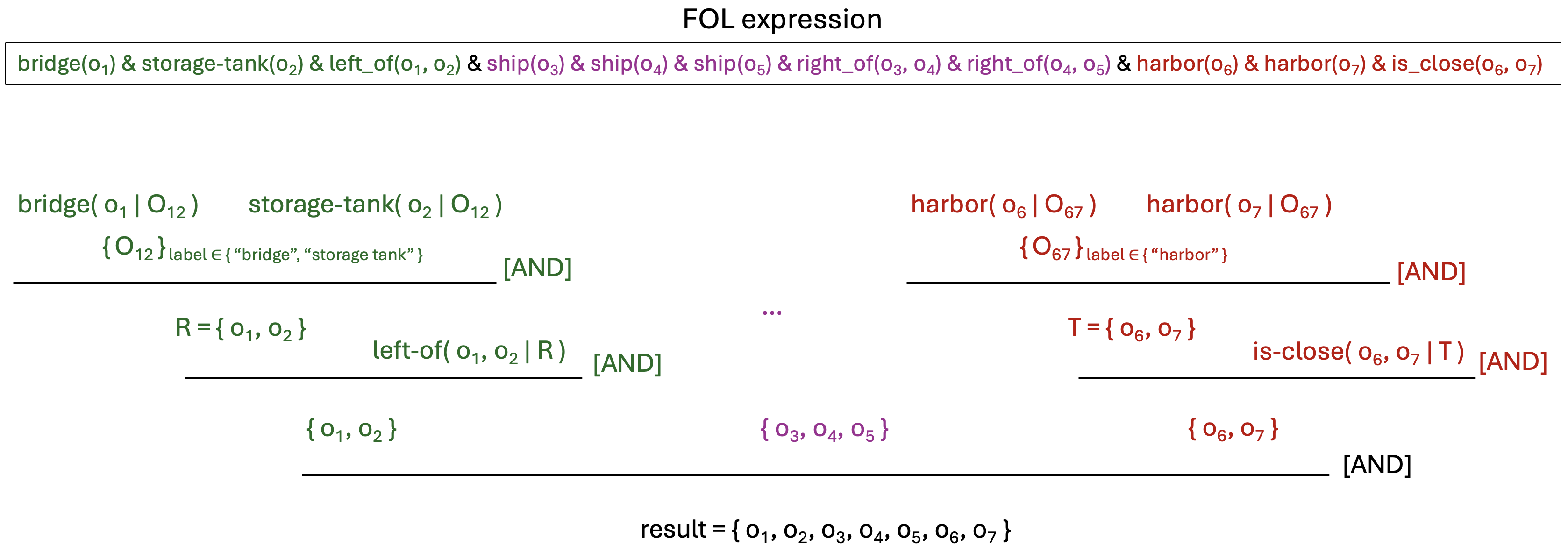
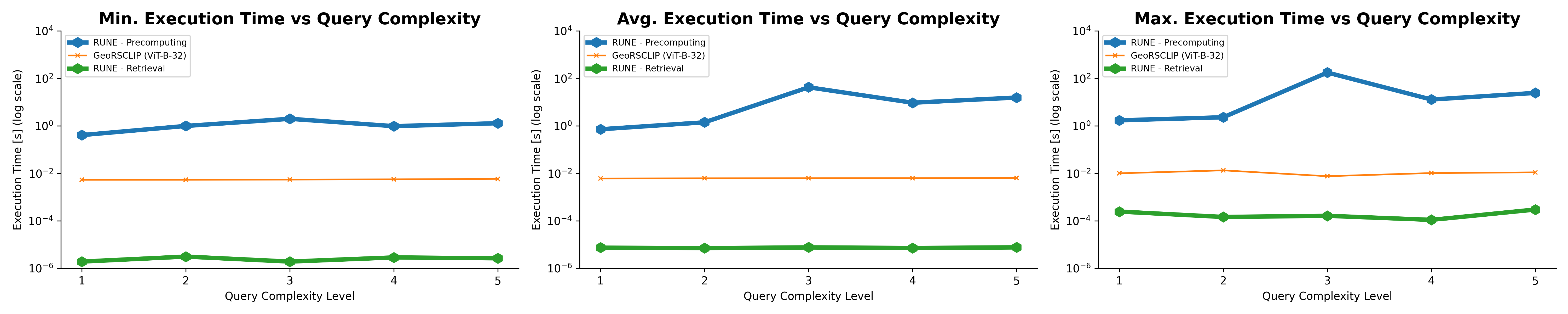
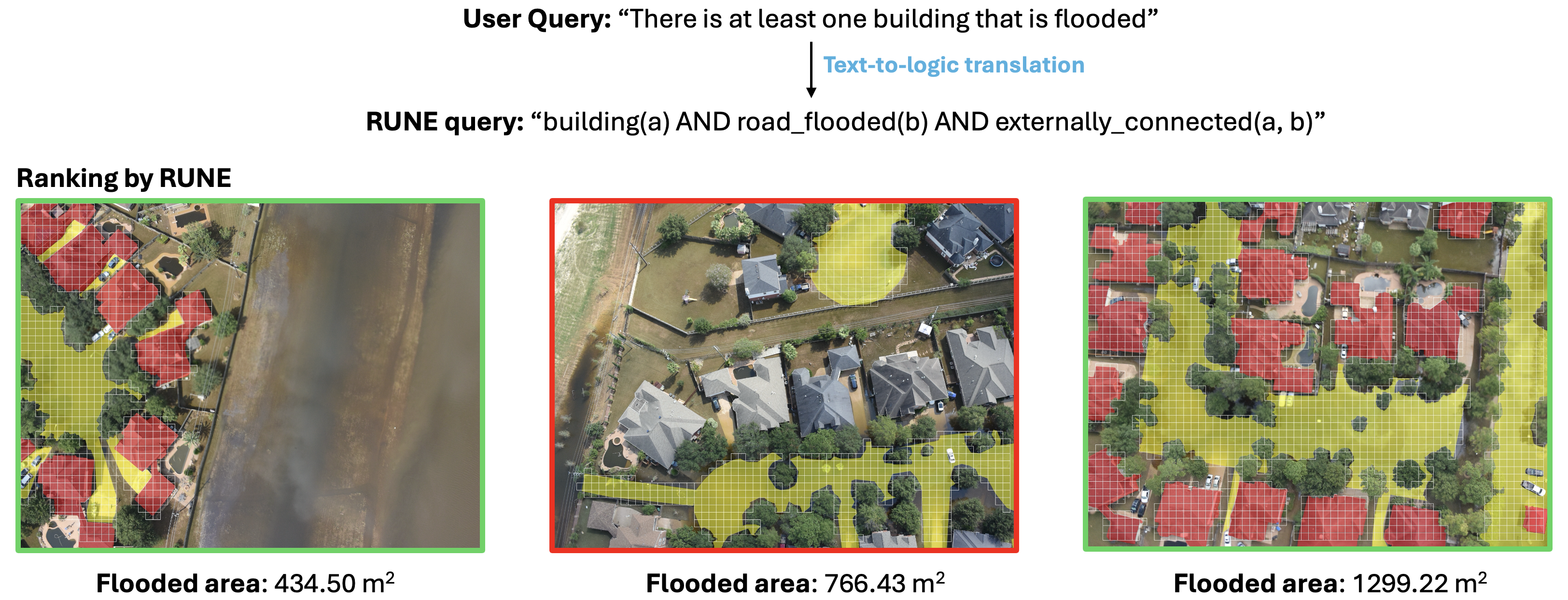
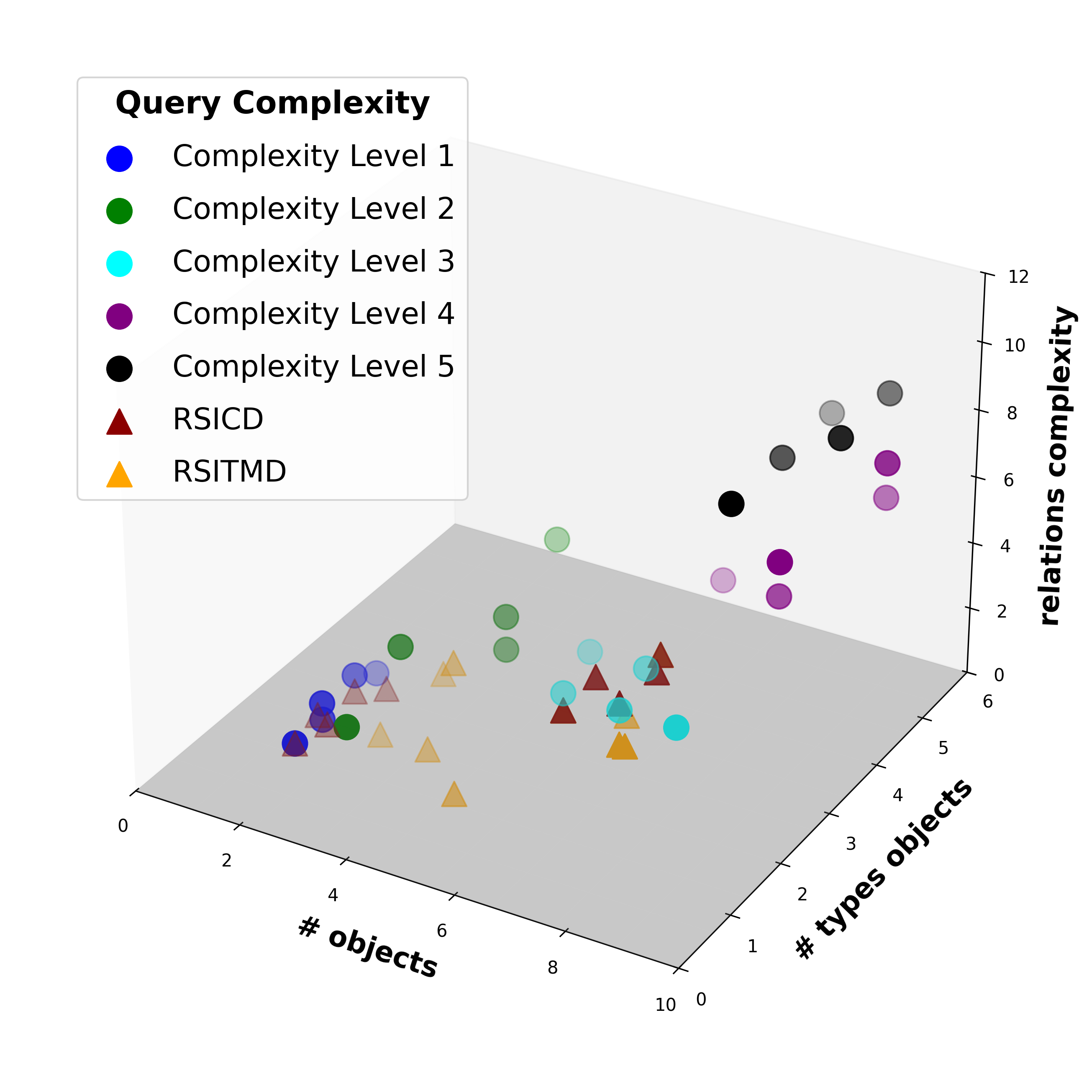
Text-to-image retrieval in remote sensing (RS) has advanced rapidly with the rise of large vision-language models (LVLMs) tailored for aerial and satellite imagery, culminating in remote sensing large vision-language models (RS-LVLMS). However, limited explainability and poor handling of complex spatial relations remain key challenges for real-world use. To address these issues, we introduce RUNE (Reasoning Using Neurosymbolic Entities), an approach that combines Large Language Models (LLMs) with neurosymbolic AI to retrieve images by reasoning over the compatibility between detected entities and First-Order Logic (FOL) expressions derived from text queries. Unlike RS-LVLMs that rely on implicit joint embeddings, RUNE performs explicit reasoning, enhancing performance and interpretability. For scalability, we propose a logic decomposition strategy that operates on conditioned subsets of detected entities, guaranteeing shorter execution time compared to neural approaches. Rather than using foundation models for end-to-end retrieval, we leverage them only to generate FOL expressions, delegating reasoning to a neurosymbolic inference module. For evaluation we repurpose the DOTA dataset, originally designed for object detection, by augmenting it with more complex queries than in existing benchmarks. We show the LLM's effectiveness in text-to-logic translation and compare RUNE with state-of-the-art RS-LVLMs, demonstrating superior performance. We introduce two metrics, Retrieval Robustness to Query Complexity (RRQC) and Retrieval Robustness to Image Uncertainty (RRIU), which evaluate performance relative to query complexity and image uncertainty. RUNE outperforms joint-embedding models in complex RS retrieval tasks, offering gains in performance, robustness, and explainability. We show RUNE's potential for real-world RS applications through a use case on post-flood satellite image retrieval.
