Generative AI for Video Translation: A Scalable Architecture for Multilingual Video Conferencing
Reading time: 5 minute
...
📝 Original Info
Title: Generative AI for Video Translation: A Scalable Architecture for Multilingual Video Conferencing
ArXiv ID: 2512.13904
Date: 2025-12-15
Authors: Amirkia Rafiei Oskooei, Eren Caglar, Ibrahim Sahin, Ayse Kayabay, Mehmet S. Aktas
📝 Abstract
The real-time deployment of cascaded generative AI pipelines for applications like video translation is constrained by significant system-level challenges. These include the cumulative latency of sequential model inference and the quadratic ($\mathcal{O}(N^2)$) computational complexity that renders multi-user video conferencing applications unscalable. This paper proposes and evaluates a practical system-level framework designed to mitigate these critical bottlenecks. The proposed architecture incorporates a turn-taking mechanism to reduce computational complexity from quadratic to linear in multi-user scenarios, and a segmented processing protocol to manage inference latency for a perceptually real-time experience. We implement a proof-of-concept pipeline and conduct a rigorous performance analysis across a multi-tiered hardware setup, including commodity (NVIDIA RTX 4060), cloud (NVIDIA T4), and enterprise (NVIDIA A100) GPUs. Our objective evaluation demonstrates that the system achieves real-time throughput ($τ< 1.0$) on modern hardware. A subjective user study further validates the approach, showing that a predictable, initial processing delay is highly acceptable to users in exchange for a smooth, uninterrupted playback experience. The work presents a validated, end-to-end system design that offers a practical roadmap for deploying scalable, real-time generative AI applications in multilingual communication platforms.
