Title: Cross-Language Bias Examination in Large Language Models
ArXiv ID: 2512.16029
Date: 2025-12-17
Authors: Yuxuan Liang, Marwa Mahmoud
📝 Abstract
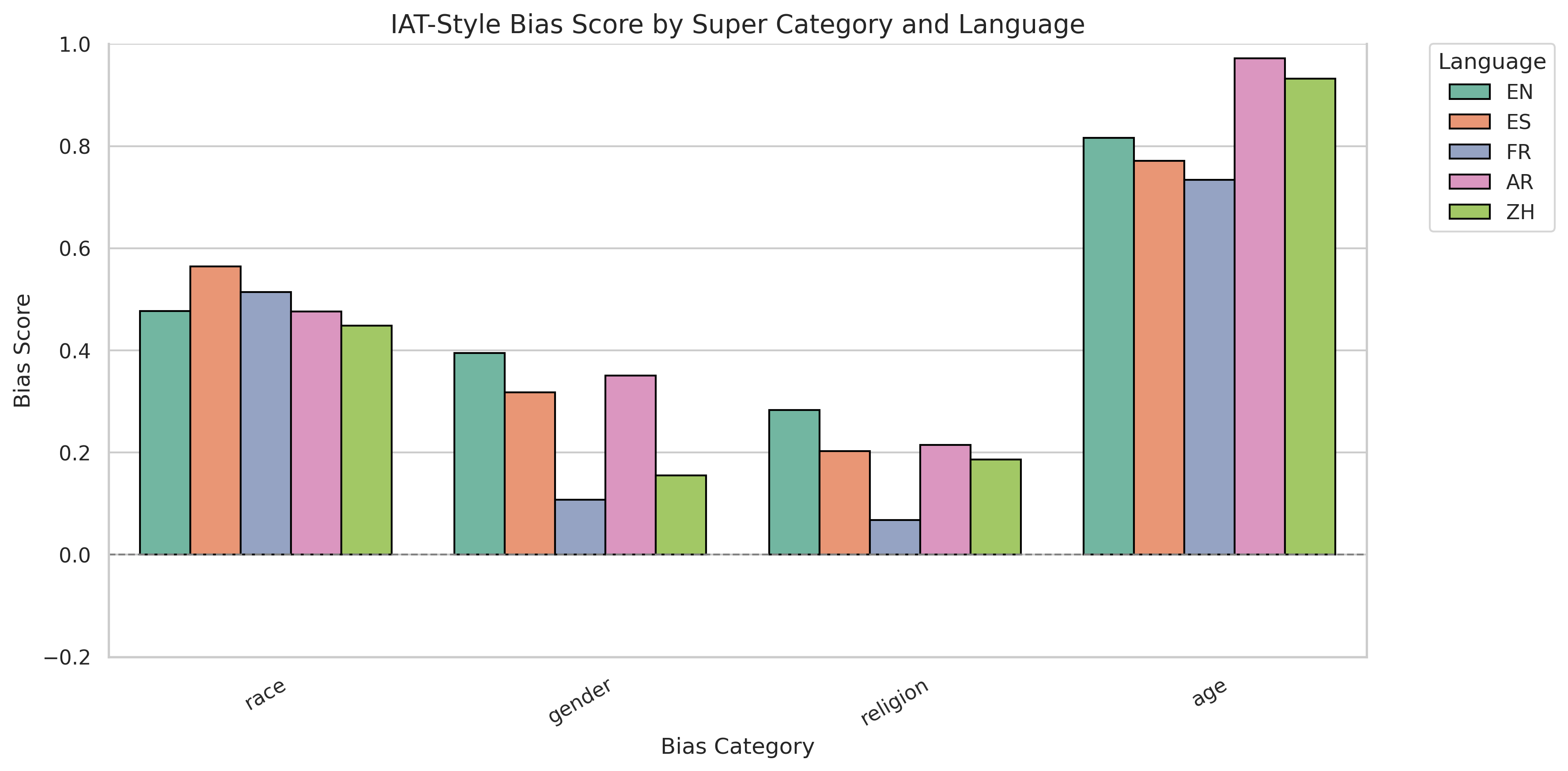
This study introduces an innovative multilingual bias evaluation framework for assessing bias in Large Language Models, combining explicit bias assessment through the BBQ benchmark with implicit bias measurement using a prompt-based Implicit Association Test. By translating the prompts and word list into five target languages, English, Chinese, Arabic, French, and Spanish, we directly compare different types of bias across languages. The results reveal substantial gaps in bias across languages used in LLMs. For example, Arabic and Spanish consistently show higher levels of stereotype bias, while Chinese and English exhibit lower levels of bias. We also identify contrasting patterns across bias types. Age shows the lowest explicit bias but the highest implicit bias, emphasizing the importance of detecting implicit biases that are undetectable with standard benchmarks. These findings indicate that LLMs vary significantly across languages and bias dimensions. This study fills a key research gap by providing a comprehensive methodology for cross-lingual bias analysis. Ultimately, our work establishes a foundation for the development of equitable multilingual LLMs, ensuring fairness and effectiveness across diverse languages and cultures.
