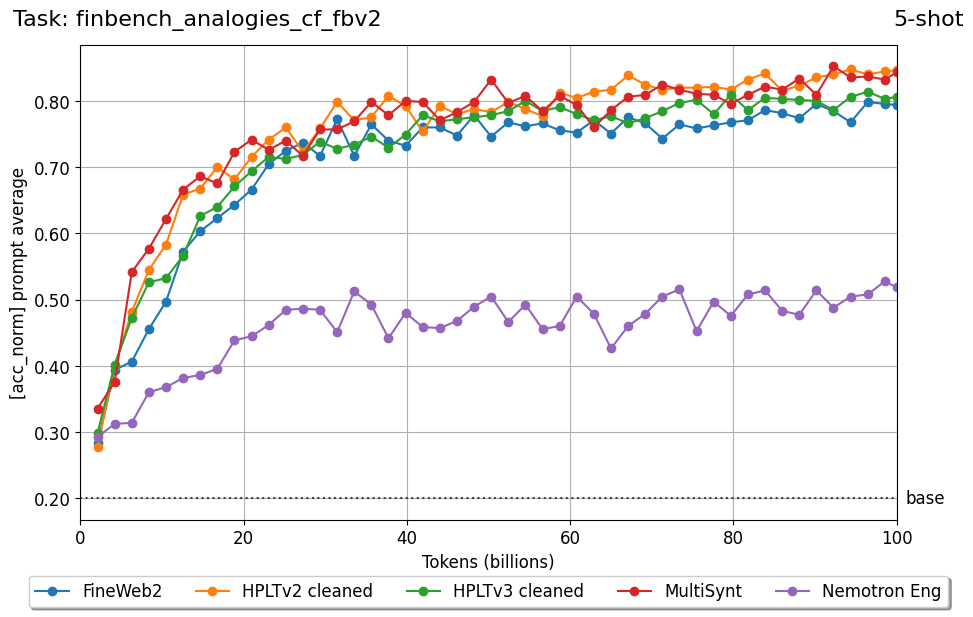
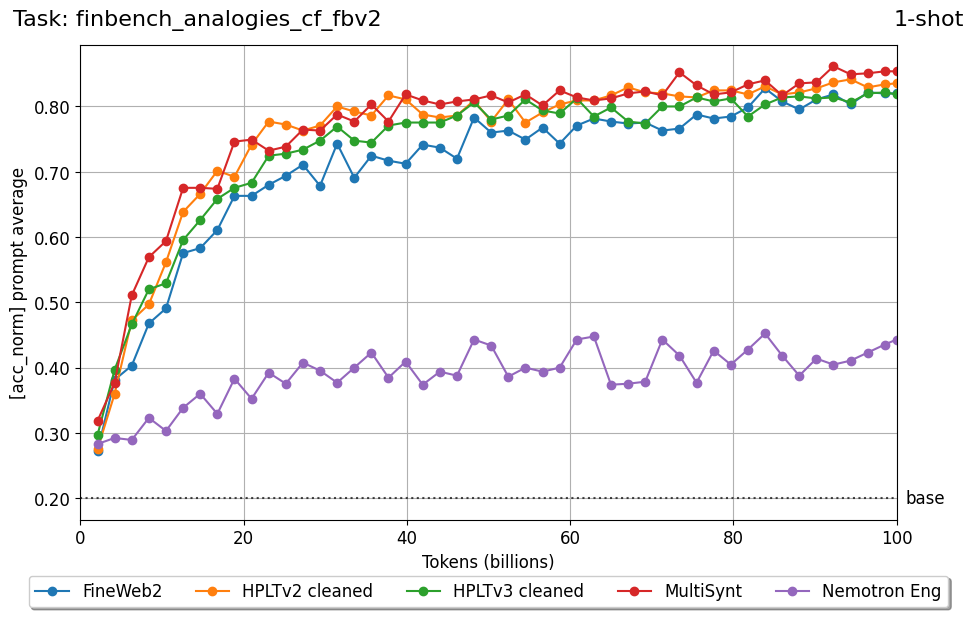
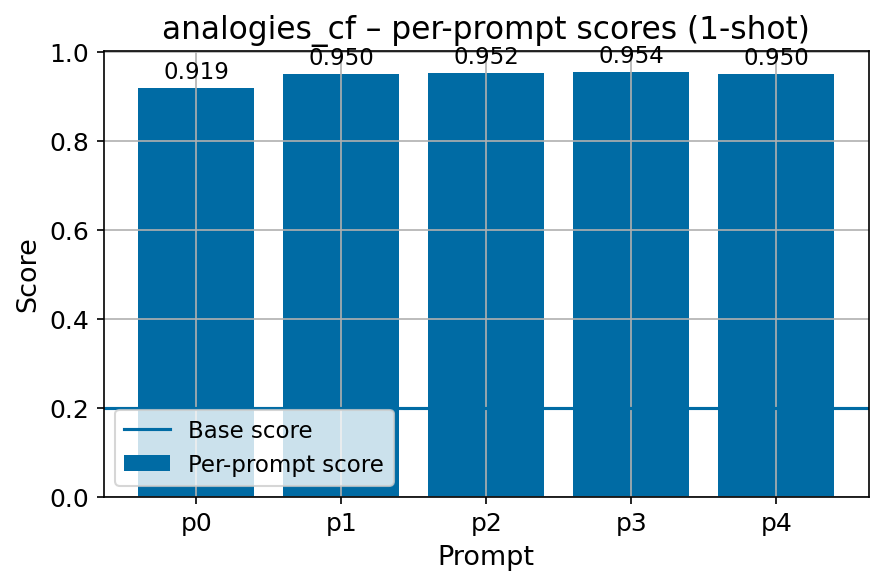
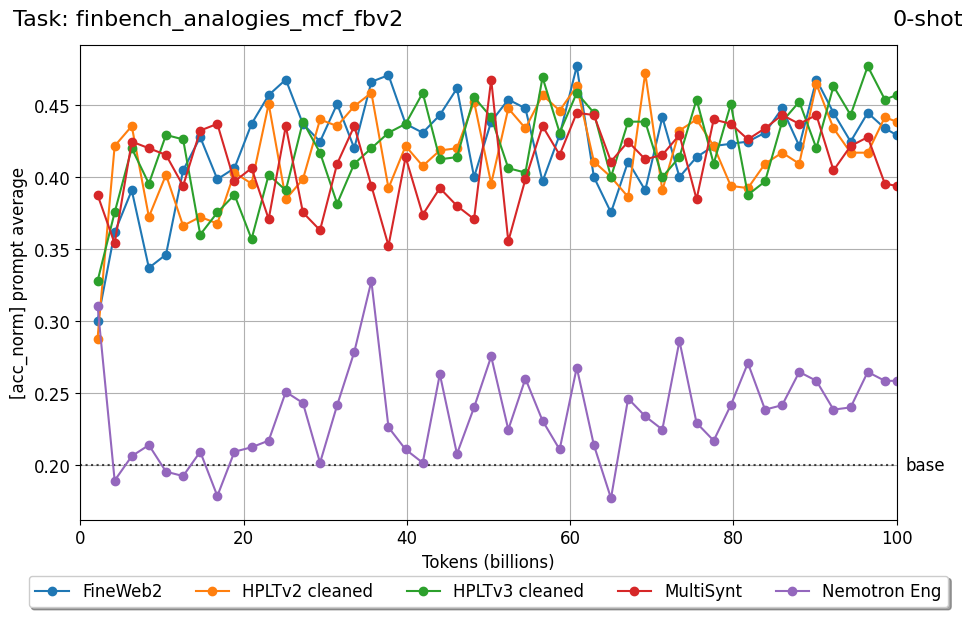
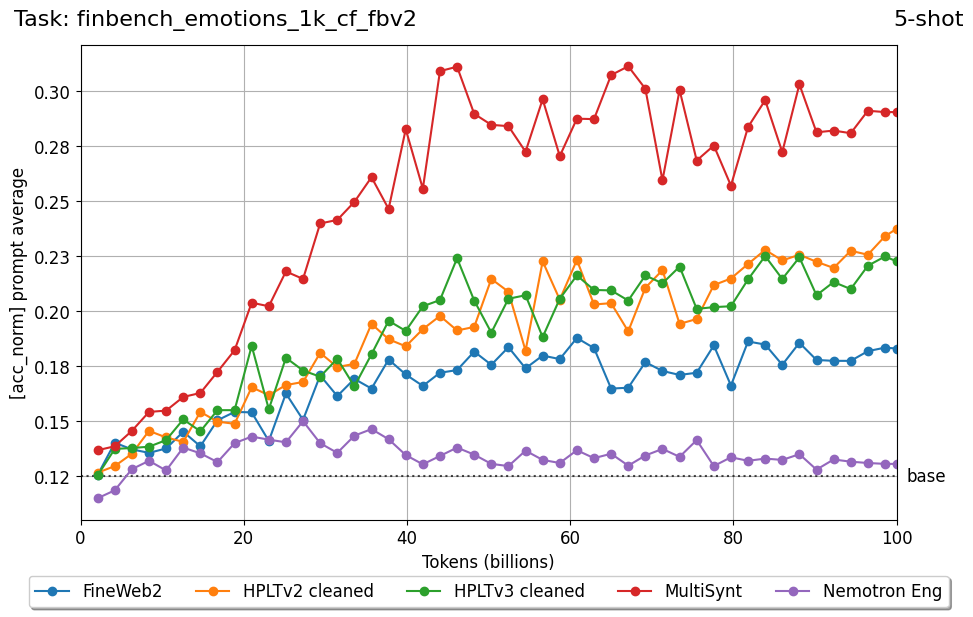
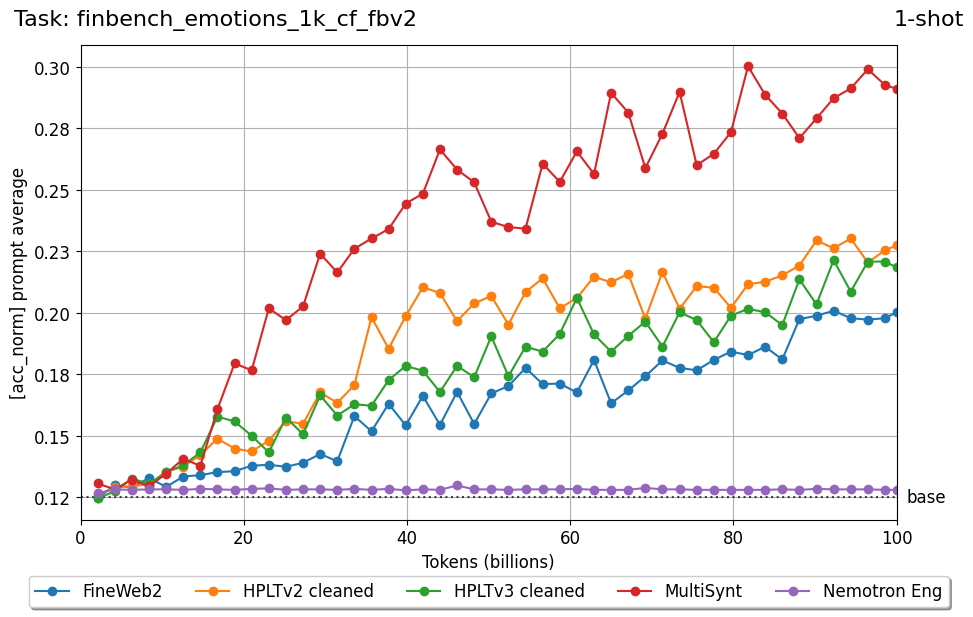
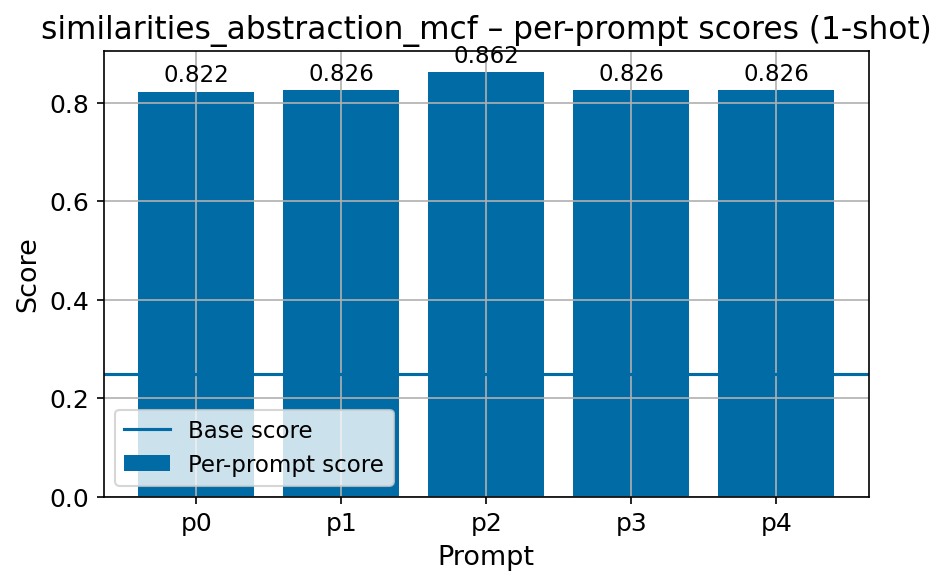
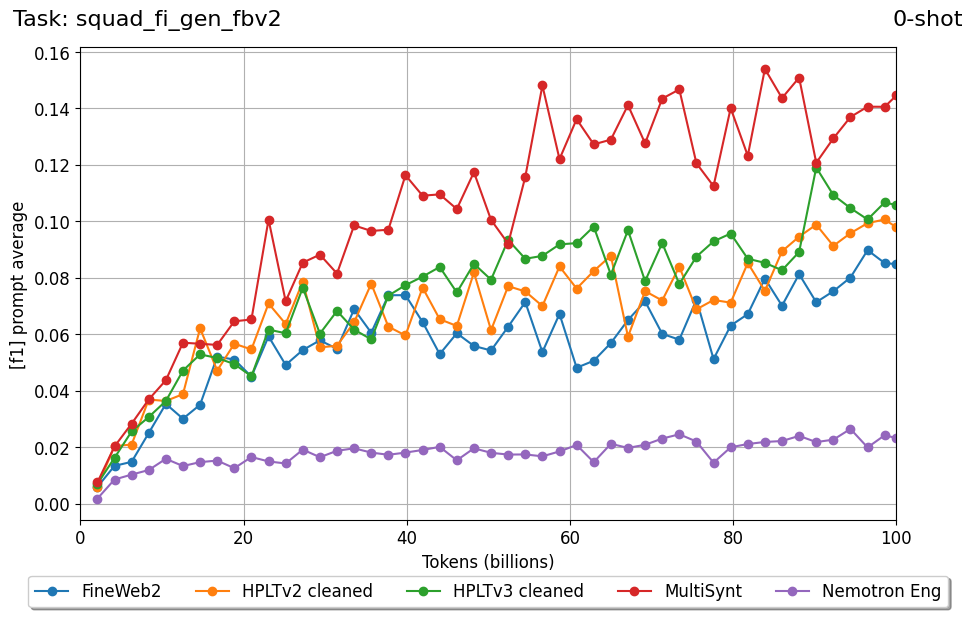
We introduce FIN-bench-v2, a unified benchmark suite for evaluating large language models in Finnish. FIN-bench-v2 consolidates Finnish versions of widely used benchmarks together with an updated and expanded version of the original FIN-bench into a single, consistently formatted collection, covering multiple-choice and generative tasks across reading comprehension, commonsense reasoning, sentiment analysis, world knowledge, and alignment. All datasets are converted to HuggingFace Datasets, which include both cloze and multiple-choice prompt formulations with five variants per task, and we incorporate human annotation or review for machinetranslated resources such as GoldenSwag and XED. To select robust tasks, we pretrain a set of 2.15B-parameter decoder-only models and use their learning curves to compute monotonicity, signal-to-noise, non-random performance, and model ordering consistency, retaining only tasks that satisfy all criteria. We further evaluate a set of larger instruction-tuned models to characterize performance across tasks and prompt formulations. All datasets, prompts, and evaluation configurations are publicly available via our fork of the Language Model Evaluation Harness at https://github.com/ LumiOpen/lm-evaluation-harness. Supplementary resources are released in a separate repository at https://github.com/ TurkuNLP/FIN-bench-v2.
Large language models (LLMs) have rapidly evolved into a central focus of modern artificial intelligence research, driving substantial progress in natural language understanding and generation. Originating from the Transformer model architecture introduced by Vaswani et al. (2017), these models with billions of trainable parameters are typically trained on unprecedentedly large textual datasets. This extensive training enables them to achieve state-of-the-art performance across a broad spectrum of applications. Crucially, it empowers these models to generalize beyond their original training objectives via in-context learning, allowing them to adapt to novel problems without the need for task-specific parameter updates. This distinct capability highlights their utility as versatile, general-purpose computational systems.
Model evaluation is a crucial part of research and deployment. Most evaluation resources are in English, hindering model development for lowresource languages such as Finnish. We have tried to mitigate this challenge by introducing the first medium-scale effort for generative model evaluation with the original FIN-bench (Luukkonen et al., 2023). Finnish has also been included in EuroEval (Nielsen et al., 2024), MMTEB (Enevoldsen et al., 2025), and GlotEval (Luo et al., 2025). However, these resources have their drawbacks:
• Data quality. Datasets’ quality for benchmarking different-sized models is not assessed, which may delimit a large proportion of tasks (Kydlíček et al., 2024), or samples are produced with machine translation without human review.
