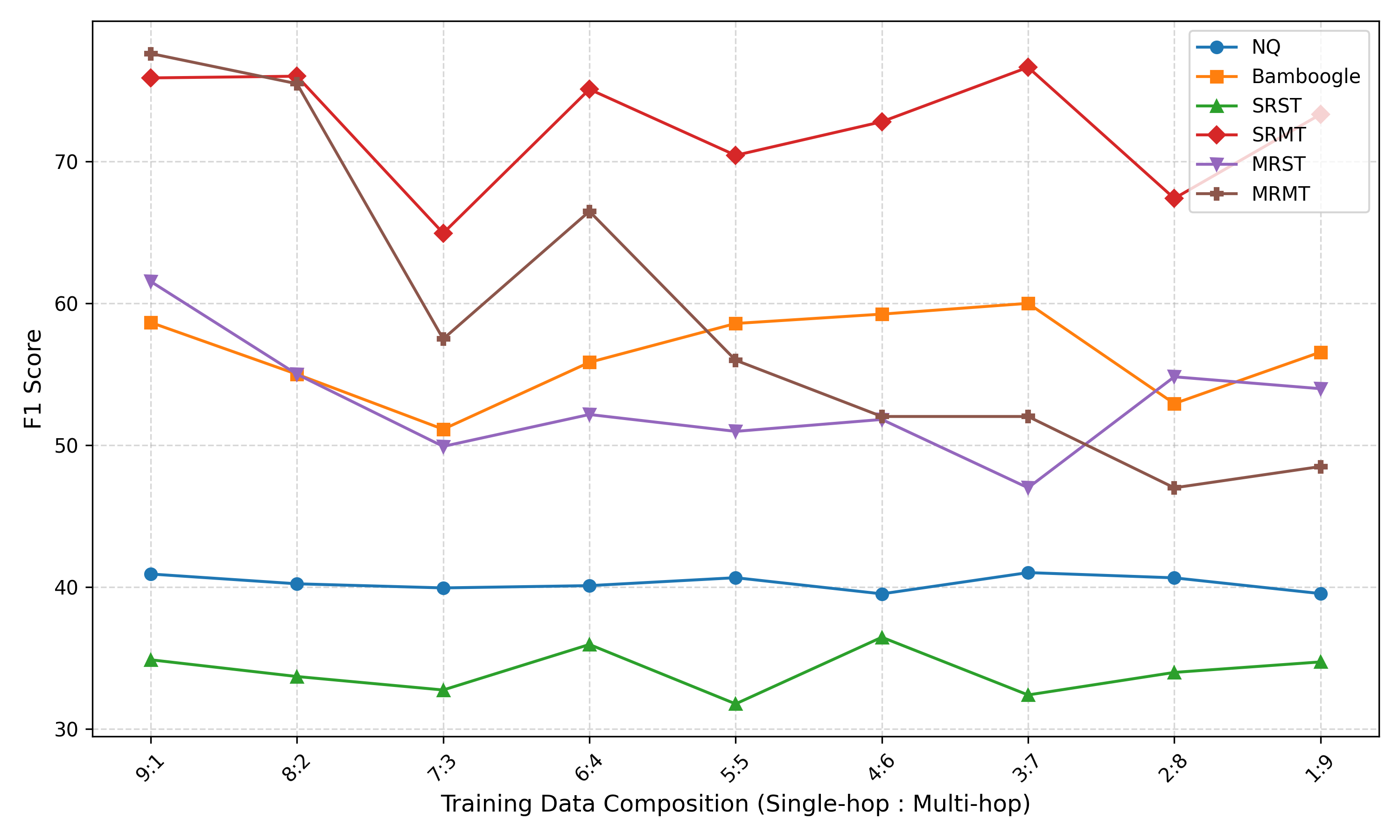
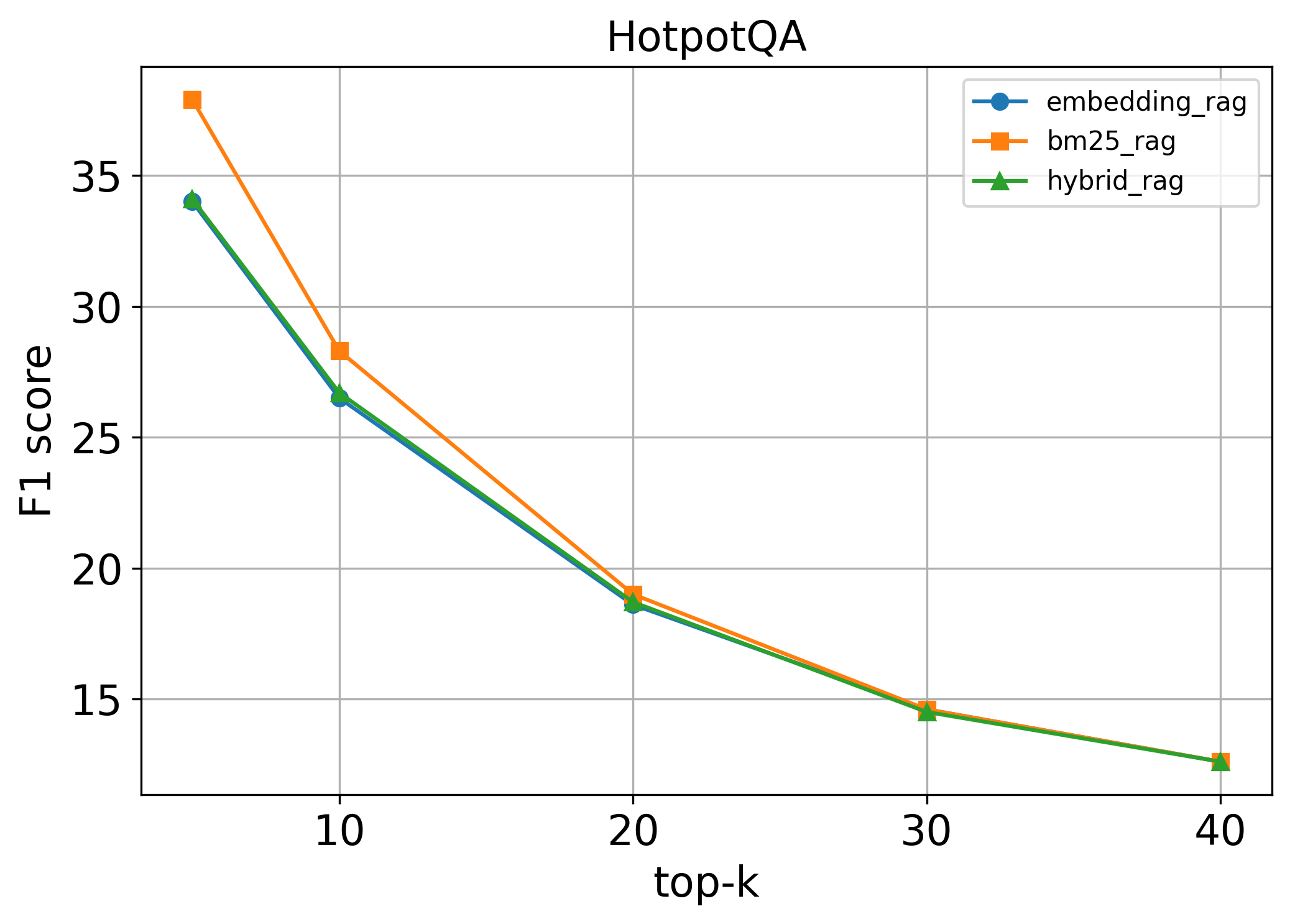
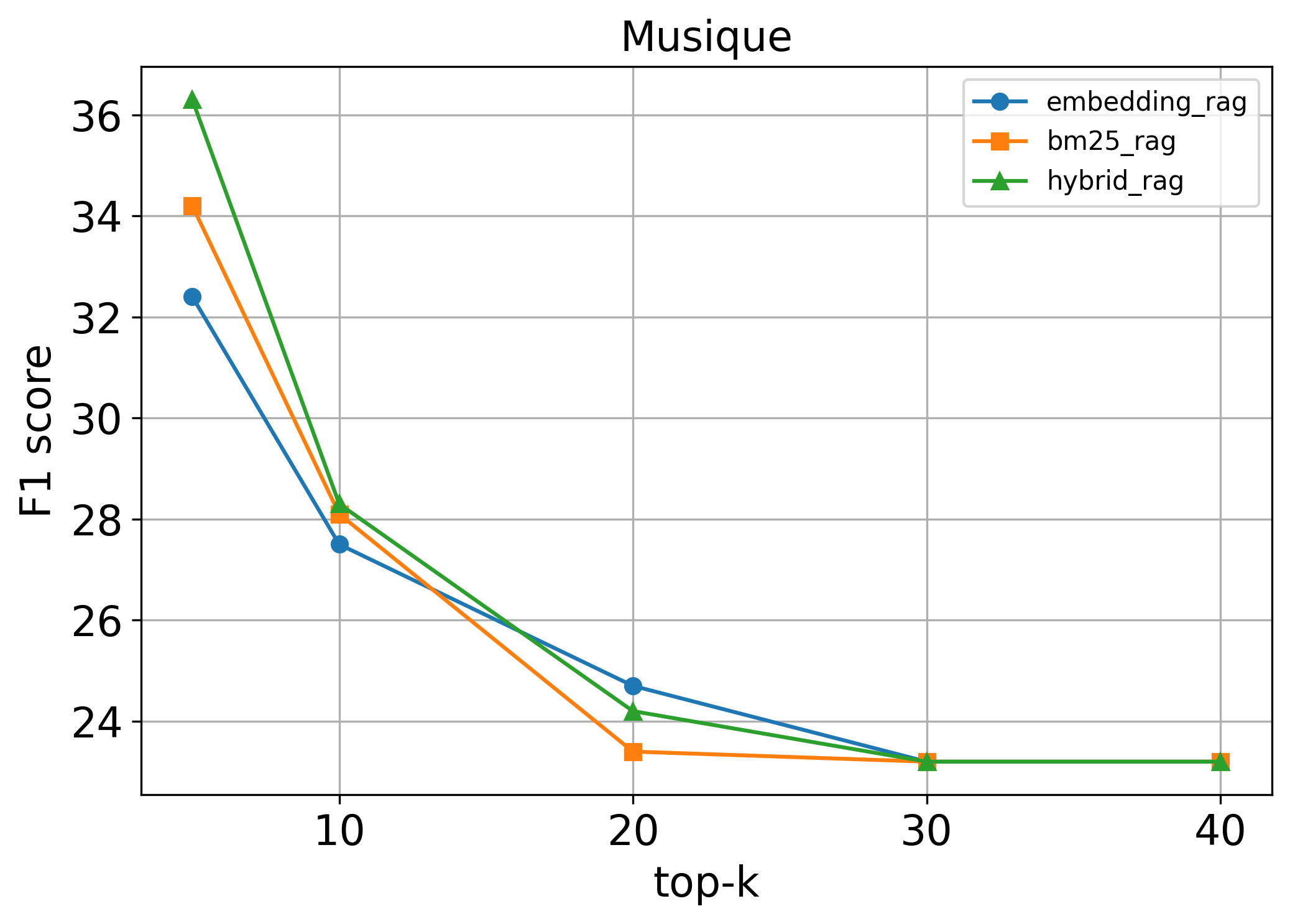
Training LLMs to invoke tools and leverage retrieved information necessitates high-quality, diverse data. However, existing pipelines for synthetic data generation often rely on tens of thousands of real API calls to enhance generalization, incurring prohibitive costs while lacking multi-hop reasoning and self-reflection. To address these limitations, we introduce ToolForge, an automated synthesis framework that achieves strong real-world tool-calling performance by constructing only a small number of virtual tools, eliminating the need for real API calls. ToolForge leverages a (question, golden context, answer) triple to synthesize large-scale tool-learning data specifically designed for multi-hop search scenarios, further enriching the generated data through multi-hop reasoning and self-reflection mechanisms. To ensure data fidelity, we employ a Multi-Layer Validation Framework that integrates both rule-based and model-based assessments. Empirical results show that a model with only 8B parameters, when trained on our synthesized data, outperforms GPT-4o on multiple benchmarks. Our code and dataset are publicly available at https://github.com/Buycar-arb/ToolForge .
