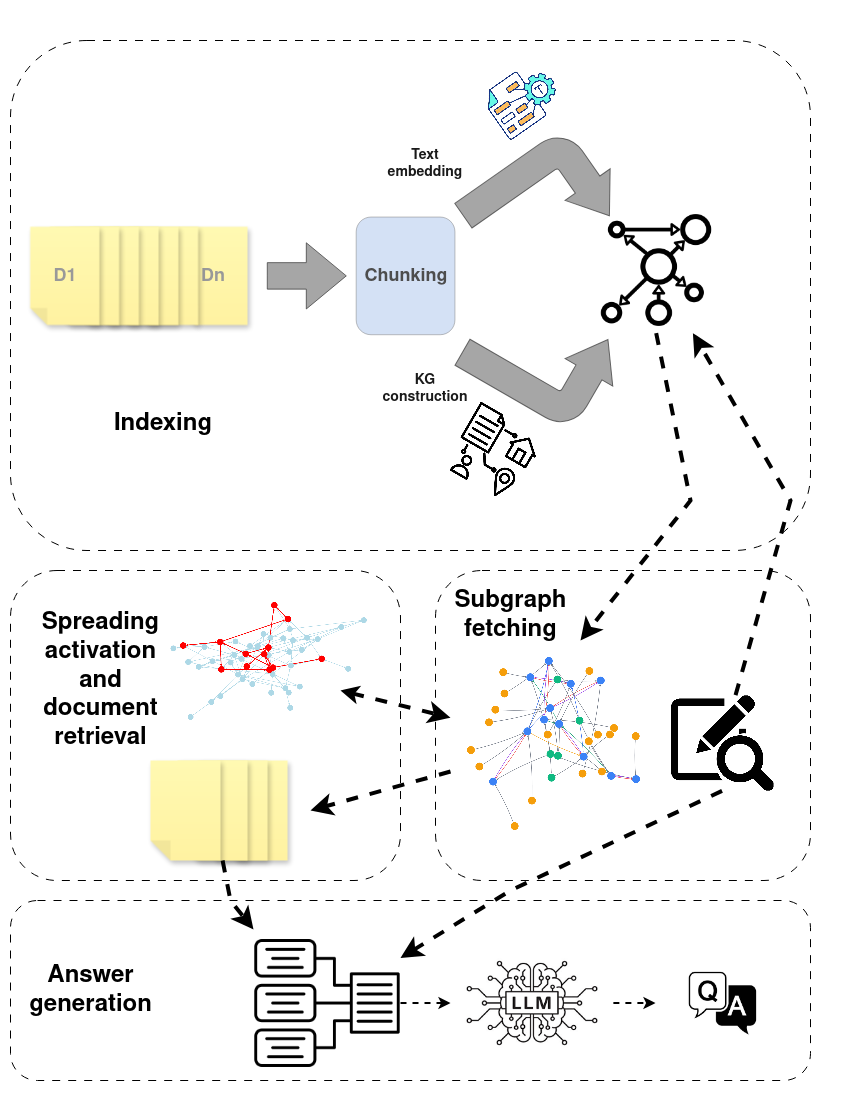
Despite initial successes and a variety of architectures, retrieval-augmented generation systems still struggle to reliably retrieve and connect the multi-step evidence required for complicated reasoning tasks. Most of the standard RAG frameworks regard all retrieved information as equally reliable, overlooking the varying credibility and interconnected nature of large textual corpora. GraphRAG approaches offer potential improvement to RAG systems by integrating knowledge graphs, which structure information into nodes and edges, capture entity relationships, and enable multi-step logical traversal. However, GraphRAG is not always an ideal solution, as it depends on high-quality graph representations of the corpus. Such representations usually rely on manually curated knowledge graphs, which are costly to construct and update, or on automated graph-construction pipelines that are often unreliable. Moreover, systems following this paradigm typically use large language models to guide graph traversal and evidence retrieval. In this paper, we propose a novel RAG framework that uses a spreading activation algorithm to retrieve information from a corpus of documents connected by an automatically constructed heterogeneous knowledge graph. This approach reduces reliance on semantic knowledge graphs, which are often incomplete due to information loss during information extraction, avoids LLM-guided graph traversal, and improves performance on multi-hop question answering. Experiments show that our method achieves better or comparable performance to several state-of-the-art RAG methods and can be integrated as a plug-and-play module with different iterative RAG pipelines. When combined with chain-of-thought iterative retrieval, it yields up to a 39% absolute improvement in answer correctness over naive RAG, while achieving these results with small open-weight language models.