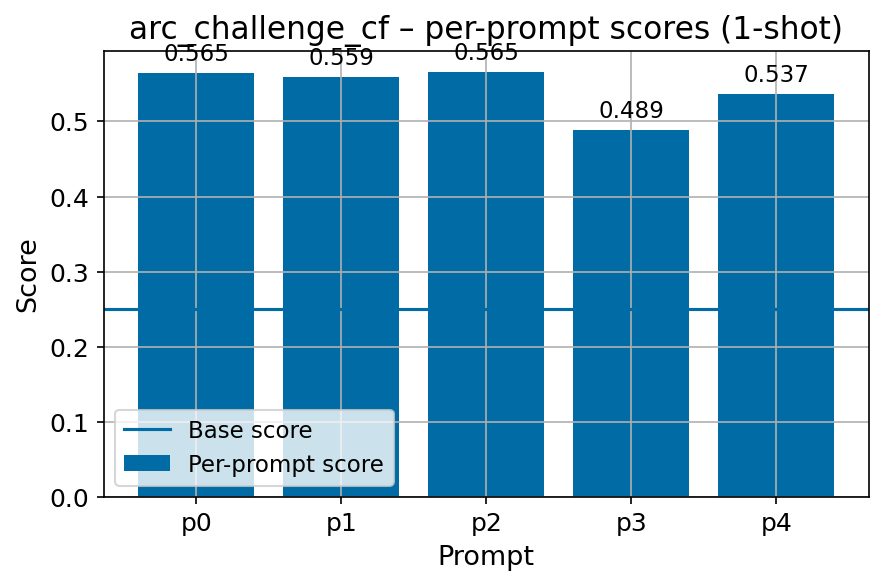
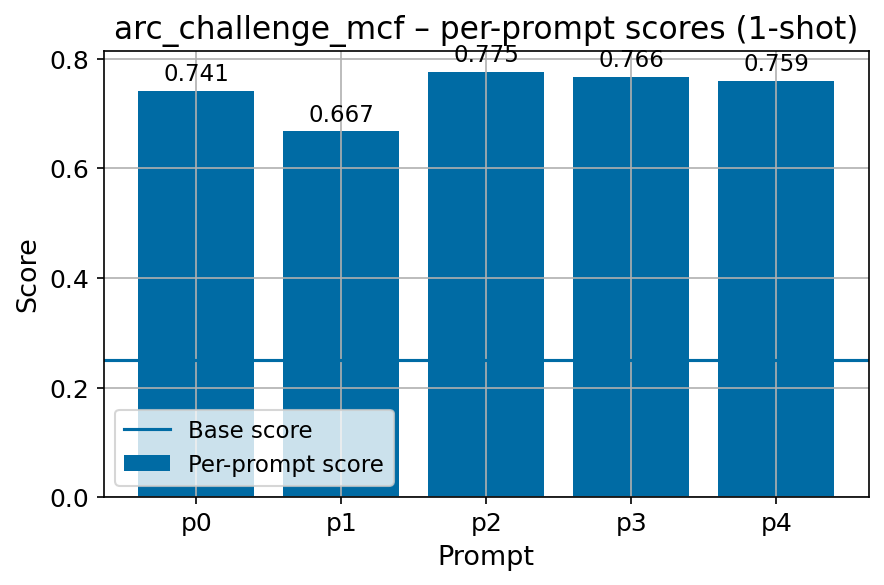
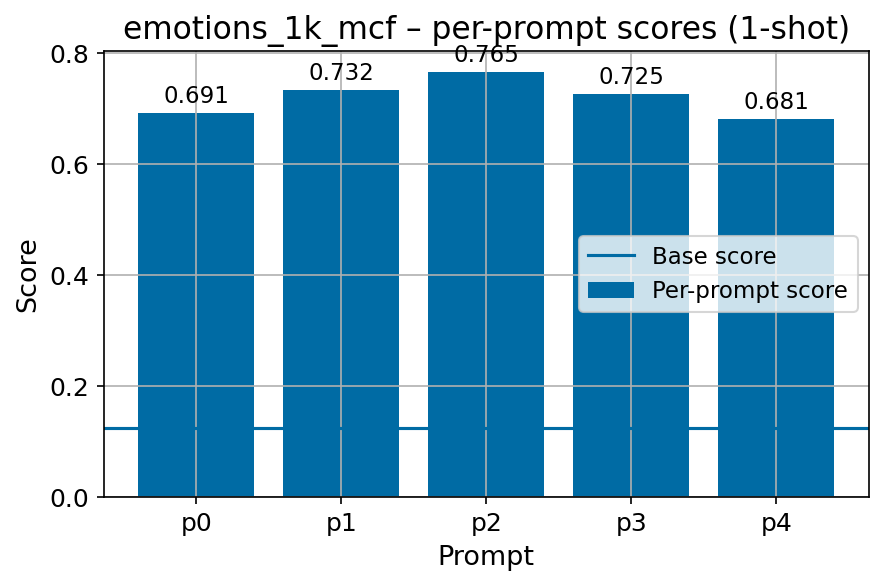
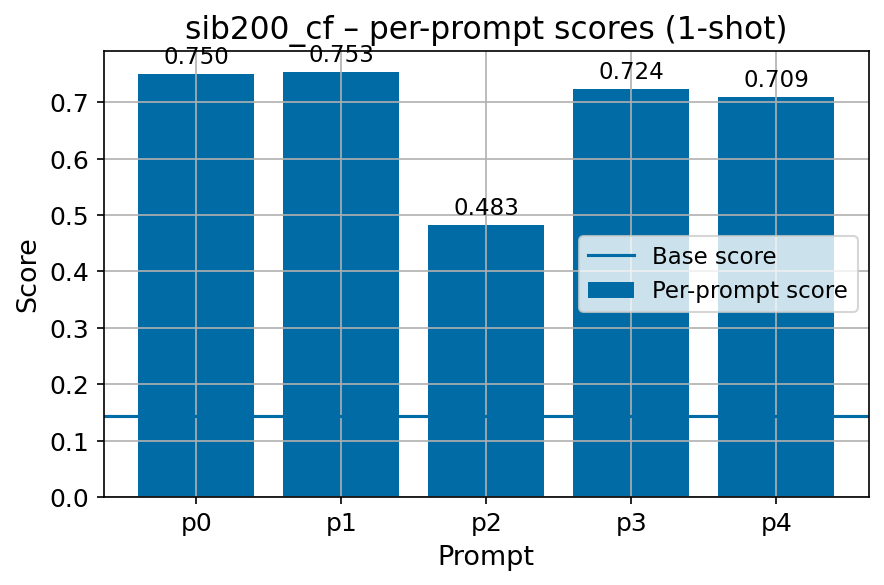
• Task formulation. Task formulations are simple and do not account for prompt sensitivity (Voronov et al., 2024), and are poorly compatible with non-instruction-tuned model evaluation (Gu et al., 2025).
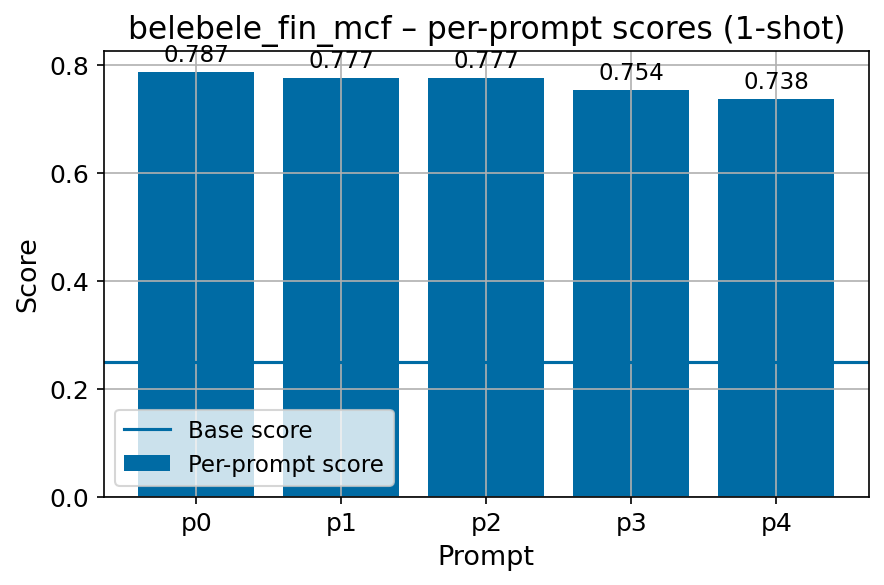
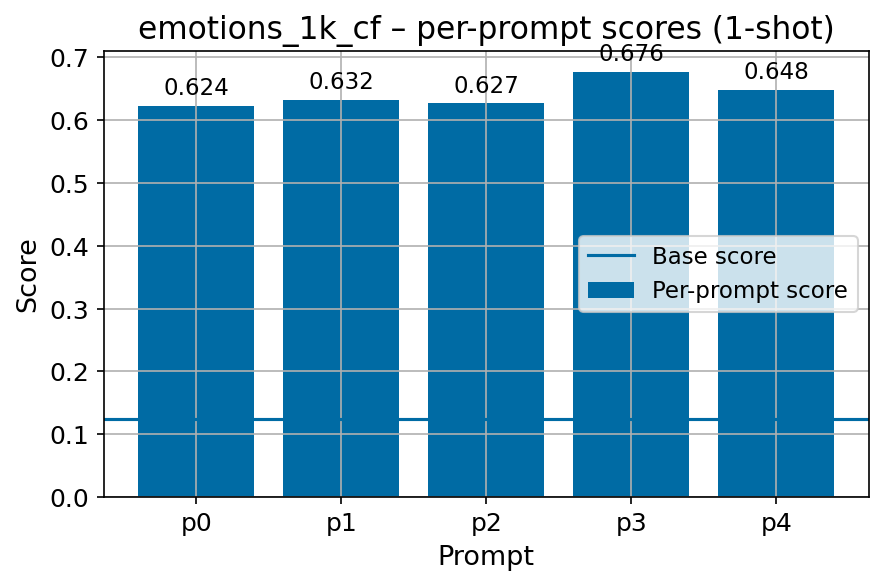
We present FIN-bench-v2, a broad collection of Finnish benchmark datasets compiled into a unified evaluation suite. We systematically evaluate the quality of benchmark datasets using various metrics, create a diverse collection of prompts by hand across all datasets with multiple human annotators, and manually refine the machine-translated GoldenSwag and XED datasets for accurate representation. We release compatible with the widely used Language Model Evaluation Harness (Gao et al., 2024).
