📝 Original Info Title: Imitation Game: Reproducing Deep Learning Bugs Leveraging an Intelligent AgentArXiv ID: 2512.14990Date: 2025-12-17Authors: - Mehil B. Shah (Dalhousie University, Halifax, Canada) – shahmehil@dal.ca - Mohammad Masudur Rahman (Dalhousie University, Halifax, Canada) – masud.rahman@dal.ca - Foutse Khomh (Polytechnique Montreal, Montreal, Canada) – foutse.khomh@polymtl.ca 📝 Abstract Despite their wide adoption in various domains (e.g., healthcare, finance, software engineering), Deep Learning (DL)-based applications suffer from many bugs, failures, and vulnerabilities. Reproducing these bugs is essential for their resolution, but it is extremely challenging due to the inherent nondeterminism of DL models and their tight coupling with hardware and software environments. According to recent studies, only about 3% of DL bugs can be reliably reproduced using manual approaches. To address these challenges, we present RepGen, a novel, automated, and intelligent approach for reproducing deep learning bugs. RepGen constructs a learningenhanced context from a project, develops a comprehensive plan for bug reproduction, employs an iterative generate-validate-refine mechanism, and thus generates such code using an LLM that reproduces the bug at hand. We evaluate RepGen on 106 real-world deep learning bugs and achieve a reproduction rate of 80.19%, a 19.81% improvement over the state-of-the-art measure. A developer study involving 27 participants shows that RepGen improves the success rate of DL bug reproduction by 23.35%, reduces the time to reproduce by 56.8%, and lowers participants' cognitive load.
CCS Concepts • Software and its engineering → Software testing and debugging.
💡 Deep Analysis
📄 Full Content Imitation Game: Reproducing Deep Learning Bugs Leveraging an
Intelligent Agent
Mehil B Shah
Dalhousie University
Halifax, Canada
shahmehil@dal.ca
Mohammad Masudur Rahman
Dalhousie University
Halifax, Canada
masud.rahman@dal.ca
Foutse Khomh
Polytechnique Montreal
Montreal, Canada
foutse.khomh@polymtl.ca
Abstract
Despite their wide adoption in various domains (e.g., healthcare,
finance, software engineering), Deep Learning (DL)-based applica-
tions suffer from many bugs, failures, and vulnerabilities. Reproduc-
