Title: Georeferencing complex relative locality descriptions with large language models
ArXiv ID: 2512.14228
Date: 2025-12-16
Authors: Aneesha Fernando, Surangika Ranathunga, Kristin Stock, Raj Prasanna, Christopher B. Jones
📝 Abstract
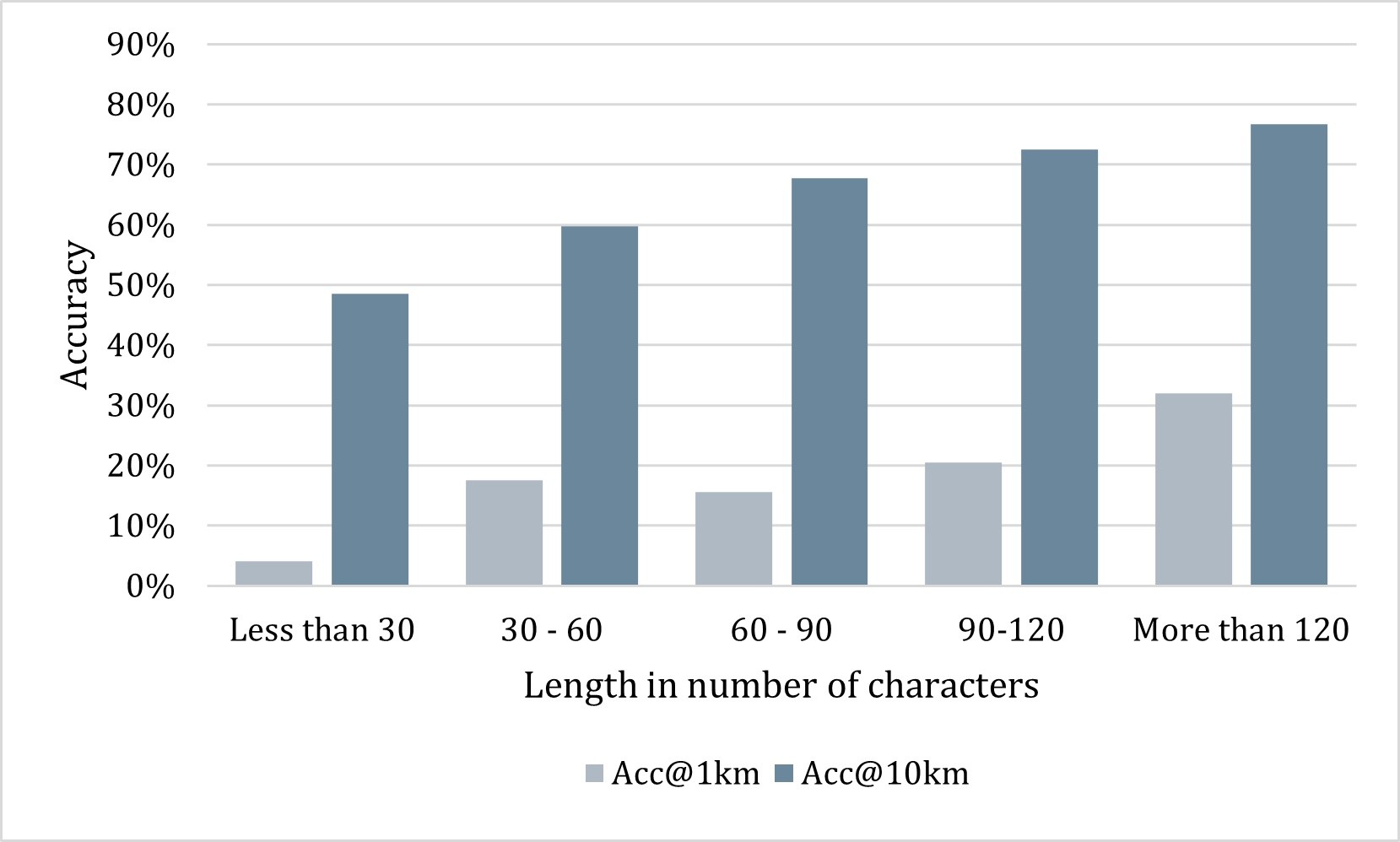
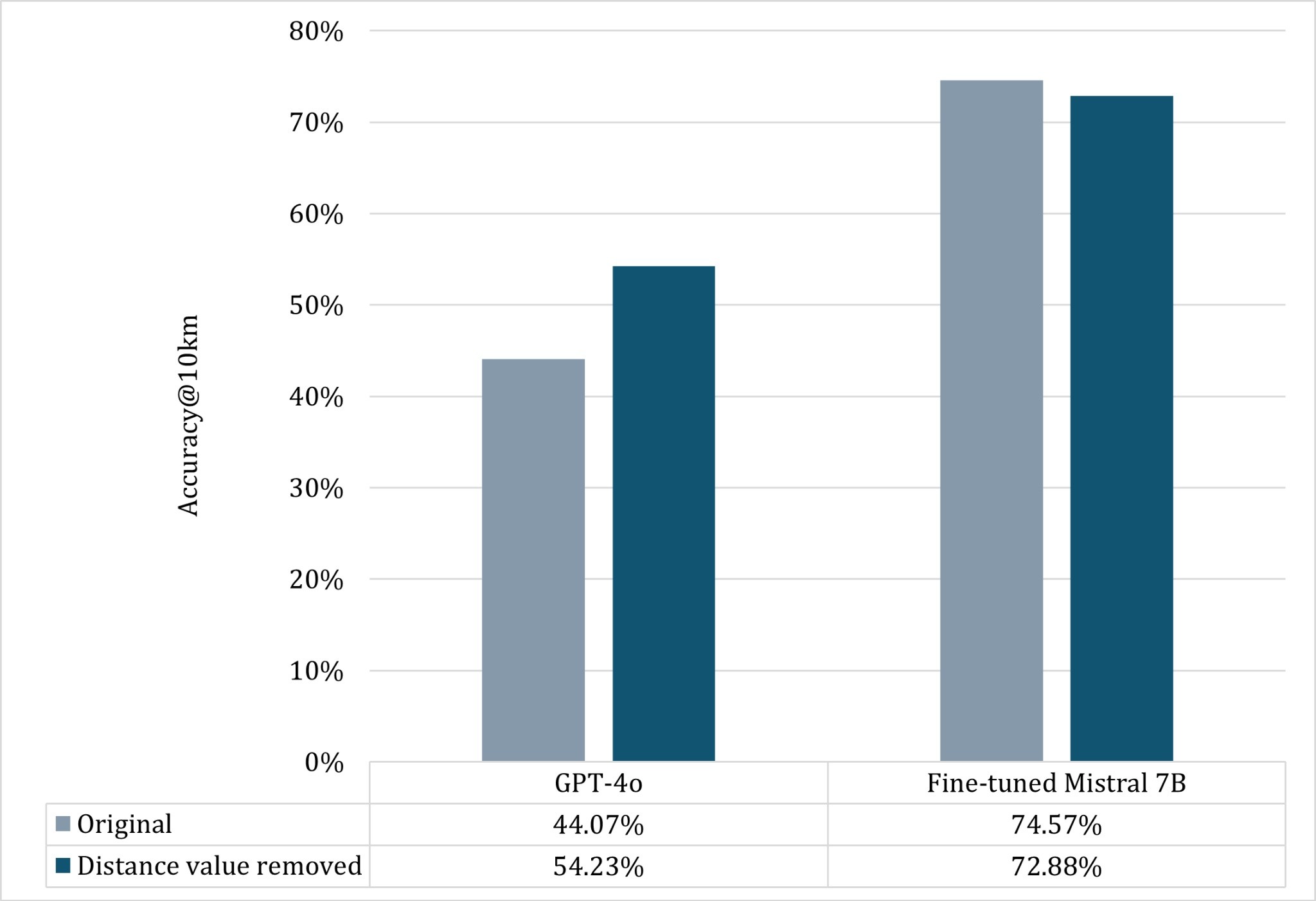
Georeferencing text documents has typically relied on either gazetteer-based methods to assign geographic coordinates to place names, or on language modelling approaches that associate textual terms with geographic locations. However, many location descriptions specify positions relatively with spatial relationships, making geocoding based solely on place names or geo-indicative words inaccurate. This issue frequently arises in biological specimen collection records, where locations are often described through narratives rather than coordinates if they pre-date GPS. Accurate georeferencing is vital for biodiversity studies, yet the process remains labour-intensive, leading to a demand for automated georeferencing solutions. This paper explores the potential of Large Language Models (LLMs) to georeference complex locality descriptions automatically, focusing on the biodiversity collections domain. We first identified effective prompting patterns, then fine-tuned an LLM using Quantized Low-Rank Adaptation (QLoRA) on biodiversity datasets from multiple regions and languages. Our approach outperforms existing baselines with an average, across datasets, of 65% of records within a 10 km radius, for a fixed amount of training data. The best results (New York state) were 85% within 10km and 67% within 1km. The selected LLM performs well for lengthy, complex descriptions, highlighting its potential for georeferencing intricate locality descriptions.
