Dual Attention Guided Defense Against Malicious Edits
Reading time: 5 minute
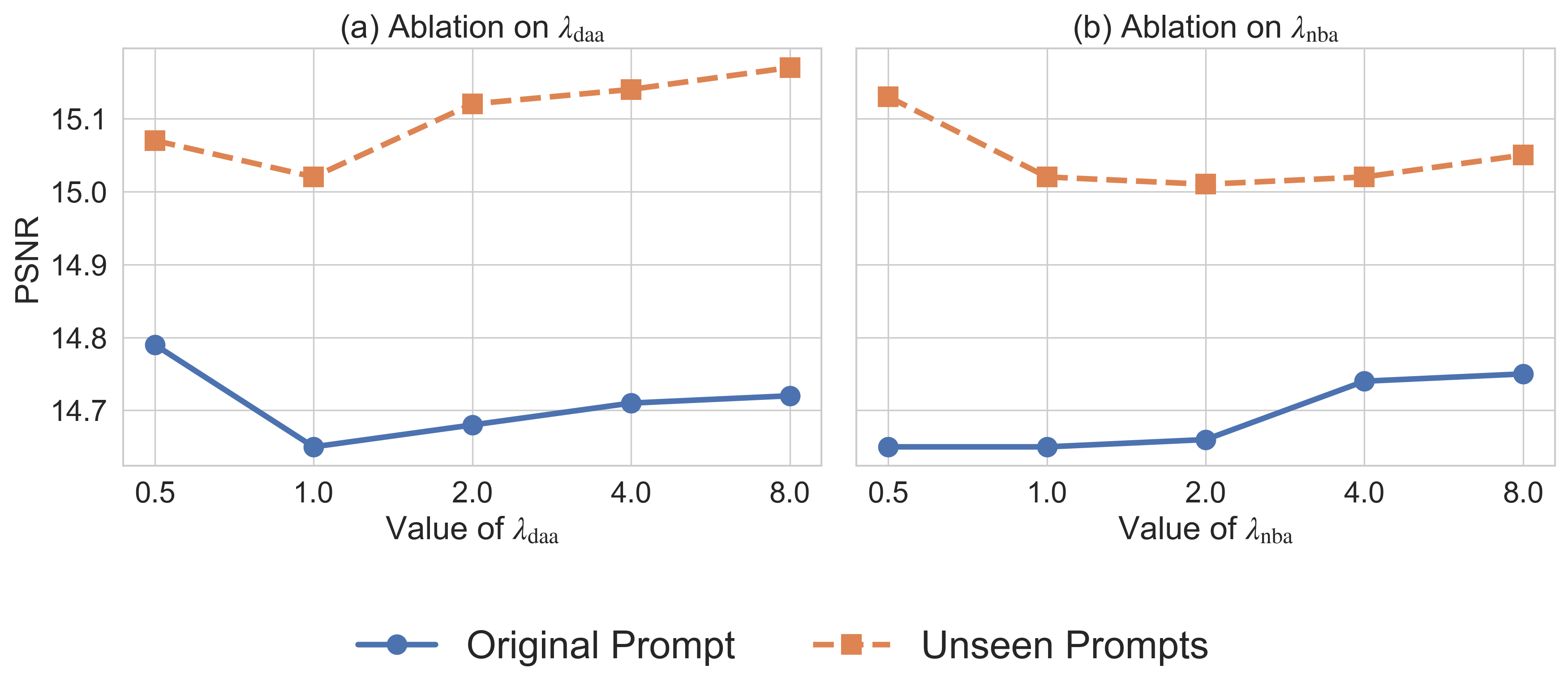
...
📝 Original Info
Title: Dual Attention Guided Defense Against Malicious Edits
ArXiv ID: 2512.14333
Date: 2025-12-16
Authors: Jie Zhang, Shuai Dong, Shiguang Shan, Xilin Chen
📝 Abstract
Recent progress in text-to-image diffusion models has transformed image editing via text prompts, yet this also introduces significant ethical challenges from potential misuse in creating deceptive or harmful content. While current defenses seek to mitigate this risk by embedding imperceptible perturbations, their effectiveness is limited against malicious tampering. To address this issue, we propose a Dual Attention-Guided Noise Perturbation (DANP) immunization method that adds imperceptible perturbations to disrupt the model's semantic understanding and generation process. DANP functions over multiple timesteps to manipulate both cross-attention maps and the noise prediction process, using a dynamic threshold to generate masks that identify text-relevant and irrelevant regions. It then reduces attention in relevant areas while increasing it in irrelevant ones, thereby misguides the edit towards incorrect regions and preserves the intended targets. Additionally, our method maximizes the discrepancy between the injected noise and the model's predicted noise to further interfere with the generation. By targeting both attention and noise prediction mechanisms, DANP exhibits impressive immunity against malicious edits, and extensive experiments confirm that our method achieves state-of-the-art performance.