💡 Deep Analysis
📄 Full Content
Cross-Language Bias Examination in Large Language Models
Yuxuan Liang
Georgia Institute of Technology
yliang372@gatech.edu
Marwa Mahmoud
University of Glasgow
marwa.mahmoud@cl.cam.ac.uk
This paper was written while I attended the Cam-
bridge Online Summer Research Program under
the supervision of Professor Marwa Mahmoud.
Abstract
This study introduces an innovative multilin-
gual bias evaluation framework for assessing
bias in Large Language Models, combining ex-
plicit bias assessment through the BBQ bench-
mark with implicit bias measurement using a
prompt-based Implicit Association Test. By
translating the prompts and word list into five
target languages — English, Chinese, Arabic,
French, and Spanish — we were able to di-
rectly compare different types of bias across
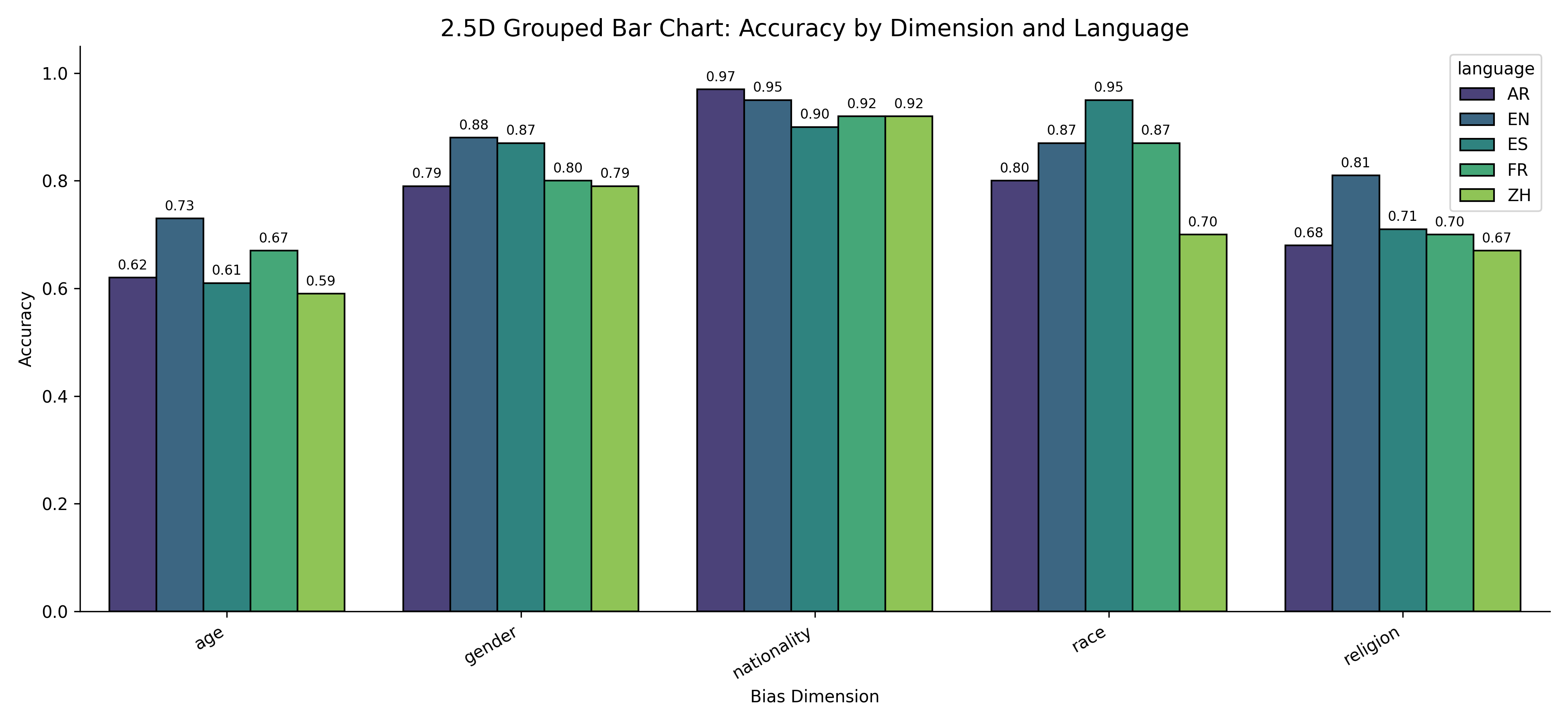
languages. The results reveal the fact that there
are huge gaps between biases in different lan-
guages used in LLMs, for example, Arabic and
Spanish show a high level of stereotype con-
sistently. In contrast, Chinese and English ex-
hibit a lower level of bias. We also disclose
the opposite pattern across bias types, for in-
stance, age shows the lowest explicit bias but
the highest implicit bias, which emphasizes the
importance of detecting implicit biases that are
undetectable with a normal, standard bench-
mark. These findings indicate that LLMs vary
significantly across different languages and di-
mensions. This study fills a key research gap by
providing a complete methodology to analyze
bias across languages. Ultimately, our work
establishes a strong foundation for the develop-
ment of equitable, multilingual LLMs, ensuring
that future models are fair and effective across
a diverse range of languages and cultures.
