Semantic distance measurement is a fundamental problem in computational linguistics, providing a quantitative characterization of similarity or relatedness between text segments, and underpinning tasks such as text retrieval and text classification. From a mathematical perspective, a semantic distance can be viewed as a metric defined on a space of texts or on a representation space derived from them. However, most classical semantic distance methods are essentially fixed, making them difficult to adapt to specific data distributions and task requirements. In this paper, a semantic distance measure based on multi-kernel Gaussian processes (MK-GP) was proposed. The latent semantic function associated with texts was modeled as a Gaussian process, with its covariance function given by a combined kernel combining Matérn and polynomial components. The kernel parameters were learned automatically from data under supervision, rather than being hand-crafted. This semantic distance was instantiated and evaluated in the context of fine-grained sentiment classification with large language models under an in-context learning (ICL) setup. The experimental results demonstrated the effectiveness of the proposed measure.
Measuring semantic distance, understood as how similar or related two texts are in meaning, is a fundamental problem in computational linguistics [1]. Effective distance measures support information retrieval [2], text classification [3], and recent large language model (LLM) paradigms such as in-context learning and retrieval-augmented generation [4].
Classical approaches can be roughly grouped into three families: (1) Statistical methods in the raw text space, such as TF-IDF and BM25 [2]; (2) Embedding-based methods, which obtain dense vectors from neural encoders such as BERT and Sentence-BERT [5] and then apply simple metrics like cosine similarity; and (3) Kernel-based methods, which define similarity via positive-definite kernels in an implicit feature space [6].
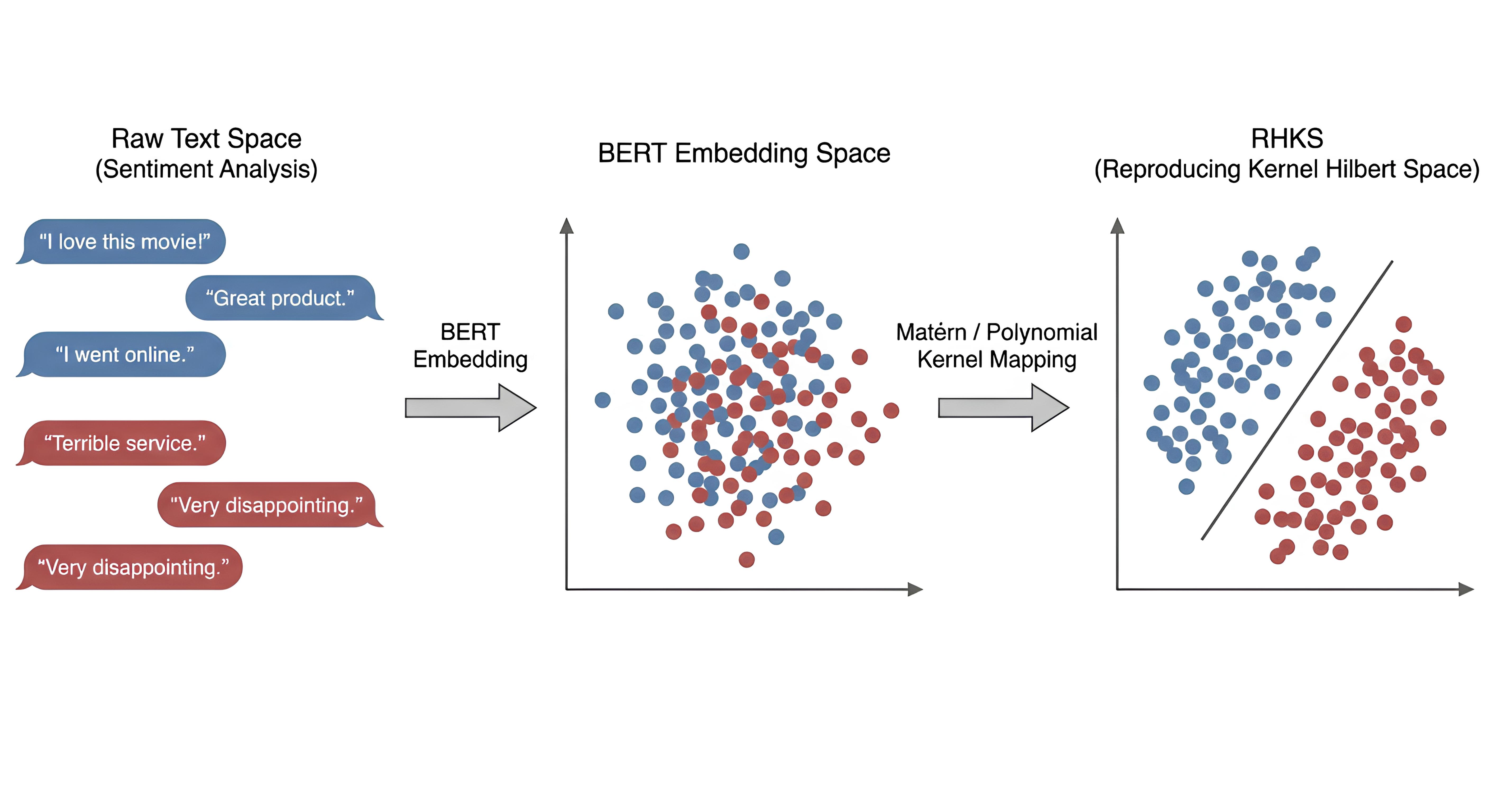