💡 Deep Analysis
📄 Full Content
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021
1
Dual Attention Guided Defense Against Malicious Edits
Jie Zhang, Member, IEEE, Shuai Dong , Shiguang Shan Fellow, IEEE, Xilin Chen Fellow, IEEE,
Abstract—Recent progress in text-to-image diffusion models
has transformed image editing via text prompts, yet this also
introduces significant ethical challenges from potential misuse
in creating deceptive or harmful content. While current de-
fenses seek to mitigate this risk by embedding imperceptible
perturbations, their effectiveness is limited against malicious
tampering. To address this issue, we propose a Dual Attention-
Guided Noise Perturbation (DANP) immunization method that
adds imperceptible perturbations to disrupt the model’s semantic
understanding and generation process. DANP functions over
multiple timesteps to manipulate both cross-attention maps and
the noise prediction process, using a dynamic threshold to
generate masks that identify text-relevant and irrelevant regions.
It then reduces attention in relevant areas while increasing it
in irrelevant ones, thereby misguides the edit towards incorrect
regions and preserves the intended targets. Additionally, our
method maximizes the discrepancy between the injected noise
and the model’s predicted noise to further interfere with the
generation. By targeting both attention and noise prediction
mechanisms, DANP exhibits impressive immunity against ma-
licious edits, and extensive experiments confirm that our method
achieves state-of-the-art performance.
Index Terms—Diffusion Models, Image Editing, Image Immu-
nization.
I. INTRODUCTION
R
ECENT advancements in diffusion models [1]–[3] have
significantly propelled generative modeling, especially in
text-to-image generation. Models like DALLE2 [4], Imagen
[5], and Stable Diffusion [6] leverage diffusion processes with
natural language inputs to generate images that align with user-
provided text, offering intuitive control over image generation.
Beyond text-to-image tasks, diffusion models have been ex-
tended to image inpainting, editing, zero-shot classification,
and open vocabulary segmentation [7]–[15]. Their progressive
generation allows dynamic content adjustment, making them
highly effective for image editing. However, the widespread
use of diffusion models also raises concerns about potential
negative impacts. Misuse of these technologies can lead to the
creation of fake or manipulated images, deceiving the public,
spreading misinformation, or manipulating opinion, thereby
exacerbating societal trust issues. Additionally, privacy risks
emerge when personal images are edited without consent,
potentially resulting in privacy breaches or psychological
harm. More seriously, these techniques can be used to produce
harmful content, posing serious threats to social stability.
Jie Zhang, Shiguang Shan and Xilin Chen are with the State Key Laboratory
of AI Safety, Institute of Computing Technology, Chinese Academy of
Sciences (CAS), Beijing 100190, China, and also with the University of China
Academy of Sciences, Beijing 100049, China (e-mail: zhangjie@ict.ac.cn;
sgshan@ict.ac.cn; xlchen@ict.ac.cn).
Shuai Dong is with the School of Computer Science, China University of
Geosciences, Wuhan 430074, China (e-mail: dongshuai_iu@cug.edu.cn).
Therefore, a thorough exploration of the security implications
surrounding image editing technologies is essential to mitigate
the risks of misuse.
In response to these challenges, two primary mitigation
strategies have emerged, namely the reactive detection of
manipulated content [16]–[21] and the proactive immunization
of original images against unauthorized editing [22]–[25].
Reactive detection operates post-facto by training classifiers
to identify digital artifacts or inconsistencies left by gener-
ative models. However, this approach does not prevent the
initial creation and spread of harmful content, as the damage
may already be done by the time an image is flagged. In
contrast, proactive immunization offers a more robust, pre-
emptive defense by embedding imperceptible, adversarial per-
turbations into an original image before it is shared. The
primary advantage of this proactive stance is its ability to
disrupt the malicious editing process at its source, preventing
harmful content from being successfully generated. Rather
than merely identifying a fake, immunization aims to make
its creation infeasible, thereby shifting the security burden
from downstream detection to the point of content origin
and empowering creators with direct control over their digital
assets.
These immunization strategies primarily rely on adversarial
attacks to disrupt the image editing process by introducing
carefully crafted perturbations at various stages. While early
immunization strategies are effective against GAN-based edit-
ing models [22], [23], the advent of diffusion models and
their robust denoising process necessitates new approaches.
For diffusion models, initial defen