Design and Evaluation of Cost-Aware PoQ for Decentralized LLM Inference
Reading time: 5 minute
...
📝 Original Info
Title: Design and Evaluation of Cost-Aware PoQ for Decentralized LLM Inference
ArXiv ID: 2512.16317
Date: 2025-12-18
Authors: Arther Tian, Alex Ding, Frank Chen, Alan Wu, Aaron Chan, Bruce Zhang
📝 Abstract
Decentralized large language model (LLM) inference promises transparent and censorship resistant access to advanced AI, yet existing verification approaches struggle to scale to modern models. Proof of Quality (PoQ) replaces cryptographic verification of computation with consensus over output quality, but the original formulation ignores heterogeneous computational costs across inference and evaluator nodes. This paper introduces a cost-aware PoQ framework that integrates explicit efficiency measurements into the reward mechanism for both types of nodes. The design combines ground truth token level F1, lightweight learned evaluators, and GPT based judgments within a unified evaluation pipeline, and adopts a linear reward function that balances normalized quality and cost.
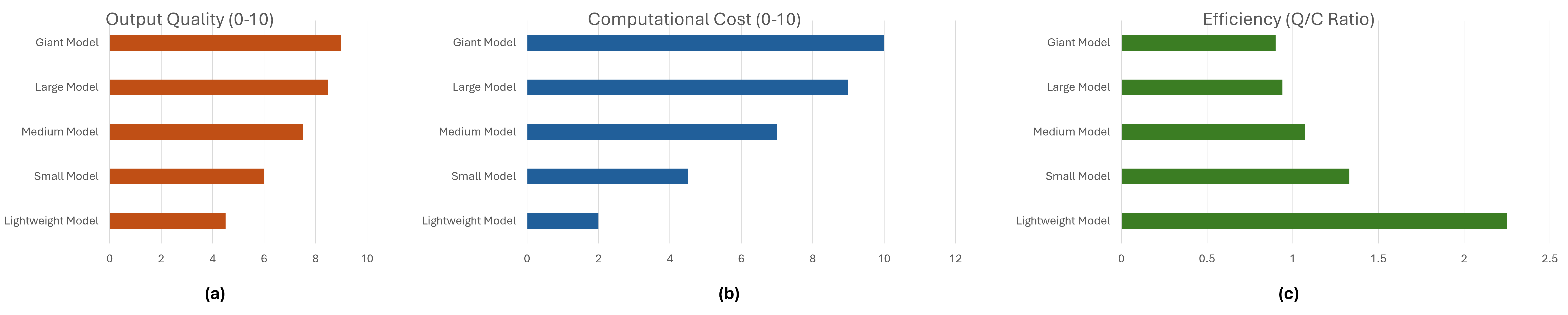
Experiments on extractive question answering and abstractive summarization use five instruction tuned LLMs ranging from TinyLlama-1.1B to Llama-3.2-3B and three evaluation models spanning cross encoder and bi encoder architectures. Results show that a semantic textual similarity bi encoder achieves much higher correlation with both ground truth and GPT scores than cross encoders, indicating that evaluator architecture is a critical design choice for PoQ. Quality-cost analysis further reveals that the largest models in the pool are also the most efficient in terms of quality per unit latency. Monte Carlo simulations over 5\,000 PoQ rounds demonstrate that the cost-aware reward scheme consistently assigns higher average rewards to high quality low cost inference models and to efficient evaluators, while penalizing slow low quality nodes. These findings suggest that cost-aware PoQ provides a practical foundation for economically sustainable decentralized LLM inference.
💡 Deep Analysis
📄 Full Content
Design and Evaluation of Cost-Aware PoQ for
Decentralized LLM Inference
Arther Tiana, Alex Dinga,*, Frank Chena
Alan Wua, Aaron Chana, Bruce Zhanga
aDGrid AI
*Corresponding author: alex.ding@dgrid.ai
Abstract
Decentralized large language model (LLM) inference promises transparent
and censorship resistant access to advanced AI, yet existing verification
approaches struggle to scale to modern models. Proof of Quality (PoQ)
replaces cryptographic verification of computation with consensus over
output quality, but the original formulation ignores heterogeneous compu-
tational costs across inference and evaluator nodes. This paper introduces
a cost-aware PoQ framework that integrates explicit efficiency measure-
ments into the reward mechanism for both types of nodes. The design
combines ground truth token level F1, lightweight learned evaluators, and
GPT based judgments within a unified evaluation pipeline, and adopts a
linear reward function that balances normalized quality and cost.
