Prompt Repetition Improves Non-Reasoning LLMs
📝 Original Info
- Title: Prompt Repetition Improves Non-Reasoning LLMs
- ArXiv ID: 2512.14982
- Date: 2025-12-17
- Authors: Yaniv Leviathan, Matan Kalman, Yossi Matias
📝 Abstract
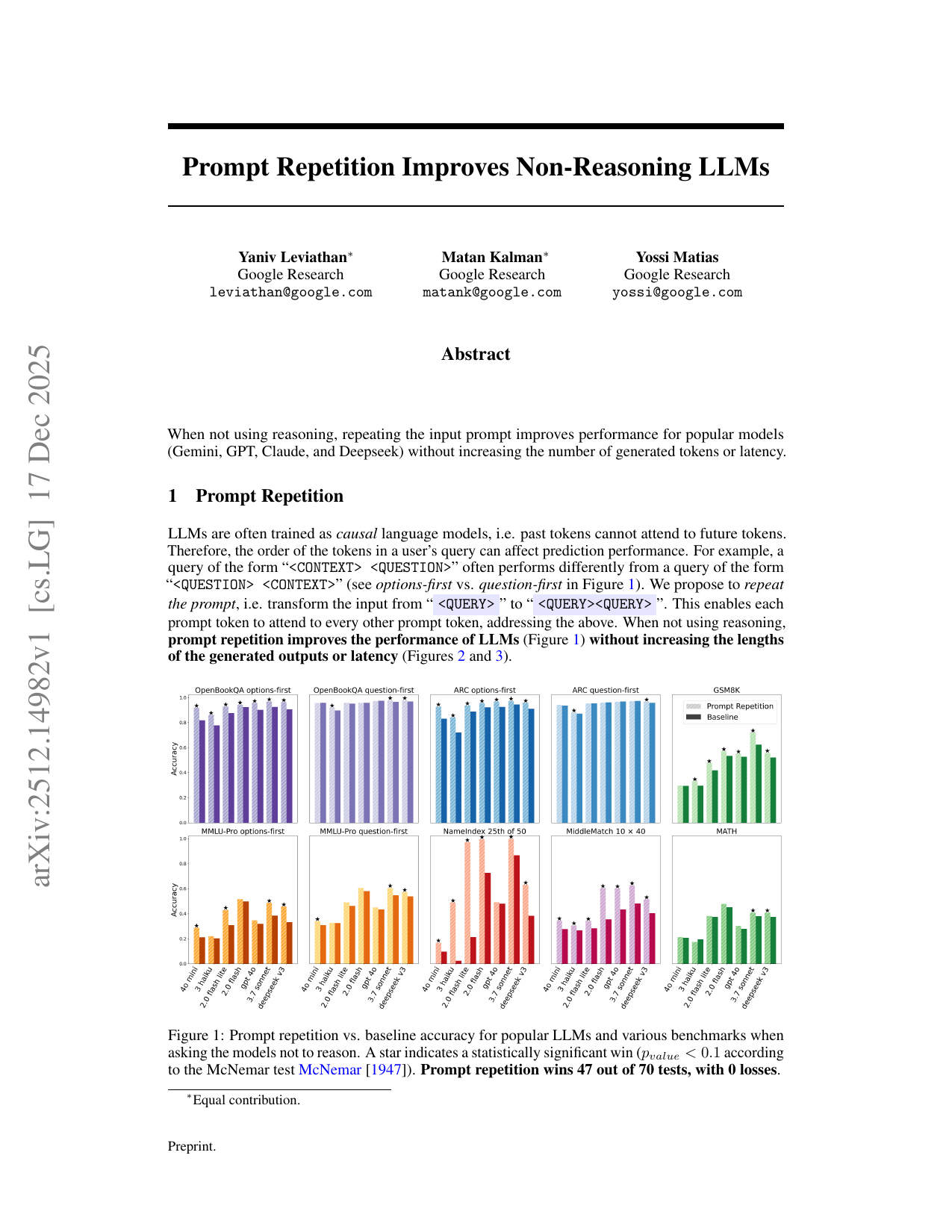
When not using reasoning, repeating the input prompt improves performance for popular models (Gemini, GPT, Claude, and Deepseek) without increasing the number of generated tokens or latency.💡 Deep Analysis
📄 Full Content
We test prompt repetition on a range of 7 popular models from leading LLM providers of varying sizes: Gemini 2.0 Flash and Gemini 2.0 Flash Lite [Gemini Team Google, 2023], GPT-4o-mini and GPT-4o [OpenAI, 2024], Claude 3 Haiku and Claude 3.7 Sonnet [Anthropic, 2024], and Deepseek V3 [DeepSeek-AI, 2025]. We ran all tests using each provider’s official API in Feb and Mar 2025.
