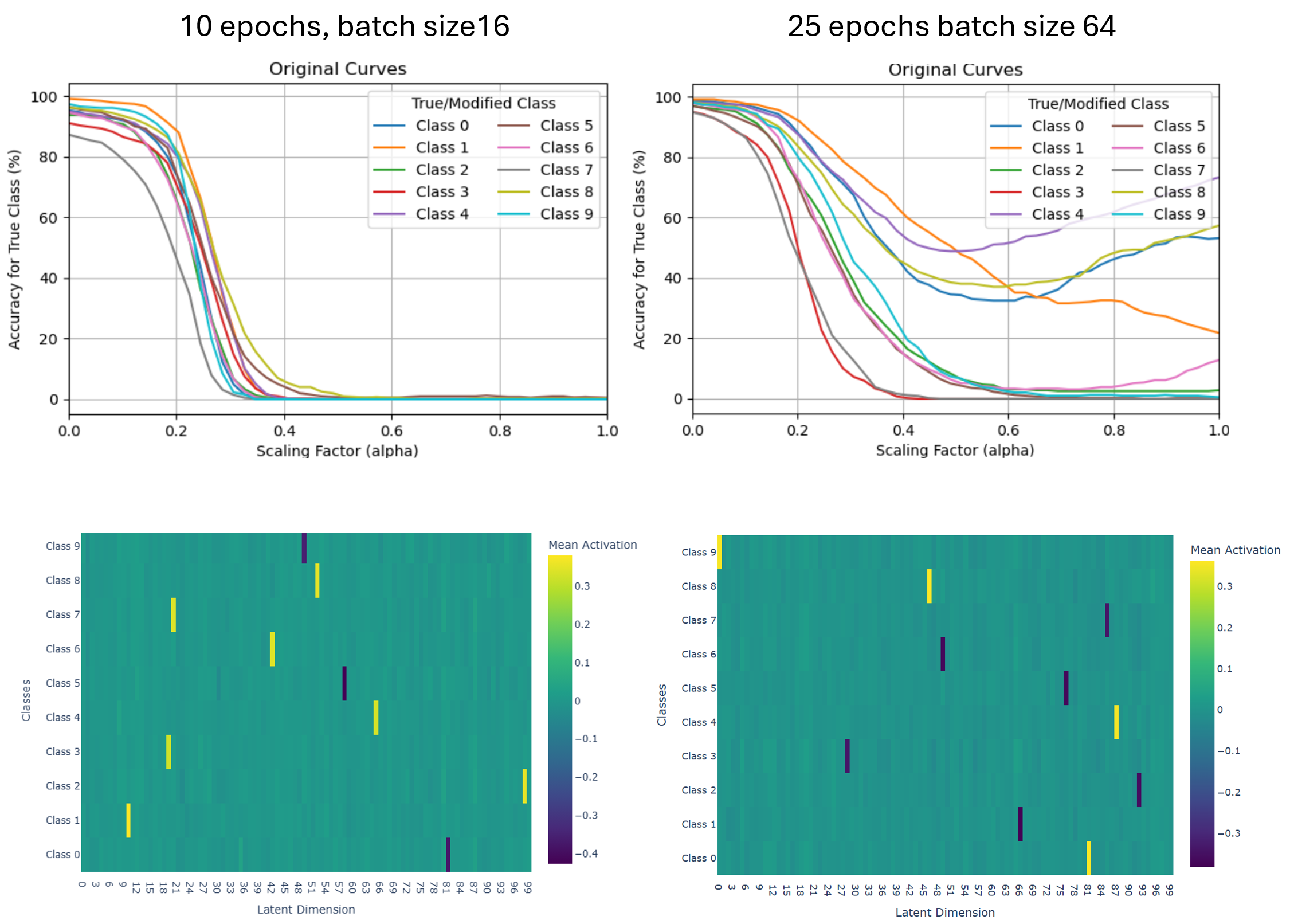
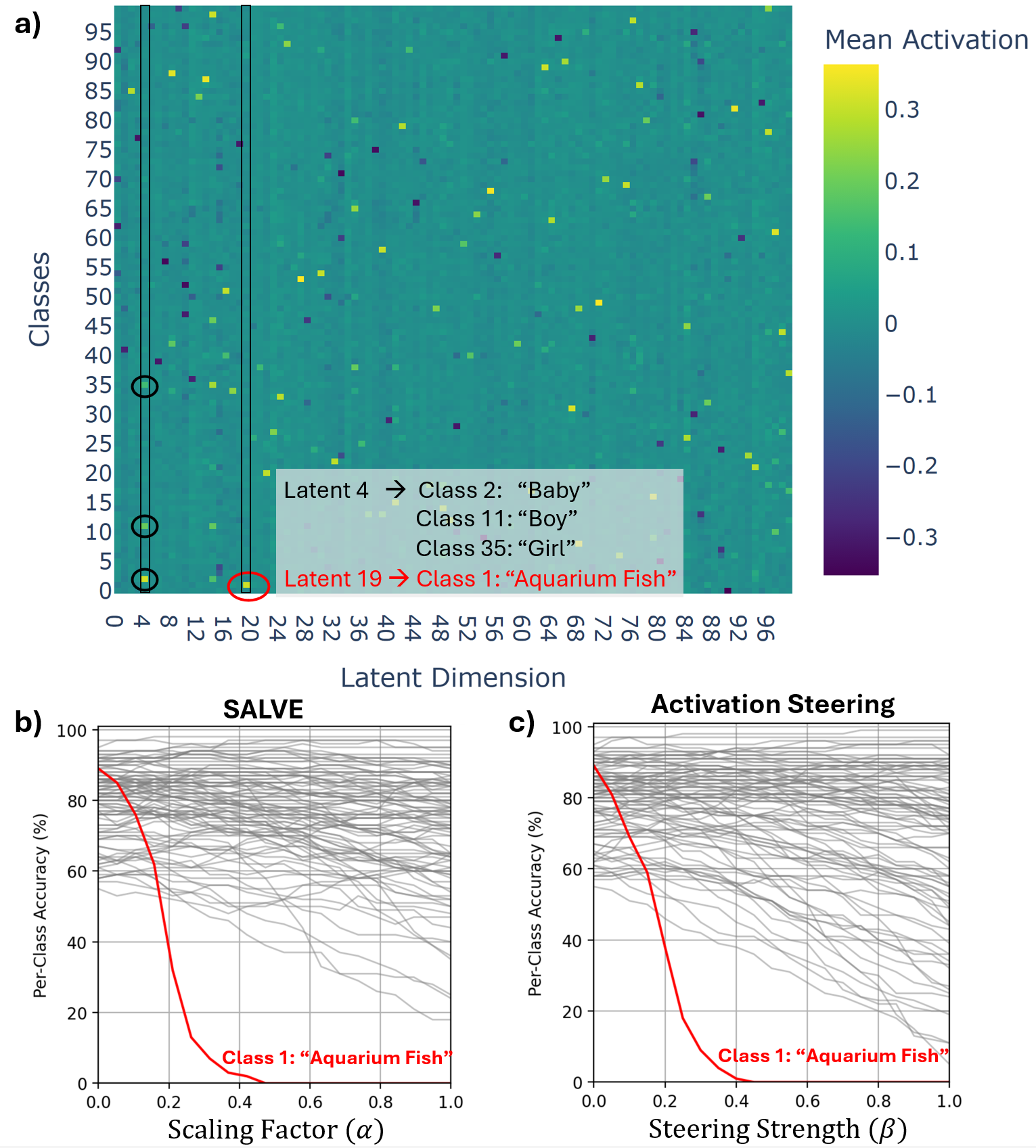
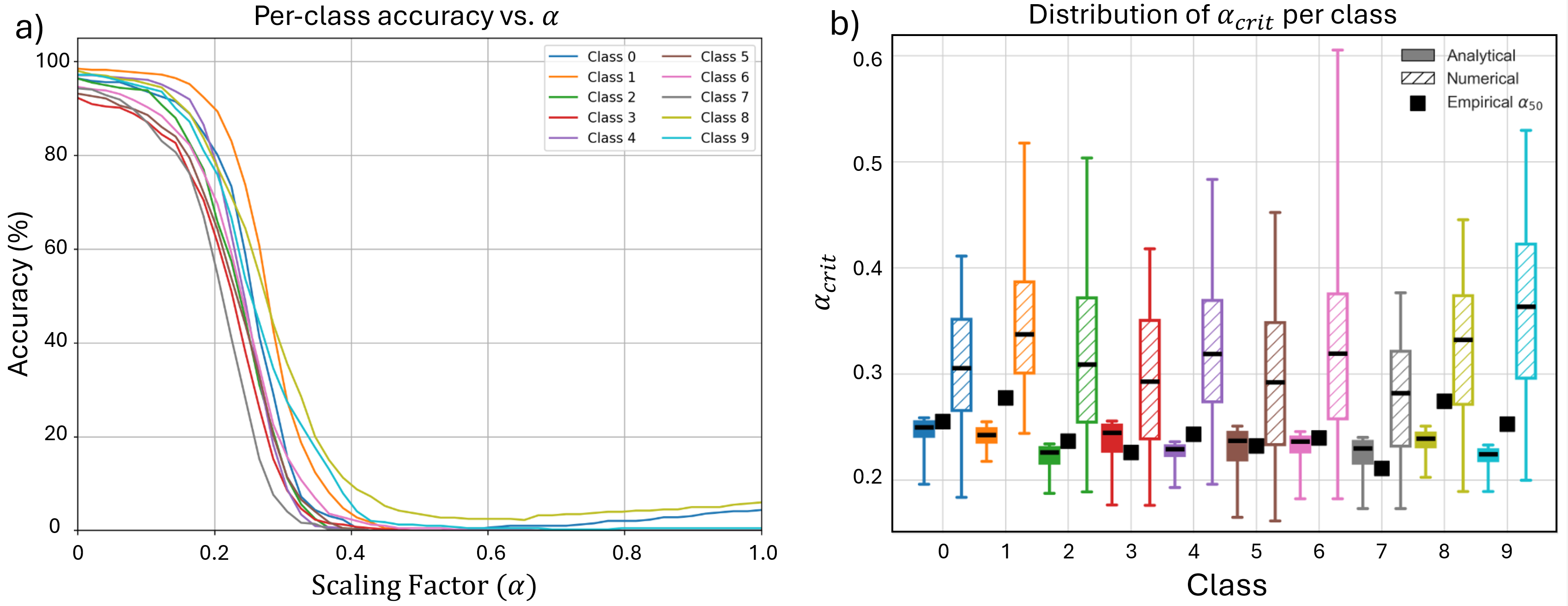
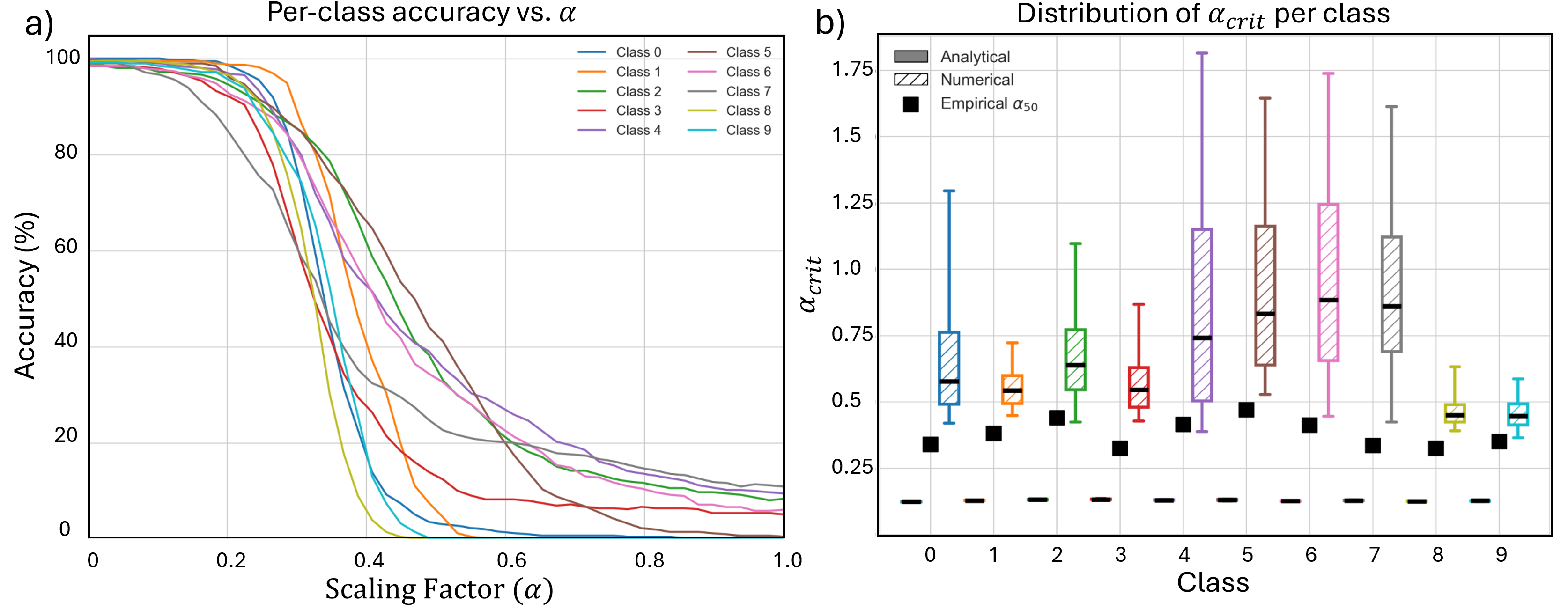
Deep neural networks achieve impressive performance but remain difficult to interpret and control. We present SALVE (Sparse Autoencoder-Latent Vector Editing), a unified "discover, validate, and control" framework that bridges mechanistic interpretability and model editing. Using an $\ell_1$-regularized autoencoder, we learn a sparse, model-native feature basis without supervision. We validate these features with Grad-FAM, a feature-level saliency mapping method that visually grounds latent features in input data. Leveraging the autoencoder's structure, we perform precise and permanent weight-space interventions, enabling continuous modulation of both class-defining and cross-class features. We further derive a critical suppression threshold, $α_{crit}$, quantifying each class's reliance on its dominant feature, supporting fine-grained robustness diagnostics. Our approach is validated on both convolutional (ResNet-18) and transformer-based (ViT-B/16) models, demonstrating consistent, interpretable control over their behavior. This work contributes a principled methodology for turning feature discovery into actionable model edits, advancing the development of transparent and controllable AI systems.
Understanding the internal mechanisms of deep neural networks remains a central challenge in machine learning. While these models achieve remarkable performance, their opacity hinders our ability to trust, debug, and control their decision-making processes, especially in high-stakes applications where reliability is non-negotiable. The field of Mechanistic interpretability aims to resolve these issues by reverse-engineering how networks compute, identifying internal structures that correspond to meaningful concepts and establishing their influence on outputs [4,18,42,1,32] However, the bridge between interpretation and intervention remains a critical frontier. While recent advances in model steering successfully use discovered features to guide temporary, inference-time adjustments, a path toward using these insights to perform durable, permanent edits to a model's weights is less established. This paper closes that gap by introducing SALVE (Sparse Autoencoder-Latent Vector Editing), a unified framework that transforms interpretability insights into direct, permanent model control. We build a bridge from unsupervised feature discovery to fine-grained, post-hoc weight-space editing. Our core contribution is a "discover, validate, and control" pipeline that uses a sparse autoencoder (SAE) to first learn a model's native feature representations and then leverages that same structure to perform precise, continuous interventions on the model's weights.