Initially proposed in [1,2], Retrieval-Augmented Generation (RAG) has become a popular technique for improving the capabilities of Large Language Models (LLMs) across various tasks, including question answering and code generation. The basic idea of RAG is to provide LLM access to an external, easily updatable knowledge source by integrating it with the Information Retrieval (IR) component. This technique aims to improve the quality of LLM responses by reducing hallucinations and enhancing text creation accuracy and coherence. Numerous enhancements to the foundational RAG paradigm have been further proposed, ranging from innovative pipeline designs to improvements in individual components. Additionally, several surveys have been conducted to classify, decompose, and identify key elements within the myriad of proposed methodologies, helping track their evolution and highlighting promising future directions [3,4,5,6].
A particularly active research area explores the combination of RAG with graph-based systems that represent diversified and relational information. The goal of these integrations is to improve performance on complex tasks involving large, structured, and interconnected knowledge corpora, resulting in methodologies sometimes referred to as GraphRAG. Comprehensive surveys covering the background, components, downstream tasks, and industrial use cases of GraphRAG, as well as the technologies and evaluation methods used, are available in [7,8].
As mentioned in [7], knowledge graph question answering (KGQA) is a key natural language processing task that has motivated the development of KG-based systems aimed at responding to user queries through structured reasoning over predefined knowledge graphs [9,10,11]. The multi-hop question answering (MHQA) task is a related but broader concept, commonly applied in areas such as academic research, customer support, and financial or legal inquiries, where a comprehensive analysis of multiple textual documents is required. In this scenario, given a document corpus, the QA system generates responses to user queries by reasoning across multiple sources, involving sequential reasoning steps where responses at one step may rely on answers from prior steps. Several standard and graph-based RAG methodologies have been proposed to enhance the performance of LLMs on this specific task [12,13,14,15]. Despite significant advancements, most of these approaches still rely primarily on standard or iterative retrieve-read-answer workflows, which are enhanced by optimized pipeline components, LLM decision-making, or LLM-guided graph traversal [16,4]. However, hallucination and weak faithfulness remain unresolved problems in the context of MHQA. LLM-guided iterative retrieval may fail due to myopic knowledge exploration, retrieving context based on partial reasoning from previous steps, which can be incorrect or contain fabricated information. Similarly, one-step RAG systems with optimized retrieval components may fetch more useful evidence in the retrieved context, but they often introduce a lot of noise or fail to capture information from “bridge” documents whose entities or phrases are not mentioned in the input query. Thus, although adding improvements to vanilla RAG, the paradigm behind these advanced methods stays fundamentally the same, thereby overlooking powerful and well-established IR algorithms that can automatically identify relationships between documents and adapt retrieval for multi-hop query scenarios.