Despite substantial progress, learning a representation and metric that encode task-specific semantic relations remained challenging when semantics were subtle, context-dependent, or organized along fine-grained categories. Multi-class sentiment classification was a prime example: labels such as “very positive” and “slightly positive” lay close on an affective continuum yet corresponded to distinct attitudes [7]. Texts in adjacent sentiment categories often shared similar lexical patterns, making them hard to separate using frequency-based methods that relied on term occurrence and inverse document frequency [3]. Embeddingbased methods with cosine similarity further assumed a globally smooth, approximately linear geometry of semantic space, which blurred fine distinctions and underrepresented non-linear phenomena such as negation, intensifiers, and sarcasm [8].
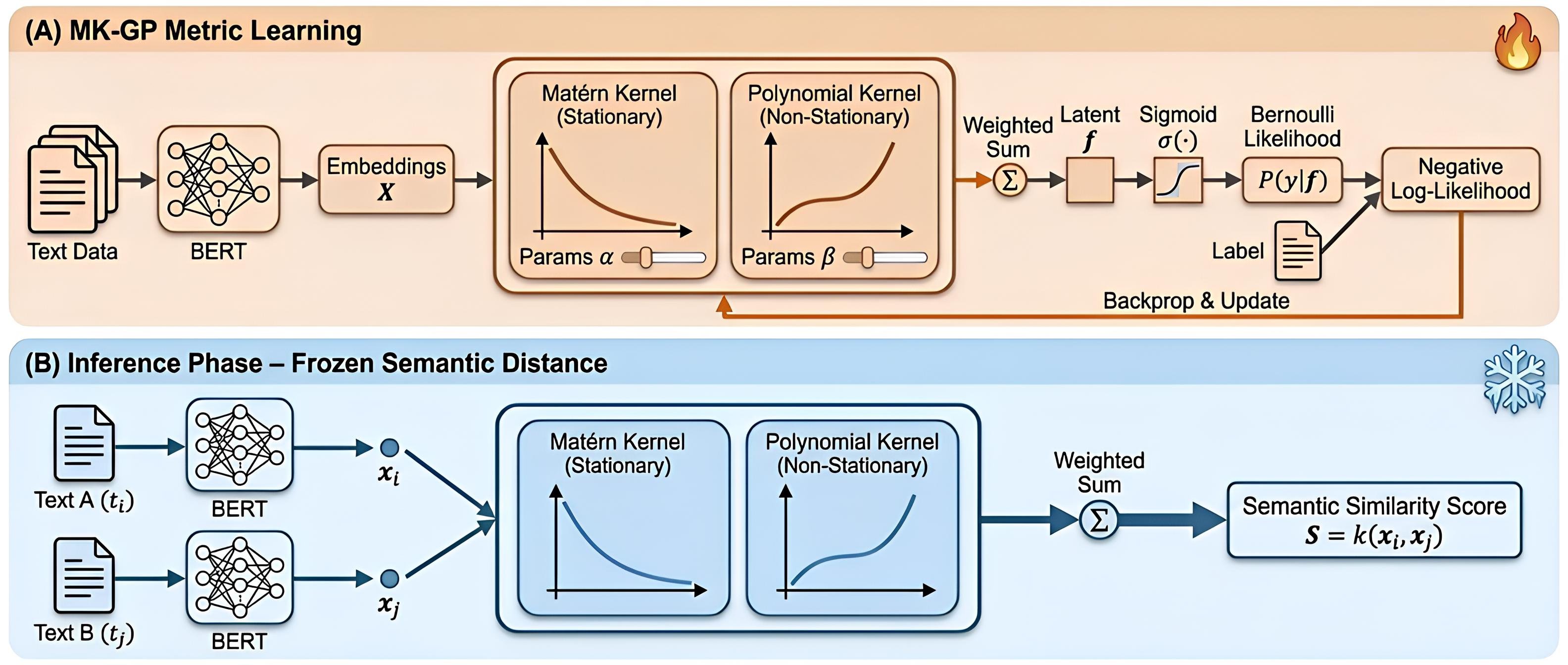
This paper addresses these limitations by proposing a semantic distance framework based on multi-kernel Gaussian processes (MK-GP). The unknown task-specific function that maps text representations to sentiment values is treated as being drawn from a Gaussian process prior with constant mean and a combined covariance function. Within this framework, semantic similarity is governed by the geometry implied by the covariance function rather than by a fixed embedding space with a hand-designed metric. Two texts are considered close when the Gaussian process prior expects similar latent outputs for them; conversely, they are far apart when the prior allows the function to vary substantially between the corresponding points. This induces a natural notion of task-aware distance linked to how uncertain the model is about interpolating between texts, providing a principled way to express confidence in fine-grained distinctions when data are scarce or ambiguous.
This paper makes the following contributions:
MK-GP-based semantic distance framework. A Gaussian-process-based semantic distance framework is proposed, in which a combined covariance function defines a learned, task-specific covariance geometry over representations and induces an explicit distance measure, replacing fixed vector-space metrics.
