Unified Interactive Multimodal Moment Retrieval via Cascaded Embedding-Reranking and Temporal-Aware Score Fusion
Reading time: 5 minute
...
📝 Original Info
Title: Unified Interactive Multimodal Moment Retrieval via Cascaded Embedding-Reranking and Temporal-Aware Score Fusion
ArXiv ID: 2512.12935
Date: 2025-12-15
Authors: Toan Le Ngo Thanh, Phat Ha Huu, Tan Nguyen Dang Duy, Thong Nguyen Le Minh, Anh Nguyen Nhu Tinh
📝 Abstract
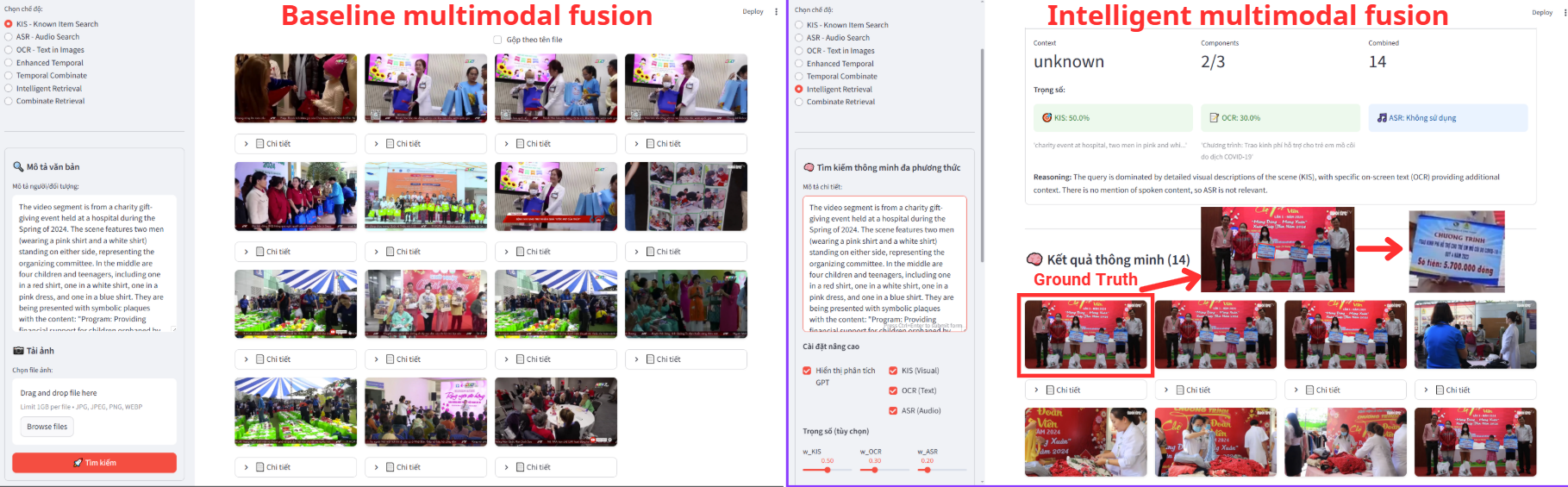
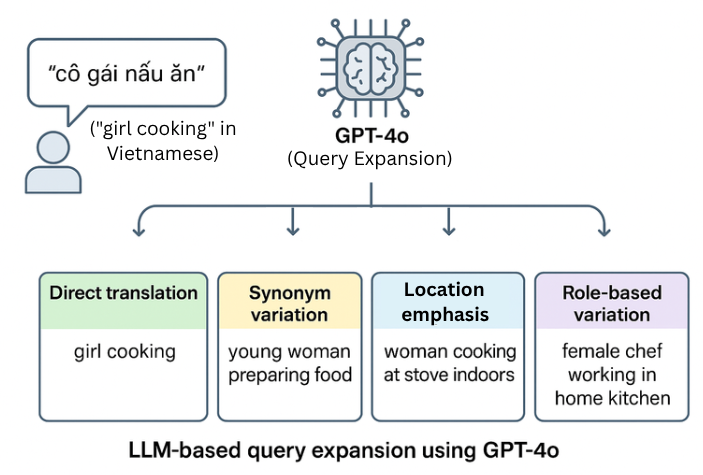