Our main objectives for FIN-bench-v2 were modernizing the previous version of FIN-bench into a long-term-maintainable, easy-to-use format and expanding the benchmark to be more extensive and reliable for the evaluation of models of different sizes.
The original FIN-bench (Luukkonen et al., 2023) covered a broad, though not comprehensive, range of tasks for evaluating the Finnish language capabilities of LLMs. However, the evaluation libraries on which it relied had become deprecated, making it difficult to use in 2025. We therefore first modernized and ported FIN-bench to work on the LM Evaluation Harness (Gao et al., 2024), converting its datasets into the native format supported by the HuggingFace Datasets library to ensure longterm maintainability and ease of use. This modernization effort later evolved into FIN-bench-v2, a broader initiative to expand and diversify the benchmark’s task coverage. In particular, we sought to introduce new tasks from a variety of domains, including mathematics, geography, and medicine, to make the suite as comprehensive and representative as possible.
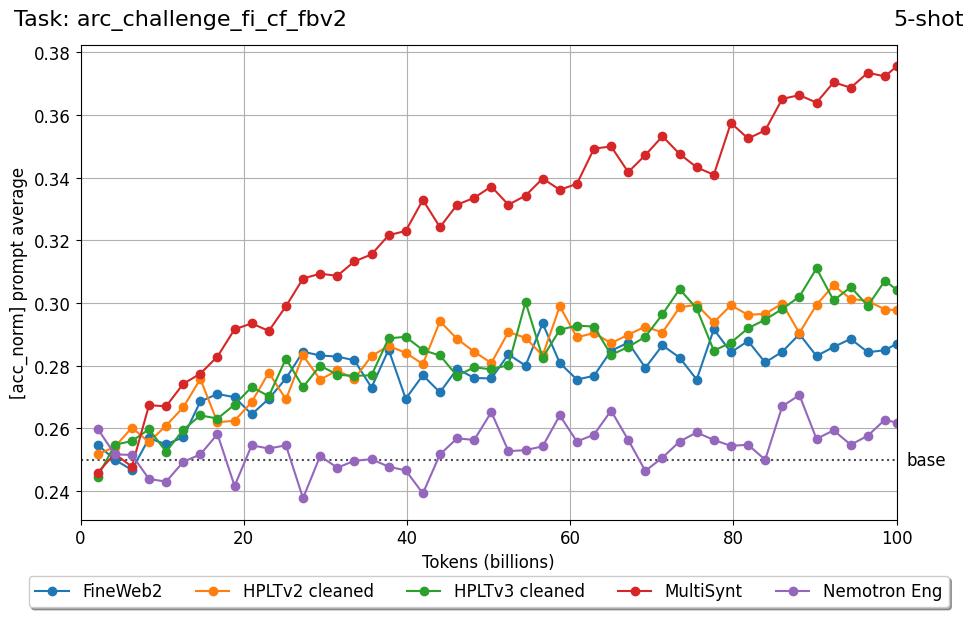
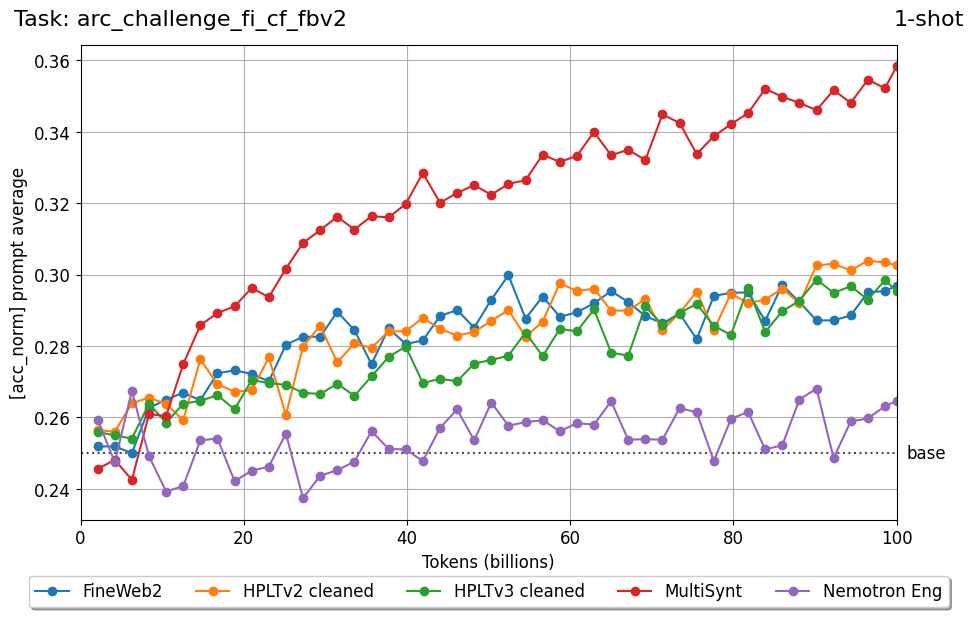
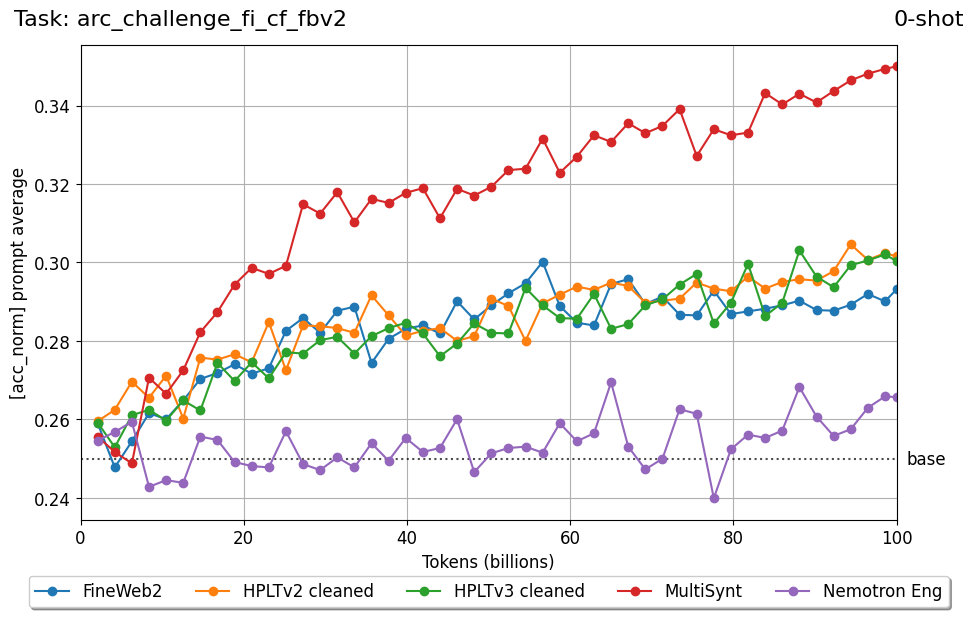
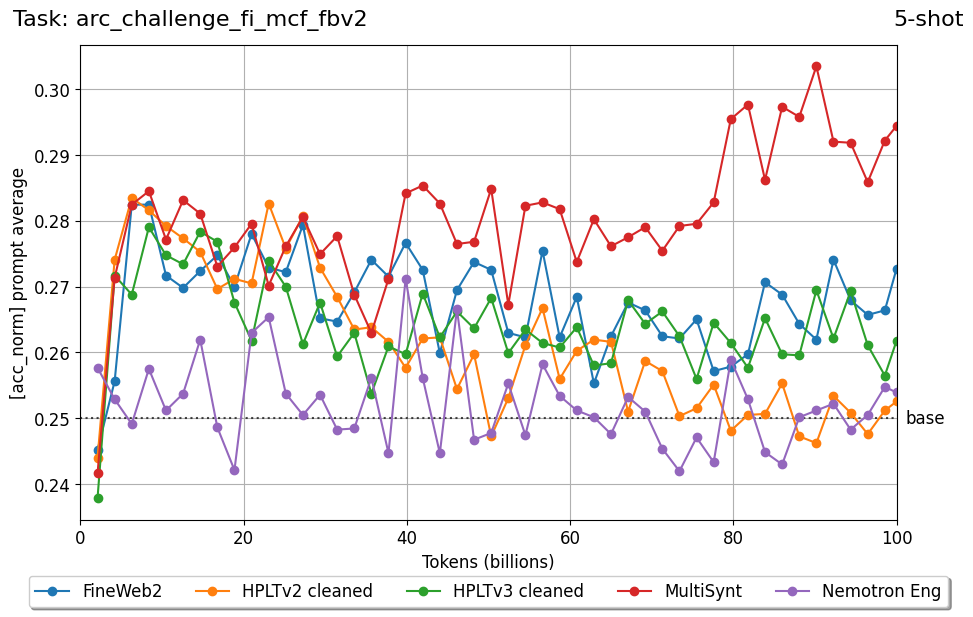
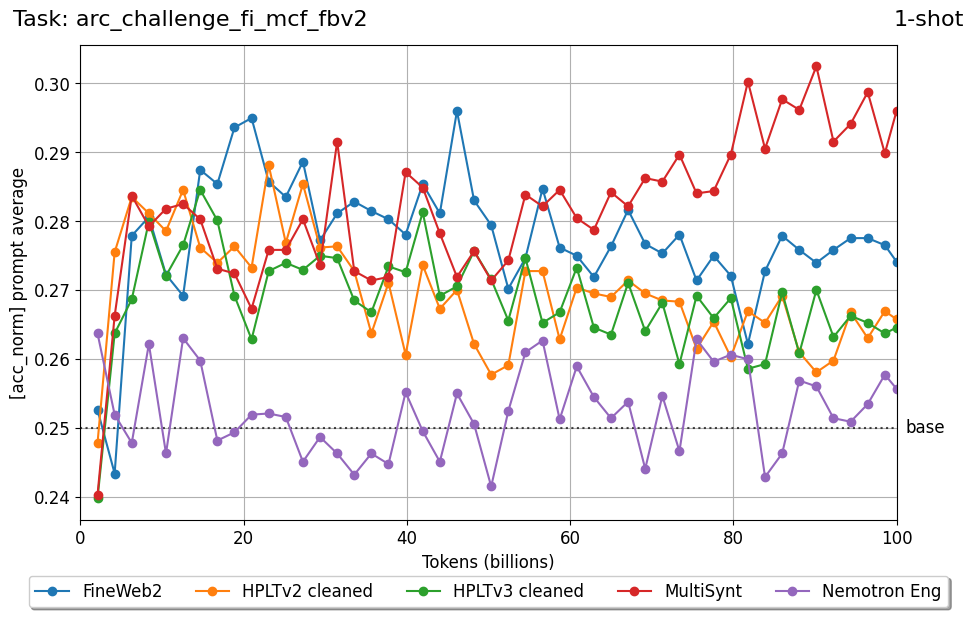
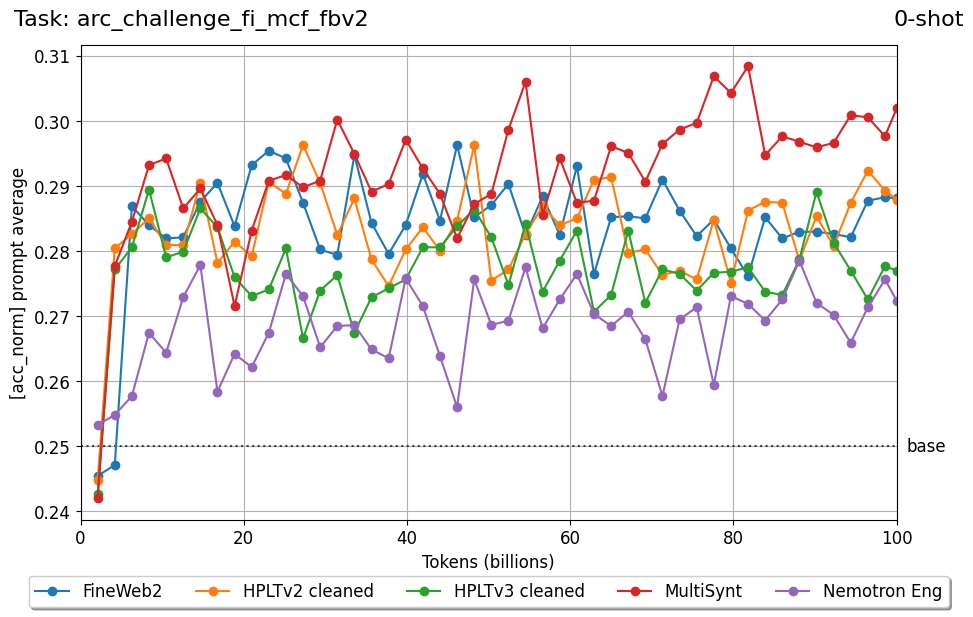
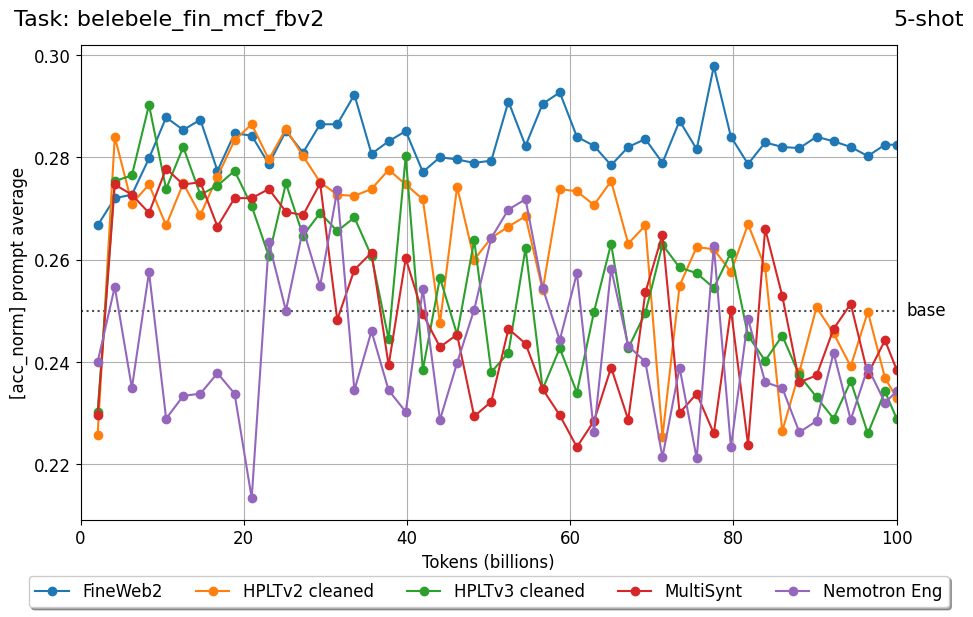
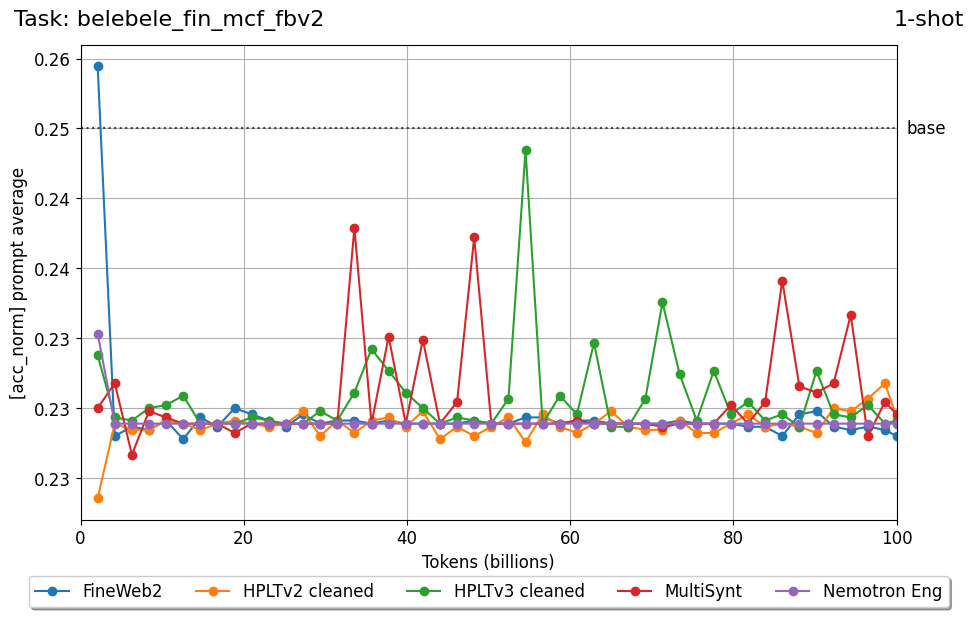
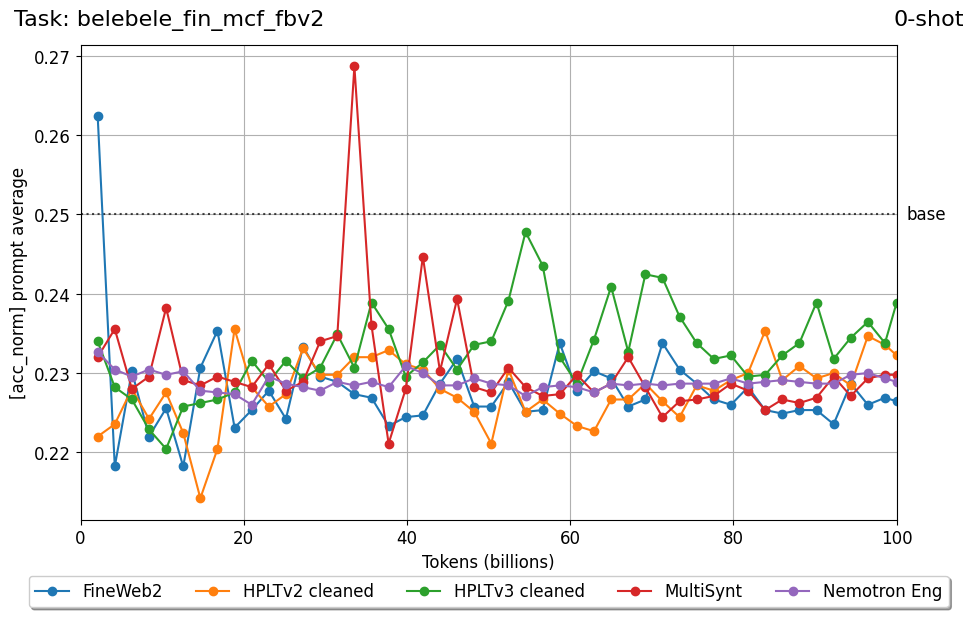
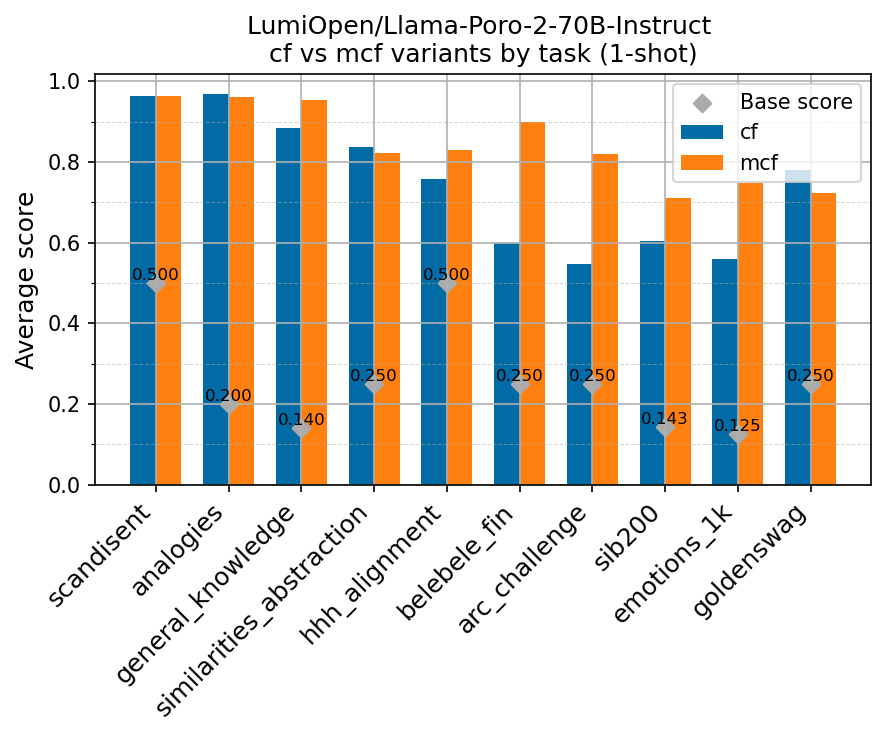
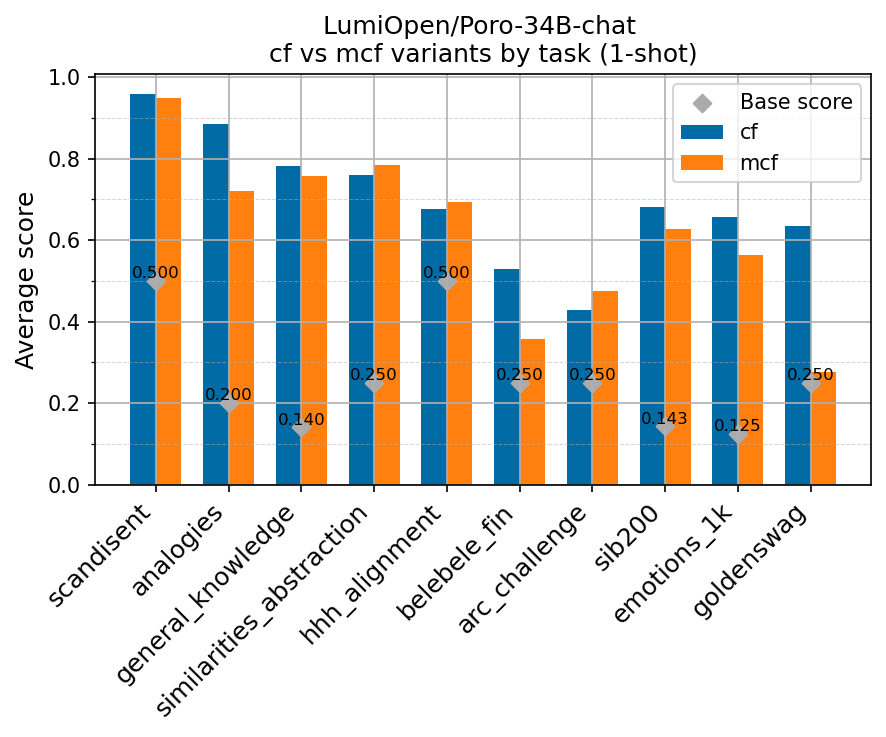
