Title: Seeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
ArXiv ID: 2512.15885
Date: 2025-12-17
Authors: Davide Caffagni, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Pier Luigi Dovesi, Shaghayegh Roohi, Mark Granroth-Wilding, Rita Cucchiara
📝 Abstract
Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
💡 Deep Analysis
📄 Full Content
Seeing Beyond Words: Self-Supervised Visual Learning for
Multimodal Large Language Models
Davide Caffagni1
Sara Sarto1
Marcella Cornia1
Lorenzo Baraldi1
Pier Luigi Dovesi2
Shaghayegh Roohi2
Mark Granroth-Wilding2
Rita Cucchiara1
1University of Modena and Reggio Emilia
2AMD Silo AI
1{name.surname}@unimore.it
2{name.surname}@amd.com
Abstract
Multimodal Large Language Models (MLLMs) have re-
cently demonstrated impressive capabilities in connecting
vision and language, yet their proficiency in fundamental vi-
sual reasoning tasks remains limited. This limitation can be
attributed to the fact that MLLMs learn visual understand-
ing primarily from textual descriptions, which constitute
a subjective and inherently incomplete supervisory signal.
Furthermore, the modest scale of multimodal instruction
tuning compared to massive text-only pre-training leads
MLLMs to overfit language priors while overlooking vi-
sual details. To address these issues, we introduce JARVIS,
a JEPA-inspired framework for self-supervised visual en-
hancement in MLLMs. Specifically, we integrate the I-JEPA
learning paradigm into the standard vision-language align-
ment pipeline of MLLMs training.
Our approach lever-
ages frozen vision foundation models as context and tar-
get encoders, while training the predictor, implemented as
the early layers of an LLM, to learn structural and se-
mantic regularities from images without relying exclusively
