The deployment of Vision-Language Models (VLMs) in safety-critical domains like autonomous driving (AD) is critically hindered by reliability failures, most notably object hallucination. This failure stems from their reliance on ungrounded, text-based Chain-of-Thought (CoT) reasoning. While existing multi-modal CoT approaches attempt mitigation, they suffer from two fundamental flaws: (1) decoupled perception and reasoning stages that prevent end-to-end joint optimization, and (2) reliance on expensive, dense localization labels. Thus we introduce OmniDrive-R1, an end-to-end VLM framework designed for autonomous driving, which unifies perception and reasoning through an interleaved Multi-modal Chain-of-Thought (iMCoT) mechanism. Our core innovation is an Reinforcement-driven visual grounding capability, enabling the model to autonomously direct its attention and "zoom in" on critical regions for fine-grained analysis. This capability is enabled by our pure two-stage reinforcement learning training pipeline and Clip-GRPO algorithm. Crucially, Clip-GRPO introduces an annotation-free, process-based grounding reward. This reward not only eliminates the need for dense labels but also circumvents the instability of external tool calls by enforcing real-time cross-modal consistency between the visual focus and the textual reasoning. Extensive experiments on DriveLMM-o1 demonstrate our model's significant improvements. Compared to the baseline Qwen2.5VL-7B, OmniDrive-R1 improves the overall reasoning score from 51.77% to 80.35%, and the final answer accuracy from 37.81% to 73.62%.
The advancement of autonomous driving (AD) systems has fundamentally shifted from pure object detection and tracking to intricate, high-level reasoning and decision-making * Equal contribution under complex, safety-critical scenarios [34,41]. Tasks such as intent prediction, causal explanation, and abstract policy planning require capabilities beyond simple perception, making them essential for robust driving deployment [15,27]. Vision-Language Models (VLMs), which seamlessly integrate visual perception with powerful linguistic reasoning, have emerged as a promising foundation for such complex, cognitive AD agents [45]. By leveraging Chain-of-Thought (CoT) reasoning [43], VLMs can articulate their decisionmaking process, offering transparency and interpretability.
Despite this potential, the deployment of VLMs in AD is critically hindered by fundamental reliability failures, most notably object hallucination [2,52]. This failure is rooted in the current reliance on ungrounded, text-based CoT reasoning. When the model’s “thought process” is largely confined to discrete textual tokens, it risks losing fidelity to the continuous, dynamic visual scene, leading to the fabrication of non-existent objects, states, or relationships. In autonomous driving, a model that hallucinates even a minor detail can lead to catastrophic and life-threatening failures.
To mitigate this challenge, a new paradigm of multimodal interactive reasoning is emerging [7,14,18]. Recent works have proposed predefined workflow based strategies [17,31,36] and tool-augmented methods [27] to incorporate visual information into CoT reasoning. The former often employs rigid, hard-coded reasoning paths. This structural inflexibility severely limits their adaptability, confining them to specific, pre-defined problem types and failing to generalize to novel scenarios. The latter delegates critical perception sub-tasks to a collection of disparate, external models. This decoupled architecture fundamentally compromises the integrity of the perception-reasoning process, preventing end-to-end joint optimization and making it difficult to ensure cross-modal consistency. Consequently, these methods not only yield suboptimal solutions [30] but also fail to cultivate and leverage the intrinsic, fine-grained visual processing potential of the core VLM itself. Critically, both paradigms are further constrained by their reliance on large-scale, high-quality annotated reasoning data, which is This mechanism dynamically acquires fine-grained visual evidence (Round 2), which is directly used to refine the thought and arrive at a confident, visually-backed final answer. This active, evidence-based process significantly enhances grounding and interpretability.
expensive and difficult to acquire.
In contrast, human drivers primarily rely on a dynamic interplay between their cognitive processes and the visual information from their surroundings to make judgments and take action. This requires a continuous and dynamic interaction with visual data. Inspired by this, we hypothesize that a VLM can achieve the same goal by exclusively optimizing its native perception, and reasoning capabilities. Here, perception is analogous to a driver’s cognitive interaction with the scene to acquire visual information, while reasoning corresponds to their process of making sense of the information.