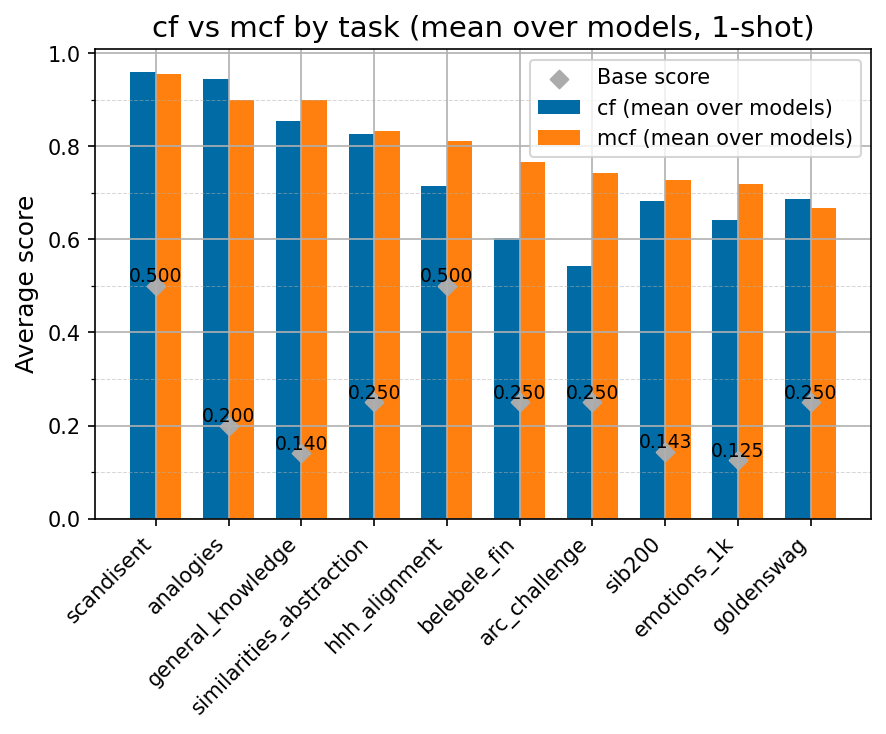
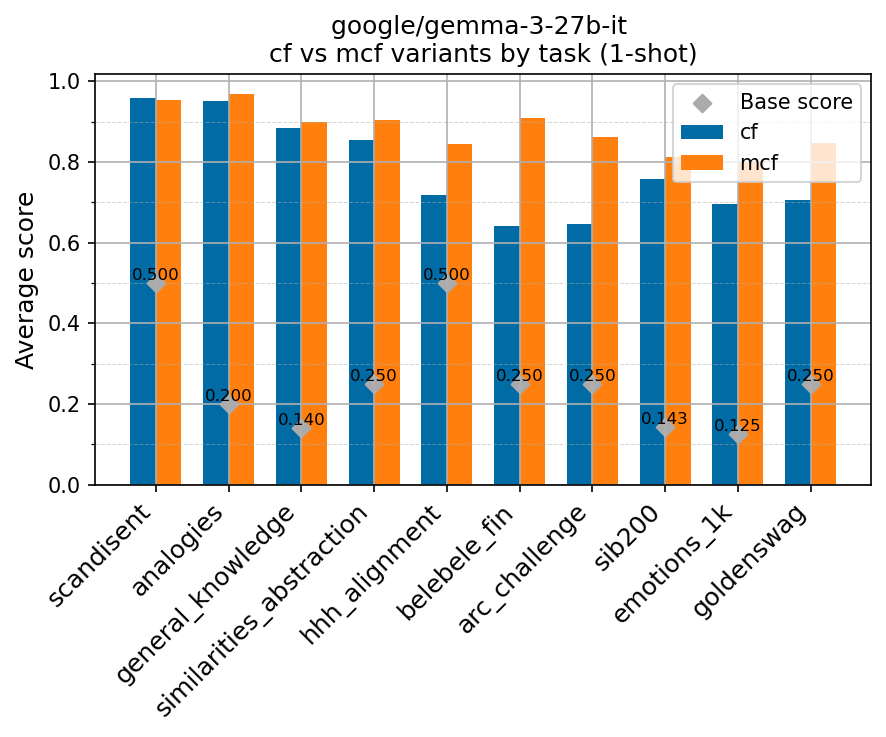
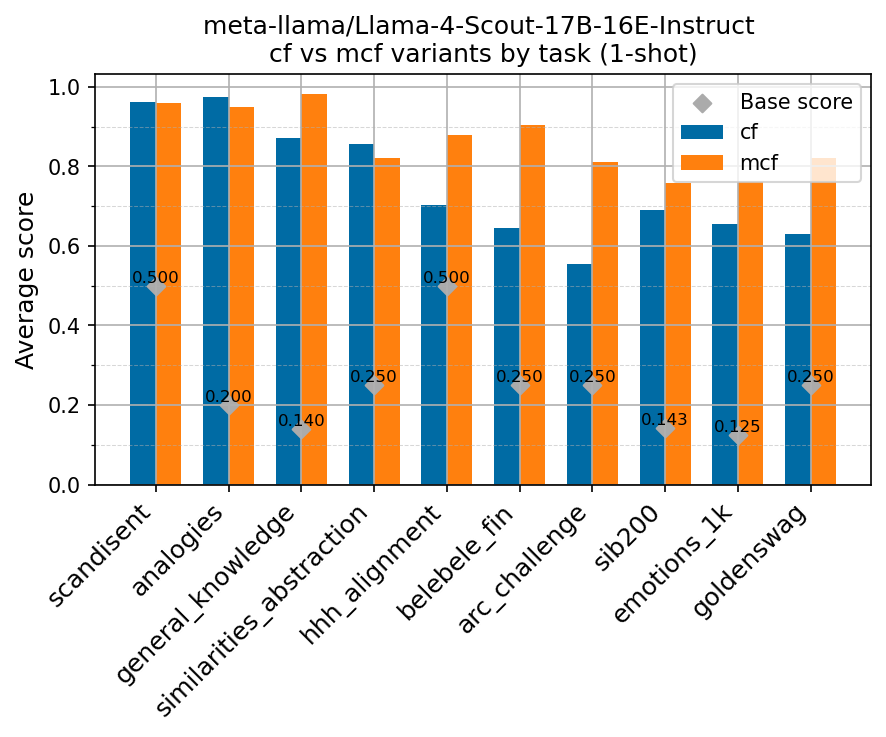
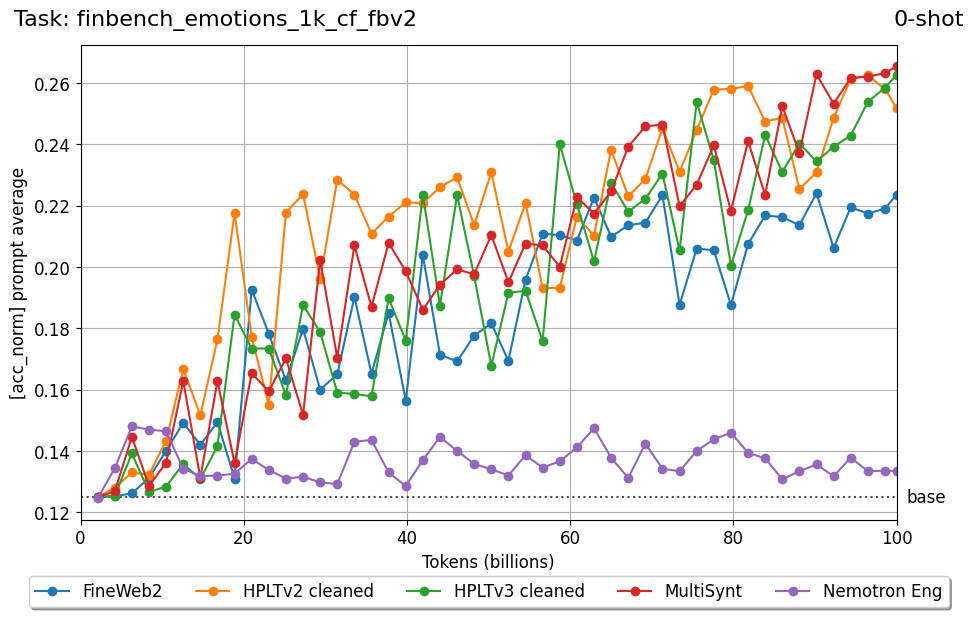
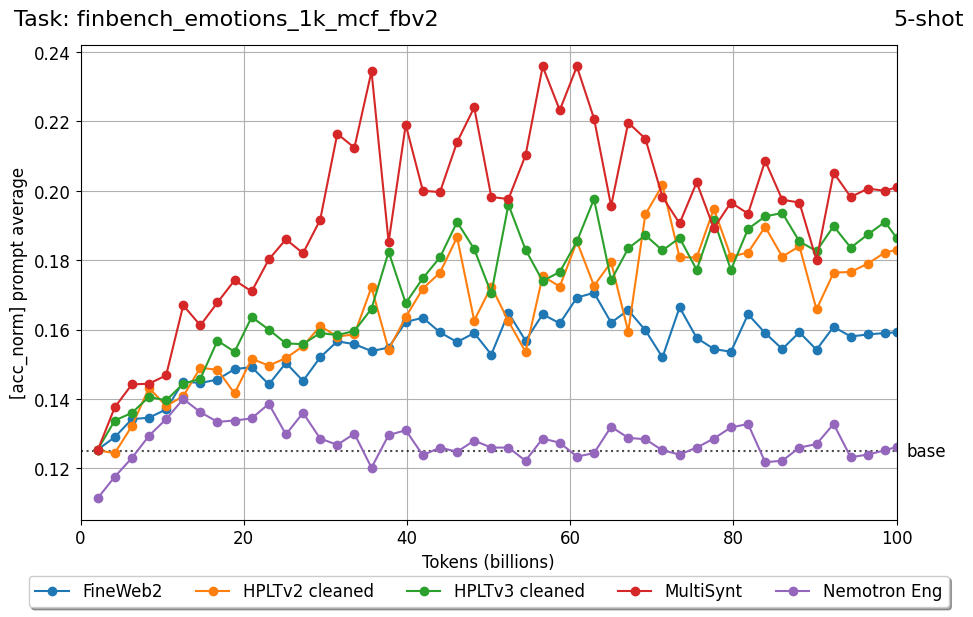
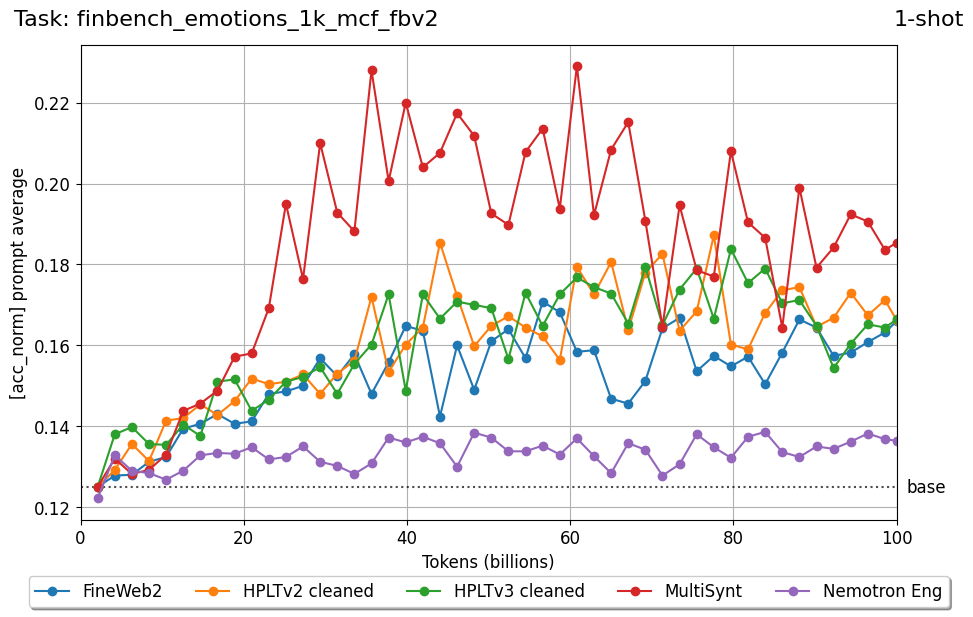
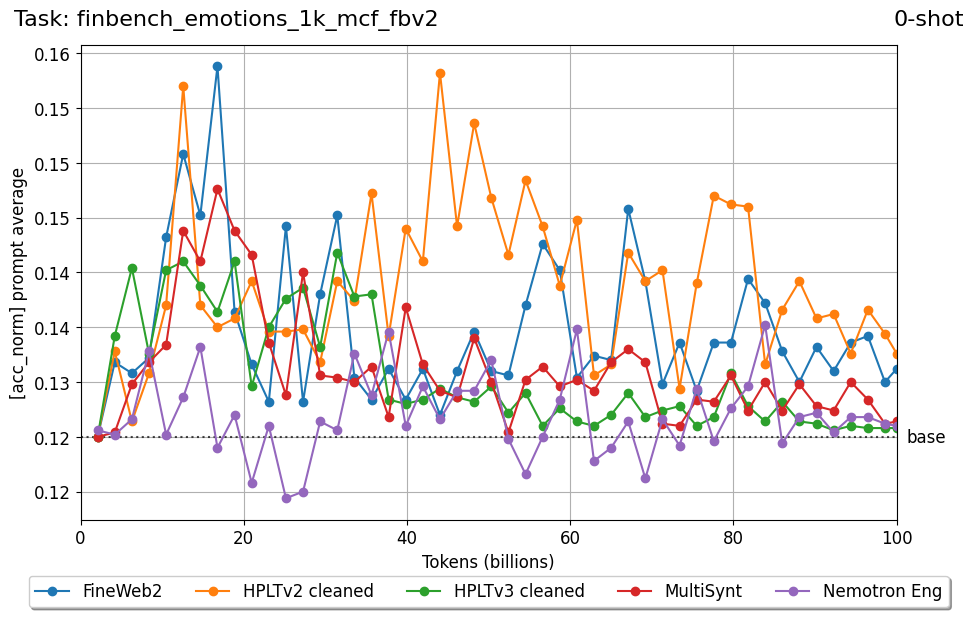
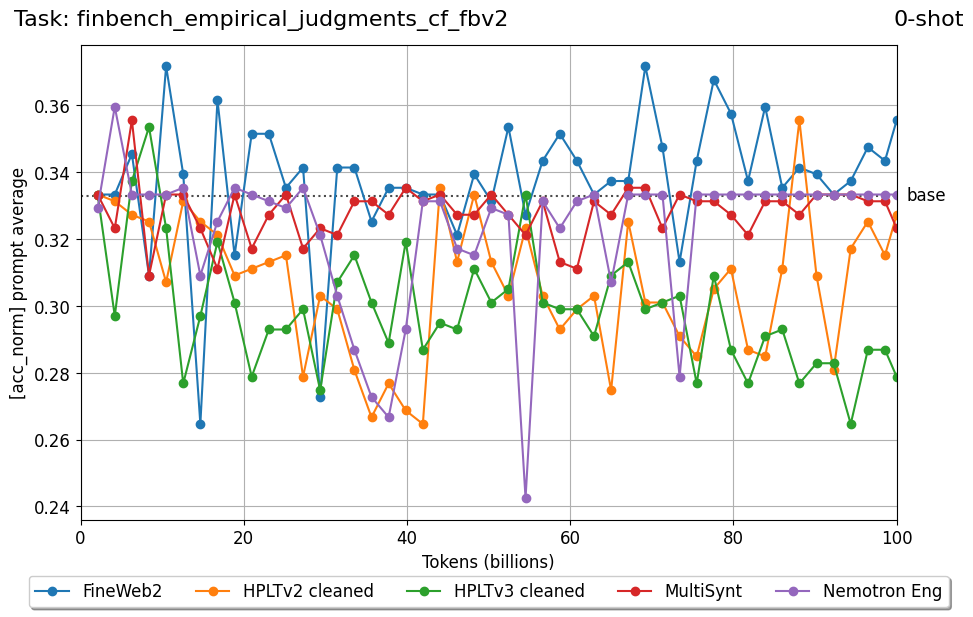
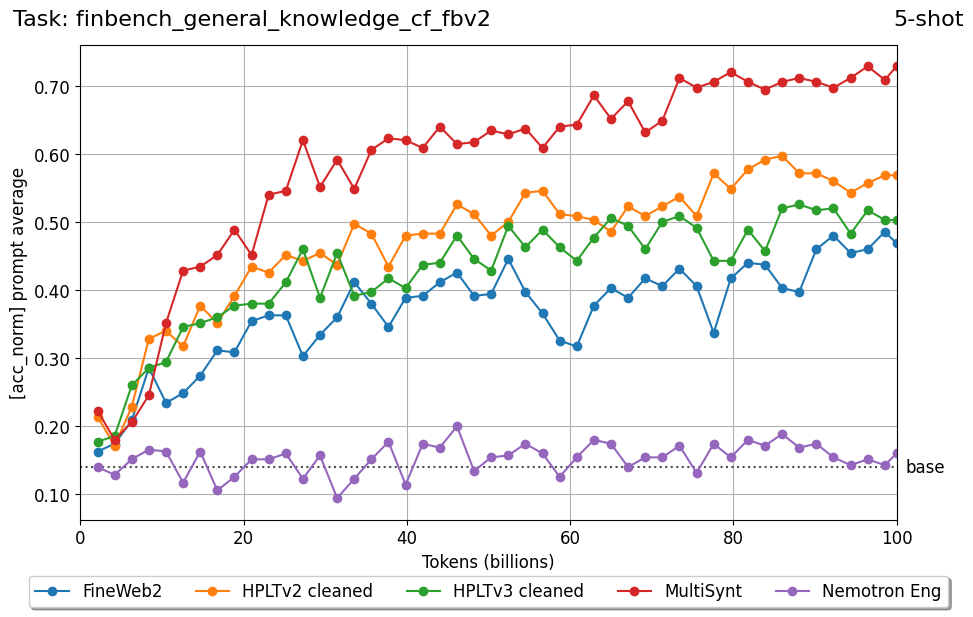
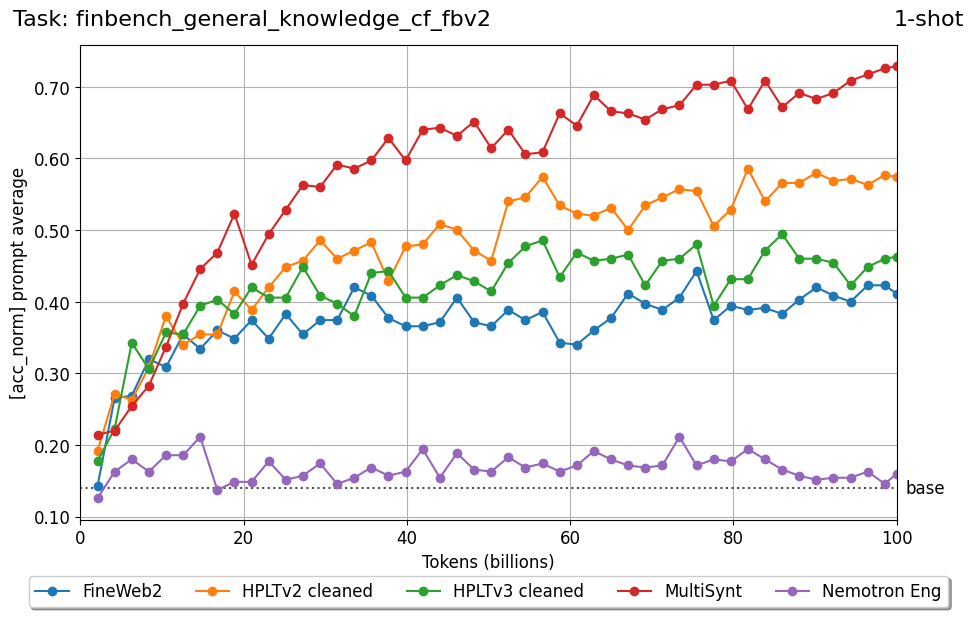
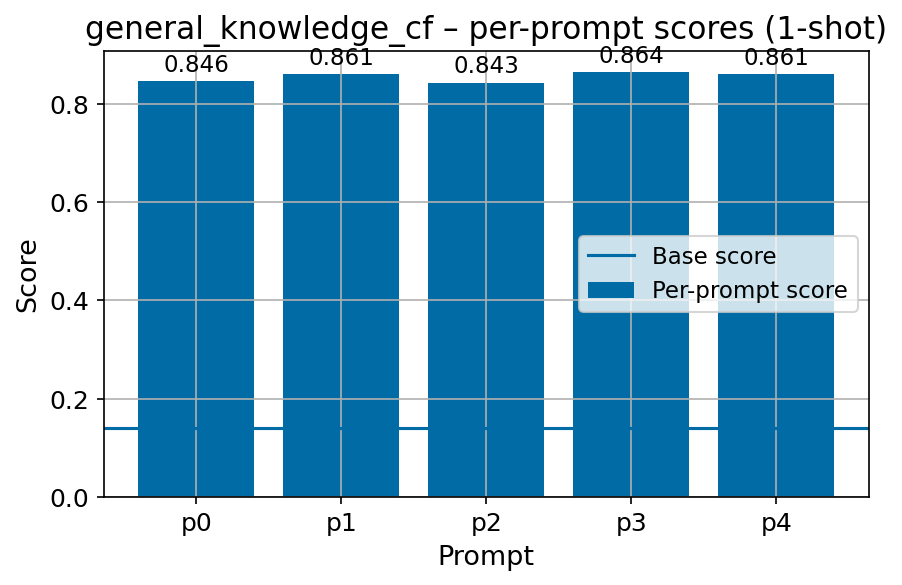
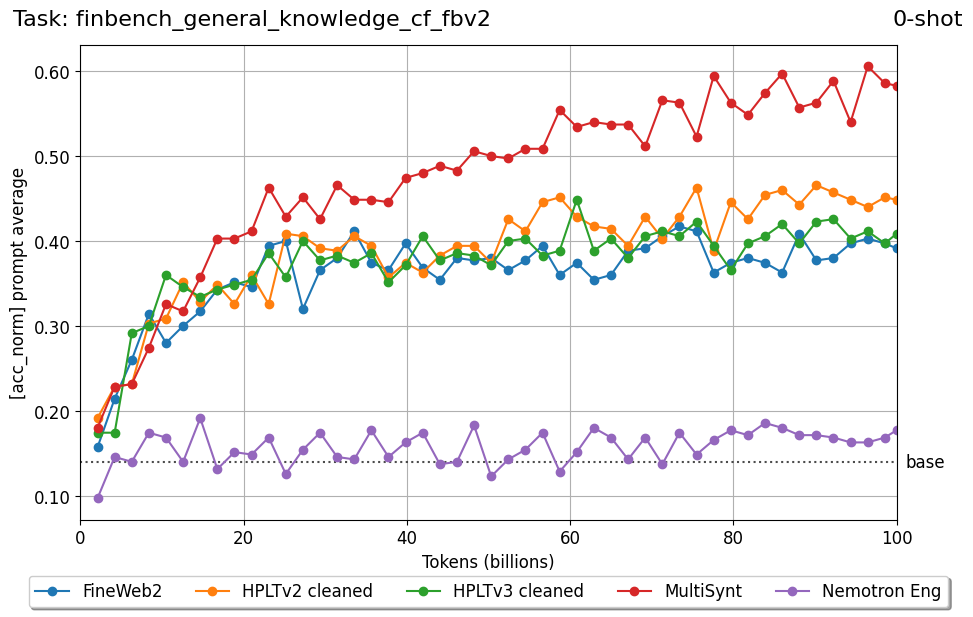
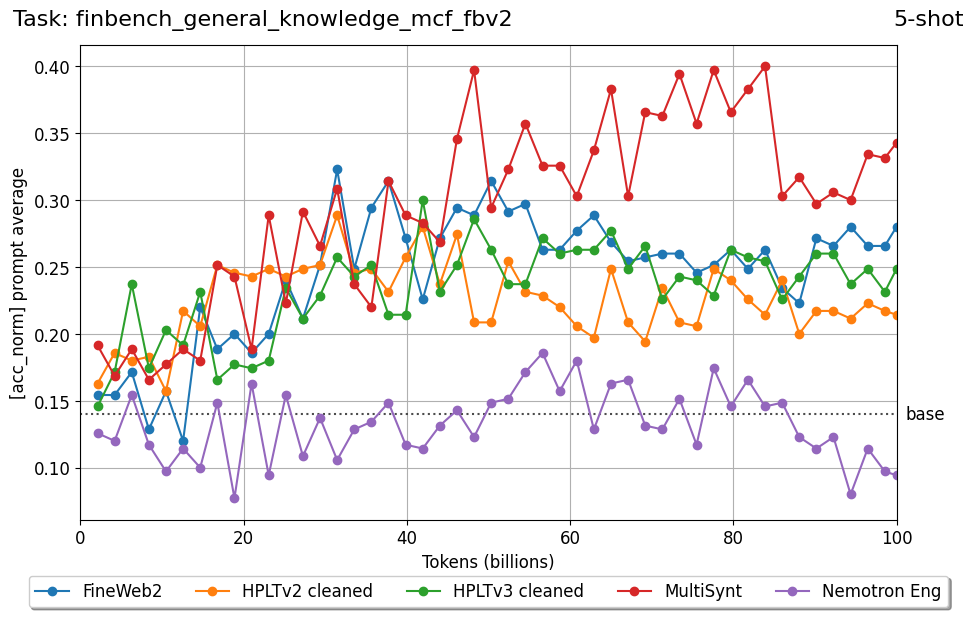
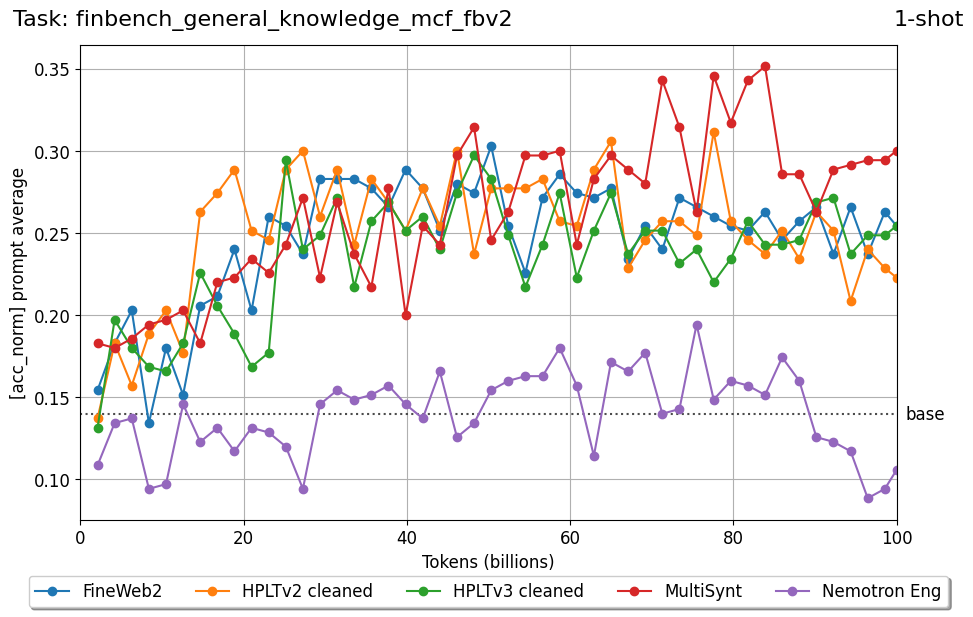
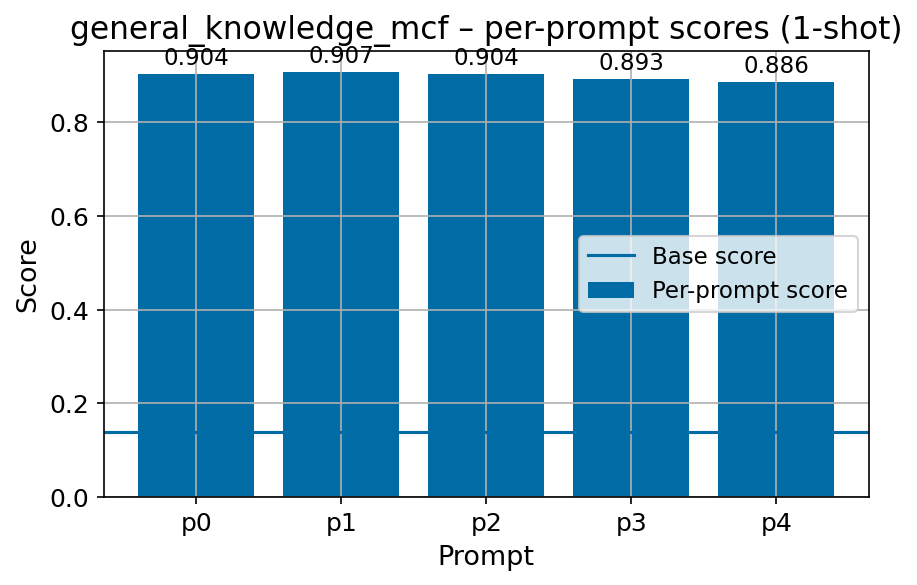
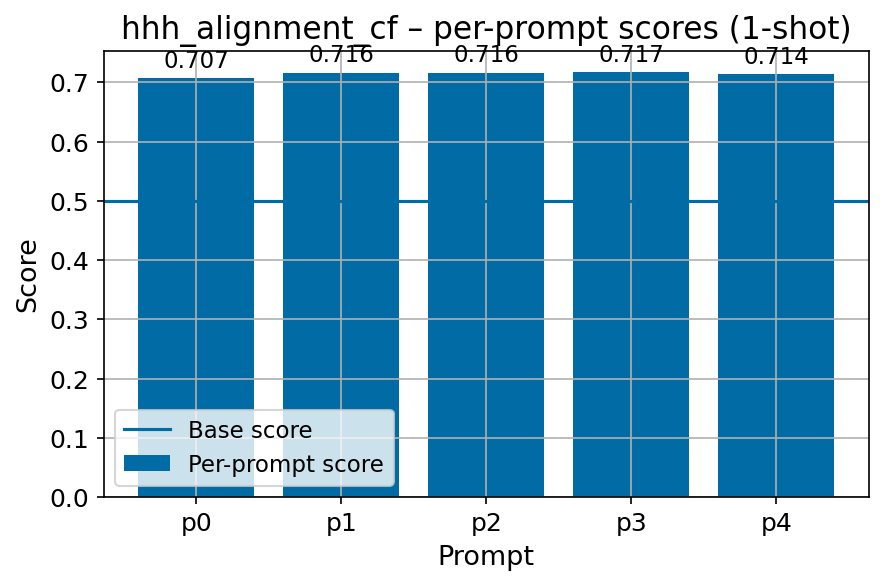
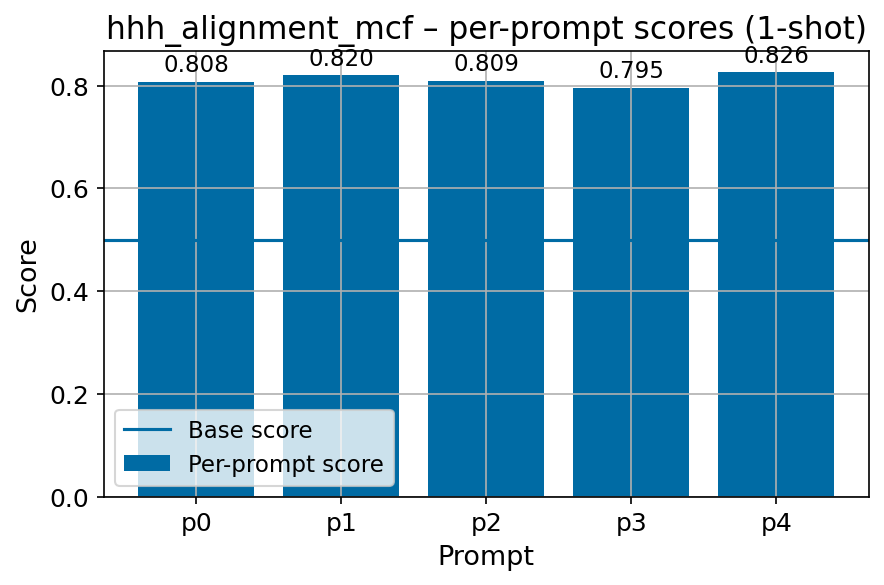
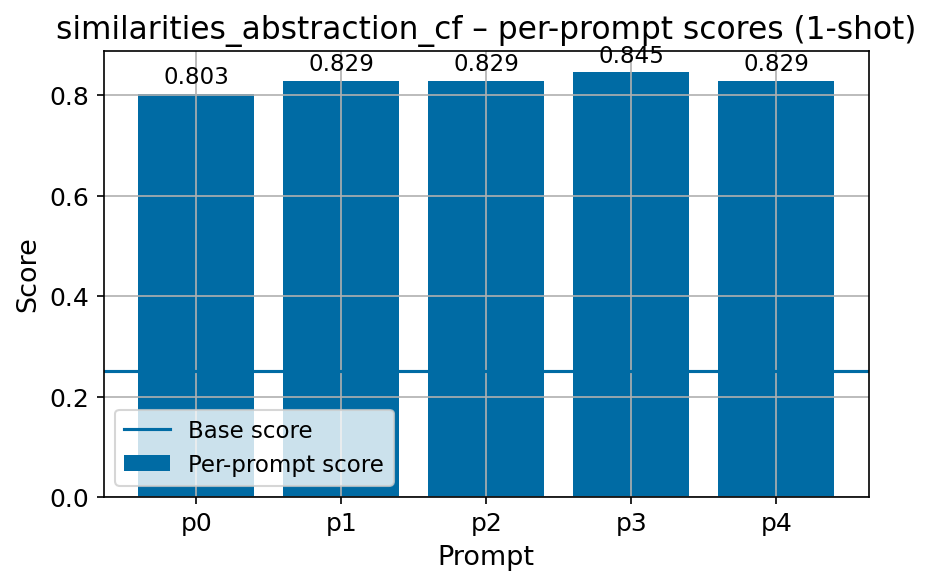
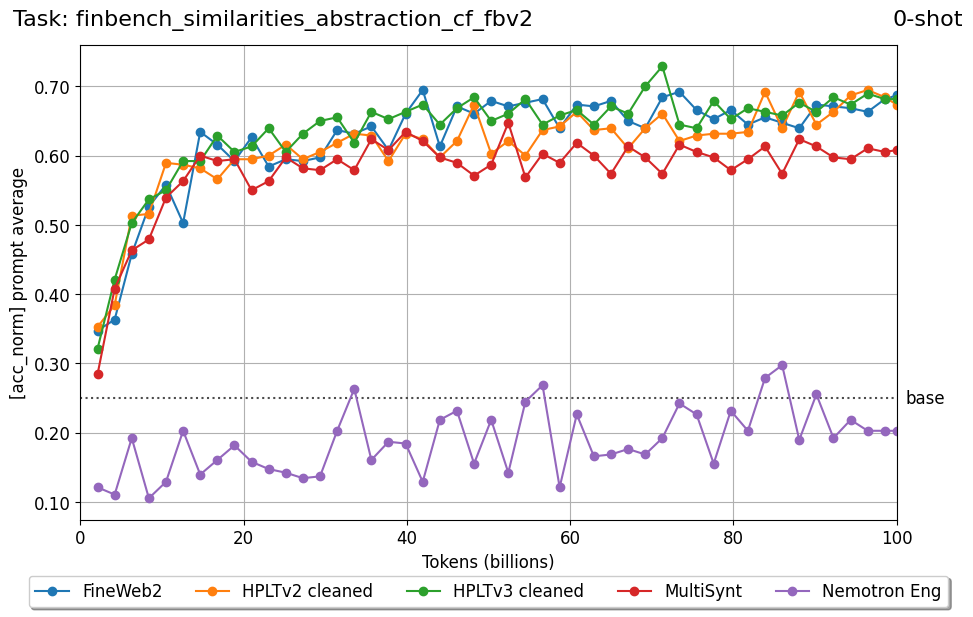
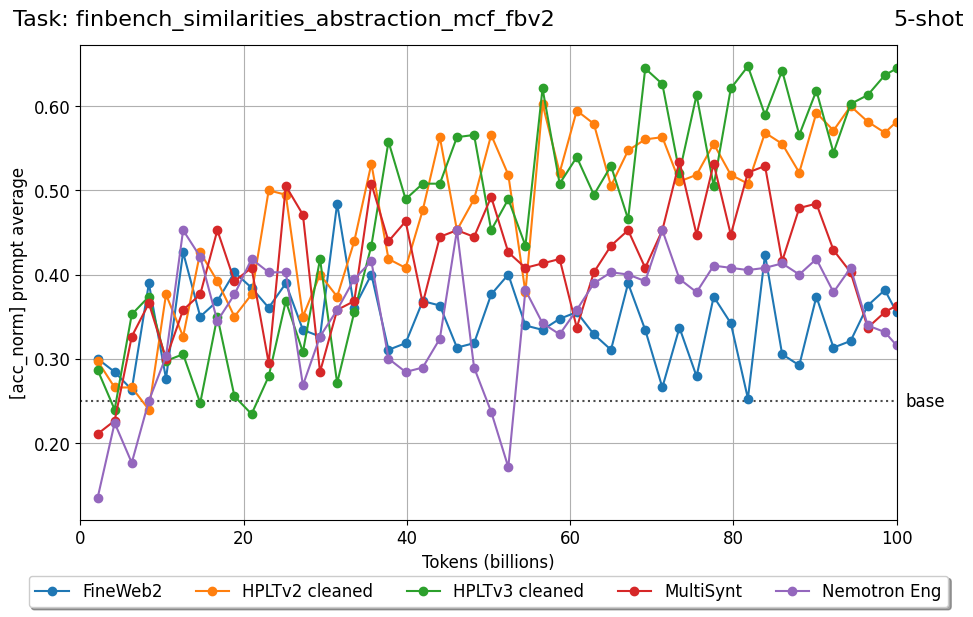
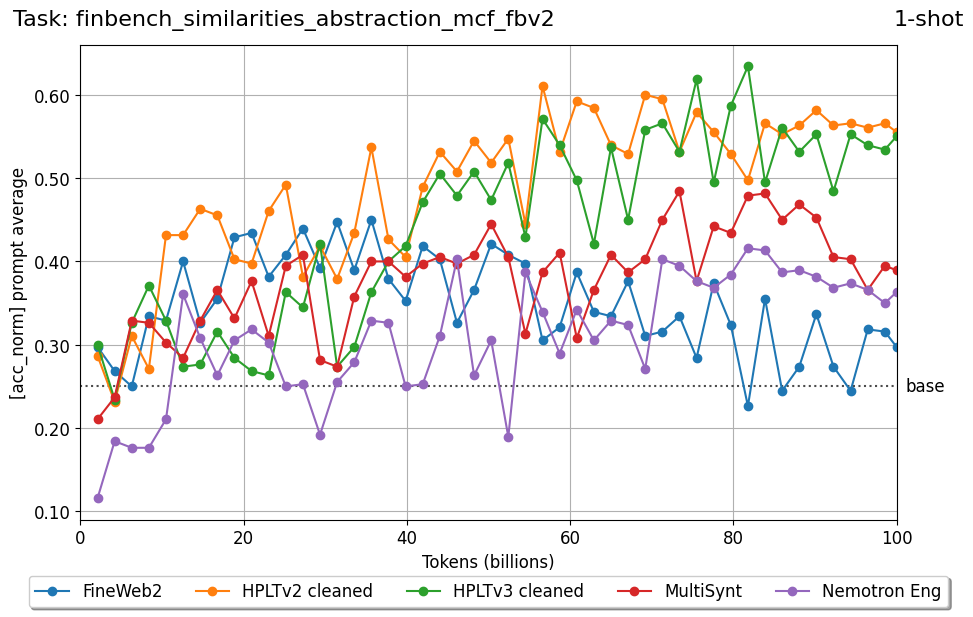