on language supervision. Extensive experiments on stan-
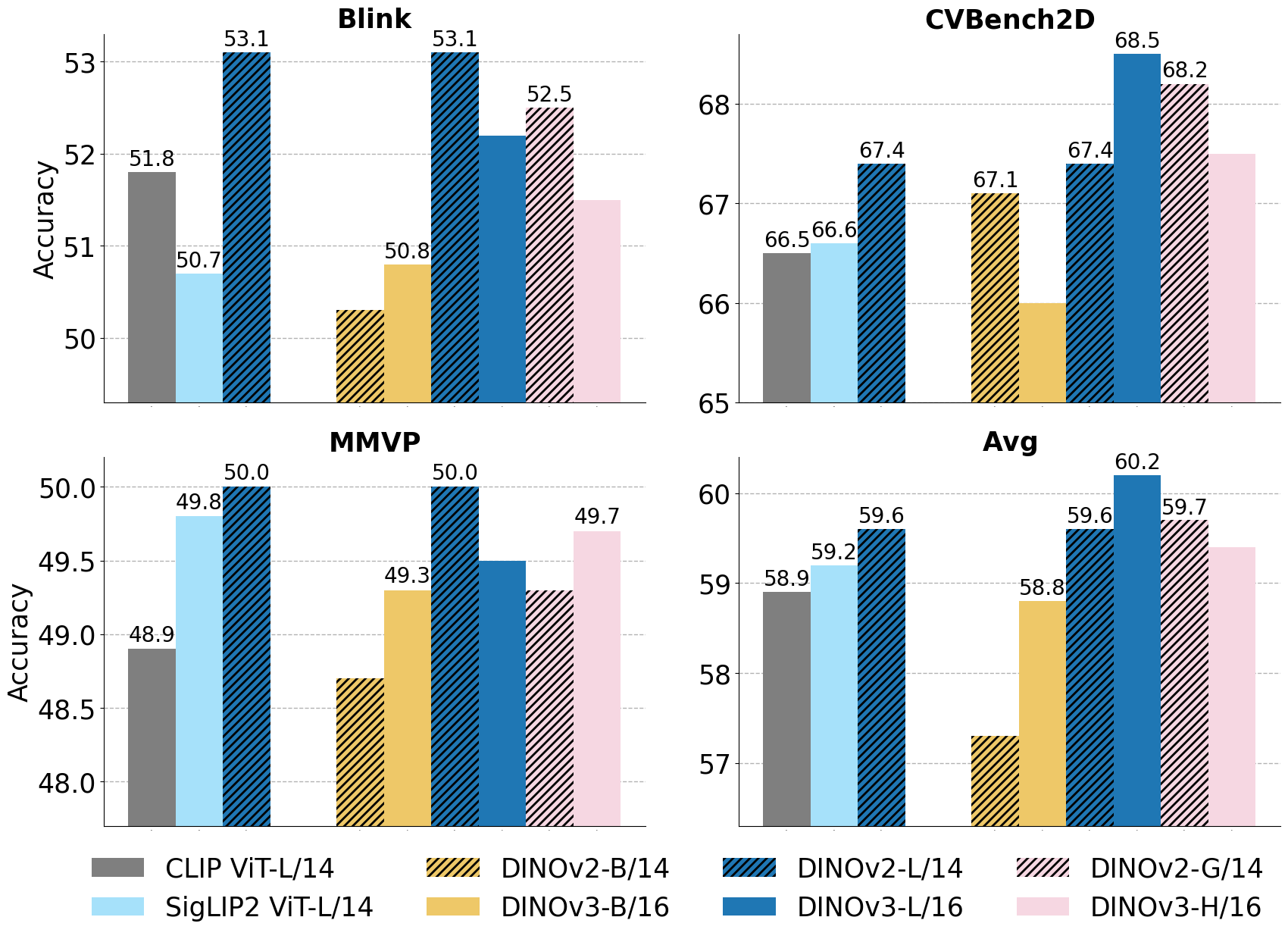
dard MLLM benchmarks show that JARVIS consistently im-
proves performance on vision-centric benchmarks across
different LLM families, without degrading multimodal rea-
soning abilities. Our source code is publicly available at:
https://github.com/aimagelab/JARVIS.
1. Introduction
The rapid success of Large Language Models (LLMs) [10,
54, 58] has shown the growing need for these models to
process and reason across modalities beyond text. This de-
mand has led to the emergence of Multimodal Large Lan-
guage Models (MLLMs) [11], which convert different in-
put modalities into the same embedding space of the LLM,
effectively allowing it to understand [3, 30, 64], or even
generate [51], other modalities, with particular emphasis
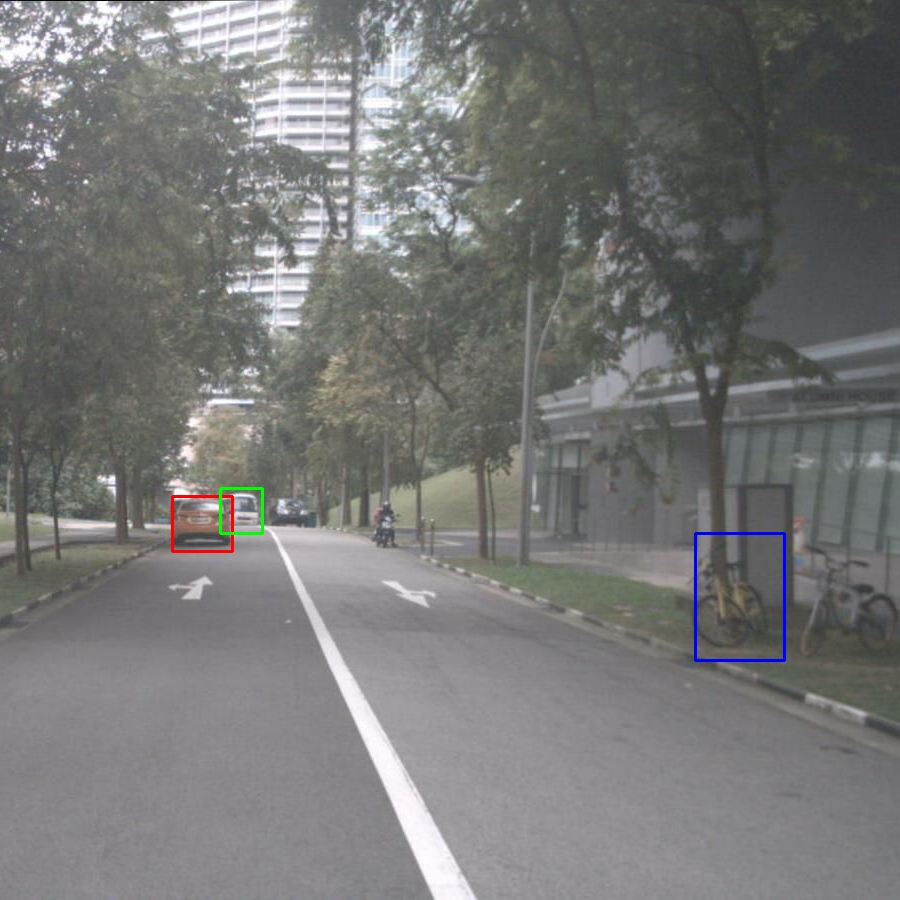
Visual
Encoder
The image depicts a
group of horses in
a field […]
LLM
Context
Encoder
The image depicts
a group of horses
in a field […]
LLM
Target
Encoder
Context
Encoder
The image depicts
a group of horses
in a field […]
LLM
Target
Encoder
Figure 1. Comparison of LLaVA (top-left), a baseline that aligns
the output of a selected layer with the output of a target encoder
(top-right), and JARVIS that align the outputs employing a masked
predictive loss (bottom-left). We also report the results of JARVIS
and LLaVA across three vision benchmarks (bottom-right).
on images. Despite impressive progress, the fundamental
recipe to design an MLLM has not changed since the in-
troduction of visual instruction tuning, originally proposed
by LLaVA [15, 32, 36, 37]. LLaVA demonstrates that a
lightweight projector can bridge visual and textual modali-
ties by aligning the image representations from the vision
encoder with the textual embedding space of the LLM.
