Music emotion recognition is a key task in symbolic music understanding (SMER). Recent approaches have shown promising results by fine-tuning large-scale pre-trained models (e.g., MIDIBERT, a benchmark in symbolic music understanding) to map musical semantics to emotional labels. While these models effectively capture distributional musical semantics, they often overlook tonal structures, particularly musical modes, which play a critical role in emotional perception according to music psychology. In this paper, we investigate the representational capacity of MIDIBERT and identify its limitations in capturing mode-emotion associations. To address this issue, we propose a Mode-Guided Enhancement (MoGE) strategy that incorporates psychological insights on mode into the model. Specifically, we first conduct a mode augmentation analysis, which reveals that MIDIBERT fails to effectively encode emotion-mode correlations. We then identify the least emotion-relevant layer within MIDIBERT and introduce a Mode-guided Feature-wise linear modulation injection (MoFi) framework to inject explicit mode features, thereby enhancing the model's capability in emotional representation and inference. Extensive experiments on the EMOPIA and VGMIDI datasets demonstrate that our mode injection strategy significantly improves SMER performance, achieving accuracies of 75.2% and 59.1%, respectively. These results validate the effectiveness of mode-guided modeling in symbolic music emotion recognition.
Music emotion recognition in the symbolic domain plays a vital role in music understanding. It has diverse applications in music generation, music psychotherapy, music recommendation system and human-computer interaction. Compared with audio-based music emotion recognition, symbolic music provides explicit and structural information that can be processed similarly to words in natural language.
Since symbolic music consists of rule-governed symbolic sequences, advances in natural language processing (NLP) have opened new opportunities for symbolic music analysis by enabling the use of language-modeling techniques. In recent years, the remarkable performance of Transformerbased pre-trained models (Vaswani et al. 2017) has inspired numerous efforts to adapt Transformer architectures (Huang et al. 2019) for symbolic music understanding tasks. The significant advancements in the BERT models (Devlin et al. 2019) trained on large-scale midi music datasets have enhanced the understanding of music (Zeng et al. 2021;Chou et al. 2024). Existing approaches have improved the capacity of models to capture richer musical information by designing diverse pre-training strategies and refining symbolic encoding formats (Zeng et al. 2021;Tian et al. 2024). However, due to the limited size of symbolic music emotion recognition datasets, these pre-trained models often fail to acquire emotion-related musical features effectively during fine-tuning. What’s more, emotions are a primary driver of human engagement with music, enabling people to experience and respond to a rich spectrum of affective states. In contrast, computational systems rely on intelligent algo-rithms to process and interpret music through fundamentally different mechanisms. While current models demonstrate strong capabilities in symbolic music understanding, they do not capture the intrinsic reasoning behind human emotional responses. As suggested in (Li et al. 2024), to better understand emotions, models need to explicitly capture features associated with human psychological responses to emotional triggers.