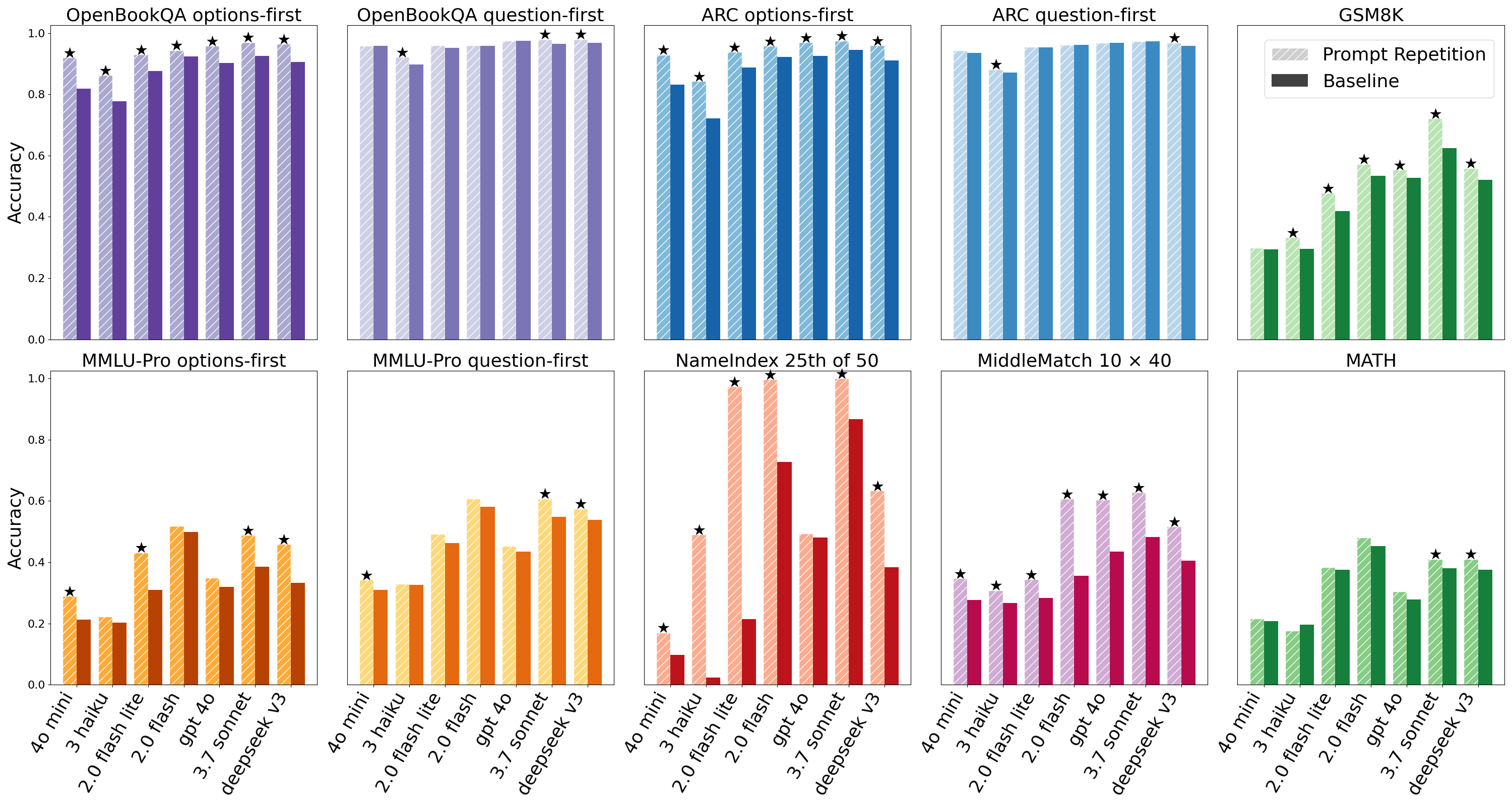
We test each of the models on a set of 7 benchmarks in several configurations: ARC (Challenge) [Clark et al., 2018], OpenBookQA [Mihaylov et al., 2018], GSM8K [Cobbe et al., 2021], MMLU-Pro [Wang et al., 2024], MATH [Hendrycks et al., 2021], and 2 custom benchmarks: NameIndex and MiddleMatch (Appendix A.3). For the multiple choice benchmarks (ARC, OpenBookQA, and MMLU-Pro) we report results both when placing the question first and the answer options later, as well as the other way around, the latter making the model process the options without seeing the question in context (unless using prompt repetition).
