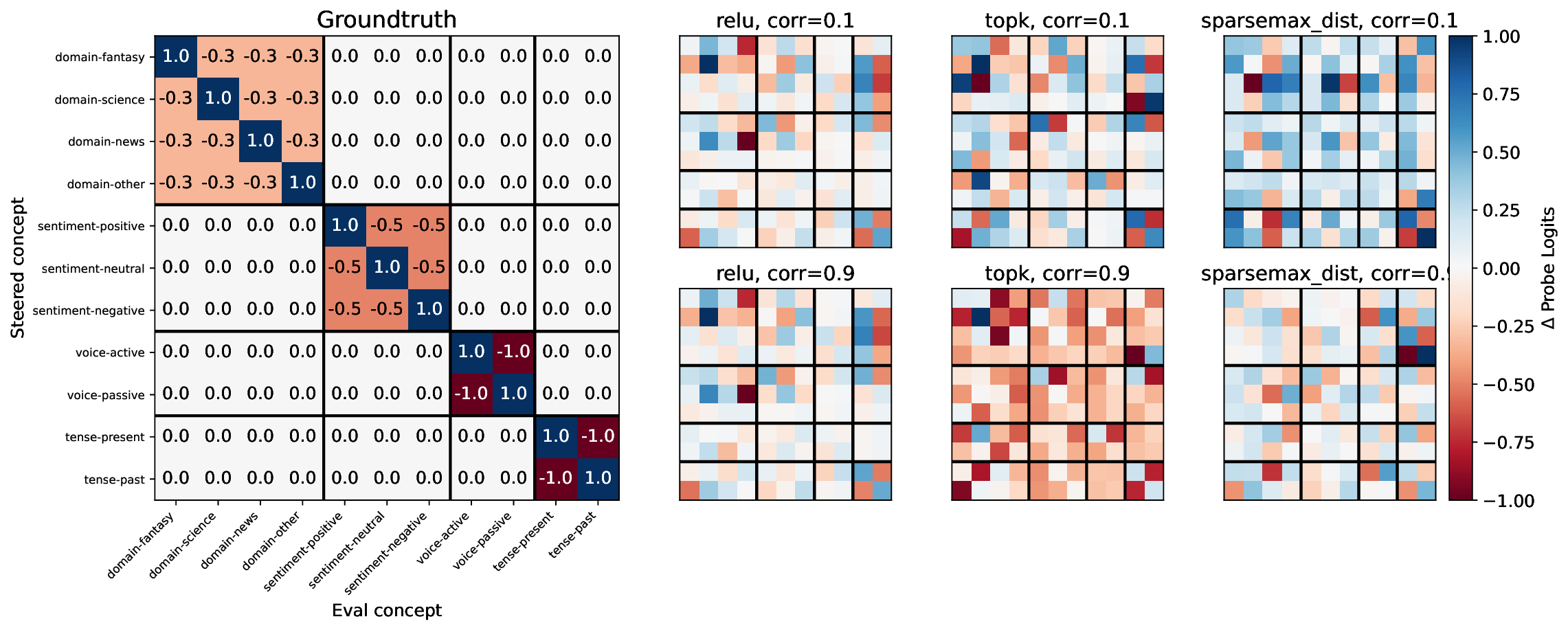
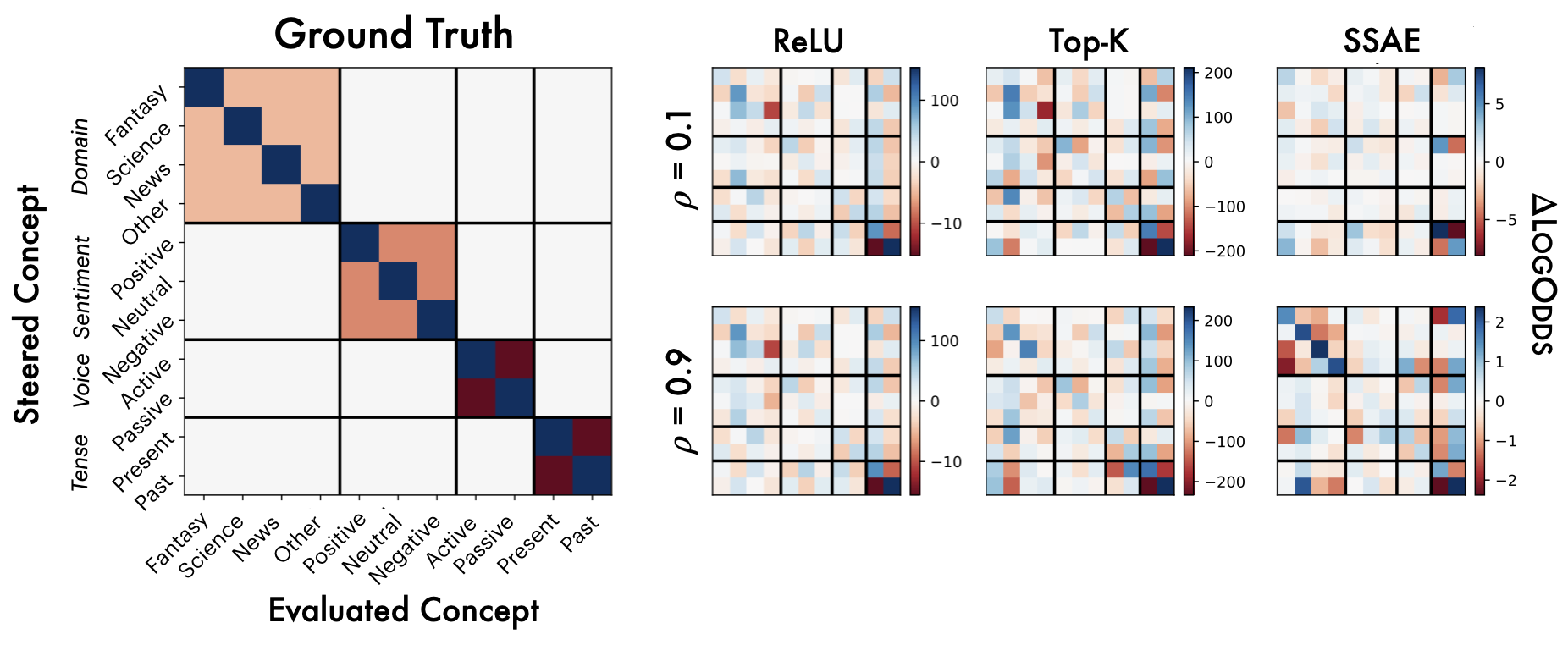
A central goal of interpretability is to recover representations of causally relevant concepts from the activations of neural networks. The quality of these concept representations is typically evaluated in isolation, and under implicit independence assumptions that may not hold in practice. Thus, it is unclear whether common featurization methods - including sparse autoencoders (SAEs) and sparse probes - recover disentangled representations of these concepts. This study proposes a multi-concept evaluation setting where we control the correlations between textual concepts, such as sentiment, domain, and tense, and analyze performance under increasing correlations between them. We first evaluate the extent to which featurizers can learn disentangled representations of each concept under increasing correlational strengths. We observe a one-to-many relationship from concepts to features: features correspond to no more than one concept, but concepts are distributed across many features. Then, we perform steering experiments, measuring whether each concept is independently manipulable. Even when trained on uniform distributions of concepts, SAE features generally affect many concepts when steered, indicating that they are neither selective nor independent; nonetheless, features affect disjoint subspaces. These results suggest that correlational metrics for measuring disentanglement are generally not sufficient for establishing independence when steering, and that affecting disjoint subspaces is not sufficient for concept selectivity. These results underscore the importance of compositional evaluations in interpretability research.