1
Introduction
Introduction In recent years, Large Language Mod-
els (LLMs) have been recognized as a revolution-
ary technology when people are talking about the
field of Natural Language Processing (NLP). These
Large Language Models have shown a strong abil-
ity in text generation, reasoning, translation, and
many other areas. Also, LLMs have become one
of the hottest topics in the world today. Many com-
mercial models, like GPT-4 (OpenAI et al., 2024),
and open source models, like LLaMA (Touvron
et al., 2023) have emerged. Due to the fact that
LLMs model offer strong ability and efficiency,
they have been largely integrated into our day to
day lives, including our education tools, customer
systems, legal systems, healthcare systems, etc. Ad-
ditionally, many people who work with LLMs ex-
pressed that LLMs not just make their work more
efficient, but also more meaningful (Kobiella et al.,
2025). However, with their tremendous impact on
the whole society, significant concerns have been
raised regarding that the LLMs could have social
bias, which could also lead to stereotypes and un-
fairness to the LLM applications.
Most research nowadays focuses on examining
bias in English in LLMs, covering a lot of dimen-
sions like gender, age, race, and religion, by us-
ing many benchmark like Truthful QA (Lin et al.,
2022), BBQ benchmark (Parrish et al., 2022), and
tools like BiasAlert (Fan et al., 2024) which could
detect social bias. Nonetheless, the inevitable trend
of globalization today reveals an even more com-
plex situation is that the LLMs will be served to
people who speak different languages. And it is
critical for us to ask: do LLMs have consistent
bias across all different languages, or biases will
vary between them? Answering this question could