💡 Deep Analysis
📄 Full Content
ToolForge: A Data Synthesis Pipeline for Multi-Hop Search
without Real-World APIs
Hao Chen1,2, Zhexin Hu2,3, Jiajun Chai2, Haocheng Yang2,4, Hang He2,5, Xiaohan Wang2,
Wei Lin2, Luhang Wang1, Guojun Yin2†, Zhuofeng Zhao1†
1North China University of Technology, 2Meituan, 3Institute of Software, Chinese Academy of Sciences
4National University of Singapore, 5East China Normal University
Abstract
Training LLMs to invoke tools and leverage retrieved infor-
mation necessitates high-quality, diverse data. However, ex-
isting pipelines for synthetic data generation often rely on
tens of thousands of real API calls to enhance generalization,
incurring prohibitive costs while lacking multi-hop reasoning
and self-reflection. To address these limitations, we introduce
ToolForge, an automated synthesis framework that achieves
strong real-world tool-calling performance by constructing
only a small number of virtual tools, eliminating the need for
real API calls. ToolForge leverages a (question, golden con-
text, answer) triple to synthesize large-scale tool-learning data
specifically designed for multi-hop search scenarios, further
enriching the generated data through multi-hop reasoning
and self-reflection mechanisms. To ensure data fidelity, we em-
ploy a Multi-Layer Validation Framework that integrates both
rule-based and model-based assessments. Empirical results
show that a model with only 8B parameters, when trained
on our synthesized data, outperforms GPT-4o on multiple
benchmarks. Our code and dataset are publicly available at
https://github.com/Buycar-arb/ToolForge.
1
Introduction
In recent years, large language models (LLMs) have demon-