💡 Deep Analysis
📄 Full Content
NEUROSYMBOLIC INFERENCE ON FOUNDATION MODELS FOR
REMOTE SENSING TEXT-TO-IMAGE RETRIEVAL WITH COMPLEX
QUERIES ∗
Emanuele Mezzi
Vrije Universiteit Amsterdam
The Netherlands
e.mezzi@vu.nl
Gertjan Burghouts
TNO
The Netherlands
gertjan.burghouts@tno.nl
Maarten Kruithof
TNO
The Netherlands
maarten.kruithof@tno.nl
ABSTRACT
Text-to-image retrieval in remote sensing (RS) has advanced rapidly with the rise of large vision-
language models (LVLMs) tailored for aerial and satellite imagery, culminating in remote sensing
large vision-language models (RS-LVLMS). However, limited explainability and poor handling of
complex spatial relations remain key challenges for real-world use. To address these issues, we
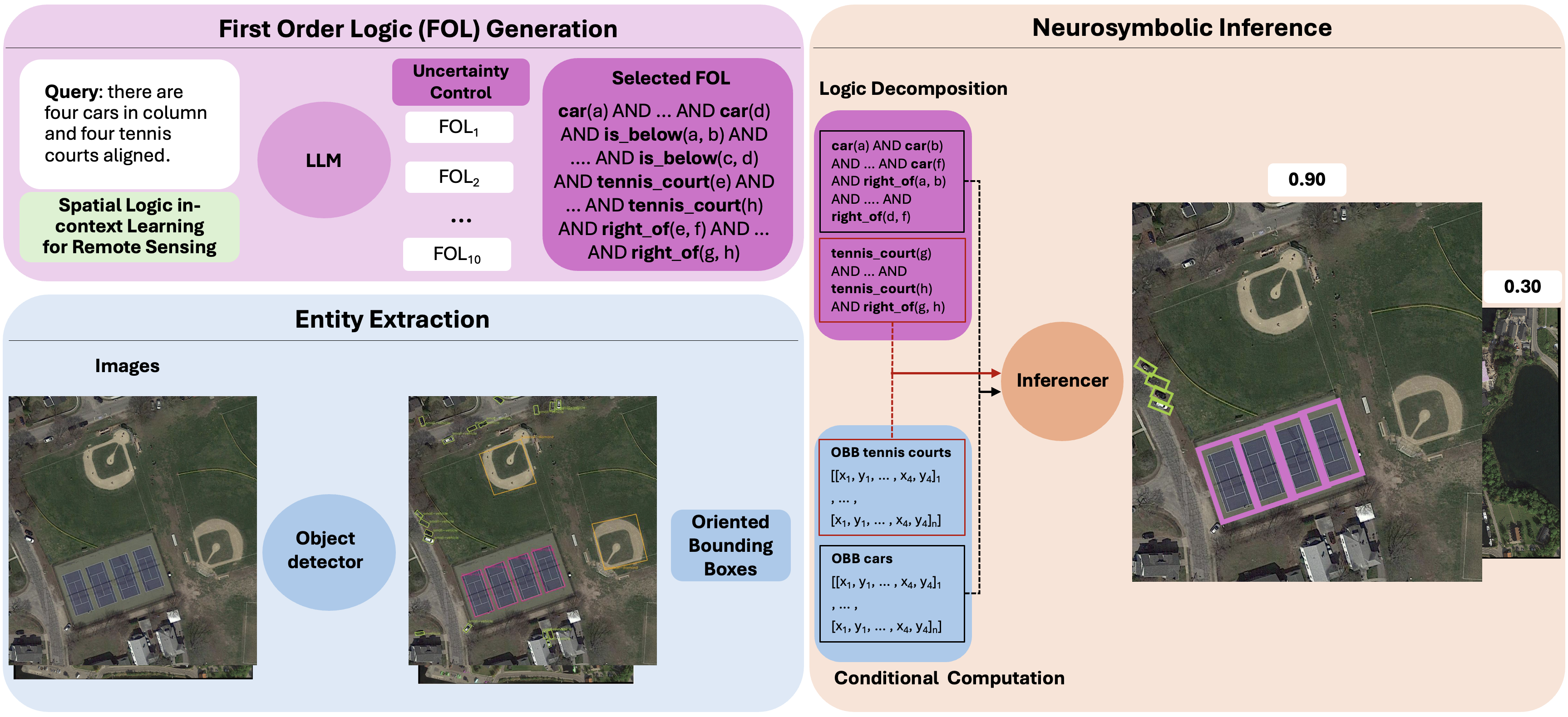
