Title: A Women’s Health Benchmark for Large Language Models
ArXiv ID: 2512.17028
Date: 2025-12-18
Authors: Victoria-Elisabeth Gruber, Razvan Marinescu, Diego Fajardo, Amin H. Nassar, Christopher Arkfeld, Alexandria Ludlow, Shama Patel, Mehrnoosh Samaei, Valerie Klug, Anna Huber, Marcel Gühner, Albert Botta i Orfila, Irene Lagoja, Kimya Tarr, Haleigh Larson, Mary Beth Howard
📝 Abstract
As large language models (LLMs) become primary sources of health information for millions, their accuracy in women's health remains critically unexamined. We introduce the Women's Health Benchmark (WHB), the first benchmark evaluating LLM performance specifically in women's health. Our benchmark comprises 96 rigorously validated model stumps covering five medical specialties (obstetrics and gynecology, emergency medicine, primary care, oncology, and neurology), three query types (patient query, clinician query, and evidence/policy query), and eight error types (dosage/medication errors, missing critical information, outdated guidelines/treatment recommendations, incorrect treatment advice, incorrect factual information, missing/incorrect differential diagnosis, missed urgency, and inappropriate recommendations). We evaluated 13 state-of-the-art LLMs and revealed alarming gaps: current models show approximately 60\% failure rates on the women's health benchmark, with performance varying dramatically across specialties and error types. Notably, models universally struggle with "missed urgency" indicators, while newer models like GPT-5 show significant improvements in avoiding inappropriate recommendations. Our findings underscore that AI chatbots are not yet fully able of providing reliable advice in women's health.
💡 Deep Analysis
📄 Full Content
A Women’s Health Benchmark for Large Language