strated remarkable capabilities in natural language understand-
ing [19, 46], particularly in search and tool learning. By inte-
grating external tool APIs [5, 30], tool-augmented LLMs have
achieved a qualitative leap in practical applicability, enabling
them to tackle complex real-world scenarios [30, 33]. Tool-
calling mechanisms empower Large Language Models (LLMs)
to interact with the external environment, enabling them to
dynamically retrieve and access up-to-date information [51].
This strategy effectively mitigates the inherent limitations of
static pretraining data and substantially expands their practical
value across various application domains. Notable examples
include workflow automation [53] and travel planning [10].
Training LLMs for tool-calling typically requires large-scale,
high-quality synthetic data covering diverse scenarios [20].
However, since training LLMs on a limited set of tools is in-
sufficient for achieving robust generalization [24, 34], existing
data synthesis pipelines [20, 39, 42] commonly compensate
for this deficiency by designing templates and executing tens
of thousands of real-world API calls to obtain results [29]
and construct training samples. To enhance the generalization
†Corresponding author.
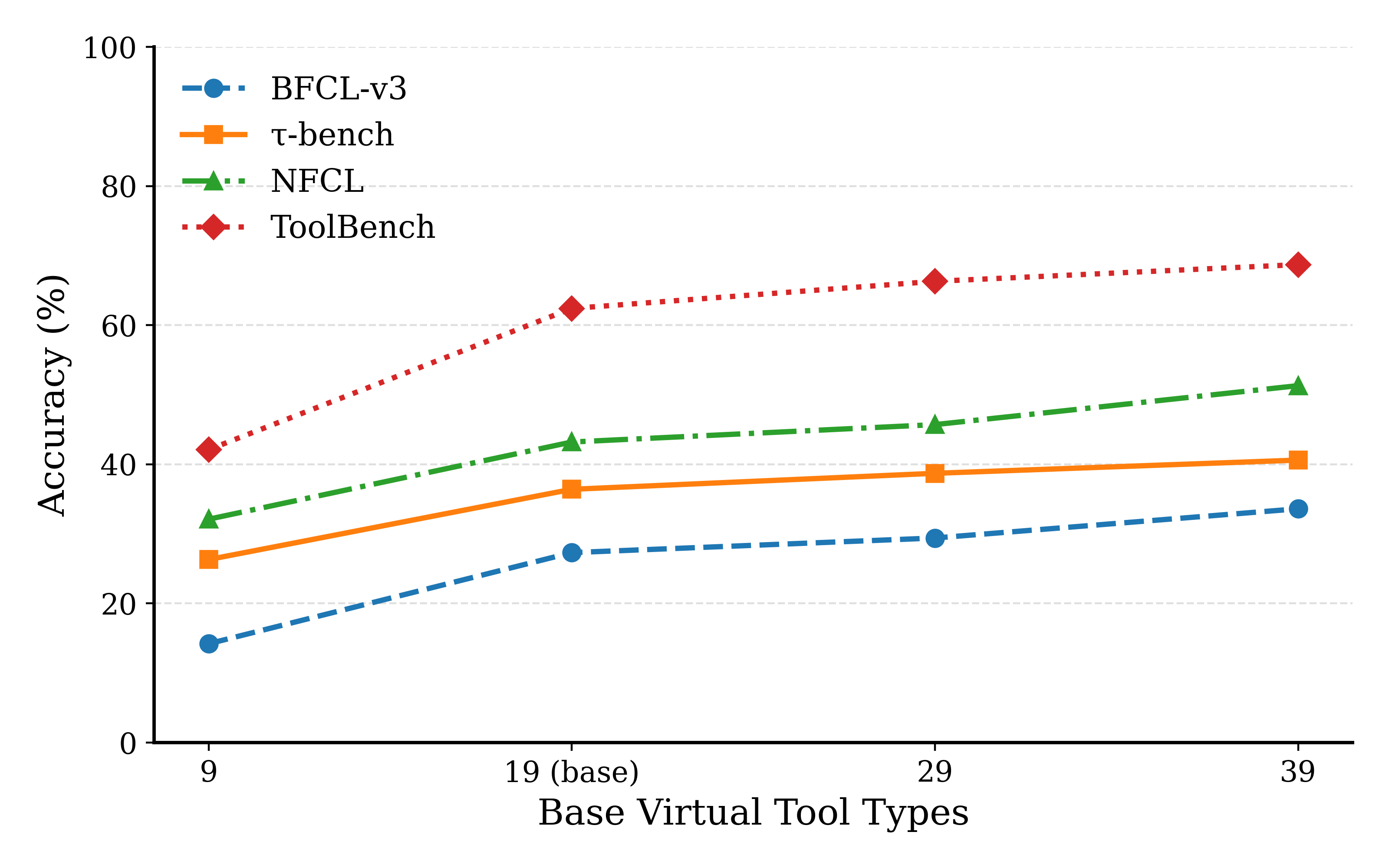
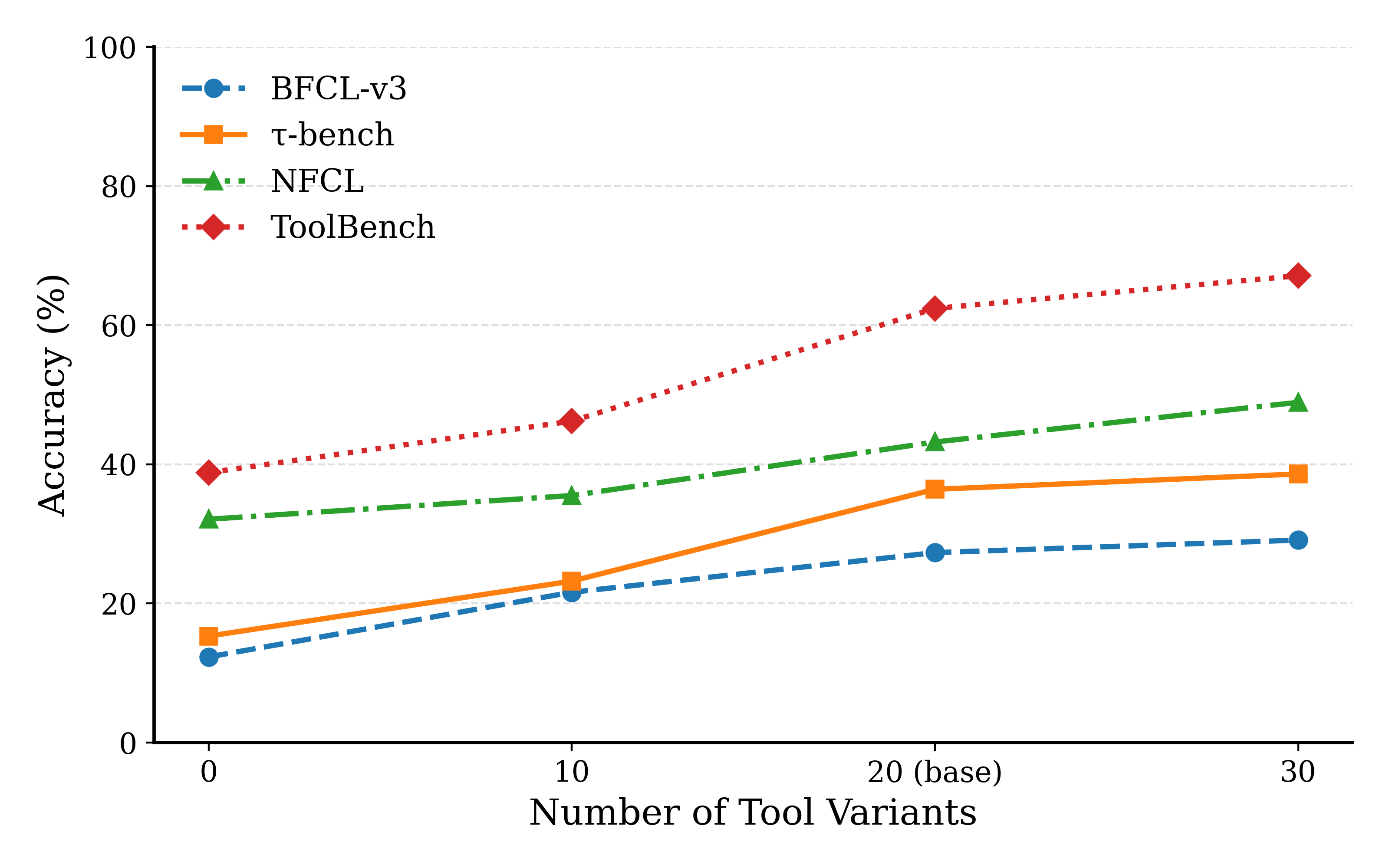
capability of Large Language Models (LLMs), we utilize 19
virtual tools as surrogates for real-world API calls.
Real-world tasks often require multi-hop reasoning [43],
i.e., a reasoning process that derives the final answer through
multiple intermediate steps and logical chains [12, 47]. Yet,
most existing works concentrate on text-based multi-hop rea-