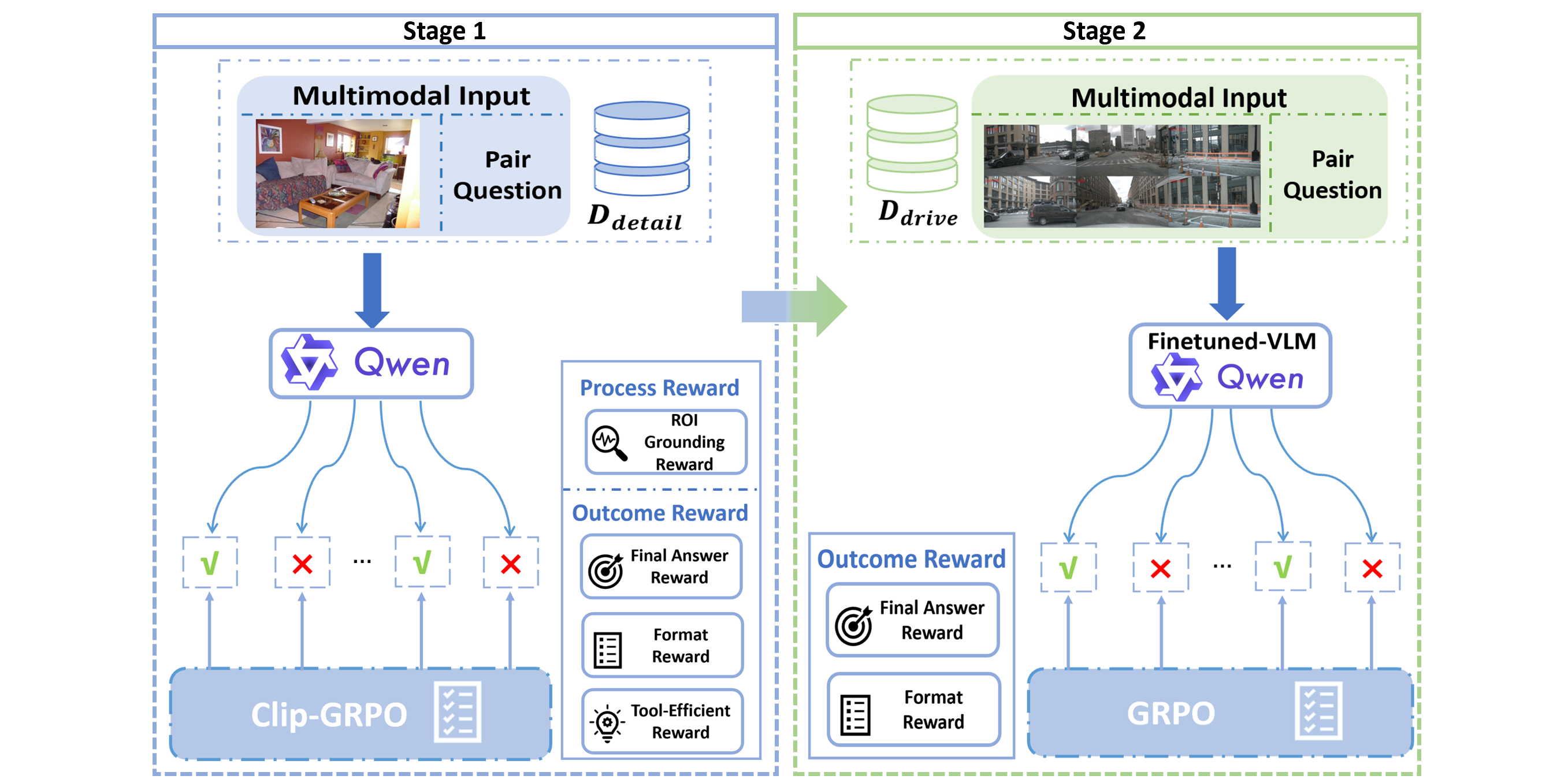
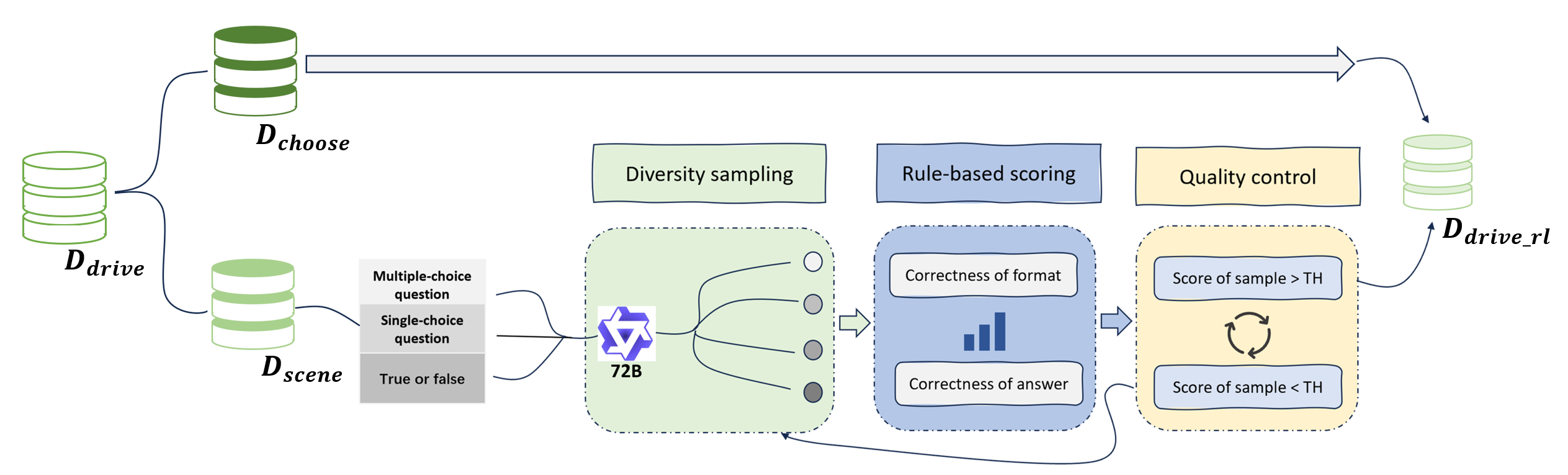
Based on this insight, we introduce OmniDrive-R1, an end-to-end VLM framework designed for autonomous driving. As illustrated in Fig. 1, OmniDrive-R1 empowers the VLM with an adaptive, active perception capability via an interleaved Multi-modal Chain-of-Thought (iMCoT) mechanism. Our core technical innovation is a reinforcementdriven visual grounding capability, enabling the model to autonomously direct its attention and zoom in on critical regions for fine-grained analysis during the reasoning process. This activation is purely driven by the base VLM’s intrinsic grounding potential, eliminating reliance on any external tools. Concretely, this capability is realized through a pure two-stage Reinforcement Learning (RL) training strategy utilizing our novel Clip-GRPO. Building upon Group Relative Policy Optimization (GRPO) [32], Clip-GRPO introduces an innovative, annotation-free, process-based grounding reward. This reward uses the CLIP model’s [29] cross-modal consistency to enforce real-time alignment between the model’s visual focus and its textual reasoning, thereby eliminating the need for dense localization labels and circumventing the instability of external tool calls.
In summary, our major contributions are as follows: 1. We propose OmniDrive-R1, the first purely RL-driven end to end VLM-based framework for AD. OmniDrive-R1 unifies perception and reasoning through an iMCoT mechanism, which leverages the VLM’s native grounding capability to dynamically locate the most task-relevant critical regions for fine-grained analysis, without reliance on external models. 2. We introduce
This content is AI-processed based on open access ArXiv data.