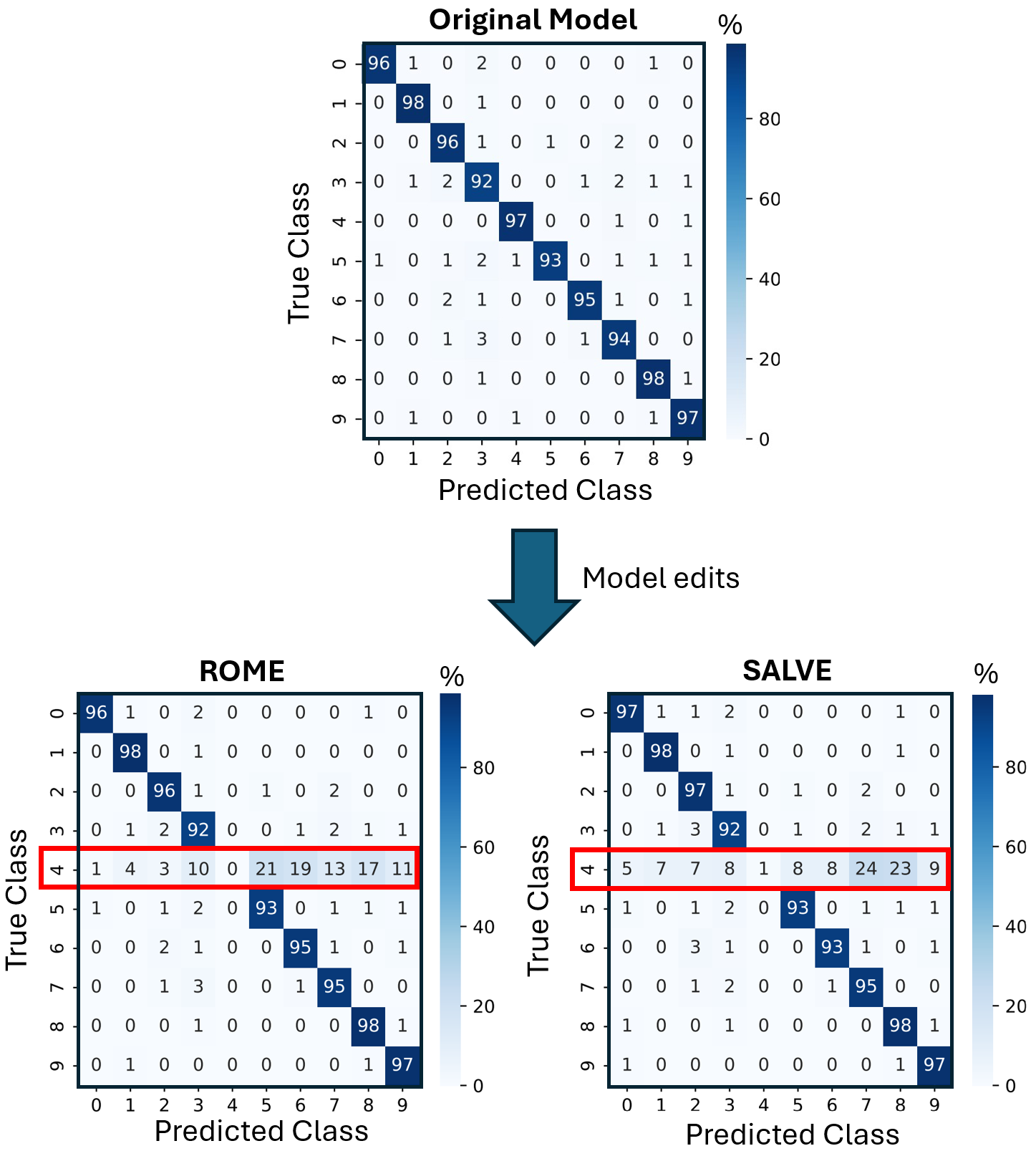
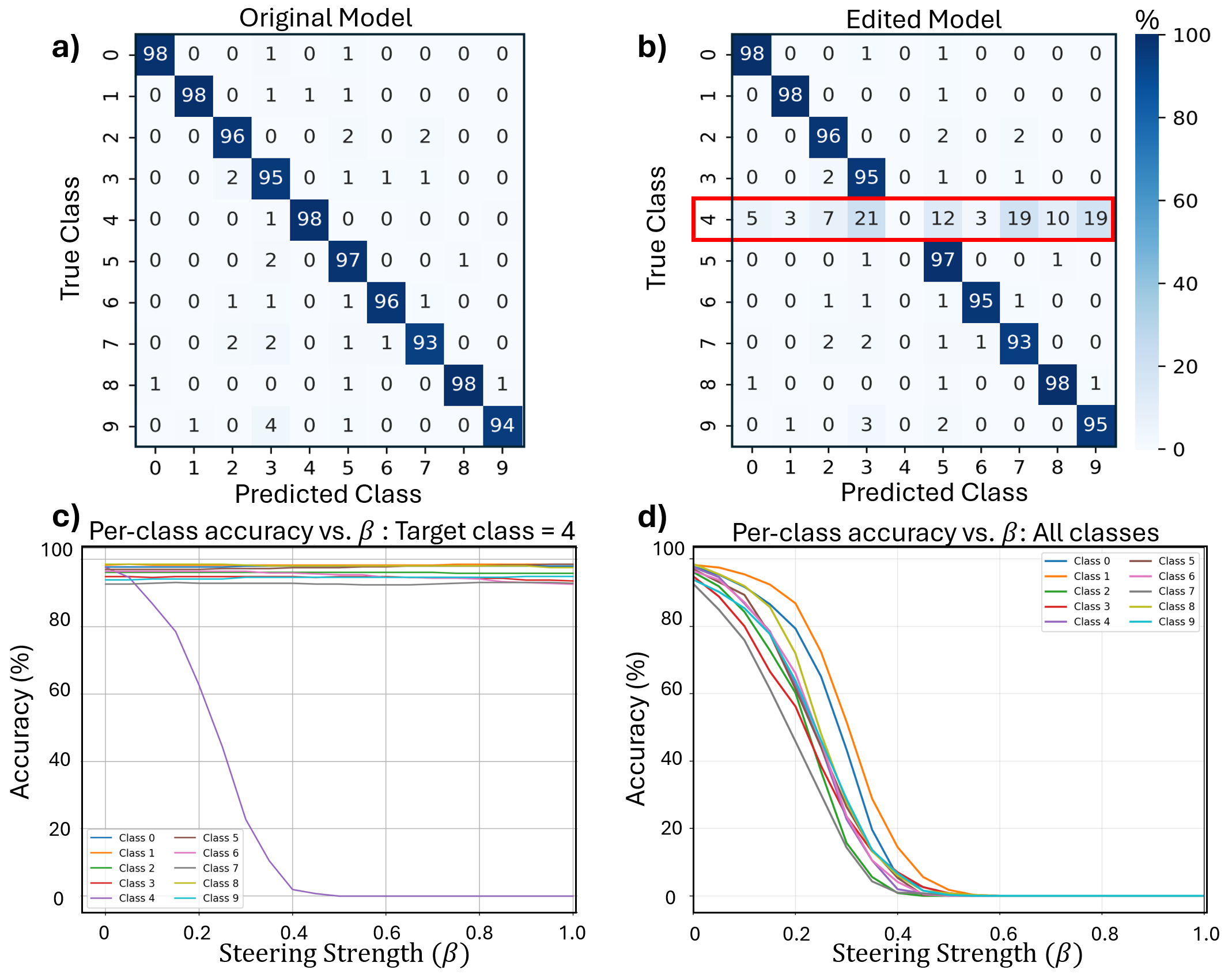
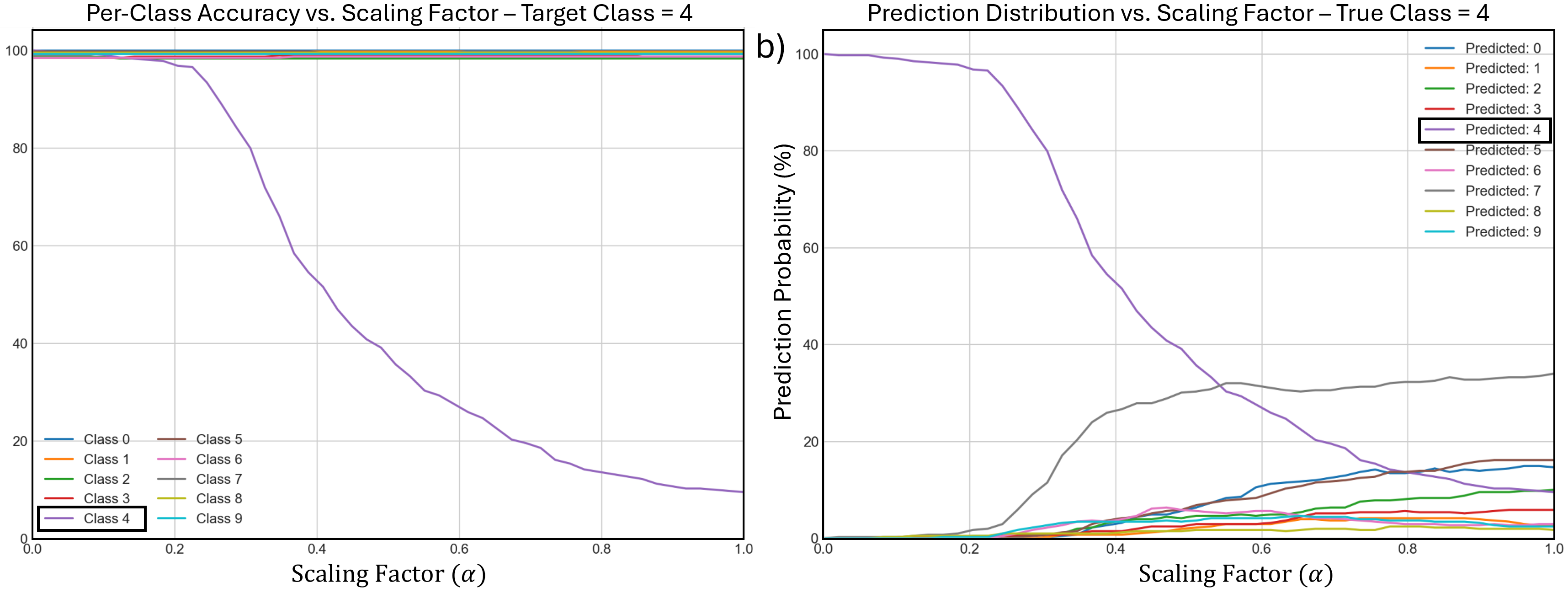
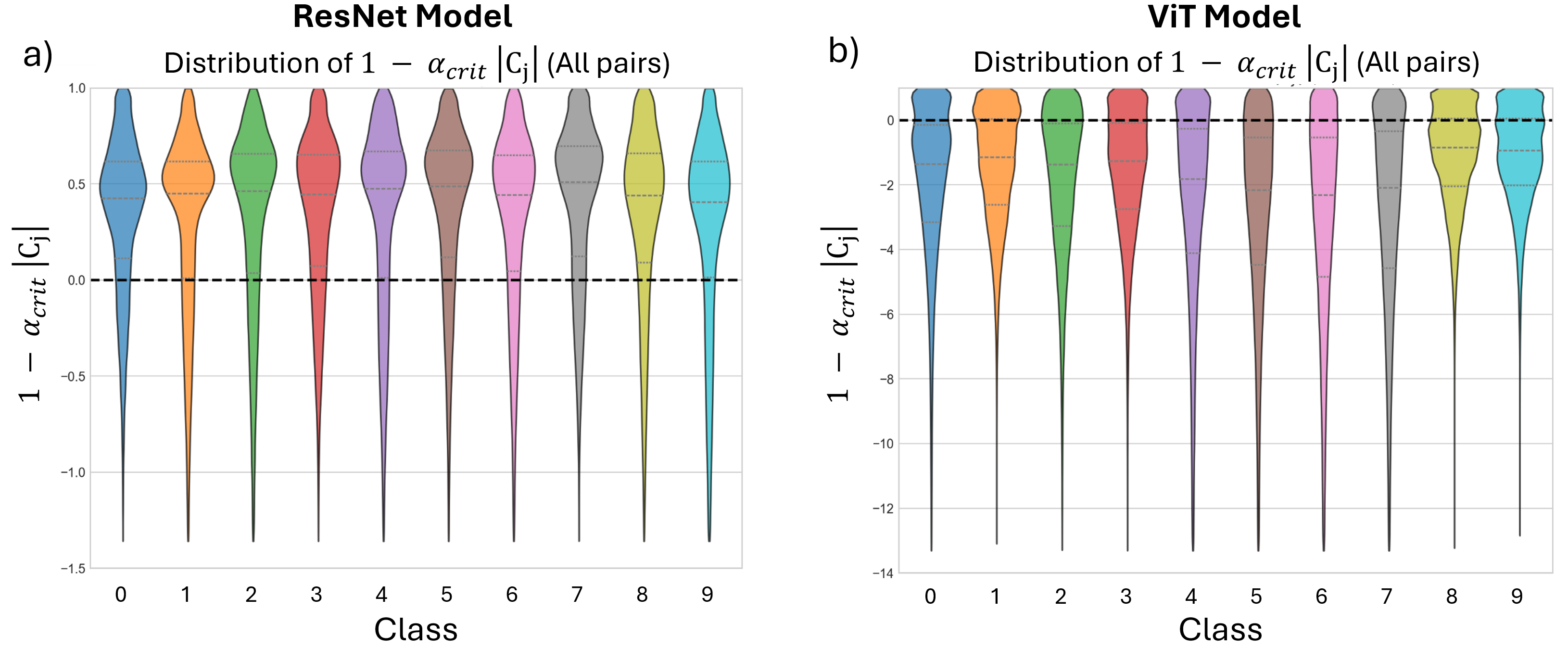
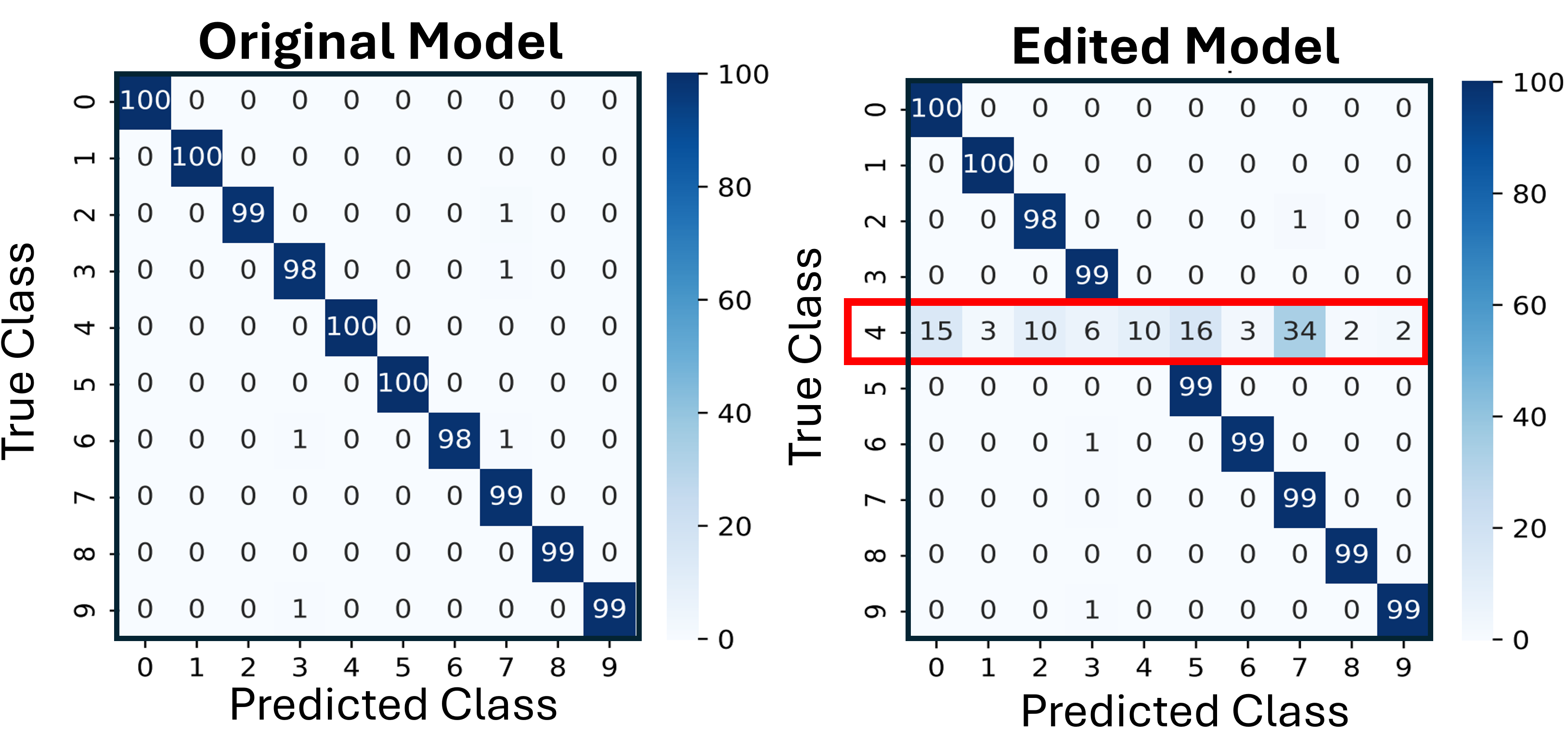
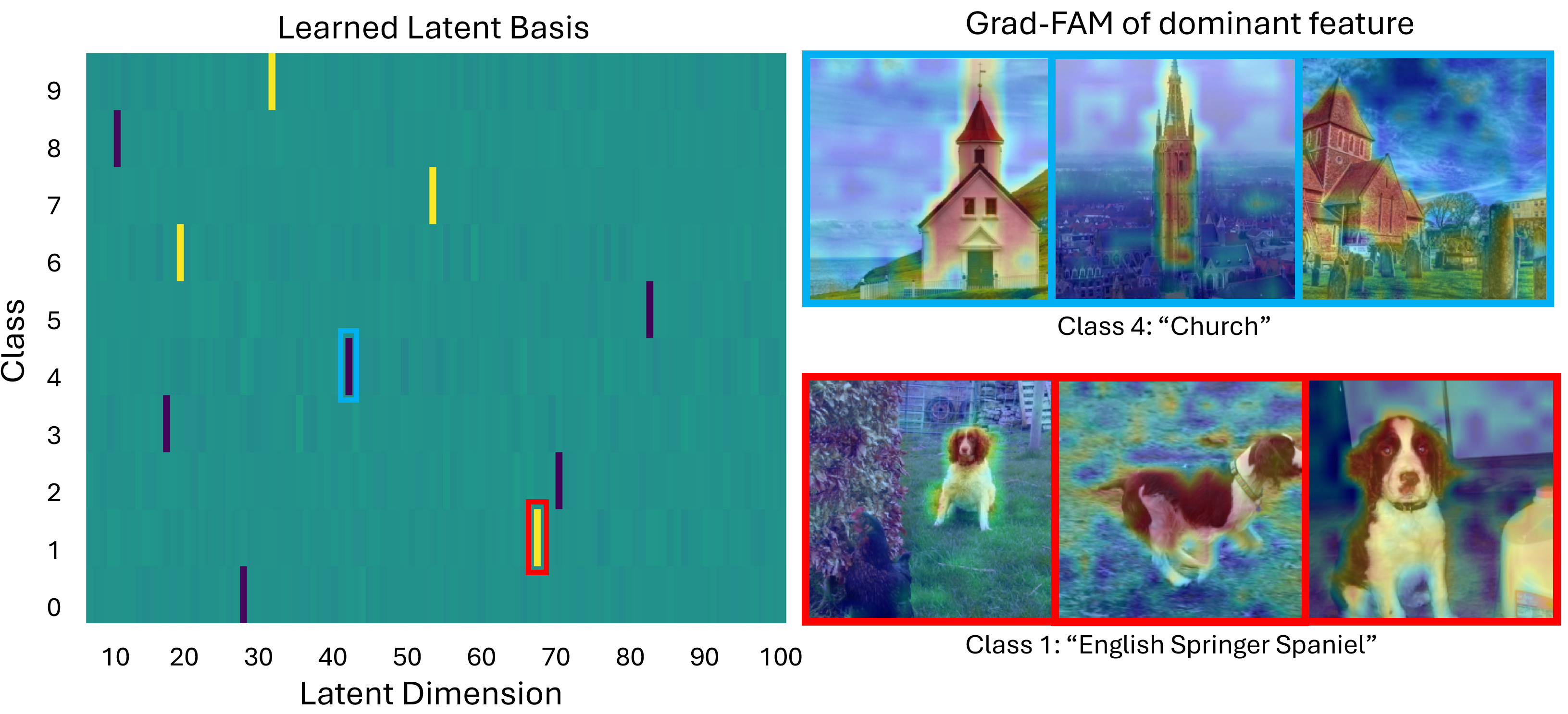
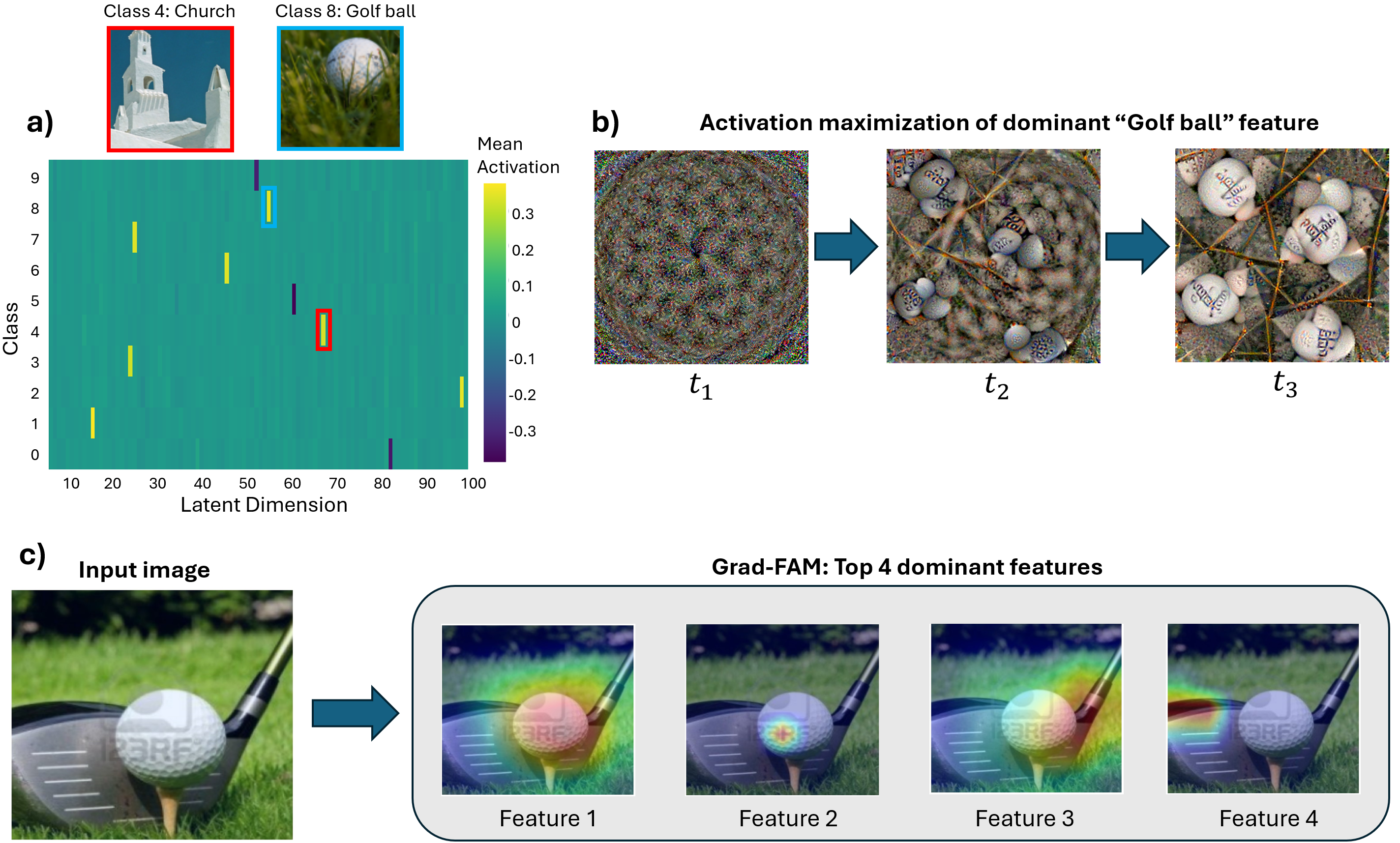
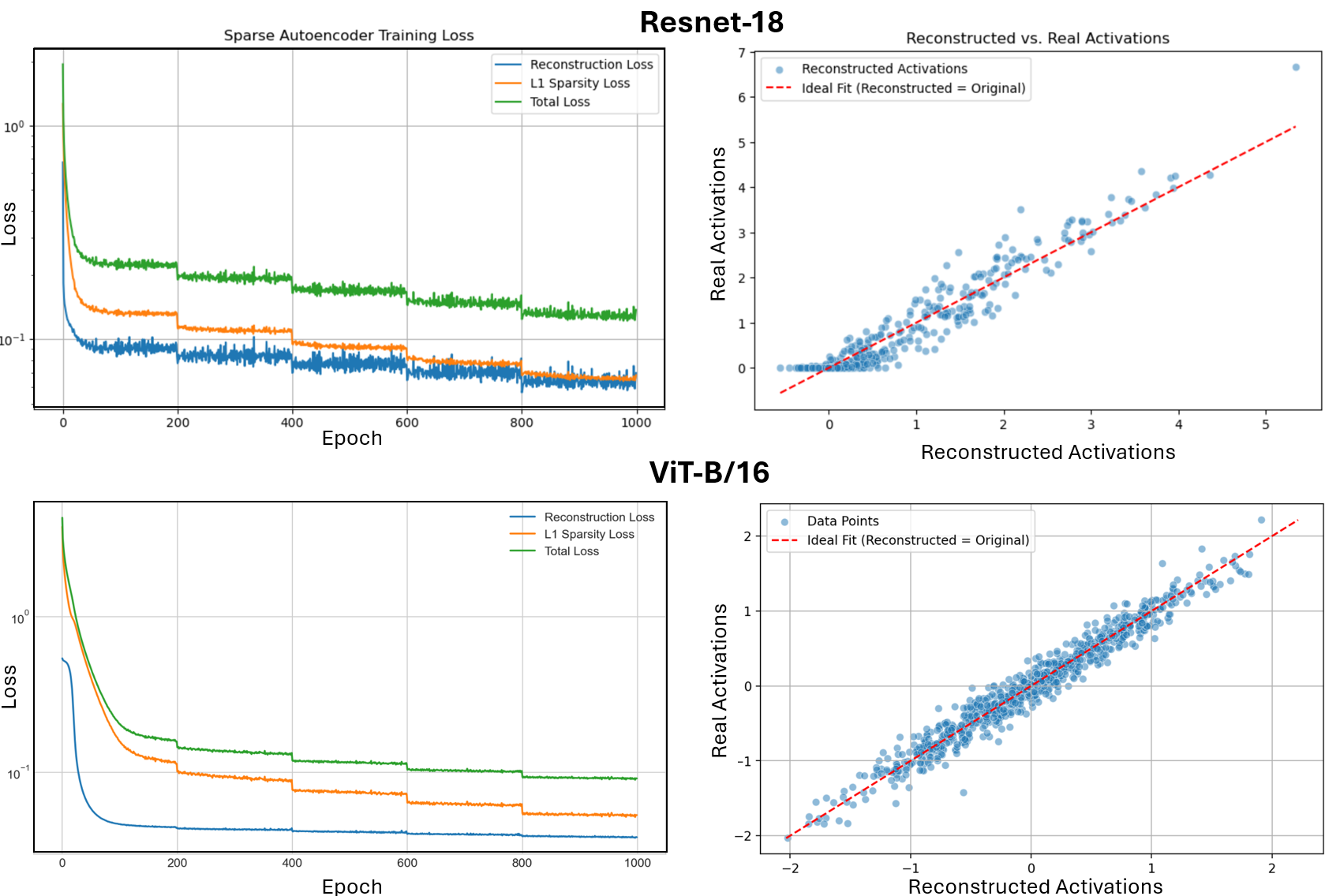
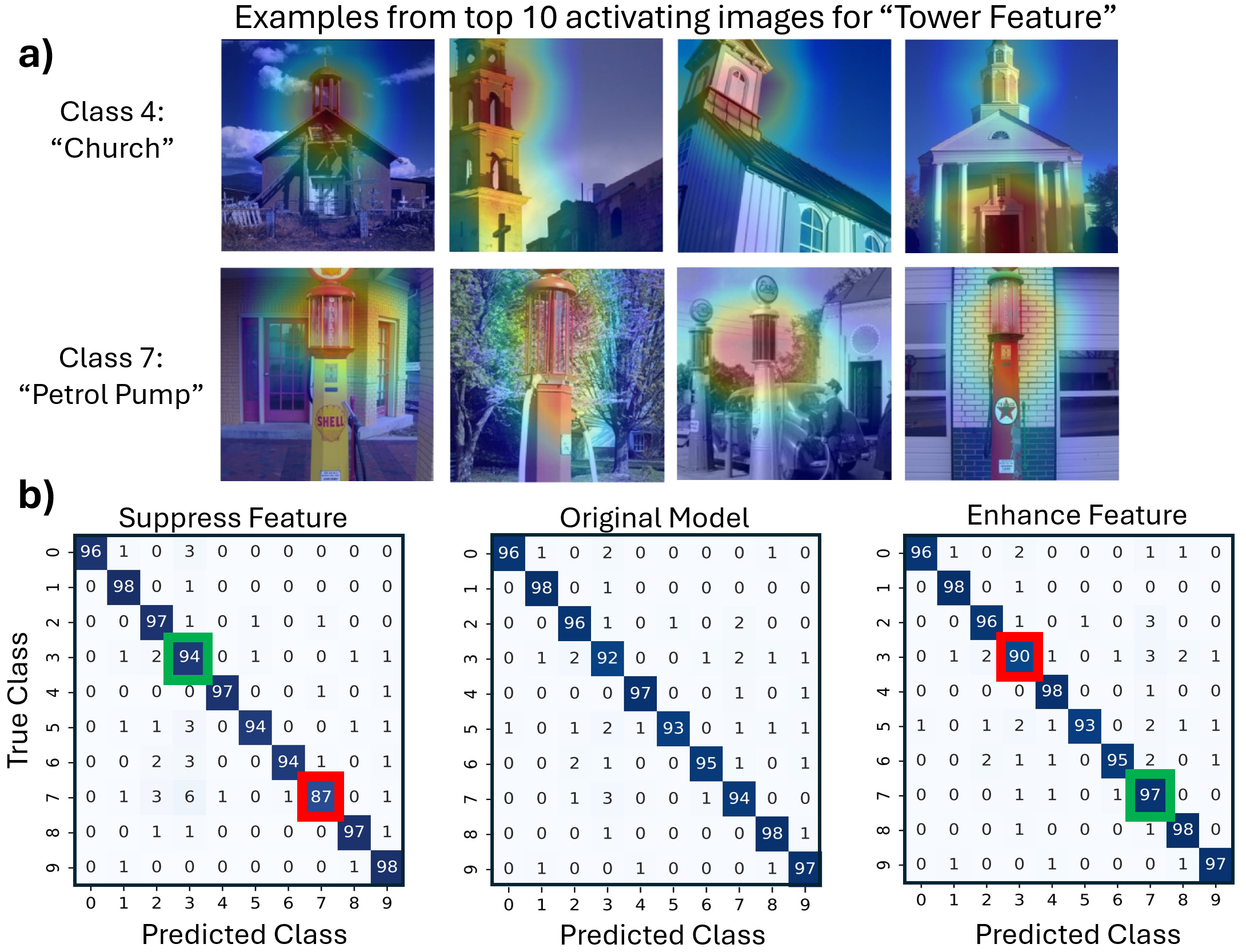
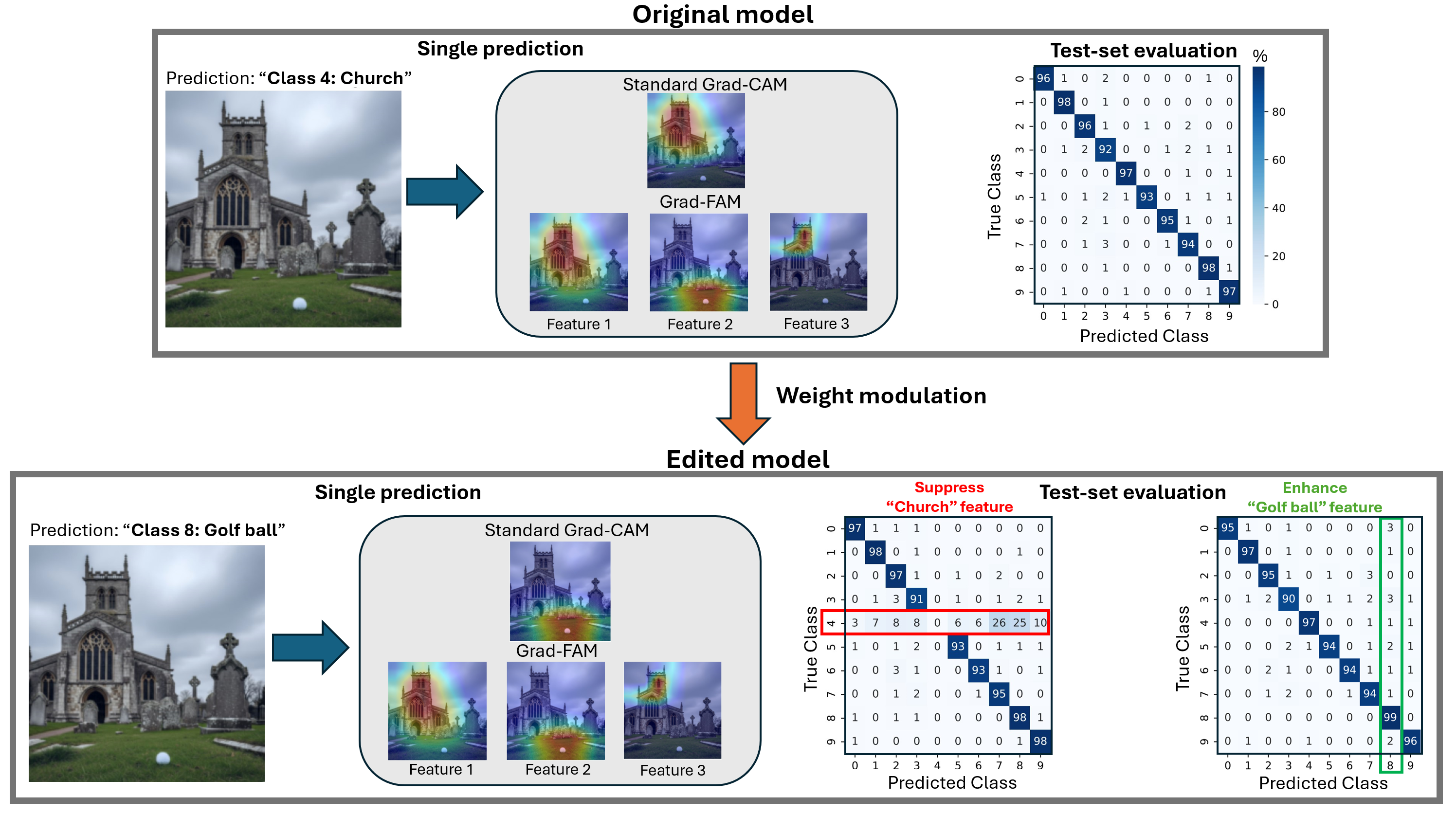
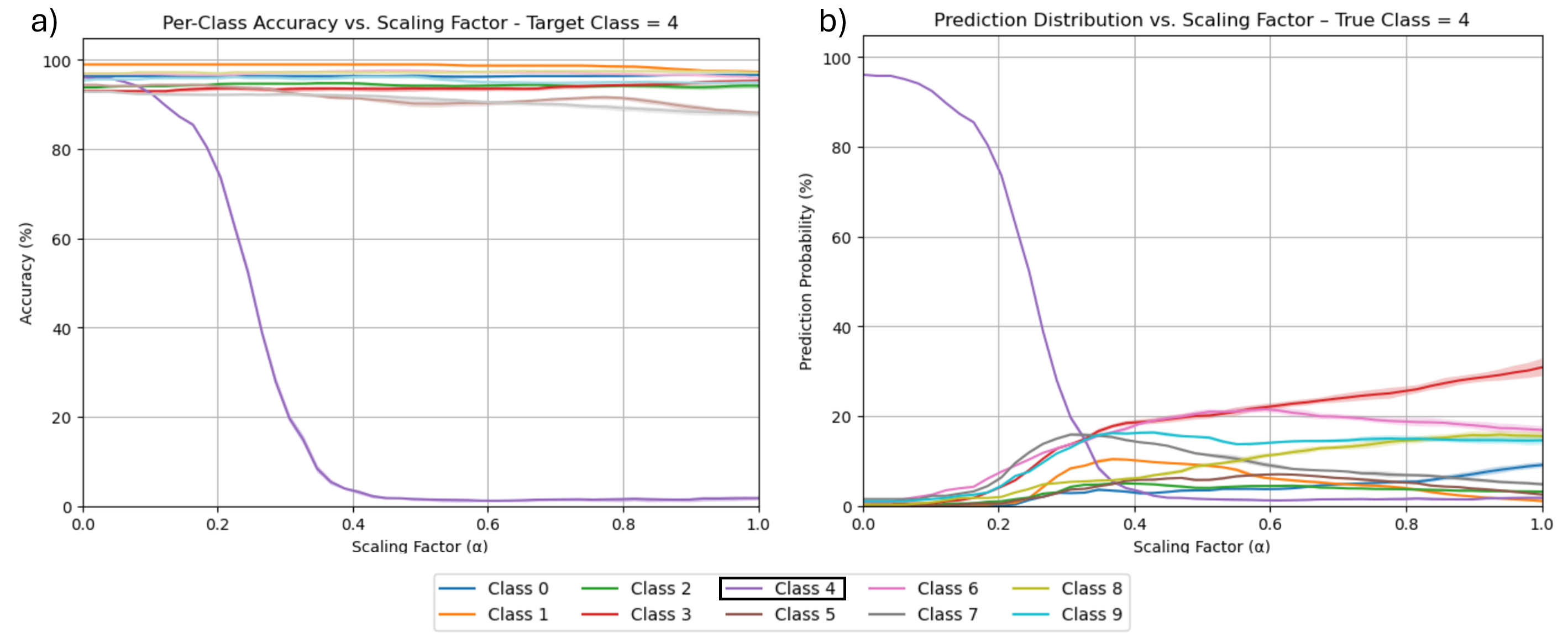
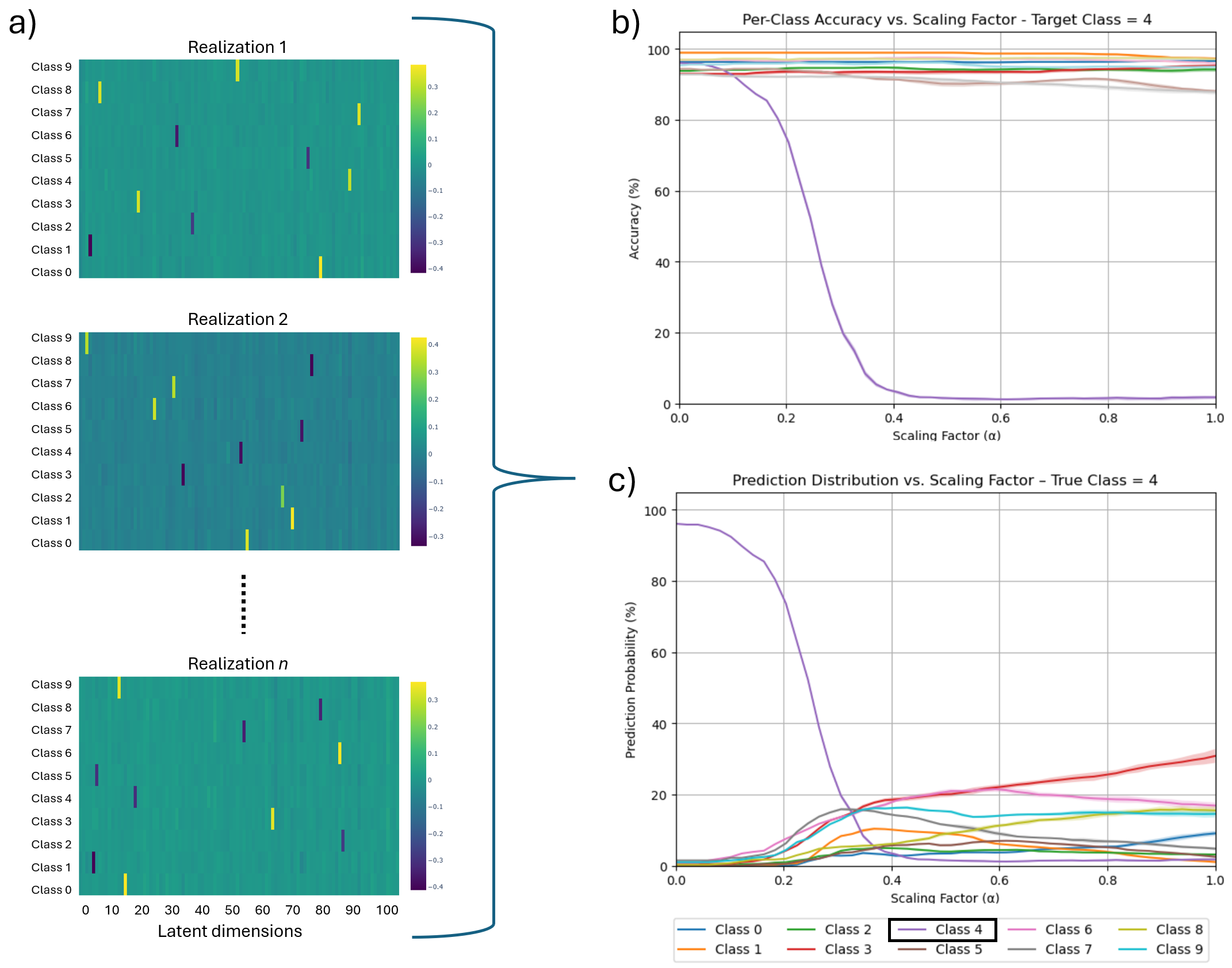
Our framework achieves this by first training an ℓ 1 -regularized autoencoder on a model’s internal activations to discover a sparse, interpretable feature basis native to the model. We