💡 Deep Analysis
📄 Full Content
Generative AI for Video Translation: A Scalable Architecture for
Multilingual Video Conferencing
Amirkia Rafiei Oskooei*
Eren Caglar
Ibrahim ¸Sahin
Ayse Kayabay
Mehmet S. Aktas
Department of Computer Engineering, Yildiz Technical University, Istanbul 34220, Turkey
Abstract
The real-time deployment of cascaded generative AI pipelines for applications like video translation
is constrained by significant system-level challenges. These include the cumulative latency of sequential
model inference and the quadratic (O(N 2)) computational complexity that renders multi-user video con-
ferencing applications unscalable. This paper proposes and evaluates a practical system-level framework
designed to mitigate these critical bottlenecks. The proposed architecture incorporates a turn-taking
mechanism to reduce computational complexity from quadratic to linear in multi-user scenarios, and
a segmented processing protocol to manage inference latency for a perceptually real-time experience.
We implement a proof-of-concept pipeline and conduct a rigorous performance analysis across a multi-
tiered hardware setup, including commodity (NVIDIA RTX 4060), cloud (NVIDIA T4), and enterprise
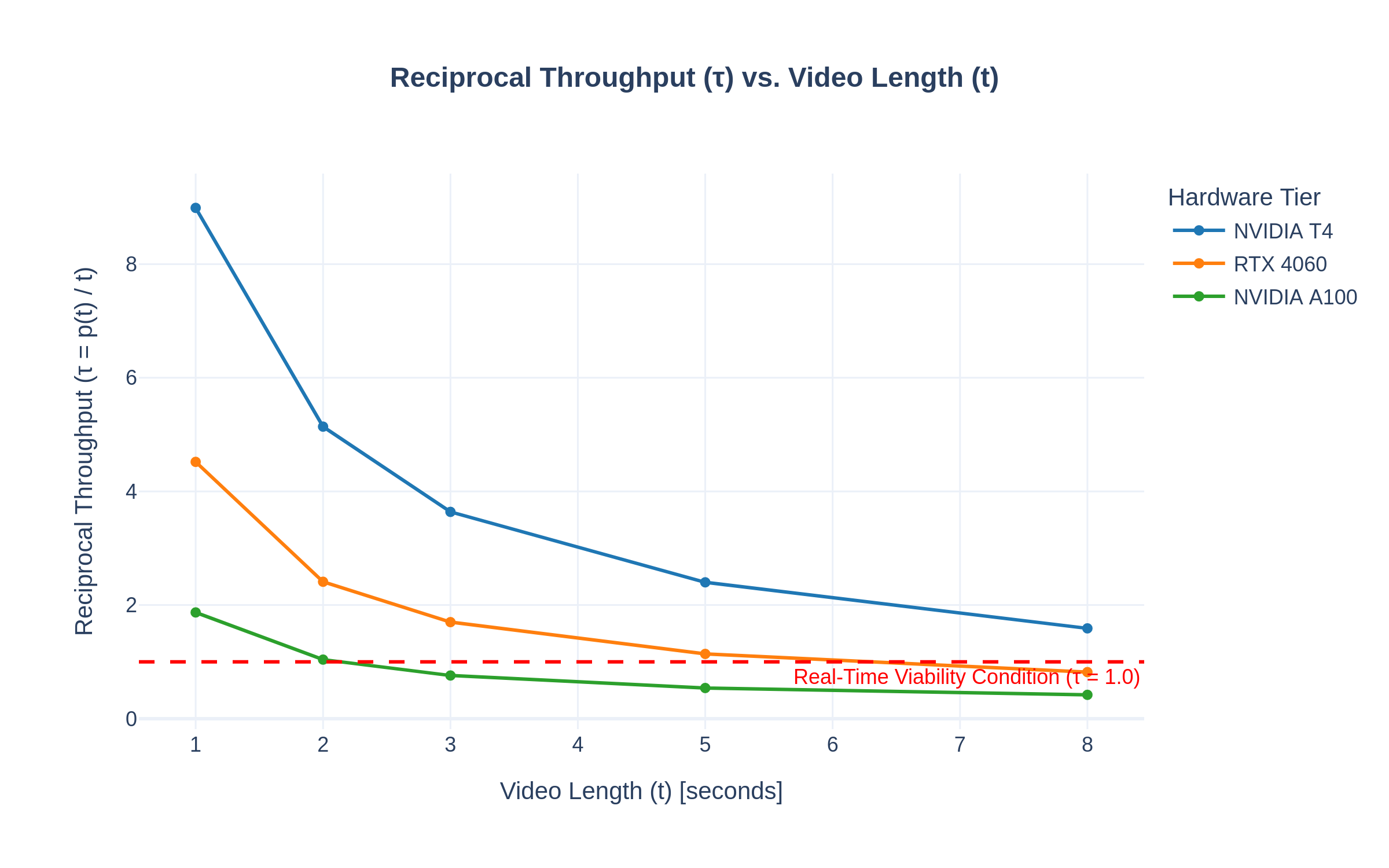
(NVIDIA A100) GPUs. Our objective evaluation demonstrates that the system achieves real-time through-
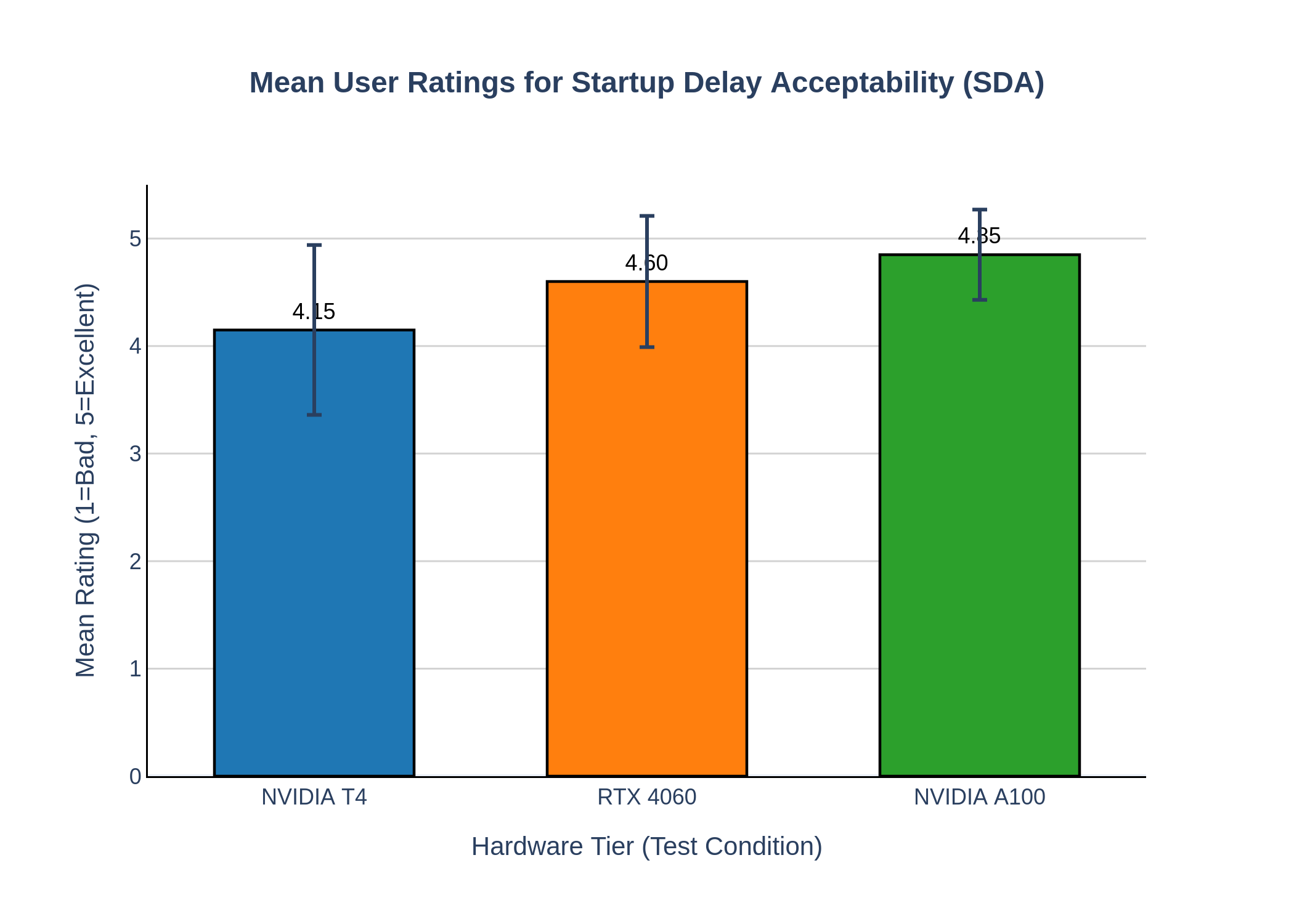
put (τ < 1.0) on modern hardware. A subjective user study further validates the approach, showing that a
predictable, initial processing delay is highly acceptable to users in exchange for a smooth, uninterrupted
playback experience. The work presents a validated, end-to-end system design that offers a practical
roadmap for deploying scalable, real-time generative AI applications in multilingual communication
