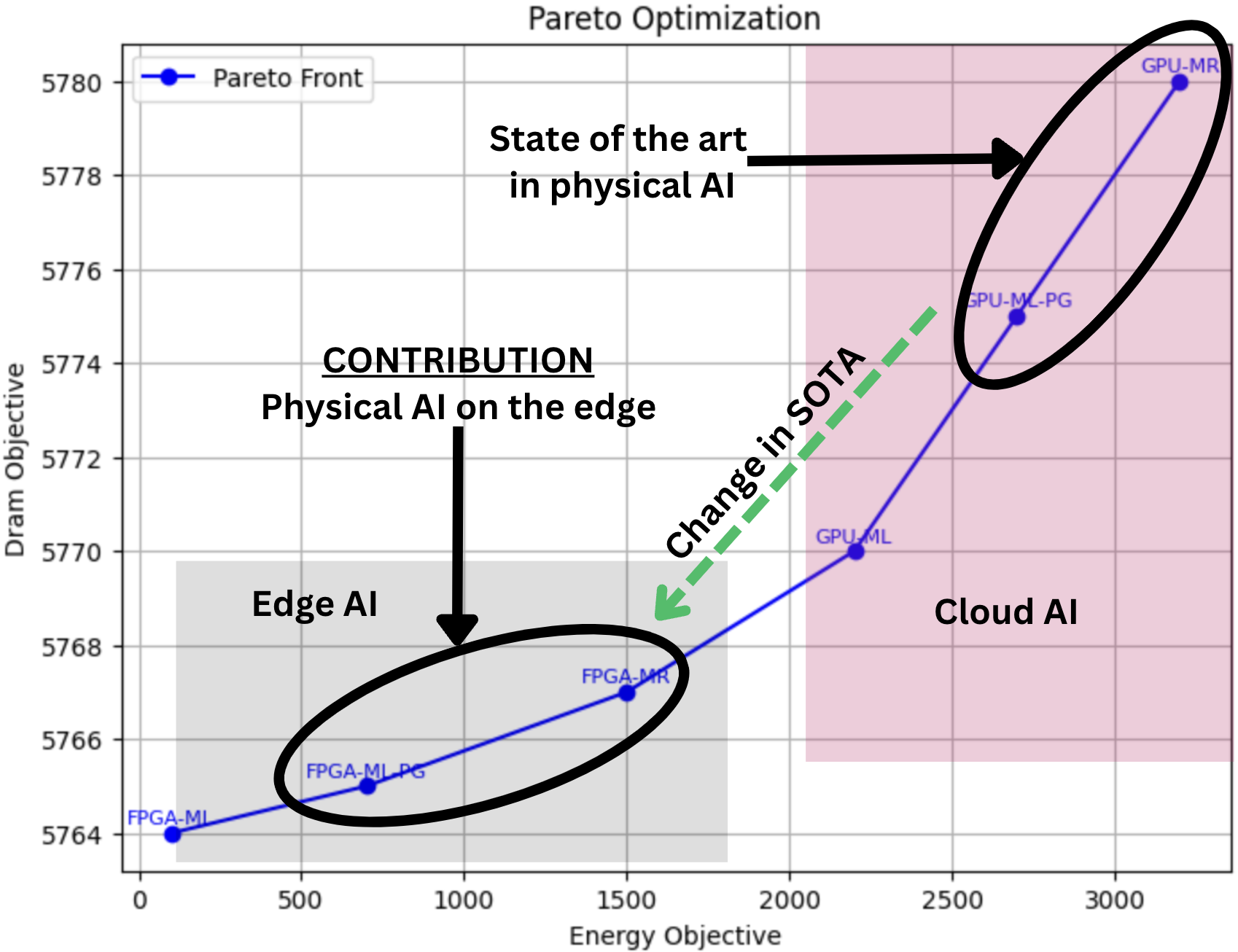
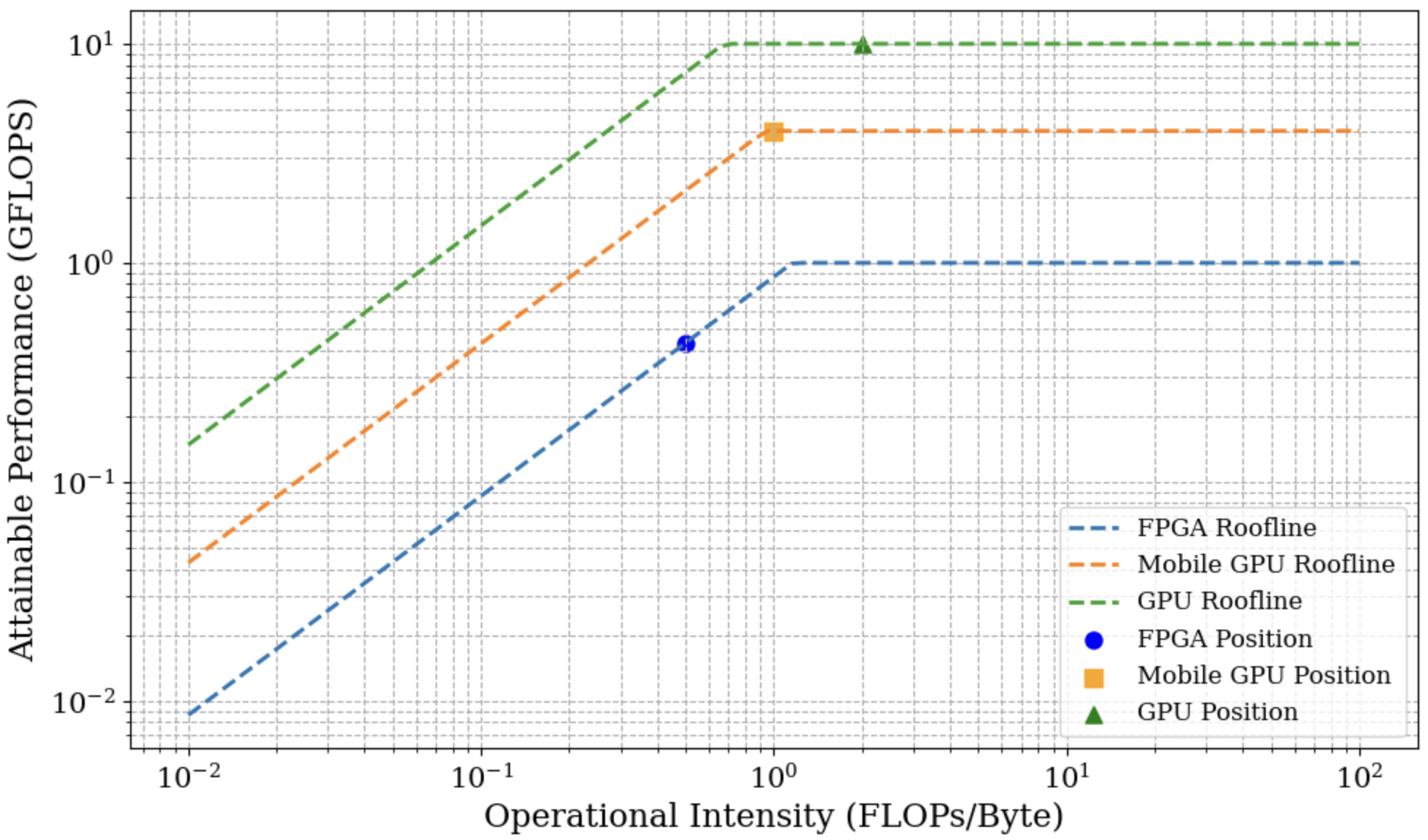
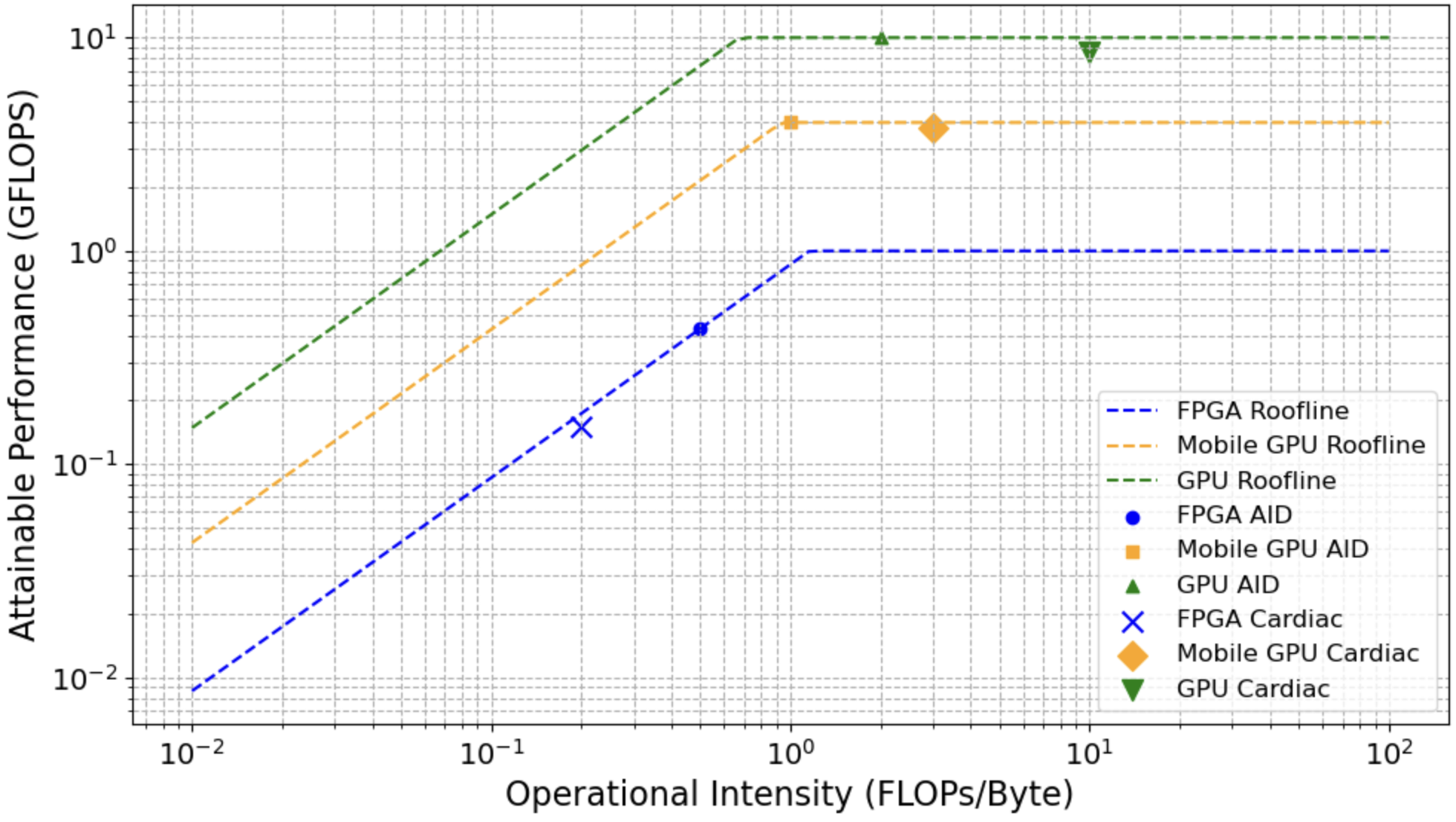
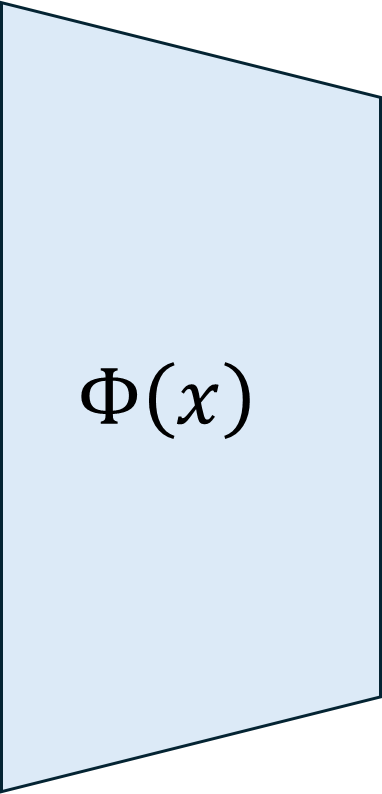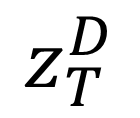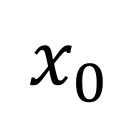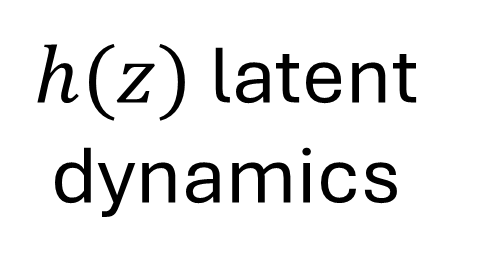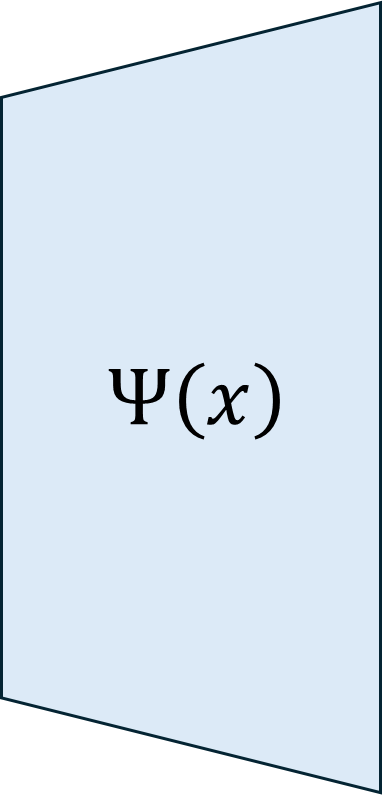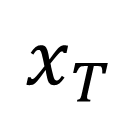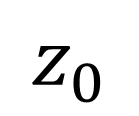Digital twins (DTs) can enable precision healthcare by continually learning a mathematical representation of patient-specific dynamics. However, mission critical healthcare applications require fast, resource-efficient DT learning, which is often infeasible with existing model recovery (MR) techniques due to their reliance on iterative solvers and high compute/memory demands. In this paper, we present a general DT learning framework that is amenable to acceleration on reconfigurable hardware such as FPGAs, enabling substantial speedup and energy efficiency. We compare our FPGA-based implementation with a multi-processing implementation in mobile GPU, which is a popular choice for AI in edge devices. Further, we compare both edge AI implementations with cloud GPU baseline. Specifically, our FPGA implementation achieves an 8.8x improvement in \text{performance-per-watt} for the MR task, a 28.5x reduction in DRAM footprint, and a 1.67x runtime speedup compared to cloud GPU baselines. On the other hand, mobile GPU achieves 2x better performance per watts but has 2x increase in runtime and 10x more DRAM footprint than FPGA. We show the usage of this technique in DT guided synthetic data generation for Type 1 Diabetes and proactive coronary artery disease detection.