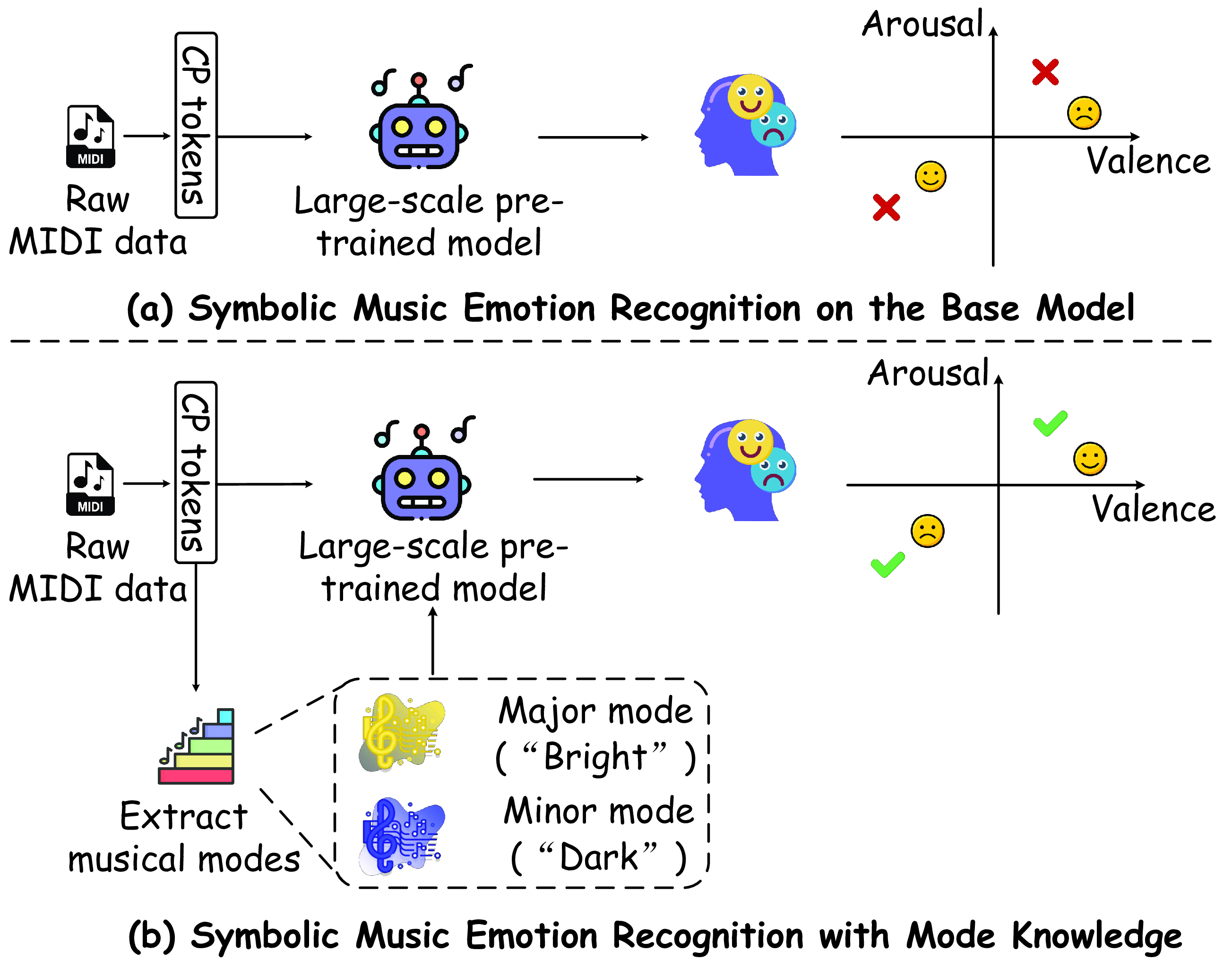
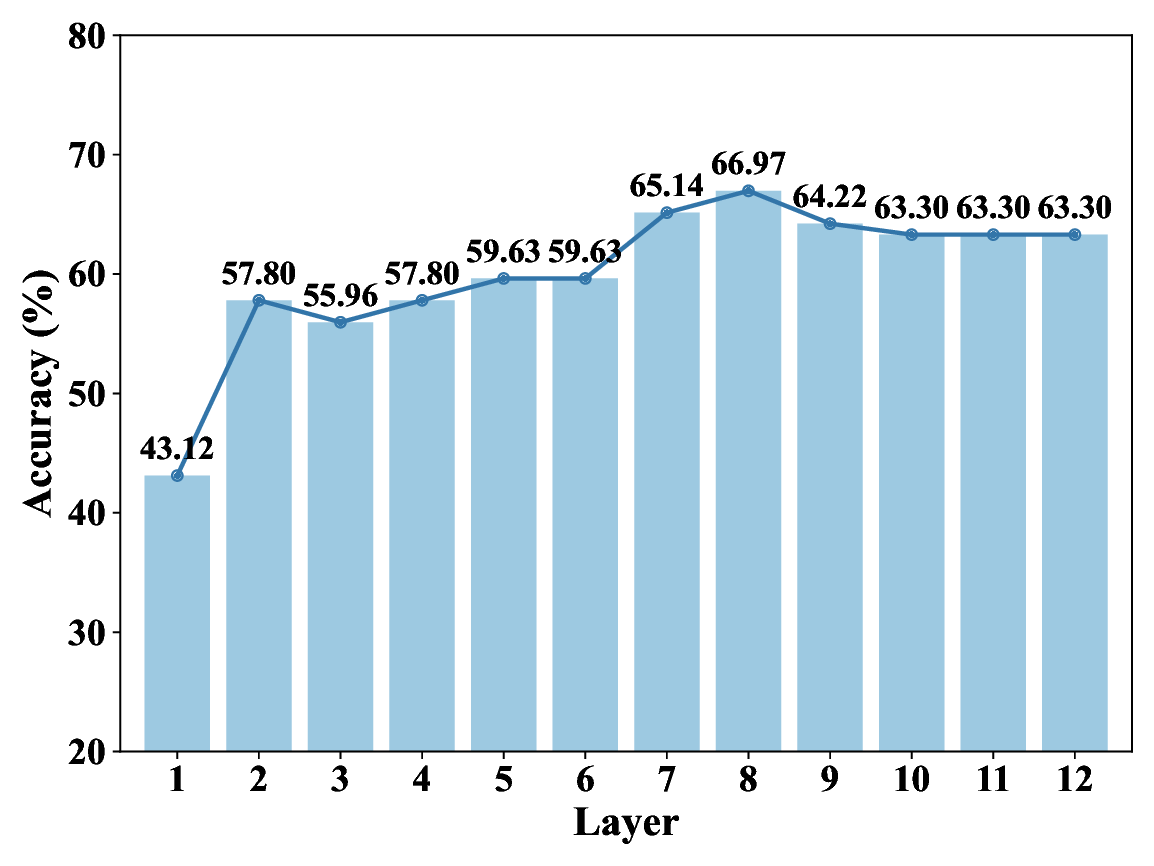
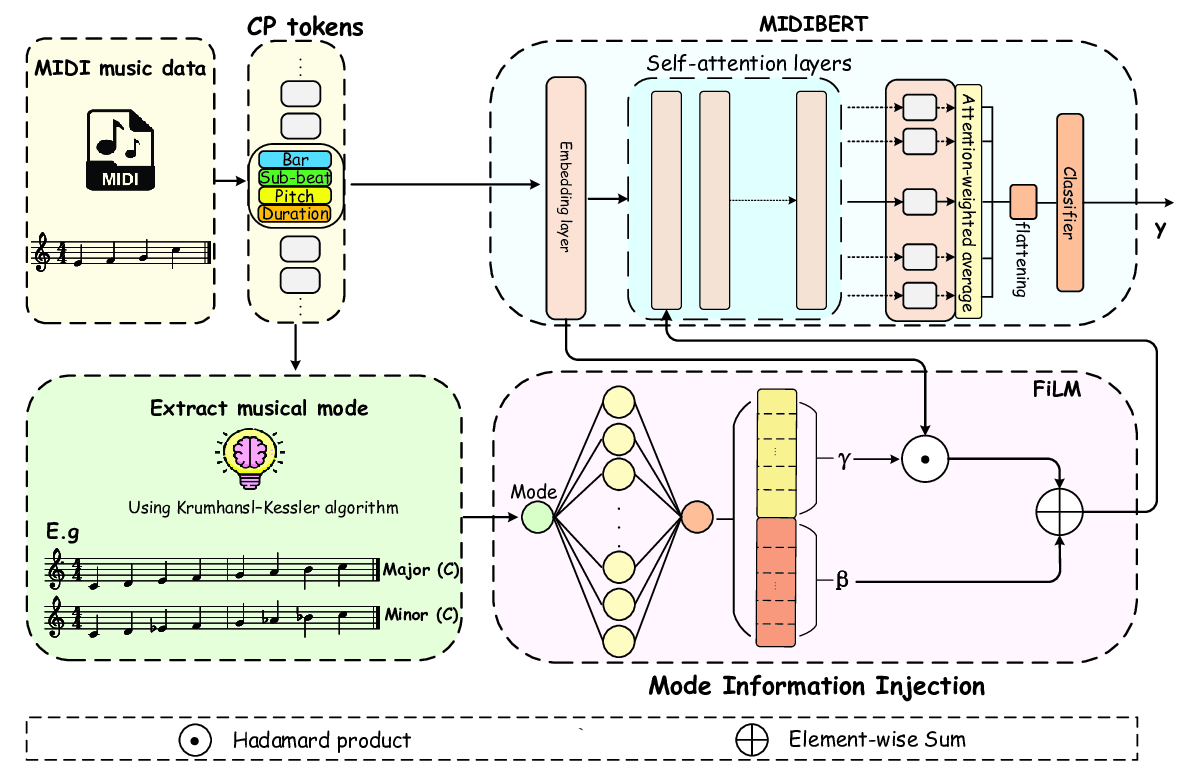
In this work, we aim to enable the model to learn the key elements of music perception in a manner aligned with human understanding. To achieve this, we propose a Mode-Guided Enhancement (MoGE) strategy and a Mode-guided Feature-wise Linear Modulation injection (MoFi) framework to diagnose the limitations and enhance the emotional representation capabilities of large-scale pre-trained models. We adopt MIDIBERT (Chou et al. 2024), which serves as a benchmark model for symbolic music understanding, as the backbone. Existing literature in psychology and music theory has revealed a strong relationship between musical modes and emotional perception (Kastner and Crowder 1990a). Specifically, we first perform a mode augmentation analysis to investigate to what extent MIDIBERT has already understood the relationship between musical modes and emotional expression. Then, to better understand MIDIBERT’s