soning [28, 41], lacking the capability to integrate with exter-
nal tools. Concurrently, while research indicates that reflec-
tion enables models to inspect and revise their own reasoning
processes [35], its potential in complex scenarios involving
multi-hop reasoning and tool-calling remains underexplored.
To bridge this gap, we devise four tool-calling paradigms and
three error perturbation classes, thereby deriving 29 distinct
interaction patterns that encompass complex, multi-turn tool-
calling scenarios.
Ensuring the fidelity of complex, automatically synthesized
data presents a significant challenge [3, 39]. Existing valida-
tion approaches are often superficial, primarily verifying the
syntactic correctness of tool-calling and the final answer con-
sistency [27, 42]. They largely overlook the semantic and logi-
cal integrity of intermediate reasoning steps, allowing subtle
errors in multi-step chains to go undetected and thus com-
promising the overall data quality [20]. To address this, we
introduce a Multi-Layer Validation Framework that combines
rule-based heuristics with model-based assessments, using
Monte Carlo Tree Search (MCTS) [36] for hard negative mining
to substantially enhance validation robustness and coverage.
In summary, our key contributions are fourfold:
• We introduce ToolForge, a novel automated synthesis frame-
work that, given only a (question, golden context, answer)
triple, can generate large-scale tool-calling data featuring
multi-hop reasoning and self-reflection.
• We enhance the generalization capability of LLMs by lever-
aging virtual tools instead of real APIs, and incorporating
reflection-driven multi-turn interactions to generate diverse
reasoning-tool int