platforms.
Keywords: generative AI; applied computer vision; multimedia; human–AI interaction; deep learning
Note: This manuscript is the authors’ accepted version of a paper published in Applied Sciences (MDPI),
2025. The final version is available from the publisher at https://www.mdpi.com/2076-3417/15/
23/12691.
1
Introduction
The convergence of powerful Generative Artificial Intelligence (GenAI) and the global ubiquity of digital
communication platforms is fundamentally reshaping human interaction. GenAI models can create novel,
high-fidelity content—including text, code [1, 2, 3, 4], audio, and video [5, 6, 7]—offering the potential to
make online environments more immersive and functional. This technological shift, occurring alongside the
widespread adoption of platforms like video conferencing systems, Augmented/Virtual Reality (AR/VR)
[8, 9, 10, 11, 12], and social networks [13, 14, 15] presents a transformative opportunity to dismantle
longstanding barriers to global communication, most notably those of language [16, 17]. Within this domain,
“Video Translation”—also known as Video-to-Video or Face-to-Face Translation—represents an emerging
paradigm of significant interest [18]. Video translation aims to deliver a seamless multilingual experience
by holistically translating all facets of human expression. This process involves converting spoken words,
*Corresponding author: amirkia.oskooei@std.yildiz.edu.tr
1
arXiv:2512.13904v1 [cs.MM] 15 Dec 2025
preserving the speaker’s vocal tone and style, and critically, synchronizing their lip movements with the
translated speech. Such a comprehensive translation fosters more natural and fluid conversations, providing
immense value to international business, global academic conferences, and multicultural social engagements.