Experiments on extractive question answering and abstractive summa-
rization use five instruction tuned LLMs ranging from TinyLlama-1.1B to
Llama-3.2-3B and three evaluation models spanning cross encoder and bi
encoder architectures.
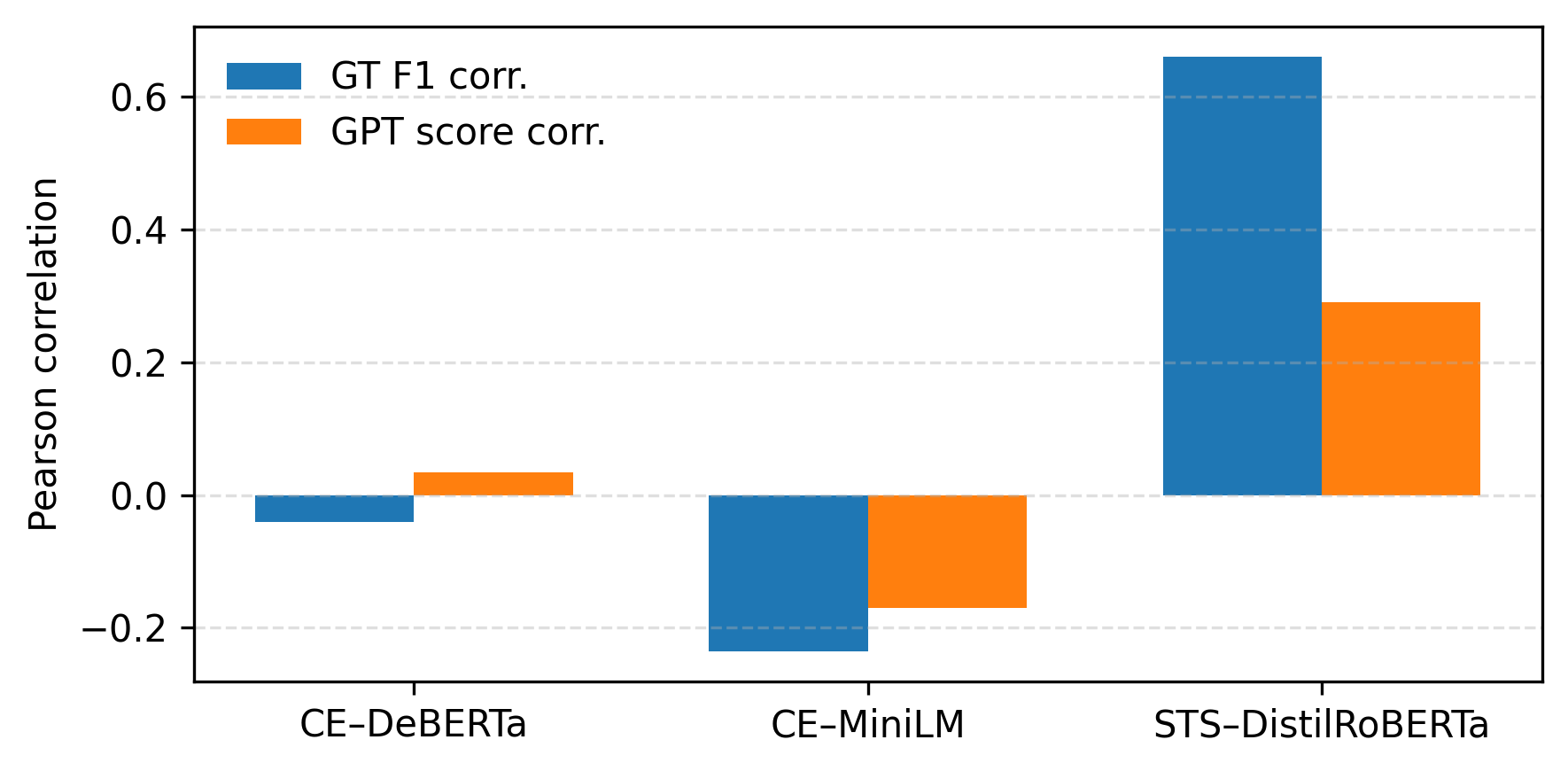
Results show that a semantic textual similarity
bi encoder achieves much higher correlation with both ground truth and