MK-GP learning algorithm. A multi-kernel Gaussian process construction is designed that combines Matérn and polynomial kernels, and a training procedure is developed to learn the combined covariance and its hyperparameters from data. The learned MK-GP geometry yields a task-specific semantic distance that is compatible with modern LLM-based feature extractors and retrieval frameworks. 3. Fine-grained sentiment ICL instantiation and analysis. The framework is instantiated in the setting of in-context learning for fine-grained sentiment tasks, using the learned MK-GP semantic distance to select support examples for LLM prompts. The analysis shows how the induced geometry captures subtle sentiment differences and ordinal structure along the sentiment continuum, and how MK-GP-based example selection impacts downstream ICL performance.
The remainder of this paper is organized as follows. Section 2 reviews related work on semantic distance metrics, kernel-based approaches for textual semantic modeling, and semantic distance measurement in the era of LLMs. Section 3 presents the proposed MK-GP methodology, detailing the multi-kernel Gaussian process formulation for semantic distance estimation and its integration with in-context learning. Section 4 reports the experiments and analyzes the empirical results. Finally, Section 5 concludes the paper and discusses directions for future work.
Text distance measures aim to quantify the similarity between pieces of text (e.g., sentences or documents). A smaller distance indicates a higher similarity. Three classical families of text distance/similarity measures are now introduced.
Classical information retrieval models such as TF-IDF and BM25 measure similarity via word overlap and term frequency statistics, often within a probabilistic relevance framework [9]. These methods work well when lexical overlap correlates with meaning, but fail on subtle, contextual phenomena such as negation or pragmatic implicature that require modeling beyond surface
This content is AI-processed based on open access ArXiv data.