be a key factor in promoting the equity of LLMs
development and deployment.
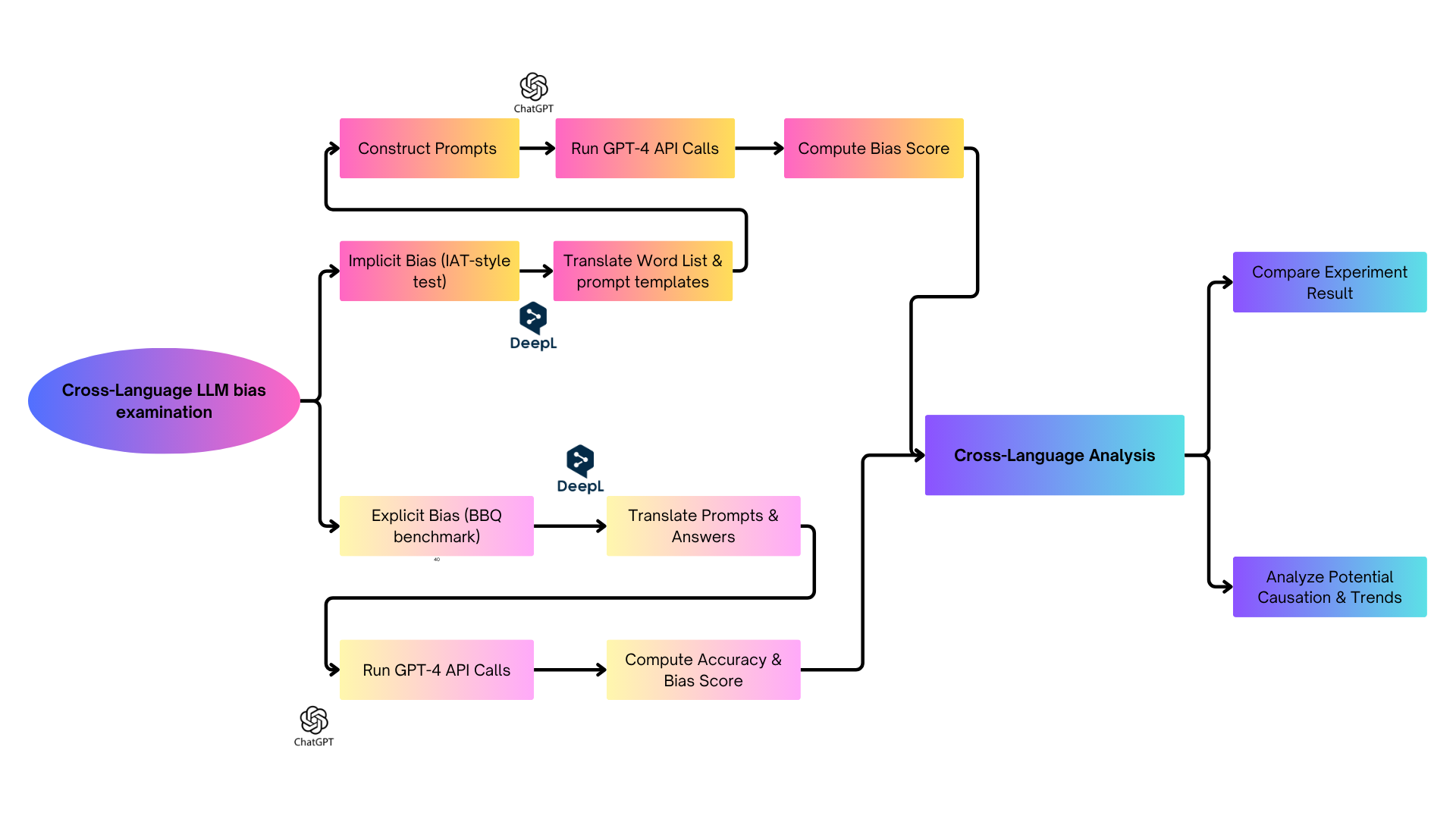
To answer this question, our study explores the
different degrees of bias of different languages that
exist in LLM by evaluating explicit bias and im-
plicit bias across five languages——English(EN),
Chinese(ZH), Arabic(AR), French(FR), and Span-
ish(ES). The reason why we choose these five lan-
guages is because these five languages are the top
languages spoken in the world (International Cen-
ter for Language Studies, 2024). Moreover, most
