Accurate intrinsic decomposition of face images under unconstrained lighting is a prerequisite for photorealistic relighting, high-fidelity digital doubles, and augmented-reality effects. This paper introduces MAGINet, a Multi-scale Attention-Guided Intrinsics Network that predicts a $512\times512$ light-normalized diffuse albedo map from a single RGB portrait. MAGINet employs hierarchical residual encoding, spatial-and-channel attention in a bottleneck, and adaptive multi-scale feature fusion in the decoder, yielding sharper albedo boundaries and stronger lighting invariance than prior U-Net variants. The initial albedo prediction is upsampled to $1024\times1024$ and refined by a lightweight three-layer CNN (RefinementNet). Conditioned on this refined albedo, a Pix2PixHD-based translator then predicts a comprehensive set of five additional physically based rendering passes: ambient occlusion, surface normal, specular reflectance, translucency, and raw diffuse colour (with residual lighting). Together with the refined albedo, these six passes form the complete intrinsic decomposition. Trained with a combination of masked-MSE, VGG, edge, and patch-LPIPS losses on the FFHQ-UV-Intrinsics dataset, the full pipeline achieves state-of-the-art performance for diffuse albedo estimation and demonstrates significantly improved fidelity for the complete rendering stack compared to prior methods. The resulting passes enable high-quality relighting and material editing of real faces.
The creation of photorealistic, editable digital humans is a foundational challenge in computer vision and graphics, with transformative potential for filmmaking, virtual reality, and next-generation communication platforms. A critical bottleneck in democratizing this technology is the ability to perform inverse rendering: recovering the intrinsic properties of a human face-its 3D shape, surface reflectance, and the effects of illumination-from a single, unconstrained portrait captured with an ordinary camera. Without specialized hardware such as light stages [4], this task is profoundly ill-posed, requiring computational models to disentangle a multitude of interacting physical phenomena from a single 2D observation. To tackle this challenge, the field has recently converged on two powerful paradigms. The first involves implicit volumetric representations, where methods based on 3D Generative Adversarial Networks (GANs) or Neural Radiance Fields (NeRFs) learn to synthesize a continuous, 3D-aware model of the face from 2D image collections [5]. These approaches can produce stunningly realistic, view-consistent avatars that can be relit. The second paradigm is driven by generative relighting models, which leverage the power of diffusion models to re-render a portrait under novel lighting conditions. Often trained in a self-supervised manner, these models excel at producing photorealistic results and handling complex effects like cast shadows without requiring explicit 3D geometry or paired ground-truth data [6]. While these implicit and generative approaches achieve state-of-the-art photorealism, they present critical trade-offs for content creation workflows. Volumetric models [5] can be computationally intensive, and their implicit nature means they do not natively produce the standard, editable rendering passes-such as separate specular, normal, or ambient occlusion (AO) maps-that are the lingua franca of professional graphics pipelines. Similarly, diffusion-based relighters [6] typically operate as holistic imageto-image translators, producing a final, "baked" relit image without the intermediate, interpretable assets required for flexible material editing or compositing. This reveals a clear and unmet need in the field: a practical method that can decompose a single portrait into a complete and explicit stack of Physically Based Rendering (PBR)compatible passes, bridging the gap between pure synthesis and the practical demands of downstream editing applications.
Our key insight is that this highly ill-posed, multi-component decomposition problem can be made tractable by structuring it as a progressive, multi-stage pipeline that strategically disentangles illumination removal from the data-driven synthesis of geometric and material properties. We introduce MAGINet, a three-stage framework designed for this purpose. First, a Multi-scale Attention-Guided Intrinsics Networkthe core MAGINet-leverages a deep receptive field and a dual-attention bottleneck to predict a robust, light-normalized diffuse albedo map. Second, a lightweight Refine-mentNet upsamples and sharpens this albedo. Finally, conditioned on this clean albedo, a conditional GAN-based translator [2] synthesizes the five remaining PBR passes: surface normals, specular reflectance, ambient occlusion, translucency, and raw diffuse color.
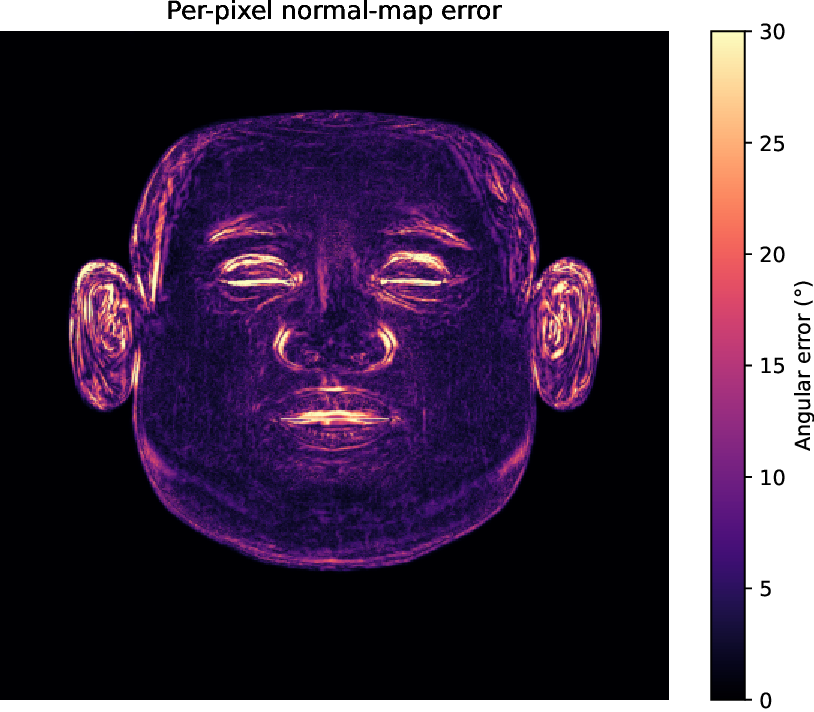
- We propose a multi-stage pipeline that, to our knowledge, is the first single-image method designed to explicitly predict a complete six-pass PBR stack (albedo, normals, AO, specular, translucency, and raw diffuse color), providing assets suitable for direct use in standard rendering workflows. 2. We introduce a specialized multi-scale attention network for albedo estimation and demonstrate that a conditional GAN framework can successfully learn to generate geometrically-plausible passes (e.g., normals, AO) from a purely 2D albedo map, exploiting the strong statistical correlations present in facial data. 3. Our full pipeline achieves state-of-the-art performance for diffuse albedo estimation on the FFHQ-UV-Intrinsics benchmark [3] and is validated on a synthetic dataset with absolute ground-truth geometry, where it achieves a mean angular error of just 2.8 • for surface normals, confirming the physical plausibility of our decomposed passes.
Our work sits at the intersection of classical intrinsic image decomposition, modern generative models for facial relighting, and physically-based inverse rendering. We position our contribution by reviewing the evolution and trade-offs within each of these domains.
Intrinsic image decomposition (IID) is the classic, ill-posed problem of separating an image into its constituent layers, primarily a view-invariant reflectance (albedo) and a view-dependent shading map [7]. Early methods relied on hand-crafted priors. With the advent of deep learning, data-driven approaches became dominant. Methods like SfSNet [8] and InverseFaceNet [9] pioneered the use of convolutional ne
This content is AI-processed based on open access ArXiv data.