Interpretability centers on understanding and controlling neural network behaviors (Geiger et al., 2025;Mueller et al., 2025a). This requires understanding the underlying causal variables and mechanisms that produce observed input-output behaviors. To precisely localize these causal variables, featurization methods, such as sparse autoencoders (SAEs; Olshausen & Field, 1997;Bricken et al., 2023;Huben et al., 2024), have become common. These methods map from activation vectors (wherein a dimension can have many meanings) to sparser spaces where there is a more one-to-one relationship between dimensions and concepts.
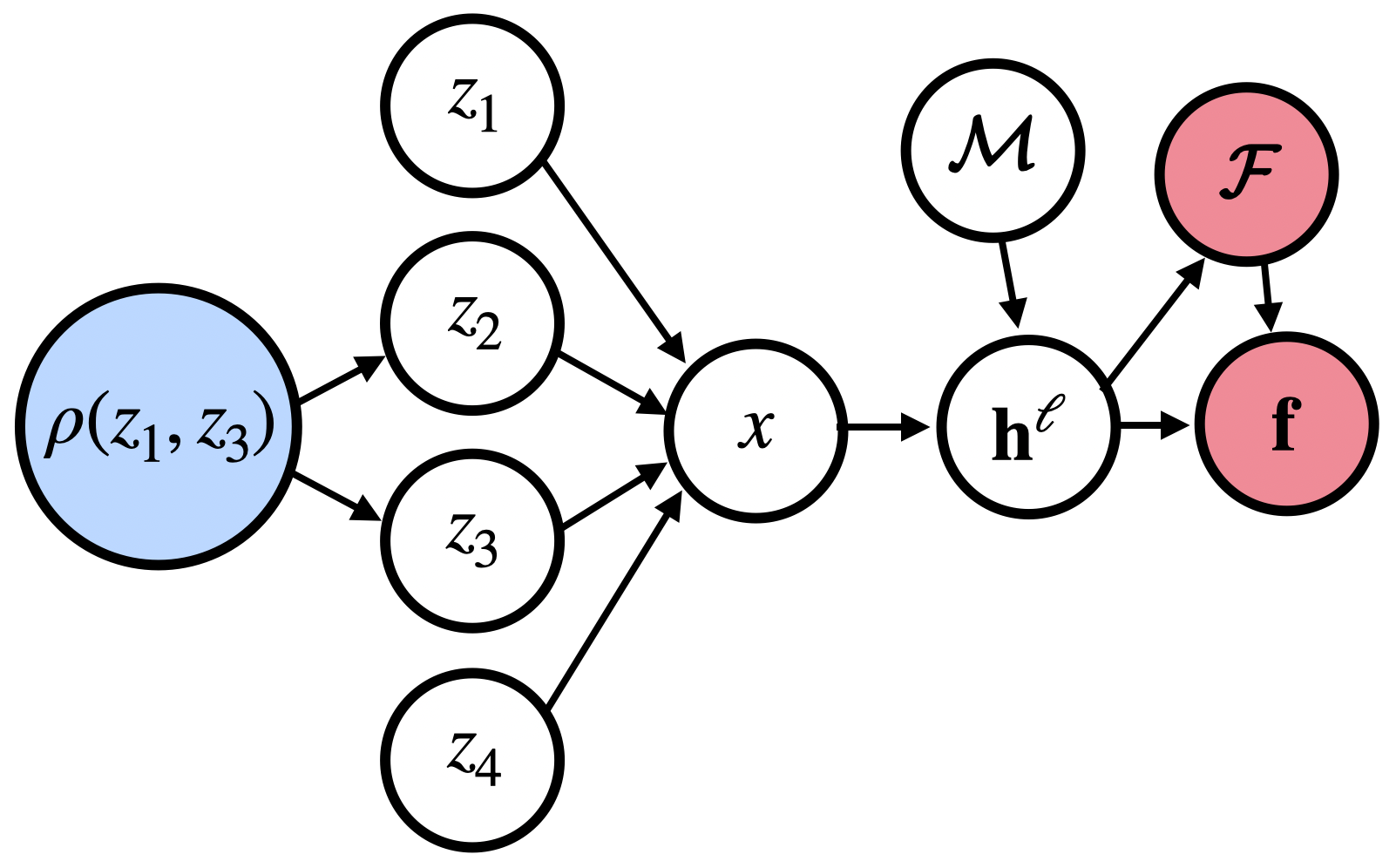
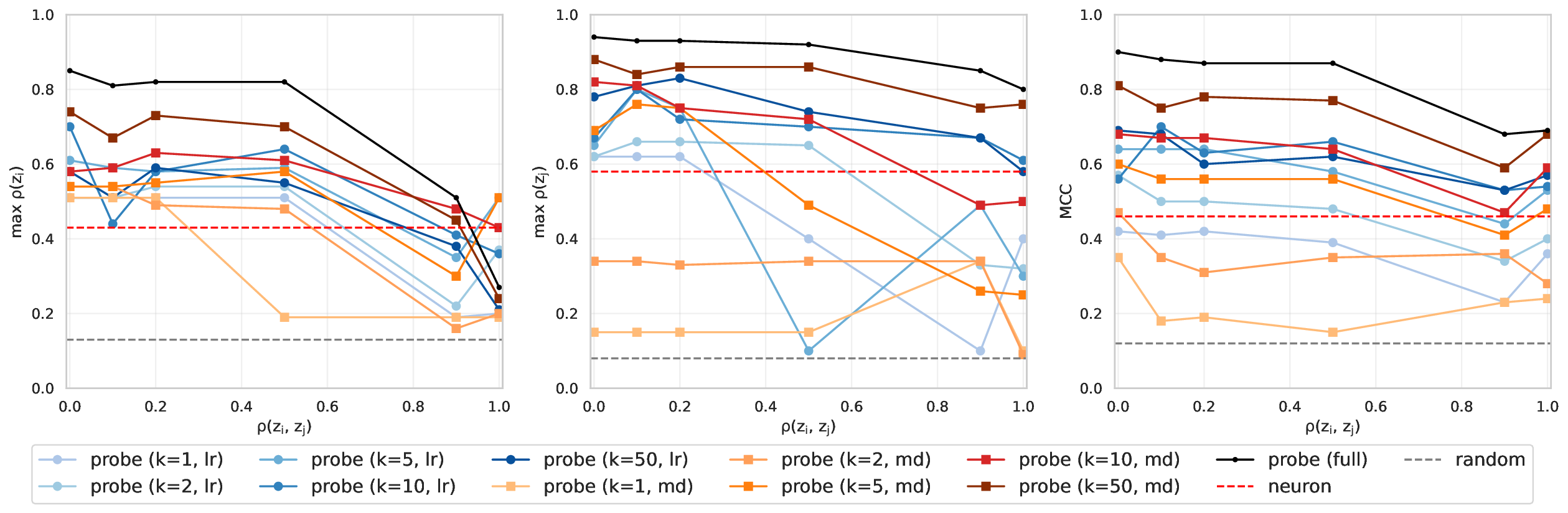