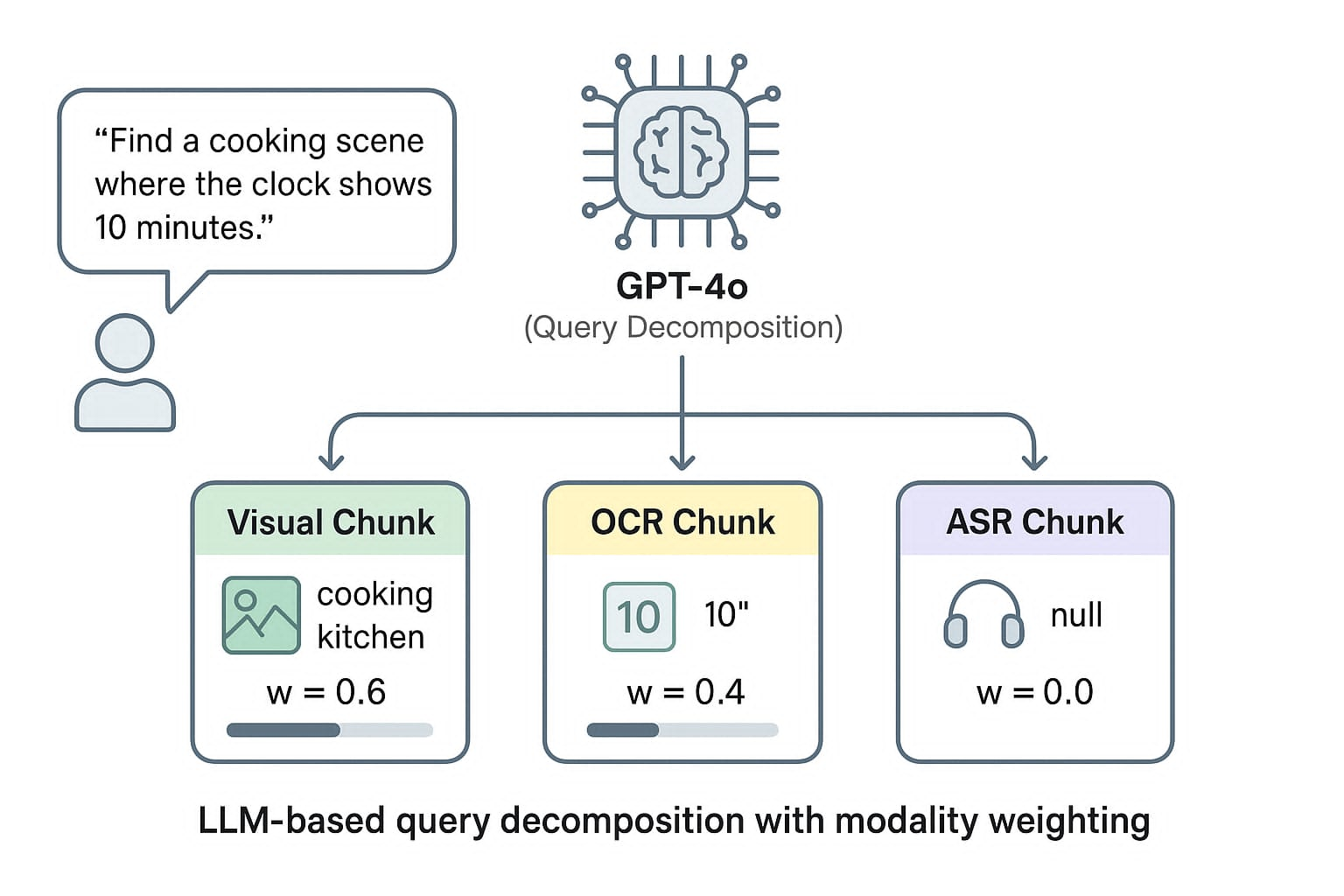
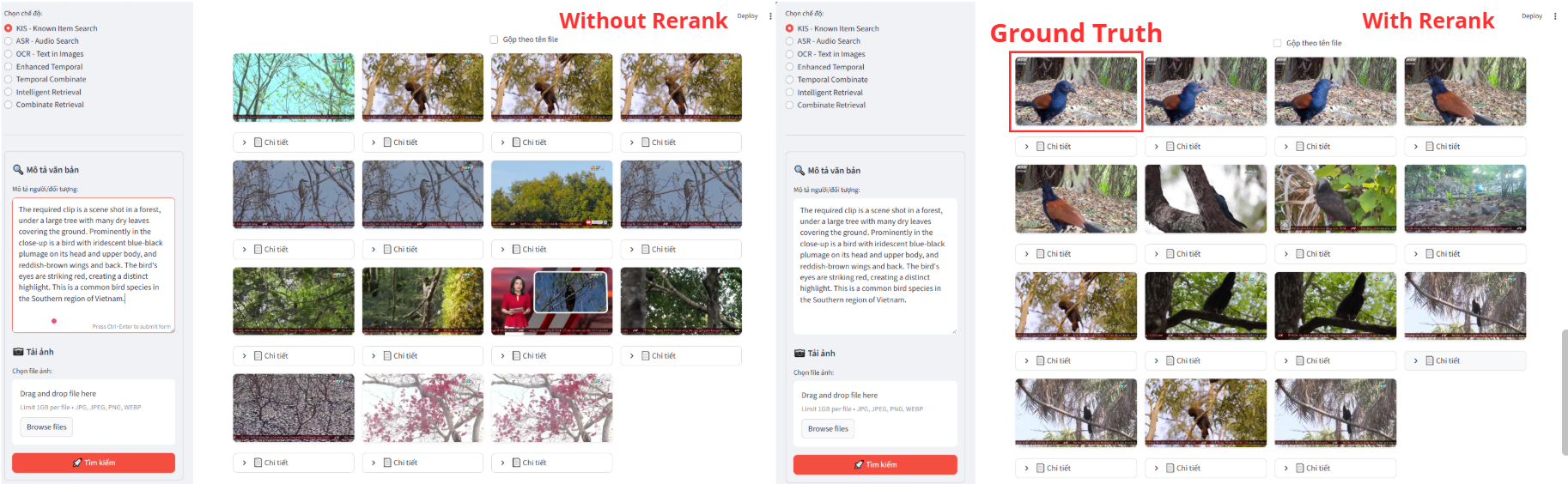
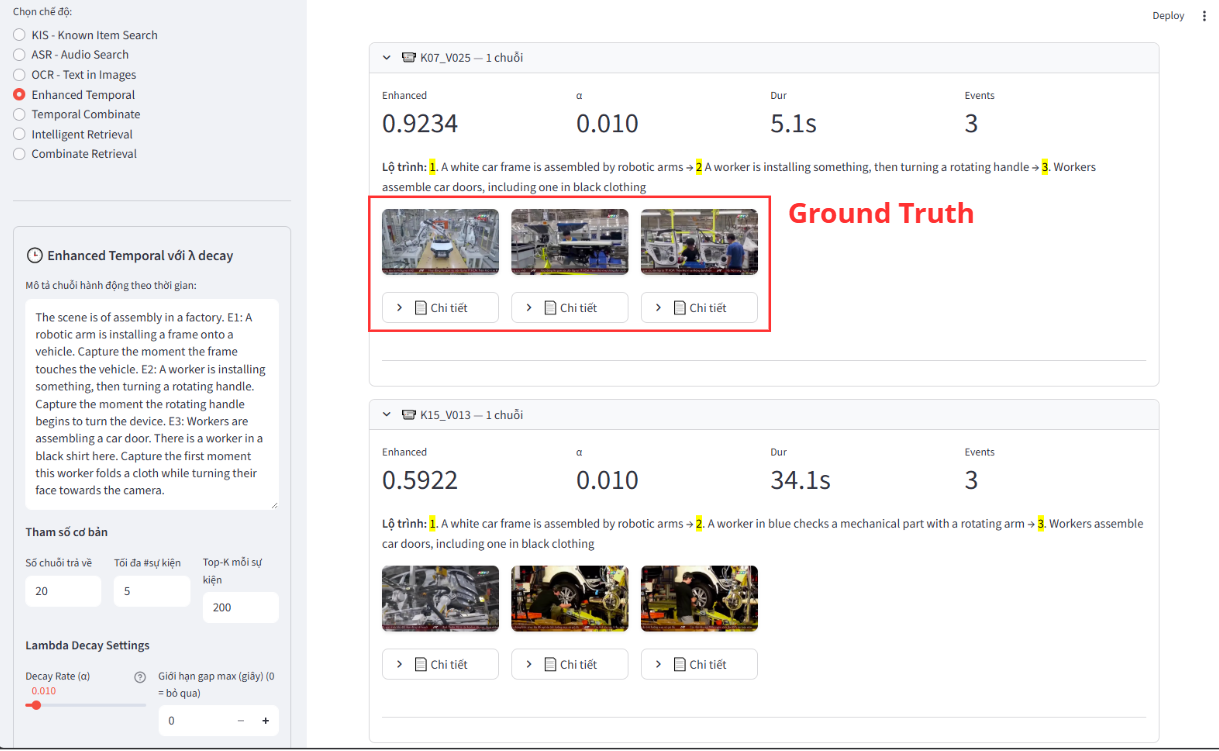
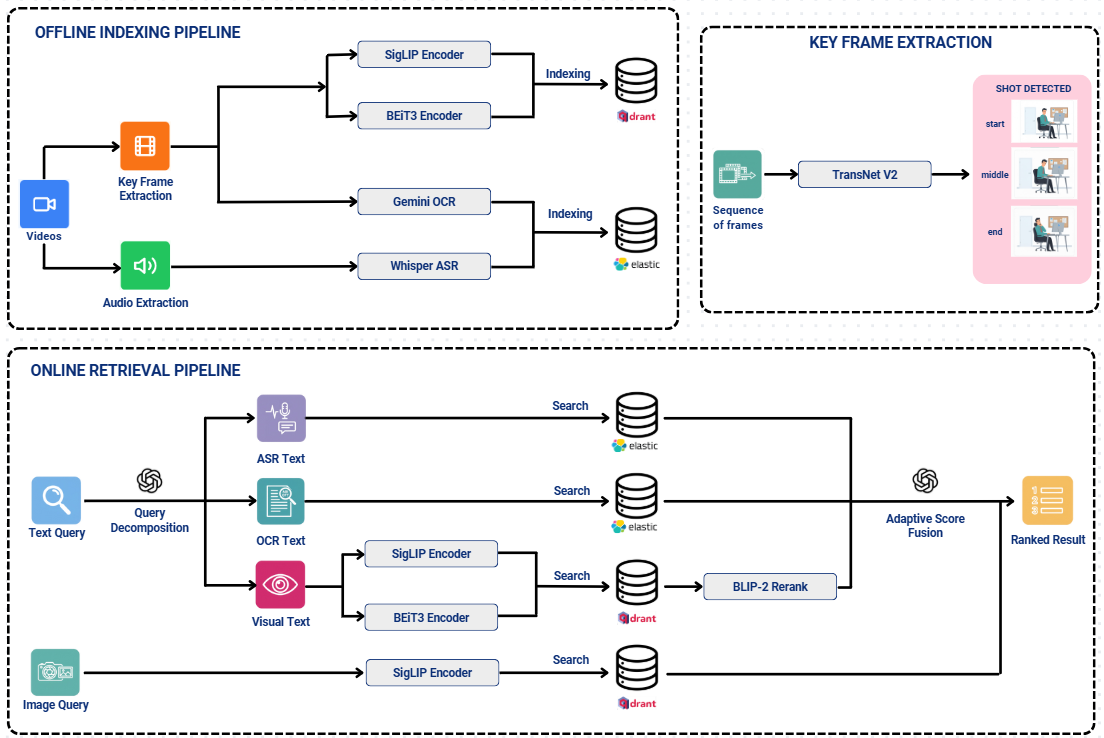
The exponential growth of video content has created an urgent need for efficient multimodal moment retrieval systems. However, existing approaches face three critical challenges: (1) fixed-weight fusion strategies fail across cross modal noise and ambiguous queries, (2) temporal modeling struggles to capture coherent event sequences while penalizing unrealistic gaps, and (3) systems require manual modality selection, reducing usability. We propose a unified multimodal moment retrieval system with three key innovations. First, a cascaded dual-embedding pipeline combines BEIT-3 and SigLIP for broad retrieval, refined by BLIP-2 based reranking to balance recall and precision. Second, a temporal-aware scoring mechanism applies exponential decay penalties to large temporal gaps via beam search, constructing coherent event sequences rather than isolated frames. Third, Agent-guided query decomposition (GPT-4o) automatically interprets ambiguous queries, decomposes them into modality specific sub-queries (visual/OCR/ASR), and performs adaptive score fusion eliminating manual modality selection. Qualitative analysis demonstrates that our system effectively handles ambiguous queries, retrieves temporally coherent sequences, and dynamically adapts fusion strategies, advancing interactive moment search capabilities.