introduce RUNE (Reasoning Using Neurosymbolic Entities), an approach that combines Large Lan-
guage Models (LLMs) with neurosymbolic AI to retrieve images by reasoning over the compatibility
between detected entities and First-Order Logic (FOL) expressions derived from text queries. Unlike
RS-LVLMs that rely on implicit joint embeddings, RUNE performs explicit reasoning, enhancing
performance and interpretability. For scalability, we propose a logic decomposition strategy that
operates on conditioned subsets of detected entities, guaranteeing shorter execution time compared to
neural approaches. Rather than using foundation models for end-to-end retrieval, we leverage them
only to generate FOL expressions, delegating reasoning to a neurosymbolic inference module. For
evaluation we repurpose the DOTA dataset, originally designed for object detection, by augmenting
it with more complex queries than in existing benchmarks. We show the LLM’s effectiveness in
text-to-logic translation and compare RUNE with state-of-the-art RS-LVLMs, demonstrating superior
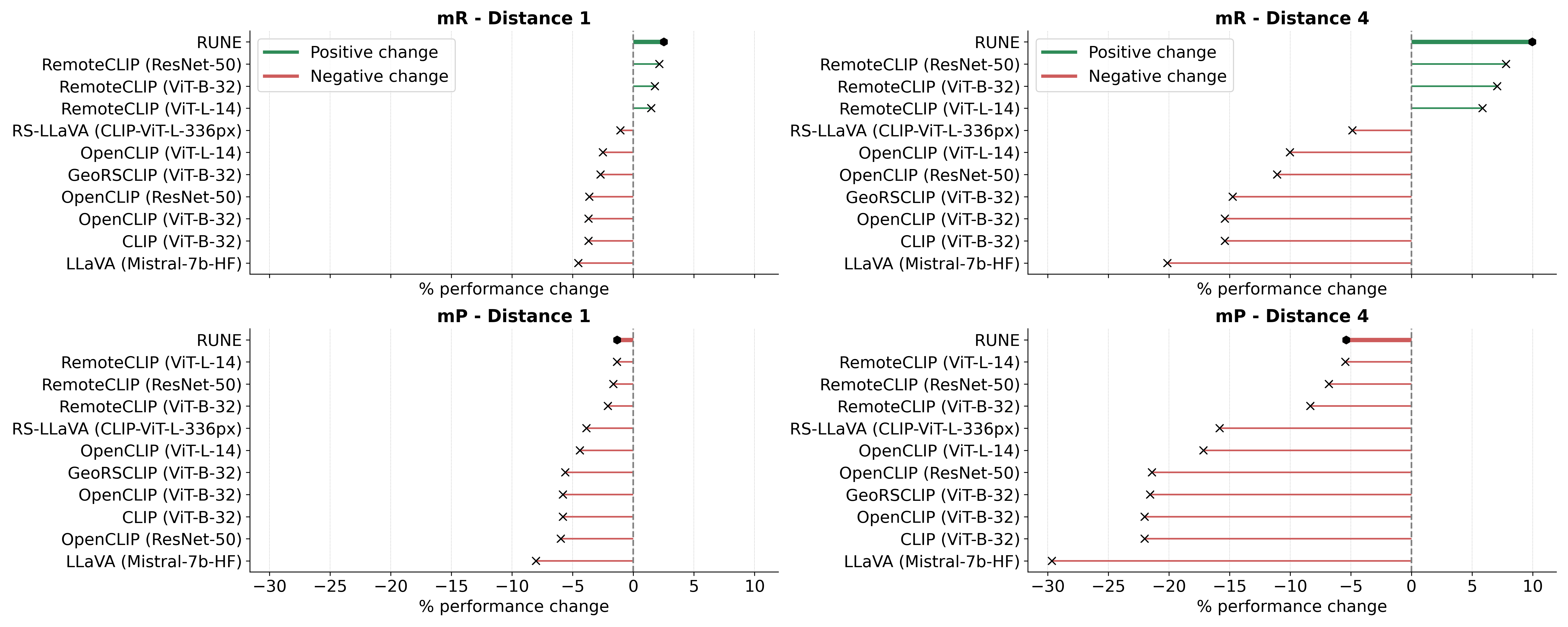
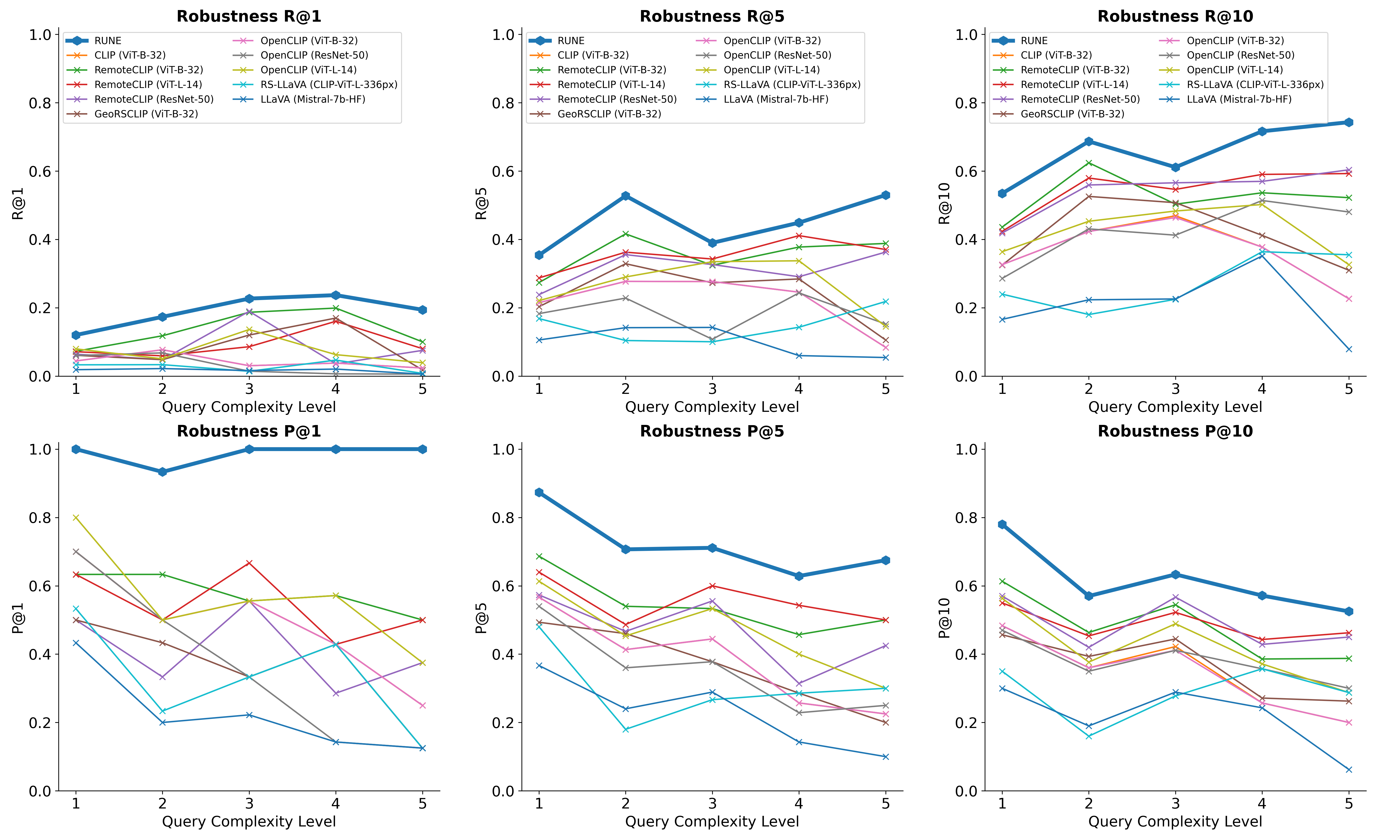
performance. We introduce two metrics, Retrieval Robustness to Query Complexity (RRQC) and
Retrieval Robustness to Image Uncertainty (RRIU), which evaluate performance relative to query
complexity and image uncertainty. RUNE outperforms joint-embedding models in complex RS
retrieval tasks, offering gains in performance, robustness, and explainability. We show RUNE’s
potential for real-world RS applications through a use case on post-flood satellite image retrieval.