ing these bugs is essential for their resolution, but it is extremely
challenging due to the inherent nondeterminism of DL models and
their tight coupling with hardware and software environments. Ac-
cording to recent studies, only about 3% of DL bugs can be reliably
reproduced using manual approaches. To address these challenges,
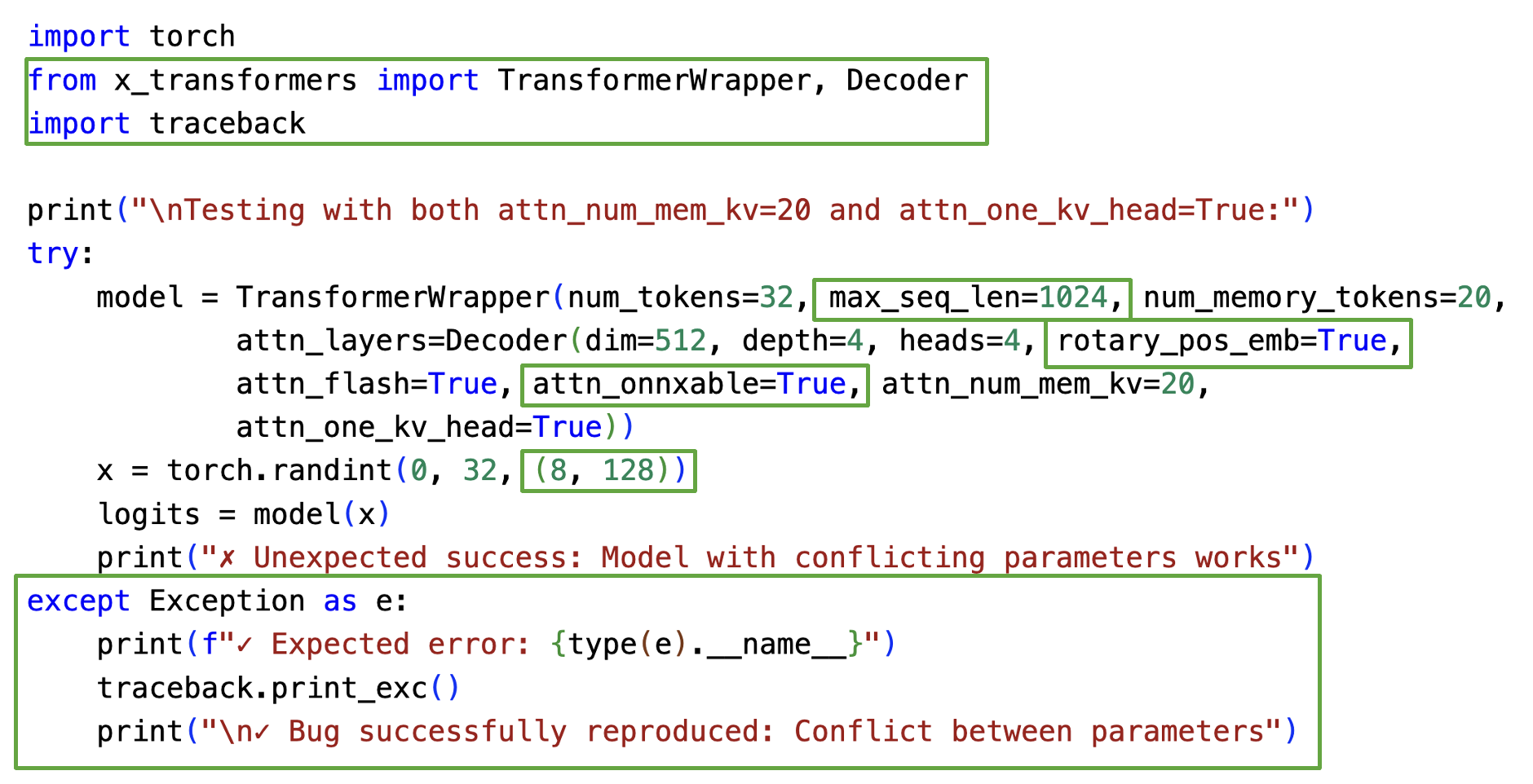
we present RepGen, a novel, automated, and intelligent approach
for reproducing deep learning bugs. RepGen constructs a learning-
enhanced context from a project, develops a comprehensive plan
for bug reproduction, employs an iterative generate-validate-refine
mechanism, and thus generates such code using an LLM that re-
produces the bug at hand. We evaluate RepGen on 106 real-world
deep learning bugs and achieve a reproduction rate of 80.19%, a
19.81% improvement over the state-of-the-art measure. A developer
study involving 27 participants shows that RepGen improves the
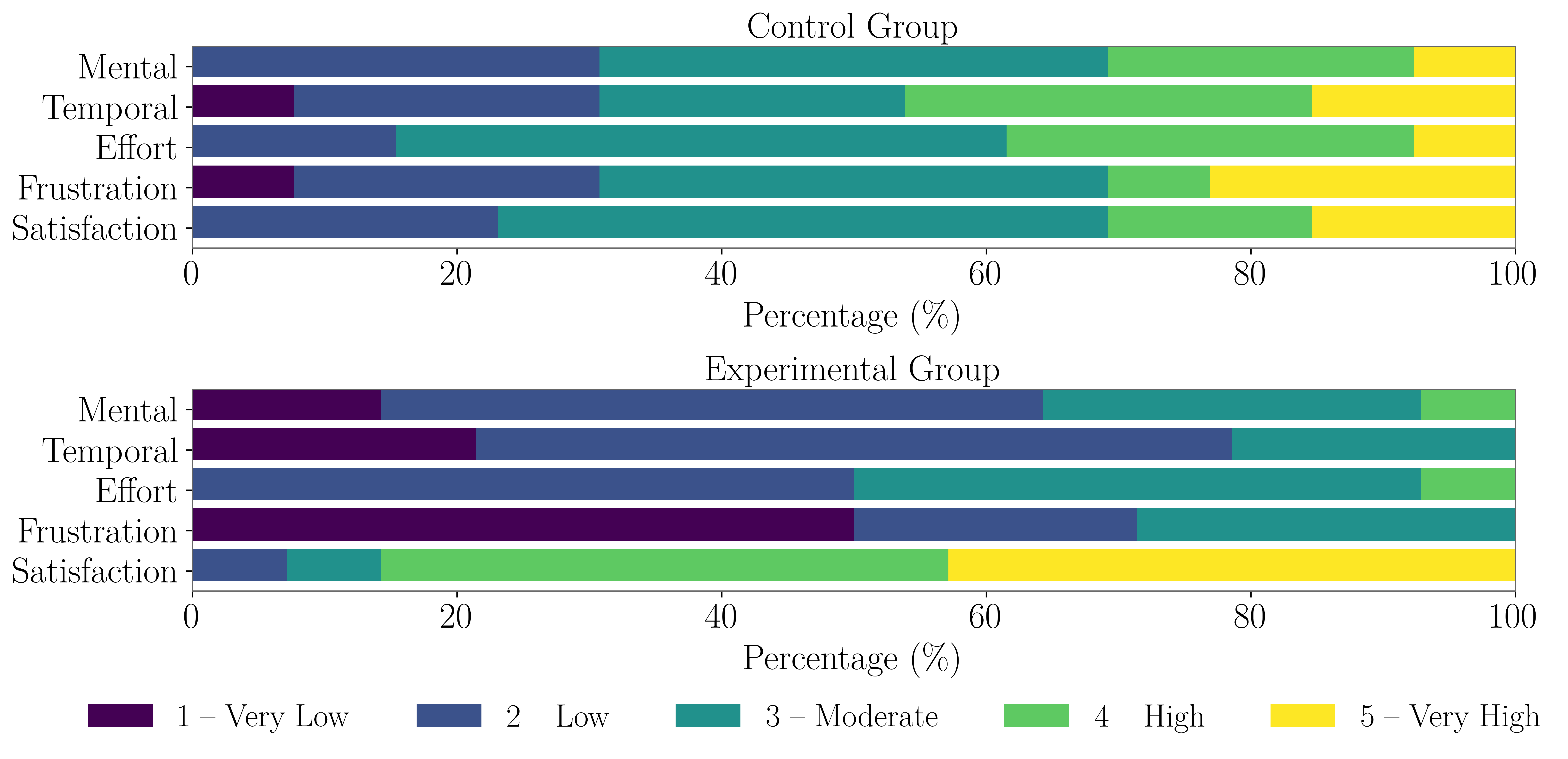
success rate of DL bug reproduction by 23.35%, reduces the time to
reproduce by 56.8%, and lowers participants’ cognitive load.
CCS Concepts
• Software and its engineering →Software testing and debug-
ging.
Keywords
Deep learning bugs, deep learning bug reproduction, automated de-
bugging, LLM-powered agents, code generation, machine learning
systems, software testing and debugging
ACM Reference Format:
Mehil B Shah, Mohammad Masudur Rahman, and Foutse Khomh. 2026.
Imitation Game: Reproducing Deep Learning Bugs Leveraging an Intelli-
gent Agent. In 2026 IEEE/ACM 48th International Conference on Software
Engineering (ICSE ’26), April 12–18, 2026, Rio de Janeiro, Brazil. ACM, New
York, NY, USA, 13 pages. https://doi.org/10.1145/3744916.3787795
1
Introduction
Artificial Intelligence (AI) has been widely adopted in many applica-
tion domains, including software engineering [45, 46], autonomous
vehicles [27], healthcare [64], finance [10], and cybersecurity [16].
This work is licensed under a Creative Commons Attribution-NonCommercial-
NoDerivatives 4.0 International License.
ICSE ’26, Rio de Janeiro, Brazil
© 2026 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-2025-3/2026/04
https://doi.org/10.1145/3744916.3787795
The global market share of AI software reached $34.8 billion in 2023