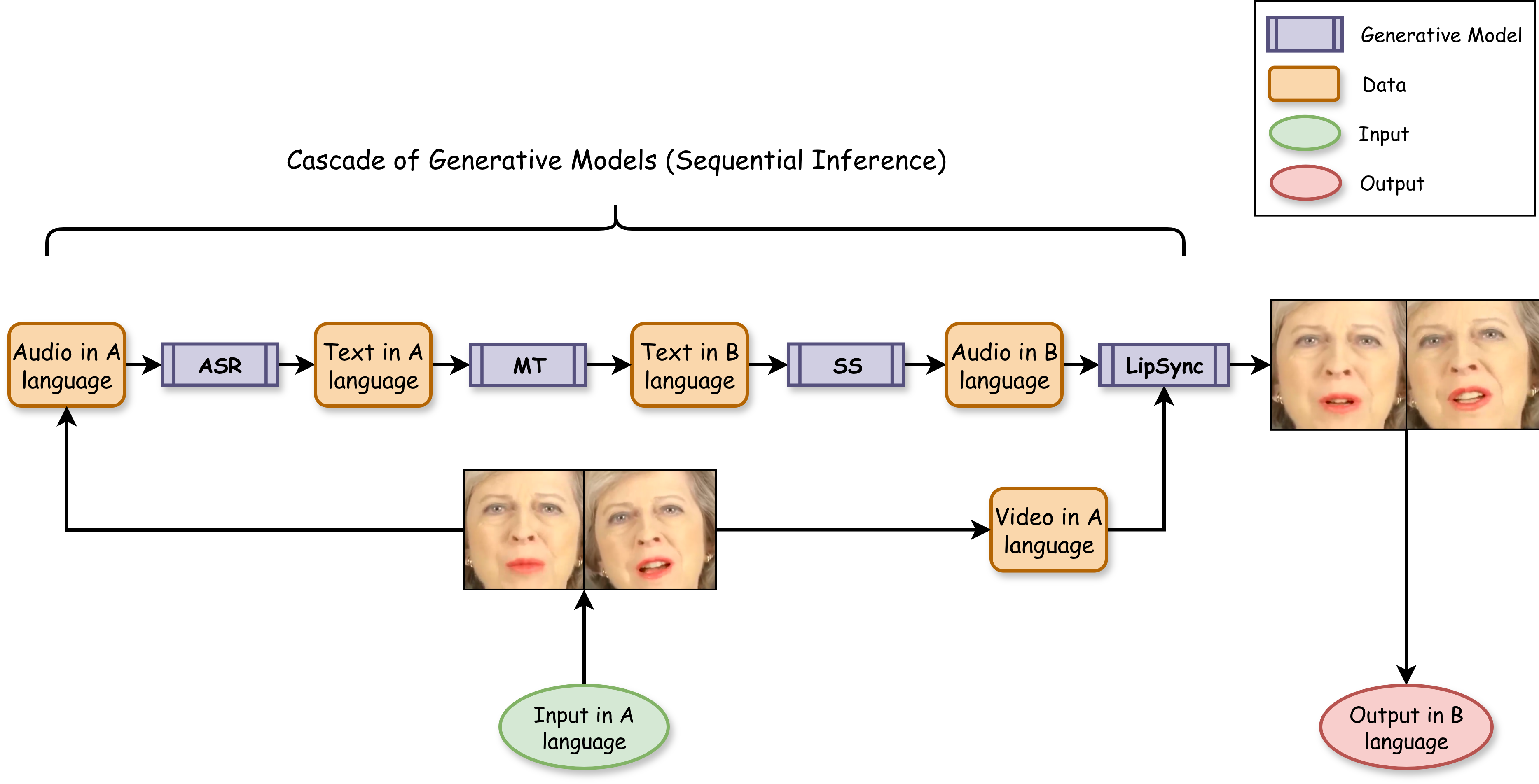
Achieving this requires end-to-end pipelines that integrate multiple GenAI models for tasks such as automatic
speech recognition (ASR), machine translation (MT), text-to-speech (TTS) synthesis, and lip synchronization
(LipSync), as illustrated in Figure 1.
Figure 1: The sequential four-stage pipeline for video translation. An input in Language A is transformed by models
for Automatic Speech Recognition (ASR), Machine Translation (MT), Speech Synthesis (SS), and Lip Synchronization
(LipSync) to generate a fully translated and visually synchronized output in Language B.