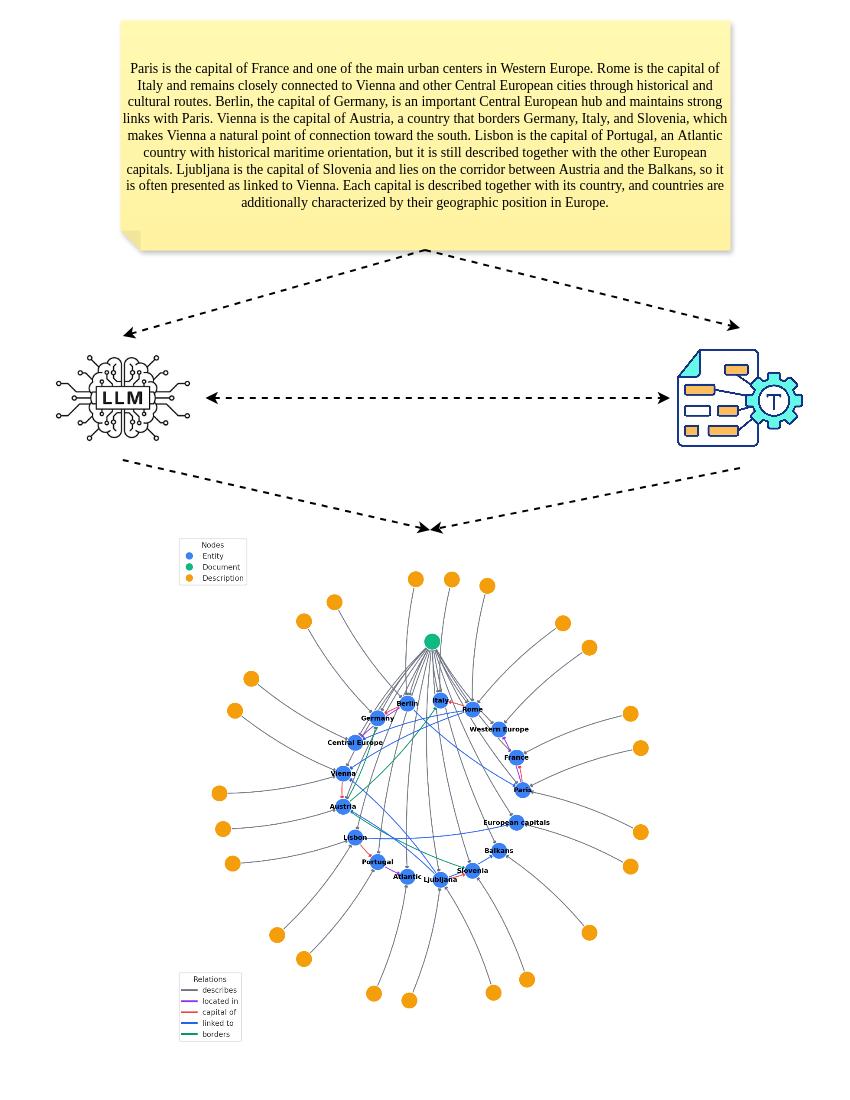
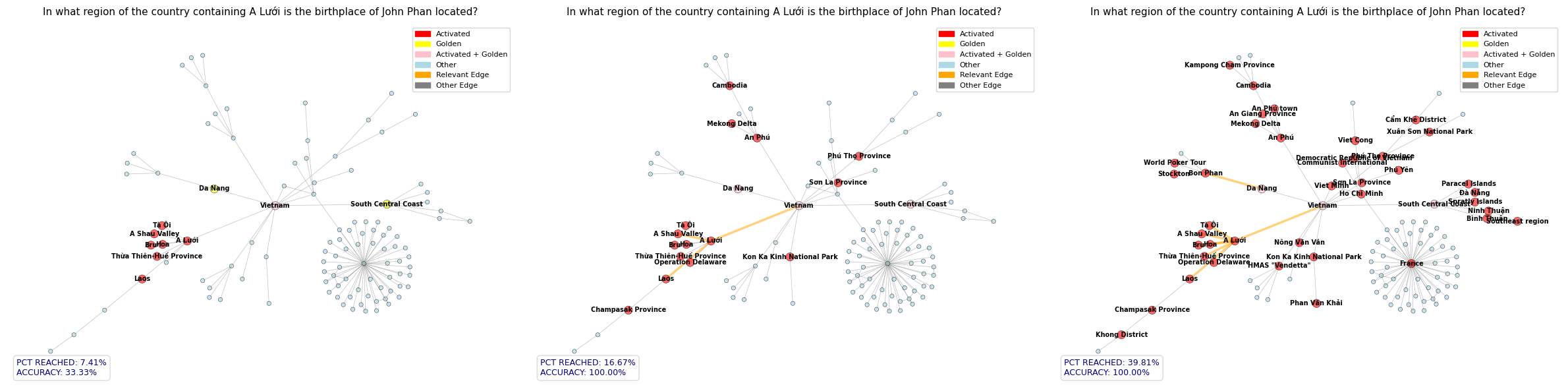
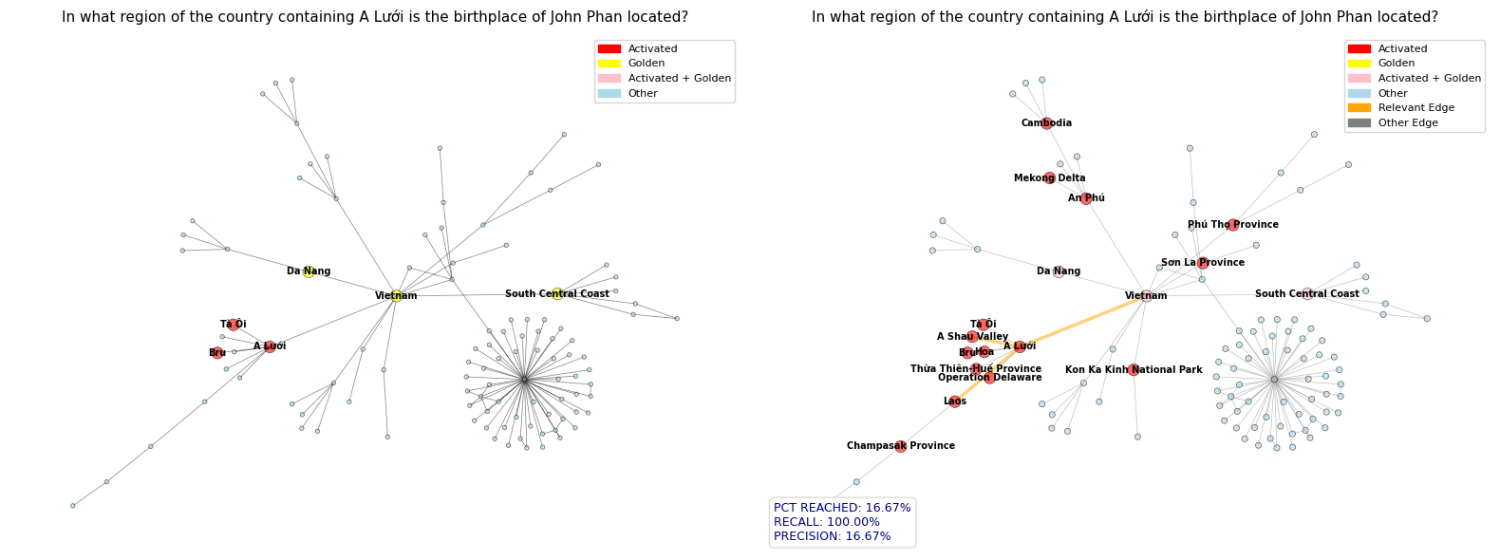
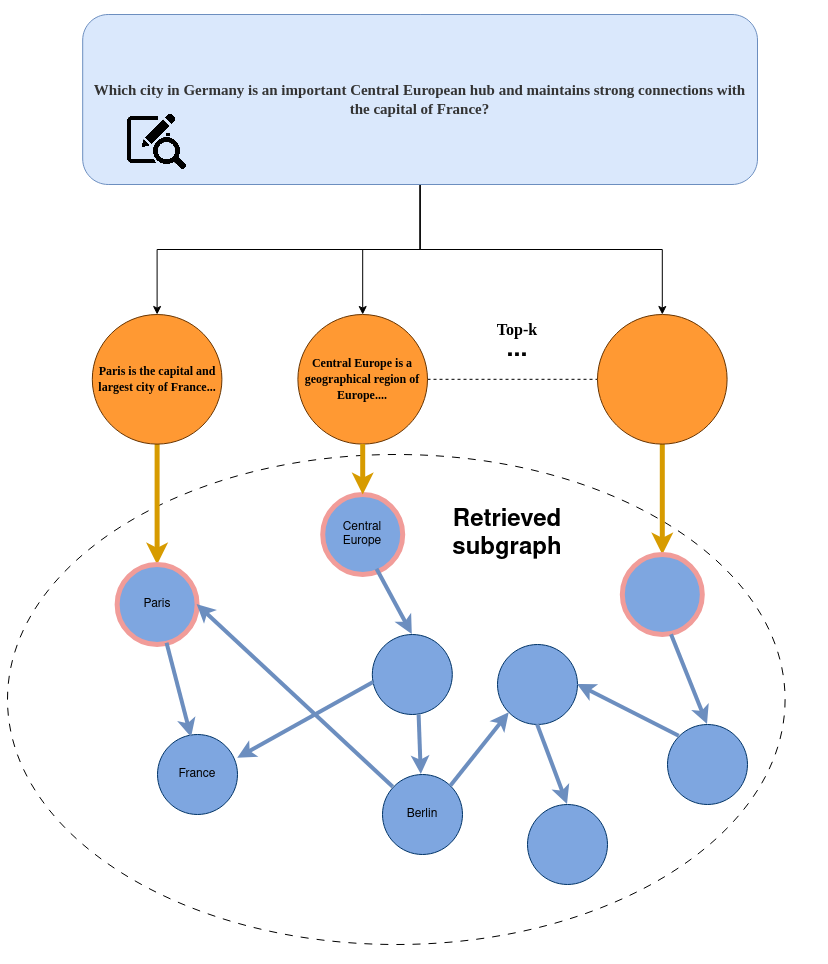
Motivated by this gap, this paper proposes a novel GraphRAG framework that integrates Spreading Activation (SA), a method for searching associative networks originating in cognitive psychology. Beyond information retrieval [17], SA has been successfully applied in several domains, including natural language processing [18,19], robotics, and reinforcement learning [20]. Specifically, we propose a RAG system that operates on a hybrid structure combining a knowledge graph with textual information from knowledge documents. It retrieves relevant documents from textual corpora by executing an SA algorithm through the knowledge graph, identifying and fetching chunks of text with the most pertinent information required to answer the multi-hop query, thereby capturing the reasoning structure and key relationships between entities mentioned in the query.
To the best of our knowledge, only one prior paper has integrated RAG and SA-based methodologies [21]. However, our approach differs in several key respects. First, the mentioned system relies on human-crafted knowledge graphs, whereas our pipeline includes an automated knowledge-graph construction phase. Second, it uses a prompted LLM to perform the SA procedure and expand the initially retrieved subgraph; by contrast, we perform SA automatically by exploring the knowledge graph in a breadth-first manner and spreading the activation based on edge weights assigned by an embedding model. Finally, the prior method fine-
This content is AI-processed based on open access ArXiv data.