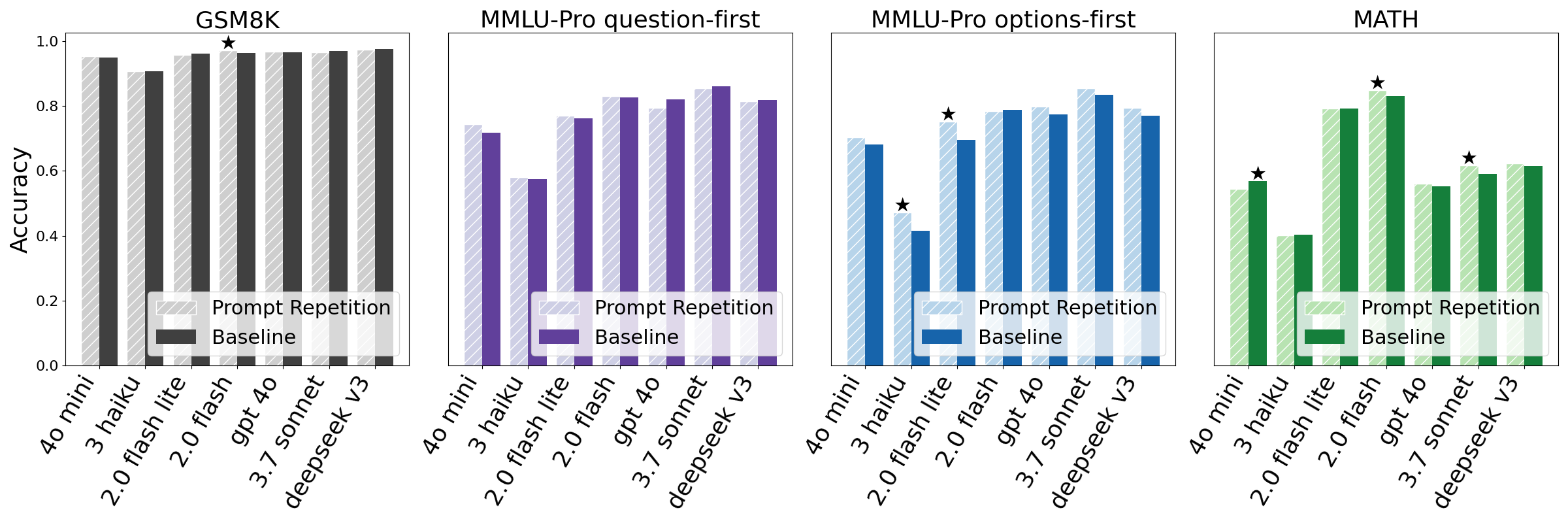
Accuracy. Without reasoning, prompt repetition improves the accuracy of all tested LLMs and benchmarks (Figure 1). We consider cases where one method is significantly better than the other according to the McNemar test [McNemar, 1947] with p value < 0.1 as wins. With this criteria, prompt repetition wins 47 out of 70 benchmark-model combinations, with 0 losses. Notably, performance is improved for all tested models. As expected, we observe smaller improvements for the multiple-choice benchmarks with question-first, and larger improvements with options-first. On the custom tasks of NameIndex and MiddleMatch we observe strong gains with prompt repetition for all models (for example, prompt repetition improves the accuracy of Gemini 2.0 Flash-Lite on NameIndex from 21.33% to 97.33%). We also test a smaller set of benchmarks when encouraging thinking step-by-step (Figure 4), where the results are neutral to slightly positive (5 wins, 1 loss, and 22 neutral), as expected (see Appendix A.2).