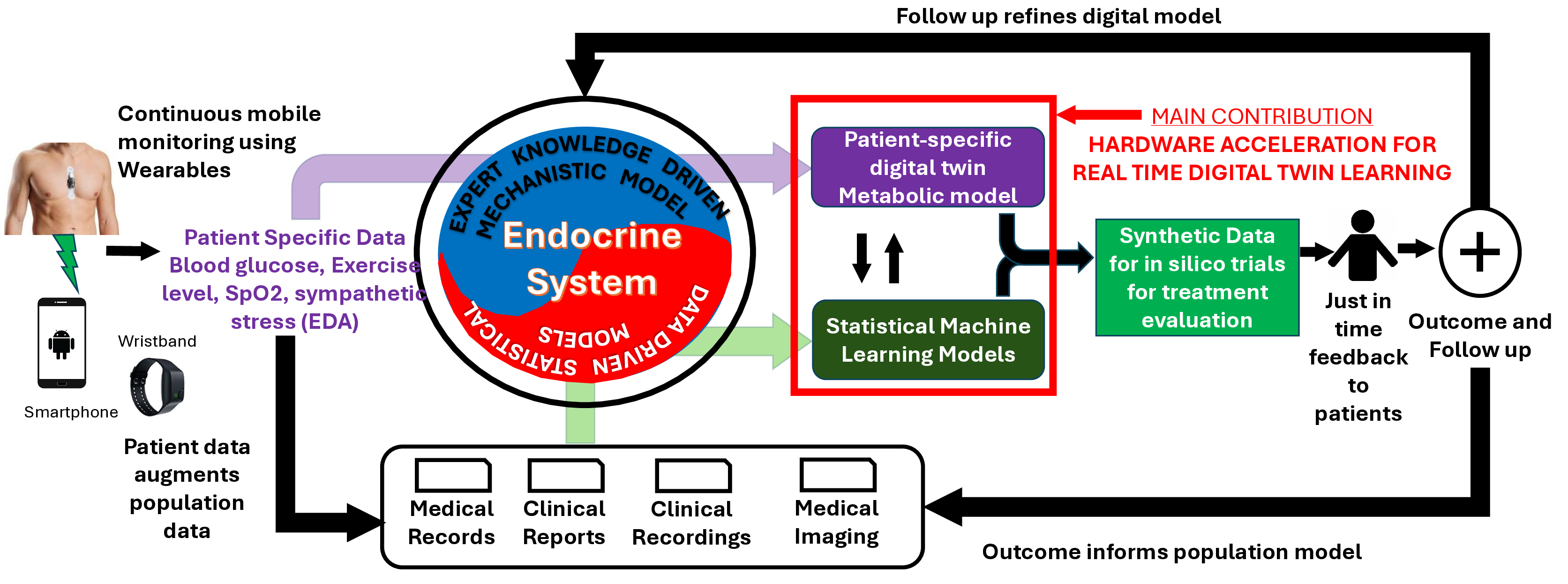
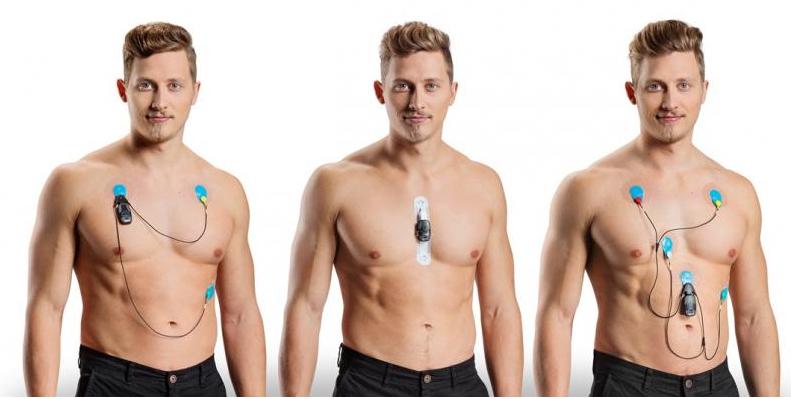
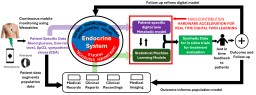
A key technological innovation towards physical AI [1] is the concept of digital twin (DT). DTs are mathematical models of physical processes with two essential properties: a) the model structure is guided by first-principle satisfied by the physical process, and b) the model parameters are continuously calibrated with real world data in real-time. A major application of DT is in precision medicine, which brings a fundamental shift in disease management from decision making based on statistical inferences of individual variance of treatment efficacy to patient specific evaluations leading to just-in-time diagnosis, personalized treatment, and individualized recovery as shown in Figure 1.
A continuously calibrated DT can be used for simulating various potential treatment plans for their safety and efficacy on the specific patient [2]- [6], derive a personalized verified safe and effective plan [7], [8] or identify novel operational scenarios [9]. Given the mission critical nature of the application of precision medicine, the calibration, simulation and safety / efficacy feedback has to be performed within time constraints. These constraints are application specific and guided by hazard evolution dynamics [10] as shown in Table I.