GPT scores than cross encoders, indicating that evaluator architecture is
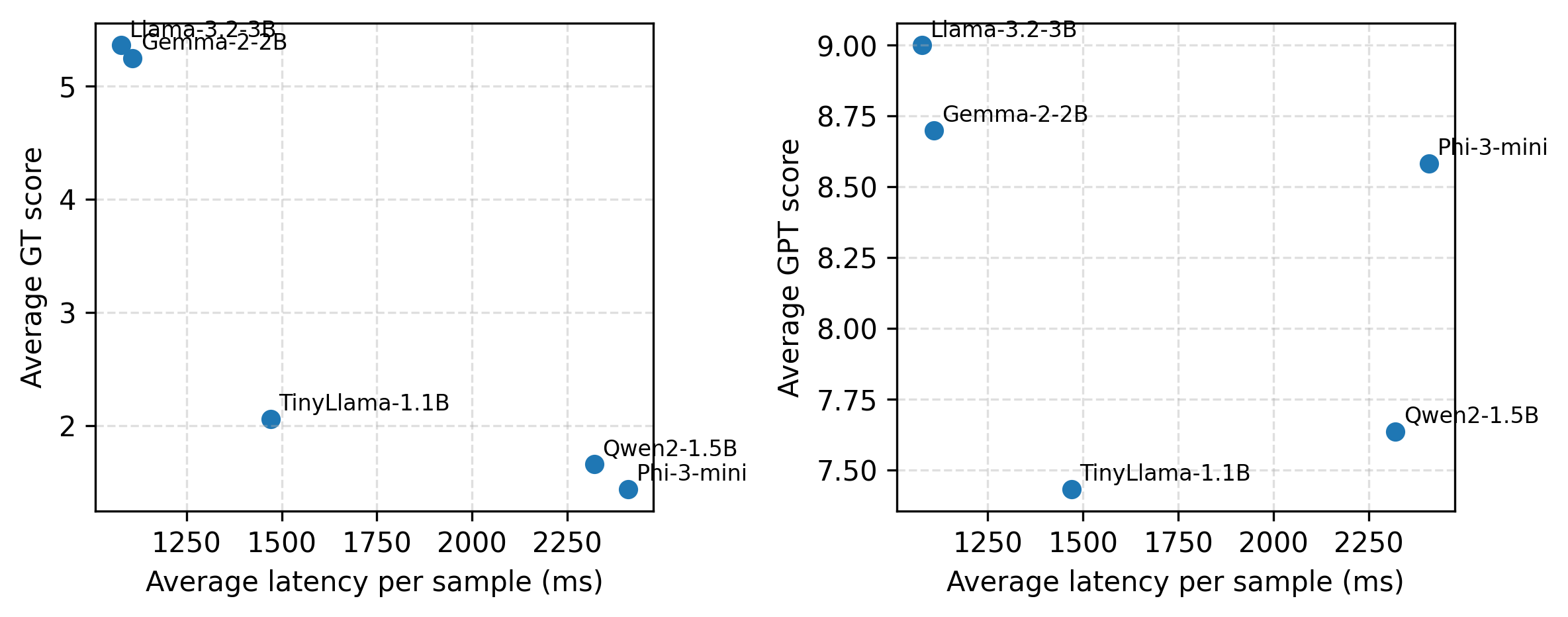
a critical design choice for PoQ. Quality–cost analysis further reveals that
the largest models in the pool are also the most efficient in terms of quality
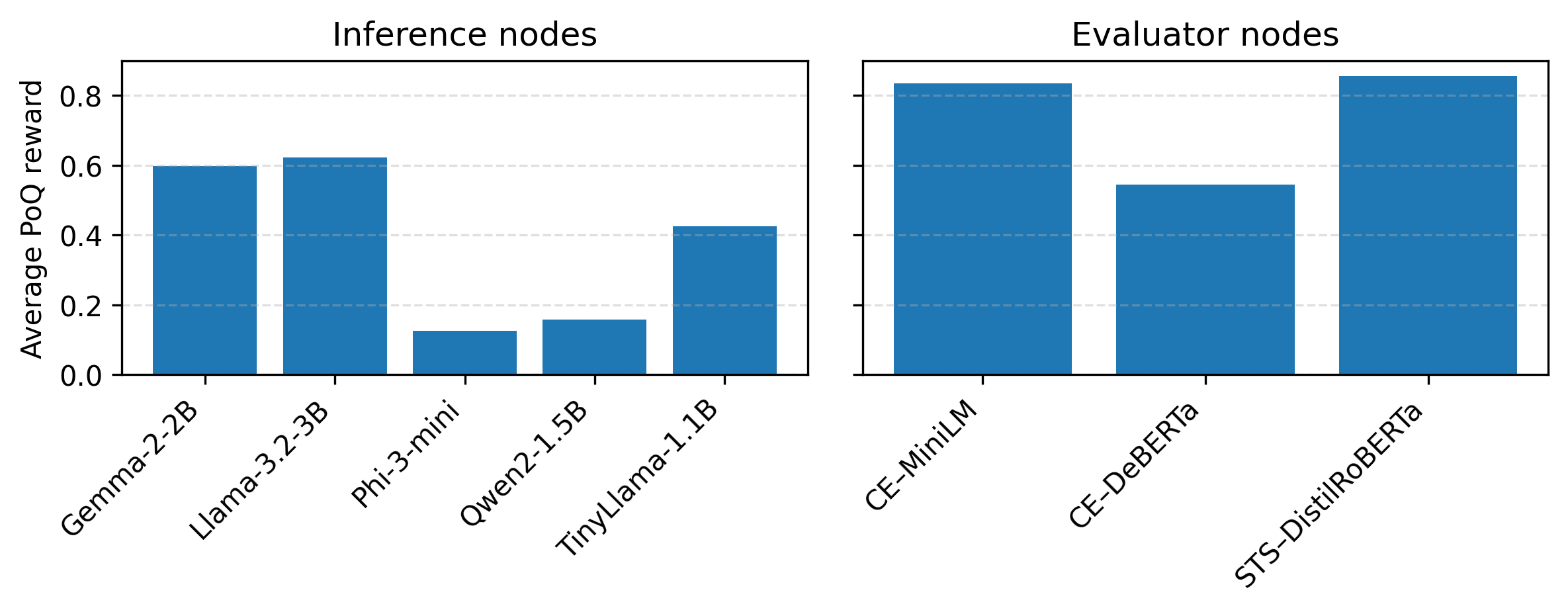
per unit latency. Monte Carlo simulations over 5 000 PoQ rounds demon-
strate that the cost-aware reward scheme consistently assigns higher av-
erage rewards to high quality low cost inference models and to efficient
evaluators, while penalizing slow low quality nodes. These findings sug-
gest that cost-aware PoQ provides a practical foundation for economically
sustainable decentralized LLM inference.