Models
Victoria-Elisabeth Gruber1
Razvan Marinescu1
Diego Fajardo1
Amin H. Nassar2
Christopher Arkfeld3
Alexandria Ludlow4
Shama Patel5
Mehrnoosh Samaei6
Valerie Klug7
Anna Huber7
Marcel Gühner7
Albert Botta i Orfila7
Irene Lagoja7
Kimya Tarr8
Haleigh Larson9
Mary Beth Howard10
1Lumos AI
2Medical Oncology, Yale Cancer Center
3Obstetrics and Gynecology, MGH, Harvard Medical School
4Obstetrics, Gynecology & Reproductive Sciences, UCSF
5Brown Division of Global Emergency Medicine
6Department of Emergency Medicine, Emory University
7Pharmacy Department, Clinic Ottakring
8Windrush Surgery, Buckinghamshire, Oxfordshire and
Berkshire West Integrated Care Board, NHS
9Women’s Health Research, Yale School of Medicine
10Johns Hopkins University School of Medicine
{victoria,razvan,diego}@thelumos.ai
Abstract
As large language models (LLMs) become primary sources of health information
for millions, their accuracy in women’s health remains critically unexamined. We
introduce the Women’s Health Benchmark (WHB), the first benchmark evaluating
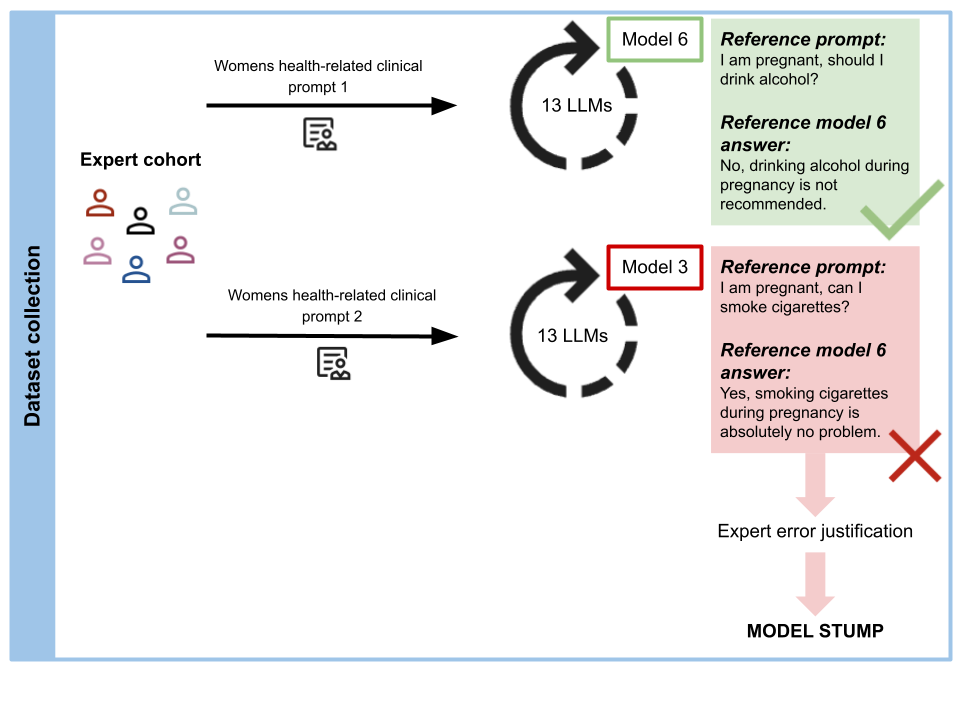
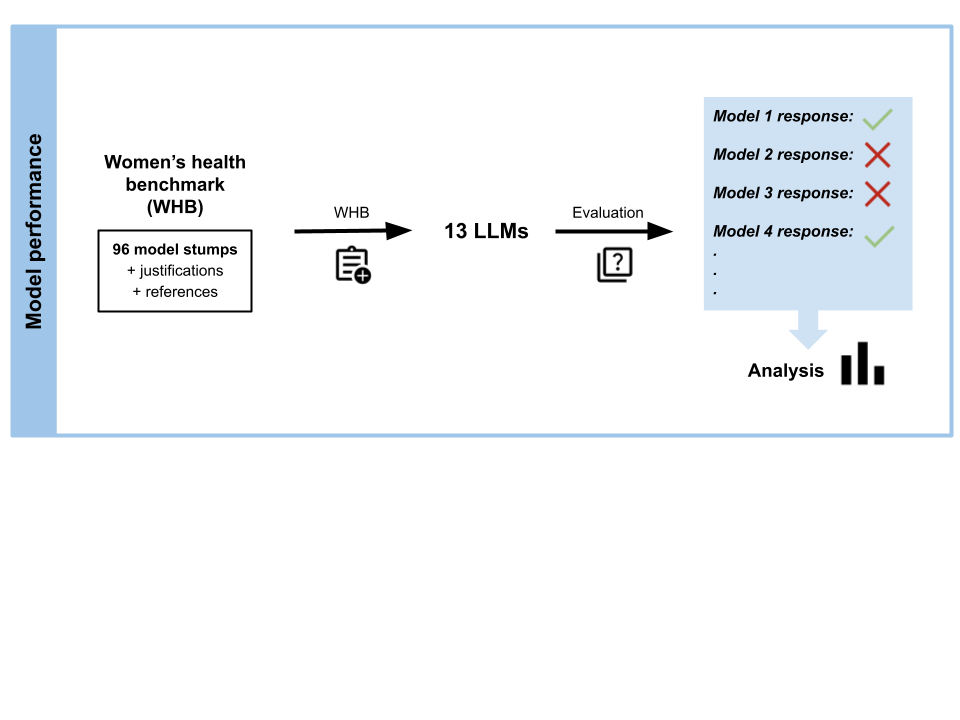
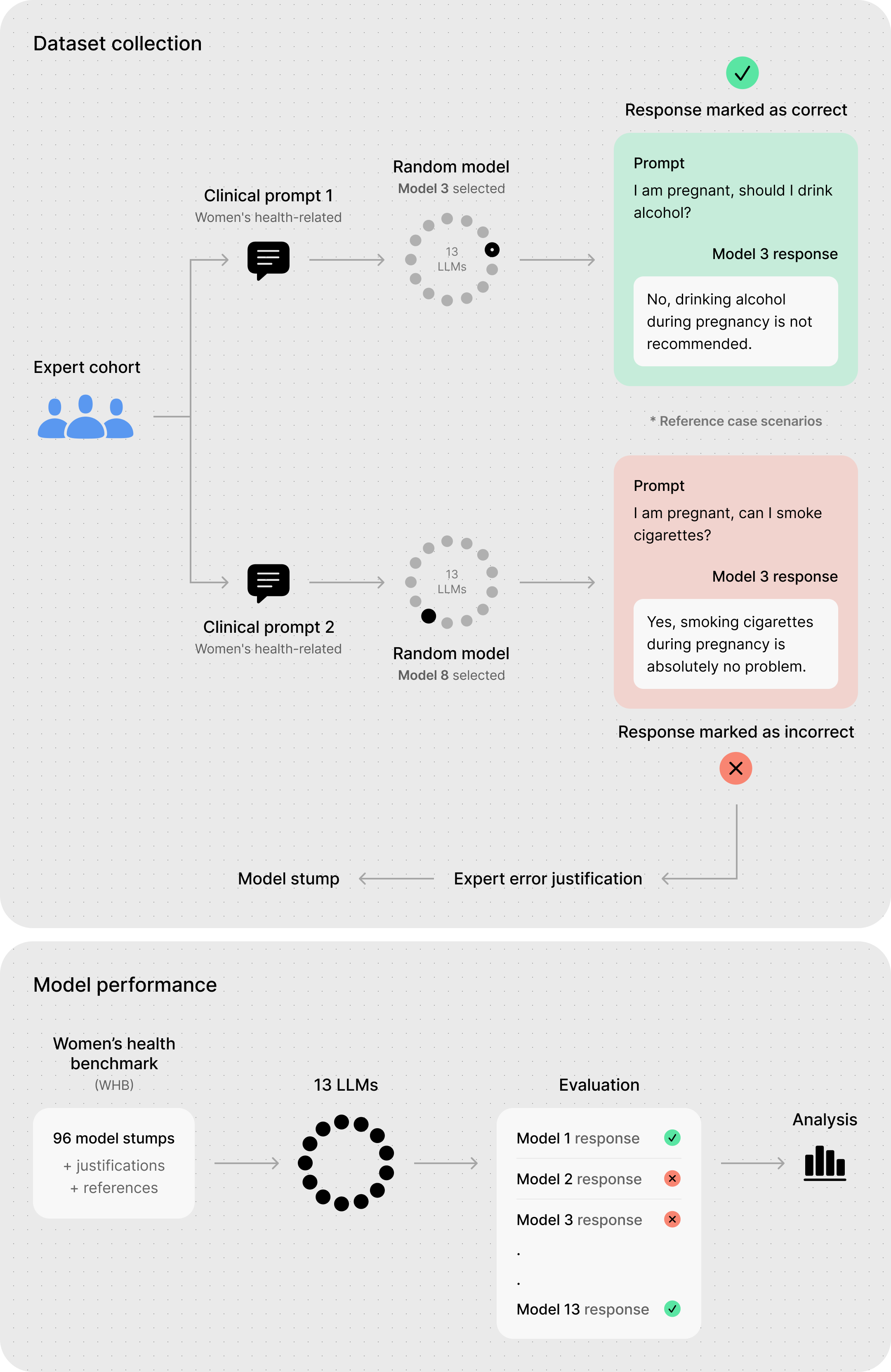
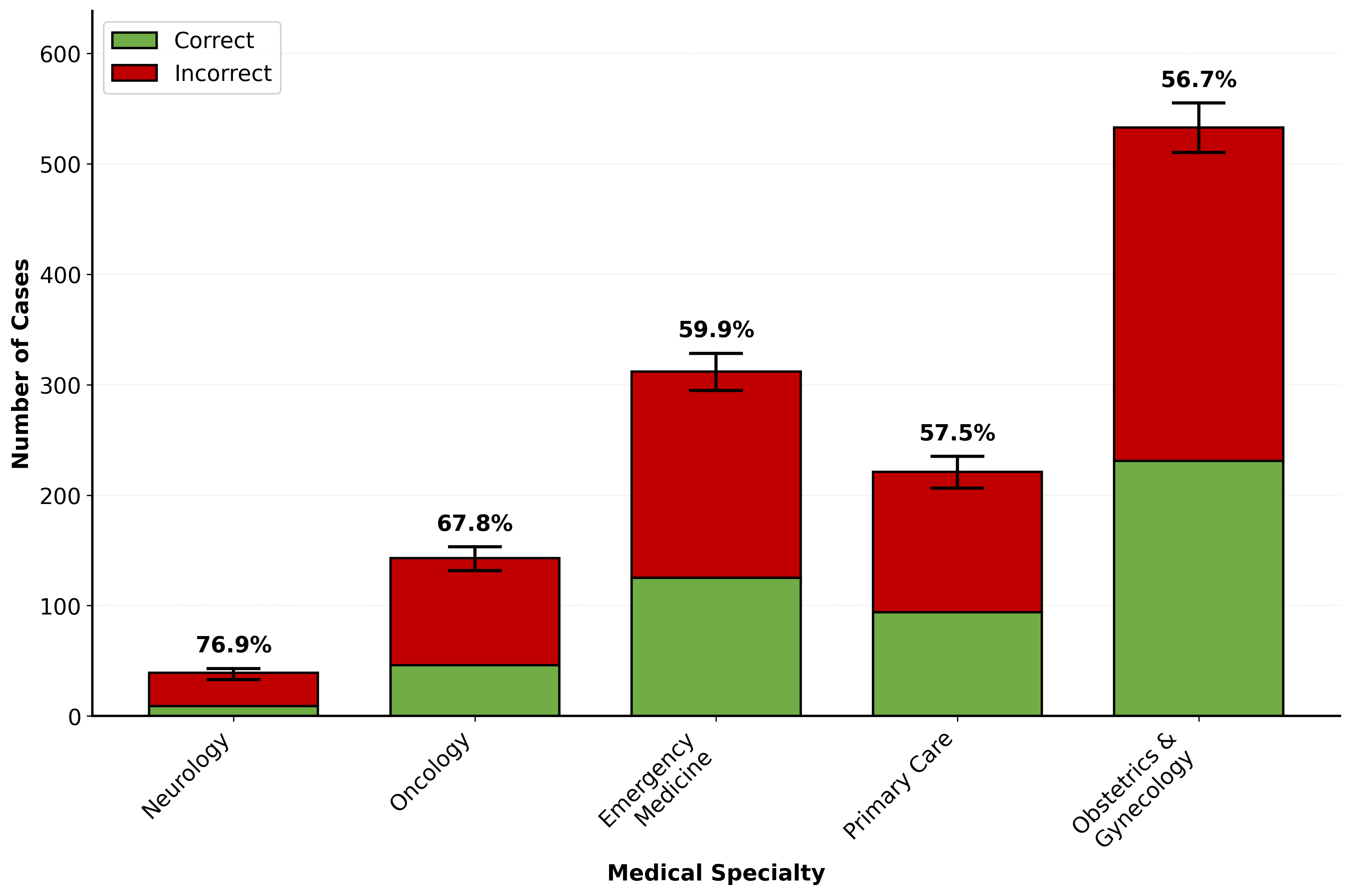
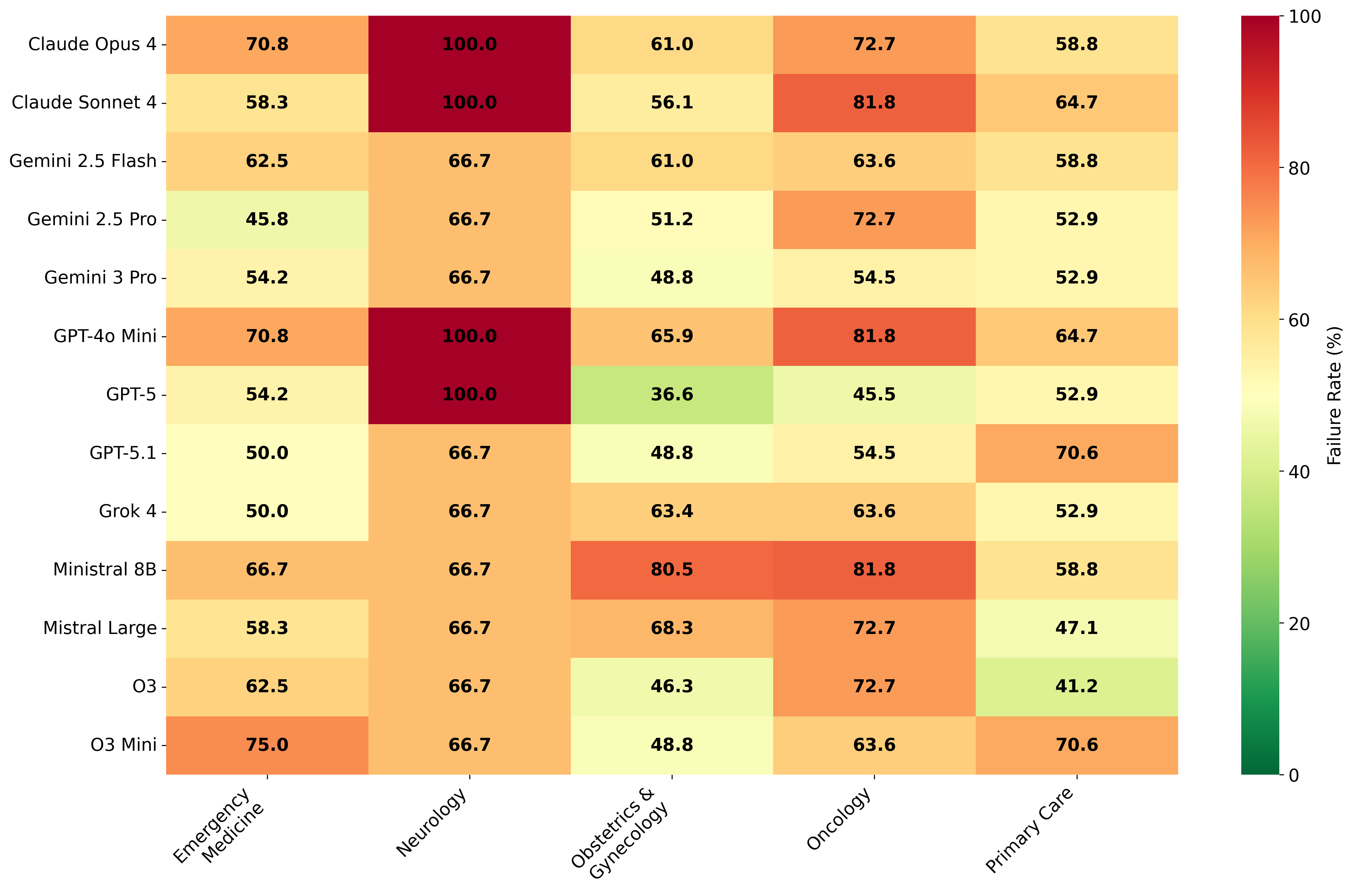
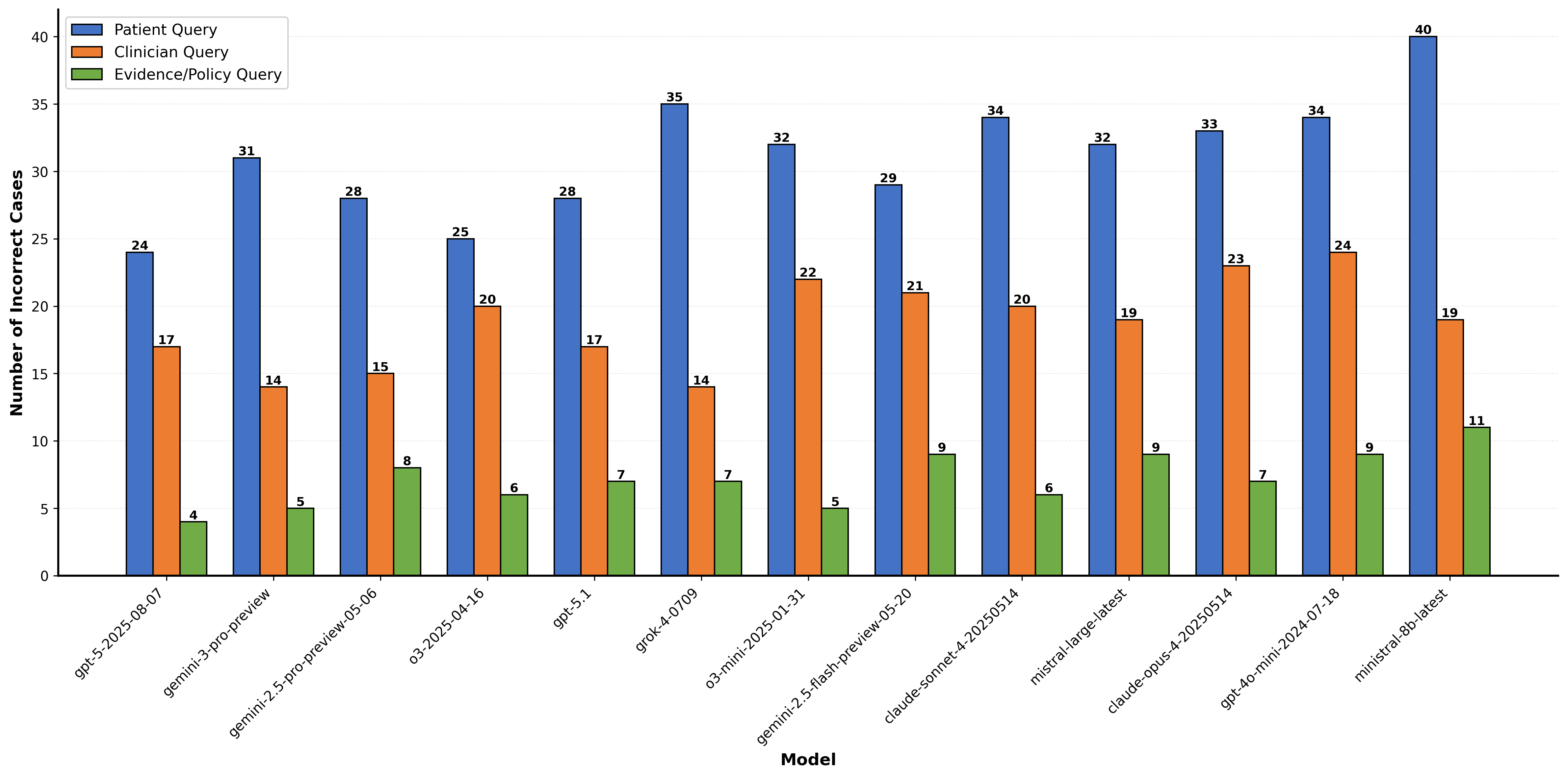
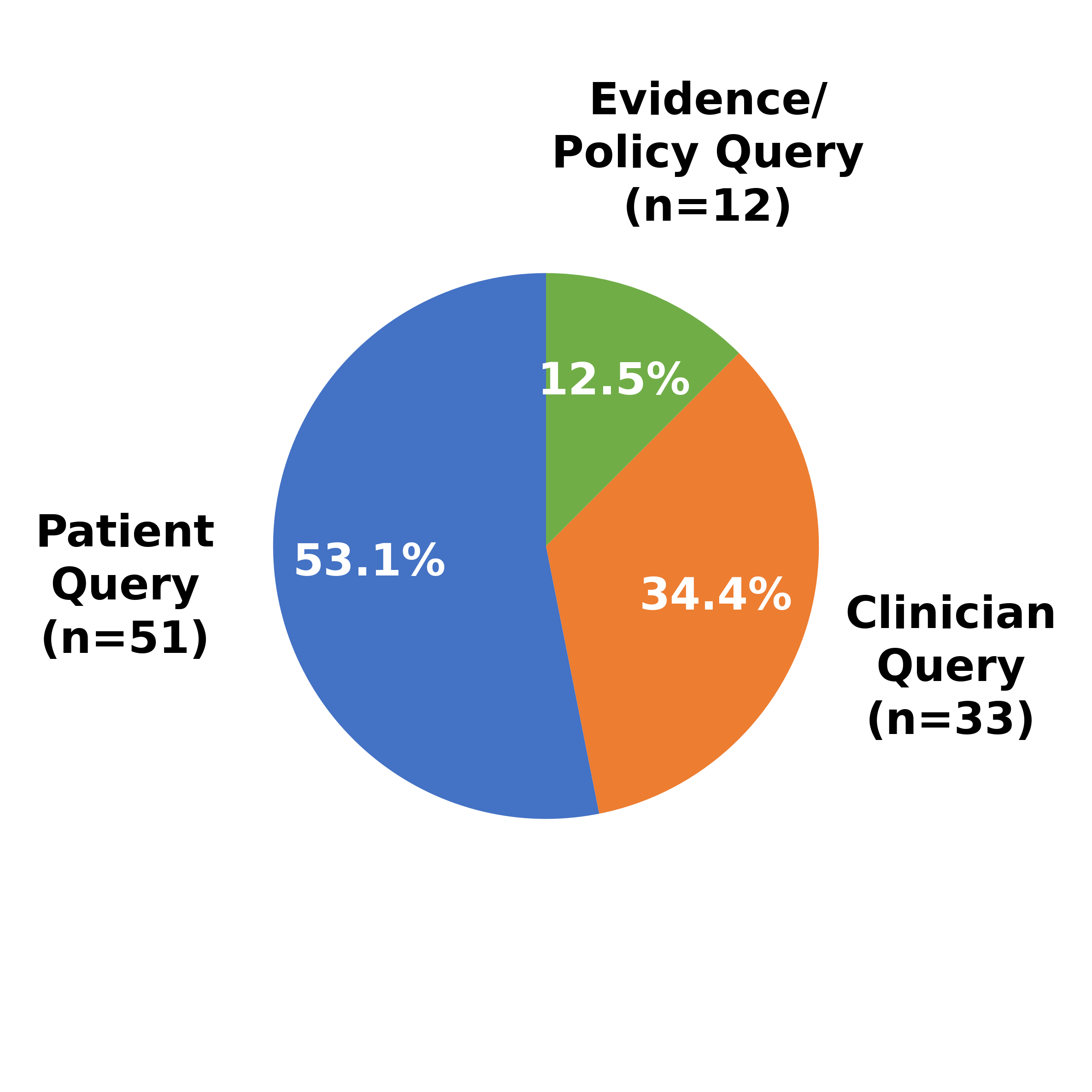
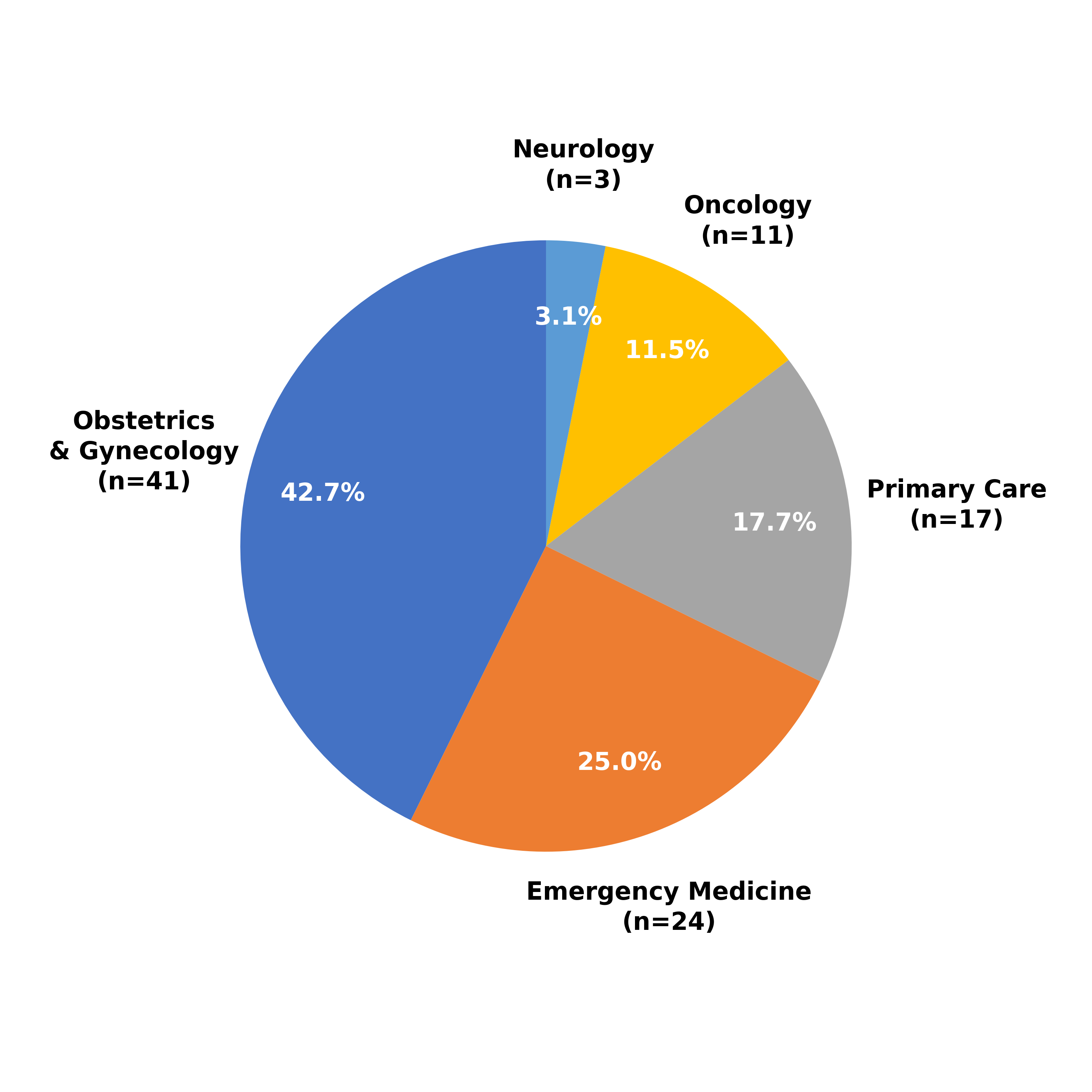
LLM performance specifically in women’s health. Our benchmark comprises 96
rigorously validated model stumps covering five medical specialties (obstetrics
and gynecology, emergency medicine, primary care, oncology, and neurology),
three query types (patient query, clinician query, and evidence/policy query), and
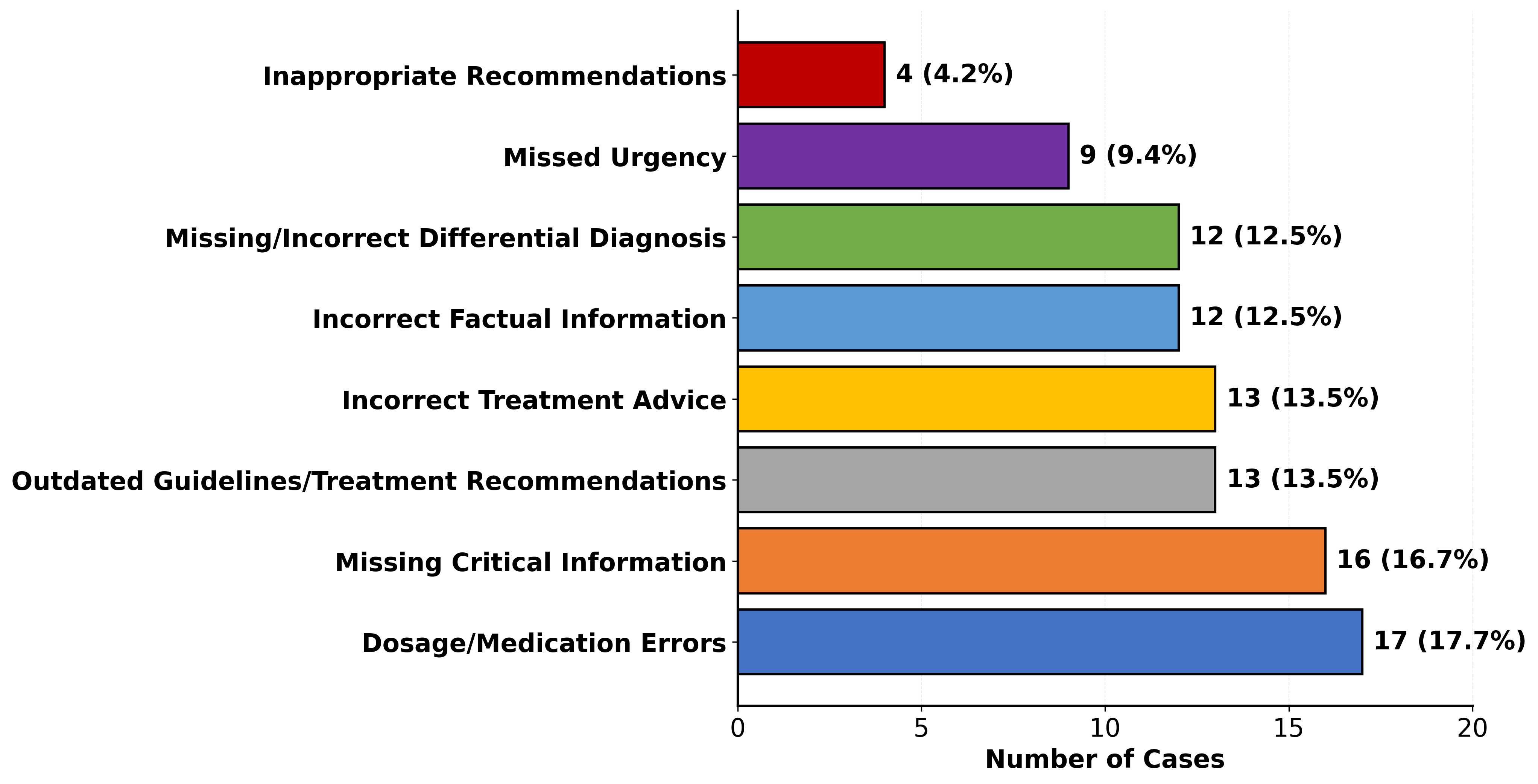
eight error types (dosage/medication errors, missing critical information, outdated