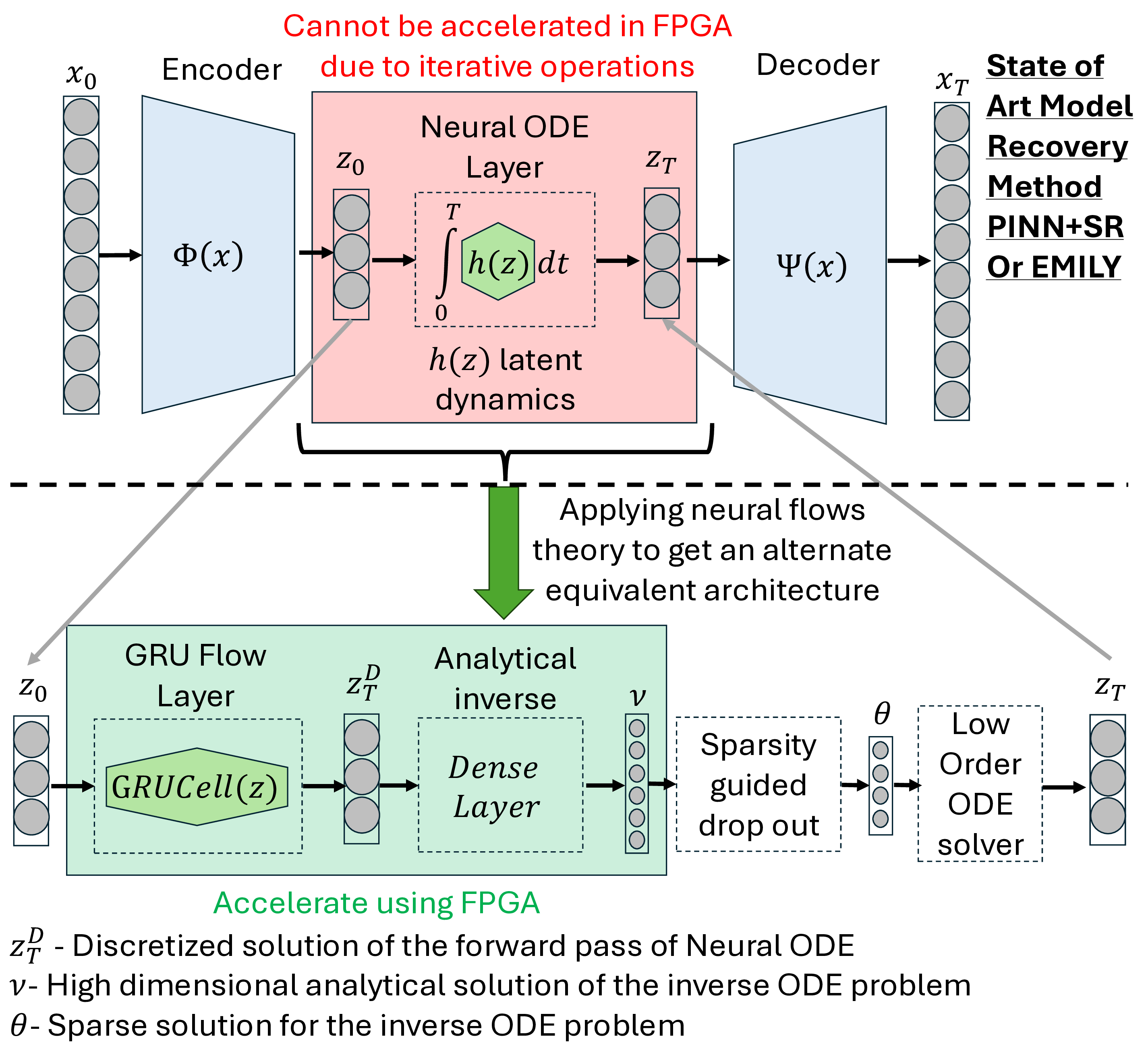
Automated continuous learning of DT in real-time is a major scientific challenge in the age of physical AI. Real-Time Challenge: The primary computational component of DT learning is physics-guided model recovery [11], where the model coefficients of a first-principle based differential dynamics is learned from real data under constraints of sampling, implicit or unmonitored dynamics, and human errors. The computational needs of physics-guided model recovery (MR) may prevent real-time operation even with parallelization with state-of-the-art (SOTA) multi-processing pipeline. Table I shows that the time to learn an application specific DT exceeds the response time required to avoid medical hazards. One of the fundamental reason is that analytical operations with physics-guided models require solution of differential dynamics which are iterative in nature. Such iterative operations are not amenable for parallelization. As such the SOTA multiprocessing pipeline is less effective in real-time DT learning. Cardiac disease [12], [13] Ischemia Alert first responders 100s
Brain sensing [11], [14] Attention deficit
Resistance capacitance model 321s 125s
Edge AI [15] Challenge: Data driven inferencing in realtime suffers from data transfer bottleneck (Table I shows data transfer times in medical DT applications forms a significant percentage or even exceeds response time). Recent advancements in edge AI aim to bring DT learning computation closer to data source, potentially bypassing the data transfer time. However, edge AI devices such as mobile GPU are resource constrained and hence may not be capable of DT learning within real-time constraints.
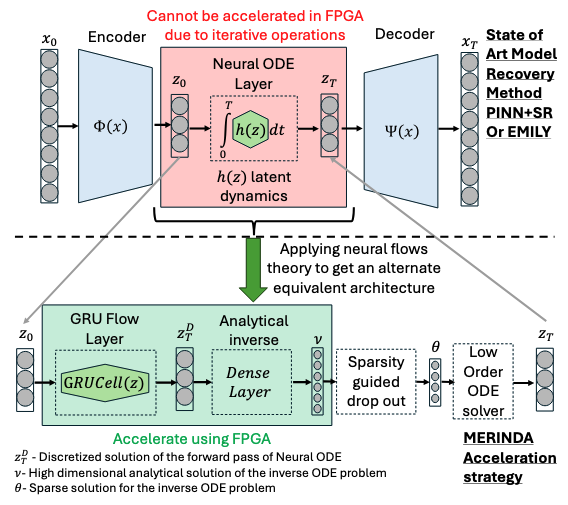