1
Introduction
The rapid advancement of large language models (LLMs) has revolutionized arti-
ficial intelligence applications, with models such as GPT-4 [17], Llama 3 [24], and
1
arXiv:2512.16317v1 [cs.AI] 18 Dec 2025
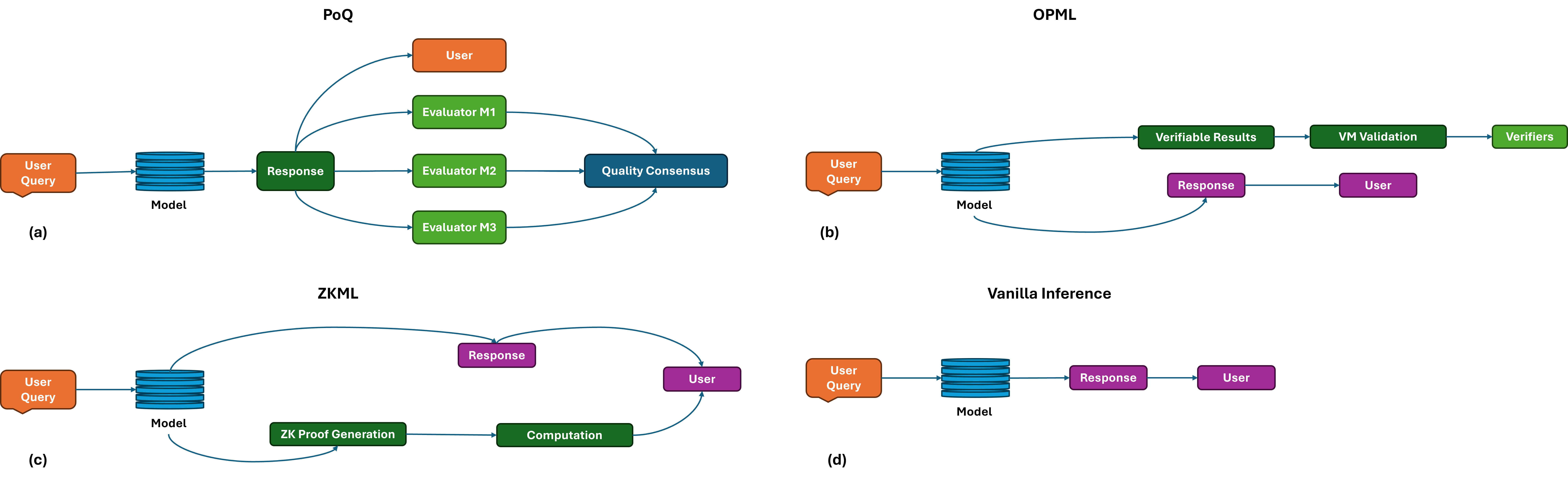
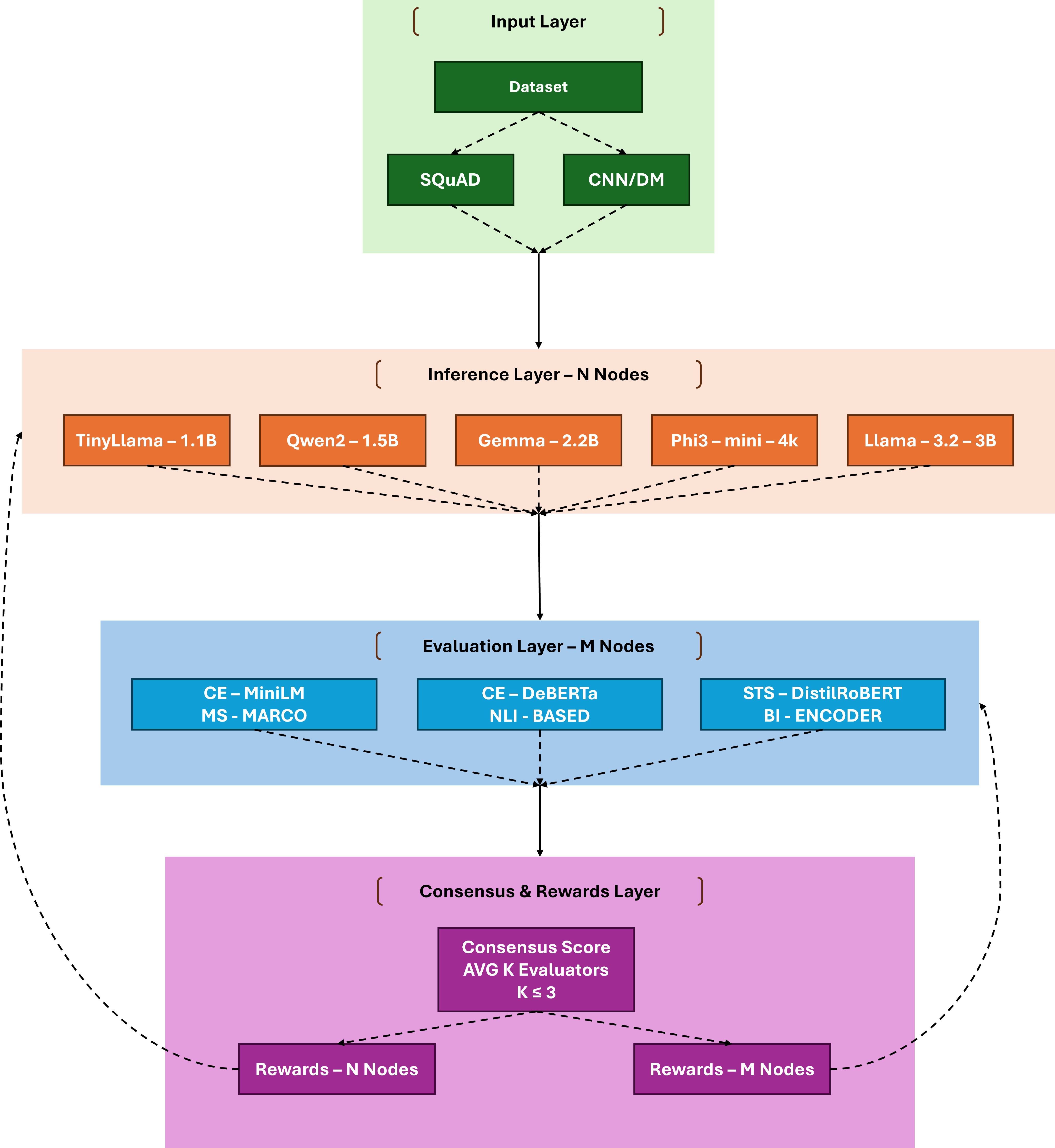
Figure 1: Comparison of inference verification paradigms in blockchain envi-
ronments. (a) Proof of Quality (PoQ) employs multiple lightweight evaluators
to assess output quality with minimal overhead. (b) OPML requires expensive
VM validation taking minutes to hours. (c) ZKML demands intensive compu-
tation for proof generation, often requiring hours for completion. (d) Vanilla
inference lacks any verification mechanism, making it unsuitable for trustless
environments.
Mixtral [7] demonstrating unprecedented capabilities in natural language under-
standing and generation. However, deploying these computationally intensive
models in decentralized environments presents significant challenges that tradi-
tional centralized architectures do not face [21]. The convergence of blockchain
technology and AI inference promises to democratize access to advanced AI ca-
pabilities while ensuring transparency, security, and resistance to single points
of failure [28].
Trustless execution of AI model inference on blockchain networks requires
mechanisms to verify both the integrity and quality of computational outputs
without relying on trusted third parties.
Existing cryptographic approaches
such as Zero-Knowledge Machine Learning (ZKML) [3] and Optimistic Ma-
chine Learning (OPML) [9] focus on proving the correctness of inference proce-
dures through circuit-based verification. However, these approaches face severe
scalability limitations when applied to modern LLMs containing billions of pa-
rameters. For instance, ZKML implementations can only handle models with a
few layers, while OPML requires hours to validate even small-scale Transformer
models, rendering them impractical for real-world deployment.
Recently, Zhang et al. proposed Proof of Quality (PoQ) [30], a novel paradigm
that shifts focus from verifying computational processes to assessing output
quality.
As illustrated in Figure 1, PoQ fundamentally differs from existing
approaches by employing multiple lightweight evaluation models to assess infer-
ence outputs, achieving consensus in seconds rather than hours. This approach
leverages cross-encoder models that require orders of magnitude less computa-
tion than the original inference, making it suitable for blockchain deployment
while maintaining trustworthiness through collective assessment.
Despite its elegance, the original PoQ framework overlooks a critical aspect
of decentralized systems: the heterogeneous computational costs across different
2
nodes and models. In practical decentralized networks, inference nodes operate
with varying hardware capabilities, energy costs, and model architectures [12].
Without considering these cost disparities, the incentive mechanism may inad-
vertently favor computationally expensive models regardless of th