Through this alignment, projected visual features can be ef-
fectively interpreted by the LLM, enabling it to reason about
images and generate text conditioned on visual content.
While this pipeline has proven highly effective across a
broad range of tasks, current MLLMs still exhibit notable
limitations in surprisingly simple visual reasoning scenar-
ios, such as confirming the presence of objects, counting
them, understanding their spatial relationships, or estimat-
ing their relative distance [18, 56, 57, 63]. The low profi-
ciency of current MLLMs in these visual tasks highlights
a severe deficit in their visual perception. We believe that
1
arXiv:2512.15885v1 [cs.CV] 17 Dec 2025
this flaw emerges because MLLMs are trained to see images
only via their textual descriptions. Indeed, during the align-
ment stage proposed by LLaVA, the MLLM is presented
with an image, and the learning objective is to generate its
caption. Intuitively, if the MLLM can describe an image,
then it should have seen it. However, image captions are
inherently subjective [13, 48]: they reflect what annotators
think are relevant, often omitting details that may be cru-
cial from other perspectives. Moreover, it is not practically
feasible to assume having access to all possible descriptions
of an image. Consequently, an image intrinsically contains
richer and more comprehensive information than any subset
of its textual descriptions. At the same time, because multi-
modal training is relatively modest compared to the massive
unsupervised pre-training on textual corpora, MLLMs often
over-rely on language priors when reasoning about an im-
age, thereby overlooking visual details [8, 16, 61, 67].
With that in mind, in this work we advocate for training
MLLMs with the self-supervised signal inherent