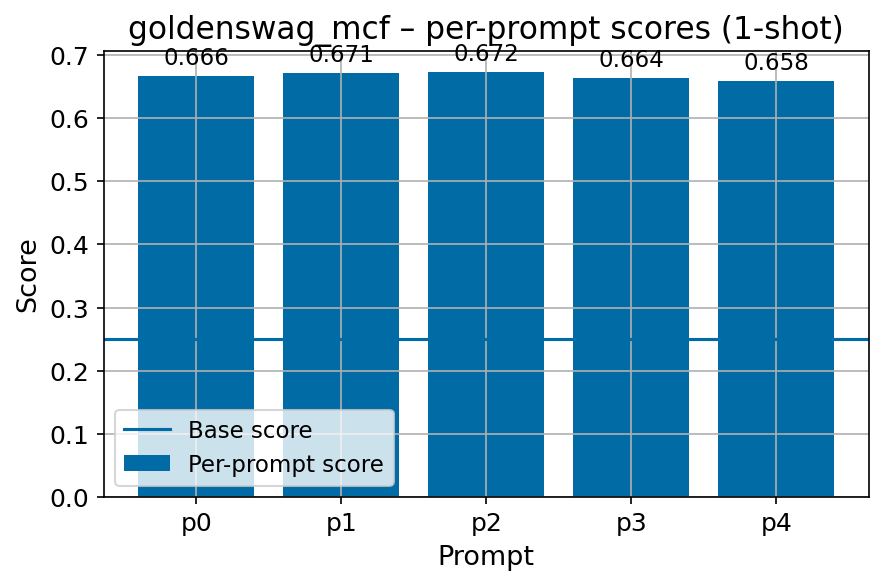
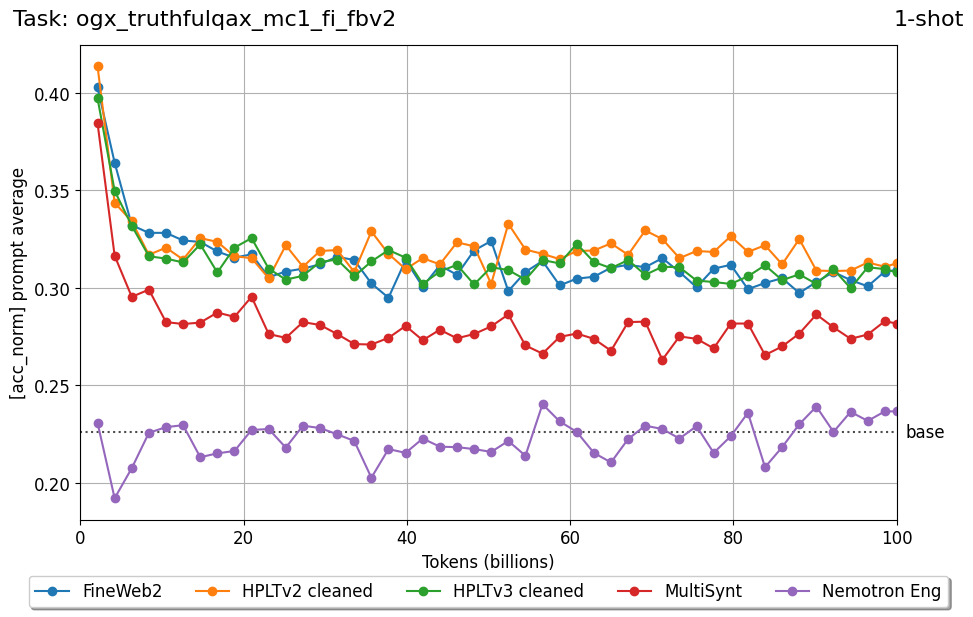
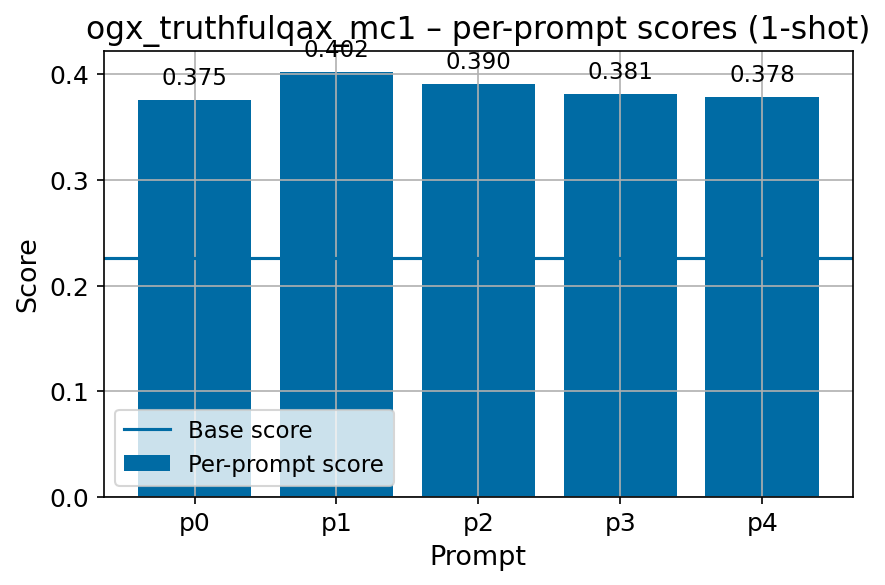
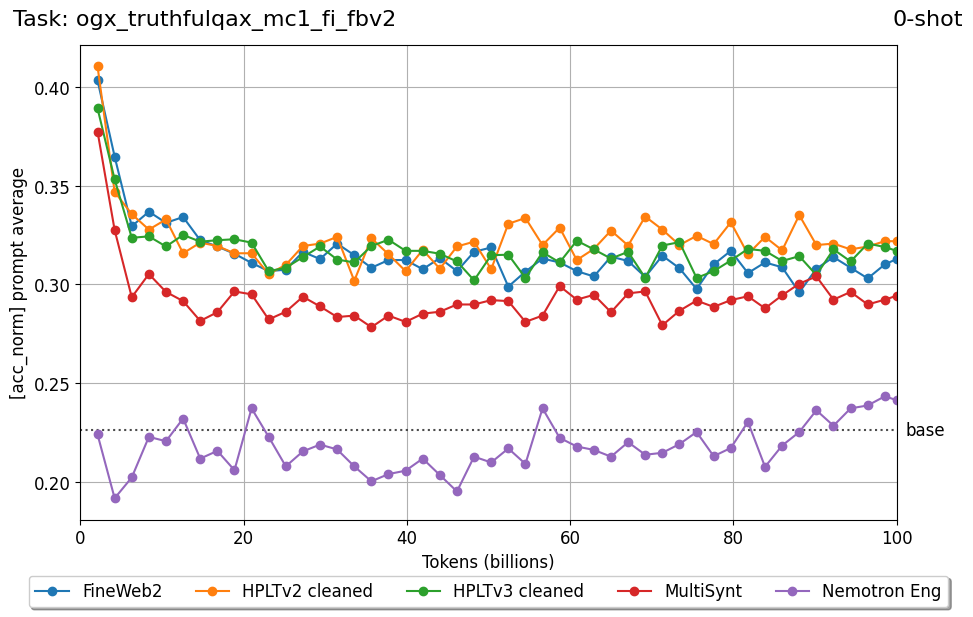
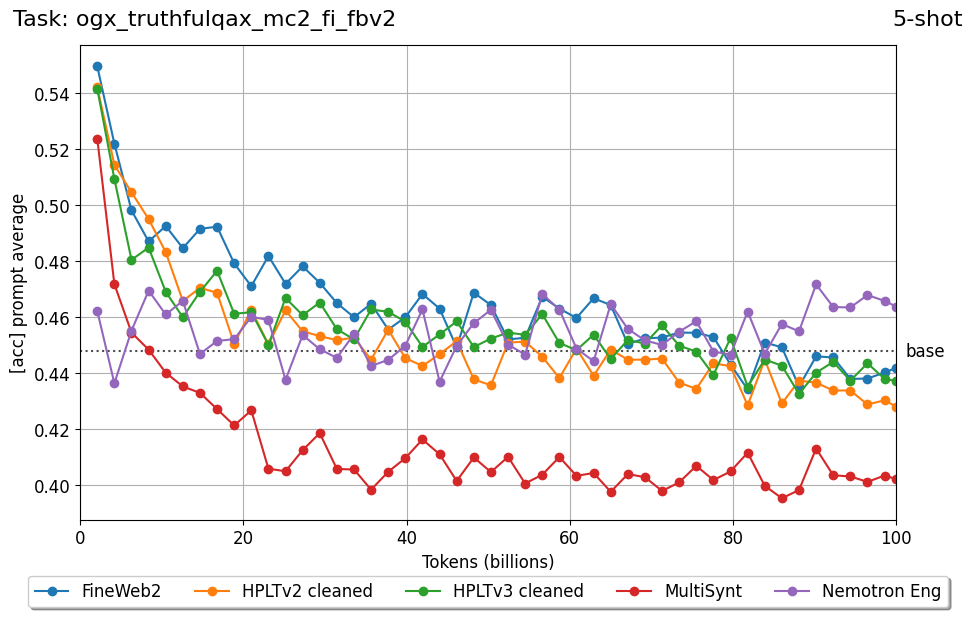
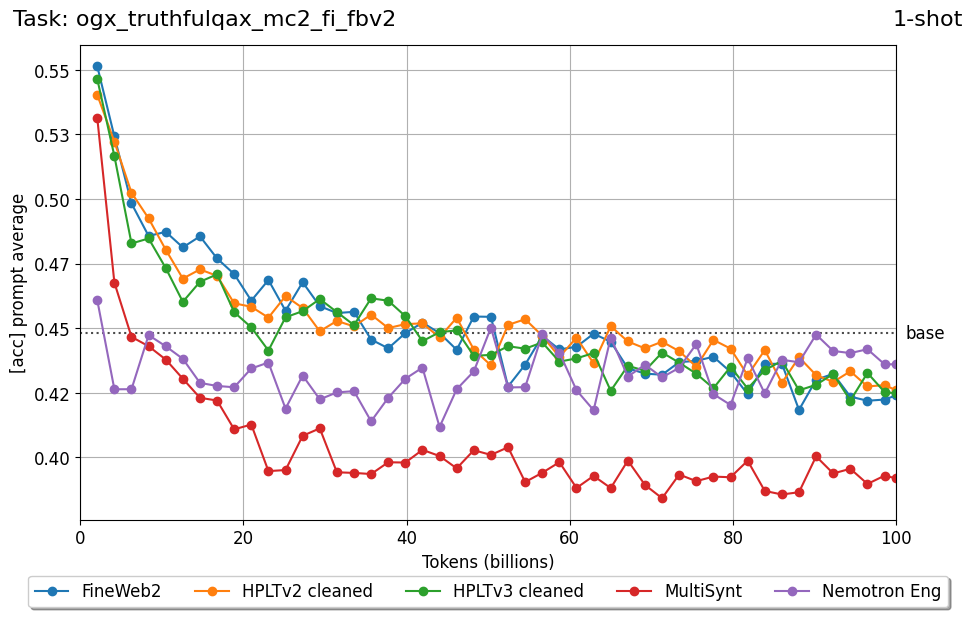
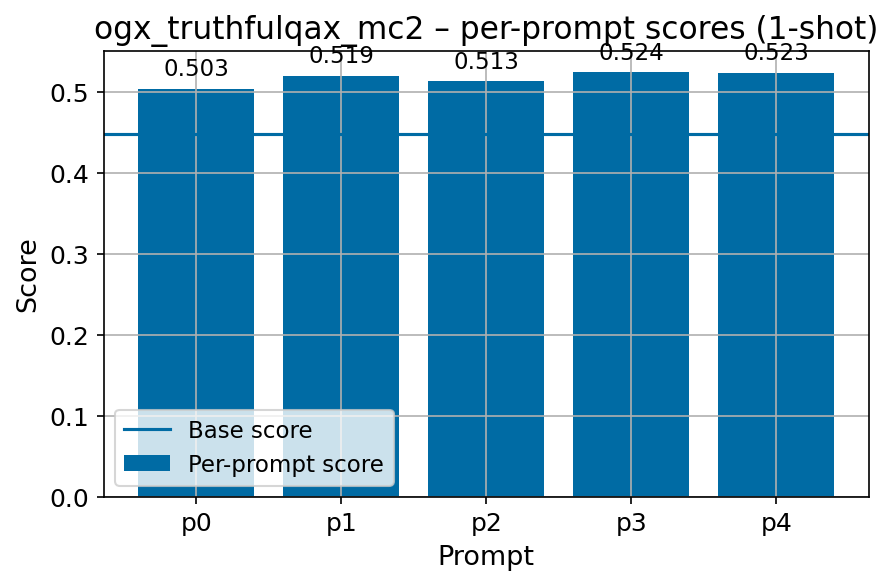
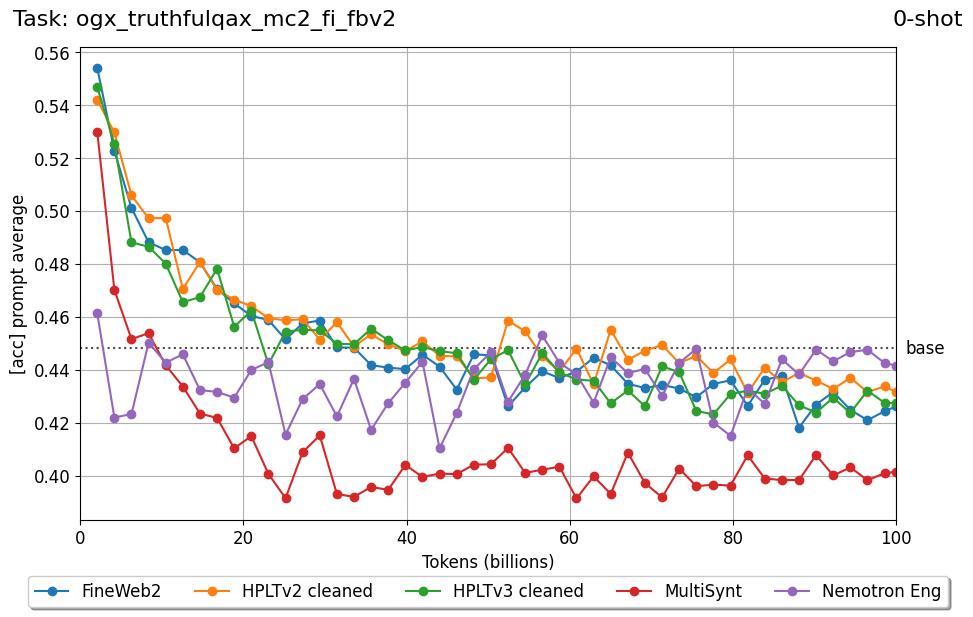
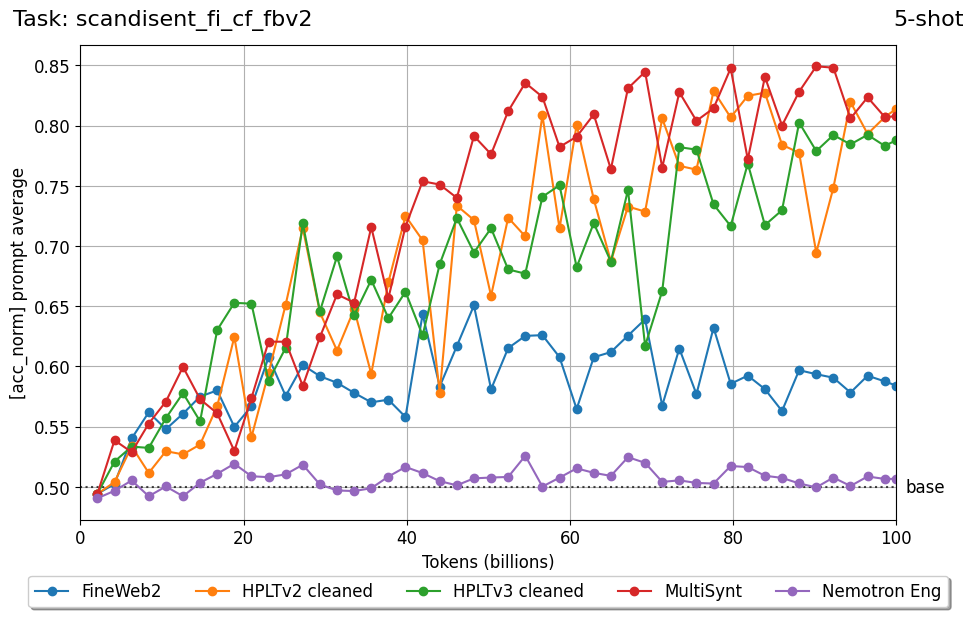
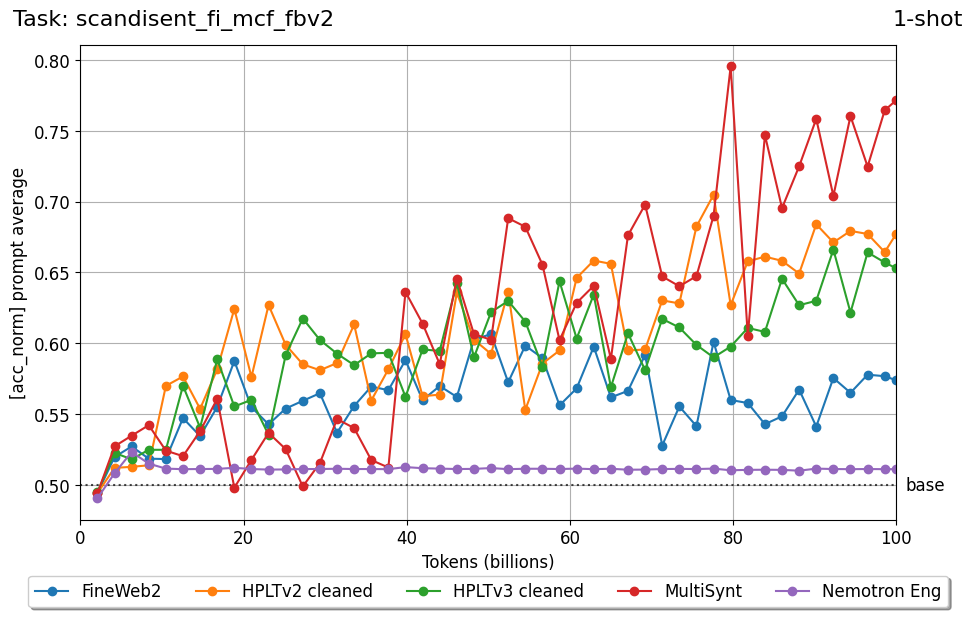
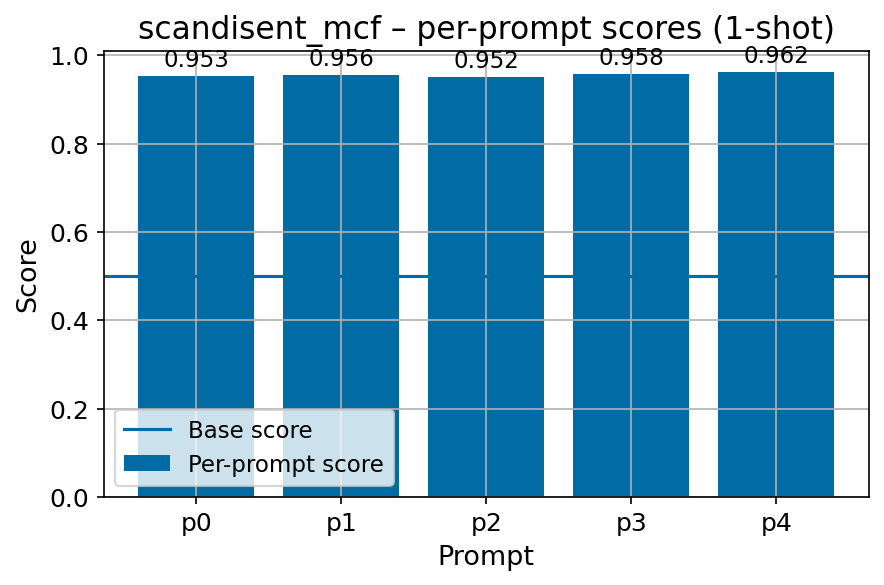
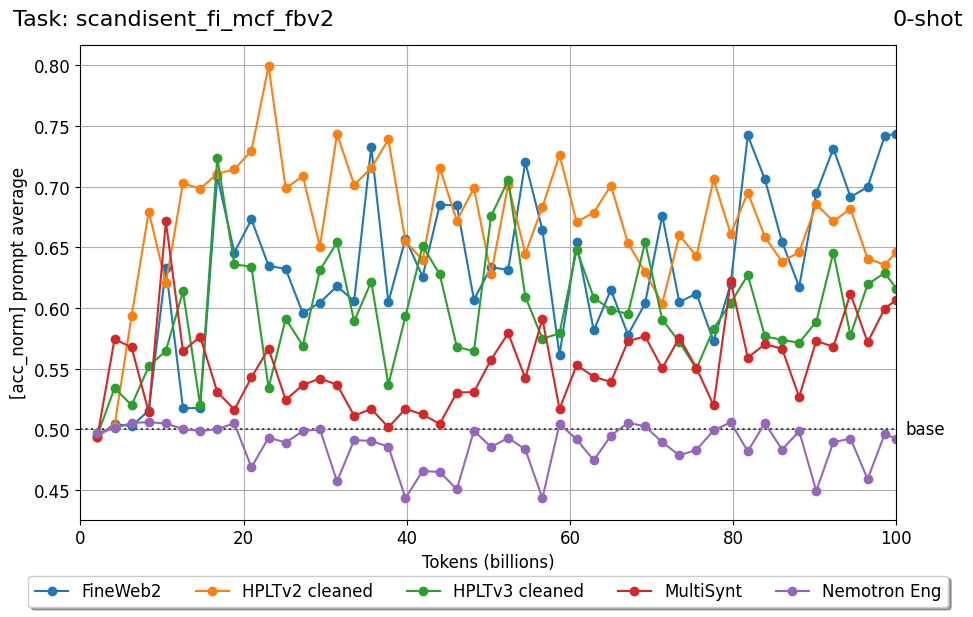
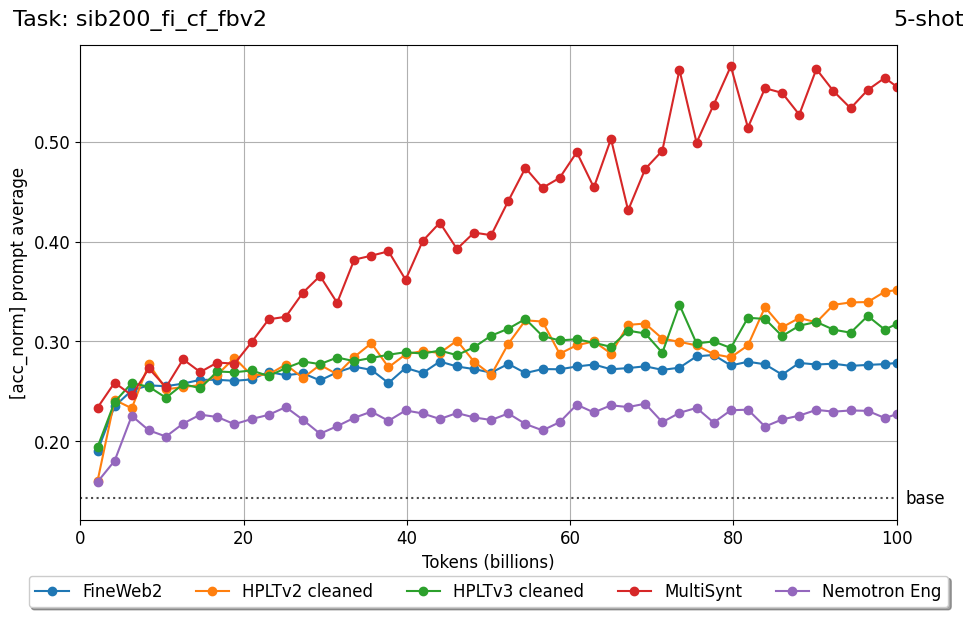
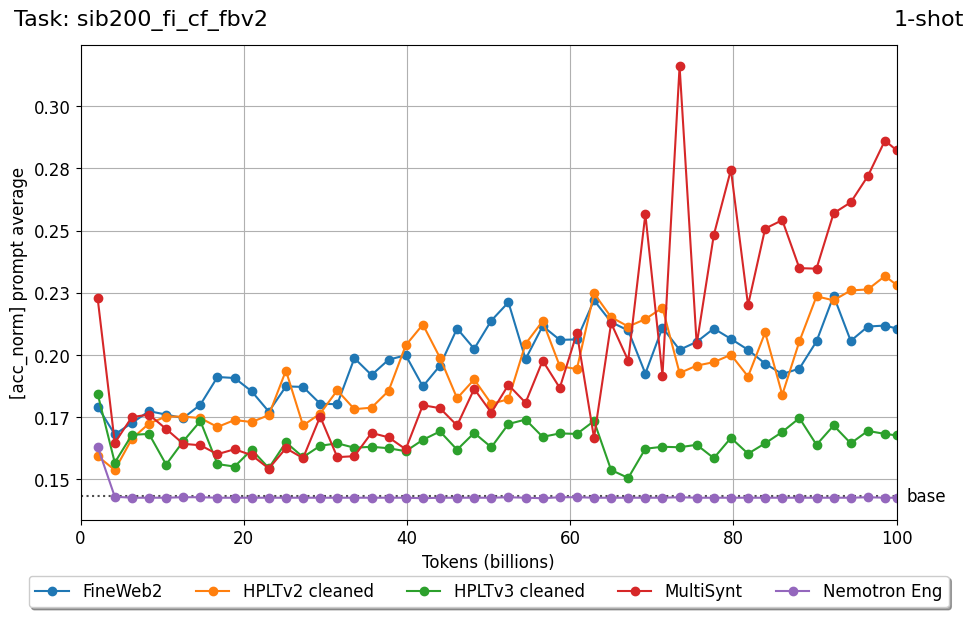
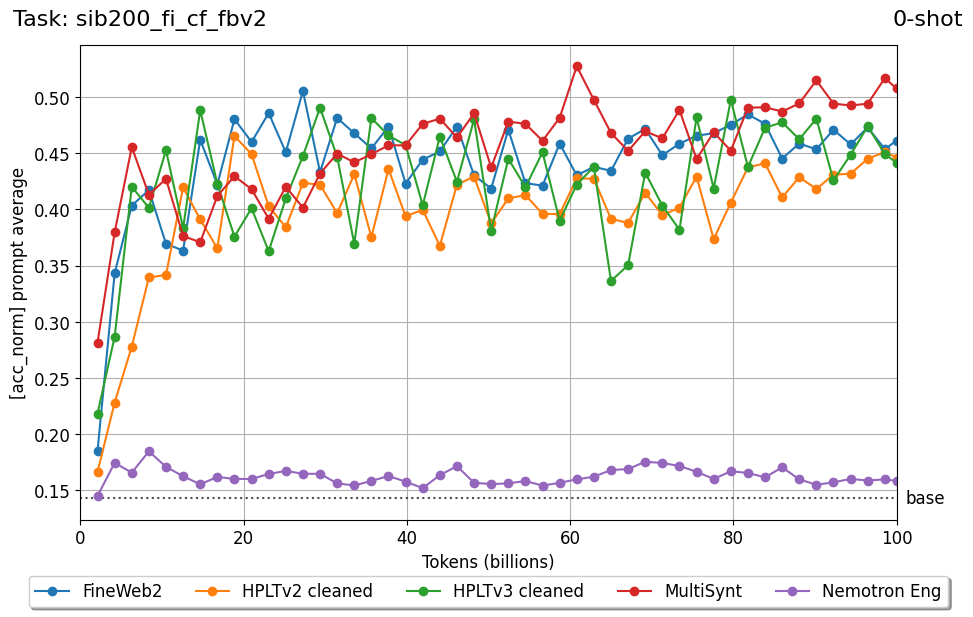
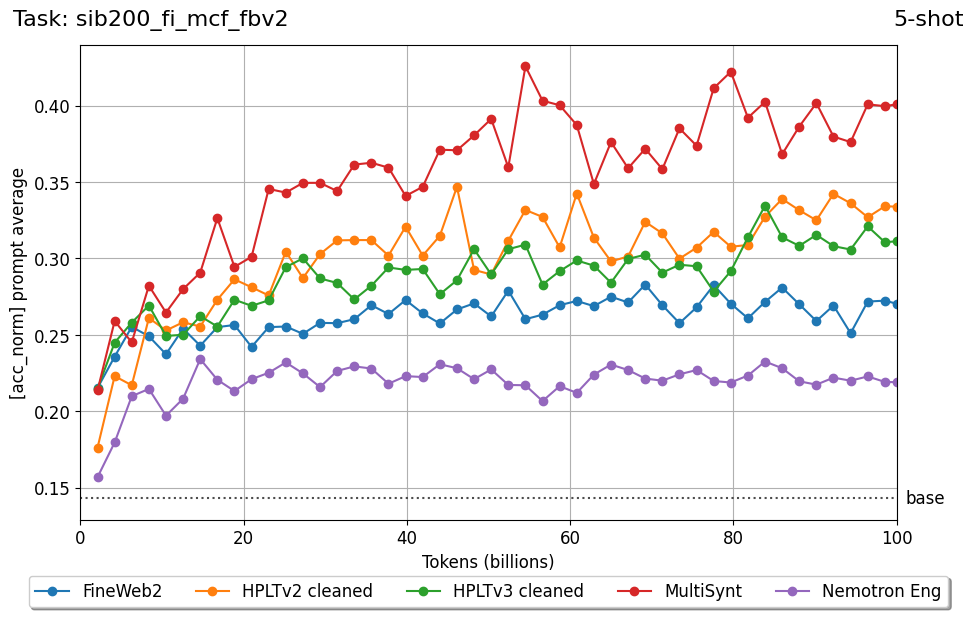
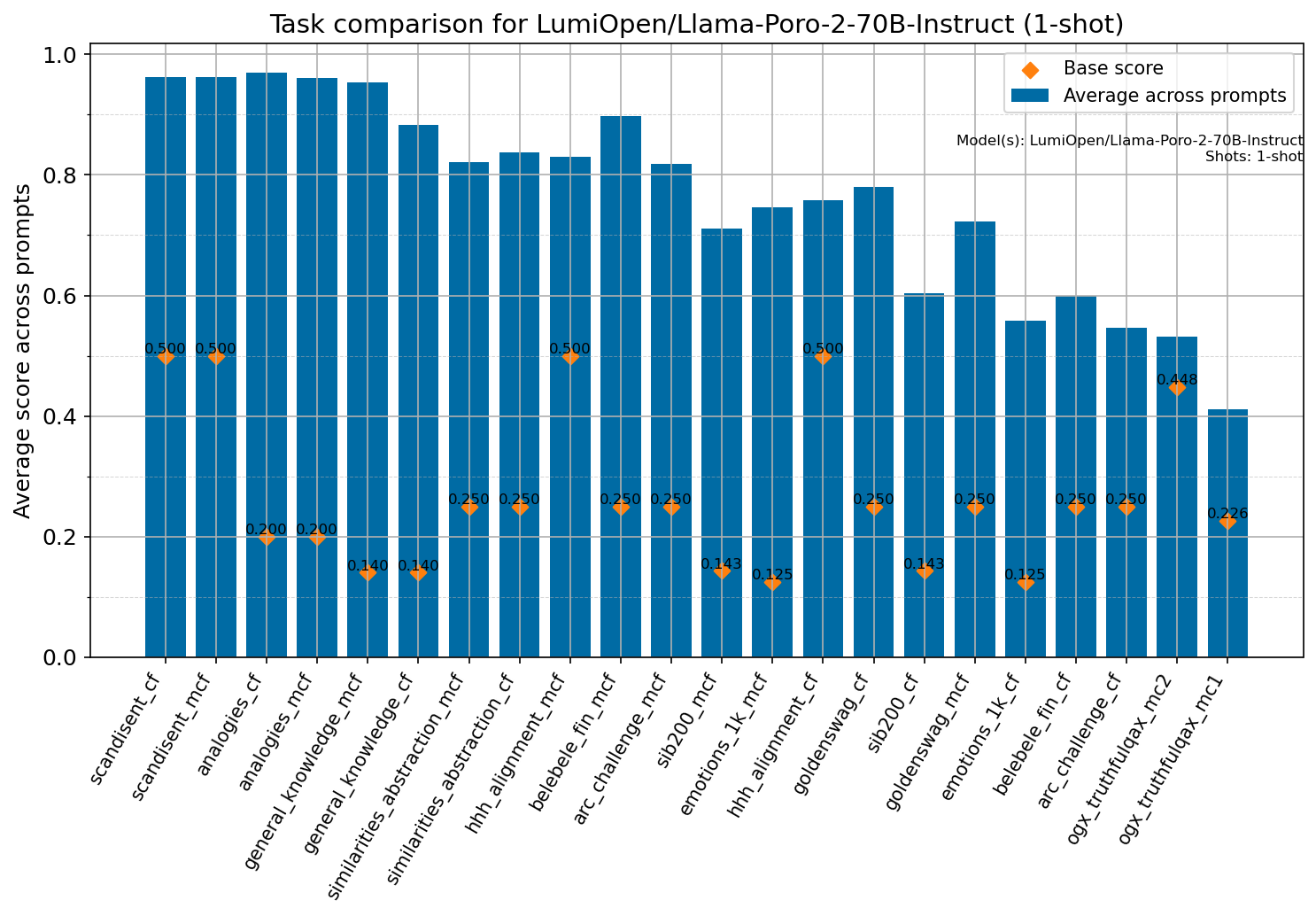
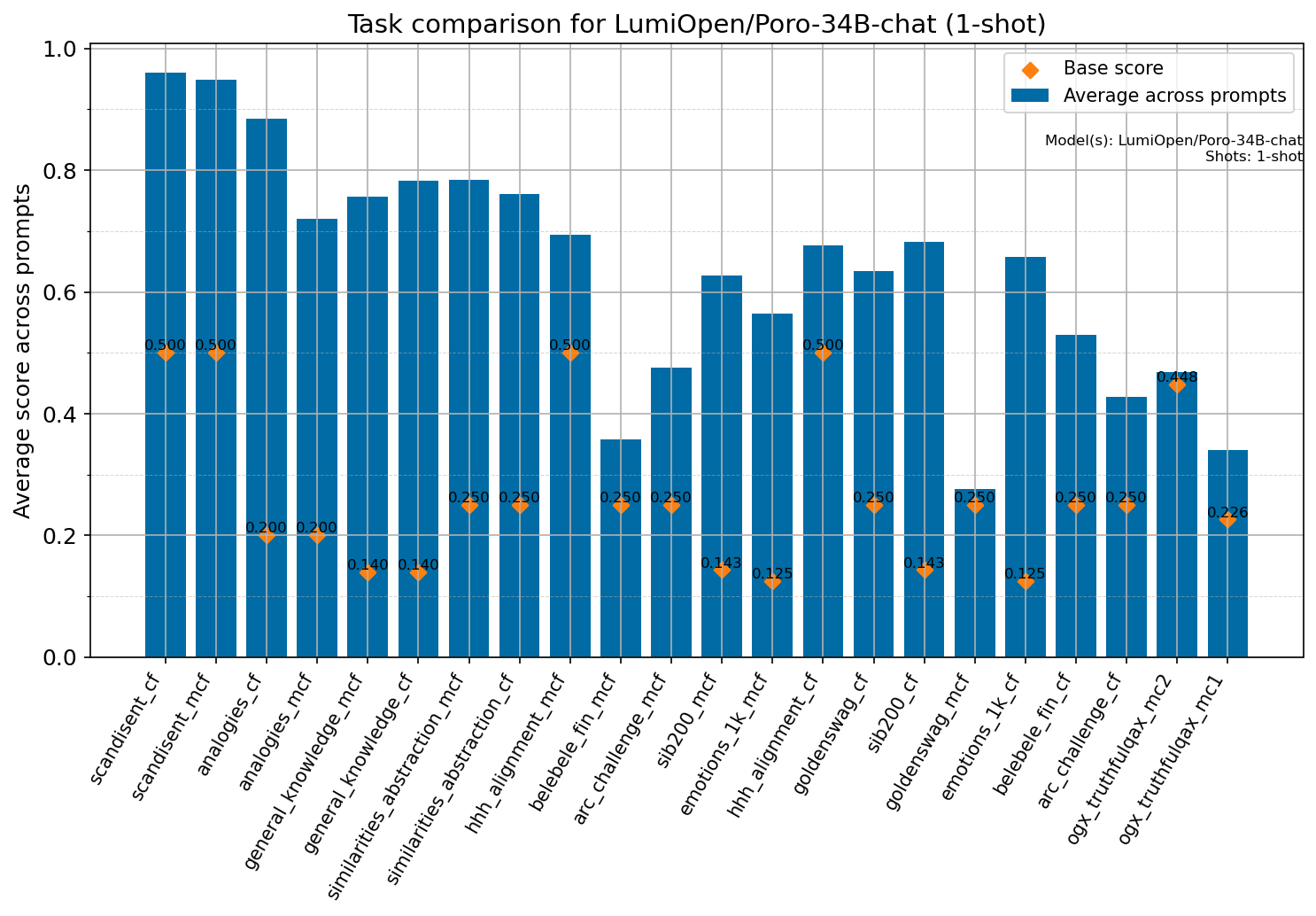
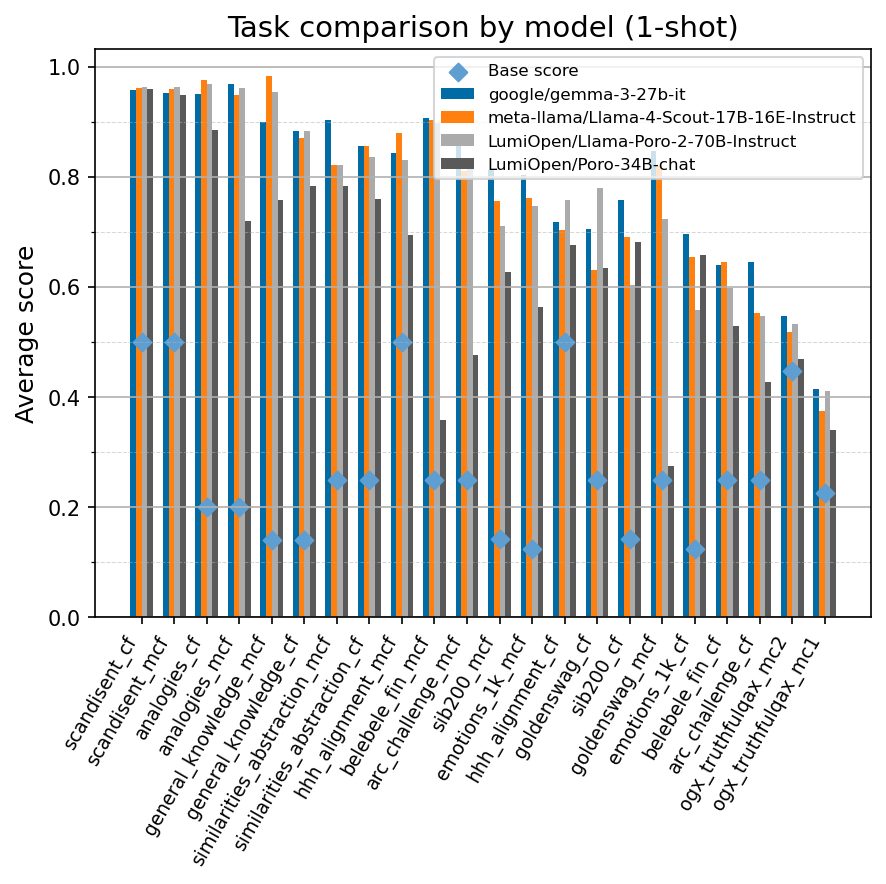
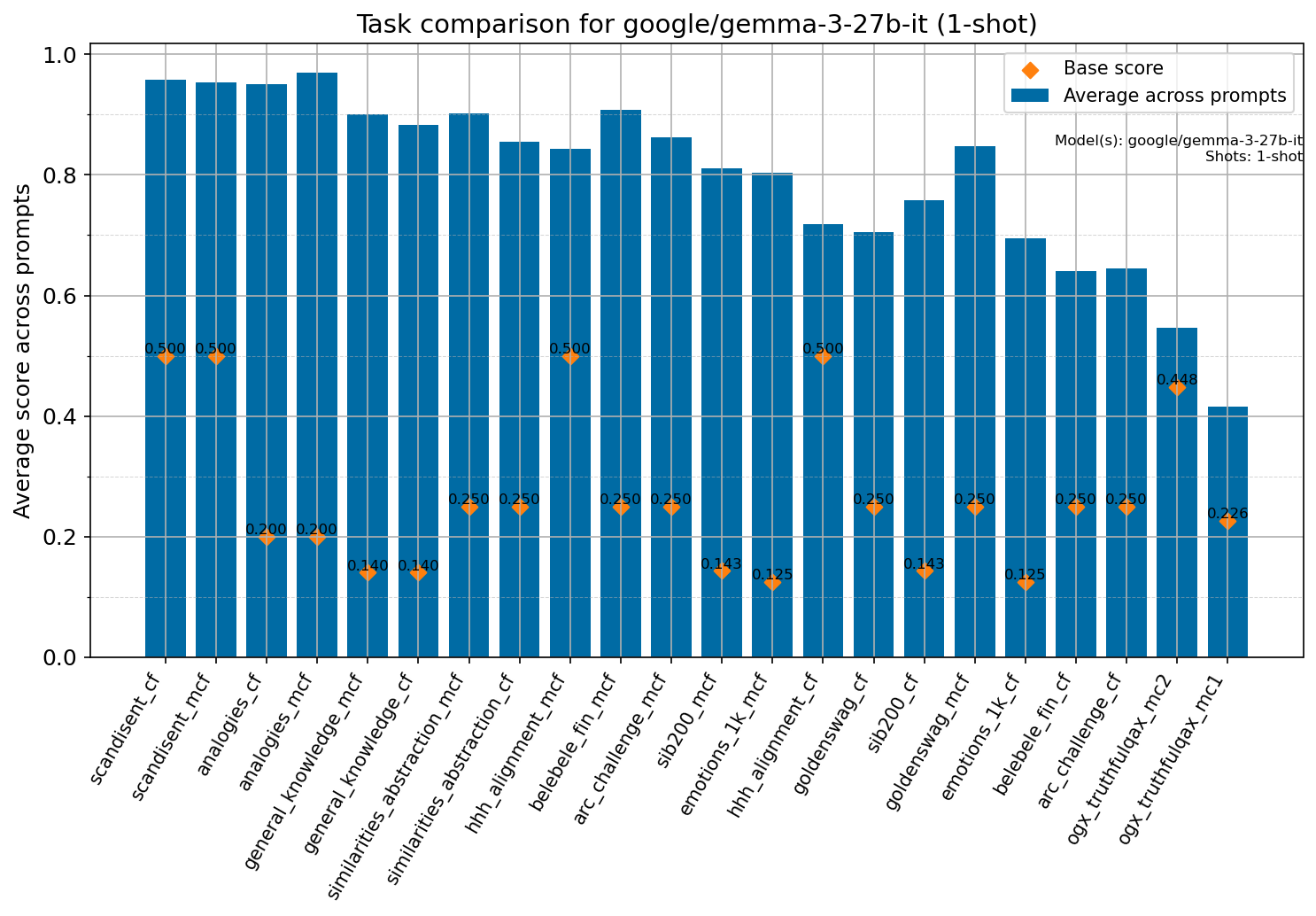