The implicit assumption underlying these applications is that if we can identify features that represent distinct concepts, then we should be able to steer those concepts by by manipulating their corresponding features. But does representational disentanglement guarantee independent manipulability? Current concept identification and steering studies focus on detecting and/or steering single concepts or behaviors at a time (e.g., Wu et al., 2025;Arditi et al., 2024;Marks & Tegmark, 2024). This tells us whether the concept exists in the model and can be manipulated, but leaves open the question of whether the concept representation is independent and disentangled from other concepts. How often does steering one concept affect others? Independence and disentanglement act as a ceiling for Preprint our trust in steering methods to induce similar behaviors in novel contexts-i.e., to what degree we have predictive power and selective control over the model’s future behaviors. This is not a new idea: the fields of causal representation learning (CRL; Schölkopf et al., 2021) and disentangled representation learning (Higgins et al., 2018;Locatello et al., 2019;2020b) have rich literatures characterizing the assumptions under which it is possible to identify the true latent causal variables for a task. However, these fields focus on learning a representation from scratch, whereas the goal of interpretability is to derive a simplified causal model of a large and complex neural network that has already been trained. Both lines of work are unified in asking: in what circumstances is it possible to recover causally efficacious representations? i=1 are used to generate an example x. We train a featurizer F to generate vectors f given activation vectors h ℓ from the output of layer ℓ of language model M. When training F on examples with increasing correlations between pairs of concepts ρ(z i , z j ), we observe whether F learns the true latents or the correlational confound (as measured by the correlation between latents in f and the presence of the true variable z i ).
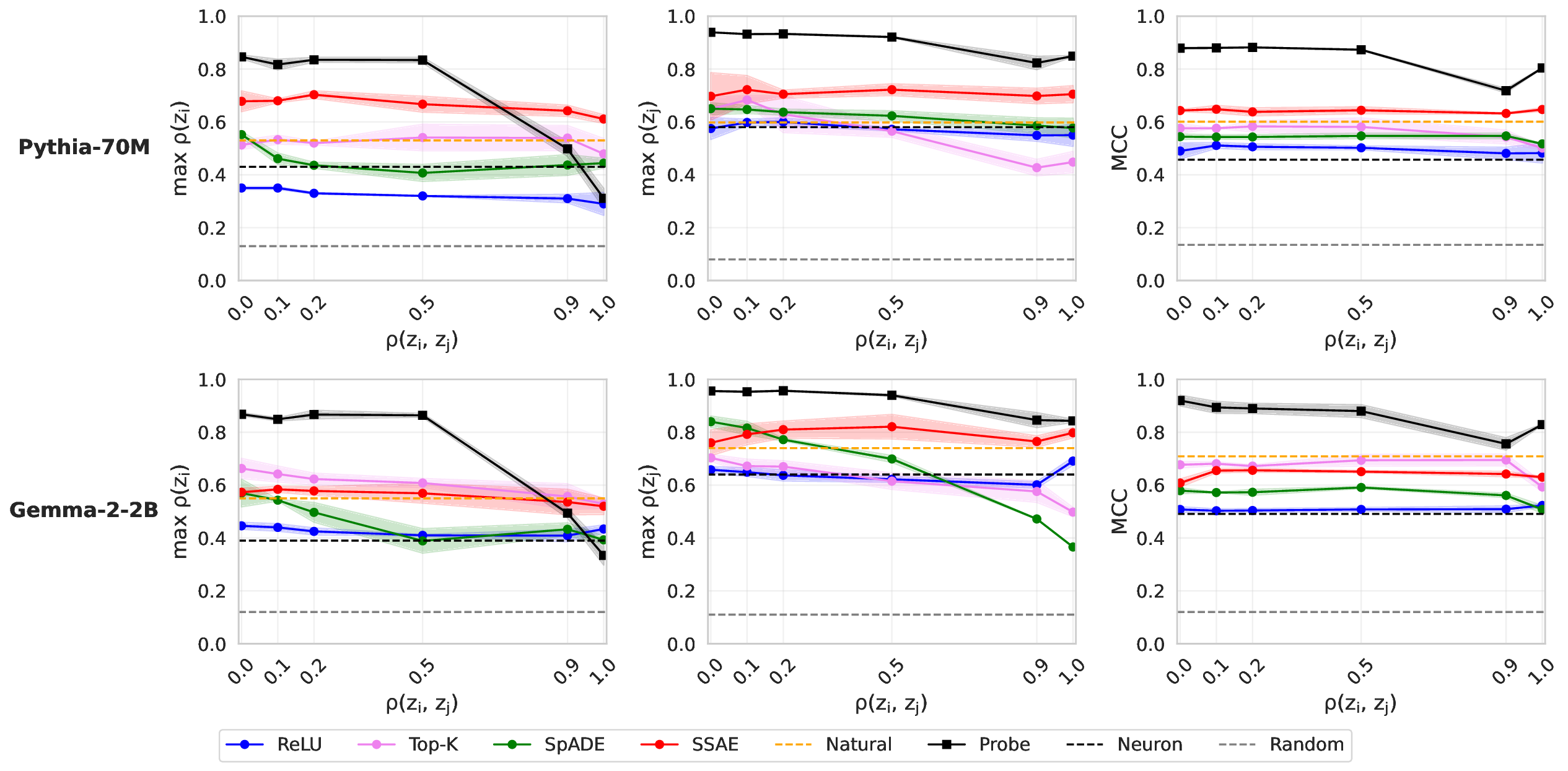
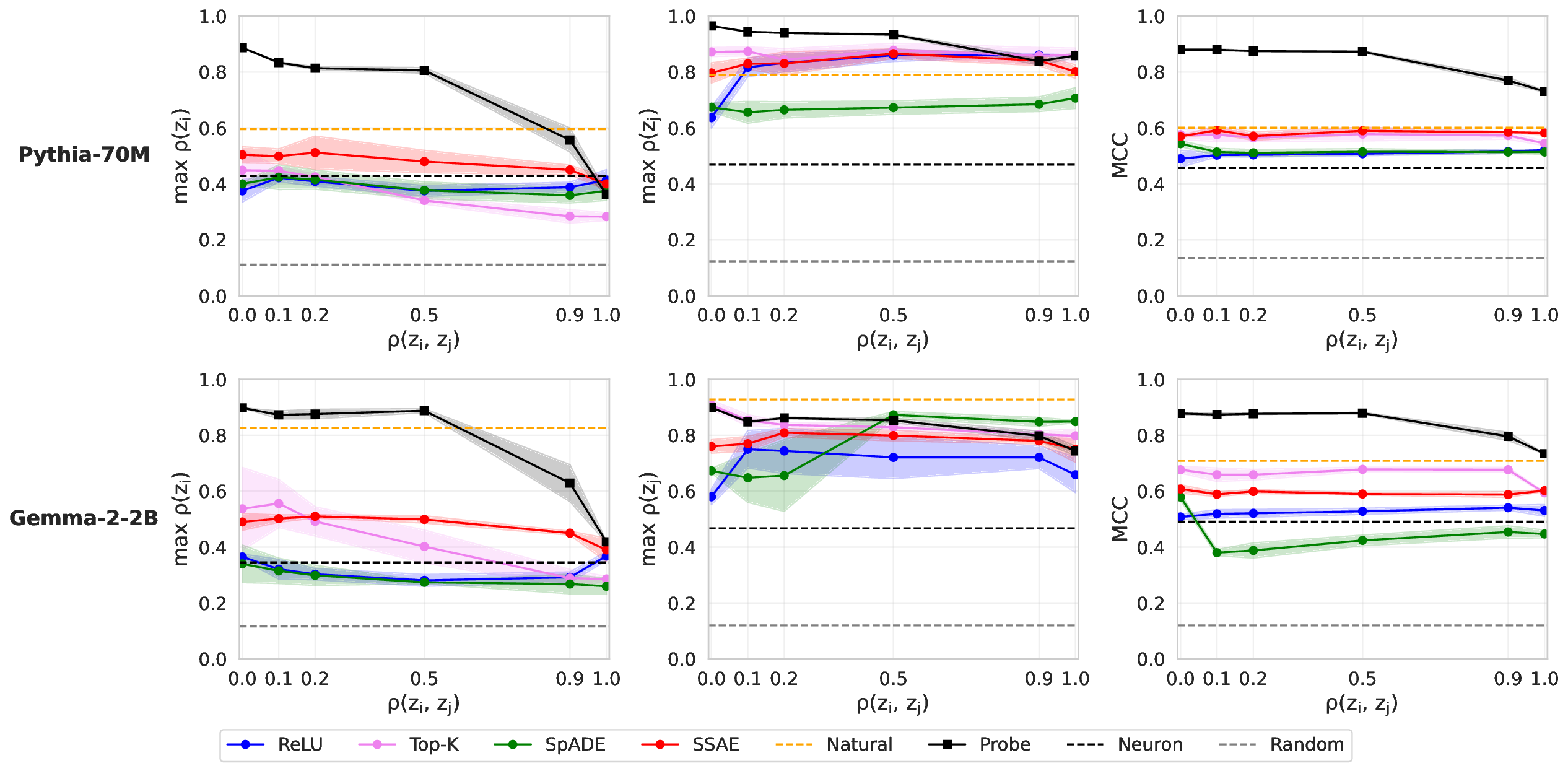
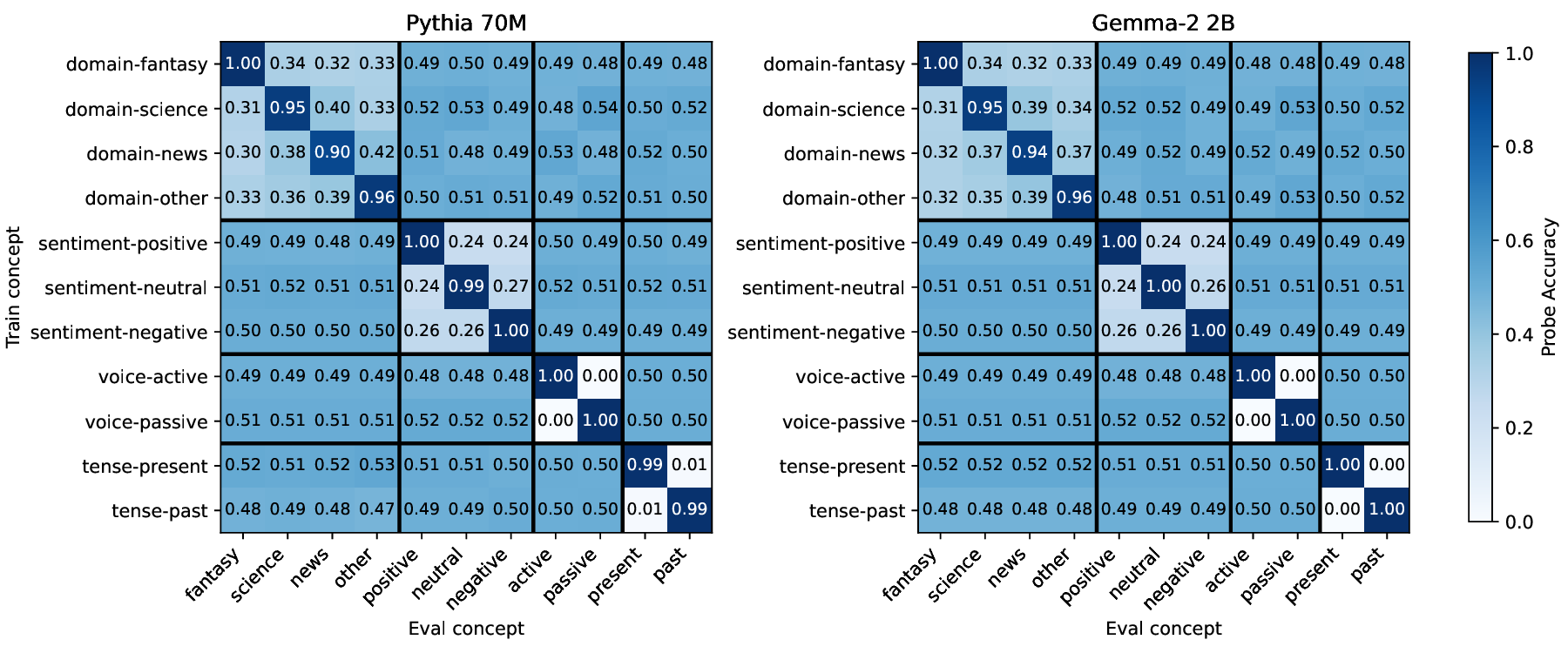
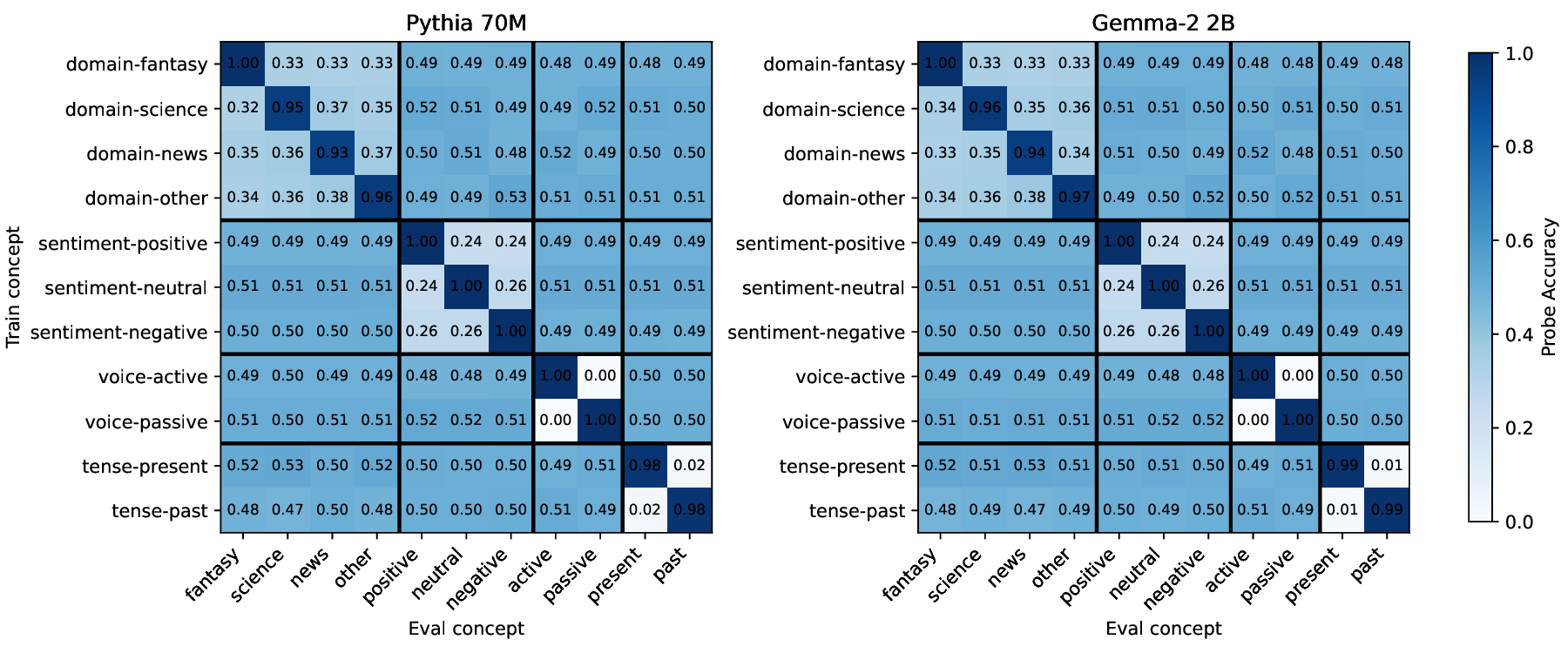
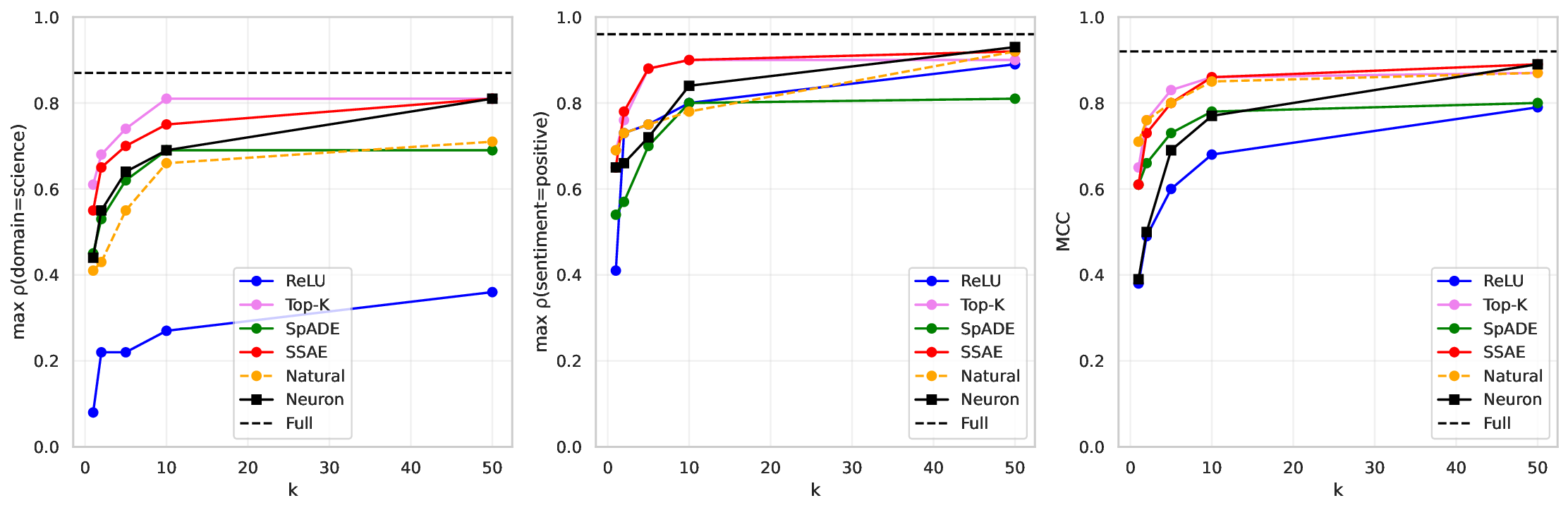
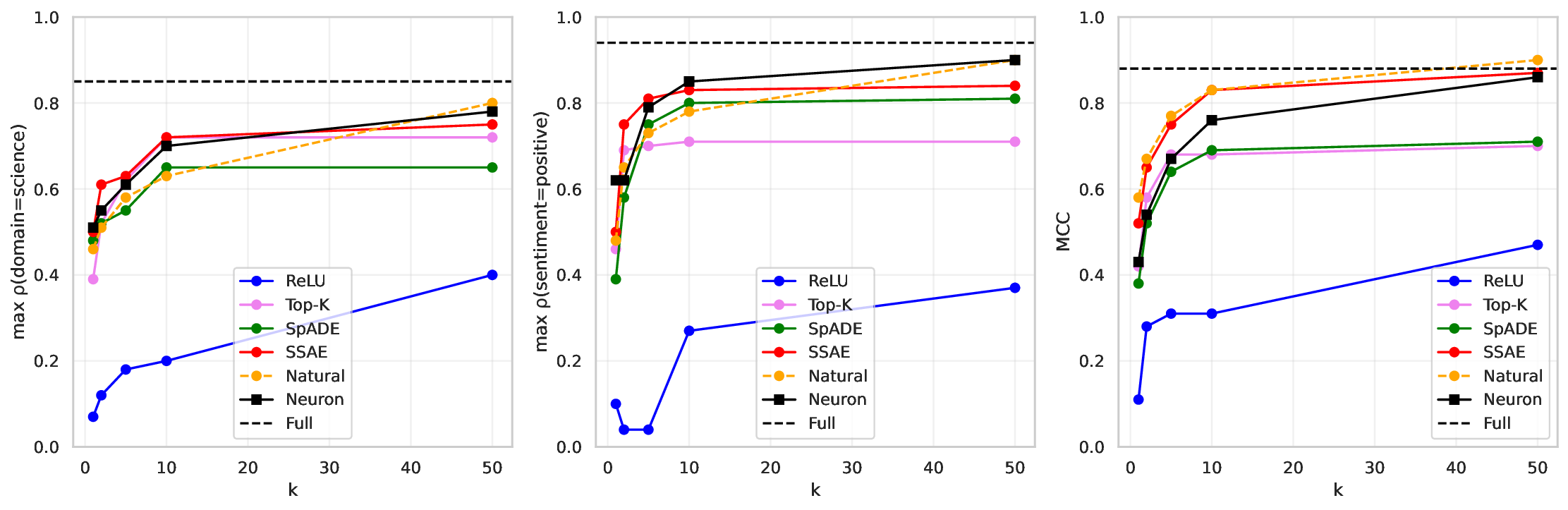
Our work builds upon and extends the metrics and evaluation paradigms of CRL to measure mechanistic independence in a multi-concept evaluation setting. To