Keywords Text-to-Image Retrieval · Neurosymbolic Reasoning · Spatial Reasoning · Large Language Models · Large
Visual Language Models
1
Introduction
Given their impressive capabilities, foundation models and large vision-language models (LVLMs) are seeing rapidly
expanding adoption, with applications spanning nearly every area of scientific research and practical implementation
[1, 2, 3, 4]. In recent years, LVLMs have been successfully applied to remote sensing (RS) [5, 6], where GeoAI
foundation models can handle a variety of tasks — notably text-to-image retrieval, which enables automated extraction
of actionable information from RS data. Models such as RemoteCLIP [7], GeoRSCLIP [8], and RS-LLaVA [9] have
shown promising retrieval performance, achieving high recall and ensuring good coverage of relevant images given a
textual query. These results highlight that, even in RS, general-purpose LVLMs can deliver strong performance when
fine-tuned on data tailored to the task.
∗Accepted for publication in ACM Transactions on Spatial Algorithms and Systems (TSAS).
arXiv:2512.14102v1 [cs.CV] 16 Dec 2025
However, RS-LVLMs face several key limitations. First, they require large amounts of training data, which is often
unavailable in the target domain, motivating the need for models that can generalize without domain-specific training.
Second, existing LVLMs rely on joint image-text embeddings, where both the query and image are projected into a