Real World Challenge: Data obtained from real world deployments of healthcare systems are restricted in sampling rate, and often compromised signal quality with potentially poor signal-to-noise ratio (SNR) especially when collected from human participants in free living conditions [16], [17]. Moreover, privacy constraints may lead to unavailability of measurements of key dynamical parameters of the DTs. Hence, any DT learning mechanism in the real world require to learn implicit or unmeasured dynamics. Recently physics-guided sparse model recovery techniques such as Physics Informed Neural Networks (PINNs) [18] or Physics informed Neural ODE (PiNODE) [19] or Extracting sparse Model from ImpLicit dYnamics (EMILY) [16] have been proposed to tackle implicit dynamics under low sampling frequencies. These techniques calibrate DT with real world data by following the Koopman theory [20]. The techniques attempt to learn a Koopman operator [20] that models the first-principle based DT dynamics using an expanded sparse state space where the dynamics become linear. The techniques utilize the universal function modeling capability of neural networks to learn the implicit dynamics while maintaining robustness to sensor noise. However, apart from the significant computational requirements of solving an Ordinary Differential Equation (ODE) in each learning step, these techniques also suffer from high memory requirements to store the expanded state space during computation. Hence, although these techniques are capable to calibrate DTs with real world data, they may not meet the real-time requirements and resource constraints of edge devices to support edge AI applications.
The hardware acceleration of physics-guided model recovery techniques remains a relatively underexplored research area, particularly in terms of evaluating their feasibility for meeting the timing and resource constraints of edge AI applications. In this paper, we demonstrate a pathway towards hardware acceleration of physics-guided model recovery such as PINNs, PiNODE, and EMILY to enabl
This content is AI-processed based on open access ArXiv data.