investigate, we require a setting where ground-truth concepts are known, and multiple concepts can be evaluated simultaneously. We generate a natural language dataset using probabilistic context-free grammars (PCFG; Booth & Thompson, 1973), where each sentence is labeled with four known concepts (voice, tense, sentiment, domain), and where we can control the degree of correlation between concepts in the dataset. This allows us to test whether SAE features maintain disentangled concept representations under varying degrees of confounding. We use this data to evaluate common interpretability methods, including sparse probes (Gurnee et al., 2023) and sparse autoencoders (Olshausen & Field, 1997;Huben et al., 2024), through two lenses: (1) Do sparse features and probes achieve high scores on standard correlational disentanglement metrics from CRL (MCC, DCI-ES)? And (2) when we steer features, do they selectively manipulate their target concepts without affecting others?
Our contributions and findings are:
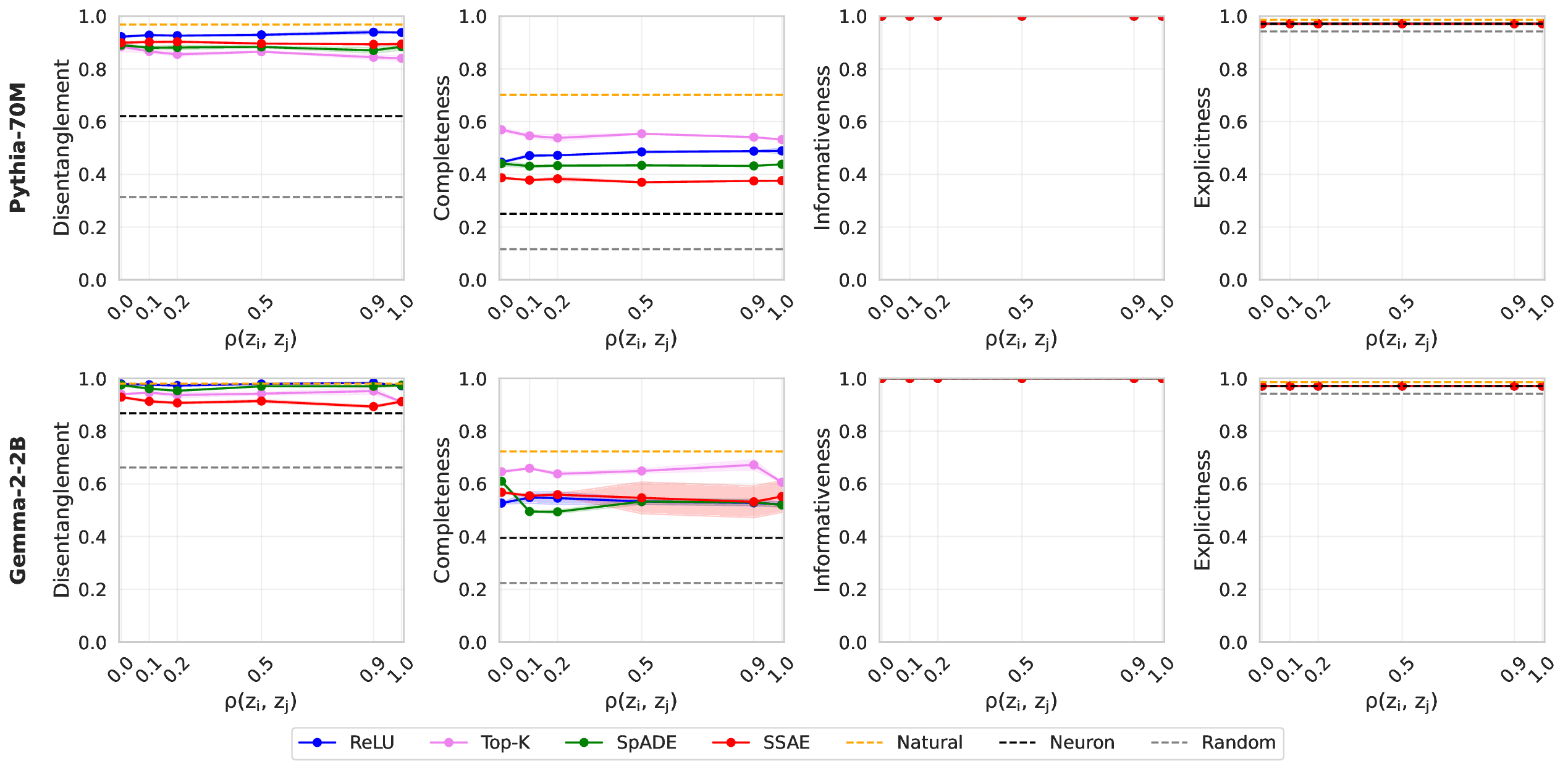
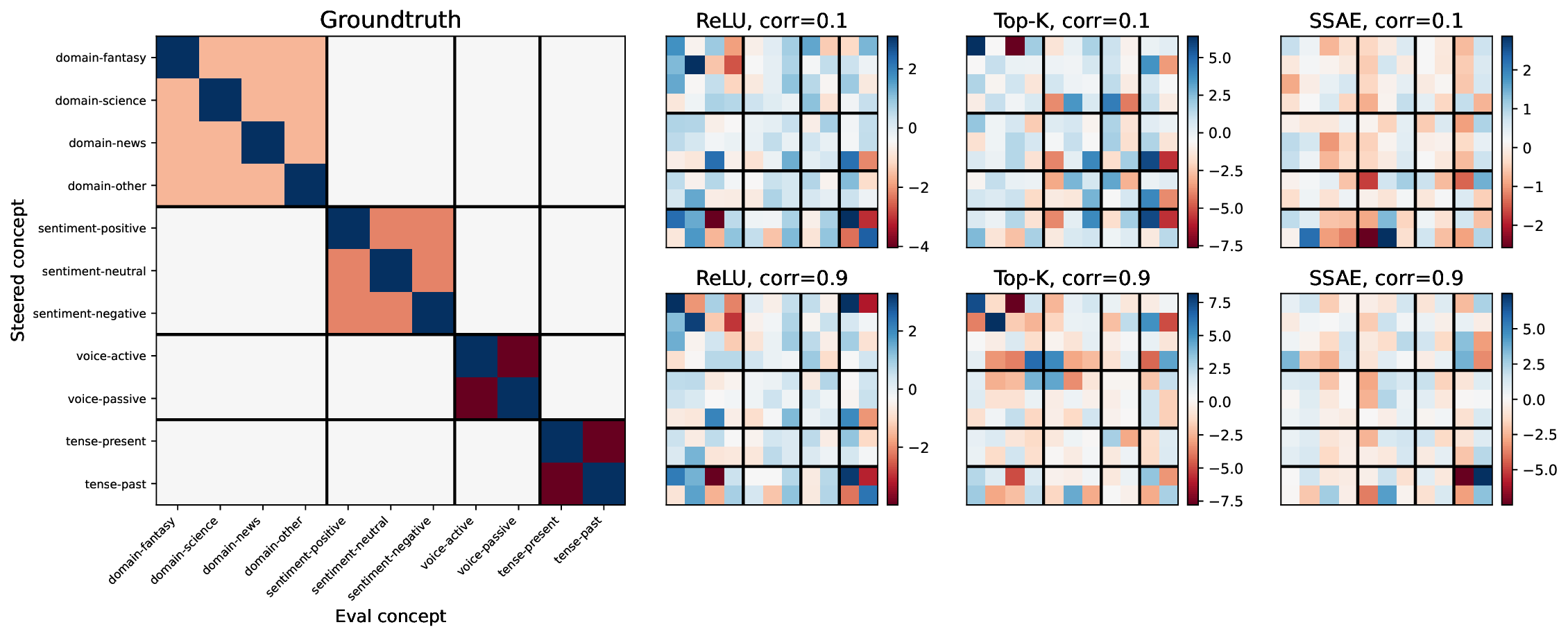
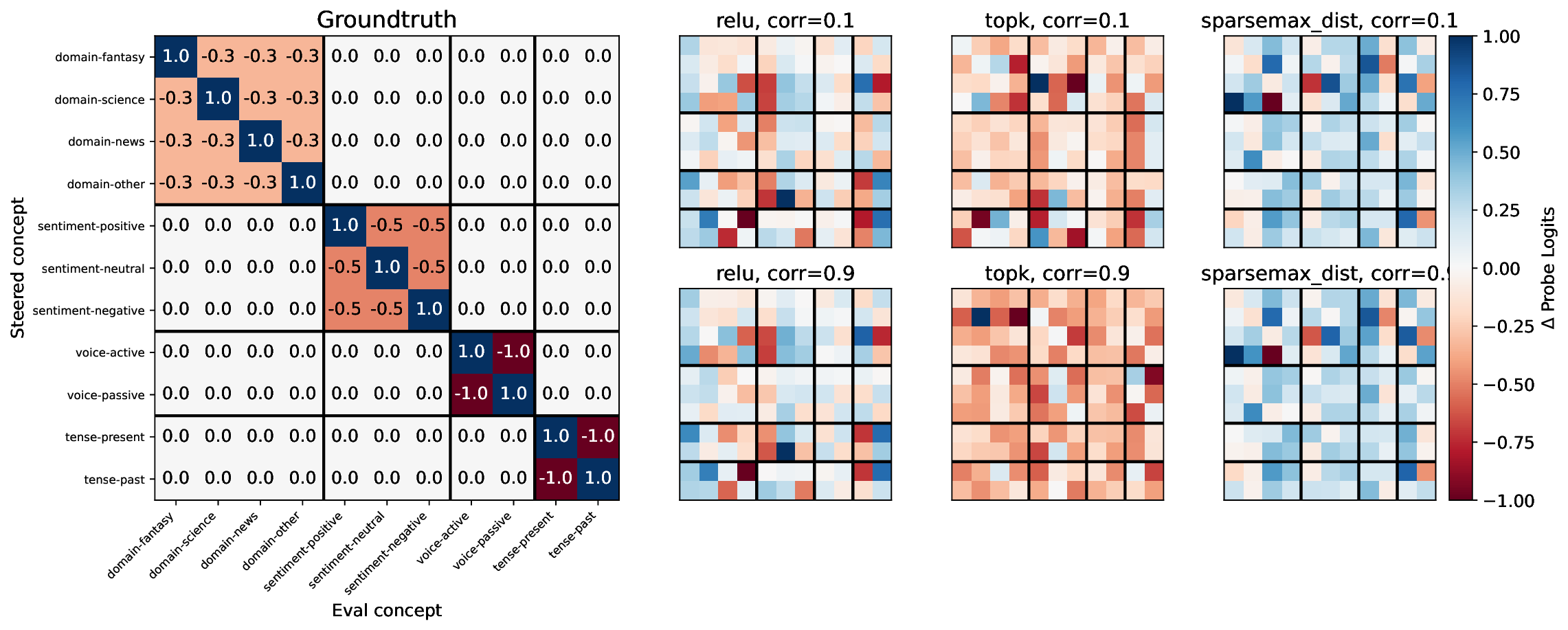
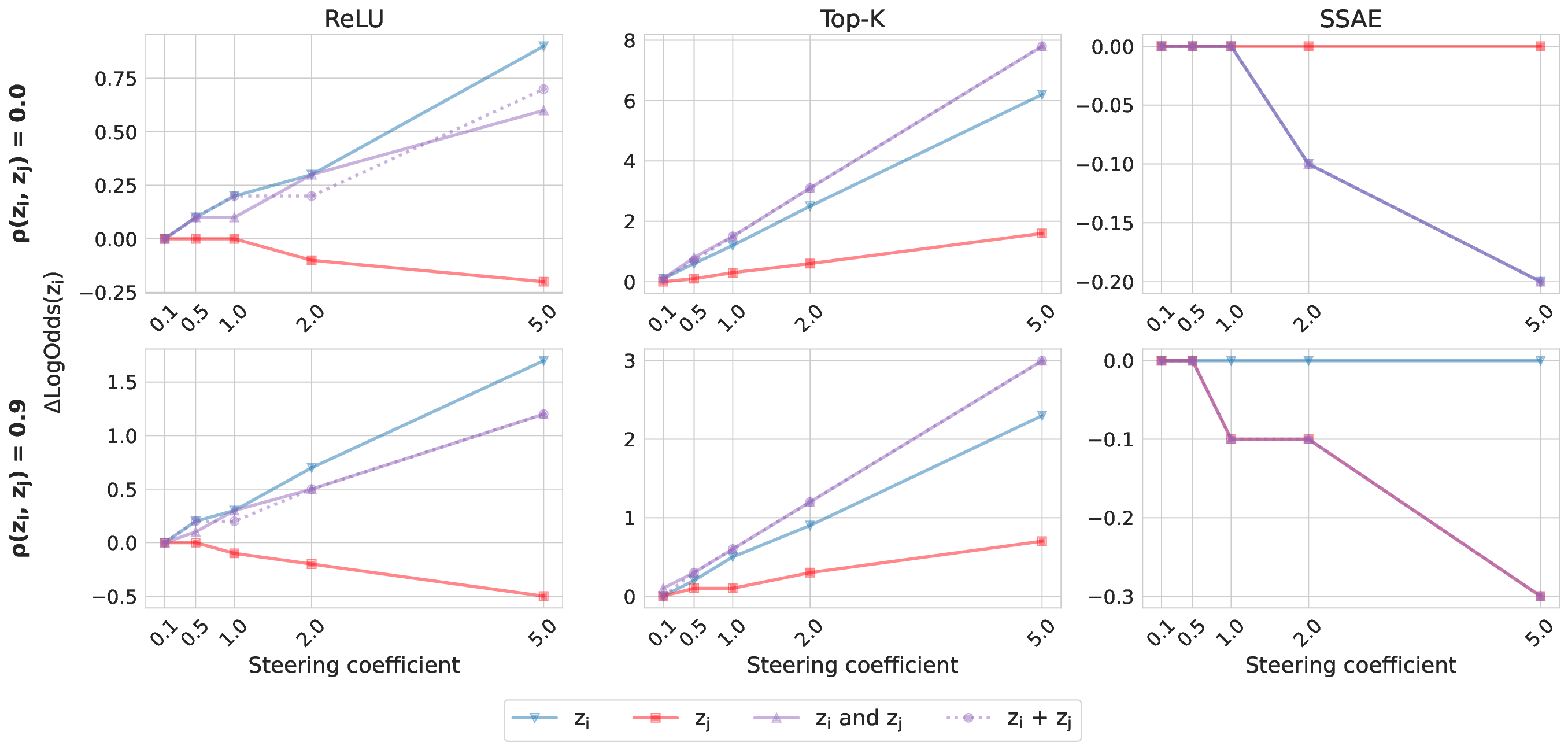
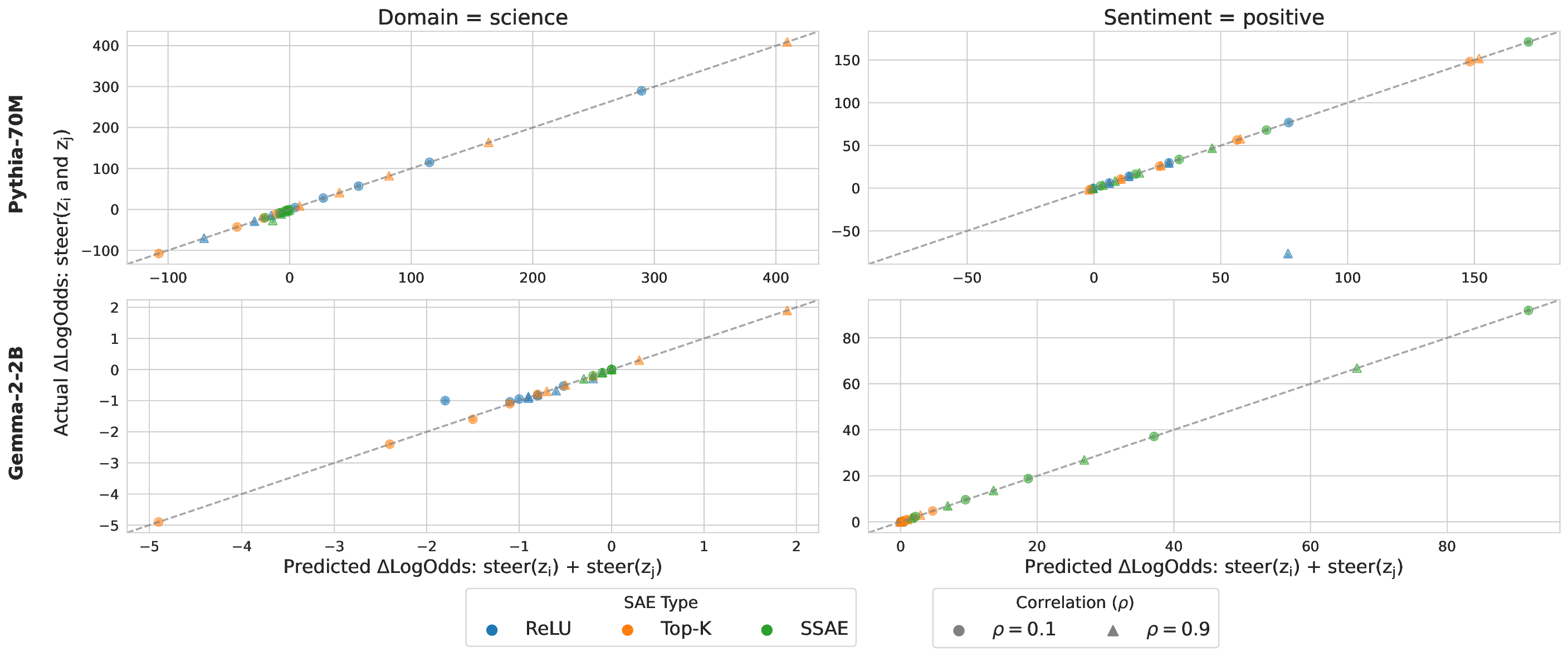
• We introduce an evaluation framework and dataset to measure concept disentanglement, with adjustable correlations between ground-truth concepts ( §3.1). • We show that standard SAE architectures and sparse probes achieve high disentanglement according to correlational metrics ( §3.1), but that this does not predict the selectivity of steering ( §4). We propose new metrics to quantify shortcomings in steering experiments ( §4.1). • We distinguish between feature disjointness (operating on non-overlapping subspaces) and independence (selective manipulability). Current methods succeed in recovering non-overlapping representations, but often affect multiple unrelated concepts downstream ( § 4.2).
Our results suggest that even principled correlational metrics are insufficient for predicting steering performance, and that current feature extractors generally do not selectively manipulate one concept at a time. The gap between disjointness and independence further suggests that current featurization objectives may be optimizing for the wrong notion of concept separation. Overall, these findings und
This content is AI-processed based on open access ArXiv data.