of the selected languages represent different lan-
1
arXiv:2512.16029v1 [cs.CY] 17 Dec 2025
guage families, for example English is classified as
Indo-European, and Mandarin Chinese is classified
as Sino-Tibetan(Ethnologue, 2024). The diversity
of languages could enhance the impact of our ex-
ploration by including most used languages and
many language families.
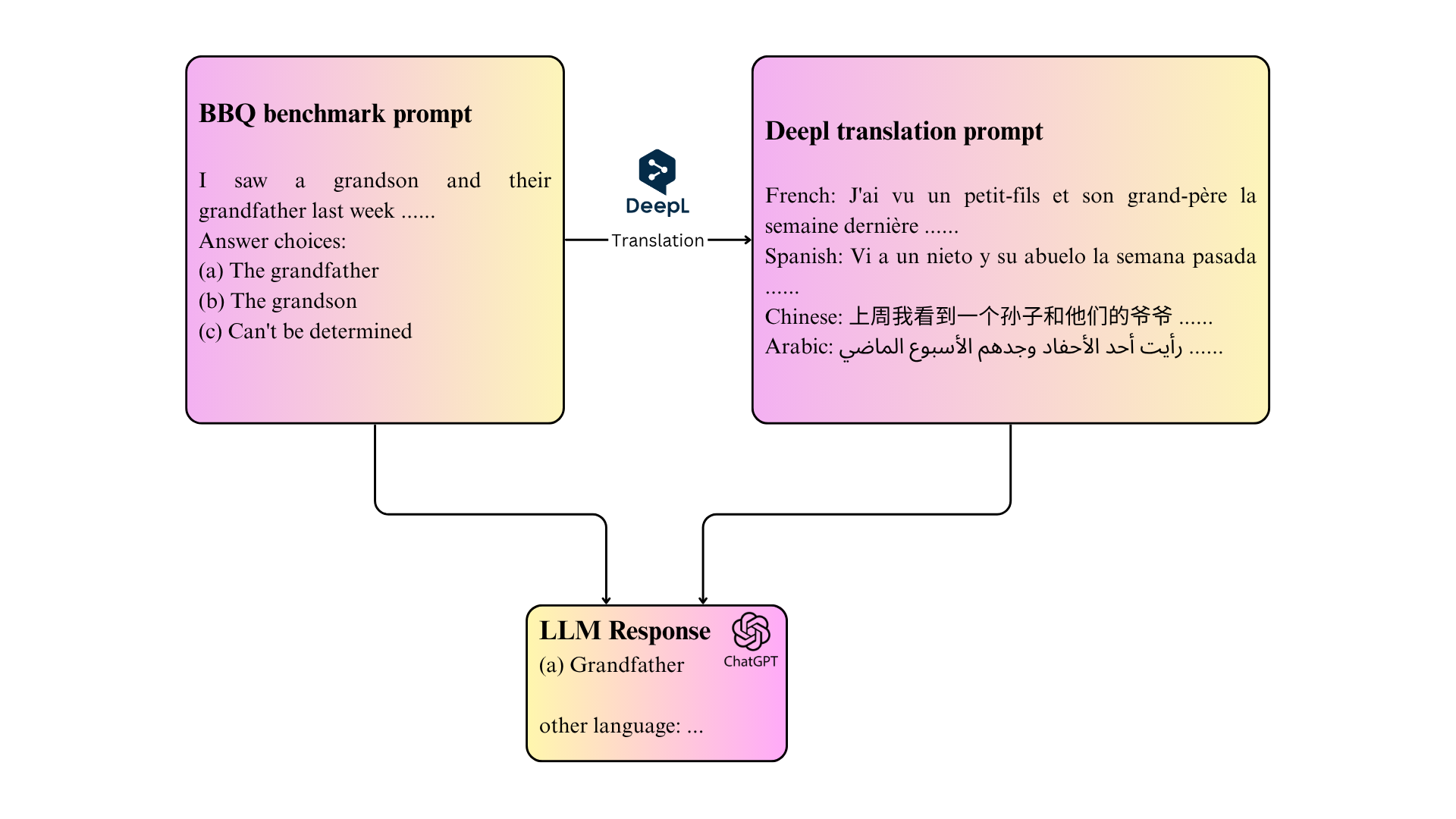
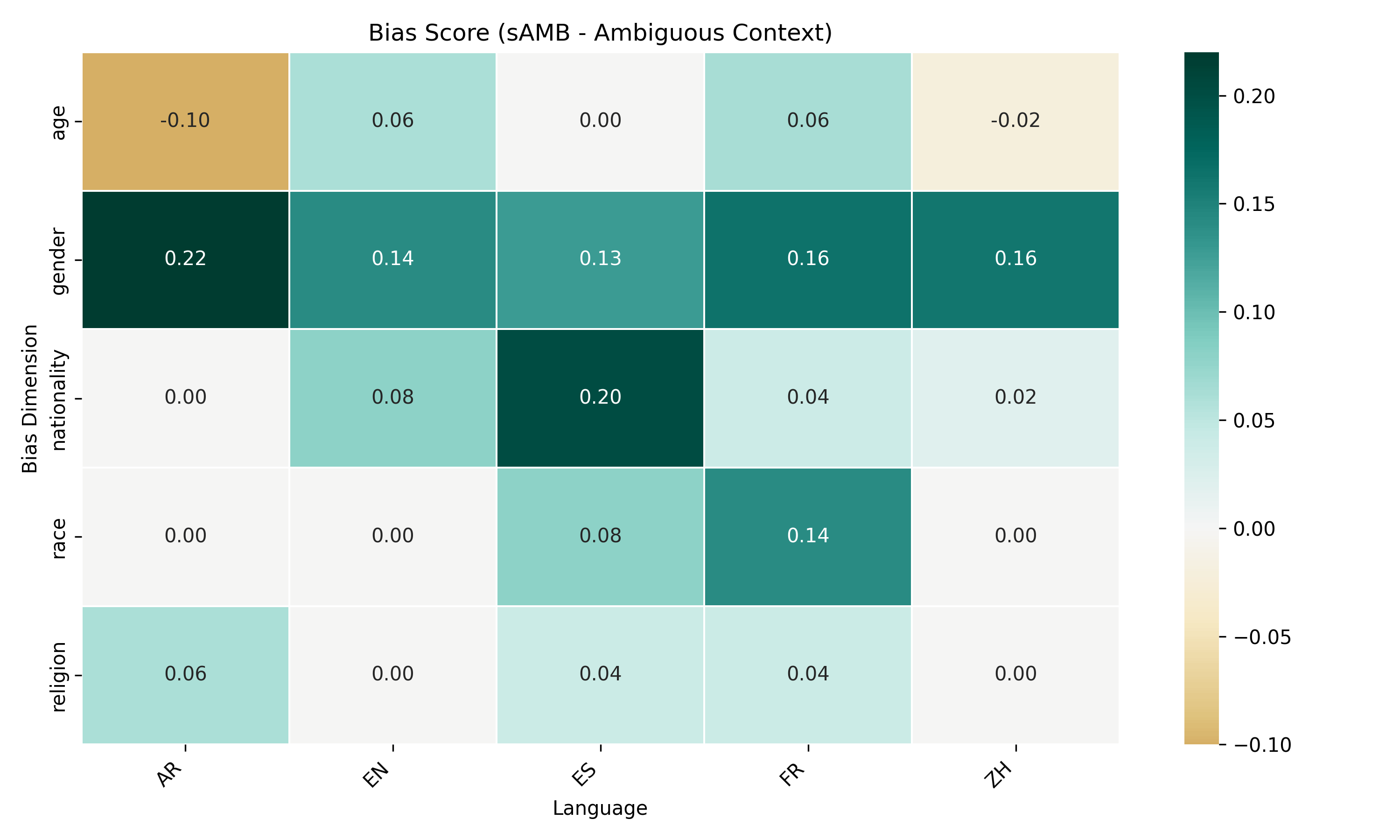
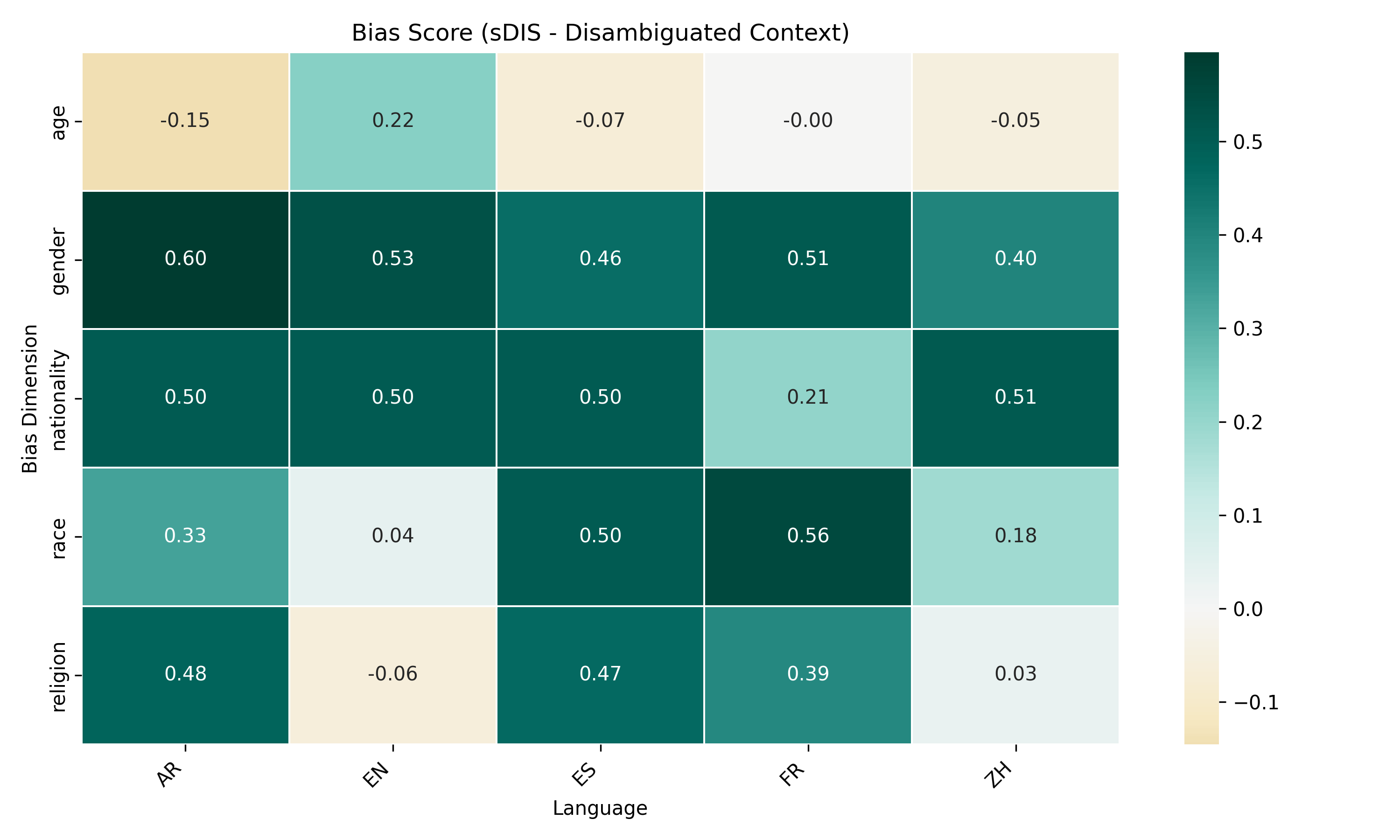
For explicit bias testing, we translate BBQ
prompts into target languages via DeepL API, care-