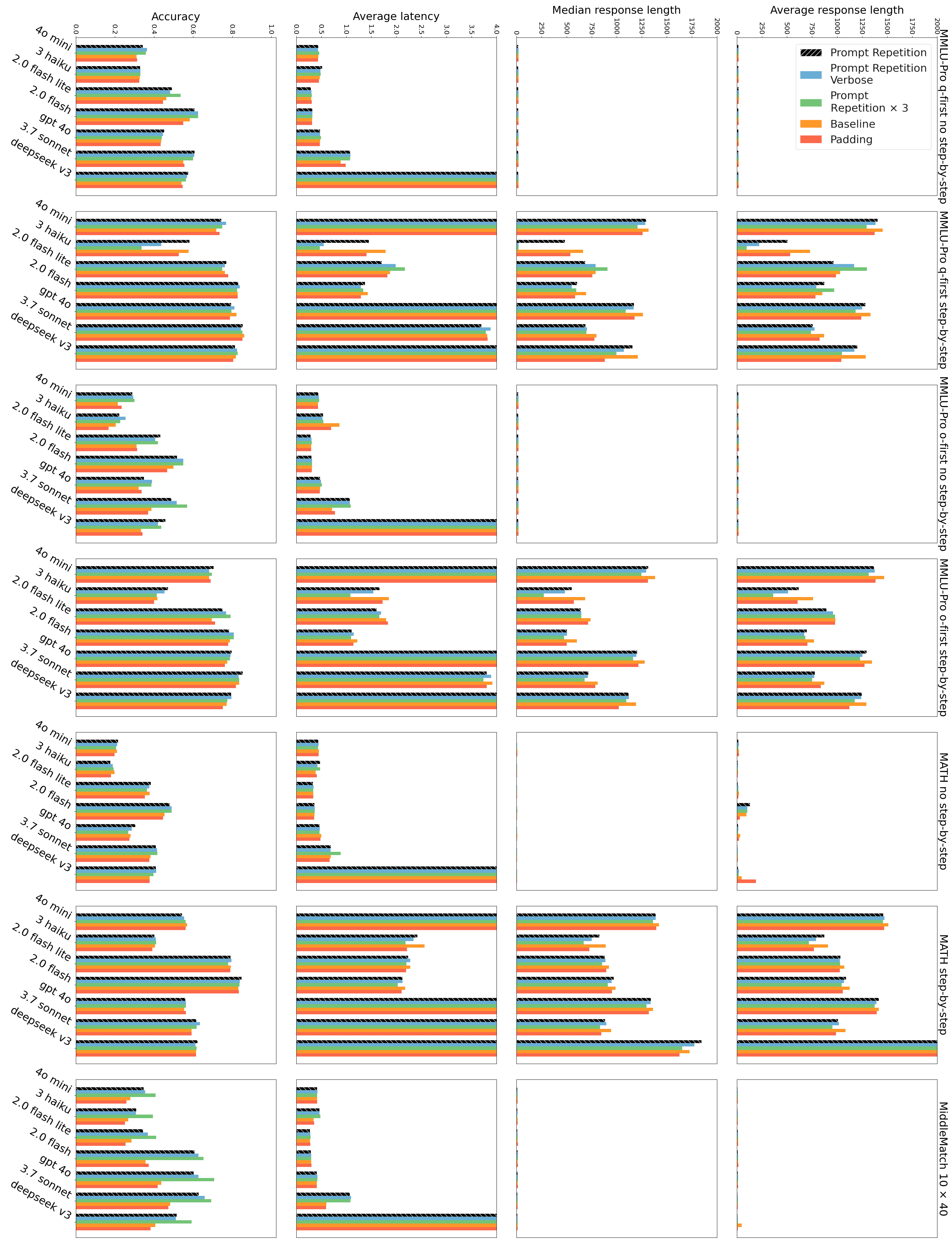
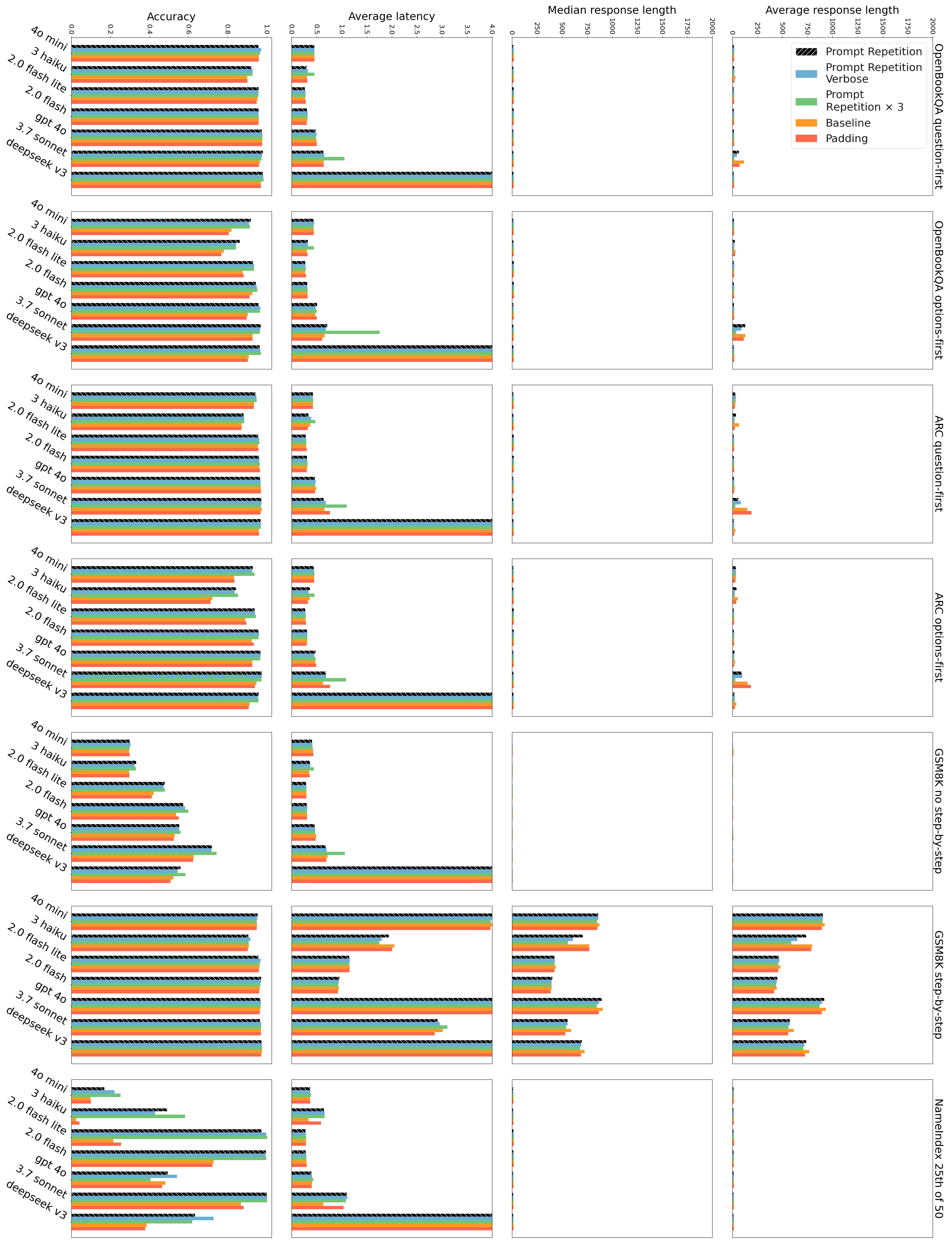
Ablations and variations. We compare prompt repetition to 2 additional variants: Prompt Repetition (Verbose) and Prompt Repetition ×3 (Appendix A.4). We observe that they perform similarly for most tasks and models (Figures 2 and3), and sometimes outperform vanilla prompt repetition. Notably, Prompt Repetition ×3 often substantially outperforms vanilla prompt repetition (which itself substantially outperforms the baseline) on NameIndex and MiddleMatch. It therefore seems worthwhile to further research variants. To demonstrate that the gains are indeed due to repeating the prompt and not to simply increasing the length of the input, we also evaluate the Padding method (Appendix A.4), which pads the inputs with periods (".") to the same length as prompt repetition, and, as expected, does not improve performance.
Efficiency. For each model, prompting method, and dataset, we measure the average and median of the lengths of the generated outputs, as well as the empirical latency 2 . As expected, we observe similar latencies for all datasets and all tested models when reasoning is disabled. With reasoning enabled, all latencies (and the lengths of the generated outputs) are dramatically higher. Either way, in all cases prompt repetition and its variants do not increase the lengths of the generated outputs or the measured latencies (Figures 2 and3), the only exception being the Anthropic models (Claude Haiku and Sonnet) for very long requests (from the NameIndex or MiddleMatch datasets or from the repeat ×3 variant) where the latencies increase (likely due to the prefill stage taking longer).
Many prompting techniques for LLMs have been suggested, notably Chain of Thought (CoT) prompting [Wei et al., 2023] (which requires specific examples per task) and “Think step by step” [Kojima et al., 2023], which achieves substantial improvements, but increases the lengths of the generated outputs and thus the latency and compute requirements (we show that it can be used in tandem with prompt repetition, yielding mostly neutral results). More recently and independently, Shaier [2024] experimented with repeating just the question part of the prompt and found that it yields no gains, Springer et al. [2024] showed that repeating the input twice yields better text embeddings, and Xu et al. [2024] showed that asking the model to re-read the question improves reasoning.
We show that repeating
📸 Image Gallery