validate these features using visualization techniques, including activation maximization and our proposed Grad-FAM (Gradient-weighted Feature Activation Mapping), to confirm their semantic meaning. This interpretable basis is then used to guide a permanent, continuous weight-space intervention that can suppress or enhance a feature’s influence. Finally, to make this control quantifiable, we derive and validate a critical suppression threshold, α crit , providing a measure of a class’s reliance on its dominant feature.
Our work is positioned at the intersection of two primary domains: the discovery of interpretable features and the direct editing and control of model behavior. We situate our contributions at the intersection of these fields, focusing on creating a direct pathway from understanding to control.
A key goal of post-hoc interpretability is to make a trained model’s decisions intelligible. Attribution methods, such as Grad-CAM [40], generate saliency maps that highlight influential input regions. While useful for visualization, these methods are correlational and do not expose the internal concepts the model has learned. Other approaches aim to link a model’s internal components with humanunderstandable concepts. For example, Network Dissection [3] quantifies the semantics of individual filters by testing their alignment with a broad set of visual concepts. Similarly, TCAV [20] uses directional derivatives to measure a model’s sensitivity to user-defined concepts. These methods are powerful but often rely on a pre-defined library of concepts.
Recent work in mechanistic interpretability has used SAEs to discover features in an unsupervised manner, primarily within Transformer-based language models. Expanding beyond the text domain, SAEs have been adapted to vision and generative architectures, revealing selective remapping of visual concepts during adaptation [27]. SAEs have also been applied to diffusion models for interpretable concept unlearning and sparse generative manipulation [6,44]. Recent SAE variants, including Gated SAEs [37], Top-k SAEs [10], and JumpReLU SAEs [38], have been shown to improve reconstruction fidelity and sparsity trade-offs in large models. Ongoing analyses of feature and dictionary structure provide broader insight into the properties of SAE-discovered representations [45,46]. Our work builds on this approach to feature discovery by using a SAE to automatically discover semantically meaningful features directly from the model’s activations.
Model editing techniques aim to modify a model’s behavior without full retraining, typically through targeted updates. Simple interventions like ablation typically zero out neurons, or entire filters, to observe their effect on the output [24,25,31]. However, while this provides evidence of their importance, these approaches are limited in their ability to perform fine-grained, continuous interventions, and often lack a structured representation in which such interventions can be reasoned about and controlled directly.
Most recent work using SAEs has focused on inference-time steering, where interventions involve adding a “steering vector” to a model’s activations during a forward pass to influence the output [46,51,5,17,34,43]. Additional lines of work study sparse, concept-conditioned interventions
This content is AI-processed based on open access ArXiv data.