💡 Deep Analysis
📄 Full Content
RESEARCH ARTICLE
Georeferencing complex relative locality descriptions with large
language models
Aneesha Fernandoa*, Surangika Ranathungaa, Kristin Stocka, Raj Prasannaa and
Christopher B. Jonesb
aMassey University, New Zealand bCardiff University, United Kingdom
ARTICLE HISTORY
Compiled December 17, 2025
ABSTRACT
Georeferencing text documents has typically relied on either gazetteer-based meth-
ods to assign geographic coordinates to place names, or on language modelling ap-
proaches that associate textual terms with geographic locations. However, many
location descriptions specify positions relatively with spatial relationships, making
geocoding based solely on place names or geo-indicative words inaccurate. This issue
frequently arises in biological specimen collection records, where locations are often
described through narratives rather than coordinates if they pre-date GPS. Accu-
rate georeferencing is vital for biodiversity studies, yet the process remains labour-
intensive, leading to a demand for automated georeferencing solutions. This paper
explores the potential of Large Language Models (LLMs) to georeference complex
locality descriptions automatically, focusing on the biodiversity collections domain.
We first identified effective prompting patterns, then fine-tuned an LLM using Quan-
tized Low-Rank Adaptation (QLoRA) on biodiversity datasets from multiple regions
and languages. Our approach outperforms existing baselines with an average, across
datasets, of 65% of records within a 10 km radius, for a fixed amount of training
data. The best results (New York state) were 85% within 10km and 67% within 1km.
The selected LLM performs well for lengthy, complex descriptions, highlighting its
potential for georeferencing intricate locality descriptions.
KEYWORDS
Locative Expressions; Spatial Relations; Generative AI; Biological Collections;
ChatGPT; Mistral; Geotagging; Georeferencing; Large Language Models; LLMs
1.
Introduction
While most geographical information systems are predominantly based on structured
digital map data, there remains a vast amount of information embedded within tex-
tual resources. Access to the information content of such resources is the subject of
the field of geographical information retrieval (Purves et al. 2018), which depends to a
large extent on the effectiveness of georeferencing methods to determine the geospatial
focus of the content of text documents. To date, georeferencing methods for textual
data have usually been applied to the content of web pages and of social media post-
ings. The methods typically employ either gazetteer-based approaches to detect and
geocode (determine coordinates for) place names in the texts, or language modelling
approaches that depend upon determining the association between text and locations,
CONTACT Aneesha Fernando. Email: afwboosa@massey.ac.nz
arXiv:2512.14228v1 [cs.AI] 16 Dec 2025
or some combination of these (Gritta et al. 2018, Melo and Martins 2017). References
to geographic locations through the use of place names are usually assumed to be
absolute, in the sense that the location is regarded as equivalent to that of a place
name or some other words that are indicative of a location (Han et al. 2012). Little
attention has been given to the fact that some descriptions of location are relative, in
that they refer to a location that has some spatial relationship to a reference place
name (Wieczorek et al. 2004, van Erp et al. 2015, Chen et al. 2018). Spatial relational
terms include phrases and words that indicate a specified distance, such as 10km west
of, as well as relative positions like near, adjacent to, and along from.
A domain in which complex locality descriptions are commonly found is that of the
collection records of natural history agencies such as museums and herbaria. These
collections can include records of biological specimens of plants and animals, fungi
and bacteria, as well as soil and geological samples. Many of the records, specially
those collected before the widespread availability of GPS, do not have associated ge-
ographical coordinates. Instead, their locations are described solely through textual
descriptions that include locality descriptions. At its simplest, a locality description
might just consist of place names (toponyms), but very commonly, place names are
combined with relative spatial terms (van Erp et al. 2015, Wieczorek et al. 2004, Scott
et al. 2021). There are billions of such records and there is a strong motivation to geo-
reference them, as being able to assign coordinates, and hence map the locations at
which they were found, is a crucial step in studying biodiversity. Such georeferenced
data enables researchers to monitor the geographical distribution of species over time,
the impacts of environmental changes on species, and to predict how environmental
changes will affect biodiversity in specific regions (van Erp et al. 2015).
To georeference textual documents such as Wikipedia arti