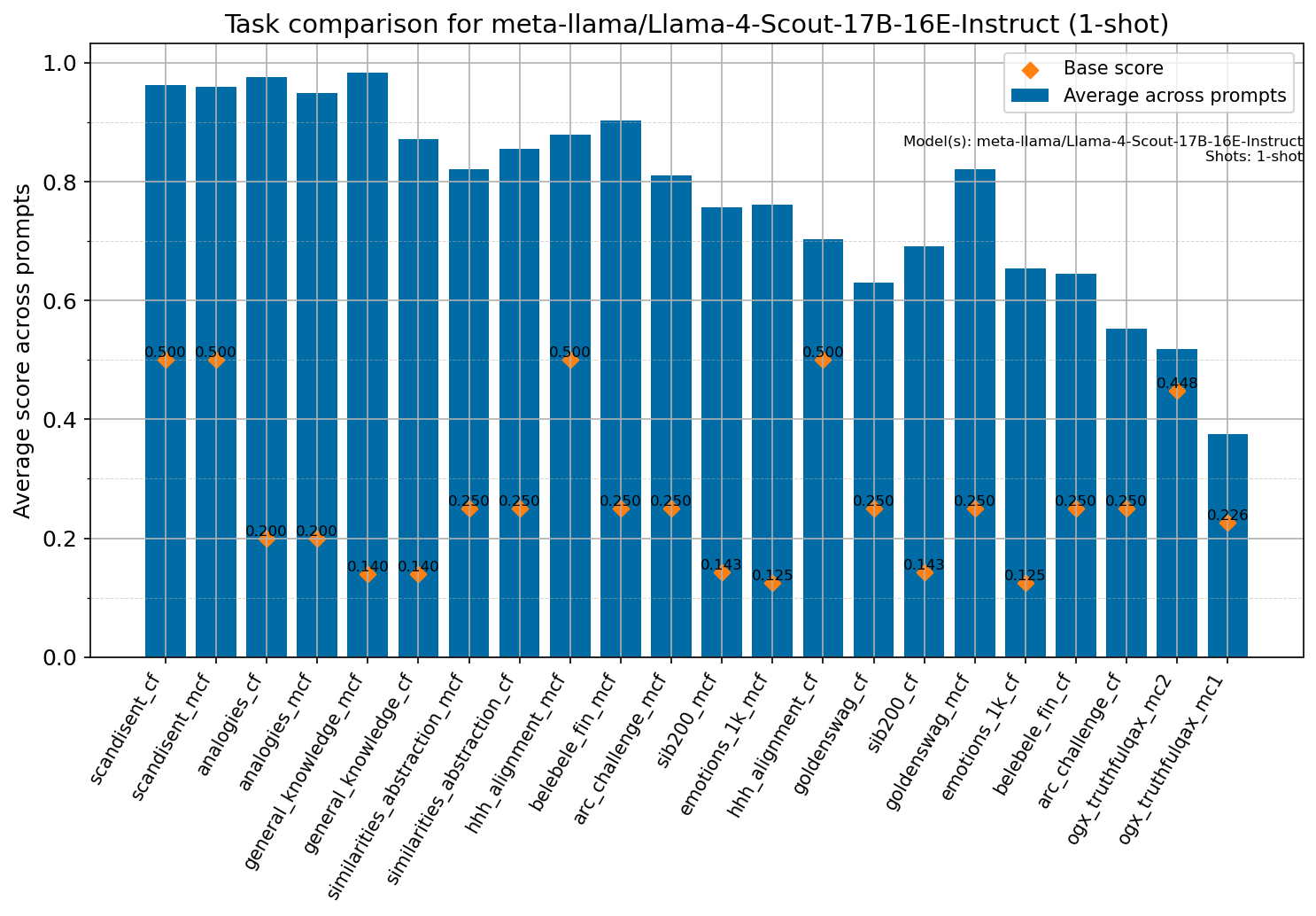
Beyond standard post-training assessment, we designed the suite to facilitate intermediate feedback during the pre-training phase via model checkpoint evaluation. To accommodate the distinct behaviors of base and fine-tuned models, we sought to implement two separate prompting strategies: Cloze Formulation (CF) and Multiple-choice Formulation (MCF) (Gu et al., 2025). This dual approach addresses established findings that while instruction-tuned models benefit from answer choices embedded in the prompt (MCF), base models typically demonstrate superior performance with standard cloze-style completions (Brown et al., 2020).
The first step of the benchmark creation was to include all tasks and datasets from the original FINbench (Luukkonen et al., 2023). As will be discussed in the following section, each of these tasks and datasets was systematically re-evaluated to determine whether it should be retained, modified, or excluded in the construction of . This reassessment ensured that the updated benchmark remained reliable, relevant, and compatible with our renewed evaluation framework.
To further broaden the scope of FIN-bench-v2 and include new tasks and datasets across a variety of domains, we investigated a wide range of existing datasets as potential candidates. While some of these datasets were already familiar to us through prior experiments and were known to meet our quality standards, others required closer inspection and additional processing. Our final pool of candidate tasks included: ARC Challenge (Clark et al., 2018), Belebele (Bandarkar et al., 2024), Golden
This content is AI-processed based on open access ArXiv data.