However, the practical deployment of these complex, multi-stage pipelines in real-time, large-scale
applications is hampered by formidable system-level engineering challenges that have not been adequately
addressed in existing research. GenAI models are computationally intensive, necessitating high-performance
hardware like GPUs for timely execution. This requirement is magnified in real-time environments like video
conferencing, giving rise to two primary bottlenecks:
1. Latency: The sequential execution of multiple deep learning models introduces significant processing
delays. Each stage in the cascade adds to the total inference time, making it difficult to achieve the
low-latency throughput required for smooth, uninterrupted conversation.
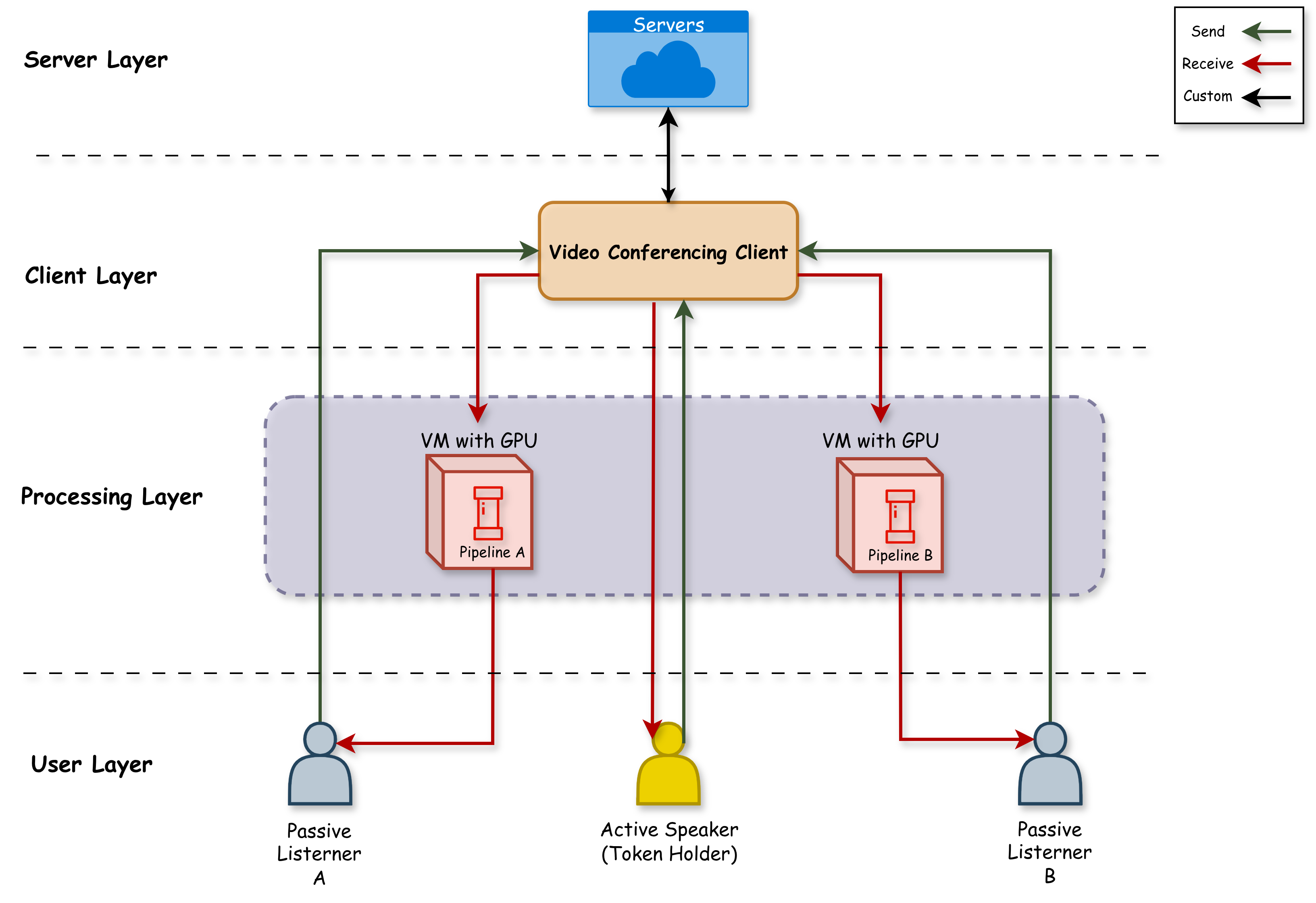
2. Scalability: In a multi-user video conference, a naive implementation would require each participant to
concurrently process video streams from all other speakers.