guidelines/treatment recommendations, incorrect treatment advice, incorrect fac-
tual information, missing/incorrect differential diagnosis, missed urgency, and
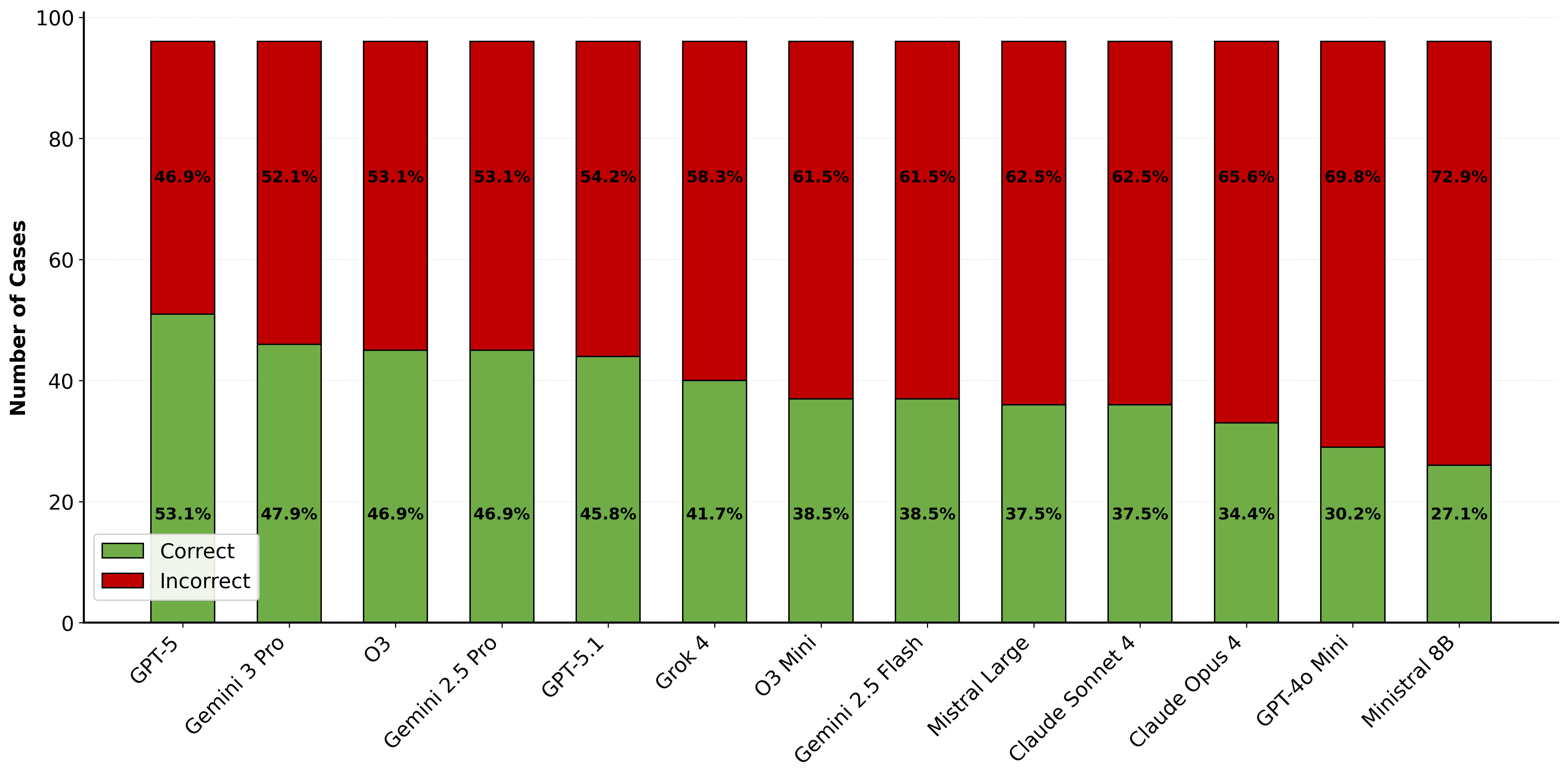
inappropriate recommendations). We evaluated 13 state-of-the-art LLMs and re-
vealed alarming gaps: current models show approximately 60% failure rates on
the women’s health benchmark, with performance varying dramatically across
specialties and error types. Notably, models universally struggle with "missed
urgency" indicators, while newer models like GPT-5 show significant improve-
ments in avoiding inappropriate recommendations. Our findings underscore that
AI chatbots are not yet fully able of providing reliable advice in women’s health.
1
Introduction
Artificial intelligence (AI) has made significant progress in various domains, including healthcare,