shared embedding space and their similarity is computed. While effective, this approach encodes the detailed semantics
of the query implicitly, limiting both representational power and interpretability. Explainability is critical for real-world
applications, where human-understandable reasoning is often required. More importantly, we show that LVLMs struggle
with semantically complex queries — especially those involving multiple objects and relationships.
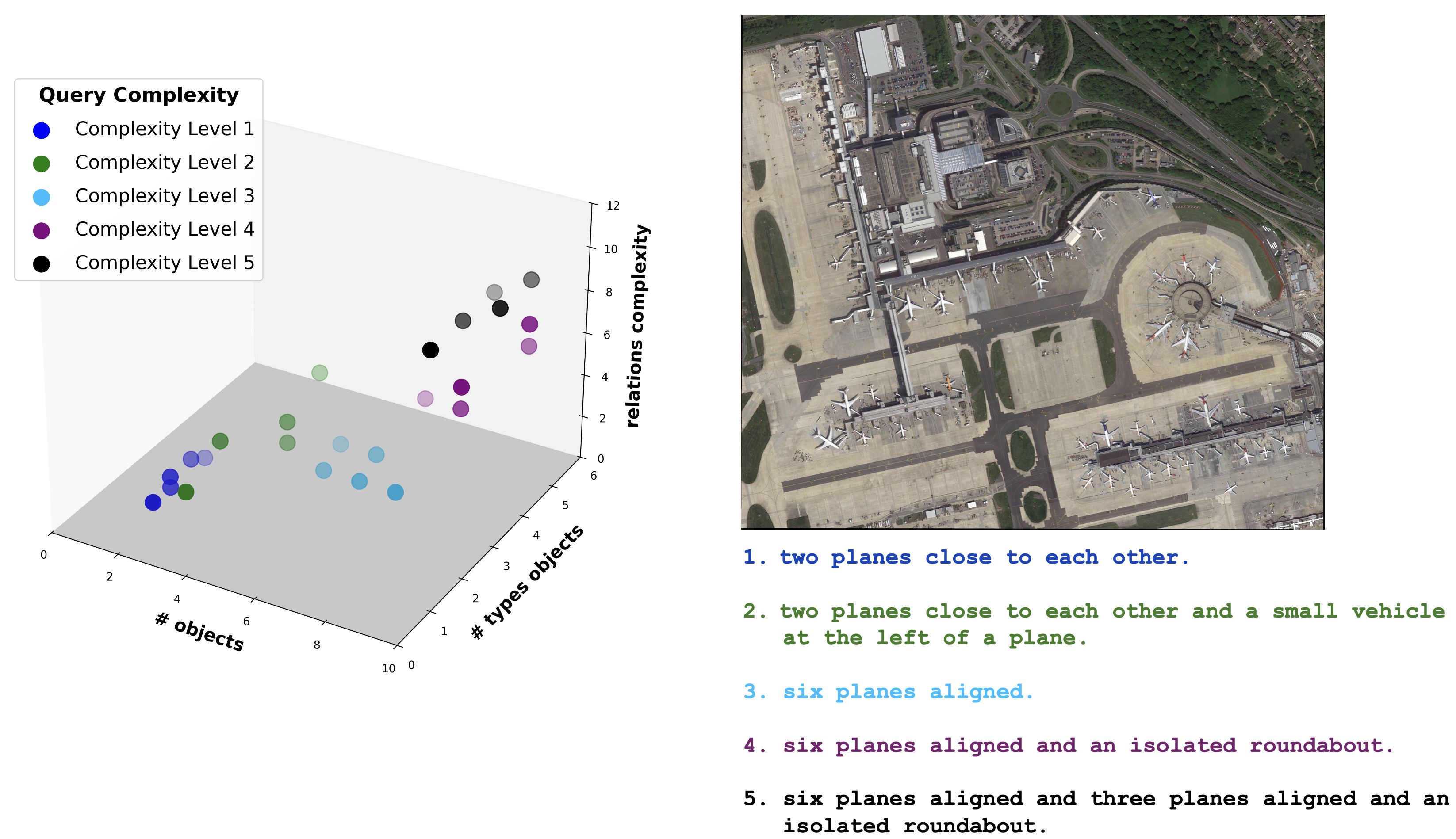
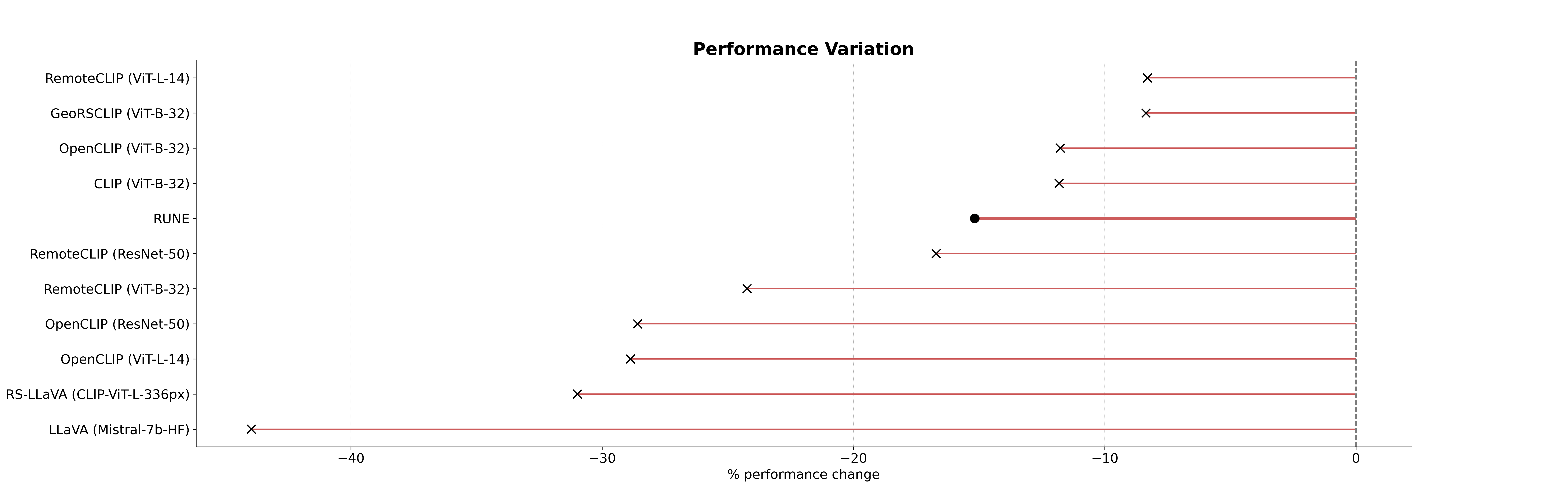
Previous evaluations have largely focused on recall (R@k), which provides useful insights into coverage and false
negatives (FNs) but fail to capture models’ ability to limit false positives (FPs), an important consideration in operational
settings, where manual intervention on every alert is impractical. To address this, we conduct a thorough evaluation of
RS-LVLMs on a dataset characterised by queries with complex spatial relations, assessing both recall and precision
(P@k), and analyzing robustness across increasing levels of query complexity. Our results reveal that current LVLMs
lack precision, robustness, and interpretability.
To overcome these challenges, we propose RUNE (Reasoning Using Neurosymbolic Entities), a novel text-to-image
retrieval approach that integrates foundation models with logical reasoning. Our met