capability, we probe each layer of the model to estimate how much emotional information it has already encoded. This analysis identifies the least emotionally informative layer as the target for MoFi. The MoFi framework extracts explicit mode features and injects them into this layer to improve MIDIBERT’s emotional representation and inference (see Figure 1).
With our design, our proposed method is equipped with mode knowledge, mimicking human perception of music. Moreover, our model inherits the robust music semantic understanding capabilities of the pre-trained MIDIBERT model. As a result, our method achieves remarkable results on two different scale datasets, EMOPIA (Hung et al. 2021) and VGMIDI (Ferreira and Whitehead 2019).
Our primary contributions are as follows:
• We tackle the challenge of capturing the intrinsic reasoning behind human emotional responses by employing the Mode-Guided Enhancement (MoGE) strategy, which consists of a targeted diagnostic experiment to analyze the model’s limitations.
• Recognizing that large-scale pre-trained model MIDIB-ERT neglects the relationship between mode features and emotion, we introduce a Mode-guided Feature-wise Linear Modulation Injection (MoFi) framework. This framework enables fine-grained and parameter-efficient incorporation of explicit music-theoretic priors into MIDIB-ERT, offering a principled and interpretable solution to its identified knowledge gaps.
• We conduct experiments on two different scale datasets, including EMOPIA and VGMIDI, and achieve superior or comparable results to state-of-the art methods.
Music emotion recognition (MER) is a core task in symbolic music understanding, requiring models to infer high-level affective states directly from the compositional structure of music.
Early approaches to Symbolic Music Emotion Recognition (SMER) primarily relied on hand-crafted features grounded in music theory (Wu et al. 2014;Malheiro et al. 2016), such as pitch histograms, rhythmic density, an
This content is AI-processed based on open access ArXiv data.