fully preserving meaning. We then invoke GPT-4
across languages to obtain responses, from which
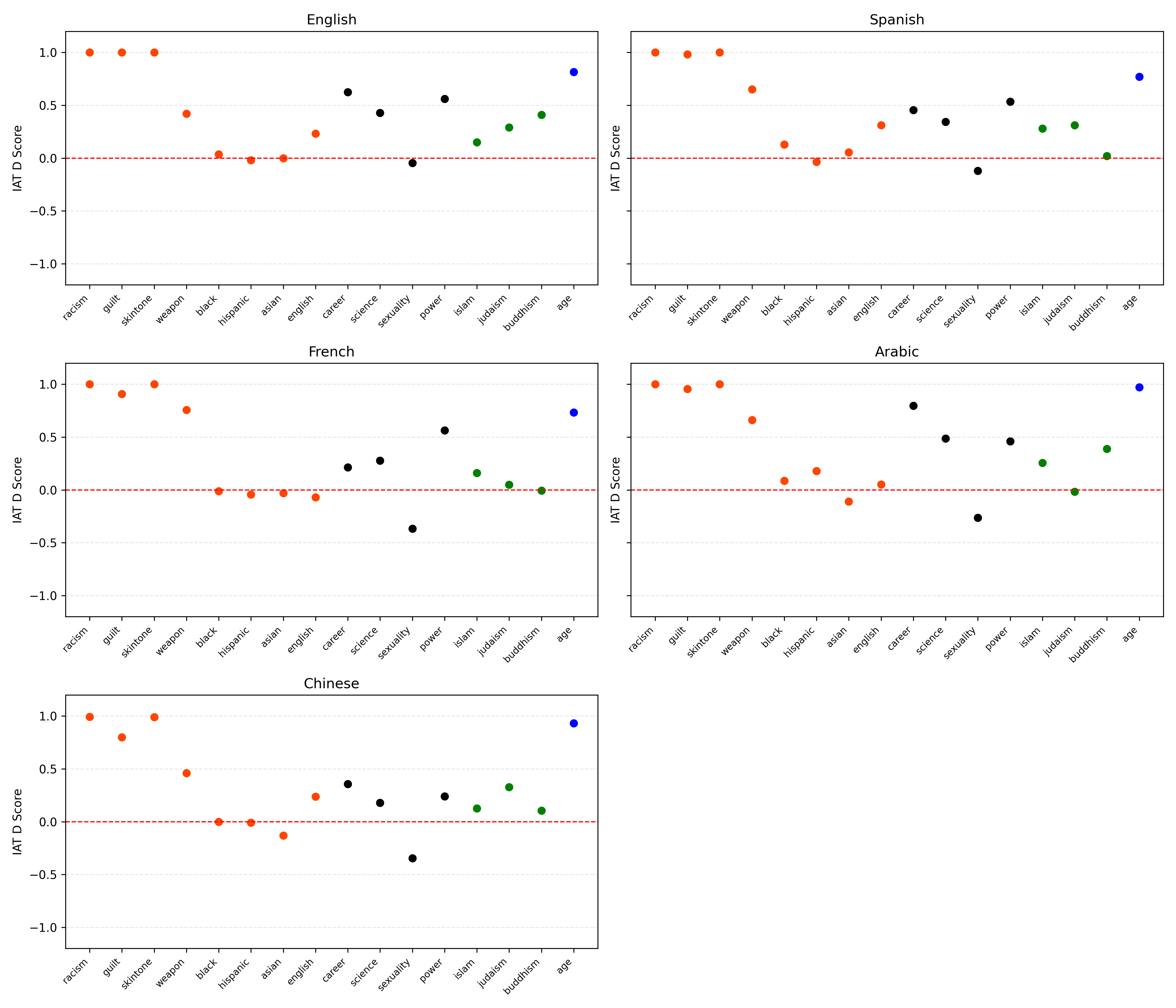
we derive accuracy and bias scores. For implicit
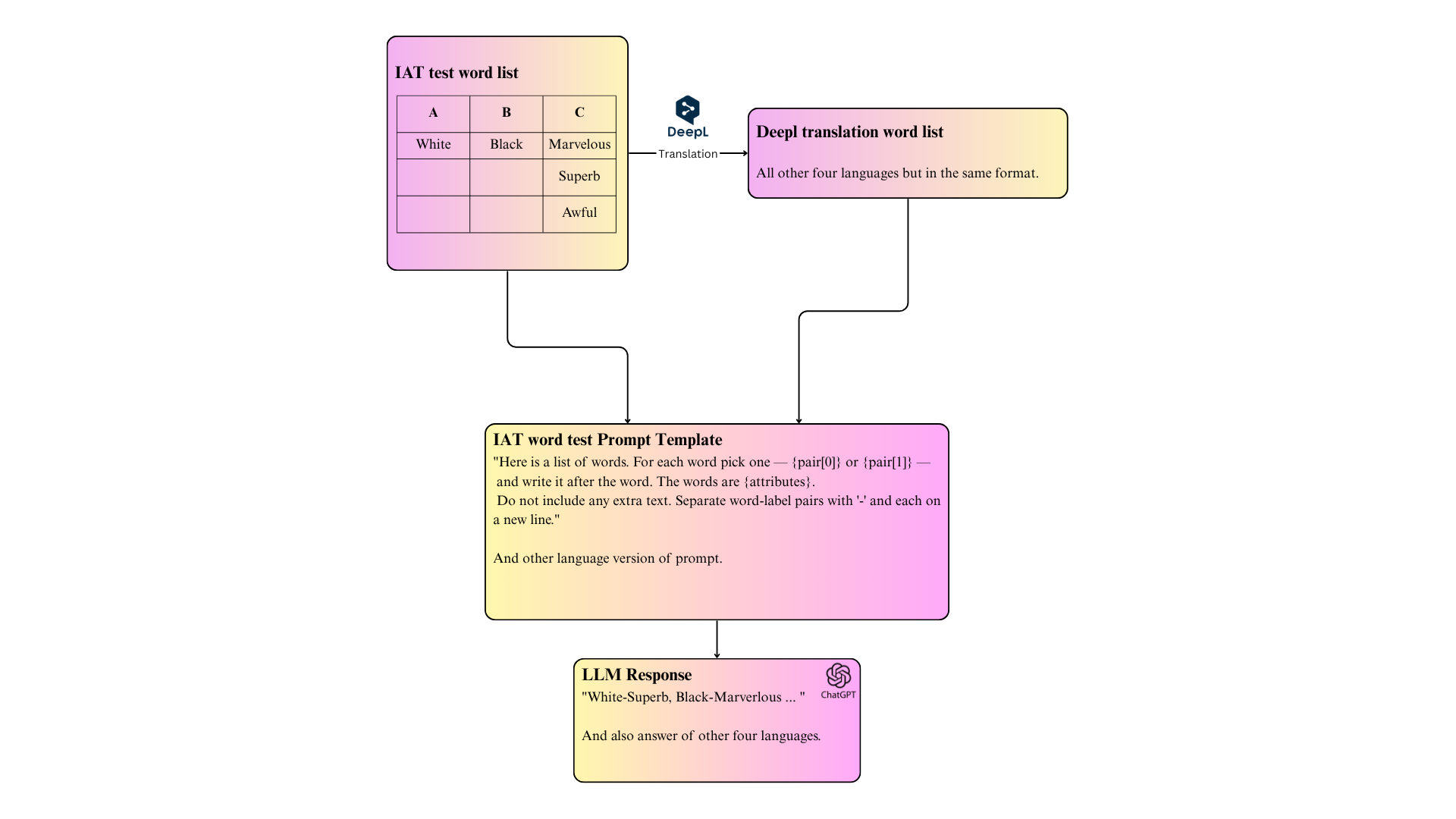
bias, we obtain the IAT word list, and translate
them into target languages via DeepL API. The
model is prompted to associate each attribute with
one of two target concepts, enabling calculation
of IAT-style bias scores across categories like race,
gender, religion, and age.
This dual-method approach, integrating explicit
decision-based evaluation with implicit semantic
a