and is projected to grow up to $360 billion by 2030 [26]. Over 67% of
top-performing companies have incorporated AI in their business
solutions, and 97% of Fortune 500 companies have invested in AI
technologies [58], indicating their significance. However, software
applications empowered by Deep Learning (DL), the underlying
technology behind current AI systems, remain prone to bugs, faults,
and vulnerabilities, which could lead to major consequences (e.g.,
system crashes) and catastrophic failures (e.g., autonomous vehicle
accidents) [69]. Unlike the bugs in traditional, developer-written
software, the bugs in DL software are inherently challenging due
to several factors. First, they are often non-deterministic due to ran-
domness in model training, i.e., random weight initialization of the
model layers [52]. Second, DL models perform high-dimensional
tensor operations and suffer from a lack of interpretability, making
their encountered bugs opaque [46]. Finally, these bugs also have
multi-faceted dependencies on hardware (e.g., GPU), underlying
frameworks (e.g., PyTorch, TensorFlow) [81], and data pipelines,
making them highly complex [62].
To resolve DL bugs, software developers must first systematically
reproduce them on their local machines. Without a reproduction,
they cannot confirm the presence of a bug or diagnose its root cause.
However, reproduction of DL bugs can be effort-intensive, time-
consuming, and frustrating due to various technical challenges.
They include intricate data pipelines, hardware dependencies, and
variations in software frameworks and library versions. Even when
a bug is reproducible, developers frequently need to engage in
trial-and-error, carefully tune environmental settings, and reason
about the contextual factors that may influence the behaviour of
DL programs, all of which can be tedious and error-prone [54].
Developers also face the challenge of missing or incomplete infor-
mation when attempting to reproduce bugs from issue reports [71].
Reports may lack crucial details of a bug and omit relevant data
or code snippets. In such cases, even experienced developers must
spend substantial time reconstructing the missing detail of a bug,
the target environment, and iteratively testing hypo
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.