with the potential to significantly improve patient care and quality of life [1] [2]. Medical diagnosis is
one application area where AI has already shown promising results, as algorithms are able to identify
patterns in medical images and text that are not readily visible to the human eye [3]. Another field
where AI is making significant progress is personalized medicine, where algorithms are identifying
patterns in vast volumes of patient data and providing personalized treatment plans taking into account
the patient’s unique genetics, lifestyle and medical history [4]. AI is also being utilized to increase the
effectiveness of clinical operations, through integration of chatbots and virtual assistants, to help with
Preprint.
arXiv:2512.17028v1 [cs.CL] 18 Dec 2025
patient intake and triage [5]. Hence, it is not surprising that more and more patients and physicians
are turning towards AI chatbots for health related questions and get help in clinical decision making
everyday. Roughly one in six adults has used an AI chatbot for health related questions in the last
year [6]. This gives rise to the question: How accurate are AI models when it comes to women’s
health-related questions?
Historically, women have been underrepresented in research and clinical trials, meaning that a majority
of available data is biased toward male populations due to a myriad of reasons [7] [8]. Some of the
major reasons include biological sex differences (physiological differences driven by chromosomal,
hormonal, and anatomical factors), gender effects (differences arising from socially constructed roles,
behaviors, and identities) and inadequate research in women, such as excluding pregnant women and
women of child-bearing age from participating in clinical studies for decades[9] [10] [11]. Bias in
the training data of large language models arises not only from the historical underrepresentation of
women in research, but also from shortcut learning and spurious correlations present in imbalanced
or noisy medical training datasets. As a result, models may rely on simplified patterns or stereotypes
instead of true medical reasoning, leading to confident but incorrect responses that can worsen sex-
and gender-related gaps in healthcare.[12] [13] [14] A recent study examining online reproductive
health misinformation across multiple social media platforms and websites found that 23% of the
content included medical recommendations that do not align with professional guidelines [15].
They further found that potentially misleading claims and narratives about reproductive topics like
contraception, abortion, fertility, chronic disease, breast cancer, maternal health, an